 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallelizing Thompson Sampling
Jun 02, 2021
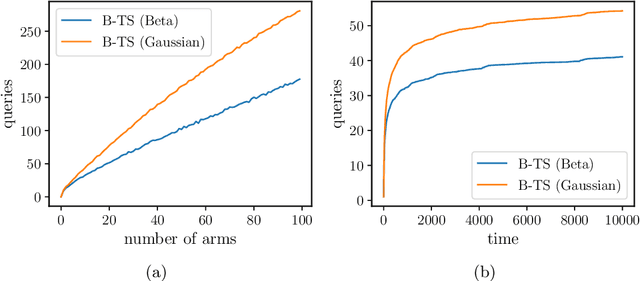
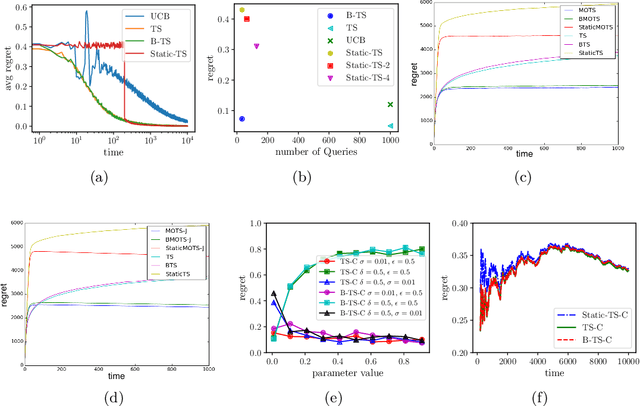
How can we make use of information parallelism in online decision making problems while efficiently balancing the exploration-exploitation trade-off? In this paper, we introduce a batch Thompson Sampling framework for two canonical online decision making problems, namely, stochastic multi-arm bandit and linear contextual bandit with finitely many arms. Over a time horizon $T$, our \textit{batch} Thompson Sampling policy achieves the same (asymptotic) regret bound of a fully sequential one while carrying out only $O(\log T)$ batch queries. To achieve this exponential reduction, i.e., reducing the number of interactions from $T$ to $O(\log T)$, our batch policy dynamically determines the duration of each batch in order to balance the exploration-exploitation trade-off. We also demonstrate experimentally that dynamic batch allocation dramatically outperforms natural baselines such as static batch allocations.
Transformer Network for Significant Stenosis Detection in CCTA of Coronary Arteries
Jul 07, 2021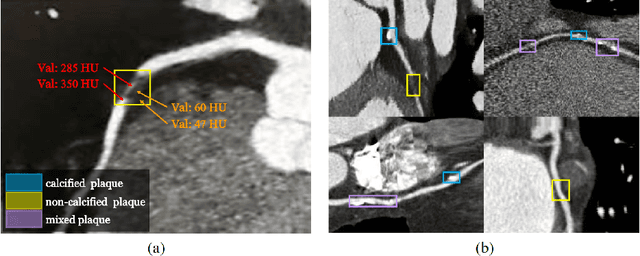
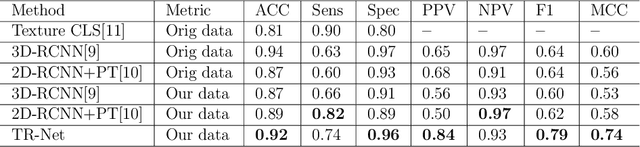
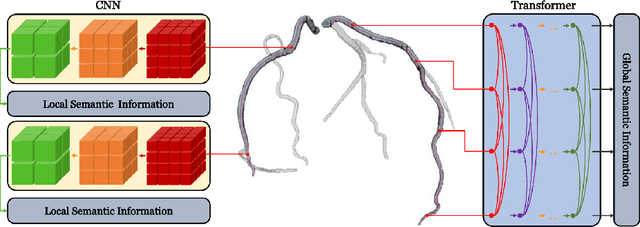
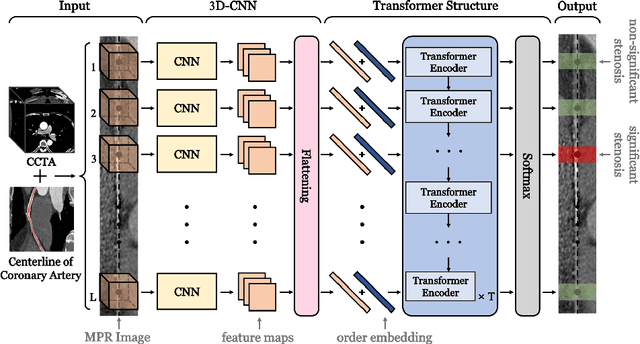
Coronary artery disease (CAD) has posed a leading threat to the lives of cardiovascular disease patients worldwide for a long time. Therefore, automated diagnosis of CAD has indispensable significance in clinical medicine. However, the complexity of coronary artery plaques that cause CAD makes the automatic detection of coronary artery stenosis in Coronary CT angiography (CCTA) a difficult task. In this paper, we propose a Transformer network (TR-Net) for the automatic detection of significant stenosis (i.e. luminal narrowing > 50%) while practically completing the computer-assisted diagnosis of CAD. The proposed TR-Net introduces a novel Transformer, and tightly combines convolutional layers and Transformer encoders, allowing their advantages to be demonstrated in the task. By analyzing semantic information sequences, TR-Net can fully understand the relationship between image information in each position of a multiplanar reformatted (MPR) image, and accurately detect significant stenosis based on both local and global information. We evaluate our TR-Net on a dataset of 76 patients from different patients annotated by experienced radiologists. Experimental results illustrate that our TR-Net has achieved better results in ACC (0.92), Spec (0.96), PPV (0.84), F1 (0.79) and MCC (0.74) indicators compared with the state-of-the-art methods. The source code is publicly available from the link (https://github.com/XinghuaMa/TR-Net).
Scientific Dataset Discovery via Topic-level Recommendation
Jun 07, 2021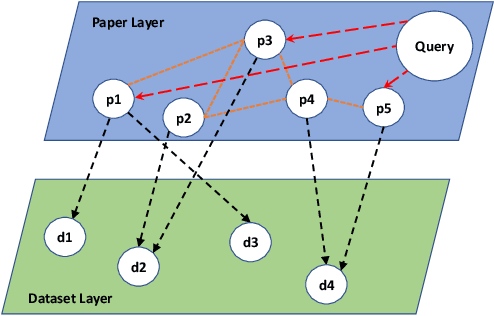
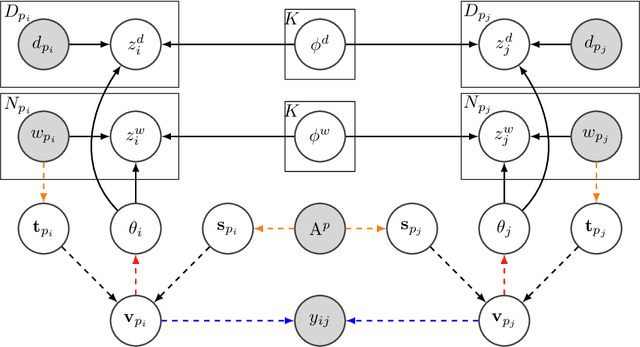
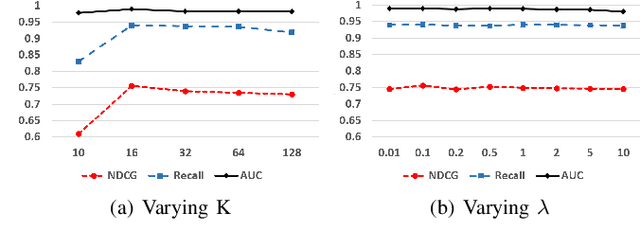
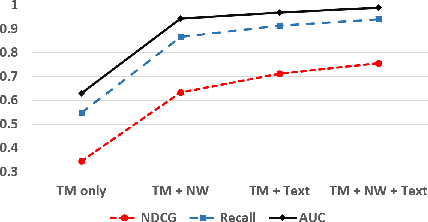
Data intensive research requires the support of appropriate datasets. However, it is often time-consuming to discover usable datasets matching a specific research topic. We formulate the dataset discovery problem on an attributed heterogeneous graph, which is composed of paper-paper citation, paper-dataset citation, and also paper content. We propose to characterize both paper and dataset nodes by their commonly shared latent topics, rather than learning user and item representations via canonical graph embedding models, because the usage of datasets and the themes of research projects can be understood on the common base of research topics. The relevant datasets to a given research project can then be inferred in the shared topic space. The experimental results show that our model can generate reasonable profiles for datasets, and recommend proper datasets for a query, which represents a research project linked with several papers.
Conditional Coding and Variable Bitrate for Practical Learned Video Coding
Apr 20, 2021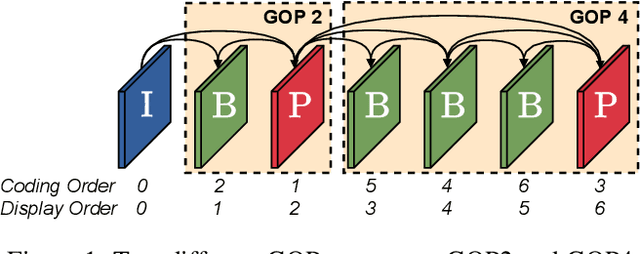
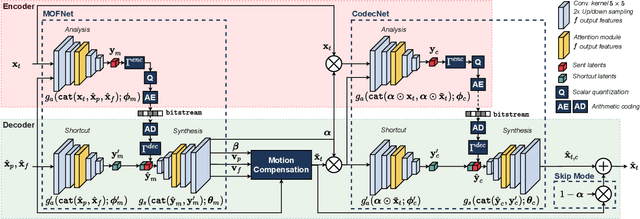
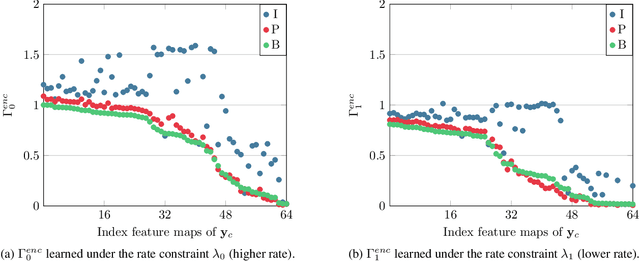
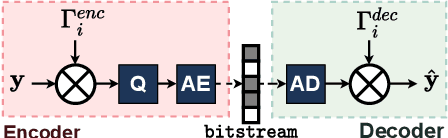
This paper introduces a practical learned video codec. Conditional coding and quantization gain vectors are used to provide flexibility to a single encoder/decoder pair, which is able to compress video sequences at a variable bitrate. The flexibility is leveraged at test time by choosing the rate and GOP structure to optimize a rate-distortion cost. Using the CLIC21 video test conditions, the proposed approach shows performance on par with HEVC.
On the Theory of Reinforcement Learning with Once-per-Episode Feedback
Jun 07, 2021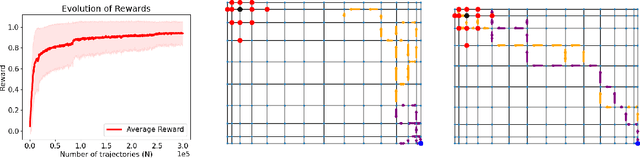
We study a theory of reinforcement learning (RL) in which the learner receives binary feedback only once at the end of an episode. While this is an extreme test case for theory, it is also arguably more representative of real-world applications than the traditional requirement in RL practice that the learner receive feedback at every time step. Indeed, in many real-world applications of reinforcement learning, such as self-driving cars and robotics, it is easier to evaluate whether a learner's complete trajectory was either "good" or "bad," but harder to provide a reward signal at each step. To show that learning is possible in this more challenging setting, we study the case where trajectory labels are generated by an unknown parametric model, and provide a statistically and computationally efficient algorithm that achieves sub-linear regret.
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
Jun 07, 2021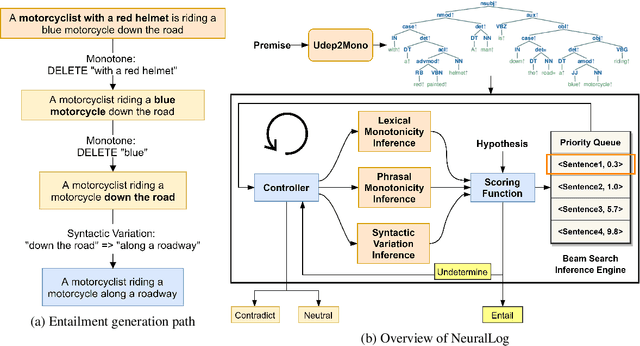
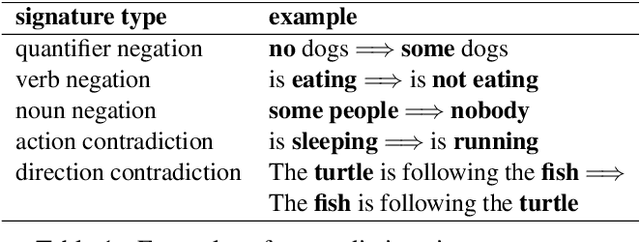
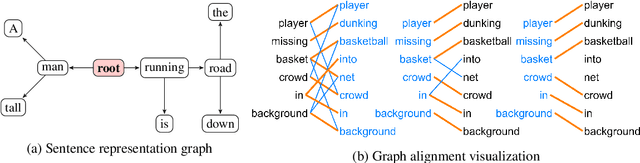

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
Towards On-Device Face Recognition in Body-worn Cameras
Apr 07, 2021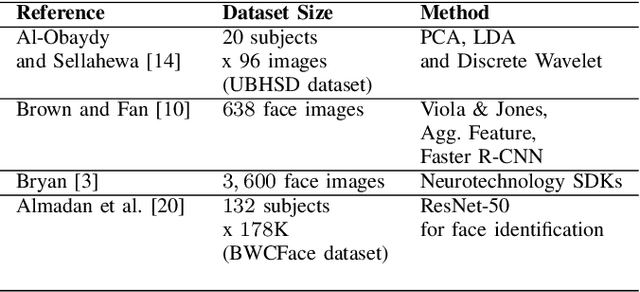
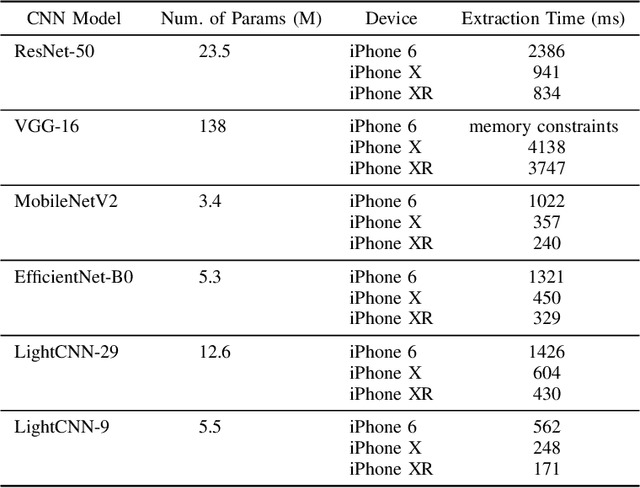
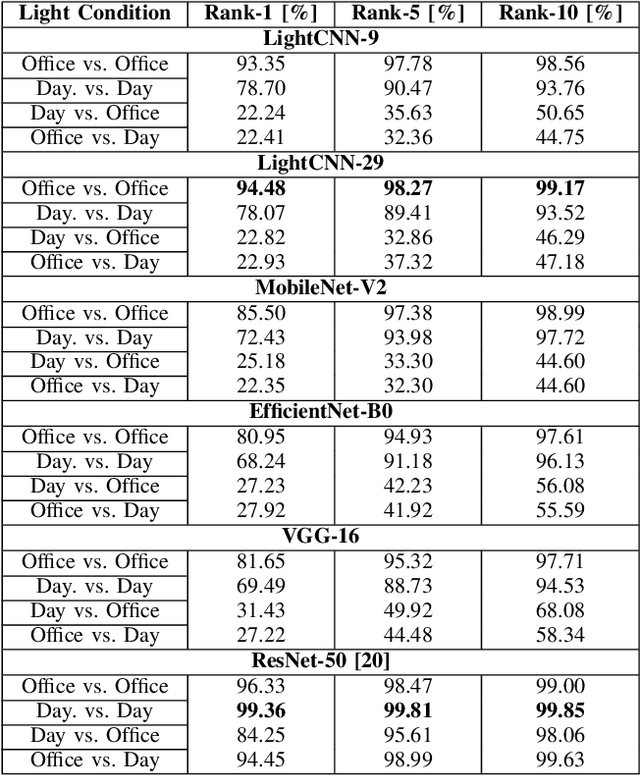
Face recognition technology related to recognizing identities is widely adopted in intelligence gathering, law enforcement, surveillance, and consumer applications. Recently, this technology has been ported to smartphones and body-worn cameras (BWC). Face recognition technology in body-worn cameras is used for surveillance, situational awareness, and keeping the officer safe. Only a handful of academic studies exist in face recognition using the body-worn camera. A recent study has assembled BWCFace facial image dataset acquired using a body-worn camera and evaluated the ResNet-50 model for face identification. However, for real-time inference in resource constraint body-worn cameras and privacy concerns involving facial images, on-device face recognition is required. To this end, this study evaluates lightweight MobileNet-V2, EfficientNet-B0, LightCNN-9 and LightCNN-29 models for face identification using body-worn camera. Experiments are performed on a publicly available BWCface dataset. The real-time inference is evaluated on three mobile devices. The comparative analysis is done with heavy-weight VGG-16 and ResNet-50 models along with six hand-crafted features to evaluate the trade-off between the performance and model size. Experimental results suggest the difference in maximum rank-1 accuracy of lightweight LightCNN-29 over best-performing ResNet-50 is \textbf{1.85\%} and the reduction in model parameters is \textbf{23.49M}. Most of the deep models obtained similar performances at rank-5 and rank-10. The inference time of LightCNNs is 2.1x faster than other models on mobile devices. The least performance difference of \textbf{14\%} is noted between LightCNN-29 and Local Phase Quantization (LPQ) descriptor at rank-1. In most of the experimental settings, lightweight LightCNN models offered the best trade-off between accuracy and the model size in comparison to most of the models.
* 6 pages
Automatic Real-time Anomaly Detection for Autonomous Aerial Vehicles
Jul 01, 2019
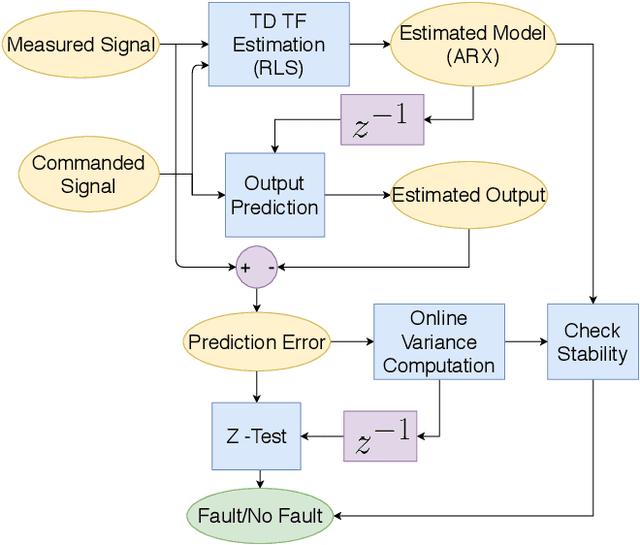
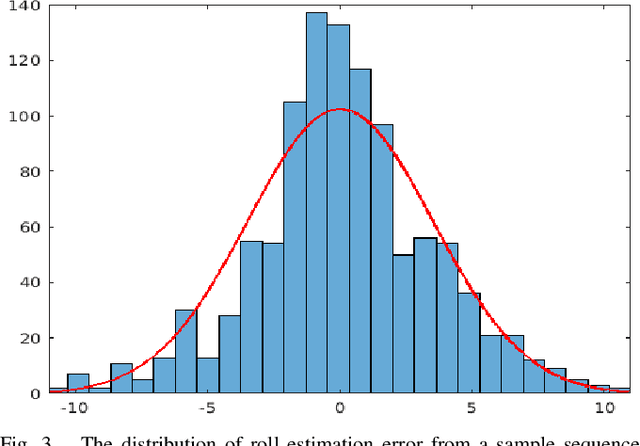

The recent increase in the use of aerial vehicles raises concerns about the safety and reliability of autonomous operations. There is a growing need for methods to monitor the status of these aircraft and report any faults and anomalies to the safety pilot or to the autopilot to deal with the emergency situation. In this paper, we present a real-time approach using the Recursive Least Squares method to detect anomalies in the behavior of an aircraft. The method models the relationship between correlated input-output pairs online and uses the model to detect the anomalies. The result is an easy-to-deploy anomaly detection method that does not assume a specific aircraft model and can detect many types of faults and anomalies in a wide range of autonomous aircraft. The experiments on this method show a precision of $88.23\%$, recall of $88.23\%$ and $86.36\%$ accuracy for over 22 flight tests. The other contribution is providing a new fault detection open dataset for autonomous aircraft, which contains complete data and the ground truth for 22 fixed-wing flights with eight different types of mid-flight actuator failures to help future fault detection research for aircraft.
Learning to Extend Program Graphs to Work-in-Progress Code
May 28, 2021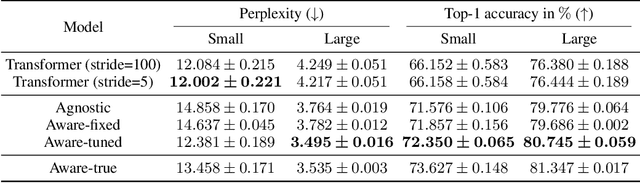
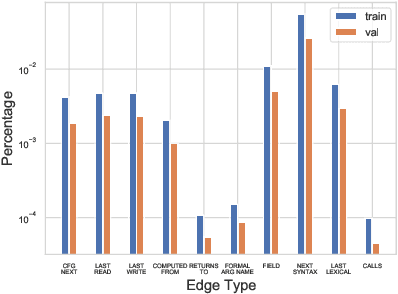
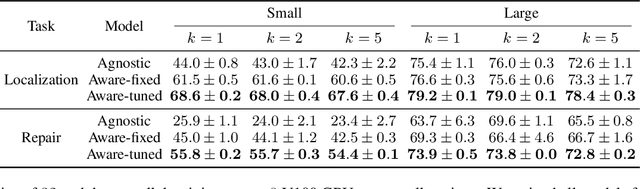
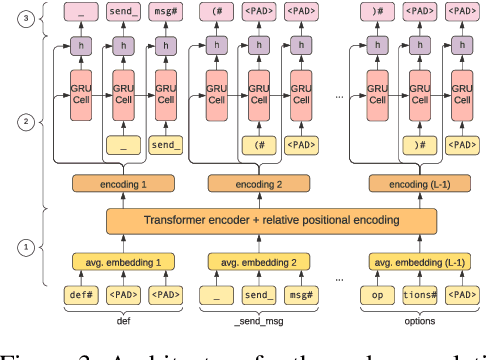
Source code spends most of its time in a broken or incomplete state during software development. This presents a challenge to machine learning for code, since high-performing models typically rely on graph structured representations of programs derived from traditional program analyses. Such analyses may be undefined for broken or incomplete code. We extend the notion of program graphs to work-in-progress code by learning to predict edge relations between tokens, training on well-formed code before transferring to work-in-progress code. We consider the tasks of code completion and localizing and repairing variable misuse in a work-in-process scenario. We demonstrate that training relation-aware models with fine-tuned edges consistently leads to improved performance on both tasks.
Comparison between DeepESNs and gated RNNs on multivariate time-series prediction
Dec 30, 2018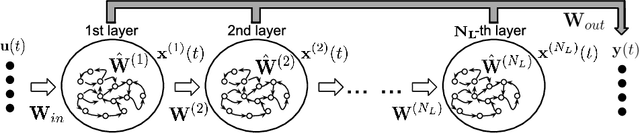
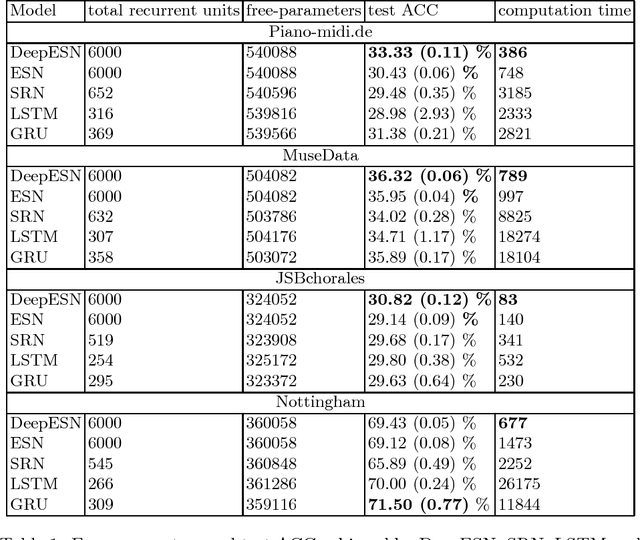
We propose an experimental comparison between Deep Echo State Networks (DeepESNs) and gated Recurrent Neural Networks (RNNs) on multivariate time-series prediction tasks. In particular, we compare reservoir and fully-trained RNNs able to represent signals featured by multiple time-scales dynamics. The analysis is performed in terms of efficiency and prediction accuracy on 4 polyphonic music tasks. Our results show that DeepESN is able to outperform ESN in terms of prediction accuracy and efficiency. Whereas, between fully-trained approaches, Gated Recurrent Units (GRU) outperforms Long Short-Term Memory (LSTM) and simple RNN models in most cases. Overall, DeepESN turned out to be extremely more efficient than others RNN approaches and the best solution in terms of prediction accuracy on 3 out of 4 tasks.