 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Co-evolving Real-Time Strategy Game Micro
Mar 27, 2018
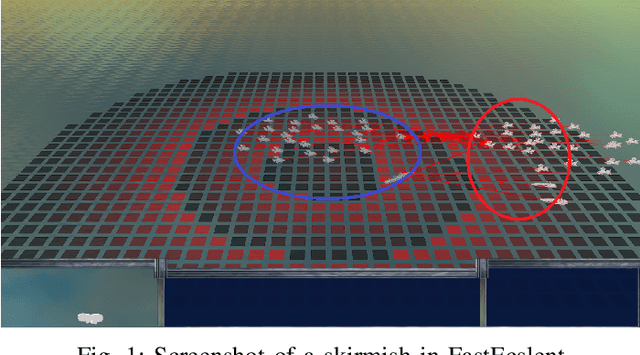
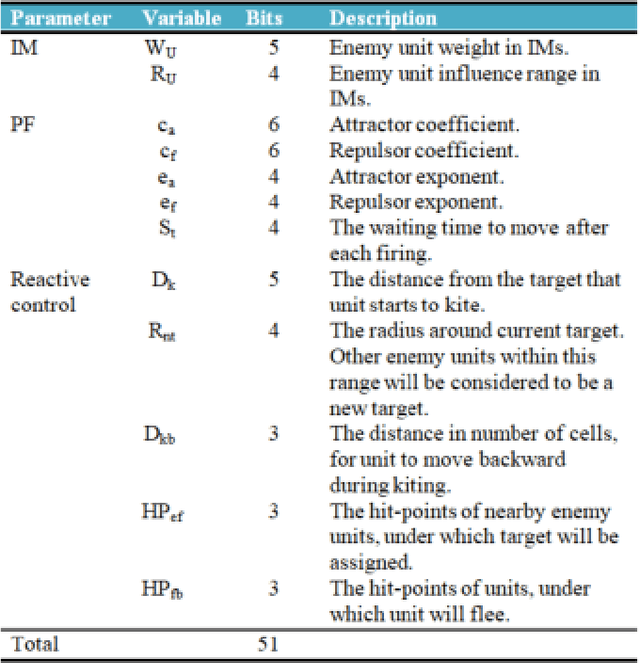
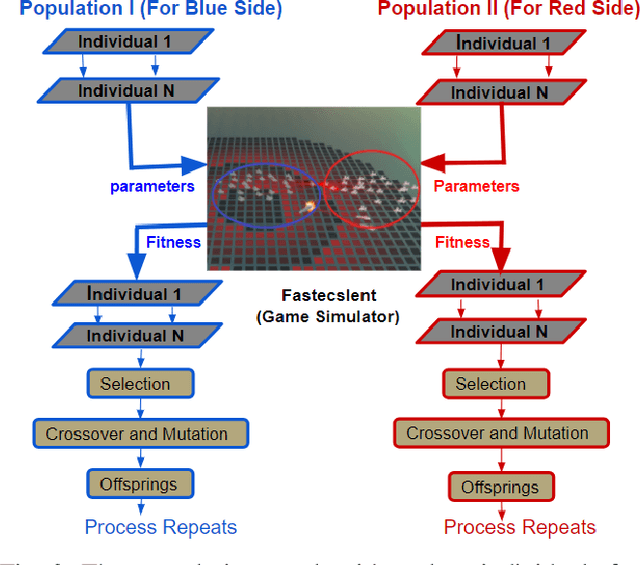
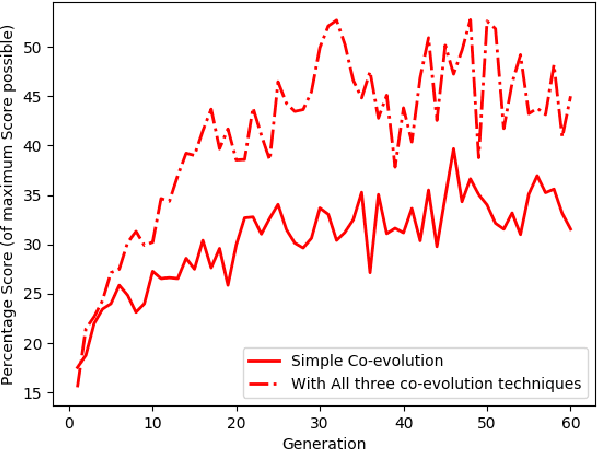
We investigate competitive co-evolution of unit micromanagement in real-time strategy games. Although good long-term macro-strategy and good short-term unit micromanagement both impact real-time strategy games performance, this paper focuses on generating quality micro. Better micro, for example, can help players win skirmishes and battles even when outnumbered. Prior work has shown that we can evolve micro to beat a given opponent. We remove the need for a good opponent to evolve against by using competitive co-evolution to evolve high-quality micro for both sides from scratch. We first co-evolve micro to control a group of ranged units versus a group of melee units. We then move to co-evolve micro for a group of ranged and melee units versus a group of ranged and melee units. Results show that competitive co-evolution produces good quality micro and when combined with the well-known techniques of fitness sharing, shared sampling, and a hall of fame takes less time to produce better quality micro than simple co-evolution. We believe these results indicate the viability of co-evolutionary approaches for generating good unit micro-management.
First Step Towards EXPLAINable DGA Multiclass Classification
Jun 23, 2021
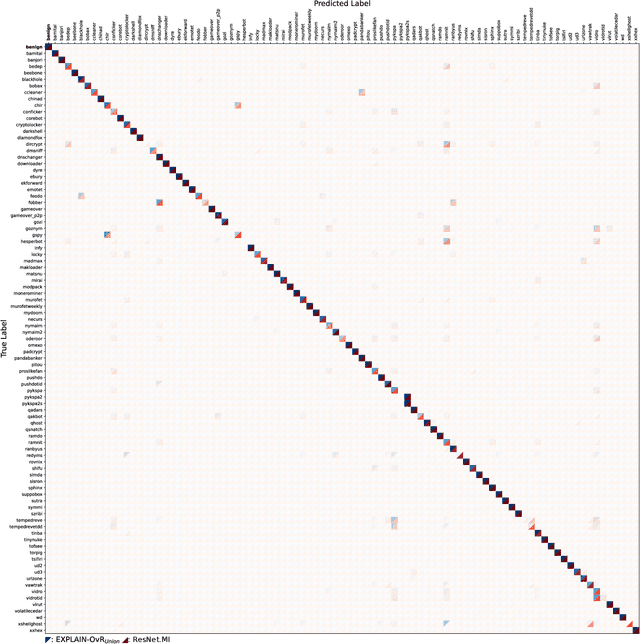
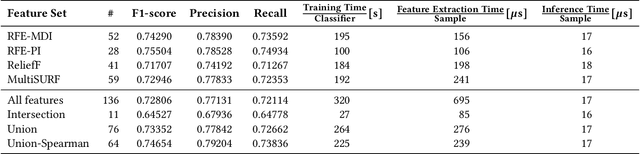
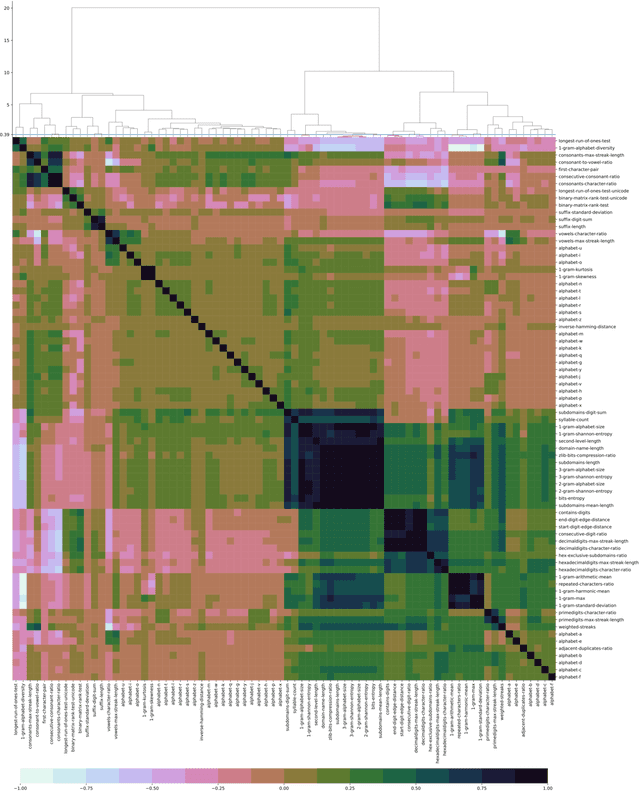
Numerous malware families rely on domain generation algorithms (DGAs) to establish a connection to their command and control (C2) server. Counteracting DGAs, several machine learning classifiers have been proposed enabling the identification of the DGA that generated a specific domain name and thus triggering targeted remediation measures. However, the proposed state-of-the-art classifiers are based on deep learning models. The black box nature of these makes it difficult to evaluate their reasoning. The resulting lack of confidence makes the utilization of such models impracticable. In this paper, we propose EXPLAIN, a feature-based and contextless DGA multiclass classifier. We comparatively evaluate several combinations of feature sets and hyperparameters for our approach against several state-of-the-art classifiers in a unified setting on the same real-world data. Our classifier achieves competitive results, is real-time capable, and its predictions are easier to trace back to features than the predictions made by the DGA multiclass classifiers proposed in related work.
Real-time Memory Efficient Large-pose Face Alignment via Deep Evolutionary Network
Nov 01, 2019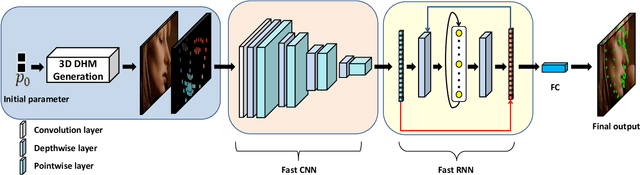
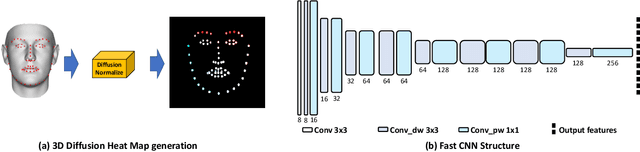
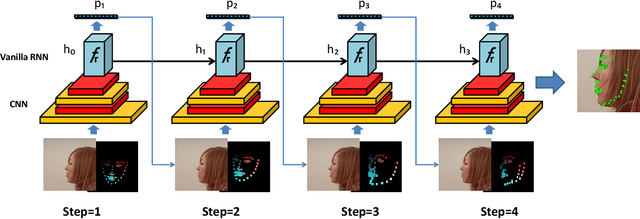
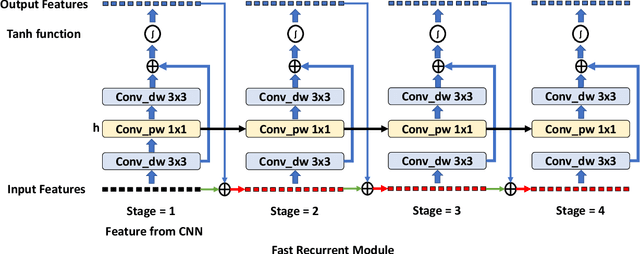
There is an urgent need to apply face alignment in a memory-efficient and real-time manner due to the recent explosion of face recognition applications. However, impact factors such as large pose variation and computational inefficiency, still hinder its broad implementation. To this end, we propose a computationally efficient deep evolutionary model integrated with 3D Diffusion Heap Maps (DHM). First, we introduce a sparse 3D DHM to assist the initial modeling process under extreme pose conditions. Afterward, a simple and effective CNN feature is extracted and fed to Recurrent Neural Network (RNN) for evolutionary learning. To accelerate the model, we propose an efficient network structure to accelerate the evolutionary learning process through a factorization strategy. Extensive experiments on three popular alignment databases demonstrate the advantage of the proposed models over the state-of-the-art, especially under large-pose conditions. Notably, the computational speed of our model is 6 times faster than the state-of-the-art on CPU and 14 times on GPU. We also discuss and analyze the limitations of our models and future research work.
Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Jul 08, 2021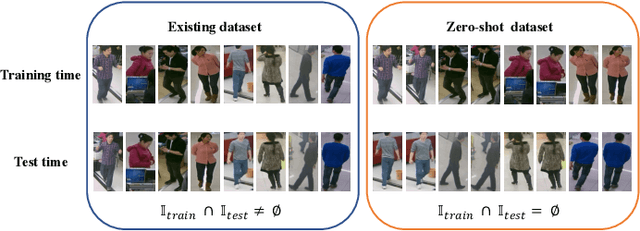


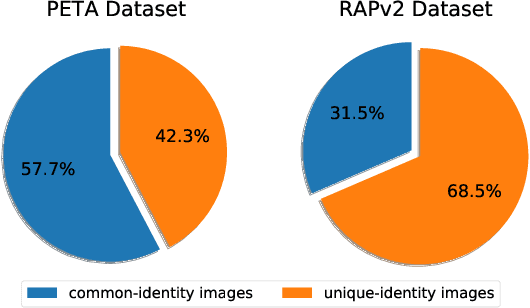
Pedestrian attribute recognition aims to assign multiple attributes to one pedestrian image captured by a video surveillance camera. Although numerous methods are proposed and make tremendous progress, we argue that it is time to step back and analyze the status quo of the area. We review and rethink the recent progress from three perspectives. First, given that there is no explicit and complete definition of pedestrian attribute recognition, we formally define and distinguish pedestrian attribute recognition from other similar tasks. Second, based on the proposed definition, we expose the limitations of the existing datasets, which violate the academic norm and are inconsistent with the essential requirement of practical industry application. Thus, we propose two datasets, PETA\textsubscript{$ZS$} and RAP\textsubscript{$ZS$}, constructed following the zero-shot settings on pedestrian identity. In addition, we also introduce several realistic criteria for future pedestrian attribute dataset construction. Finally, we reimplement existing state-of-the-art methods and introduce a strong baseline method to give reliable evaluations and fair comparisons. Experiments are conducted on four existing datasets and two proposed datasets to measure progress on pedestrian attribute recognition.
Behavior Mimics Distribution: Combining Individual and Group Behaviors for Federated Learning
Jun 23, 2021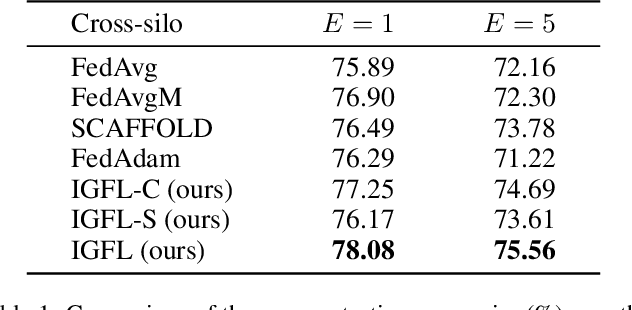
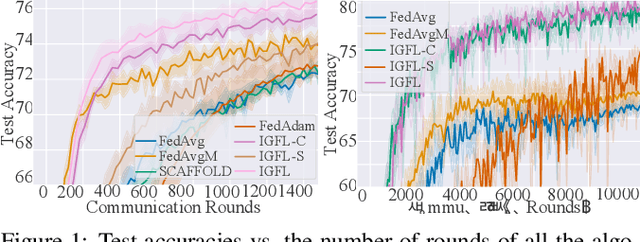
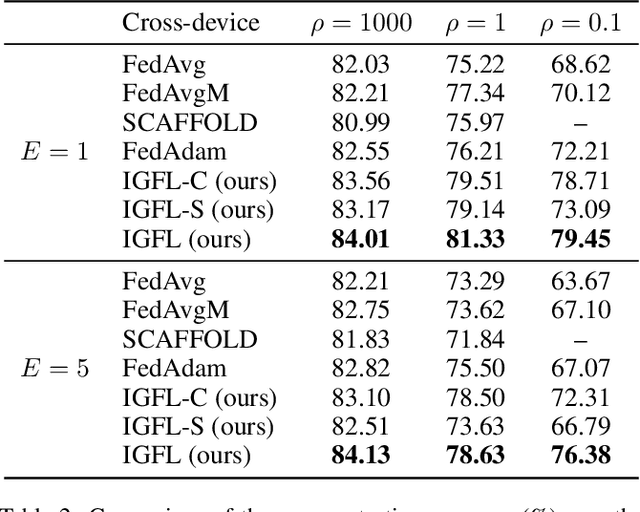
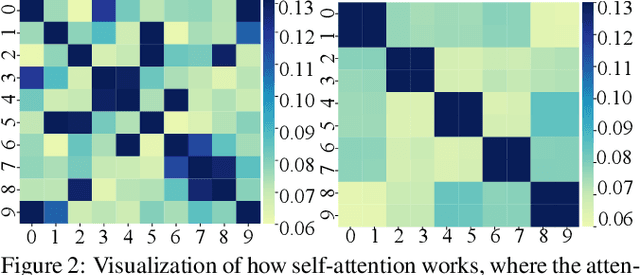
Federated Learning (FL) has become an active and promising distributed machine learning paradigm. As a result of statistical heterogeneity, recent studies clearly show that the performance of popular FL methods (e.g., FedAvg) deteriorates dramatically due to the client drift caused by local updates. This paper proposes a novel Federated Learning algorithm (called IGFL), which leverages both Individual and Group behaviors to mimic distribution, thereby improving the ability to deal with heterogeneity. Unlike existing FL methods, our IGFL can be applied to both client and server optimization. As a by-product, we propose a new attention-based federated learning in the server optimization of IGFL. To the best of our knowledge, this is the first time to incorporate attention mechanisms into federated optimization. We conduct extensive experiments and show that IGFL can significantly improve the performance of existing federated learning methods. Especially when the distributions of data among individuals are diverse, IGFL can improve the classification accuracy by about 13% compared with prior baselines.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021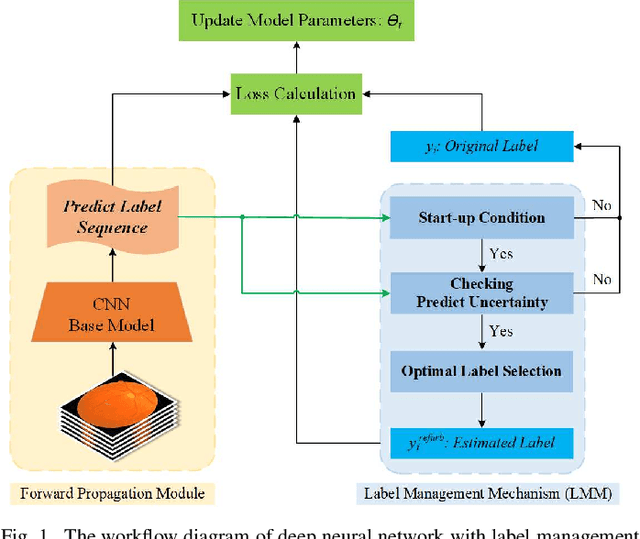
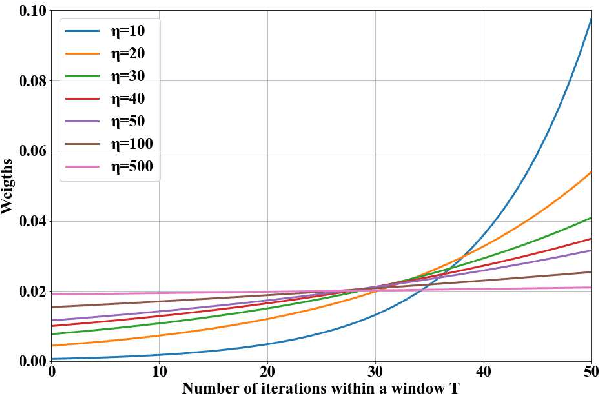
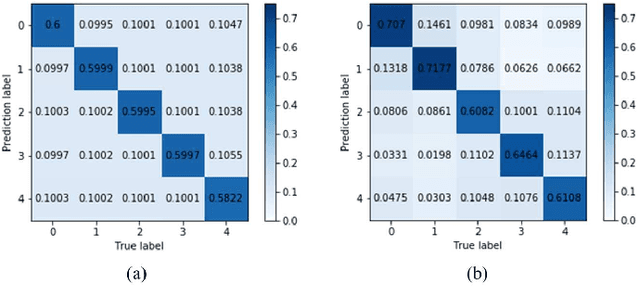
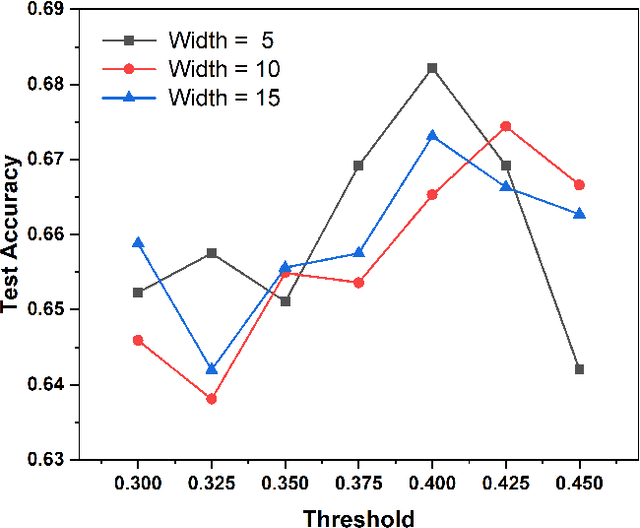
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.
Numerical influence of ReLU'(0) on backpropagation
Jun 23, 2021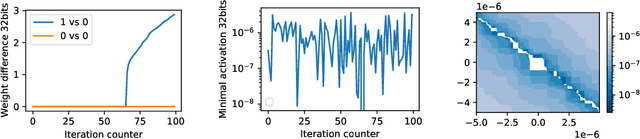
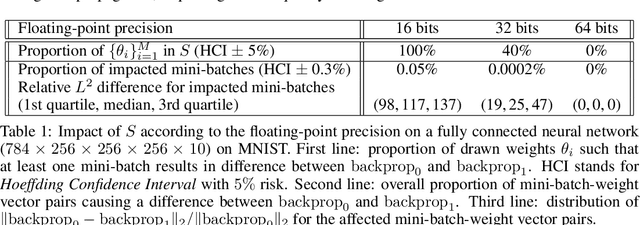
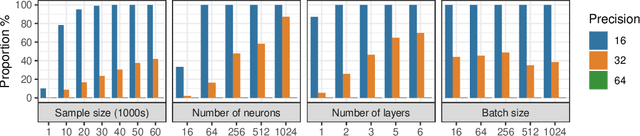
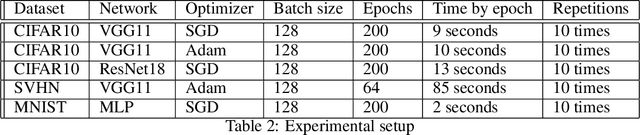
In theory, the choice of ReLU (0) in [0, 1] for a neural network has a negligible influence both on backpropagation and training. Yet, in the real world, 32 bits default precision combined with the size of deep learning problems makes it a hyperparameter of training methods. We investigate the importance of the value of ReLU (0) for several precision levels (16, 32, 64 bits), on various networks (fully connected, VGG, ResNet) and datasets (MNIST, CIFAR10, SVHN). We observe considerable variations of backpropagation outputs which occur around half of the time in 32 bits precision. The effect disappears with double precision, while it is systematic at 16 bits. For vanilla SGD training, the choice ReLU (0) = 0 seems to be the most efficient. We also evidence that reconditioning approaches as batch-norm or ADAM tend to buffer the influence of ReLU (0)'s value. Overall, the message we want to convey is that algorithmic differentiation of nonsmooth problems potentially hides parameters that could be tuned advantageously.
On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models
Jul 31, 2021High-quality labeled datasets play a crucial role in fueling the development of machine learning (ML), and in particular the development of deep learning (DL). However, since the emergence of the ImageNet dataset and the AlexNet model in 2012, the size of new open-source labeled vision datasets has remained roughly constant. Consequently, only a minority of publications in the computer vision community tackle supervised learning on datasets that are orders of magnitude larger than Imagenet. In this paper, we survey computer vision research domains that study the effects of such large datasets on model performance across different vision tasks. We summarize the community's current understanding of those effects, and highlight some open questions related to training with massive datasets. In particular, we tackle: (a) The largest datasets currently used in computer vision research and the interesting takeaways from training on such datasets; (b) The effectiveness of pre-training on large datasets; (c) Recent advancements and hurdles facing synthetic datasets; (d) An overview of double descent and sample non-monotonicity phenomena; and finally, (e) A brief discussion of lifelong/continual learning and how it fares compared to learning from huge labeled datasets in an offline setting. Overall, our findings are that research on optimization for deep learning focuses on perfecting the training routine and thus making DL models less data hungry, while research on synthetic datasets aims to offset the cost of data labeling. However, for the time being, acquiring non-synthetic labeled data remains indispensable to boost performance.
TEACHTEXT: CrossModal Generalized Distillation for Text-Video Retrieval
Apr 16, 2021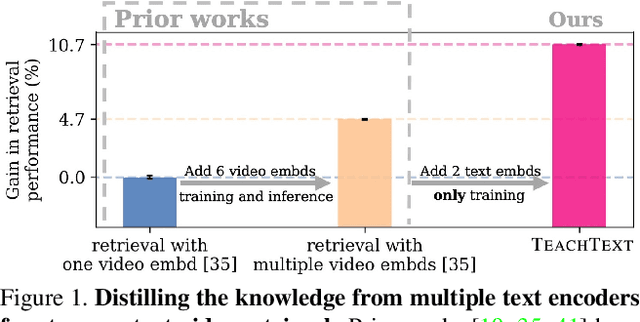

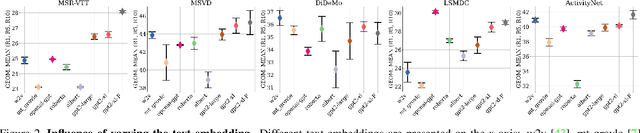
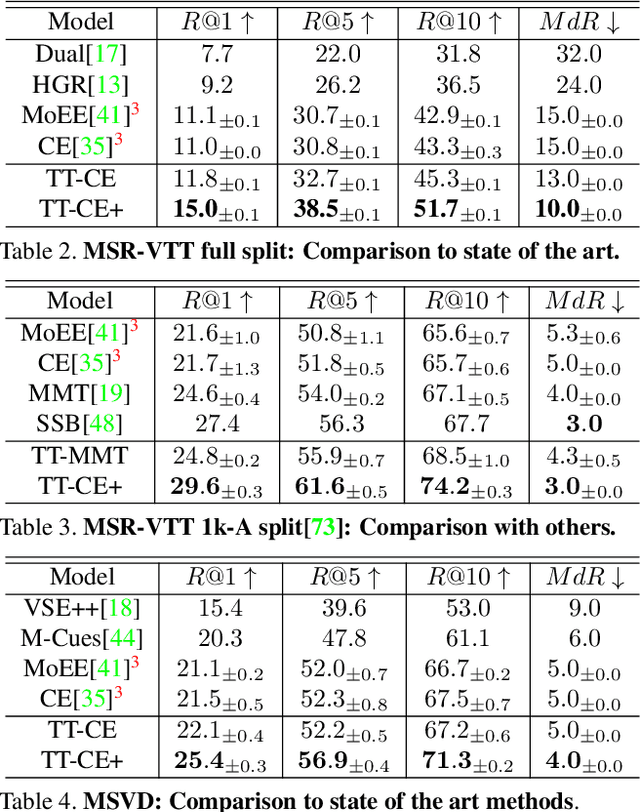
In recent years, considerable progress on the task of text-video retrieval has been achieved by leveraging large-scale pretraining on visual and audio datasets to construct powerful video encoders. By contrast, despite the natural symmetry, the design of effective algorithms for exploiting large-scale language pretraining remains under-explored. In this work, we are the first to investigate the design of such algorithms and propose a novel generalized distillation method, TeachText, which leverages complementary cues from multiple text encoders to provide an enhanced supervisory signal to the retrieval model. Moreover, we extend our method to video side modalities and show that we can effectively reduce the number of used modalities at test time without compromising performance. Our approach advances the state of the art on several video retrieval benchmarks by a significant margin and adds no computational overhead at test time. Last but not least, we show an effective application of our method for eliminating noise from retrieval datasets. Code and data can be found at https://www.robots.ox.ac.uk/~vgg/research/teachtext/.
Distance-based Hyperspherical Classification for Multi-source Open-Set Domain Adaptation
Jul 14, 2021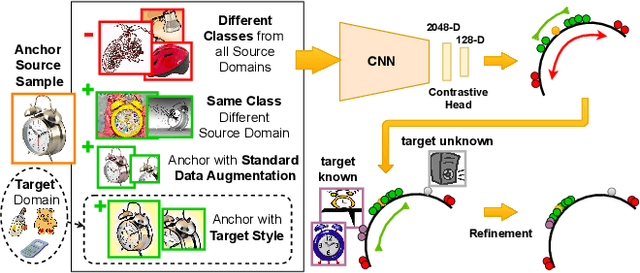
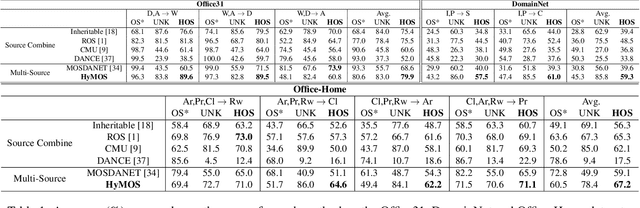
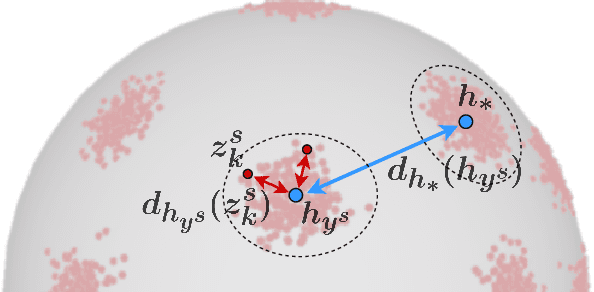
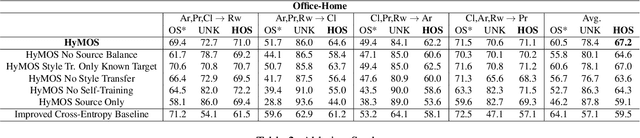
Vision systems trained in closed-world scenarios will inevitably fail when presented with new environmental conditions, new data distributions and novel classes at deployment time. How to move towards open-world learning is a long standing research question, but the existing solutions mainly focus on specific aspects of the problem (single domain Open-Set, multi-domain Closed-Set), or propose complex strategies which combine multiple losses and manually tuned hyperparameters. In this work we tackle multi-source Open-Set domain adaptation by introducing HyMOS: a straightforward supervised model that exploits the power of contrastive learning and the properties of its hyperspherical feature space to correctly predict known labels on the target, while rejecting samples belonging to any unknown class. HyMOS includes a tailored data balancing to enforce cross-source alignment and introduces style transfer among the instance transformations of contrastive learning for source-target adaptation, avoiding the risk of negative transfer. Finally a self-training strategy refines the model without the need for handcrafted thresholds. We validate our method over three challenging datasets and provide an extensive quantitative and qualitative experimental analysis. The obtained results show that HyMOS outperforms several Open-Set and universal domain adaptation approaches, defining the new state-of-the-art.