 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The application of predictive analytics to identify at-risk students in health professions education
Aug 05, 2021
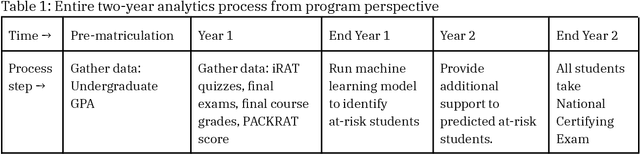
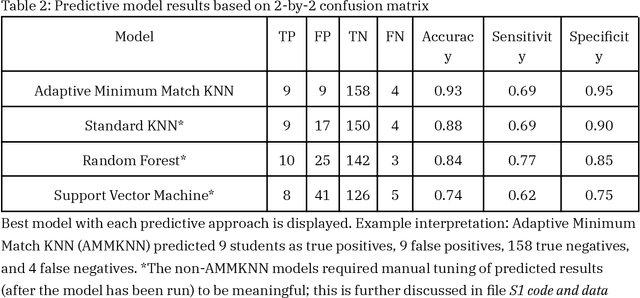
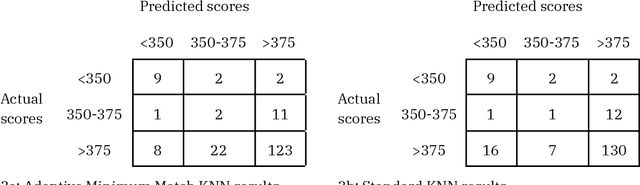
Introduction: When a learner fails to reach a milestone, educators often wonder if there had been any warning signs that could have allowed them to intervene sooner. Machine learning is used to predict which students are at risk of failing a national certifying exam. Predictions are made well in advance of the exam, such that educators can meaningfully intervene before students take the exam. Methods: Using already-collected, first-year student assessment data from four cohorts in a Master of Physician Assistant Studies program, the authors implement an "adaptive minimum match" version of the k-nearest neighbors algorithm (AMMKNN), using changing numbers of neighbors to predict each student's future exam scores on the Physician Assistant National Certifying Examination (PANCE). Leave-one-out cross validation (LOOCV) was used to evaluate the practical capabilities of this model, before making predictions for new students. Results: The best predictive model has an accuracy of 93%, sensitivity of 69%, and specificity of 94%. It generates a predicted PANCE score for each student, one year before they are scheduled to take the exam. Students can then be prospectively categorized into groups that need extra support, optional extra support, or no extra support. The educator then has one year to provide the appropriate customized support to each type of student. Conclusions: Predictive analytics can help health professions educators allocate scarce time and resources across their students. Interprofessional educators can use the included methods and code to generate predicted test outcomes for students. The authors recommend that educators using this or similar predictive methods act responsibly and transparently.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021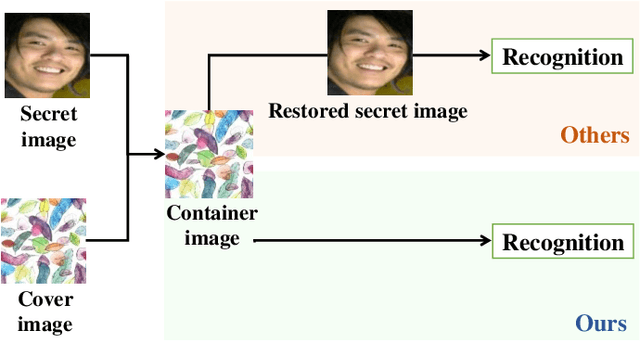

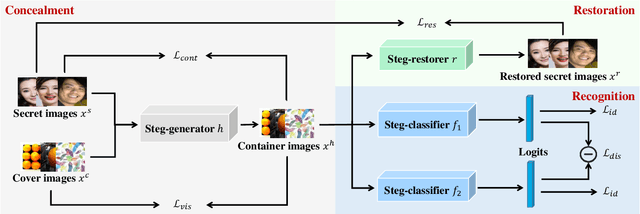
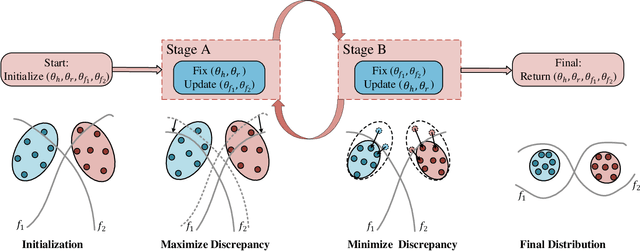
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
Emotions in Macroeconomic News and their Impact on the European Bond Market
Jun 15, 2021
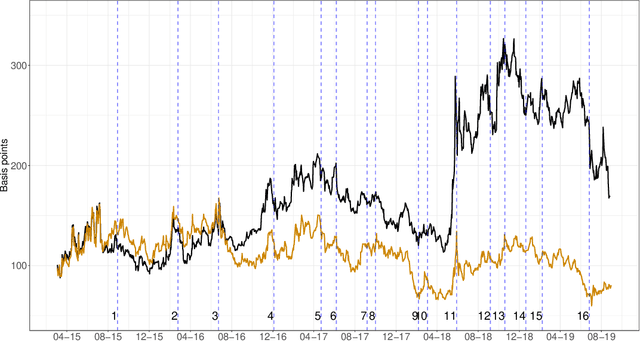
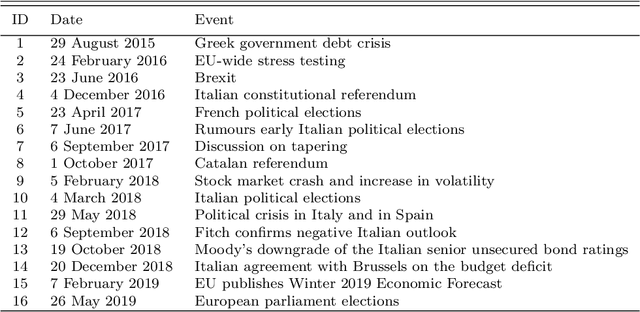
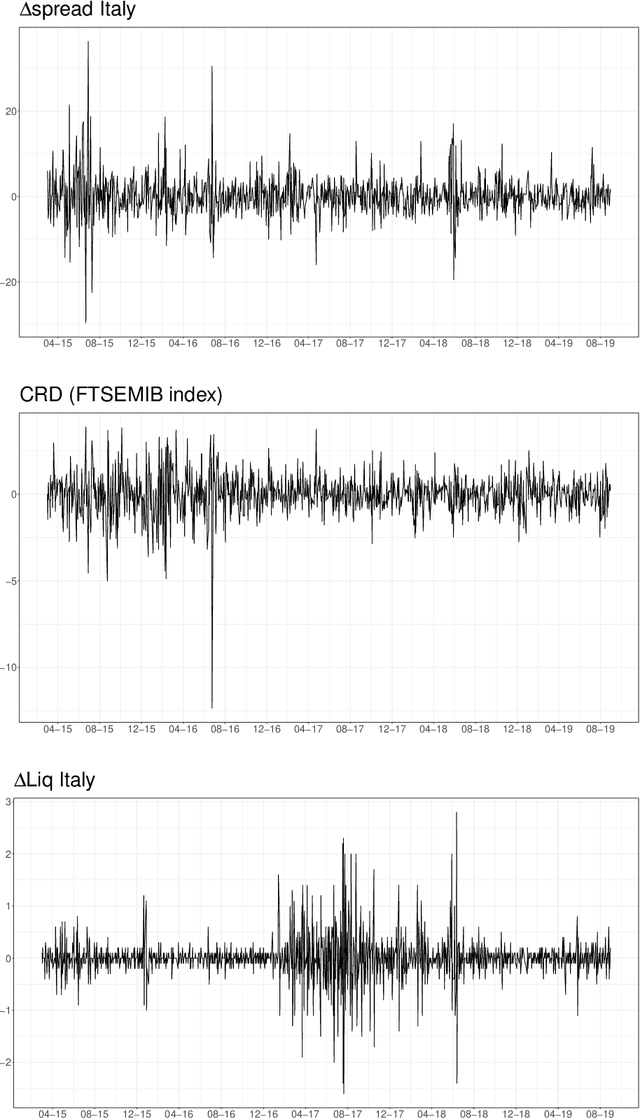
We show how emotions extracted from macroeconomic news can be used to explain and forecast future behaviour of sovereign bond yield spreads in Italy and Spain. We use a big, open-source, database known as Global Database of Events, Language and Tone to construct emotion indicators of bond market affective states. We find that negative emotions extracted from news improve the forecasting power of government yield spread models during distressed periods even after controlling for the number of negative words present in the text. In addition, stronger negative emotions, such as panic, reveal useful information for predicting changes in spread at the short-term horizon, while milder emotions, such as distress, are useful at longer time horizons. Emotions generated by the Italian political turmoil propagate to the Spanish news affecting this neighbourhood market.
Ab Initio Particle-based Object Manipulation
Jul 19, 2021
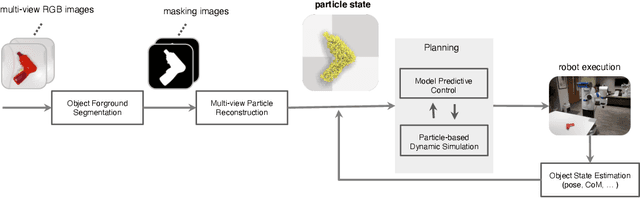

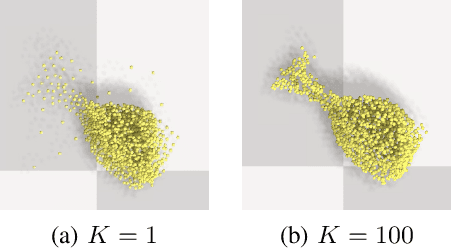
This paper presents Particle-based Object Manipulation (Prompt), a new approach to robot manipulation of novel objects ab initio, without prior object models or pre-training on a large object data set. The key element of Prompt is a particle-based object representation, in which each particle represents a point in the object, the local geometric, physical, and other features of the point, and also its relation with other particles. Like the model-based analytic approaches to manipulation, the particle representation enables the robot to reason about the object's geometry and dynamics in order to choose suitable manipulation actions. Like the data-driven approaches, the particle representation is learned online in real-time from visual sensor input, specifically, multi-view RGB images. The particle representation thus connects visual perception with robot control. Prompt combines the benefits of both model-based reasoning and data-driven learning. We show empirically that Prompt successfully handles a variety of everyday objects, some of which are transparent. It handles various manipulation tasks, including grasping, pushing, etc,. Our experiments also show that Prompt outperforms a state-of-the-art data-driven grasping method on the daily objects, even though it does not use any offline training data.
A Multi-UAV System for Exploration and Target Finding in Cluttered and GPS-Denied Environments
Jul 19, 2021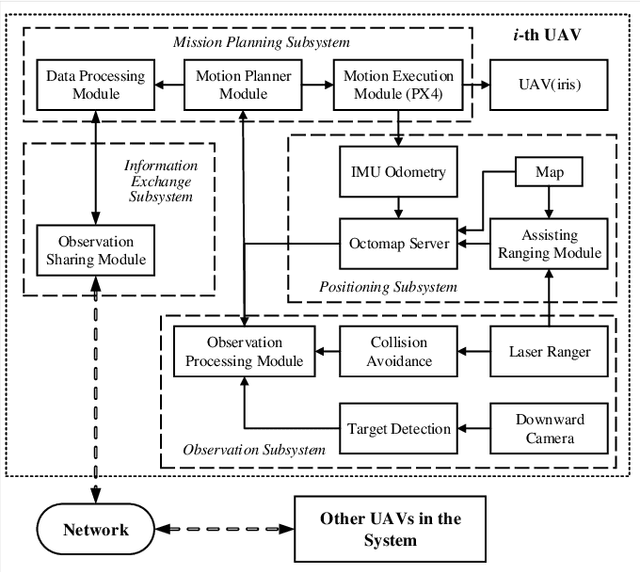
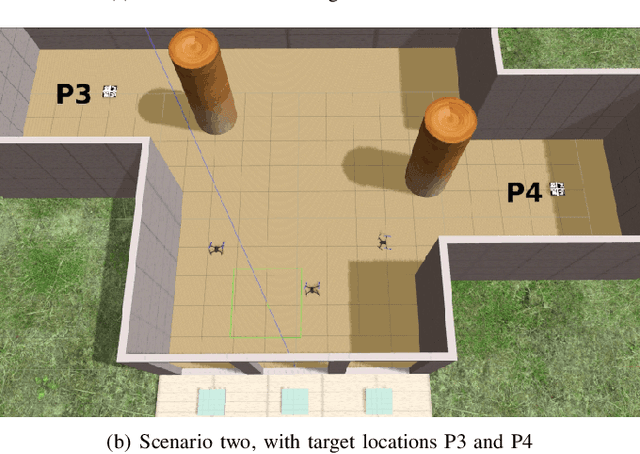
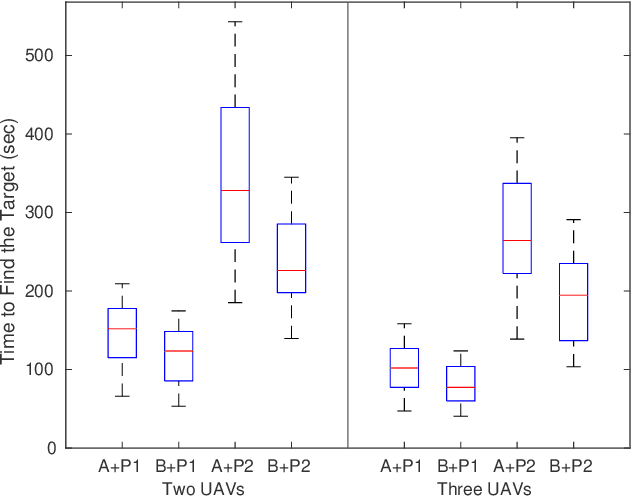
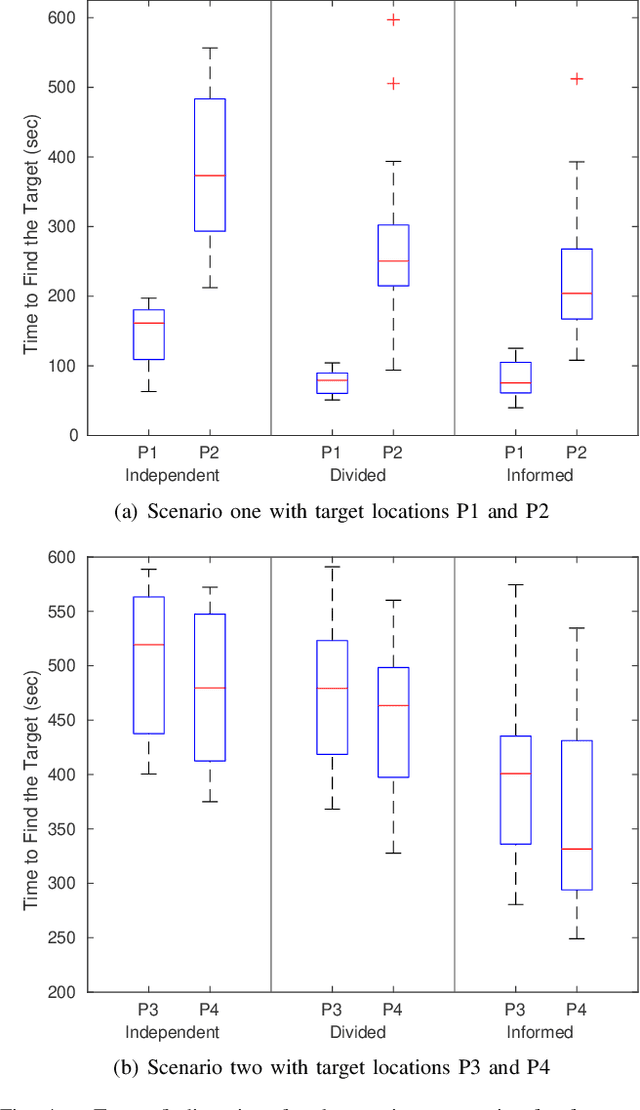
The use of multi-rotor Unmanned Aerial Vehicles (UAVs) for search and rescue as well as remote sensing is rapidly increasing. Multi-rotor UAVs, however, have limited endurance. The range of UAV applications can be widened if teams of multiple UAVs are used. We propose a framework for a team of UAVs to cooperatively explore and find a target in complex GPS-denied environments with obstacles. The team of UAVs autonomously navigates, explores, detects, and finds the target in a cluttered environment with a known map. Examples of such environments include indoor scenarios, urban or natural canyons, caves, and tunnels, where the GPS signal is limited or blocked. The framework is based on a probabilistic decentralised Partially Observable Markov Decision Process which accounts for the uncertainties in sensing and the environment. The team can cooperate efficiently, with each UAV sharing only limited processed observations and their locations during the mission. The system is simulated using the Robotic Operating System and Gazebo. Performance of the system with an increasing number of UAVs in several indoor scenarios with obstacles is tested. Results indicate that the proposed multi-UAV system has improvements in terms of time-cost, the proportion of search area surveyed, as well as successful rates for search and rescue missions.
Explainable Machine Learning for Fraud Detection
May 13, 2021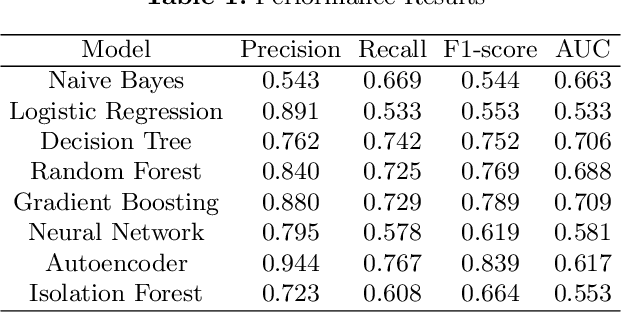
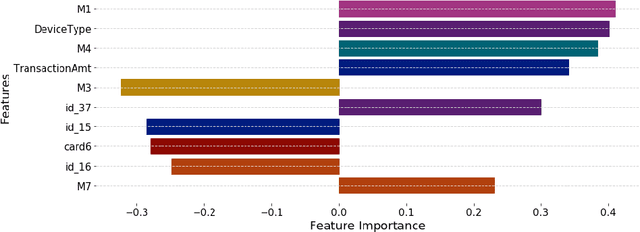
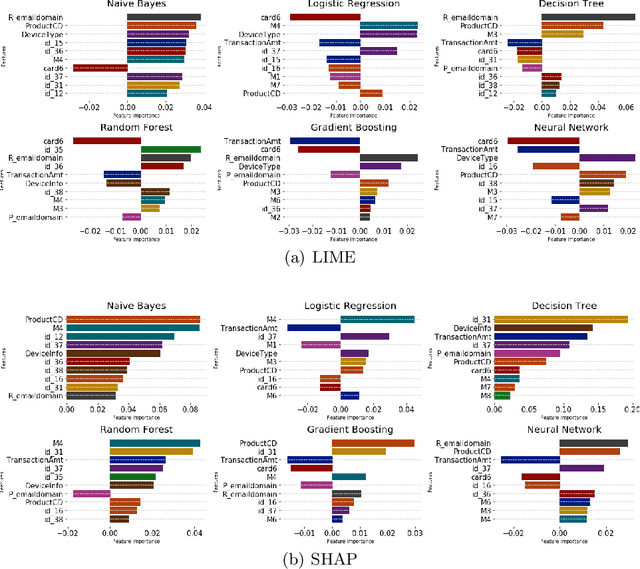
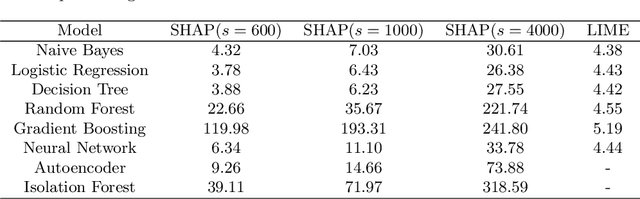
The application of machine learning to support the processing of large datasets holds promise in many industries, including financial services. However, practical issues for the full adoption of machine learning remain with the focus being on understanding and being able to explain the decisions and predictions made by complex models. In this paper, we explore explainability methods in the domain of real-time fraud detection by investigating the selection of appropriate background datasets and runtime trade-offs on both supervised and unsupervised models.
A Fast MR Fingerprinting Simulator for Direct Error Estimation and Sequence Optimization
May 25, 2021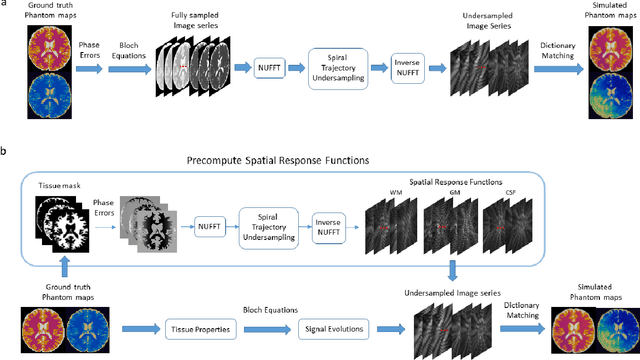
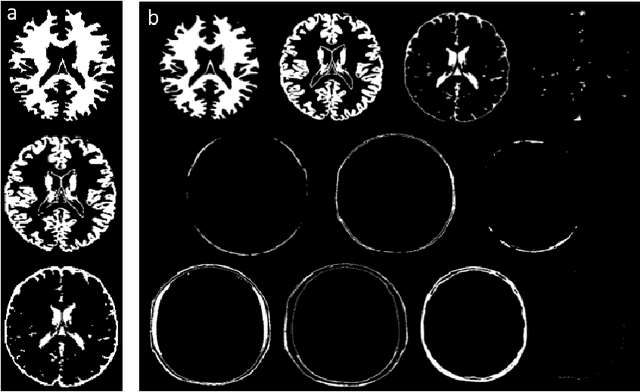
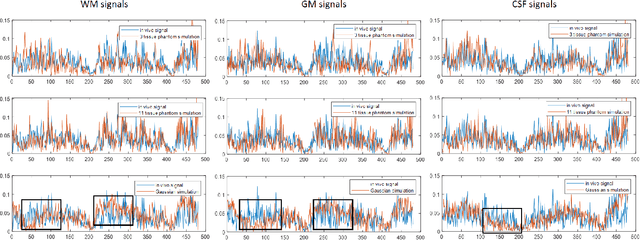

MR Fingerprinting is a novel quantitative MR technique that could simultaneously provide multiple tissue property maps. When optimizing MRF scans, modeling undersampling errors and field imperfections in cost functions will make the optimization results more practical and robust. However, this process is computationally expensive and impractical for sequence optimization algorithms when MRF signal evolutions need to be generated for each optimization iteration. Here, we introduce a fast MRF simulator to simulate aliased images from actual scan scenarios including undersampling and system imperfections, which substantially reduces computational time and allows for direct error estimation and efficient sequence optimization. By constraining the total number of tissues present in a brain phantom, MRF signals from highly undersampled scans can be simulated as the product of the spatial response functions based on sampling patterns and sequence-dependent temporal functions. During optimization, the spatial response function is independent of sequence design and does not need to be recalculated. We evaluate the performance and computational speed of the proposed approach by simulations and in vivo experiments. We also demonstrate the power of applying the simulator in MRF sequence optimization. The simulation results from the proposed method closely approximate the signals and MRF maps from in vivo scans, with 158 times shorter processing time than the conventional simulation method using Non-uniform Fourier transform. Incorporating the proposed simulator in the MRF optimization framework makes direct estimation of undersampling errors during the optimization process feasible, and provide optimized MRF sequences that are robust against undersampling factors and system inhomogeneity.
Text-Aware Predictive Monitoring of Business Processes
Apr 21, 2021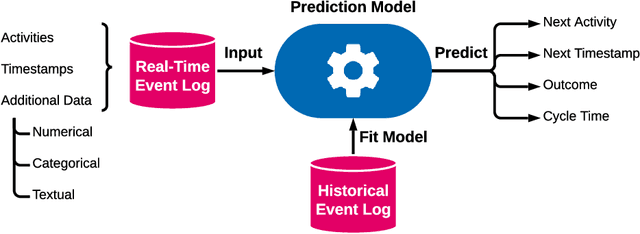

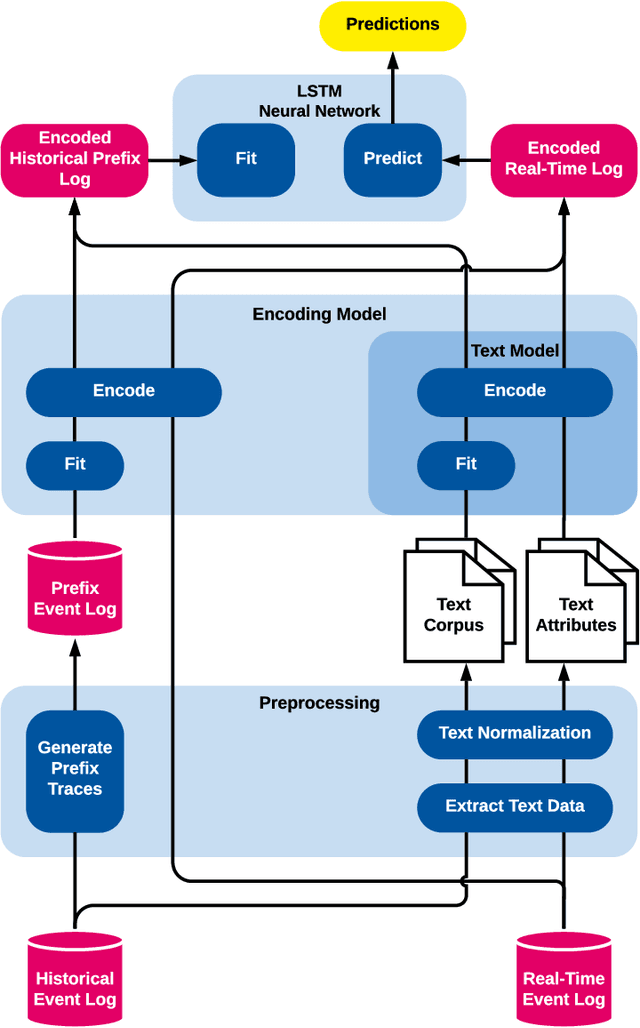
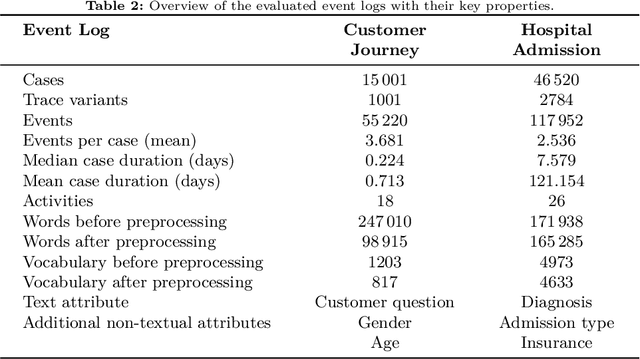
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
SRIB-LEAP submission to Far-field Multi-Channel Speech Enhancement Challenge for Video Conferencing
Jun 24, 2021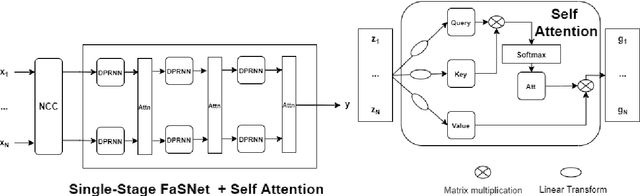
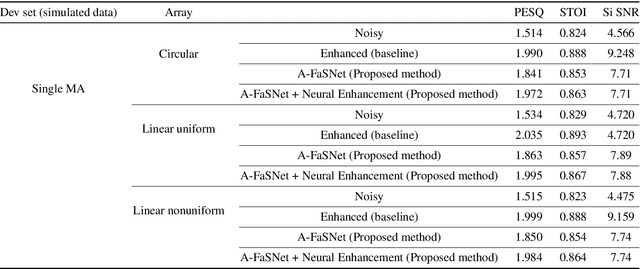


This paper presents the details of the SRIB-LEAP submission to the ConferencingSpeech challenge 2021. The challenge involved the task of multi-channel speech enhancement to improve the quality of far field speech from microphone arrays in a video conferencing room. We propose a two stage method involving a beamformer followed by single channel enhancement. For the beamformer, we incorporated self-attention mechanism as inter-channel processing layer in the filter-and-sum network (FaSNet), an end-to-end time-domain beamforming system. The single channel speech enhancement is done in log spectral domain using convolution neural network (CNN)-long short term memory (LSTM) based architecture. We achieved improvements in objective quality metrics - perceptual evaluation of speech quality (PESQ) of 0.5 on the noisy data. On subjective quality evaluation, the proposed approach improved the mean opinion score (MOS) by an absolute measure of 0.9 over the noisy audio.
Scalable, Proposal-free Instance Segmentation Network for 3D Pixel Clustering and Particle Trajectory Reconstruction in Liquid Argon Time Projection Chambers
Jul 06, 2020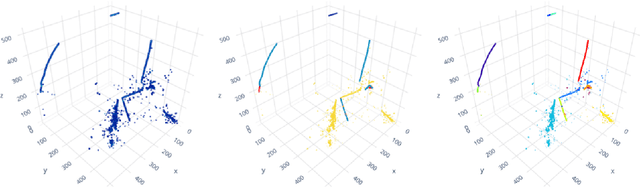
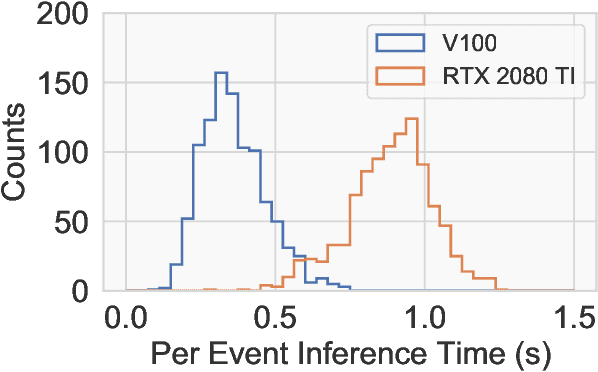
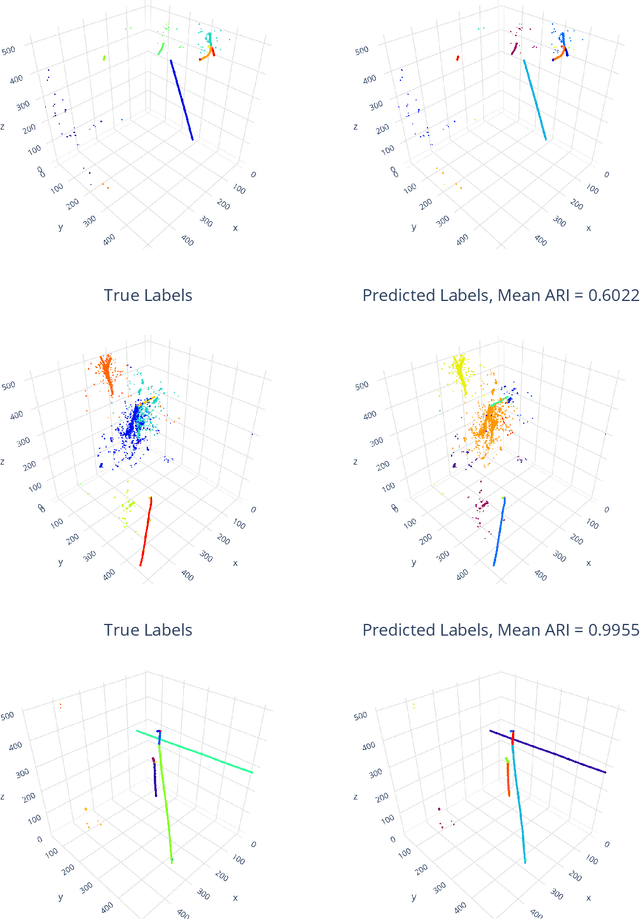
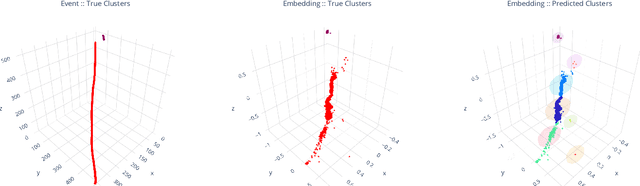
Liquid Argon Time Projection Chambers (LArTPCs) are high resolution particle imaging detectors, employed by accelerator-based neutrino oscillation experiments for high precision physics measurements. While images of particle trajectories are intuitive to analyze for physicists, the development of a high quality, automated data reconstruction chain remains challenging. One of the most critical reconstruction steps is particle clustering: the task of grouping 3D image pixels into different particle instances that share the same particle type. In this paper, we propose the first scalable deep learning algorithm for particle clustering in LArTPC data using sparse convolutional neural networks (SCNN). Building on previous works on SCNNs and proposal free instance segmentation, we build an end-to-end trainable instance segmentation network that learns an embedding of the image pixels to perform point cloud clustering in a transformed space. We benchmark the performance of our algorithm on PILArNet, a public 3D particle imaging dataset, with respect to common clustering evaluation metrics. 3D pixels were successfully clustered into individual particle trajectories with 90% of them having an adjusted Rand index score greater than 92% with a mean pixel clustering efficiency and purity above 96%. This work contributes to the development of an end-to-end optimizable full data reconstruction chain for LArTPCs, in particular pixel-based 3D imaging detectors including the near detector of the Deep Underground Neutrino Experiment. Our algorithm is made available in the open access repository, and we share our Singularity software container, which can be used to reproduce our work on the dataset.