 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Boosting the Convergence of Reinforcement Learning-based Auto-pruning Using Historical Data
Jul 16, 2021
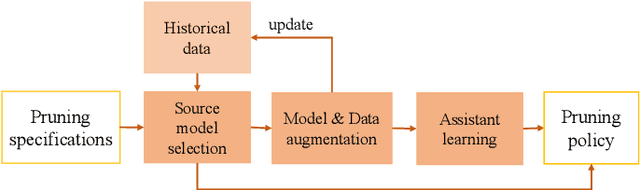
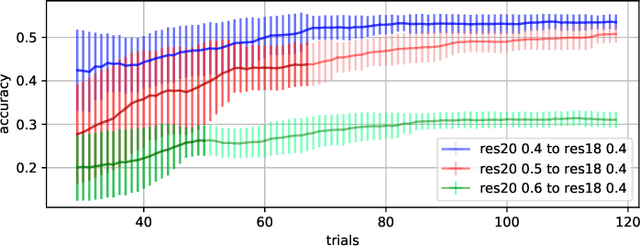
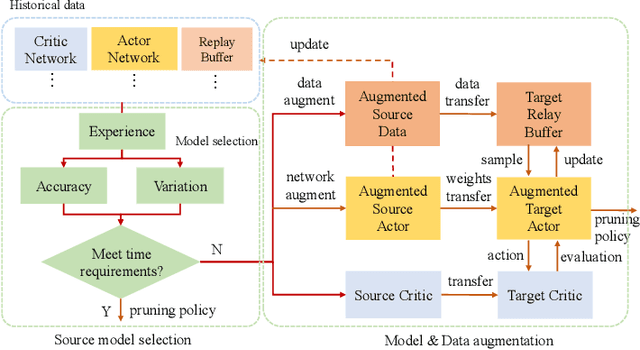
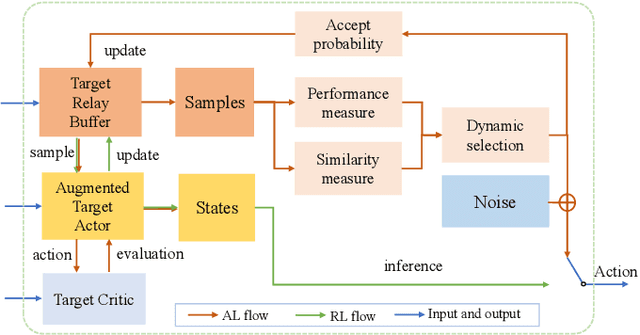
Recently, neural network compression schemes like channel pruning have been widely used to reduce the model size and computational complexity of deep neural network (DNN) for applications in power-constrained scenarios such as embedded systems. Reinforcement learning (RL)-based auto-pruning has been further proposed to automate the DNN pruning process to avoid expensive hand-crafted work. However, the RL-based pruner involves a time-consuming training process and the high expense of each sample further exacerbates this problem. These impediments have greatly restricted the real-world application of RL-based auto-pruning. Thus, in this paper, we propose an efficient auto-pruning framework which solves this problem by taking advantage of the historical data from the previous auto-pruning process. In our framework, we first boost the convergence of the RL-pruner by transfer learning. Then, an augmented transfer learning scheme is proposed to further speed up the training process by improving the transferability. Finally, an assistant learning process is proposed to improve the sample efficiency of the RL agent. The experiments have shown that our framework can accelerate the auto-pruning process by 1.5-2.5 times for ResNet20, and 1.81-2.375 times for other neural networks like ResNet56, ResNet18, and MobileNet v1.
Finding Failures in High-Fidelity Simulation using Adaptive Stress Testing and the Backward Algorithm
Jul 27, 2021
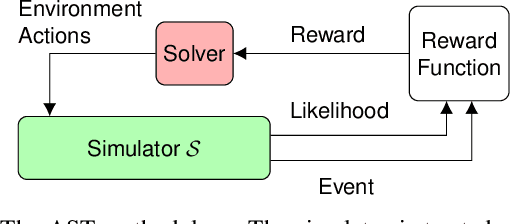

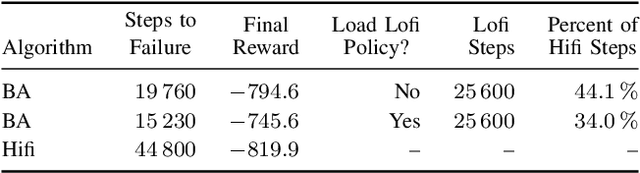
Validating the safety of autonomous systems generally requires the use of high-fidelity simulators that adequately capture the variability of real-world scenarios. However, it is generally not feasible to exhaustively search the space of simulation scenarios for failures. Adaptive stress testing (AST) is a method that uses reinforcement learning to find the most likely failure of a system. AST with a deep reinforcement learning solver has been shown to be effective in finding failures across a range of different systems. This approach generally involves running many simulations, which can be very expensive when using a high-fidelity simulator. To improve efficiency, we present a method that first finds failures in a low-fidelity simulator. It then uses the backward algorithm, which trains a deep neural network policy using a single expert demonstration, to adapt the low-fidelity failures to high-fidelity. We have created a series of autonomous vehicle validation case studies that represent some of the ways low-fidelity and high-fidelity simulators can differ, such as time discretization. We demonstrate in a variety of case studies that this new AST approach is able to find failures with significantly fewer high-fidelity simulation steps than are needed when just running AST directly in high-fidelity. As a proof of concept, we also demonstrate AST on NVIDIA's DriveSim simulator, an industry state-of-the-art high-fidelity simulator for finding failures in autonomous vehicles.
Accelerating Kinodynamic RRT* Through Dimensionality Reduction
Jul 02, 2021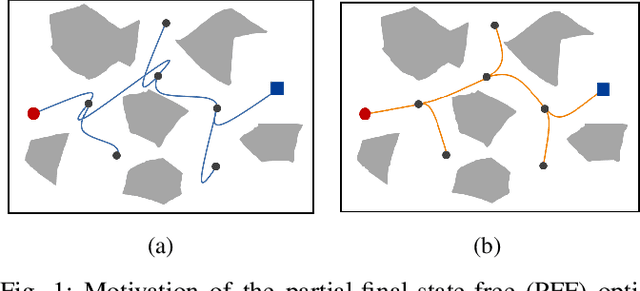
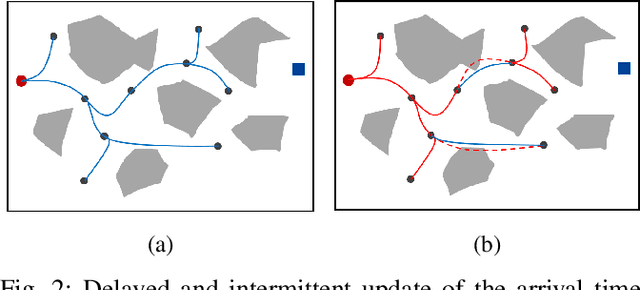


Sampling-based motion planning algorithms such as RRT* are well-known for their ability to quickly find an initial solution and then converge to the optimal solution asymptotically. However, the convergence rate can be slow for highdimensional planning problems, particularly for dynamical systems where the sampling space is not just the configuration space but the full state space. In this paper, we introduce the idea of using a partial-final-state-free (PFF) optimal controller in kinodynamic RRT* [1] to reduce the dimensionality of the sampling space. Instead of sampling the full state space, the proposed accelerated kinodynamic RRT*, called Kino-RRT*, only samples part of the state space, while the rest of the states are selected by the PFF optimal controller. We also propose a delayed and intermittent update of the optimal arrival time of all the edges in the RRT* tree to decrease the computation complexity of the algorithm. We tested the proposed algorithm using 4-D and 10-D state-space linear systems and showed that Kino-RRT* converges much faster than the kinodynamic RRT* algorithm.
DRAS-CQSim: A Reinforcement Learning based Framework for HPC Cluster Scheduling
May 16, 2021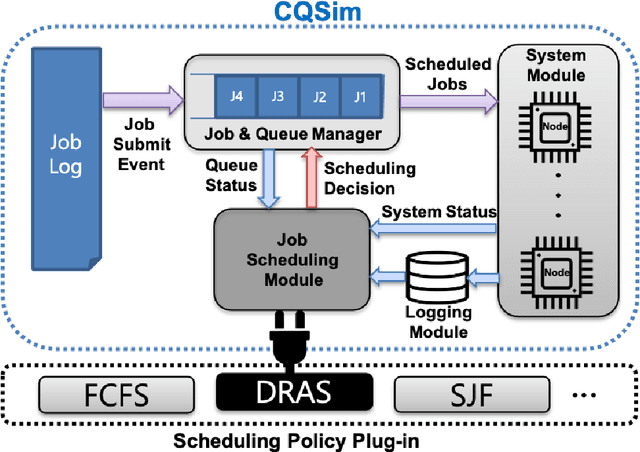

For decades, system administrators have been striving to design and tune cluster scheduling policies to improve the performance of high performance computing (HPC) systems. However, the increasingly complex HPC systems combined with highly diverse workloads make such manual process challenging, time-consuming, and error-prone. We present a reinforcement learning based HPC scheduling framework named DRAS-CQSim to automatically learn optimal scheduling policy. DRAS-CQSim encapsulates simulation environments, agents, hyperparameter tuning options, and different reinforcement learning algorithms, which allows the system administrators to quickly obtain customized scheduling policies.
Approximate FPGA-based LSTMs under Computation Time Constraints
Jan 07, 2018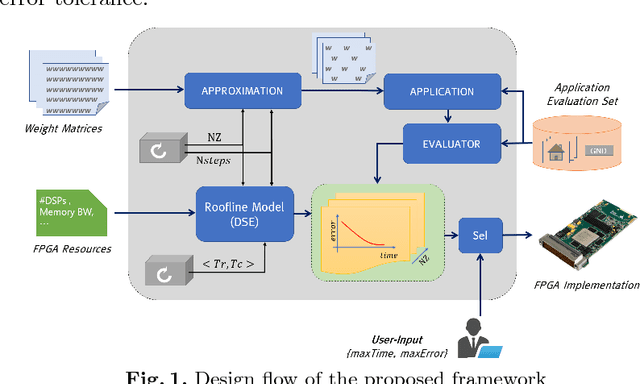
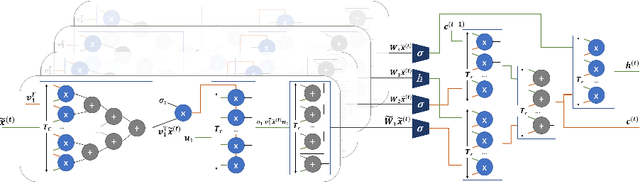
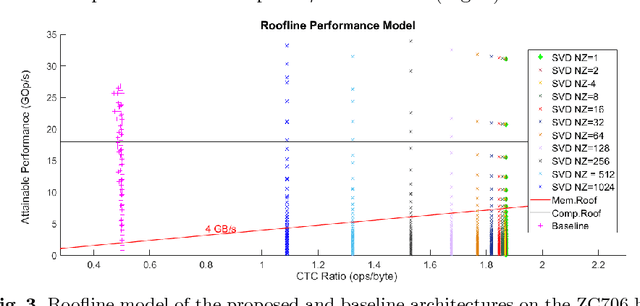
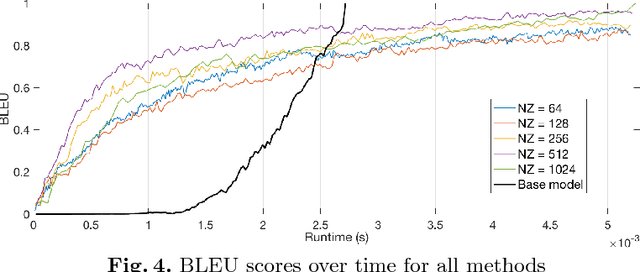
Recurrent Neural Networks and in particular Long Short-Term Memory (LSTM) networks have demonstrated state-of-the-art accuracy in several emerging Artificial Intelligence tasks. However, the models are becoming increasingly demanding in terms of computational and memory load. Emerging latency-sensitive applications including mobile robots and autonomous vehicles often operate under stringent computation time constraints. In this paper, we address the challenge of deploying computationally demanding LSTMs at a constrained time budget by introducing an approximate computing scheme that combines iterative low-rank compression and pruning, along with a novel FPGA-based LSTM architecture. Combined in an end-to-end framework, the approximation method's parameters are optimised and the architecture is configured to address the problem of high-performance LSTM execution in time-constrained applications. Quantitative evaluation on a real-life image captioning application indicates that the proposed methods required up to 6.5x less time to achieve the same application-level accuracy compared to a baseline method, while achieving an average of 25x higher accuracy under the same computation time constraints.
Learning-based real-time method to looking through scattering medium beyond the memory effect
Nov 04, 2019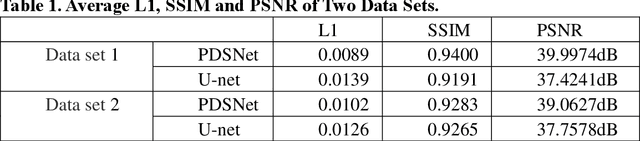


Strong scattering medium brings great difficulties to optical imaging, which is also a problem in medical imaging and many other fields. Optical memory effect makes it possible to image through strong random scattering medium. However, this method also has the limitation of limited angle field-of-view (FOV), which prevents it from being applied in practice. In this paper, a kind of practical convolutional neural network called PDSNet is proposed, which effectively breaks through the limitation of optical memory effect on FOV. Experiments is conducted to prove that the scattered pattern can be reconstructed accurately in real-time by PDSNet, and it is widely applicable to retrieve complex objects of random scales and different scattering media.
Banker Online Mirror Descent
Jun 16, 2021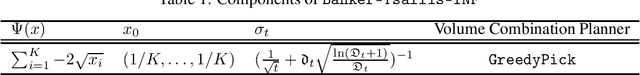
We propose Banker-OMD, a novel framework generalizing the classical Online Mirror Descent (OMD) technique in online learning algorithm design. Banker-OMD allows algorithms to robustly handle delayed feedback, and offers a general methodology for achieving $\tilde{O}(\sqrt{T} + \sqrt{D})$-style regret bounds in various delayed-feedback online learning tasks, where $T$ is the time horizon length and $D$ is the total feedback delay. We demonstrate the power of Banker-OMD with applications to three important bandit scenarios with delayed feedback, including delayed adversarial Multi-armed bandits (MAB), delayed adversarial linear bandits, and a novel delayed best-of-both-worlds MAB setting. Banker-OMD achieves nearly-optimal performance in all the three settings. In particular, it leads to the first delayed adversarial linear bandit algorithm achieving $\tilde{O}(\text{poly}(n)(\sqrt{T} + \sqrt{D}))$ regret.
Road Roughness Estimation Using Machine Learning
Jul 02, 2021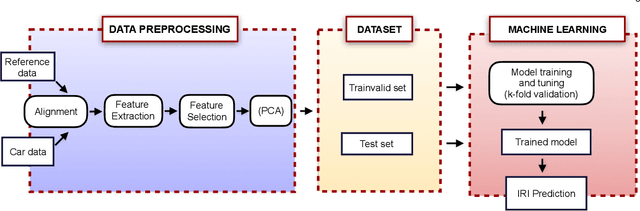

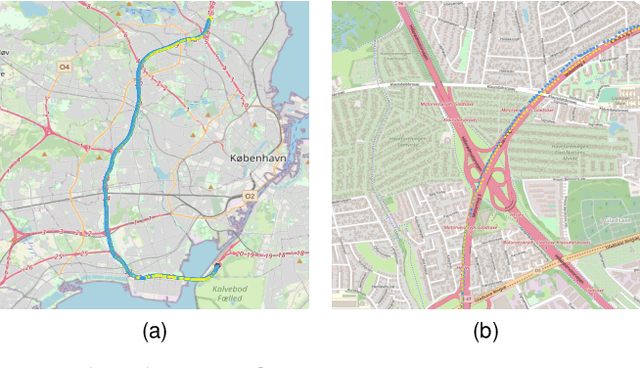
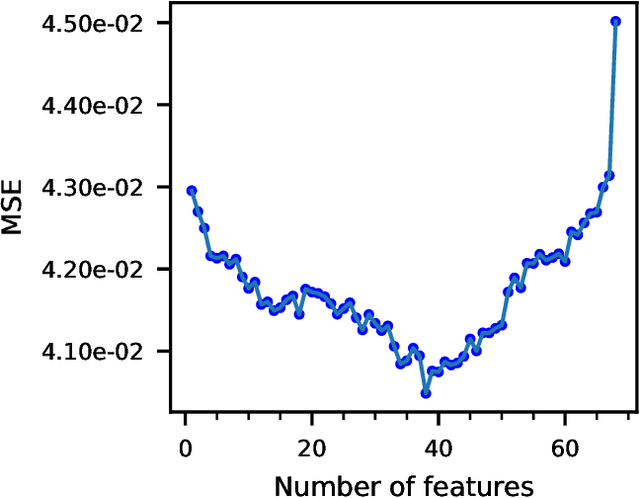
Road roughness is a very important road condition for the infrastructure, as the roughness affects both the safety and ride comfort of passengers. The roads deteriorate over time which means the road roughness must be continuously monitored in order to have an accurate understand of the condition of the road infrastructure. In this paper, we propose a machine learning pipeline for road roughness prediction using the vertical acceleration of the car and the car speed. We compared well-known supervised machine learning models such as linear regression, naive Bayes, k-nearest neighbor, random forest, support vector machine, and the multi-layer perceptron neural network. The models are trained on an optimally selected set of features computed in the temporal and statistical domain. The results demonstrate that machine learning methods can accurately predict road roughness, using the recordings of the cost approachable in-vehicle sensors installed in conventional passenger cars. Our findings demonstrate that the technology is well suited to meet future pavement condition monitoring, by enabling continuous monitoring of a wide road network.
An Algorithm for Stochastic and Adversarial Bandits with Switching Costs
Feb 19, 2021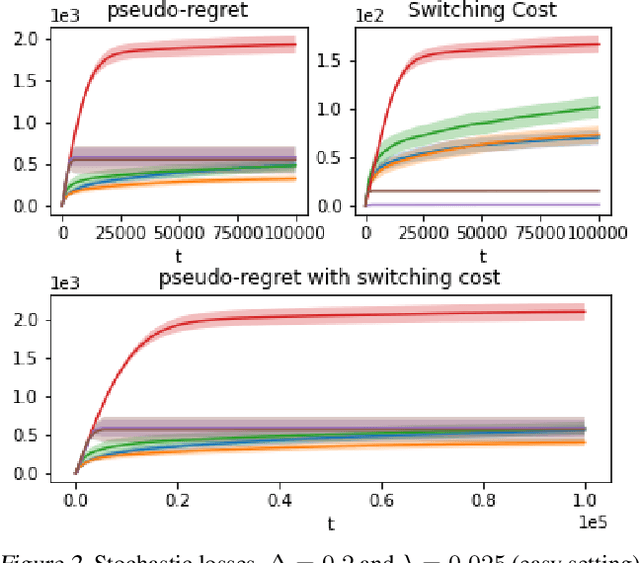
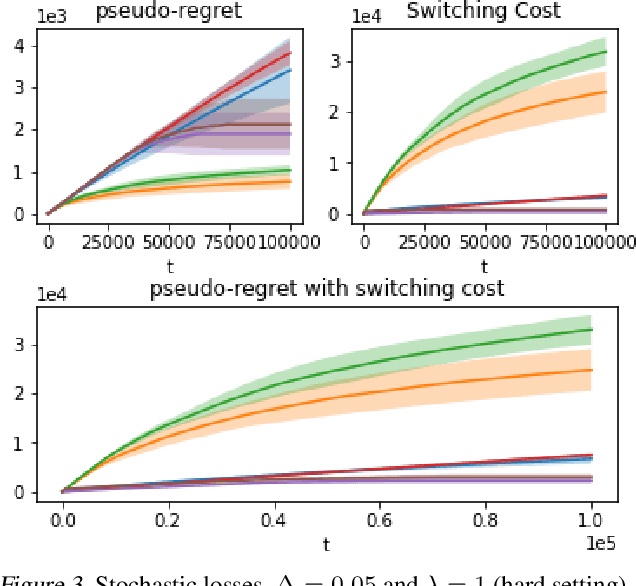
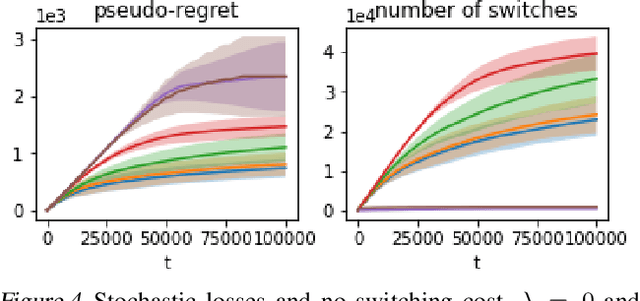
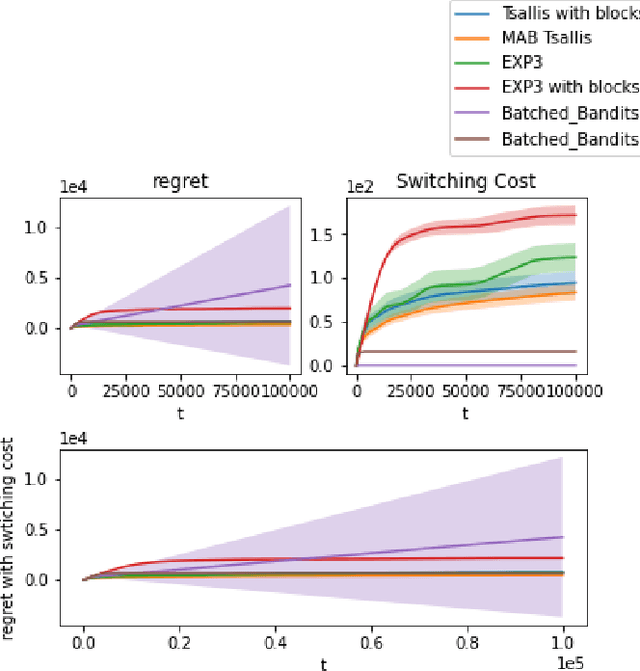
We propose an algorithm for stochastic and adversarial multiarmed bandits with switching costs, where the algorithm pays a price $\lambda$ every time it switches the arm being played. Our algorithm is based on adaptation of the Tsallis-INF algorithm of Zimmert and Seldin (2021) and requires no prior knowledge of the regime or time horizon. In the oblivious adversarial setting it achieves the minimax optimal regret bound of $O\big((\lambda K)^{1/3}T^{2/3} + \sqrt{KT}\big)$, where $T$ is the time horizon and $K$ is the number of arms. In the stochastically constrained adversarial regime, which includes the stochastic regime as a special case, it achieves a regret bound of $O\left(\big((\lambda K)^{2/3} T^{1/3} + \ln T\big)\sum_{i \neq i^*} \Delta_i^{-1}\right)$, where $\Delta_i$ are the suboptimality gaps and $i^*$ is a unique optimal arm. In the special case of $\lambda = 0$ (no switching costs), both bounds are minimax optimal within constants. We also explore variants of the problem, where switching cost is allowed to change over time. We provide experimental evaluation showing competitiveness of our algorithm with the relevant baselines in the stochastic, stochastically constrained adversarial, and adversarial regimes with fixed switching cost.
Tracking agitation in people living with dementia in a care environment
Apr 26, 2021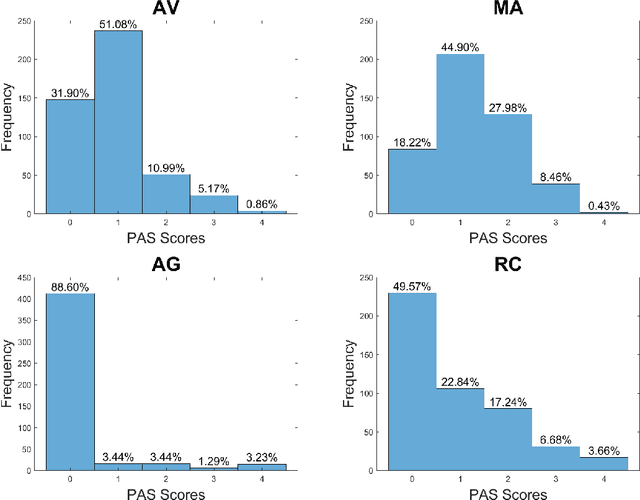
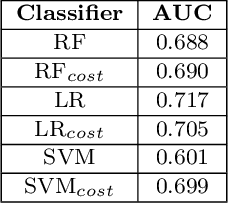

Agitation is a symptom that communicates distress in people living with dementia (PwD), and that can place them and others at risk. In a long term care (LTC) environment, care staff track and document these symptoms as a way to detect when there has been a change in resident status to assess risk, and to monitor for response to interventions. However, this documentation can be time-consuming, and due to staffing constraints, episodes of agitation may go unobserved. This brings into question the reliability of these assessments, and presents an opportunity for technology to help track and monitor behavioural symptoms in dementia. In this paper, we present the outcomes of a 2 year real-world study performed in a dementia unit, where a multi-modal wearable device was worn by $20$ PwD. In line with a commonly used clinical documentation tool, this large multi-modal time-series data was analyzed to track the presence of episodes of agitation in 8-hour nursing shifts. The development of a baseline classification model (AUC=0.717) on this dataset and subsequent improvement (AUC= 0.779) lays the groundwork for automating the process of annotating agitation events in nursing charts.