 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BERT Fine-Tuning for Sentiment Analysis on Indonesian Mobile Apps Reviews
Jul 14, 2021



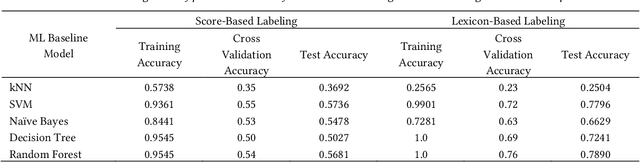
User reviews have an essential role in the success of the developed mobile apps. User reviews in the textual form are unstructured data, creating a very high complexity when processed for sentiment analysis. Previous approaches that have been used often ignore the context of reviews. In addition, the relatively small data makes the model overfitting. A new approach, BERT, has been introduced as a transfer learning model with a pre-trained model that has previously been trained to have a better context representation. This study examines the effectiveness of fine-tuning BERT for sentiment analysis using two different pre-trained models. Besides the multilingual pre-trained model, we use the pre-trained model that only has been trained in Indonesian. The dataset used is Indonesian user reviews of the ten best apps in 2020 in Google Play sites. We also perform hyper-parameter tuning to find the optimum trained model. Two training data labeling approaches were also tested to determine the effectiveness of the model, which is score-based and lexicon-based. The experimental results show that pre-trained models trained in Indonesian have better average accuracy on lexicon-based data. The pre-trained Indonesian model highest accuracy is 84%, with 25 epochs and a training time of 24 minutes. These results are better than all of the machine learning and multilingual pre-trained models.
Noise Detection with Spectator Qubits and Quantum Feature Engineering
Mar 24, 2021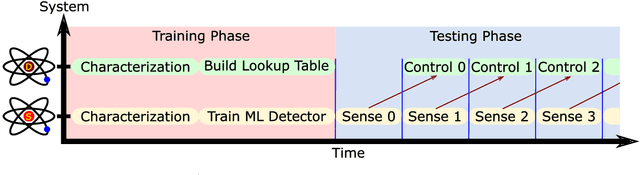
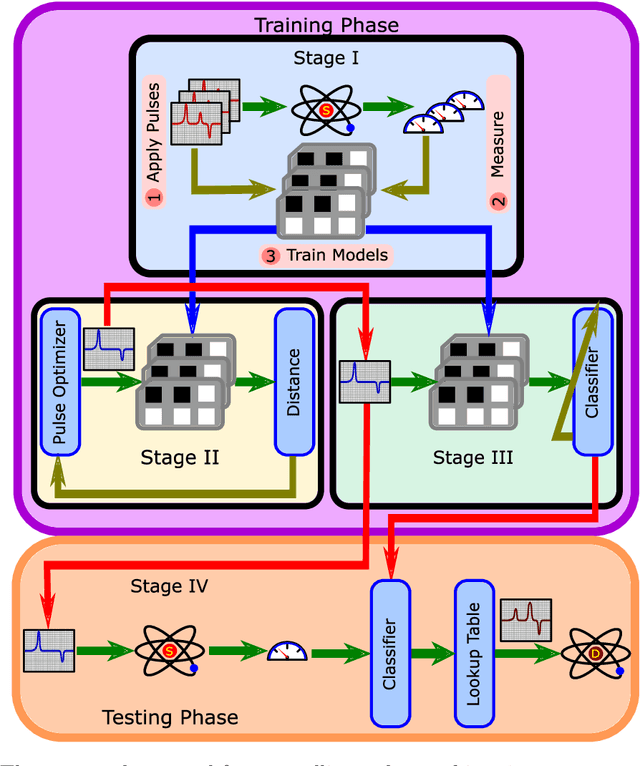
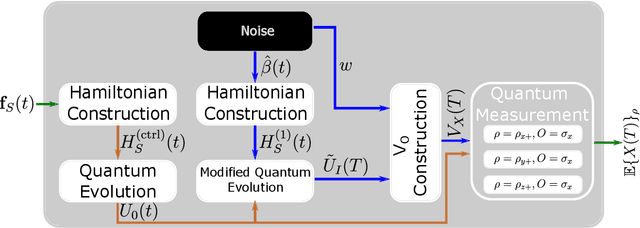
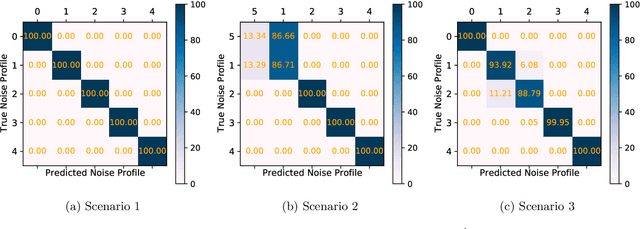
Designing optimal control pulses that drive a noisy qubit to a target state is a challenging and crucial task for quantum engineering. In a situation where the properties of the quantum noise affecting the system are dynamic, a periodic characterization procedure is essential to ensure the models are updated. As a result, the operation of the qubit is disrupted frequently. In this paper, we propose a protocol that addresses this challenge by making use of a spectator qubit to monitor the noise in real-time. We develop a quantum machine-learning-based quantum feature engineering approach for designing the protocol. The complexity of the protocol is front-loaded in a characterization phase, which allow real-time execution during the quantum computations. We present the results of numerical simulations that showcase the favorable performance of the protocol.
A Novel Non-population-based Meta-heuristic Optimizer Inspired by the Philosophy of Yi Jing
Apr 17, 2021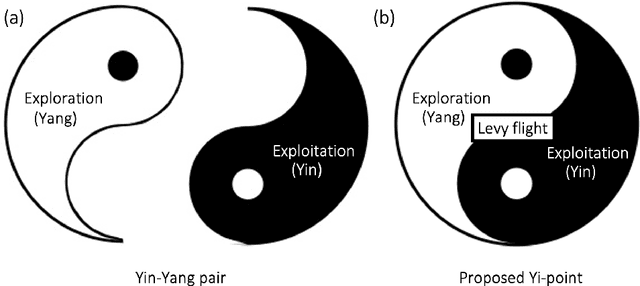
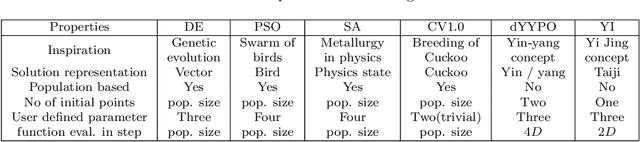
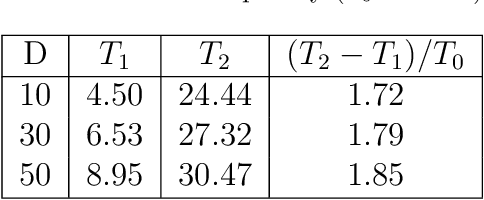
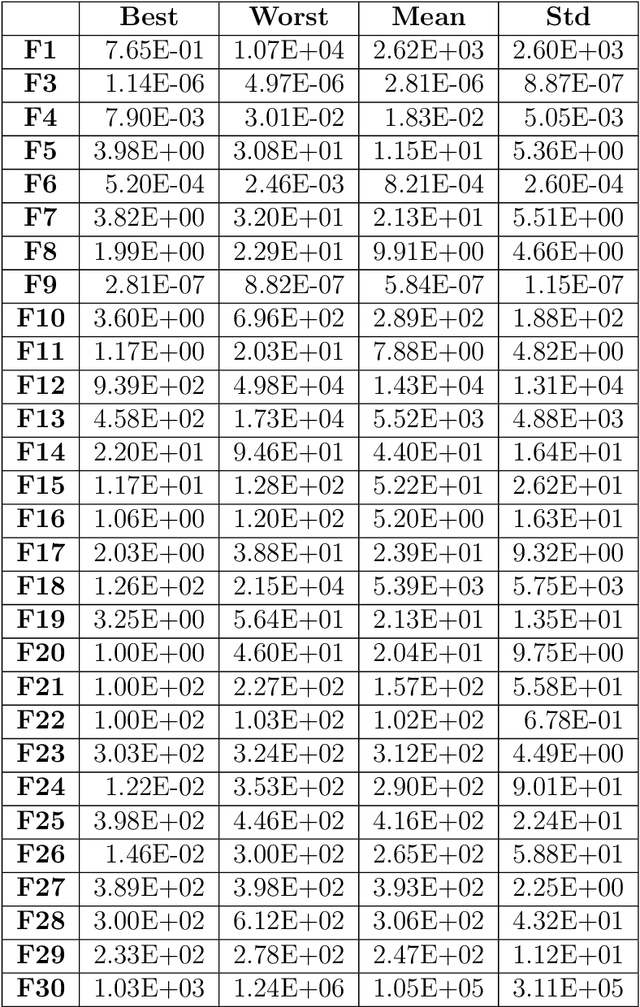
Drawing inspiration from the philosophy of Yi Jing, Yin-Yang pair optimization (YYPO) has been shown to achieve competitive performance in single objective optimizations. Besides, it has the advantage of low time complexity when comparing to other population-based optimization. As a conceptual extension of YYPO, we proposed the novel Yi optimization (YI) algorithm as one of the best non-population-based optimizer. Incorporating both the harmony and reversal concept of Yi Jing, we replace the Yin-Yang pair with a Yi-point, in which we utilize the Levy flight to update the solution and balance both the effort of the exploration and the exploitation in the optimization process. As a conceptual prototype, we examine YI with IEEE CEC 2017 benchmark and compare its performance with a Levy flight-based optimizer CV1.0, the state-of-the-art dynamical Yin-Yang pair optimization in YYPO family and a few classical optimizers. According to the experimental results, YI shows highly competitive performance while keeping the low time complexity. Hence, the results of this work have implications for enhancing meta-heuristic optimizer using the philosophy of Yi Jing, which deserves research attention.
H2Learn: High-Efficiency Learning Accelerator for High-Accuracy Spiking Neural Networks
Jul 25, 2021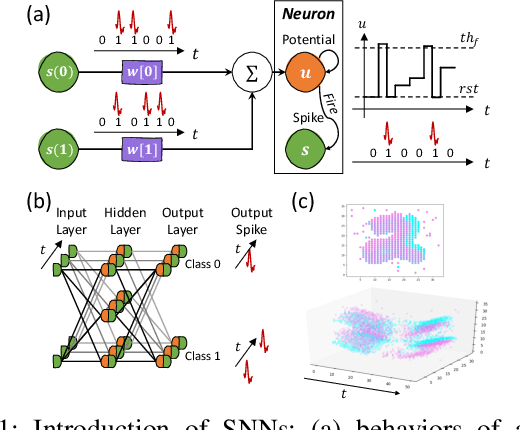
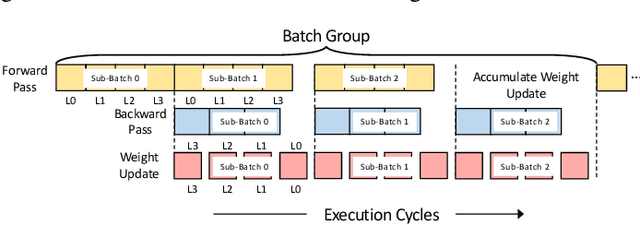
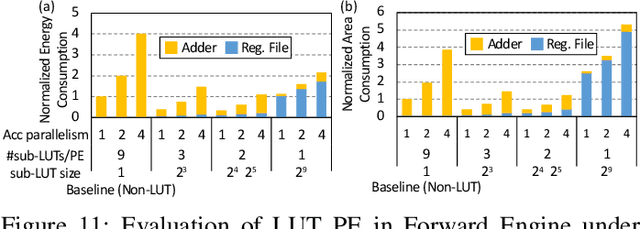
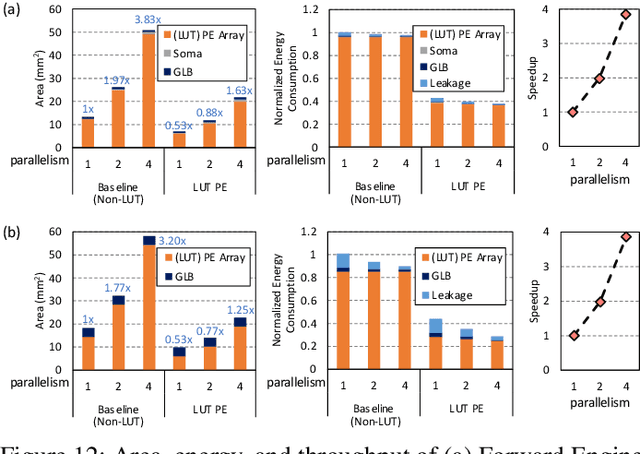
Although spiking neural networks (SNNs) take benefits from the bio-plausible neural modeling, the low accuracy under the common local synaptic plasticity learning rules limits their application in many practical tasks. Recently, an emerging SNN supervised learning algorithm inspired by backpropagation through time (BPTT) from the domain of artificial neural networks (ANNs) has successfully boosted the accuracy of SNNs and helped improve the practicability of SNNs. However, current general-purpose processors suffer from low efficiency when performing BPTT for SNNs due to the ANN-tailored optimization. On the other hand, current neuromorphic chips cannot support BPTT because they mainly adopt local synaptic plasticity rules for simplified implementation. In this work, we propose H2Learn, a novel architecture that can achieve high efficiency for BPTT-based SNN learning which ensures high accuracy of SNNs. At the beginning, we characterized the behaviors of BPTT-based SNN learning. Benefited from the binary spike-based computation in the forward pass and the weight update, we first design lookup table (LUT) based processing elements in Forward Engine and Weight Update Engine to make accumulations implicit and to fuse the computations of multiple input points. Second, benefited from the rich sparsity in the backward pass, we design a dual-sparsity-aware Backward Engine which exploits both input and output sparsity. Finally, we apply a pipeline optimization between different engines to build an end-to-end solution for the BPTT-based SNN learning. Compared with the modern NVIDIA V100 GPU, H2Learn achieves 7.38x area saving, 5.74-10.20x speedup, and 5.25-7.12x energy saving on several benchmark datasets.
Coalitional strategies for efficient individual prediction explanation
Apr 01, 2021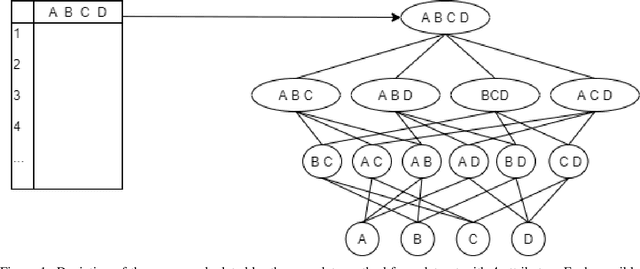
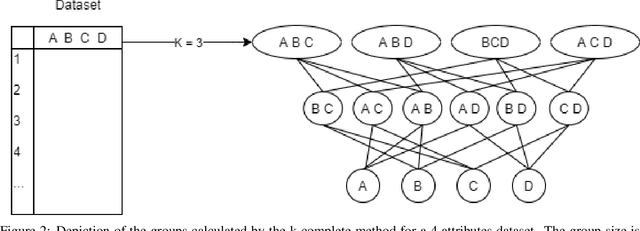
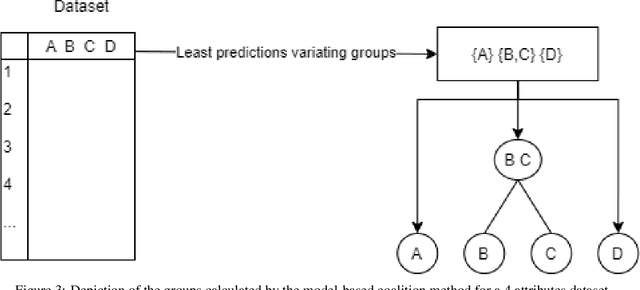
As Machine Learning (ML) is now widely applied in many domains, in both research and industry, an understanding of what is happening inside the black box is becoming a growing demand, especially by non-experts of these models. Several approaches had thus been developed to provide clear insights of a model prediction for a particular observation but at the cost of long computation time or restrictive hypothesis that does not fully take into account interaction between attributes. This paper provides methods based on the detection of relevant groups of attributes -- named coalitions -- influencing a prediction and compares them with the literature. Our results show that these coalitional methods are more efficient than existing ones such as SHapley Additive exPlanation (SHAP). Computation time is shortened while preserving an acceptable accuracy of individual prediction explanations. Therefore, this enables wider practical use of explanation methods to increase trust between developed ML models, end-users, and whoever impacted by any decision where these models played a role.
MDE4QAI: Towards Model-Driven Engineering for Quantum Artificial Intelligence
Jul 14, 2021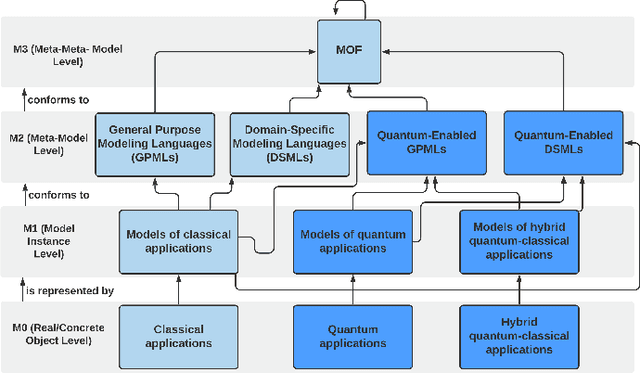
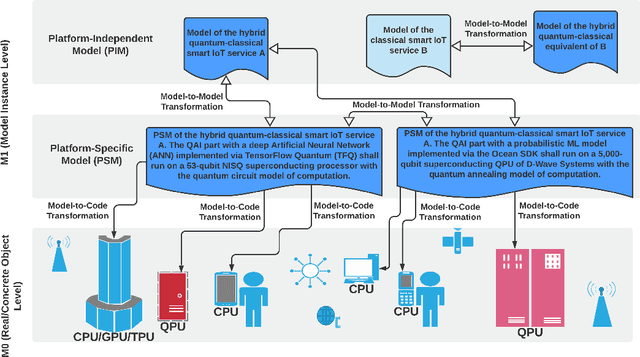
Over the past decade, Artificial Intelligence (AI) has provided enormous new possibilities and opportunities, but also new demands and requirements for software systems. In particular, Machine Learning (ML) has proven useful in almost every vertical application domain. Although other sub-disciplines of AI, such as intelligent agents and Multi-Agent Systems (MAS) did not become promoted to the same extent, they still possess the potential to be integrated into the mainstream technology stacks and ecosystems, for example, due to the ongoing prevalence of the Internet of Things (IoT) and smart Cyber-Physical Systems (CPS). However, in the decade ahead, an unprecedented paradigm shift from classical computing towards Quantum Computing (QC) is expected, with perhaps a quantum-classical hybrid model. We expect the Model-Driven Engineering (MDE) paradigm to be an enabler and a facilitator, when it comes to the quantum and the quantum-classical hybrid applications as it has already proven beneficial in the highly complex domains of IoT, smart CPS and AI with inherently heterogeneous hardware and software platforms, and APIs. This includes not only automated code generation, but also automated model checking and verification, as well as model analysis in the early design phases, and model-to-model transformations both at the design-time and at the runtime. In this paper, the vision is focused on MDE for Quantum AI, and a holistic approach integrating all of the above.
A Roadmap-Path Reshaping Algorithm for Real-Time Motion Planning
Feb 28, 2019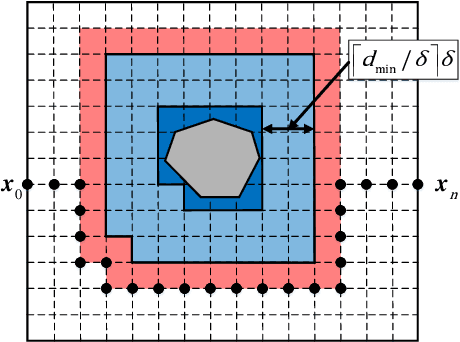
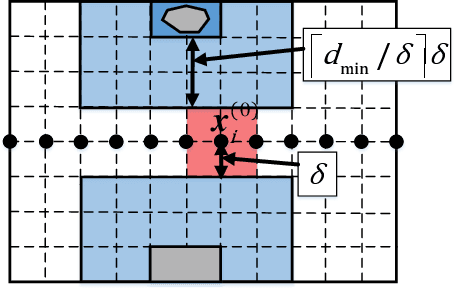
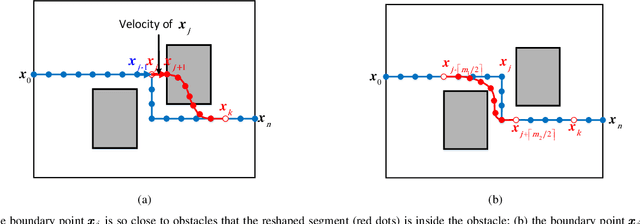
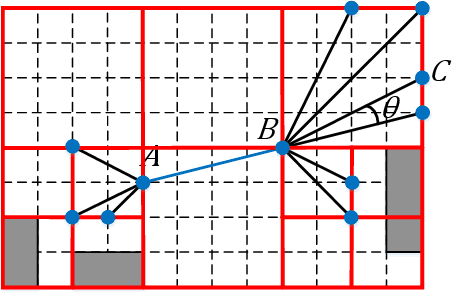
Real-time motion planning is a vital function of robotic systems. Different from existing roadmap algorithms which first determine the free space and then determine the collision-free path, researchers recently proposed several convex relaxation based smoothing algorithms which first select an initial path to link the starting configuration and the goal configuration and then reshape this path to meet other requirements (e.g., collision-free conditions) by using convex relaxation. However, convex relaxation based smoothing algorithms often fail to give a satisfactory path, since the initial paths are selected randomly. Moreover, the curvature constraints were not considered in the existing convex relaxation based smoothing algorithms. In this paper, we show that we can first grid the whole configuration space to pick a candidate path and reshape this shortest path to meet our goal. This new algorithm inherits the merits of the roadmap algorithms and the convex feasible set algorithm. We further discuss how to meet the curvature constraints by using both the Beamlet algorithm to select a better initial path and an iterative optimization algorithm to adjust the curvature of the path. Theoretical analyzing and numerical testing results show that it can almost surely find a feasible path and use much less time than the recently proposed convex feasible set algorithm.
Efficient Conformer with Prob-Sparse Attention Mechanism for End-to-EndSpeech Recognition
Jun 17, 2021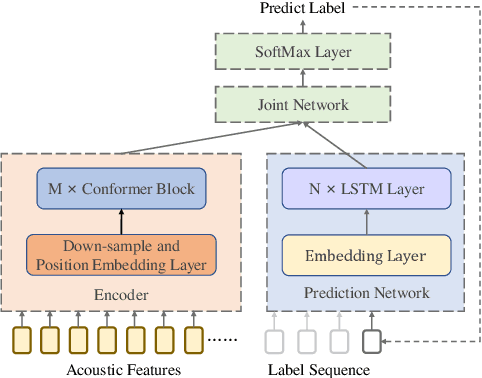
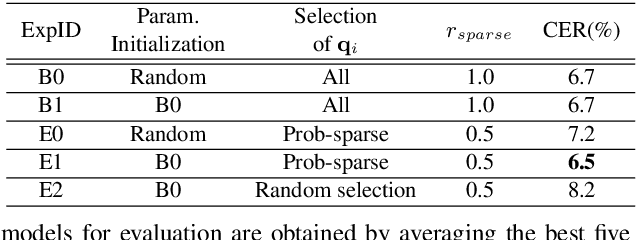
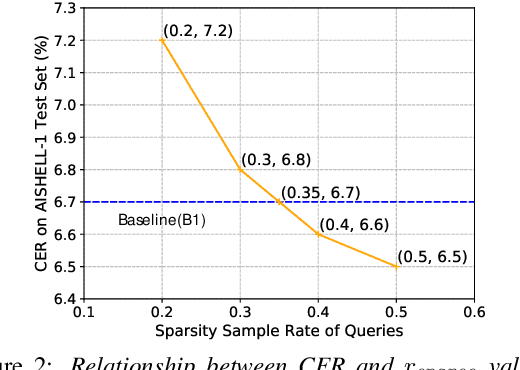
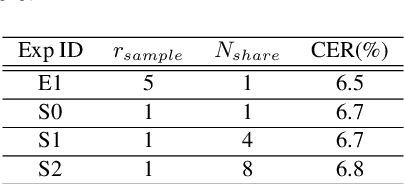
End-to-end models are favored in automatic speech recognition (ASR) because of their simplified system structure and superior performance. Among these models, Transformer and Conformer have achieved state-of-the-art recognition accuracy in which self-attention plays a vital role in capturing important global information. However, the time and memory complexity of self-attention increases squarely with the length of the sentence. In this paper, a prob-sparse self-attention mechanism is introduced into Conformer to sparse the computing process of self-attention in order to accelerate inference speed and reduce space consumption. Specifically, we adopt a Kullback-Leibler divergence based sparsity measurement for each query to decide whether we compute the attention function on this query. By using the prob-sparse attention mechanism, we achieve impressively 8% to 45% inference speed-up and 15% to 45% memory usage reduction of the self-attention module of Conformer Transducer while maintaining the same level of error rate.
Medical Concept Embedding with Time-Aware Attention
Jun 06, 2018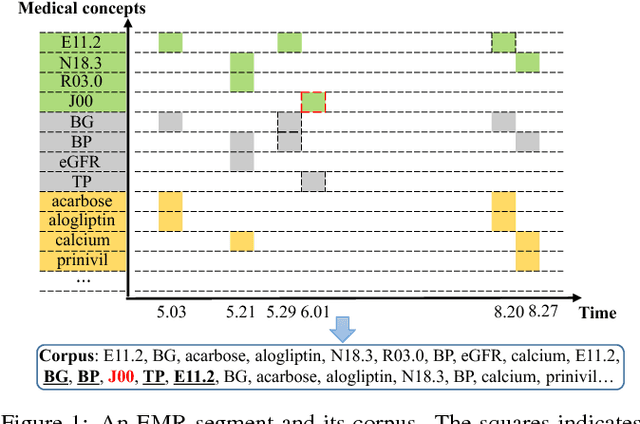


Embeddings of medical concepts such as medication, procedure and diagnosis codes in Electronic Medical Records (EMRs) are central to healthcare analytics. Previous work on medical concept embedding takes medical concepts and EMRs as words and documents respectively. Nevertheless, such models miss out the temporal nature of EMR data. On the one hand, two consecutive medical concepts do not indicate they are temporally close, but the correlations between them can be revealed by the time gap. On the other hand, the temporal scopes of medical concepts often vary greatly (e.g., \textit{common cold} and \textit{diabetes}). In this paper, we propose to incorporate the temporal information to embed medical codes. Based on the Continuous Bag-of-Words model, we employ the attention mechanism to learn a "soft" time-aware context window for each medical concept. Experiments on public and proprietary datasets through clustering and nearest neighbour search tasks demonstrate the effectiveness of our model, showing that it outperforms five state-of-the-art baselines.
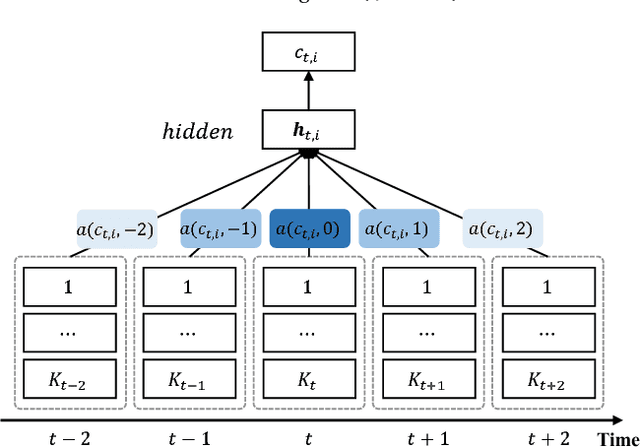
Co-evolutionary multi-task learning for dynamic time series prediction
Jun 13, 2018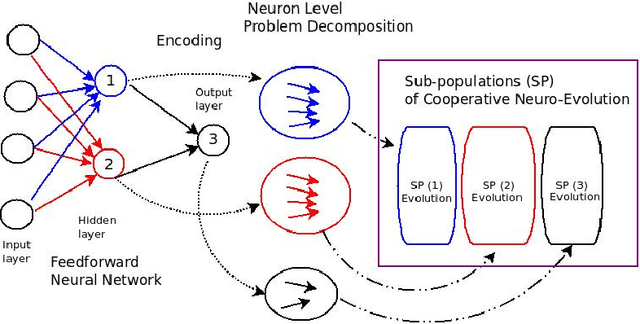
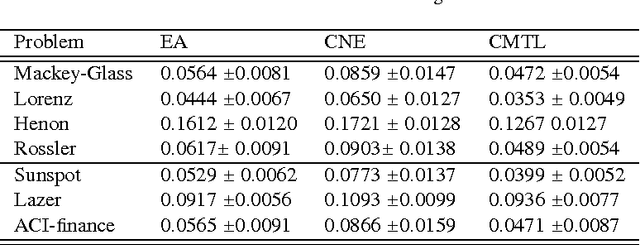
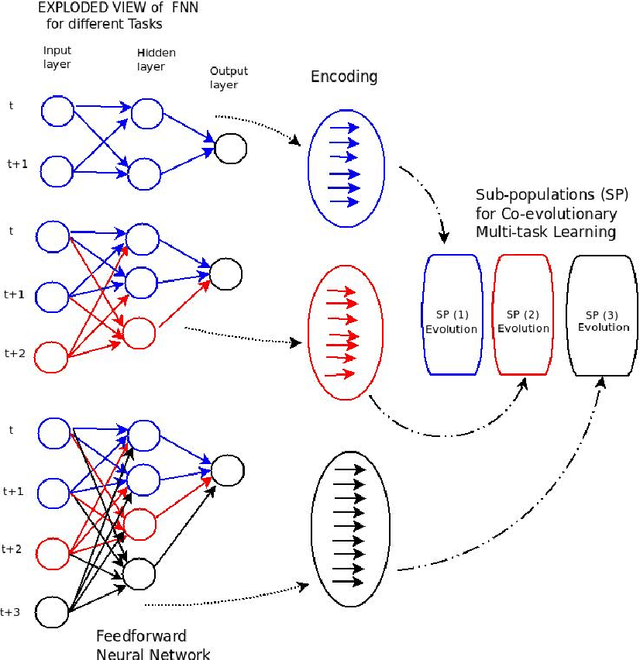
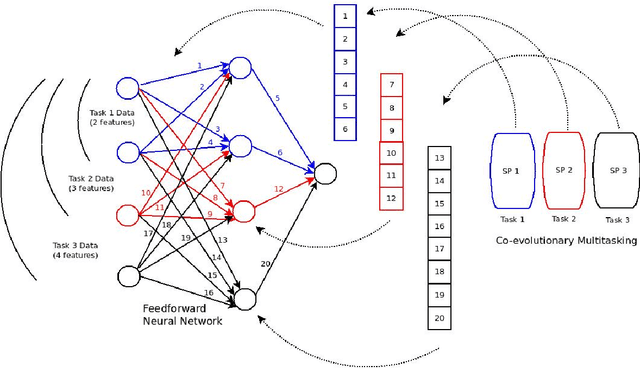
Time series prediction typically consists of a data reconstruction phase where the time series is broken into overlapping windows known as the timespan. The size of the timespan can be seen as a way of determining the extent of past information required for an effective prediction. In certain applications such as the prediction of wind-intensity of storms and cyclones, prediction models need to be dynamic in accommodating different values of the timespan. These applications require robust prediction as soon as the event takes place. We identify a new category of problem called dynamic time series prediction that requires a model to give prediction when presented with varying lengths of the timespan. In this paper, we propose a co-evolutionary multi-task learning method that provides a synergy between multi-task learning and co-evolutionary algorithms to address dynamic time series prediction. The method features effective use of building blocks of knowledge inspired by dynamic programming and multi-task learning. It enables neural networks to retain modularity during training for making a decision in situations even when certain inputs are missing. The effectiveness of the method is demonstrated using one-step-ahead chaotic time series and tropical cyclone wind-intensity prediction.