 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Resource Management for Providing QoS in Drone Delivery Systems
Mar 06, 2021
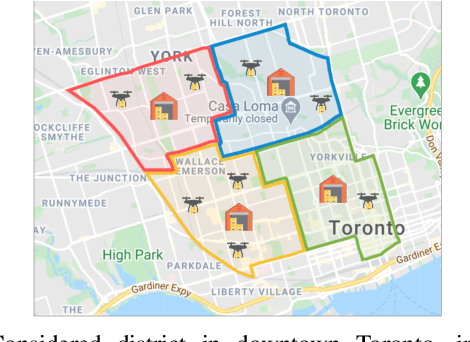
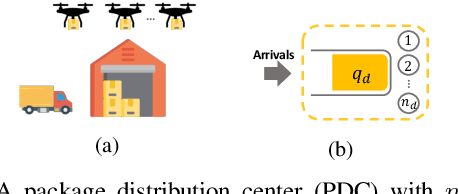
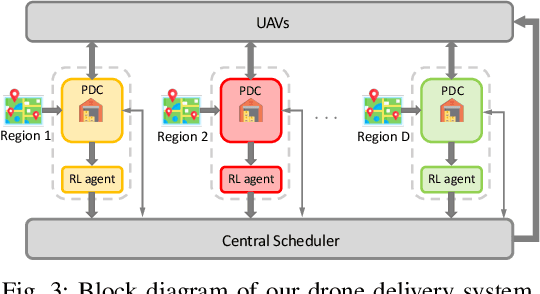
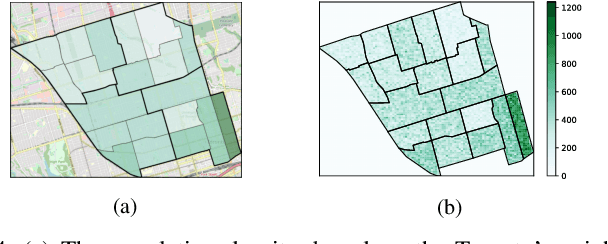
Drones have been considered as an alternative means of package delivery to reduce the delivery cost and time. Due to the battery limitations, the drones are best suited for last-mile delivery, i.e., the delivery from the package distribution centers (PDCs) to the customers. Since a typical delivery system consists of multiple PDCs, each having random and time-varying demands, the dynamic drone-to-PDC allocation would be of great importance in meeting the demand in an efficient manner. In this paper, we study the dynamic UAV assignment problem for a drone delivery system with the goal of providing measurable Quality of Service (QoS) guarantees. We adopt a queueing theoretic approach to model the customer-service nature of the problem. Furthermore, we take a deep reinforcement learning approach to obtain a dynamic policy for the re-allocation of the UAVs. This policy guarantees a probabilistic upper-bound on the queue length of the packages waiting in each PDC, which is beneficial from both the service provider's and the customers' viewpoints. We evaluate the performance of our proposed algorithm by considering three broad arrival classes, including Bernoulli, Time-Varying Bernoulli, and Markov-Modulated Bernoulli arrivals. Our results show that the proposed method outperforms the baselines, particularly in scenarios with Time-Varying and Markov-Modulated Bernoulli arrivals, which are more representative of real-world demand patterns. Moreover, our algorithm satisfies the QoS constraints in all the studied scenarios while minimizing the average number of UAVs in use.
Exploring Stronger Feature for Temporal Action Localization
Jun 24, 2021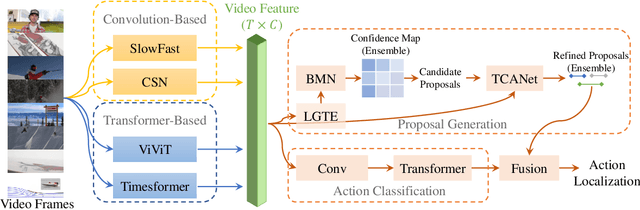
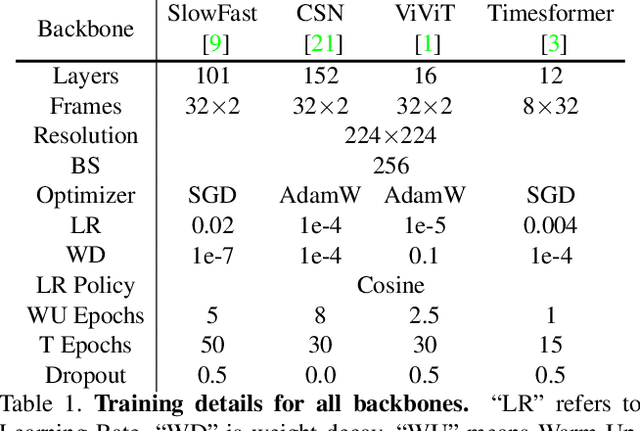
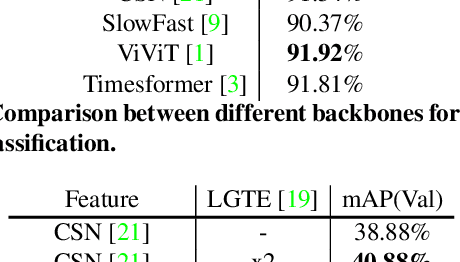

Temporal action localization aims to localize starting and ending time with action category. Limited by GPU memory, mainstream methods pre-extract features for each video. Therefore, feature quality determines the upper bound of detection performance. In this technical report, we explored classic convolution-based backbones and the recent surge of transformer-based backbones. We found that the transformer-based methods can achieve better classification performance than convolution-based, but they cannot generate accuracy action proposals. In addition, extracting features with larger frame resolution to reduce the loss of spatial information can also effectively improve the performance of temporal action localization. Finally, we achieve 42.42% in terms of mAP on validation set with a single SlowFast feature by a simple combination: BMN+TCANet, which is 1.87% higher than the result of 2020's multi-model ensemble. Finally, we achieve Rank 1st on the CVPR2021 HACS supervised Temporal Action Localization Challenge.
What Doesn't Kill You Makes You Robust(er): Adversarial Training against Poisons and Backdoors
Feb 26, 2021Data poisoning is a threat model in which a malicious actor tampers with training data to manipulate outcomes at inference time. A variety of defenses against this threat model have been proposed, but each suffers from at least one of the following flaws: they are easily overcome by adaptive attacks, they severely reduce testing performance, or they cannot generalize to diverse data poisoning threat models. Adversarial training, and its variants, is currently considered the only empirically strong defense against (inference-time) adversarial attacks. In this work, we extend the adversarial training framework to instead defend against (training-time) poisoning and backdoor attacks. Our method desensitizes networks to the effects of poisoning by creating poisons during training and injecting them into training batches. We show that this defense withstands adaptive attacks, generalizes to diverse threat models, and incurs a better performance trade-off than previous defenses.
A Sketching Framework for Reduced Data Transfer in Photon Counting Lidar
Feb 17, 2021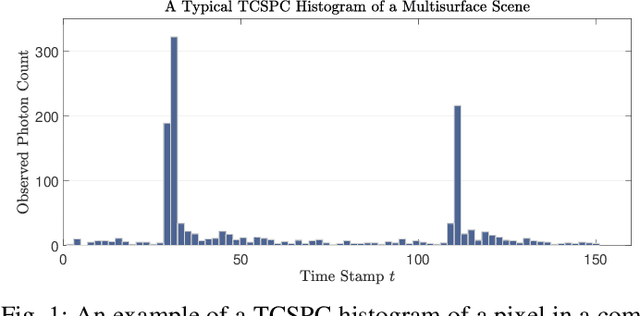
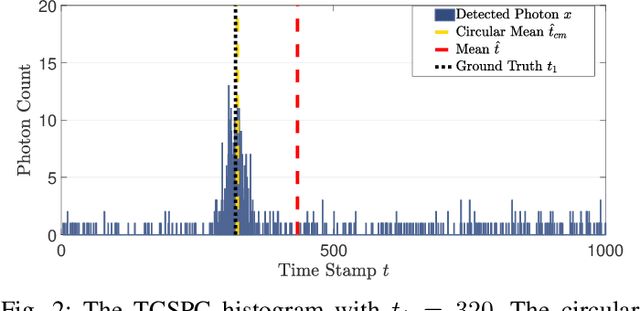
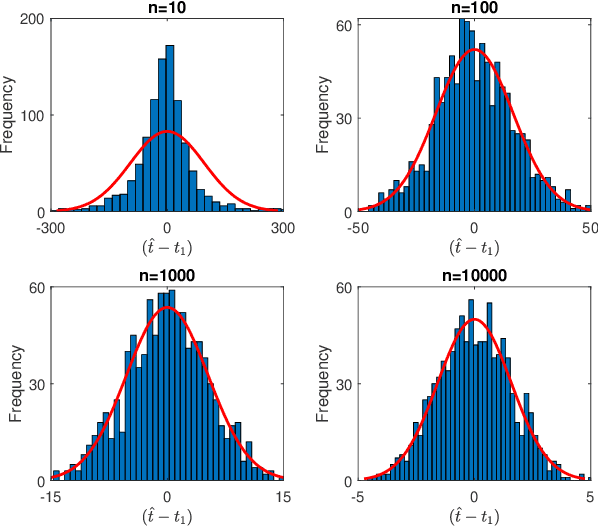
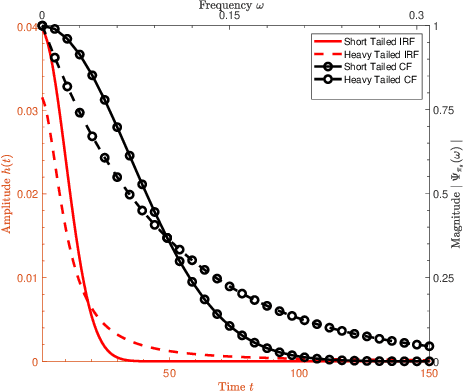
Single-photon lidar has become a prominent tool for depth imaging in recent years. At the core of the technique, the depth of a target is measured by constructing a histogram of time delays between emitted light pulses and detected photon arrivals. A major data processing bottleneck arises on the device when either the number of photons per pixel is large or the resolution of the time stamp is fine, as both the space requirement and the complexity of the image reconstruction algorithms scale with these parameters. We solve this limiting bottleneck of existing lidar techniques by sampling the characteristic function of the time of flight (ToF) model to build a compressive statistic, a so-called sketch of the time delay distribution, which is sufficient to infer the spatial distance and intensity of the object. The size of the sketch scales with the degrees of freedom of the ToF model (number of objects) and not, fundamentally, with the number of photons or the time stamp resolution. Moreover, the sketch is highly amenable for on-chip online processing. We show theoretically that the loss of information for compression is controlled and the mean squared error of the inference quickly converges towards the optimal Cram\'er-Rao bound (i.e. no loss of information) for modest sketch sizes. The proposed compressed single-photon lidar framework is tested and evaluated on real life datasets of complex scenes where it is shown that a compression rate of up-to 1/150 is achievable in practice without sacrificing the overall resolution of the reconstructed image.
MIMO Ambiguity Functions and Harmonic Analysis
Apr 26, 2021Multi input multi output (MIMO) systems\' capability of using seperate signals brings many advantages to radar signal processing and time frequency analysis. In this paper, a variety of properties of MIMO ambiguity functions related with representations of Heisenberg group are given. Some of the existing results for SIMO ambiguity functions are generalized to MIMO case. Combined effect of seperate signals is investigated.
Conformer-based End-to-end Speech Recognition With Rotary Position Embedding
Jul 13, 2021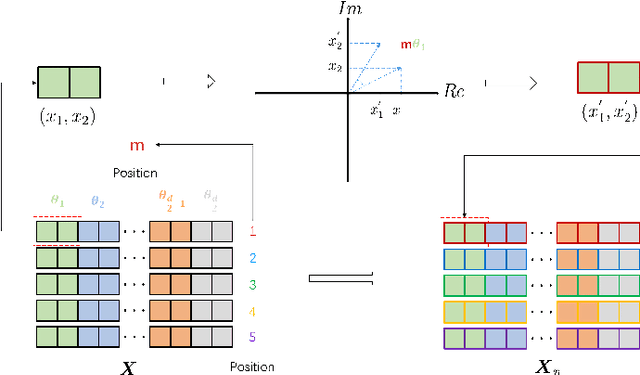
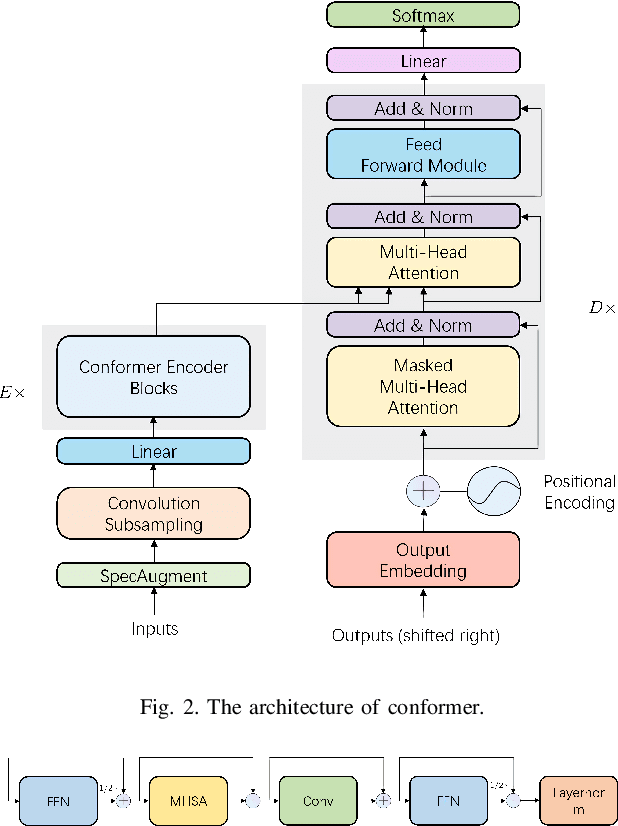
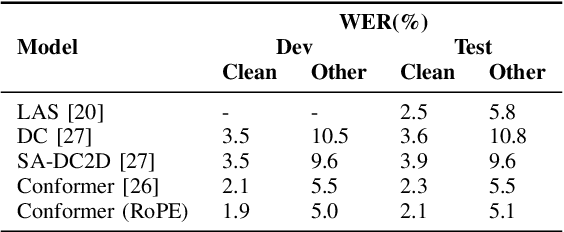
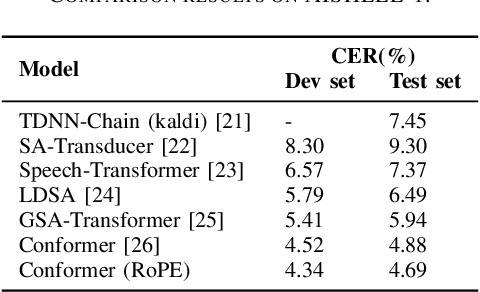
Transformer-based end-to-end speech recognition models have received considerable attention in recent years due to their high training speed and ability to model a long-range global context. Position embedding in the transformer architecture is indispensable because it provides supervision for dependency modeling between elements at different positions in the input sequence. To make use of the time order of the input sequence, many works inject some information about the relative or absolute position of the element into the input sequence. In this work, we investigate various position embedding methods in the convolution-augmented transformer (conformer) and adopt a novel implementation named rotary position embedding (RoPE). RoPE encodes absolute positional information into the input sequence by a rotation matrix, and then naturally incorporates explicit relative position information into a self-attention module. To evaluate the effectiveness of the RoPE method, we conducted experiments on AISHELL-1 and LibriSpeech corpora. Results show that the conformer enhanced with RoPE achieves superior performance in the speech recognition task. Specifically, our model achieves a relative word error rate reduction of 8.70% and 7.27% over the conformer on test-clean and test-other sets of the LibriSpeech corpus respectively.
Fast approximations of the Jeffreys divergence between univariate Gaussian mixture models via exponential polynomial densities
Jul 13, 2021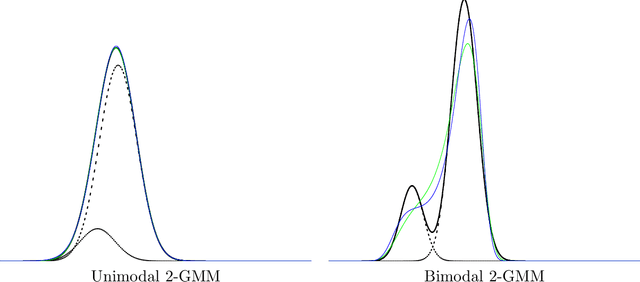
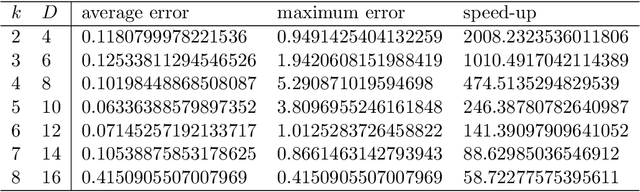
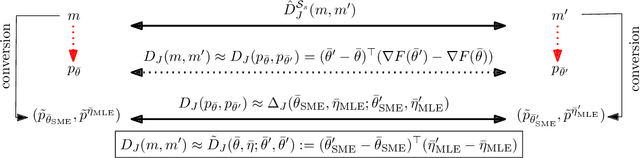

The Jeffreys divergence is a renown symmetrization of the statistical Kullback-Leibler divergence which is often used in machine learning, signal processing, and information sciences. Since the Jeffreys divergence between the ubiquitous Gaussian Mixture Models are not available in closed-form, many techniques with various pros and cons have been proposed in the literature to either (i) estimate, (ii) approximate, or (iii) lower and upper bound this divergence. In this work, we propose a simple yet fast heuristic to approximate the Jeffreys divergence between two GMMs of arbitrary number of components. The heuristic relies on converting GMMs into pairs of dually parameterized probability densities belonging to exponential families. In particular, we consider Polynomial Exponential Densities, and design a goodness-of-fit criterion to measure the dissimilarity between a GMM and a PED which is a generalization of the Hyv\"arinen divergence. This criterion allows one to select the orders of the PEDs to approximate the GMMs. We demonstrate experimentally that the computational time of our heuristic improves over the stochastic Monte Carlo estimation baseline by several orders of magnitude while approximating reasonably well the Jeffreys divergence, specially when the univariate mixtures have a small number of modes.
Near-Linear Time Local Polynomial Nonparametric Estimation
Feb 26, 2018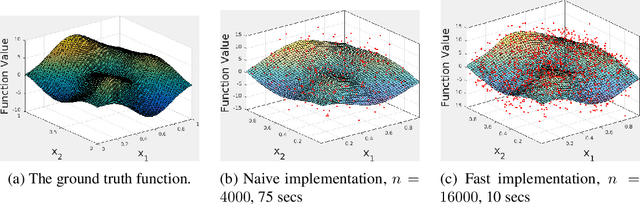
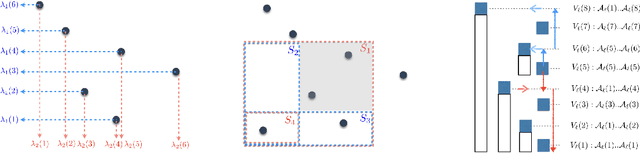
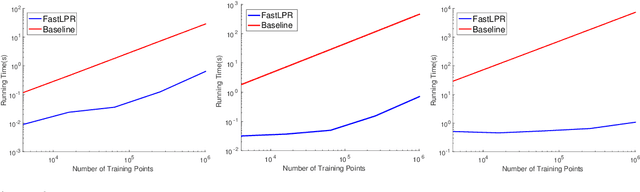
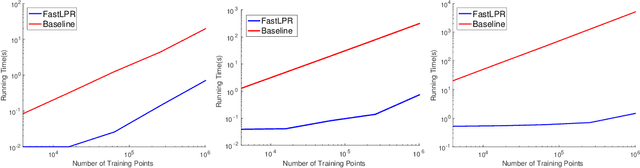
Local polynomial regression (Fan & Gijbels, 1996) is an important class of methods for nonparametric density estimation and regression problems. However, straightforward implementation of local polynomial regression has quadratic time complexity which hinders its applicability in large-scale data analysis. In this paper, we significantly accelerate the computation of local polynomial estimates by novel applications of multi-dimensional binary indexed trees (Fenwick, 1994). Both time and space complexities of our proposed algorithm are nearly linear in the number of inputs. Simulation results confirm the efficiency and effectiveness of our approach.
Frequency Estimation Under Multiparty Differential Privacy: One-shot and Streaming
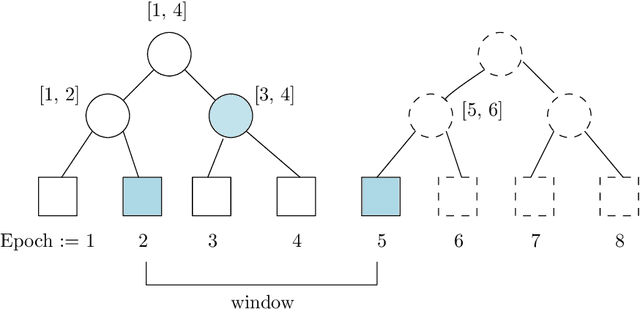
Apr 05, 2021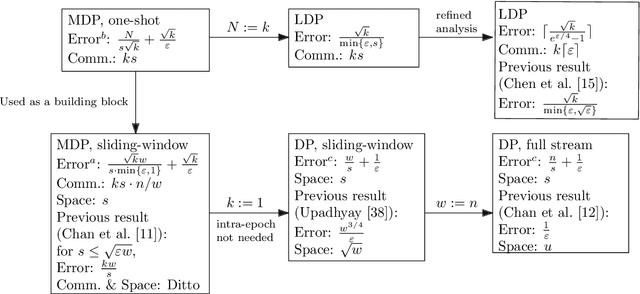
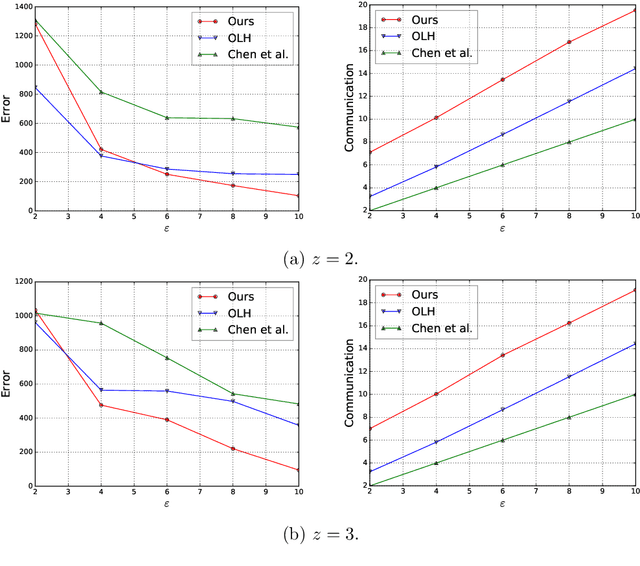
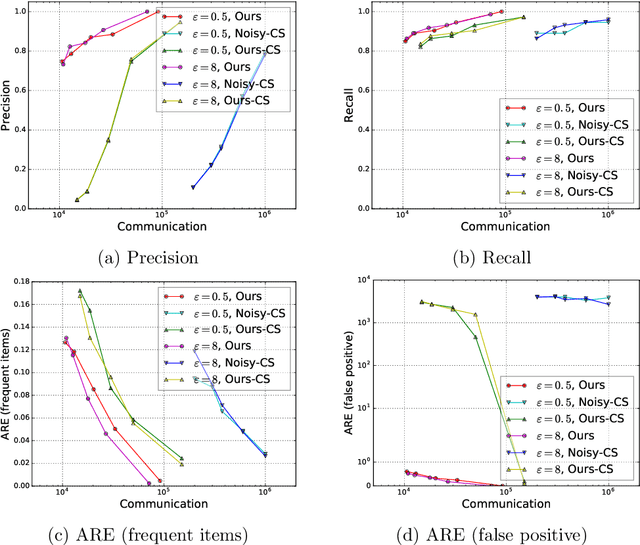
We study the fundamental problem of frequency estimation under both privacy and communication constraints, where the data is distributed among $k$ parties. We consider two application scenarios: (1) one-shot, where the data is static and the aggregator conducts a one-time computation; and (2) streaming, where each party receives a stream of items over time and the aggregator continuously monitors the frequencies. We adopt the model of multiparty differential privacy (MDP), which is more general than local differential privacy (LDP) and (centralized) differential privacy. Our protocols achieve optimality (up to logarithmic factors) permissible by the more stringent of the two constraints. In particular, when specialized to the $\varepsilon$-LDP model, our protocol achieves an error of $\sqrt{k}/(e^{\Theta(\varepsilon)}-1)$ for all $\varepsilon$, while the previous protocol (Chen et al., 2020) has error $O(\sqrt{k}/\min\{\varepsilon, \sqrt{\varepsilon}\})$.
Personalized Stress Monitoring using Wearable Sensors in Everyday Settings
Jul 31, 2021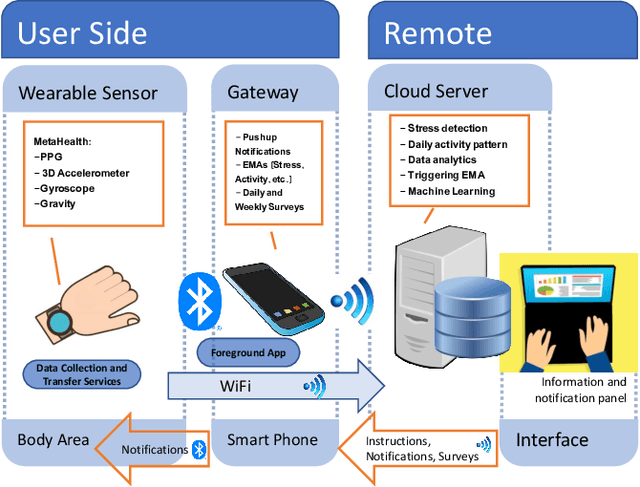
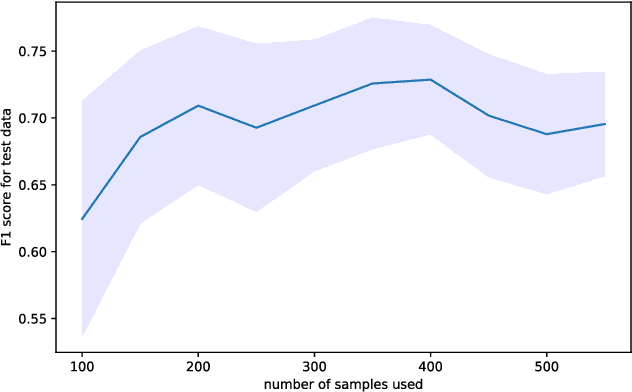
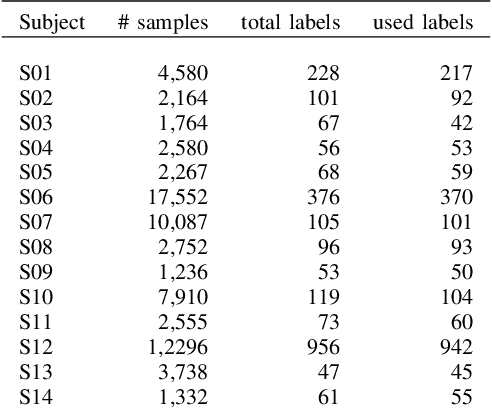

Since stress contributes to a broad range of mental and physical health problems, the objective assessment of stress is essential for behavioral and physiological studies. Although several studies have evaluated stress levels in controlled settings, objective stress assessment in everyday settings is still largely under-explored due to challenges arising from confounding contextual factors and limited adherence for self-reports. In this paper, we explore the objective prediction of stress levels in everyday settings based on heart rate (HR) and heart rate variability (HRV) captured via low-cost and easy-to-wear photoplethysmography (PPG) sensors that are widely available on newer smart wearable devices. We present a layered system architecture for personalized stress monitoring that supports a tunable collection of data samples for labeling, and present a method for selecting informative samples from the stream of real-time data for labeling. We captured the stress levels of fourteen volunteers through self-reported questionnaires over periods of between 1-3 months, and explored binary stress detection based on HR and HRV using Machine Learning Methods. We observe promising preliminary results given that the dataset is collected in the challenging environments of everyday settings. The binary stress detector is fairly accurate and can detect stressful vs non-stressful samples with a macro-F1 score of up to \%76. Our study lays the groundwork for more sophisticated labeling strategies that generate context-aware, personalized models that will empower health professionals to provide personalized interventions.