 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sample Efficient Social Navigation Using Inverse Reinforcement Learning
Jun 18, 2021

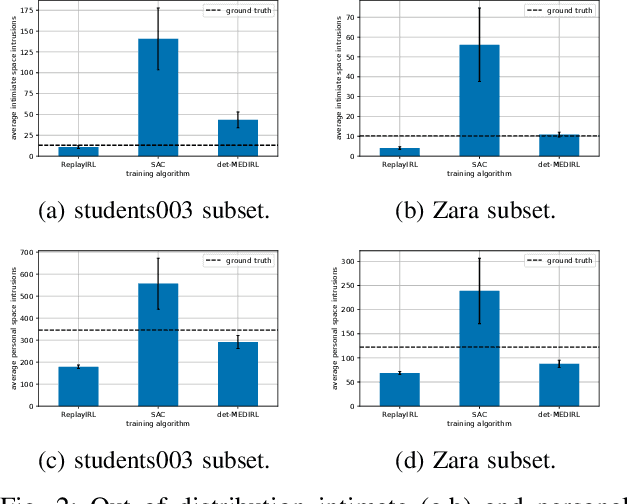
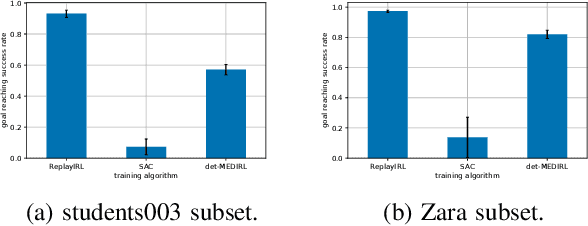
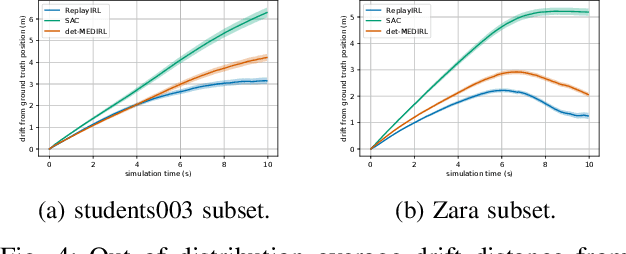
In this paper, we present an algorithm to efficiently learn socially-compliant navigation policies from observations of human trajectories. As mobile robots come to inhabit and traffic social spaces, they must account for social cues and behave in a socially compliant manner. We focus on learning such cues from examples. We describe an inverse reinforcement learning based algorithm which learns from human trajectory observations without knowing their specific actions. We increase the sample-efficiency of our approach over alternative methods by leveraging the notion of a replay buffer (found in many off-policy reinforcement learning methods) to eliminate the additional sample complexity associated with inverse reinforcement learning. We evaluate our method by training agents using publicly available pedestrian motion data sets and compare it to related methods. We show that our approach yields better performance while also decreasing training time and sample complexity.
Going Deeper into Semi-supervised Person Re-identification
Jul 24, 2021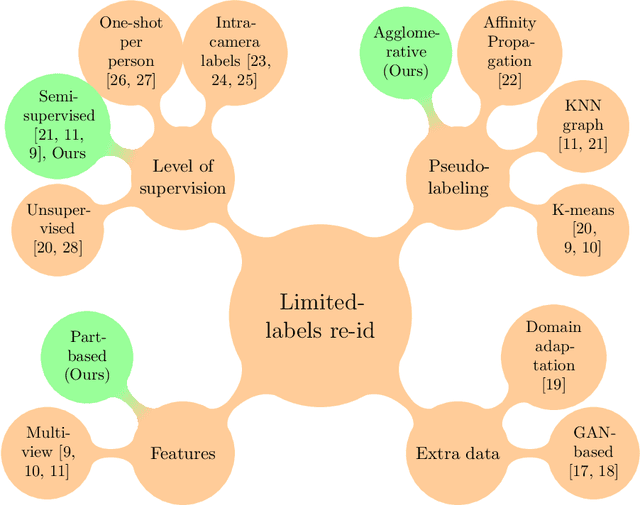
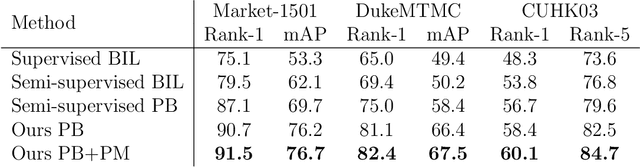
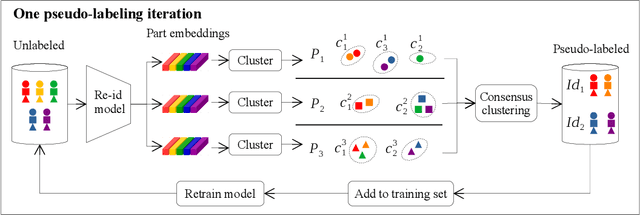

Person re-identification is the challenging task of identifying a person across different camera views. Training a convolutional neural network (CNN) for this task requires annotating a large dataset, and hence, it involves the time-consuming manual matching of people across cameras. To reduce the need for labeled data, we focus on a semi-supervised approach that requires only a subset of the training data to be labeled. We conduct a comprehensive survey in the area of person re-identification with limited labels. Existing works in this realm are limited in the sense that they utilize features from multiple CNNs and require the number of identities in the unlabeled data to be known. To overcome these limitations, we propose to employ part-based features from a single CNN without requiring the knowledge of the label space (i.e., the number of identities). This makes our approach more suitable for practical scenarios, and it significantly reduces the need for computational resources. We also propose a PartMixUp loss that improves the discriminative ability of learned part-based features for pseudo-labeling in semi-supervised settings. Our method outperforms the state-of-the-art results on three large-scale person re-id datasets and achieves the same level of performance as fully supervised methods with only one-third of labeled identities.
Sync-Switch: Hybrid Parameter Synchronization for Distributed Deep Learning
Apr 20, 2021Stochastic Gradient Descent (SGD) has become the de facto way to train deep neural networks in distributed clusters. A critical factor in determining the training throughput and model accuracy is the choice of the parameter synchronization protocol. For example, while Bulk Synchronous Parallel (BSP) often achieves better converged accuracy, the corresponding training throughput can be negatively impacted by stragglers. In contrast, Asynchronous Parallel (ASP) can have higher throughput, but its convergence and accuracy can be impacted by stale gradients. To improve the performance of synchronization protocol, recent work often focuses on designing new protocols with a heavy reliance on hard-to-tune hyper-parameters. In this paper, we design a hybrid synchronization approach that exploits the benefits of both BSP and ASP, i.e., reducing training time while simultaneously maintaining the converged accuracy. Based on extensive empirical profiling, we devise a collection of adaptive policies that determine how and when to switch between synchronization protocols. Our policies include both offline ones that target recurring jobs and online ones for handling transient stragglers. We implement the proposed policies in a prototype system, called Sync-Switch, on top of TensorFlow, and evaluate the training performance with popular deep learning models and datasets. Our experiments show that Sync-Switch achieves up to 5.13X throughput speedup and similar converged accuracy when comparing to BSP. Further, we observe that Sync-Switch achieves 3.8% higher converged accuracy with just 1.23X the training time compared to training with ASP. Moreover, Sync-Switch can be used in settings when training with ASP leads to divergence errors. Sync-Switch achieves all of these benefits with very low overhead, e.g., the framework overhead can be as low as 1.7% of the total training time.
Autoencoder based Randomized Learning of Feedforward Neural Networks for Regression
Jul 04, 2021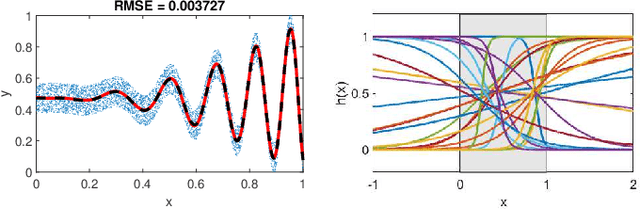
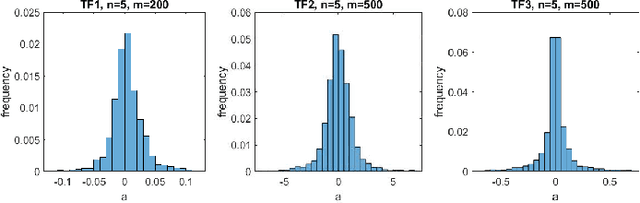
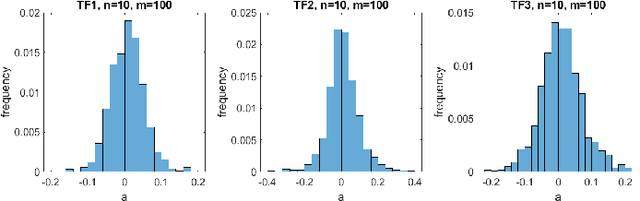
Feedforward neural networks are widely used as universal predictive models to fit data distribution. Common gradient-based learning, however, suffers from many drawbacks making the training process ineffective and time-consuming. Alternative randomized learning does not use gradients but selects hidden node parameters randomly. This makes the training process extremely fast. However, the problem in randomized learning is how to determine the random parameters. A recently proposed method uses autoencoders for unsupervised parameter learning. This method showed superior performance on classification tasks. In this work, we apply this method to regression problems, and, finding that it has some drawbacks, we show how to improve it. We propose a learning method of autoencoders that controls the produced random weights. We also propose how to determine the biases of hidden nodes. We empirically compare autoencoder based learning with other randomized learning methods proposed recently for regression and find that despite the proposed improvement of the autoencoder based learning, it does not outperform its competitors in fitting accuracy. Moreover, the method is much more complex than its competitors.
Predicting traffic signals on transportation networks using spatio-temporal correlations on graphs
Apr 27, 2021
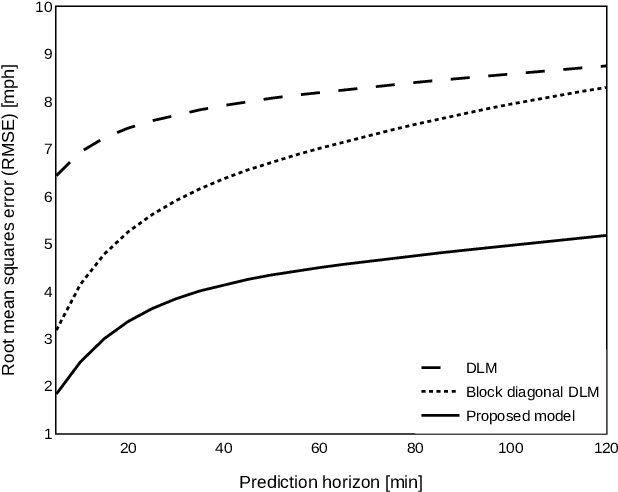
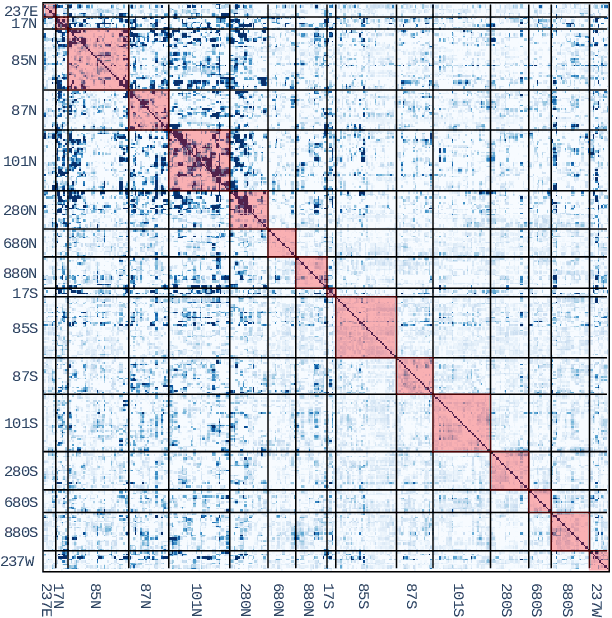
Forecasting multivariate time series is challenging as the variables are intertwined in time and space, like in the case of traffic signals. Defining signals on graphs relaxes such complexities by representing the evolution of signals over a space using relevant graph kernels such as the heat diffusion kernel. However, this kernel alone does not fully capture the actual dynamics of the data as it only relies on the graph structure. The gap can be filled by combining the graph kernel representation with data-driven models that utilize historical data. This paper proposes a traffic propagation model that merges multiple heat diffusion kernels into a data-driven prediction model to forecast traffic signals. We optimize the model parameters using Bayesian inference to minimize the prediction errors and, consequently, determine the mixing ratio of the two approaches. Such mixing ratio strongly depends on training data size and data anomalies, which typically correspond to the peak hours for traffic data. The proposed model demonstrates prediction accuracy comparable to that of the state-of-the-art deep neural networks with lower computational effort. It particularly shows excellent performance for long-term prediction since it inherits the data-driven models' periodicity modeling.
SpikE: spike-based embeddings for multi-relational graph data
Apr 27, 2021
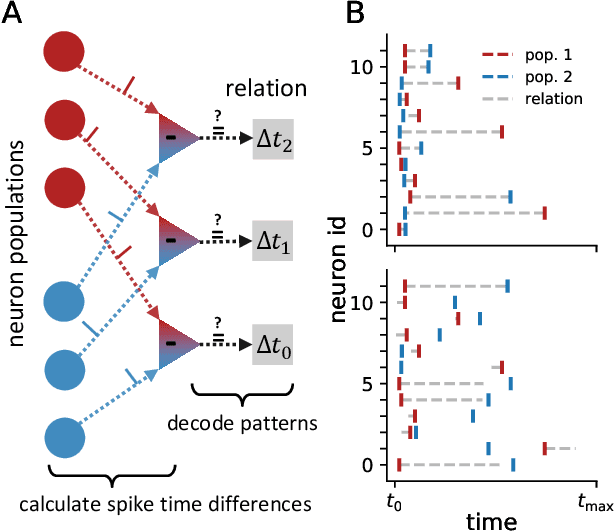
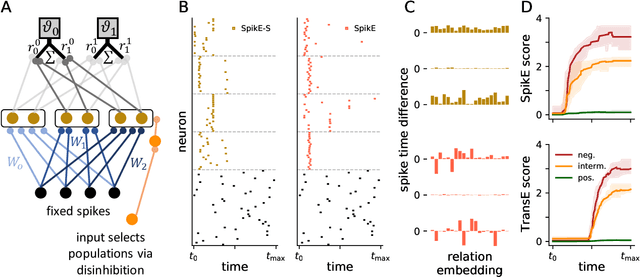
Despite the recent success of reconciling spike-based coding with the error backpropagation algorithm, spiking neural networks are still mostly applied to tasks stemming from sensory processing, operating on traditional data structures like visual or auditory data. A rich data representation that finds wide application in industry and research is the so-called knowledge graph - a graph-based structure where entities are depicted as nodes and relations between them as edges. Complex systems like molecules, social networks and industrial factory systems can be described using the common language of knowledge graphs, allowing the usage of graph embedding algorithms to make context-aware predictions in these information-packed environments. We propose a spike-based algorithm where nodes in a graph are represented by single spike times of neuron populations and relations as spike time differences between populations. Learning such spike-based embeddings only requires knowledge about spike times and spike time differences, compatible with recently proposed frameworks for training spiking neural networks. The presented model is easily mapped to current neuromorphic hardware systems and thereby moves inference on knowledge graphs into a domain where these architectures thrive, unlocking a promising industrial application area for this technology.
A Hybrid Decomposition-based Multi-objective Evolutionary Algorithm for the Multi-Point Dynamic Aggregation Problem
May 11, 2021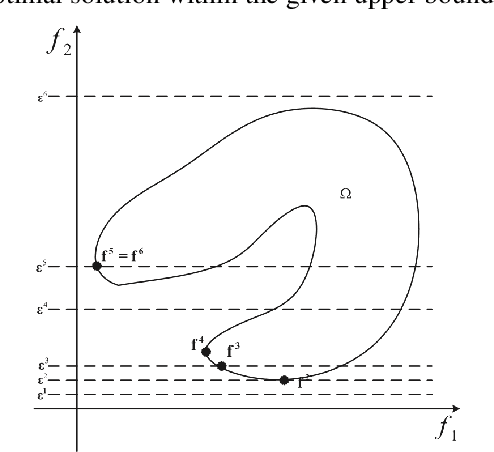
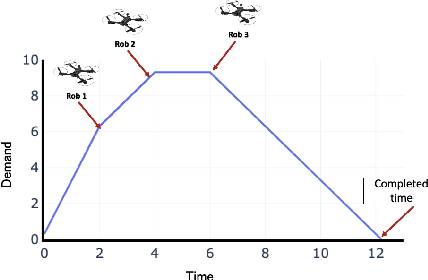


An emerging optimisation problem from the real-world applications, named the multi-point dynamic aggregation (MPDA) problem, has become one of the active research topics of the multi-robot system. This paper focuses on a multi-objective MPDA problem which is to design an execution plan of the robots to minimise the number of robots and the maximal completion time of all the tasks. The strongly-coupled relationships among robots and tasks, the redundancy of the MPDA encoding, and the variable-size decision space of the MO-MPDA problem posed extra challenges for addressing the problem effectively. To address the above issues, we develop a hybrid decomposition-based multi-objective evolutionary algorithm (HDMOEA) using $ \varepsilon $-constraint method. It selects the maximal completion time of all tasks as the main objective, and converted the other objective into constraints. HDMOEA decomposes a MO-MPDA problem into a series of scalar constrained optimization subproblems by assigning each subproblem with an upper bound robot number. All the subproblems are optimized simultaneously with the transferring knowledge from other subproblems. Besides, we develop a hybrid population initialisation mechanism to enhance the quality of initial solutions, and a reproduction mechanism to transmit effective information and tackle the encoding redundancy. Experimental results show that the proposed HDMOEA method significantly outperforms the state-of-the-art methods in terms of several most-used metrics.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021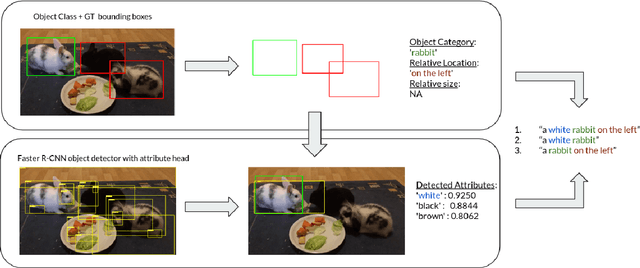



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
Probabilistic and Geometric Depth: Detecting Objects in Perspective
Jul 29, 2021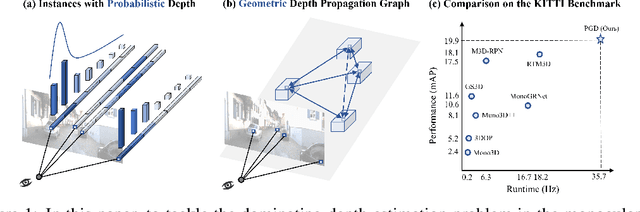
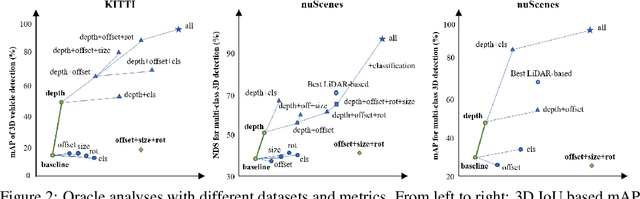
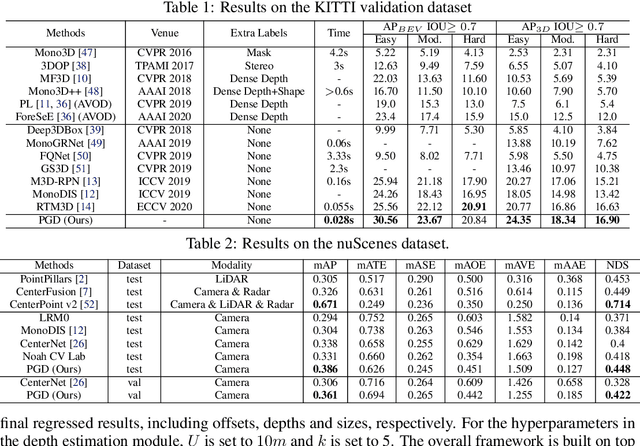
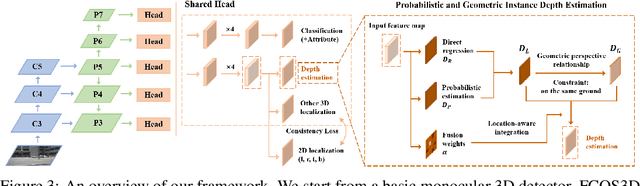
3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as an economical solution compared to conventional settings relying on binocular vision or LiDAR, has drawn increasing attention recently but still yields unsatisfactory results. This paper first presents a systematic study on this problem and observes that the current monocular 3D detection problem can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. However, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects, which can be valuable constraints as the key information about depth is not directly manifest in the monocular image. Therefore, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method obtains significant improvements on KITTI and nuScenes benchmarks, achieving the 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at https://github.com/open-mmlab/mmdetection3d.
ProfileSR-GAN: A GAN based Super-Resolution Method for Generating High-Resolution Load Profiles
Jul 18, 2021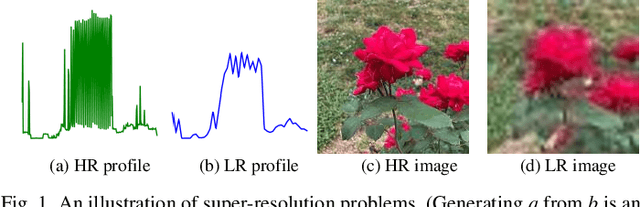
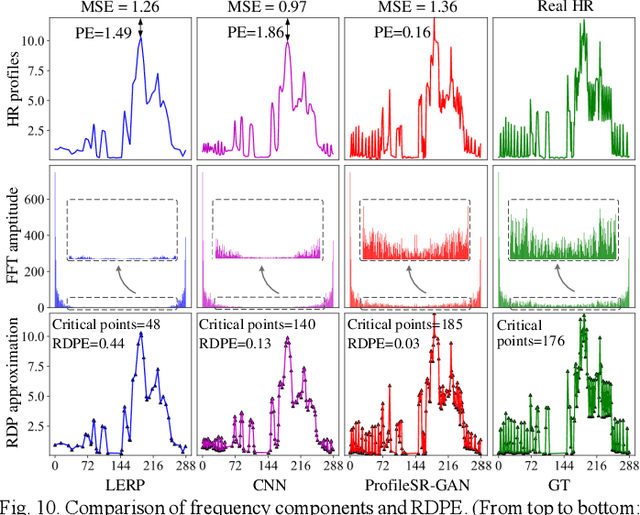
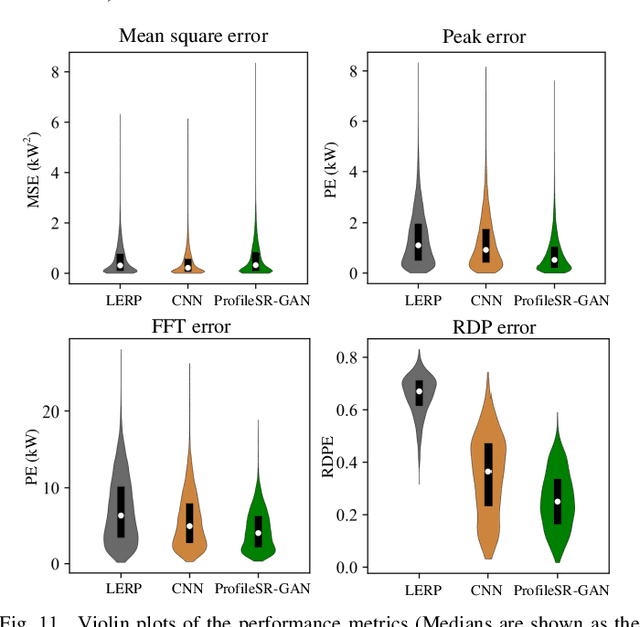
It is a common practice for utilities to down-sample smart meter measurements from high resolution (e.g. 1-min or 1-sec) to low resolution (e.g. 15-, 30- or 60-min) to lower the data transmission and storage cost. However, down-sampling can remove high-frequency components from time-series load profiles, making them unsuitable for in-depth studies such as quasi-static power flow analysis or non-intrusive load monitoring (NILM). Thus, in this paper, we propose ProfileSR-GAN: a Generative Adversarial Network (GAN) based load profile super-resolution (LPSR) framework for restoring high-frequency components lost through the smoothing effect of the down-sampling process. The LPSR problem is formulated as a Maximum-a-Prior problem. When training the ProfileSR-GAN generator network, to make the generated profiles more realistic, we introduce two new shape-related losses in addition to conventionally used content loss: adversarial loss and feature-matching loss. Moreover, a new set of shape-based evaluation metrics are proposed to evaluate the realisticness of the generated profiles. Simulation results show that ProfileSR-GAN outperforms Mean-Square Loss based methods in all shape-based metrics. The successful application in NILM further demonstrates that ProfileSR-GAN is effective in recovering high-resolution realistic waveforms.