 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SELM: Siamese Extreme Learning Machine with Application to Face Biometrics
Aug 06, 2021
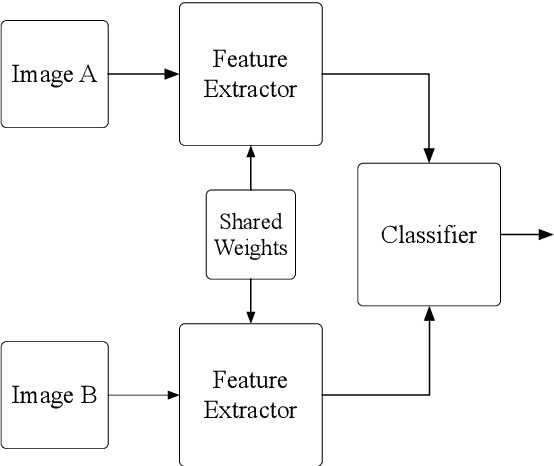
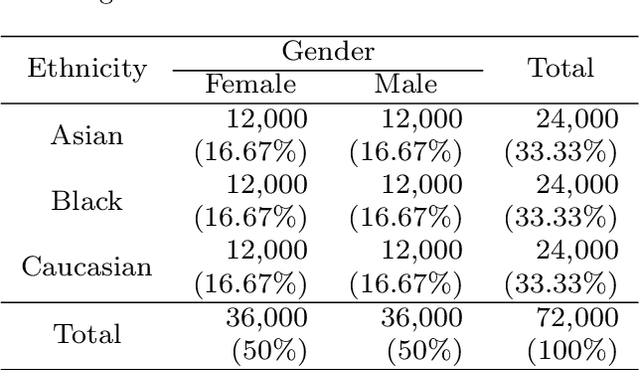
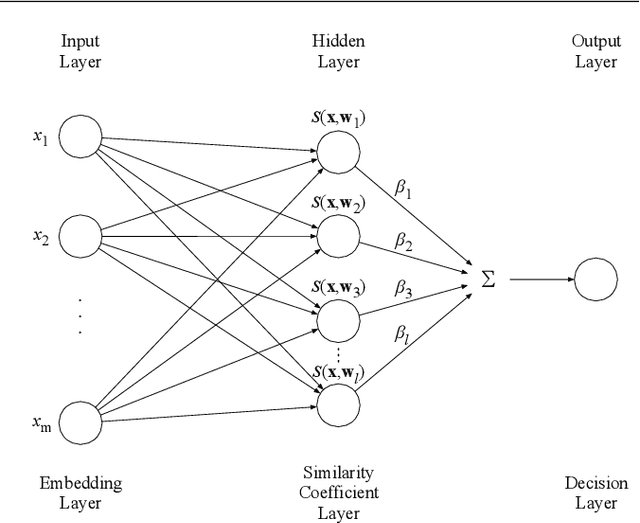
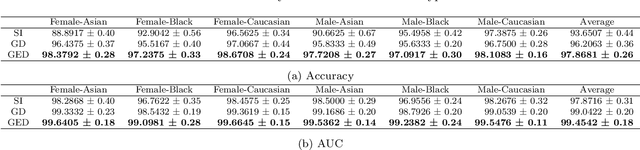
Extreme Learning Machine is a powerful classification method very competitive existing classification methods. It is extremely fast at training. Nevertheless, it cannot perform face verification tasks properly because face verification tasks require comparison of facial images of two individuals at the same time and decide whether the two faces identify the same person. The structure of Extreme Leaning Machine was not designed to feed two input data streams simultaneously, thus, in 2-input scenarios Extreme Learning Machine methods are normally applied using concatenated inputs. However, this setup consumes two times more computational resources and it is not optimized for recognition tasks where learning a separable distance metric is critical. For these reasons, we propose and develop a Siamese Extreme Learning Machine (SELM). SELM was designed to be fed with two data streams in parallel simultaneously. It utilizes a dual-stream Siamese condition in the extra Siamese layer to transform the data before passing it along to the hidden layer. Moreover, we propose a Gender-Ethnicity-Dependent triplet feature exclusively trained on a variety of specific demographic groups. This feature enables learning and extracting of useful facial features of each group. Experiments were conducted to evaluate and compare the performances of SELM, Extreme Learning Machine, and DCNN. The experimental results showed that the proposed feature was able to perform correct classification at 97.87% accuracy and 99.45% AUC. They also showed that using SELM in conjunction with the proposed feature provided 98.31% accuracy and 99.72% AUC. They outperformed the well-known DCNN and Extreme Leaning Machine methods by a wide margin.
Cervical Optical Coherence Tomography Image Classification Based on Contrastive Self-Supervised Texture Learning
Aug 11, 2021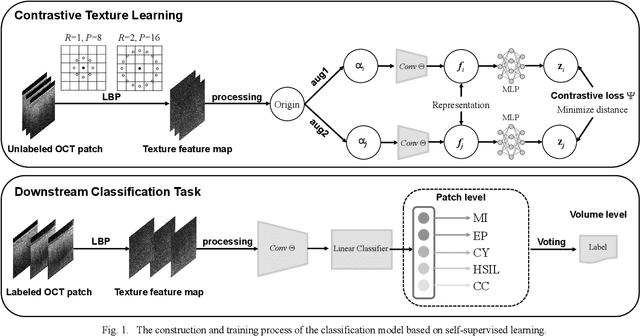
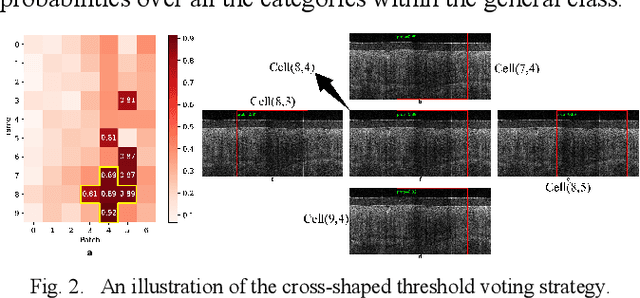
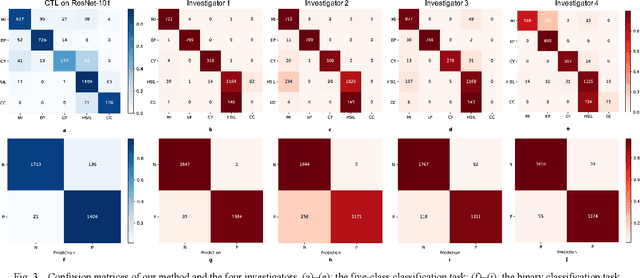
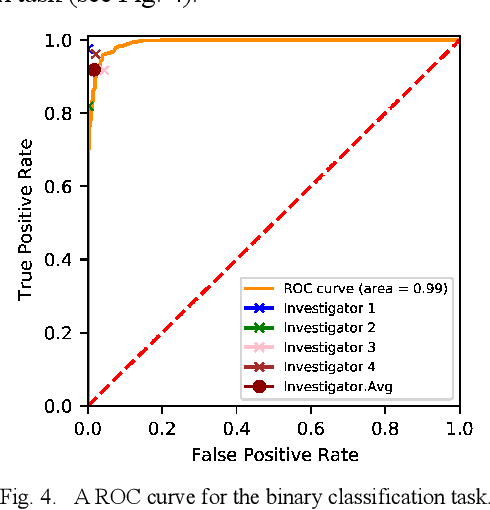
Background: Cervical cancer seriously affects the health of the female reproductive system. Optical coherence tomography (OCT) emerges as a non-invasive, high-resolution imaging technology for cervical disease detection. However, OCT image annotation is knowledge-intensive and time-consuming, which impedes the training process of deep-learning-based classification models. Objective: This study aims to develop a computer-aided diagnosis (CADx) approach to classifying in-vivo cervical OCT images based on self-supervised learning. Methods: Besides high-level semantic features extracted by a convolutional neural network (CNN), the proposed CADx approach leverages unlabeled cervical OCT images' texture features learned by contrastive texture learning. We conducted ten-fold cross-validation on the OCT image dataset from a multi-center clinical study on 733 patients from China. Results: In a binary classification task for detecting high-risk diseases, including high-grade squamous intraepithelial lesion (HSIL) and cervical cancer, our method achieved an area-under-the-curve (AUC) value of 0.9798 Plus or Minus 0.0157 with a sensitivity of 91.17 Plus or Minus 4.99% and a specificity of 93.96 Plus or Minus 4.72% for OCT image patches; also, it outperformed two out of four medical experts on the test set. Furthermore, our method achieved a 91.53% sensitivity and 97.37% specificity on an external validation dataset containing 287 3D OCT volumes from 118 Chinese patients in a new hospital using a cross-shaped threshold voting strategy. Conclusion: The proposed contrastive-learning-based CADx method outperformed the end-to-end CNN models and provided better interpretability based on texture features, which holds great potential to be used in the clinical protocol of "see-and-treat."
RepVGG: Making VGG-style ConvNets Great Again
Jan 11, 2021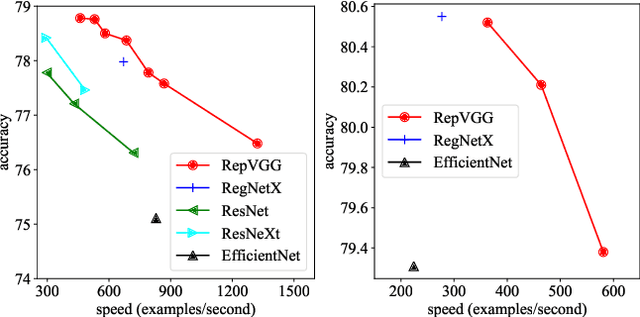
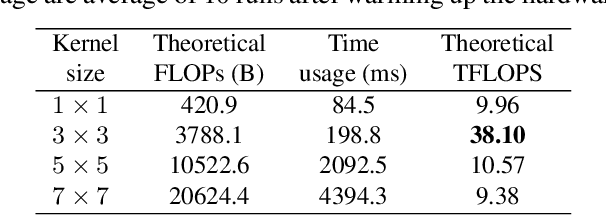
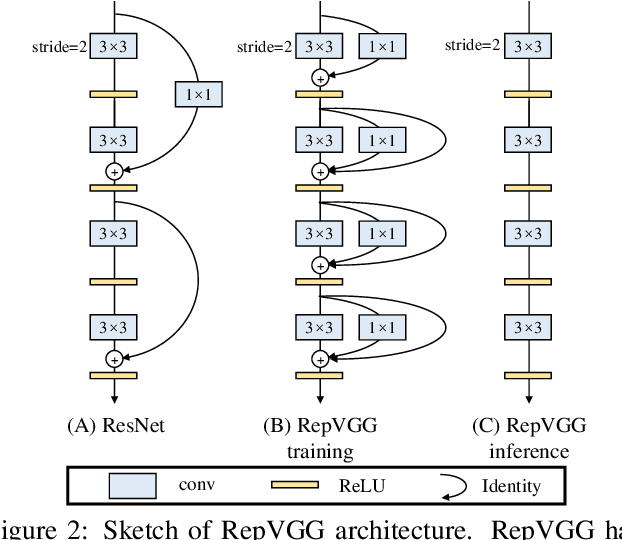

We present a simple but powerful architecture of convolutional neural network, which has a VGG-like inference-time body composed of nothing but a stack of 3x3 convolution and ReLU, while the training-time model has a multi-branch topology. Such decoupling of the training-time and inference-time architecture is realized by a structural re-parameterization technique so that the model is named RepVGG. On ImageNet, RepVGG reaches over 80\% top-1 accuracy, which is the first time for a plain model, to the best of our knowledge. On NVIDIA 1080Ti GPU, RepVGG models run 83% faster than ResNet-50 or 101% faster than ResNet-101 with higher accuracy and show favorable accuracy-speed trade-off compared to the state-of-the-art models like EfficientNet and RegNet. The code and trained models are available at https://github.com/megvii-model/RepVGG.
POLAR: A Polynomial Arithmetic Framework for Verifying Neural-Network Controlled Systems
Jul 07, 2021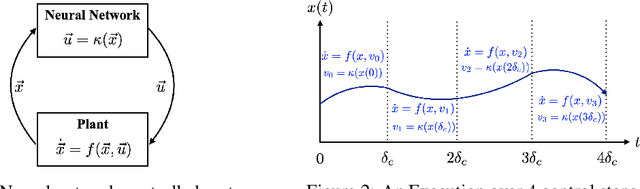
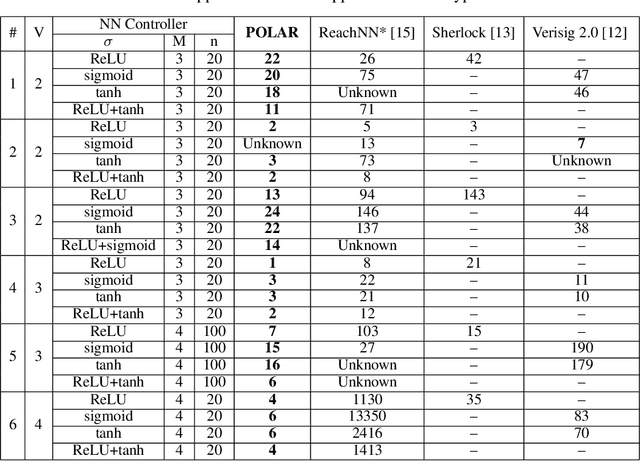
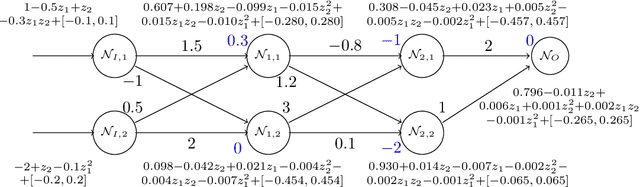
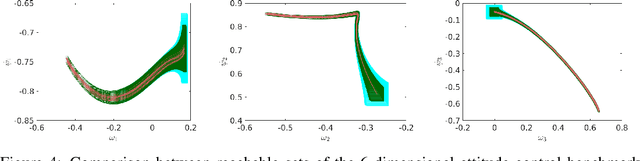
We propose POLAR, a \textbf{pol}ynomial \textbf{ar}ithmetic framework that leverages polynomial overapproximations with interval remainders for bounded-time reachability analysis of neural network-controlled systems (NNCSs). Compared with existing arithmetic approaches that use standard Taylor models, our framework uses a novel approach to iteratively overapproximate the neuron output ranges layer-by-layer with a combination of Bernstein polynomial interpolation for continuous activation functions and Taylor model arithmetic for the other operations. This approach can overcome the main drawback in the standard Taylor model arithmetic, i.e. its inability to handle functions that cannot be well approximated by Taylor polynomials, and significantly improve the accuracy and efficiency of reachable states computation for NNCSs. To further tighten the overapproximation, our method keeps the Taylor model remainders symbolic under the linear mappings when estimating the output range of a neural network. We show that POLAR can be seamlessly integrated with existing Taylor model flowpipe construction techniques, and demonstrate that POLAR significantly outperforms the current state-of-the-art techniques on a suite of benchmarks.
A causal learning framework for the analysis and interpretation of COVID-19 clinical data
May 14, 2021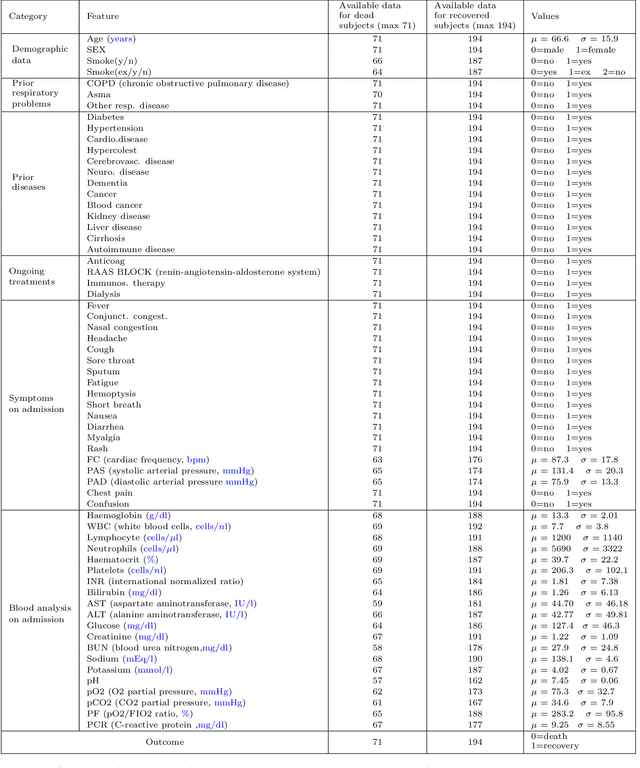
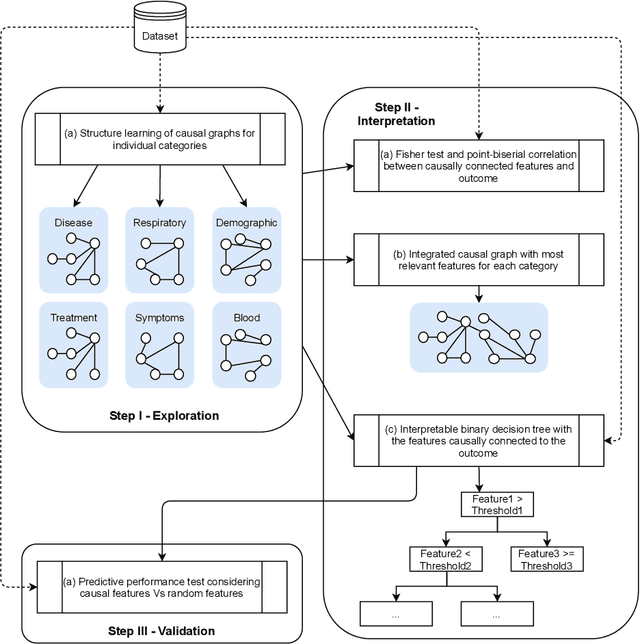
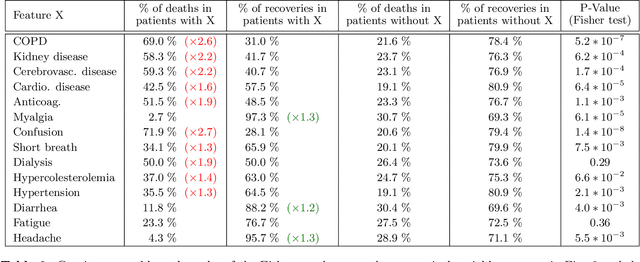
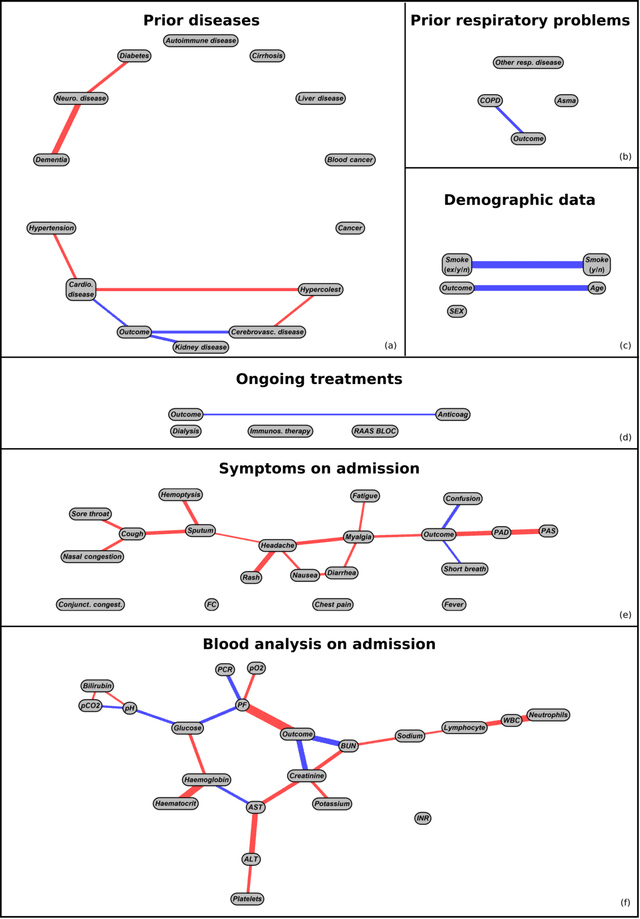
We present a workflow for clinical data analysis that relies on Bayesian Structure Learning (BSL), an unsupervised learning approach, robust to noise and biases, that allows to incorporate prior medical knowledge into the learning process and that provides explainable results in the form of a graph showing the causal connections among the analyzed features. The workflow consists in a multi-step approach that goes from identifying the main causes of patient's outcome through BSL, to the realization of a tool suitable for clinical practice, based on a Binary Decision Tree (BDT), to recognize patients at high-risk with information available already at hospital admission time. We evaluate our approach on a feature-rich COVID-19 dataset, showing that the proposed framework provides a schematic overview of the multi-factorial processes that jointly contribute to the outcome. We discuss how these computational findings are confirmed by current understanding of the COVID-19 pathogenesis. Further, our approach yields to a highly interpretable tool correctly predicting the outcome of 85% of subjects based exclusively on 3 features: age, a previous history of chronic obstructive pulmonary disease and the PaO2/FiO2 ratio at the time of arrival to the hospital. The inclusion of additional information from 4 routine blood tests (Creatinine, Glucose, pO2 and Sodium) increases predictive accuracy to 94.5%.
ULTRA: An Unbiased Learning To Rank Algorithm Toolbox
Aug 11, 2021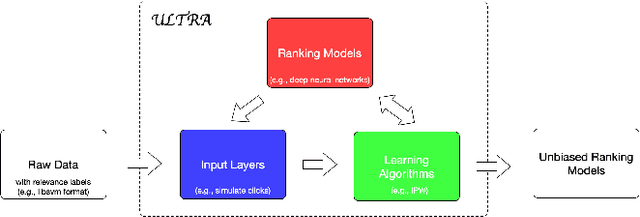
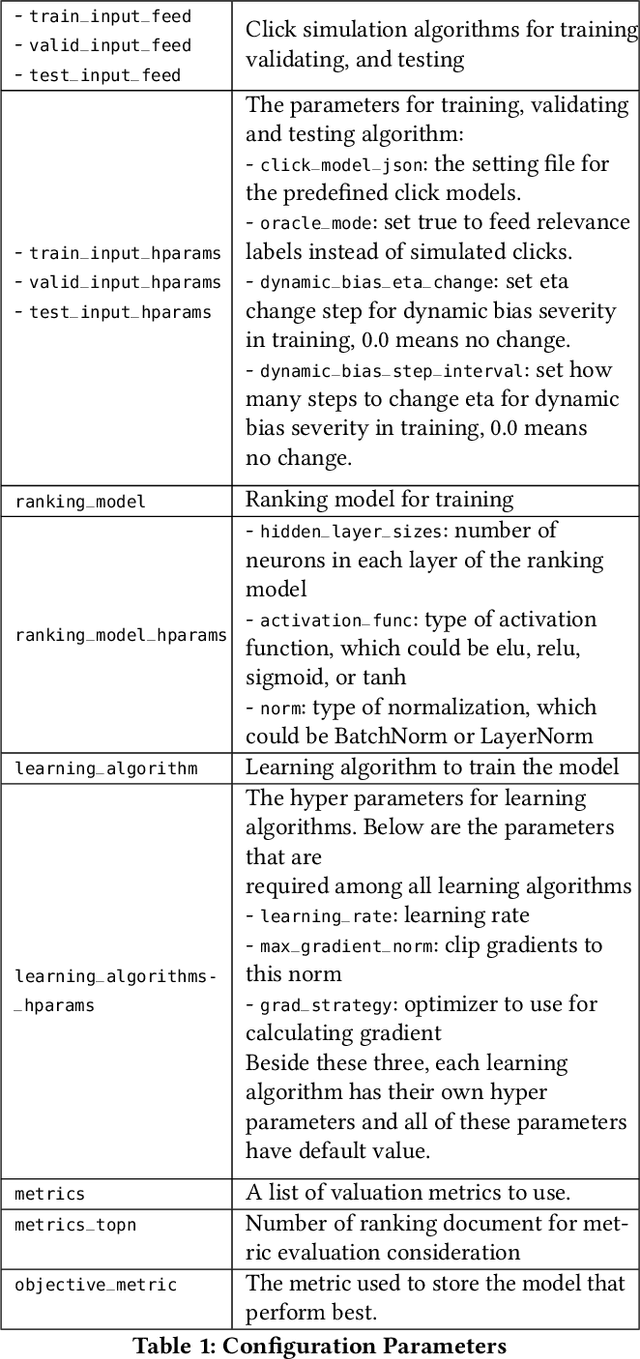
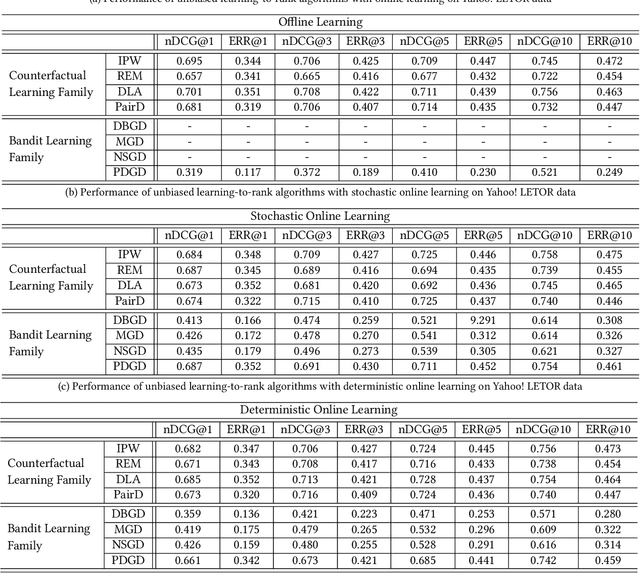
Learning to rank systems has become an important aspect of our daily life. However, the implicit user feedback that is used to train many learning to rank models is usually noisy and suffered from user bias (i.e., position bias). Thus, obtaining an unbiased model using biased feedback has become an important research field for IR. Existing studies on unbiased learning to rank (ULTR) can be generalized into two families-algorithms that attain unbiasedness with logged data, offline learning, and algorithms that achieve unbiasedness by estimating unbiased parameters with real-time user interactions, namely online learning. While there exist many algorithms from both families, there lacks a unified way to compare and benchmark them. As a result, it can be challenging for researchers to choose the right technique for their problems or for people who are new to the field to learn and understand existing algorithms. To solve this problem, we introduced ULTRA, which is a flexible, extensible, and easily configure ULTR toolbox. Its key features include support for multiple ULTR algorithms with configurable hyperparameters, a variety of built-in click models that can be used separately to simulate clicks, different ranking model architecture and evaluation metrics, and simple learning to rank pipeline creation. In this paper, we discuss the general framework of ULTR, briefly describe the algorithms in ULTRA, detailed the structure, and pipeline of the toolbox. We experimented on all the algorithms supported by ultra and showed that the toolbox performance is reasonable. Our toolbox is an important resource for researchers to conduct experiments on ULTR algorithms with different configurations as well as testing their own algorithms with the supported features.
Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 11, 2021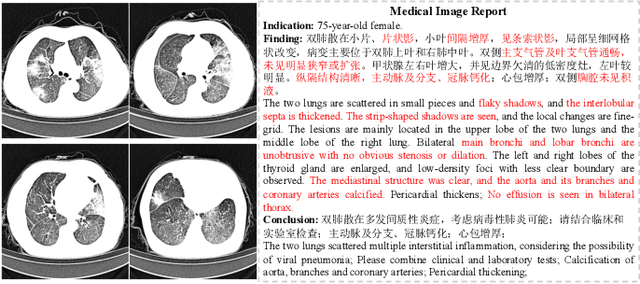
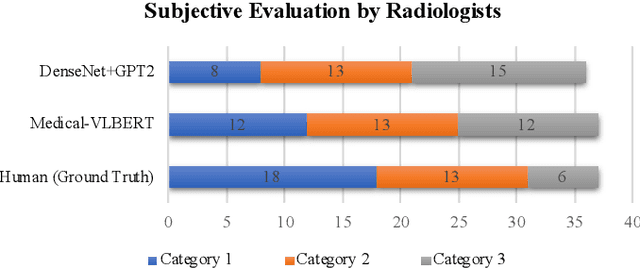
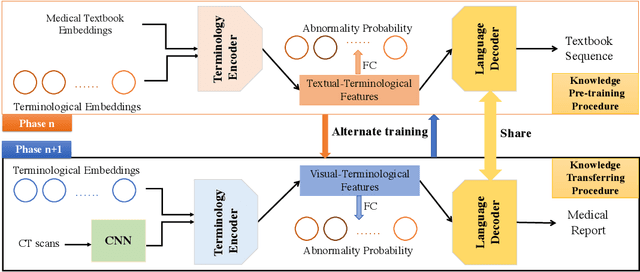
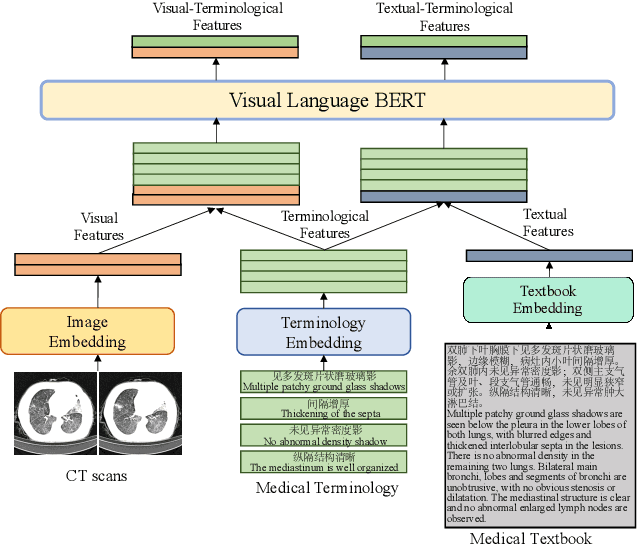
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
EML Online Speech Activity Detection for the Fearless Steps Challenge Phase-III
Jun 21, 2021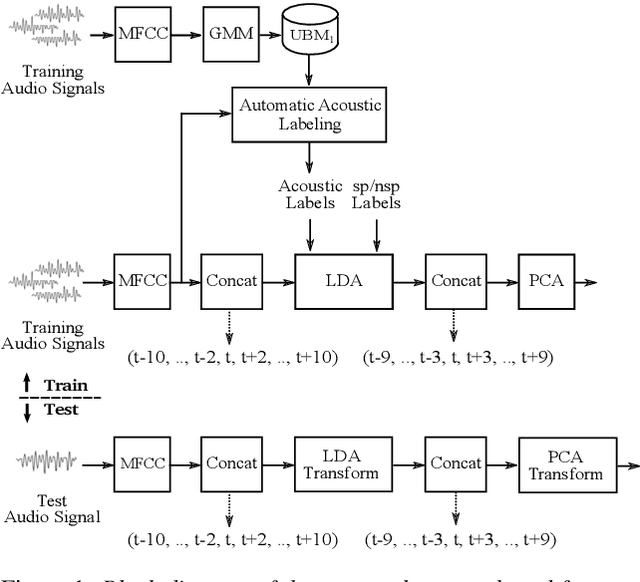

Speech Activity Detection (SAD), locating speech segments within an audio recording, is a main part of most speech technology applications. Robust SAD is usually more difficult in noisy conditions with varying signal-to-noise ratios (SNR). The Fearless Steps challenge has recently provided such data from the NASA Apollo-11 mission for different speech processing tasks including SAD. Most audio recordings are degraded by different kinds and levels of noise varying within and between channels. This paper describes the EML online algorithm for the most recent phase of this challenge. The proposed algorithm can be trained both in a supervised and unsupervised manner and assigns speech and non-speech labels at runtime approximately every 0.1 sec. The experimental results show a competitive accuracy on both development and evaluation datasets with a real-time factor of about 0.002 using a single CPU machine.
H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
Jul 26, 2021
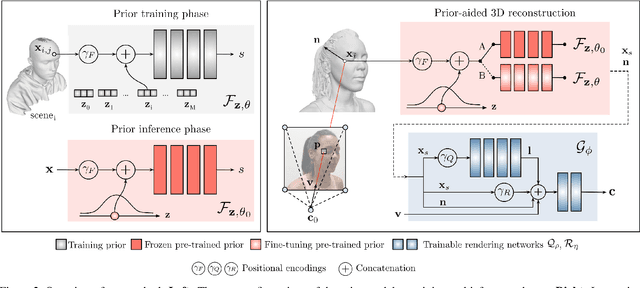


Recent learning approaches that implicitly represent surface geometry using coordinate-based neural representations have shown impressive results in the problem of multi-view 3D reconstruction. The effectiveness of these techniques is, however, subject to the availability of a large number (several tens) of input views of the scene, and computationally demanding optimizations. In this paper, we tackle these limitations for the specific problem of few-shot full 3D head reconstruction, by endowing coordinate-based representations with a probabilistic shape prior that enables faster convergence and better generalization when using few input images (down to three). First, we learn a shape model of 3D heads from thousands of incomplete raw scans using implicit representations. At test time, we jointly overfit two coordinate-based neural networks to the scene, one modeling the geometry and another estimating the surface radiance, using implicit differentiable rendering. We devise a two-stage optimization strategy in which the learned prior is used to initialize and constrain the geometry during an initial optimization phase. Then, the prior is unfrozen and fine-tuned to the scene. By doing this, we achieve high-fidelity head reconstructions, including hair and shoulders, and with a high level of detail that consistently outperforms both state-of-the-art 3D Morphable Models methods in the few-shot scenario, and non-parametric methods when large sets of views are available.
MTH-IDS: A Multi-Tiered Hybrid Intrusion Detection System for Internet of Vehicles
May 26, 2021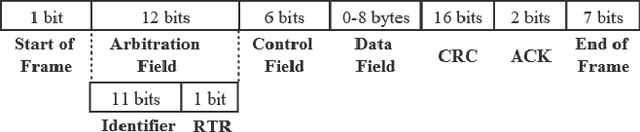
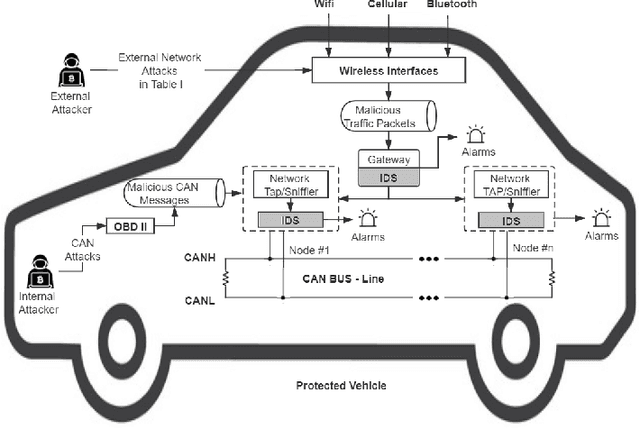
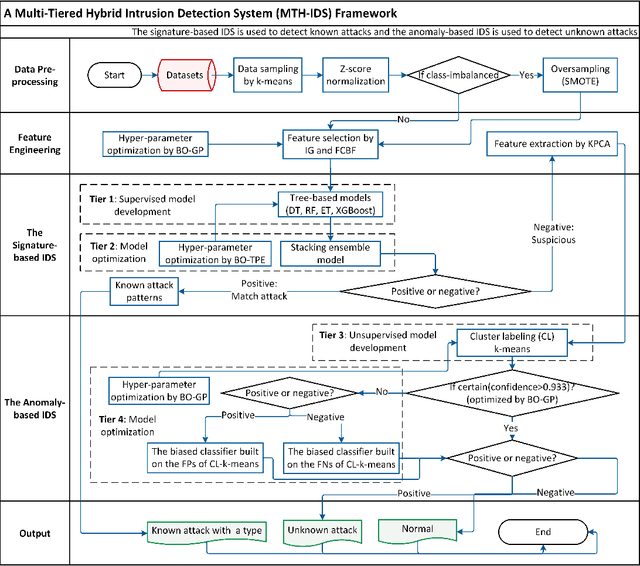

Modern vehicles, including connected vehicles and autonomous vehicles, nowadays involve many electronic control units connected through intra-vehicle networks to implement various functionalities and perform actions. Modern vehicles are also connected to external networks through vehicle-to-everything technologies, enabling their communications with other vehicles, infrastructures, and smart devices. However, the improving functionality and connectivity of modern vehicles also increase their vulnerabilities to cyber-attacks targeting both intra-vehicle and external networks due to the large attack surfaces. To secure vehicular networks, many researchers have focused on developing intrusion detection systems (IDSs) that capitalize on machine learning methods to detect malicious cyber-attacks. In this paper, the vulnerabilities of intra-vehicle and external networks are discussed, and a multi-tiered hybrid IDS that incorporates a signature-based IDS and an anomaly-based IDS is proposed to detect both known and unknown attacks on vehicular networks. Experimental results illustrate that the proposed system can detect various types of known attacks with 99.99% accuracy on the CAN-intrusion-dataset representing the intra-vehicle network data and 99.88% accuracy on the CICIDS2017 dataset illustrating the external vehicular network data. For the zero-day attack detection, the proposed system achieves high F1-scores of 0.963 and 0.800 on the above two datasets, respectively. The average processing time of each data packet on a vehicle-level machine is less than 0.6 ms, which shows the feasibility of implementing the proposed system in real-time vehicle systems. This emphasizes the effectiveness and efficiency of the proposed IDS.