 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resilience of Autonomous Vehicle Object Category Detection to Universal Adversarial Perturbations
Jul 10, 2021


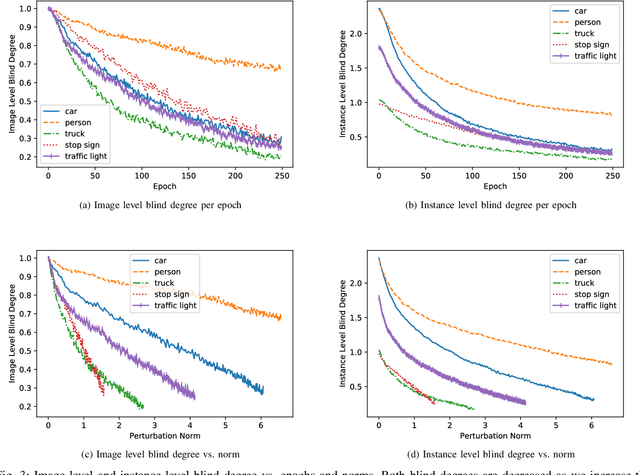
Due to the vulnerability of deep neural networks to adversarial examples, numerous works on adversarial attacks and defenses have been burgeoning over the past several years. However, there seem to be some conventional views regarding adversarial attacks and object detection approaches that most researchers take for granted. In this work, we bring a fresh perspective on those procedures by evaluating the impact of universal perturbations on object detection at a class-level. We apply it to a carefully curated data set related to autonomous driving. We use Faster-RCNN object detector on images of five different categories: person, car, truck, stop sign and traffic light from the COCO data set, while carefully perturbing the images using Universal Dense Object Suppression algorithm. Our results indicate that person, car, traffic light, truck and stop sign are resilient in that order (most to least) to universal perturbations. To the best of our knowledge, this is the first time such a ranking has been established which is significant for the security of the data sets pertaining to autonomous vehicles and object detection in general.
Learning Graph Embeddings for Open World Compositional Zero-Shot Learning
May 03, 2021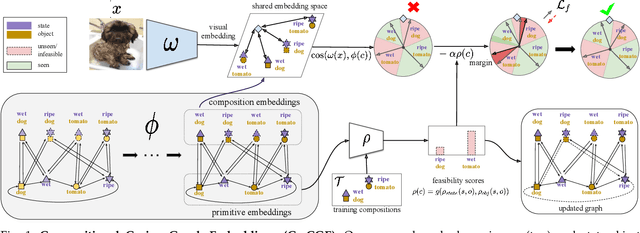
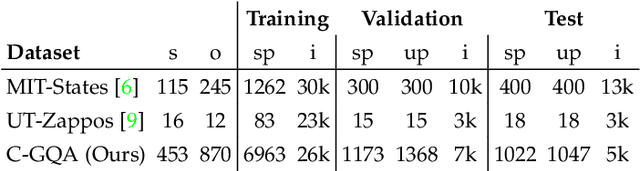
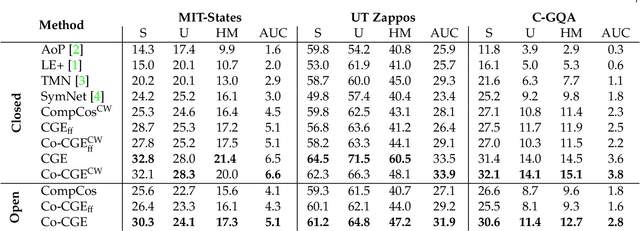

Compositional Zero-Shot learning (CZSL) aims to recognize unseen compositions of state and object visual primitives seen during training. A problem with standard CZSL is the assumption of knowing which unseen compositions will be available at test time. In this work, we overcome this assumption operating on the open world setting, where no limit is imposed on the compositional space at test time, and the search space contains a large number of unseen compositions. To address this problem, we propose a new approach, Compositional Cosine Graph Embeddings (Co-CGE), based on two principles. First, Co-CGE models the dependency between states, objects and their compositions through a graph convolutional neural network. The graph propagates information from seen to unseen concepts, improving their representations. Second, since not all unseen compositions are equally feasible, and less feasible ones may damage the learned representations, Co-CGE estimates a feasibility score for each unseen composition, using the scores as margins in a cosine similarity-based loss and as weights in the adjacency matrix of the graphs. Experiments show that our approach achieves state-of-the-art performances in standard CZSL while outperforming previous methods in the open world scenario.
Explaining Deep Classification of Time-Series Data with Learned Prototypes
Apr 18, 2019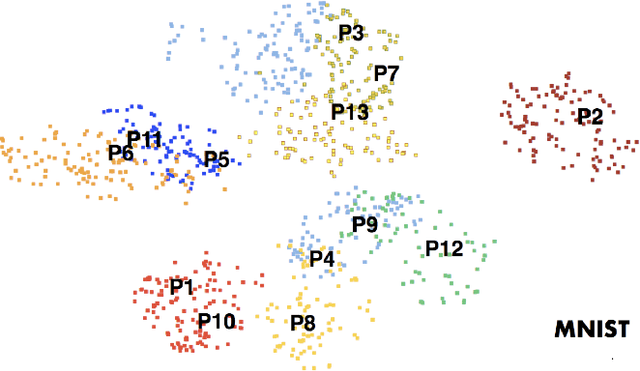

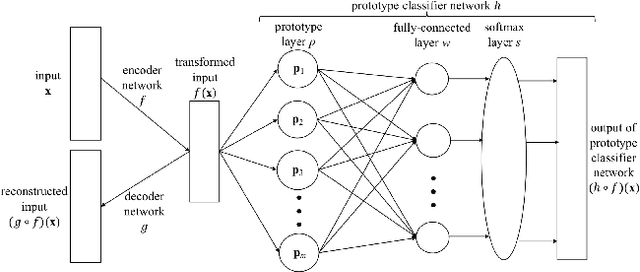
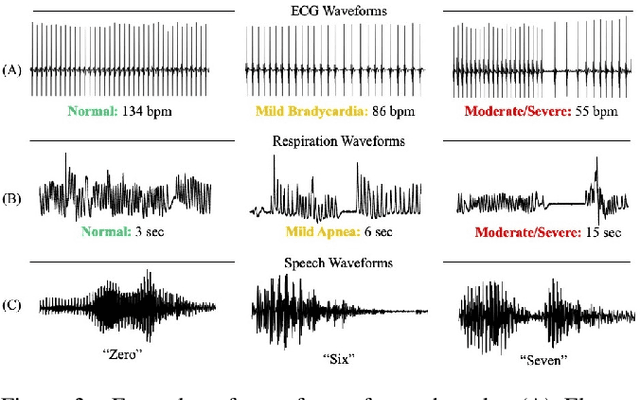
The emergence of deep learning networks raises a need for algorithms to explain their decisions so that users and domain experts can be confident using algorithmic recommendations for high-risk decisions. In this paper we leverage the information-rich latent space induced by such models to learn data representations or prototypes within such networks to elucidate their internal decision-making process. We introduce a novel application of case-based reasoning using prototypes to understand the decisions leading to the classification of time-series data, specifically investigating electrocardiogram (ECG) waveforms for classification of bradycardia, a slowing of heart rate, in infants. We improve upon existing models by explicitly optimizing for increased prototype diversity which in turn improves model accuracy by learning regions of the latent space that highlight features for distinguishing classes. We evaluate the hyperparameter space of our model to show robustness in diversity prototype generation and additionally, explore the resultant latent space of a deep classification network on ECG waveforms via an interactive tool to visualize the learned prototypical waveforms therein. We show that the prototypes are capable of learning real-world features - in our case-study ECG morphology related to bradycardia - as well as features within sub-classes. Our novel work leverages learned prototypical framework on two dimensional time-series data to produce explainable insights during classification tasks.
Time-Aware and View-Aware Video Rendering for Unsupervised Representation Learning
Nov 29, 2018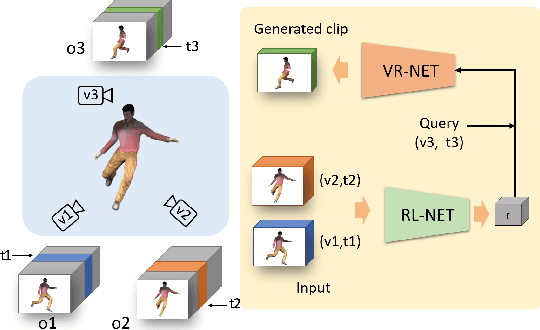

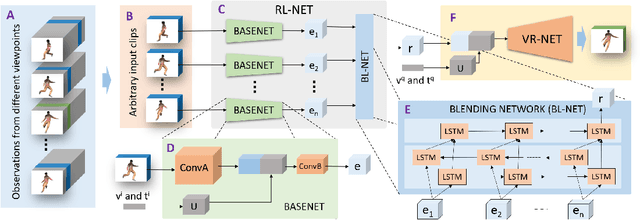
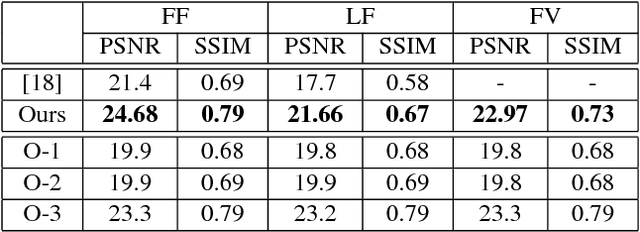
The recent success in deep learning has lead to various effective representation learning methods for videos. However, the current approaches for video representation require large amount of human labeled datasets for effective learning. We present an unsupervised representation learning framework to encode scene dynamics in videos captured from multiple viewpoints. The proposed framework has two main components: Representation Learning Network (RL-NET), which learns a representation with the help of Blending Network (BL-NET), and Video Rendering Network (VR-NET), which is used for video synthesis. The framework takes as input video clips from different viewpoints and time, learns an internal representation and uses this representation to render a video clip from an arbitrary given viewpoint and time. The ability of the proposed network to render video frames from arbitrary viewpoints and time enable it to learn a meaningful and robust representation of the scene dynamics. We demonstrate the effectiveness of the proposed method in rendering view-aware as well as time-aware video clips on two different real-world datasets including UCF-101 and NTU-RGB+D. To further validate the effectiveness of the learned representation, we use it for the task of view-invariant activity classification where we observe a significant improvement (~26%) in the performance on NTU-RGB+D dataset compared to the existing state-of-the art methods.
Real-time image-based instrument classification for laparoscopic surgery
Aug 01, 2018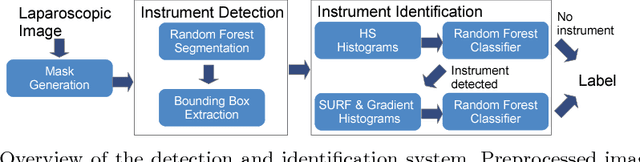
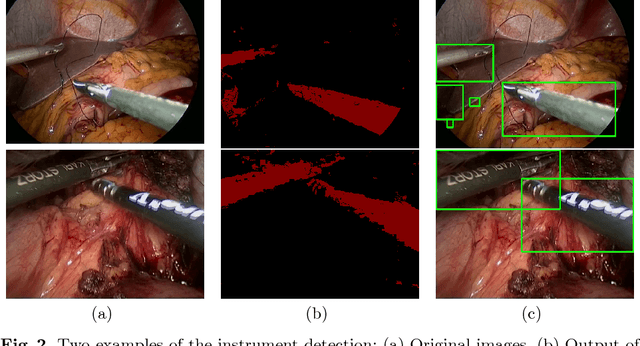


During laparoscopic surgery, context-aware assistance systems aim to alleviate some of the difficulties the surgeon faces. To ensure that the right information is provided at the right time, the current phase of the intervention has to be known. Real-time locating and classification the surgical tools currently in use are key components of both an activity-based phase recognition and assistance generation. In this paper, we present an image-based approach that detects and classifies tools during laparoscopic interventions in real-time. First, potential instrument bounding boxes are detected using a pixel-wise random forest segmentation. Each of these bounding boxes is then classified using a cascade of random forest. For this, multiple features, such as histograms over hue and saturation, gradients and SURF feature, are extracted from each detected bounding box. We evaluated our approach on five different videos from two different types of procedures. We distinguished between the four most common classes of instruments (LigaSure, atraumatic grasper, aspirator, clip applier) and background. Our method succesfully located up to 86% of all instruments respectively. On manually provided bounding boxes, we achieve a instrument type recognition rate of up to 58% and on automatically detected bounding boxes up to 49%. To our knowledge, this is the first approach that allows an image-based classification of surgical tools in a laparoscopic setting in real-time.
* Workshop paper accepted and presented at Modeling and Monitoring of Computer Assisted Interventions (M2CAI) (2015)
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 23, 2021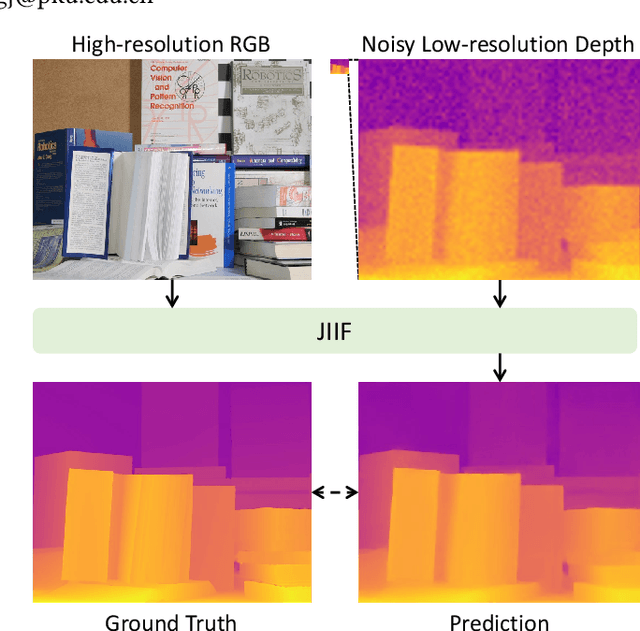
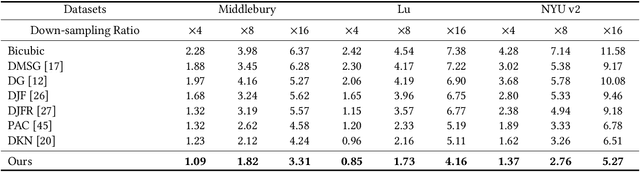
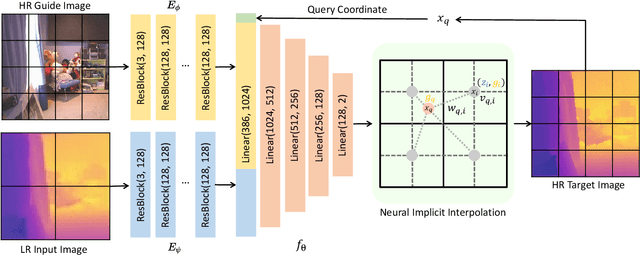
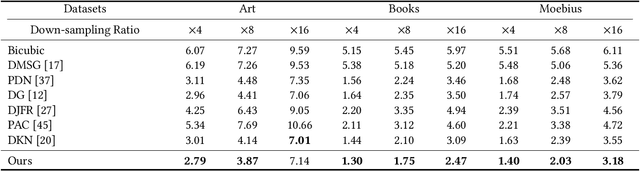
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.
Partially Coherent Radar Unties Range Resolution from Bandwidth Limitations
Jun 28, 2021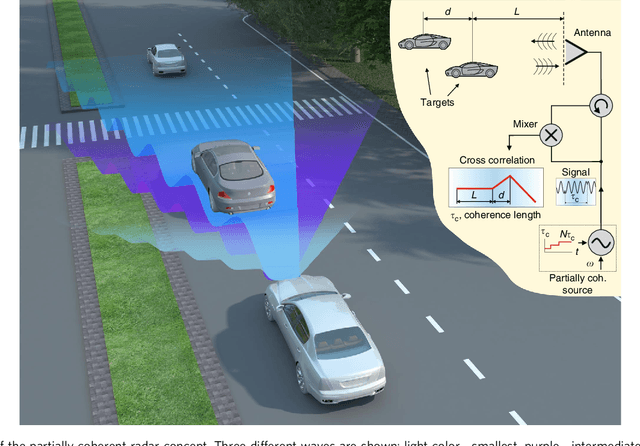
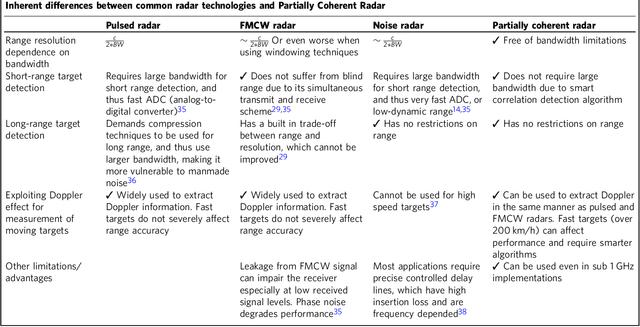
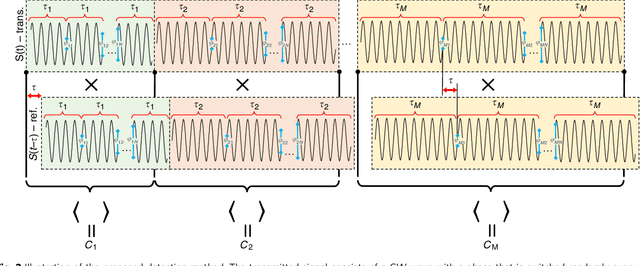
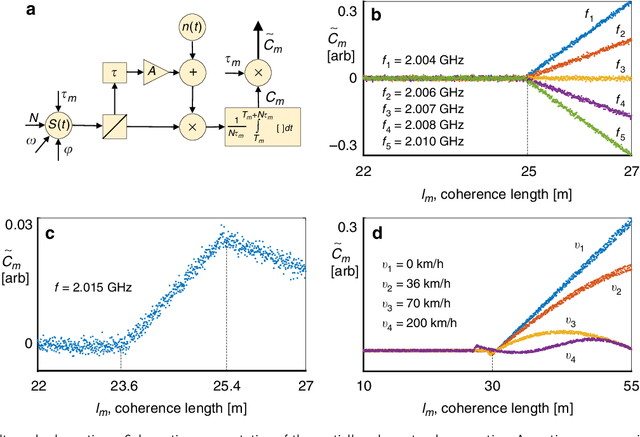
It is widely believed that range resolution, the ability to distinguish between two closely situated targets, depends inversely on the bandwidth of the transmitted radar signal. Here we demonstrate a different type of ranging system, which possesses superior range resolution that is almost completely free of bandwidth limitations. By sweeping over the coherence length of the transmitted signal, the partially coherent radar experimentally demonstrates an improvement of over an order of magnitude in resolving targets, compared to standard coherent radars with the same bandwidth.. A theoretical framework is developed to show that the resolution could be further improved without a bound, revealing a tradeoff between bandwidth and sweep time. This concept offers solutions to problems which require high range resolution and accuracy but available bandwidth is limited, as is the case for the autonomous car industry, optical imaging, and astronomy to name just few.
Resource Constrained Neural Networks for 5G Direction-of-Arrival Estimation in Micro-controllers
Jul 23, 2021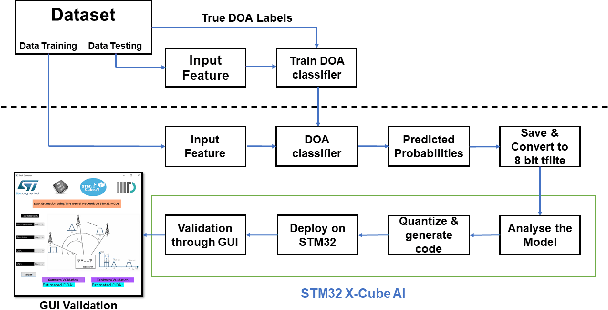
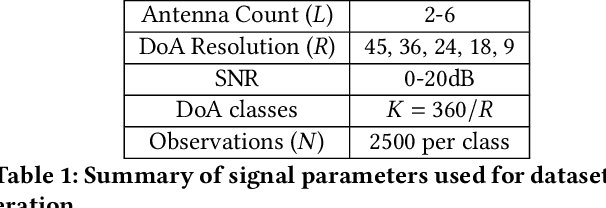
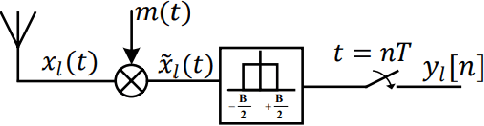
With the introduction of shared spectrum sensing and beam-forming based multi-antenna transceivers, 5G networks demand spectrum sensing to identify opportunities in time, frequency, and spatial domains. Narrow beam-forming makes it difficult to have spatial sensing (direction-of-arrival, DoA, estimation) in a centralized manner, and with the evolution of paradigms such as artificial intelligence of Things (AIOT), ultra-reliable low latency communication (URLLC) services and distributed networks, intelligence for edge devices (Edge-AI) is highly desirable. It helps to reduce the data-communication overhead compared to cloud-AI-centric networks and is more secure and free from scalability limitations. However, achieving desired functional accuracy is a challenge on edge devices such as microcontroller units (MCU) due to area, memory, and power constraints. In this work, we propose low complexity neural network-based algorithm for accurate DoA estimation and its efficient mapping on the off-the-self MCUs. An ad-hoc graphical-user interface (GUI) is developed to configure the STM32 NUCLEO-H743ZI2 MCU with the proposed algorithm and to validate its functionality. The performance of the proposed algorithm is analyzed for different signal-to-noise ratios (SNR), word-length, the number of antennas, and DoA resolution. In-depth experimental results show that it outperforms the conventional statistical spatial sensing approach.
LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos
Jul 02, 2021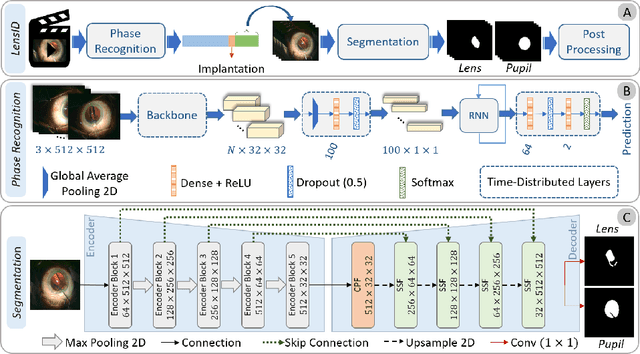
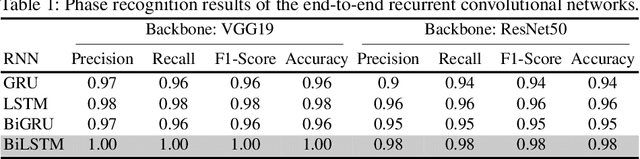
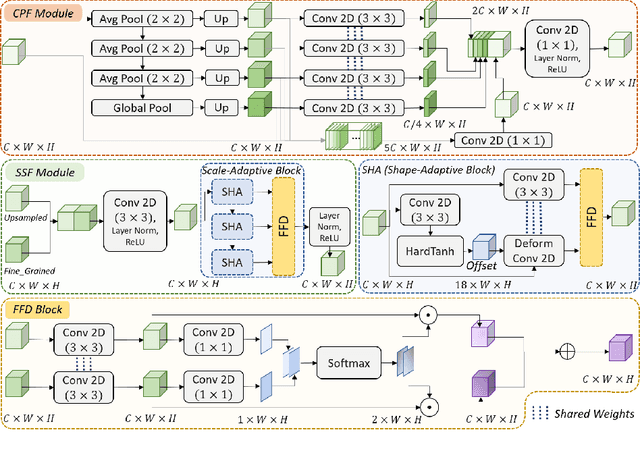
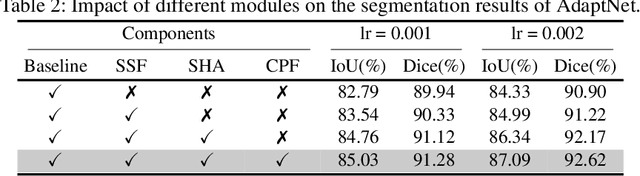
A critical complication after cataract surgery is the dislocation of the lens implant leading to vision deterioration and eye trauma. In order to reduce the risk of this complication, it is vital to discover the risk factors during the surgery. However, studying the relationship between lens dislocation and its suspicious risk factors using numerous videos is a time-extensive procedure. Hence, the surgeons demand an automatic approach to enable a larger-scale and, accordingly, more reliable study. In this paper, we propose a novel framework as the major step towards lens irregularity detection. In particular, we propose (I) an end-to-end recurrent neural network to recognize the lens-implantation phase and (II) a novel semantic segmentation network to segment the lens and pupil after the implantation phase. The phase recognition results reveal the effectiveness of the proposed surgical phase recognition approach. Moreover, the segmentation results confirm the proposed segmentation network's effectiveness compared to state-of-the-art rival approaches.
Transformer-Based Behavioral Representation Learning Enables Transfer Learning for Mobile Sensing in Small Datasets
Jul 09, 2021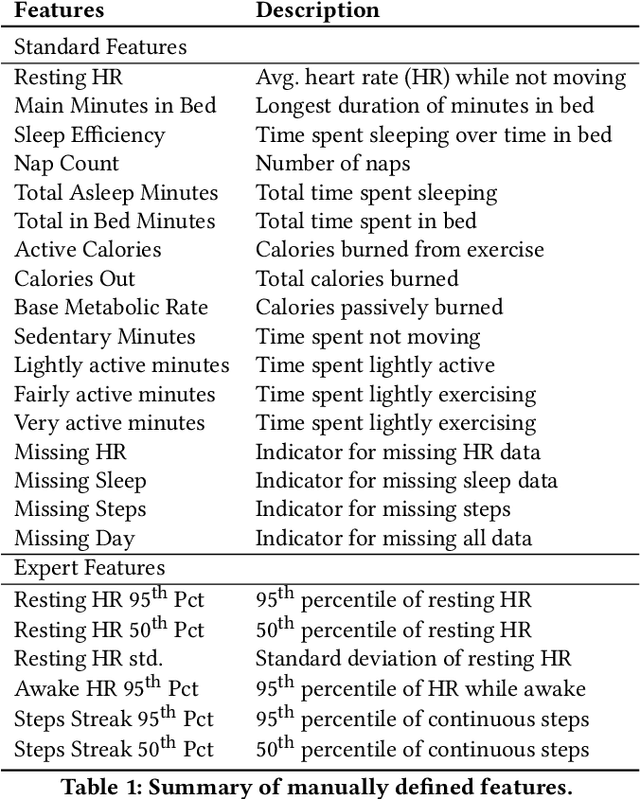

While deep learning has revolutionized research and applications in NLP and computer vision, this has not yet been the case for behavioral modeling and behavioral health applications. This is because the domain's datasets are smaller, have heterogeneous datatypes, and typically exhibit a large degree of missingness. Therefore, off-the-shelf deep learning models require significant, often prohibitive, adaptation. Accordingly, many research applications still rely on manually coded features with boosted tree models, sometimes with task-specific features handcrafted by experts. Here, we address these challenges by providing a neural architecture framework for mobile sensing data that can learn generalizable feature representations from time series and demonstrates the feasibility of transfer learning on small data domains through finetuning. This architecture combines benefits from CNN and Trans-former architectures to (1) enable better prediction performance by learning directly from raw minute-level sensor data without the need for handcrafted features by up to 0.33 ROC AUC, and (2) use pretraining to outperform simpler neural models and boosted decision trees with data from as few a dozen participants.