 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Sep 22, 2020
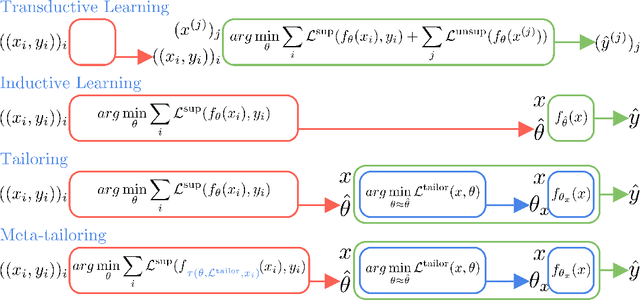
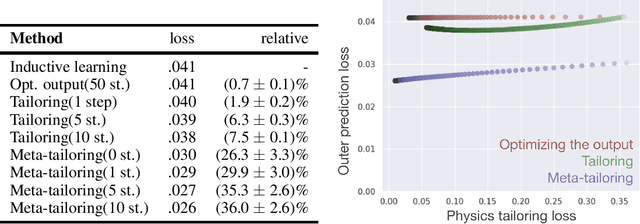
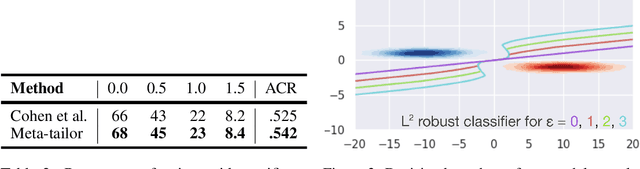
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from transductive learning and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.
Distributed Learning and Democratic Embeddings: Polynomial-Time Source Coding Schemes Can Achieve Minimax Lower Bounds for Distributed Gradient Descent under Communication Constraints
Mar 13, 2021
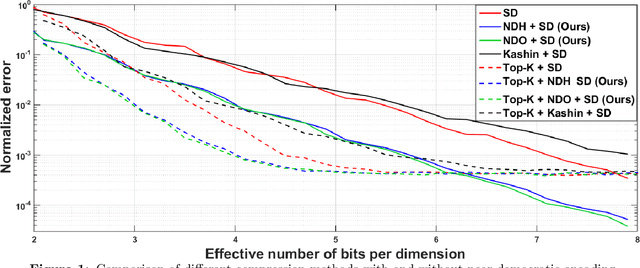
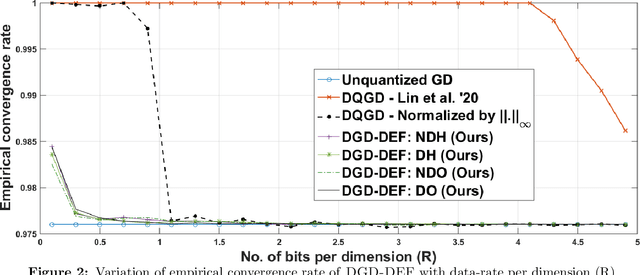
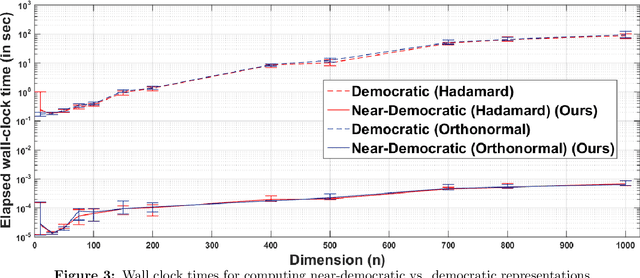
In this work, we consider the distributed optimization setting where information exchange between the computation nodes and the parameter server is subject to a maximum bit-budget. We first consider the problem of compressing a vector in the n-dimensional Euclidean space, subject to a bit-budget of R-bits per dimension, for which we introduce Democratic and Near-Democratic source-coding schemes. We show that these coding schemes are (near) optimal in the sense that the covering efficiency of the resulting quantizer is either dimension independent, or has a very weak logarithmic dependence. Subsequently, we propose a distributed optimization algorithm: DGD-DEF, which employs our proposed coding strategy, and achieves the minimax optimal convergence rate to within (near) constant factors for a class of communication-constrained distributed optimization algorithms. Furthermore, we extend the utility of our proposed source coding scheme by showing that it can remarkably improve the performance when used in conjunction with other compression schemes. We validate our theoretical claims through numerical simulations. Keywords: Fast democratic (Kashin) embeddings, Distributed optimization, Data-rate constraint, Quantized gradient descent, Error feedback.
Federated Learning with Dynamic Transformer for Text to Speech
Jul 09, 2021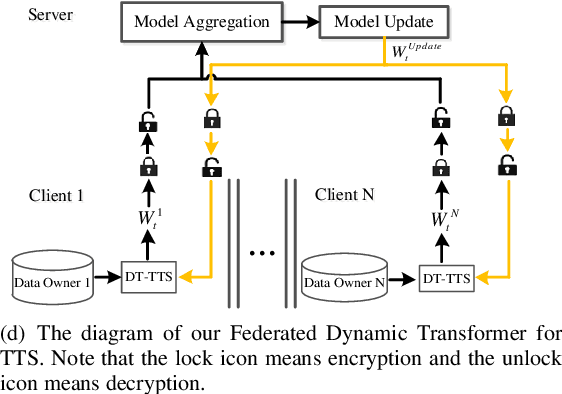

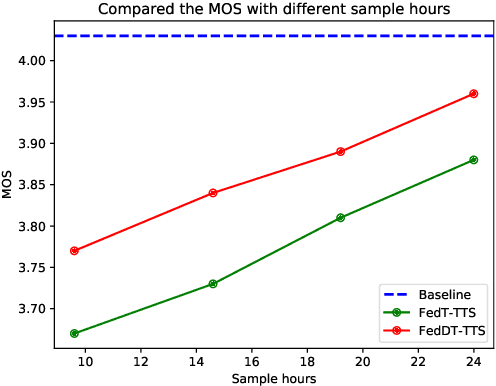
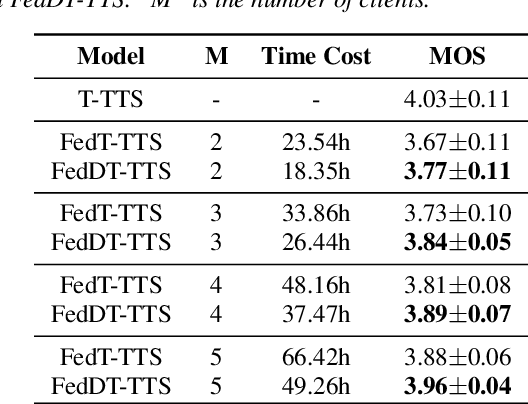
Text to speech (TTS) is a crucial task for user interaction, but TTS model training relies on a sizable set of high-quality original datasets. Due to privacy and security issues, the original datasets are usually unavailable directly. Recently, federated learning proposes a popular distributed machine learning paradigm with an enhanced privacy protection mechanism. It offers a practical and secure framework for data owners to collaborate with others, thus obtaining a better global model trained on the larger dataset. However, due to the high complexity of transformer models, the convergence process becomes slow and unstable in the federated learning setting. Besides, the transformer model trained in federated learning is costly communication and limited computational speed on clients, impeding its popularity. To deal with these challenges, we propose the federated dynamic transformer. On the one hand, the performance is greatly improved comparing with the federated transformer, approaching centralize-trained Transformer-TTS when increasing clients number. On the other hand, it achieves faster and more stable convergence in the training phase and significantly reduces communication time. Experiments on the LJSpeech dataset also strongly prove our method's advantage.
Edge-competing Pathological Liver Vessel Segmentation with Limited Labels
Aug 01, 2021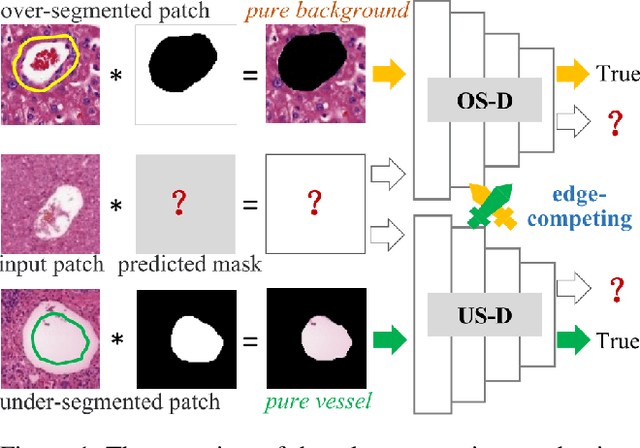
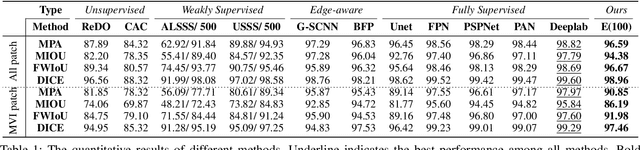
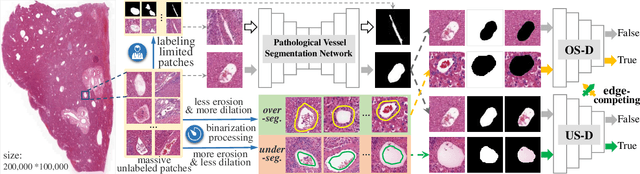
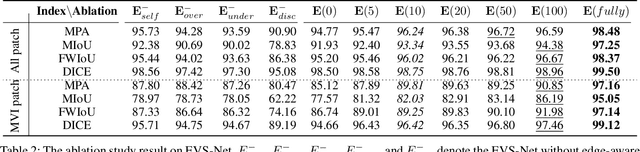
The microvascular invasion (MVI) is a major prognostic factor in hepatocellular carcinoma, which is one of the malignant tumors with the highest mortality rate. The diagnosis of MVI needs discovering the vessels that contain hepatocellular carcinoma cells and counting their number in each vessel, which depends heavily on experiences of the doctor, is largely subjective and time-consuming. However, there is no algorithm as yet tailored for the MVI detection from pathological images. This paper collects the first pathological liver image dataset containing 522 whole slide images with labels of vessels, MVI, and hepatocellular carcinoma grades. The first and essential step for the automatic diagnosis of MVI is the accurate segmentation of vessels. The unique characteristics of pathological liver images, such as super-large size, multi-scale vessel, and blurred vessel edges, make the accurate vessel segmentation challenging. Based on the collected dataset, we propose an Edge-competing Vessel Segmentation Network (EVS-Net), which contains a segmentation network and two edge segmentation discriminators. The segmentation network, combined with an edge-aware self-supervision mechanism, is devised to conduct vessel segmentation with limited labeled patches. Meanwhile, two discriminators are introduced to distinguish whether the segmented vessel and background contain residual features in an adversarial manner. In the training stage, two discriminators are devised tocompete for the predicted position of edges. Exhaustive experiments demonstrate that, with only limited labeled patches, EVS-Net achieves a close performance of fully supervised methods, which provides a convenient tool for the pathological liver vessel segmentation. Code is publicly available at https://github.com/zju-vipa/EVS-Net.
Explaining Ridesharing: Selection of Explanations for Increasing User Satisfaction
May 26, 2021
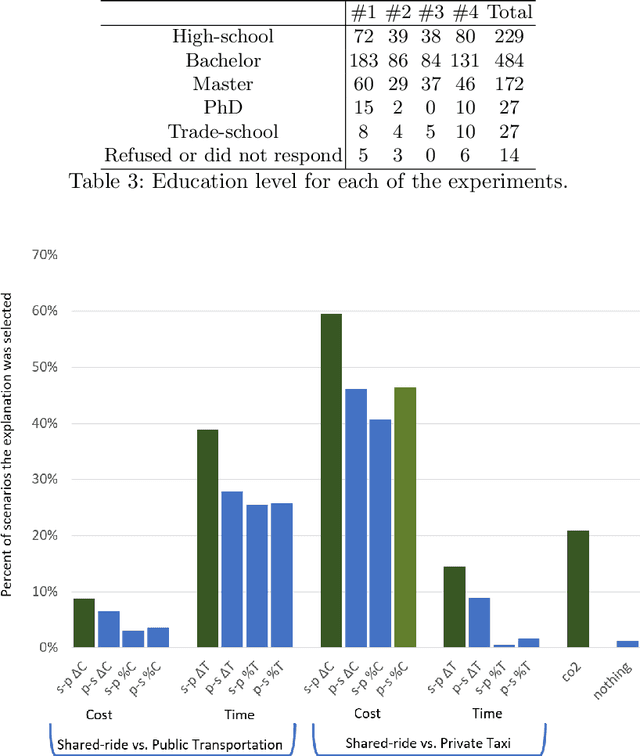
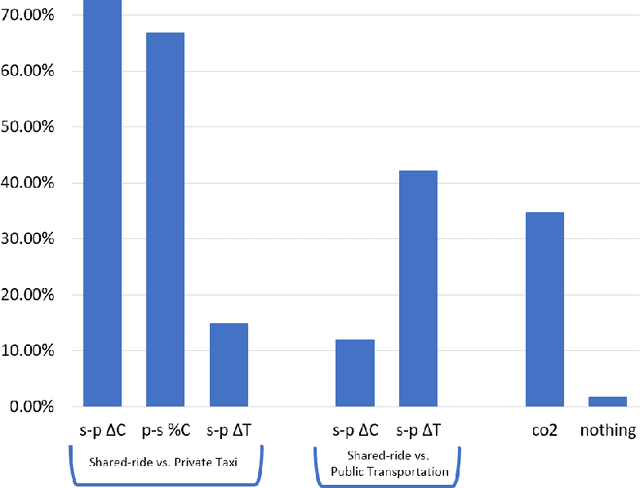

Transportation services play a crucial part in the development of modern smart cities. In particular, on-demand ridesharing services, which group together passengers with similar itineraries, are already operating in several metropolitan areas. These services can be of significant social and environmental benefit, by reducing travel costs, road congestion and CO2 emissions. Unfortunately, despite their advantages, not many people opt to use these ridesharing services. We believe that increasing the user satisfaction from the service will cause more people to utilize it, which, in turn, will improve the quality of the service, such as the waiting time, cost, travel time, and service availability. One possible way for increasing user satisfaction is by providing appropriate explanations comparing the alternative modes of transportation, such as a private taxi ride and public transportation. For example, a passenger may be more satisfied from a shared-ride if she is told that a private taxi ride would have cost her 50% more. Therefore, the problem is to develop an agent that provides explanations that will increase the user satisfaction. We model our environment as a signaling game and show that a rational agent, which follows the perfect Bayesian equilibrium, must reveal all of the information regarding the possible alternatives to the passenger. In addition, we develop a machine learning based agent that, when given a shared-ride along with its possible alternatives, selects the explanations that are most likely to increase user satisfaction. Using feedback from humans we show that our machine learning based agent outperforms the rational agent and an agent that randomly chooses explanations, in terms of user satisfaction.
Multi Projection Fusion for Real-time Semantic Segmentation of 3D LiDAR Point Clouds
Nov 06, 2020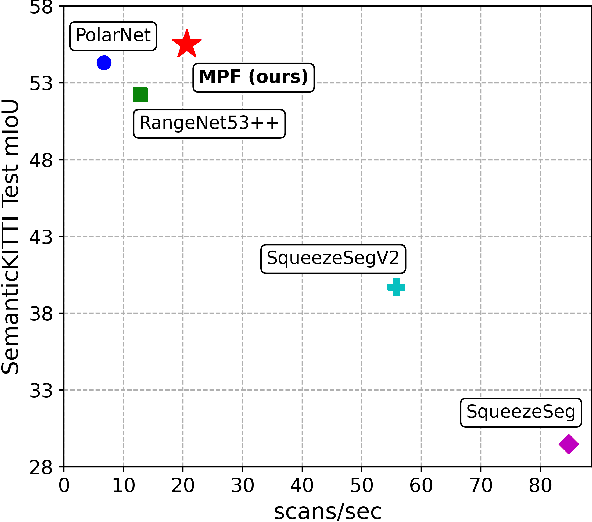
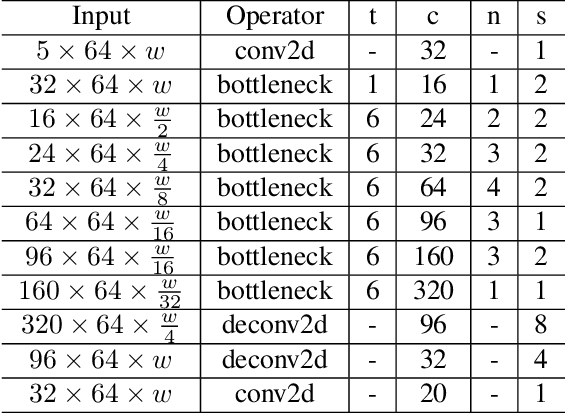
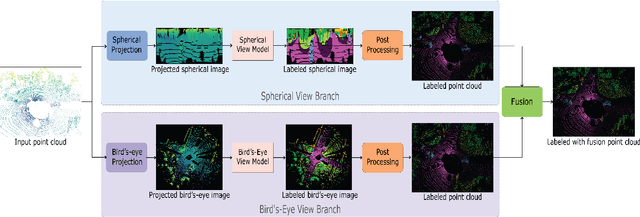
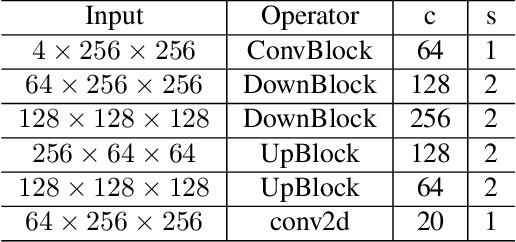
Semantic segmentation of 3D point cloud data is essential for enhanced high-level perception in autonomous platforms. Furthermore, given the increasing deployment of LiDAR sensors onboard of cars and drones, a special emphasis is also placed on non-computationally intensive algorithms that operate on mobile GPUs. Previous efficient state-of-the-art methods relied on 2D spherical projection of point clouds as input for 2D fully convolutional neural networks to balance the accuracy-speed trade-off. This paper introduces a novel approach for 3D point cloud semantic segmentation that exploits multiple projections of the point cloud to mitigate the loss of information inherent in single projection methods. Our Multi-Projection Fusion (MPF) framework analyzes spherical and bird's-eye view projections using two separate highly-efficient 2D fully convolutional models then combines the segmentation results of both views. The proposed framework is validated on the SemanticKITTI dataset where it achieved a mIoU of 55.5 which is higher than state-of-the-art projection-based methods RangeNet++ and PolarNet while being 1.6x faster than the former and 3.1x faster than the latter.
Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning
Jul 27, 2021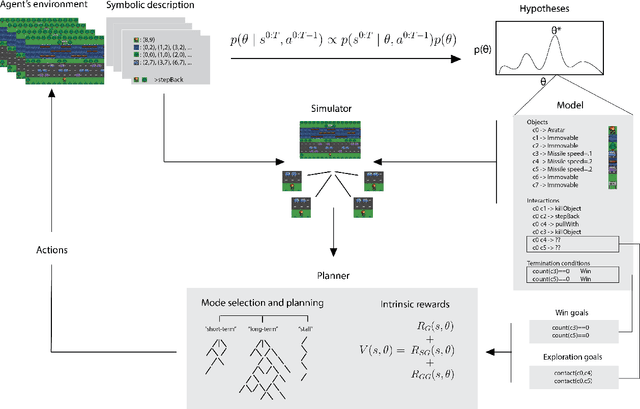
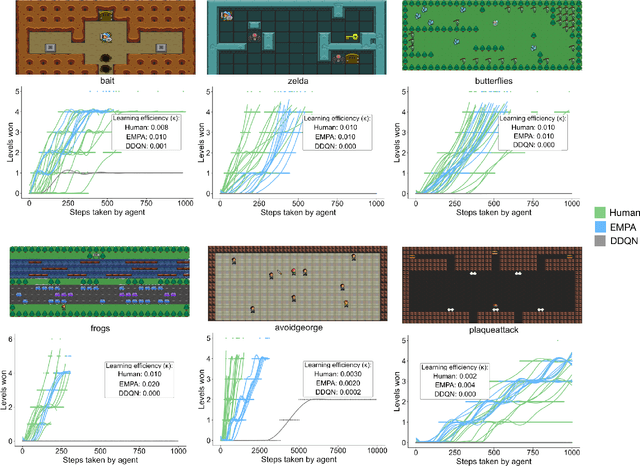
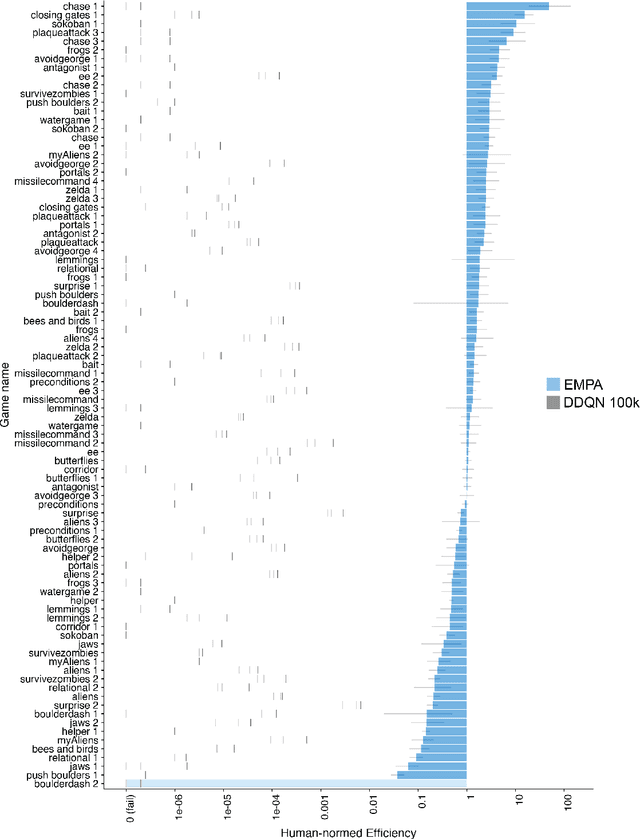
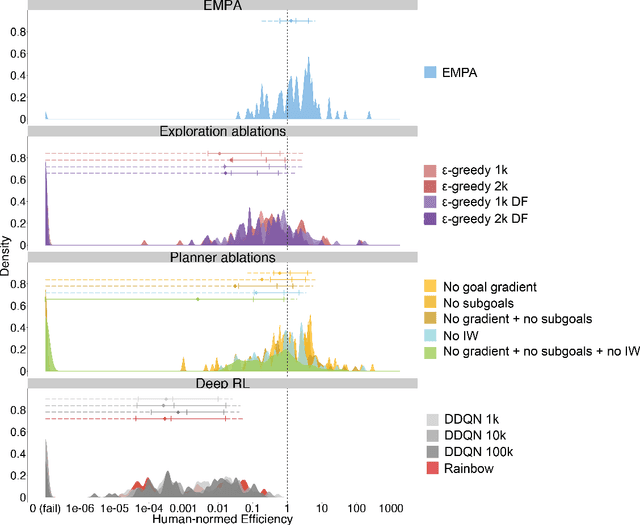
Reinforcement learning (RL) studies how an agent comes to achieve reward in an environment through interactions over time. Recent advances in machine RL have surpassed human expertise at the world's oldest board games and many classic video games, but they require vast quantities of experience to learn successfully -- none of today's algorithms account for the human ability to learn so many different tasks, so quickly. Here we propose a new approach to this challenge based on a particularly strong form of model-based RL which we call Theory-Based Reinforcement Learning, because it uses human-like intuitive theories -- rich, abstract, causal models of physical objects, intentional agents, and their interactions -- to explore and model an environment, and plan effectively to achieve task goals. We instantiate the approach in a video game playing agent called EMPA (the Exploring, Modeling, and Planning Agent), which performs Bayesian inference to learn probabilistic generative models expressed as programs for a game-engine simulator, and runs internal simulations over these models to support efficient object-based, relational exploration and heuristic planning. EMPA closely matches human learning efficiency on a suite of 90 challenging Atari-style video games, learning new games in just minutes of game play and generalizing robustly to new game situations and new levels. The model also captures fine-grained structure in people's exploration trajectories and learning dynamics. Its design and behavior suggest a way forward for building more general human-like AI systems.
Estimation of conditional mixture Weibull distribution with right-censored data using neural network for time-to-event analysis
Feb 21, 2020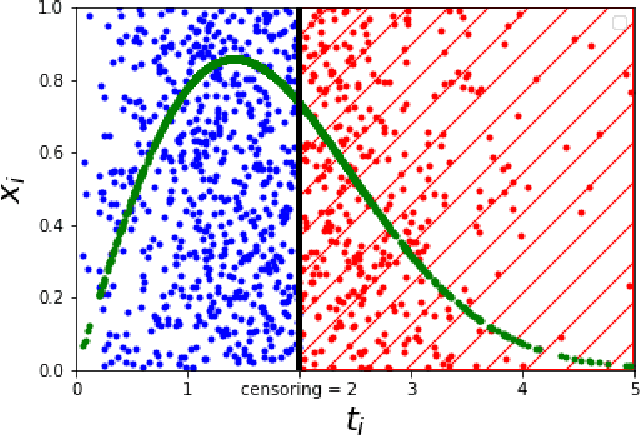
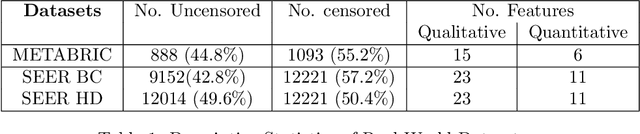
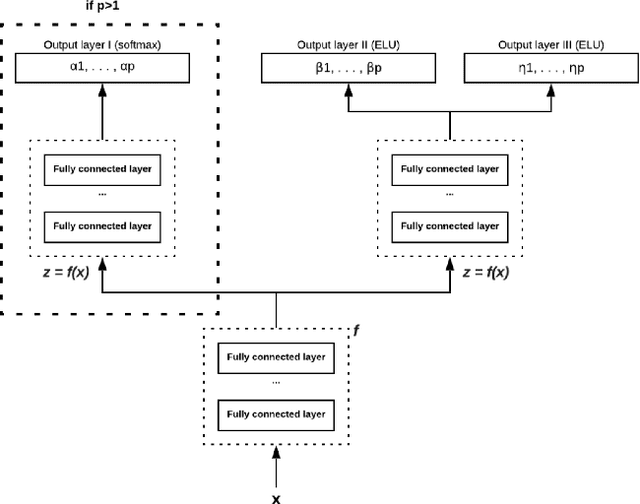
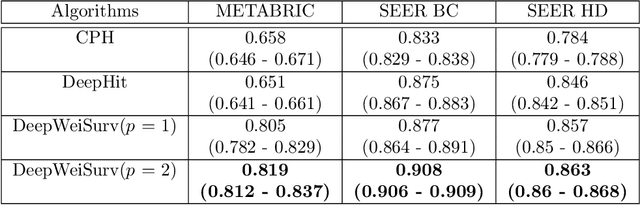
In this paper, we consider survival analysis with right-censored data which is a common situation in predictive maintenance and health field. We propose a model based on the estimation of two-parameter Weibull distribution conditionally to the features. To achieve this result, we describe a neural network architecture and the associated loss functions that takes into account the right-censored data. We extend the approach to a finite mixture of two-parameter Weibull distributions. We first validate that our model is able to precisely estimate the right parameters of the conditional Weibull distribution on synthetic datasets. In numerical experiments on two real-word datasets (METABRIC and SEER), our model outperforms the state-of-the-art methods. We also demonstrate that our approach can consider any survival time horizon.
Design Optimization of Monoblade Autorotating Pods To Exhibit an Unconventional Descent Technique Using Glauert's Modelling
Jul 01, 2021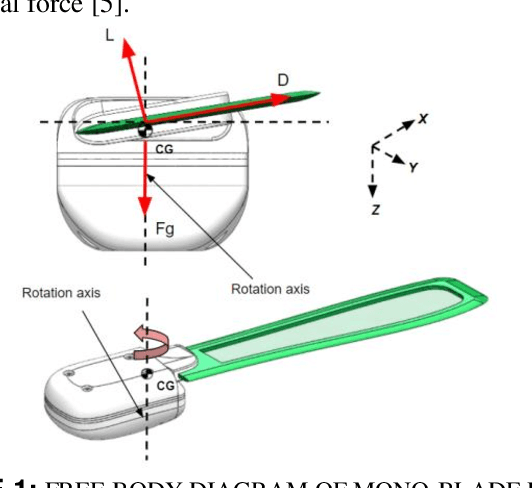
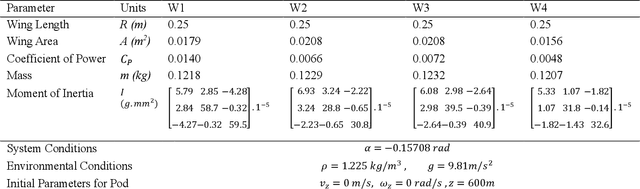
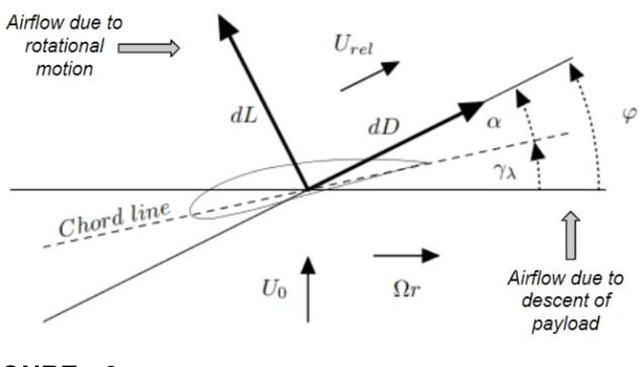
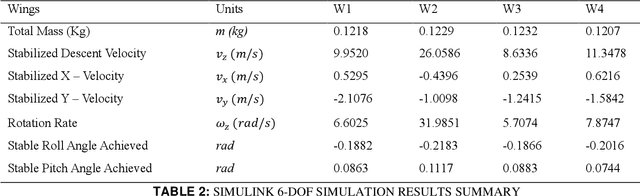
Many unconventional descent mechanisms are evolved in nature to maximize the dispersion of seeds to increase the population of floral species. The induced autorotation produces lift through asymmetrical weight distribution, increasing the fall duration and giving the seed extra time to get drifted away by the wind. The proposed bio-inspired concept was used to produce novel modern pods for various aerospace applications that require free-falling or controlled velocity descent in planetary or interplanetary missions without relying on traditional techniques such as propulsion-based descent and the use of parachutes. We provide an explanation for the design procedure and the functioning of a mono blade auto-rotating wing. An element-based computational method based on Glauert's blade element momentum theory (BEMT) model was employed to estimate the geometry by maximizing the coefficient of power through MATLAB's optimization toolbox using the Sequential quadratic programming (SQP) solver. The dynamic model was developed for the single-wing design through the MATLAB Simulink 6-DOF toolbox to carry out a free-flight simulation of the wing to verify its global stability.
High-Resolution Pelvic MRI Reconstruction Using a Generative Adversarial Network with Attention and Cyclic Loss
Jul 21, 2021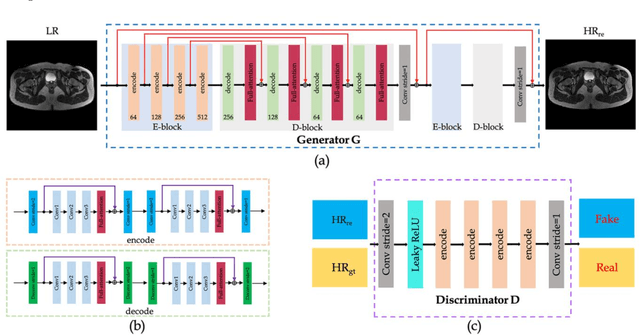
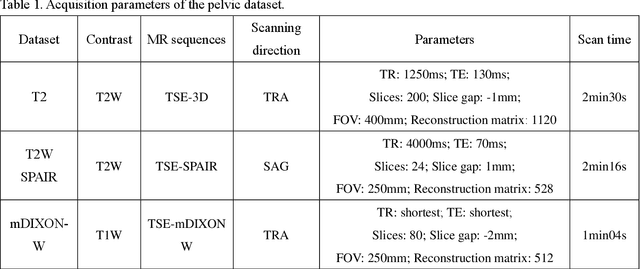
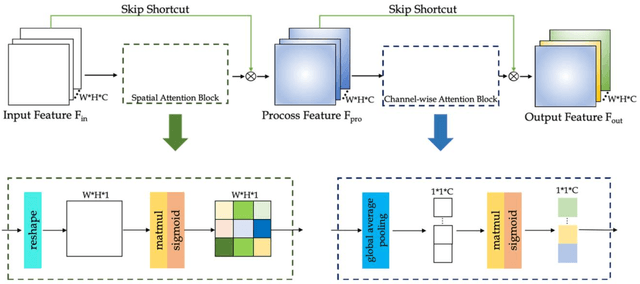

Magnetic resonance imaging (MRI) is an important medical imaging modality, but its acquisition speed is quite slow due to the physiological limitations. Recently, super-resolution methods have shown excellent performance in accelerating MRI. In some circumstances, it is difficult to obtain high-resolution images even with prolonged scan time. Therefore, we proposed a novel super-resolution method that uses a generative adversarial network (GAN) with cyclic loss and attention mechanism to generate high-resolution MR images from low-resolution MR images by a factor of 2. We implemented our model on pelvic images from healthy subjects as training and validation data, while those data from patients were used for testing. The MR dataset was obtained using different imaging sequences, including T2, T2W SPAIR, and mDIXON-W. Four methods, i.e., BICUBIC, SRCNN, SRGAN, and EDSR were used for comparison. Structural similarity, peak signal to noise ratio, root mean square error, and variance inflation factor were used as calculation indicators to evaluate the performances of the proposed method. Various experimental results showed that our method can better restore the details of the high-resolution MR image as compared to the other methods. In addition, the reconstructed high-resolution MR image can provide better lesion textures in the tumor patients, which is promising to be used in clinical diagnosis.