 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sleep Staging Based on Multi Scale Dual Attention Network
Aug 14, 2021
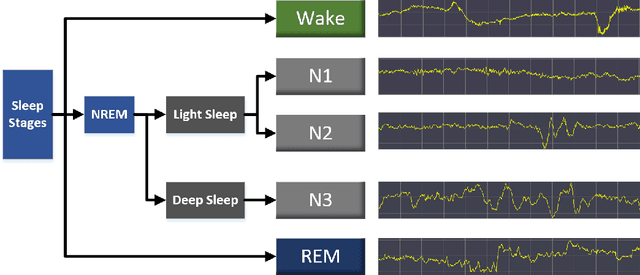

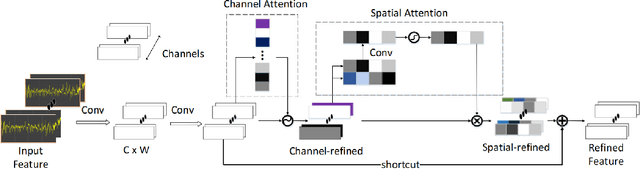

Sleep staging plays an important role on the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition process of multiple signals is much complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become a popular research topic. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with promising results and achieve the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage do not satisfy the needs of the diagnosis. In this paper, we propose a deep learning model multi scale dual attention network(MSDAN) based on raw EEG, which utilizes multi-scale convolution to extract features in different waveforms contained in the EEG signal, connects channel attention and spatial attention mechanisms in series to filter and highlight key information, and uses soft thresholding to remove redundant information. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.70%, 91.74%, 0.8231 and 0.8723 on the Sleep-EDF dataset, 96.14%, 90.35%, 0.7945 and 0.8284 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.41% and 52.79% on the two datasets respectively. The results show the superiority of our network over the existing methods, reaching a new state-of-the-art. In particular, the proposed method achieves excellent results in the N1 sleep stage compared to other methods.
Decay-Function-Free Time-Aware Attention to Context and Speaker Indicator for Spoken Language Understanding
Mar 29, 2019
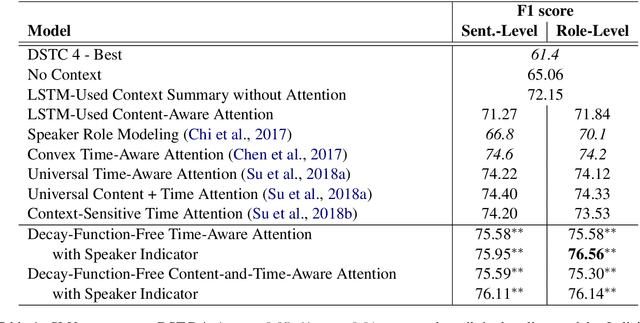
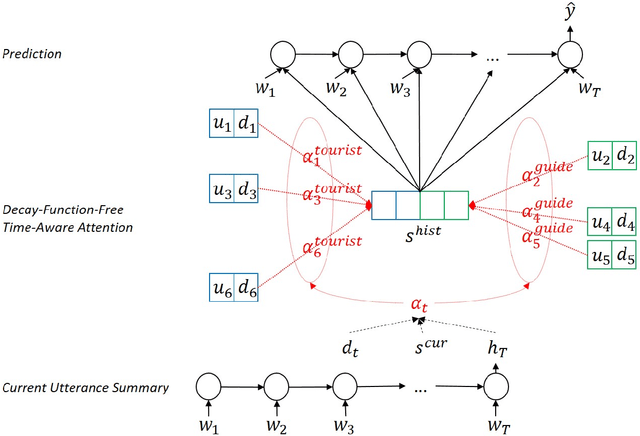
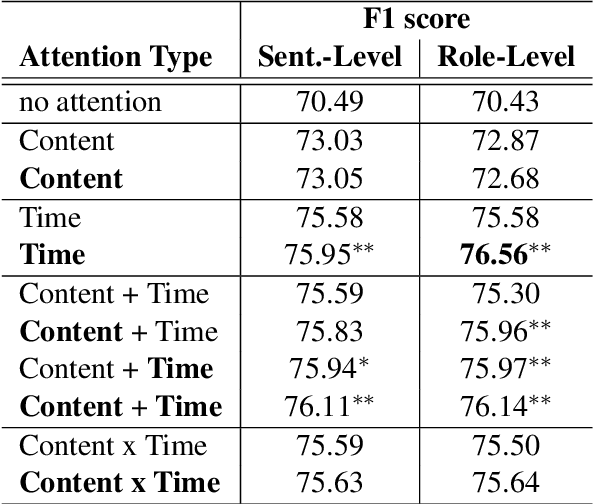
To capture salient contextual information for spoken language understanding (SLU) of a dialogue, we propose time-aware models that automatically learn the latent time-decay function of the history without a manual time-decay function. We also propose a method to identify and label the current speaker to improve the SLU accuracy. In experiments on the benchmark dataset used in Dialog State Tracking Challenge 4, the proposed models achieved significantly higher F1 scores than the state-of-the-art contextual models. Finally, we analyze the effectiveness of the introduced models in detail. The analysis demonstrates that the proposed methods were effective to improve SLU accuracy individually.
Temporal and Object Quantification Networks
Jun 10, 2021
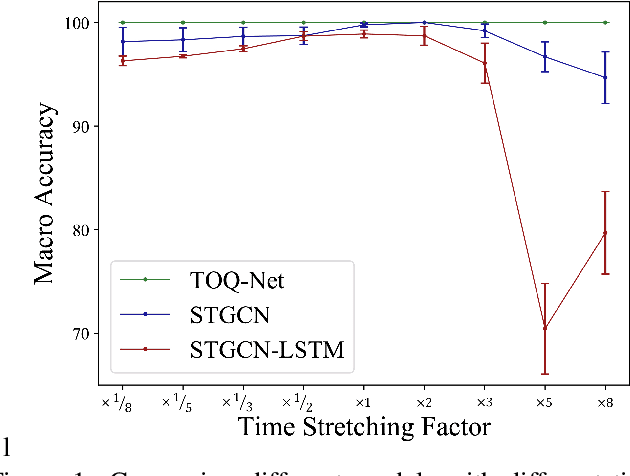
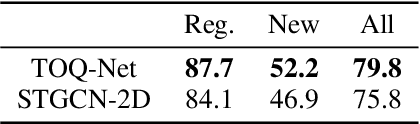
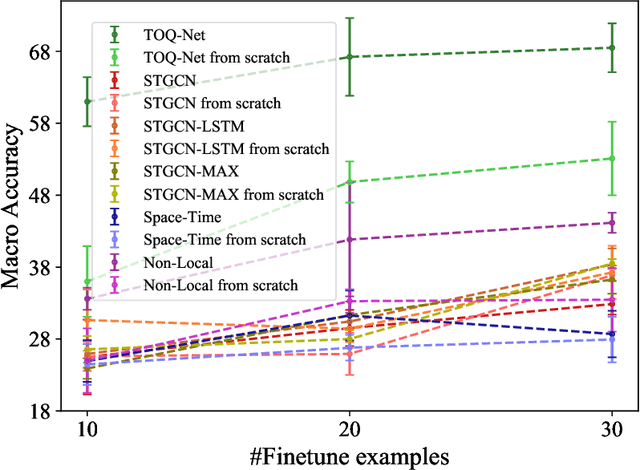
We present Temporal and Object Quantification Networks (TOQ-Nets), a new class of neuro-symbolic networks with a structural bias that enables them to learn to recognize complex relational-temporal events. This is done by including reasoning layers that implement finite-domain quantification over objects and time. The structure allows them to generalize directly to input instances with varying numbers of objects in temporal sequences of varying lengths. We evaluate TOQ-Nets on input domains that require recognizing event-types in terms of complex temporal relational patterns. We demonstrate that TOQ-Nets can generalize from small amounts of data to scenarios containing more objects than were present during training and to temporal warpings of input sequences.
Distributed support-vector-machine over dynamic balanced directed networks
Apr 01, 2021


In this paper, we consider the binary classification problem via distributed Support-Vector-Machines (SVM), where the idea is to train a network of agents, with limited share of data, to cooperatively learn the SVM classifier for the global database. Agents only share processed information regarding the classifier parameters and the gradient of the local loss functions instead of their raw data. In contrast to the existing work, we propose a continuous-time algorithm that incorporates network topology changes in discrete jumps. This hybrid nature allows us to remove chattering that arises because of the discretization of the underlying CT process. We show that the proposed algorithm converges to the SVM classifier over time-varying weight balanced directed graphs by using arguments from the matrix perturbation theory.
Time-to-Event Prediction with Neural Networks and Cox Regression
Jul 01, 2019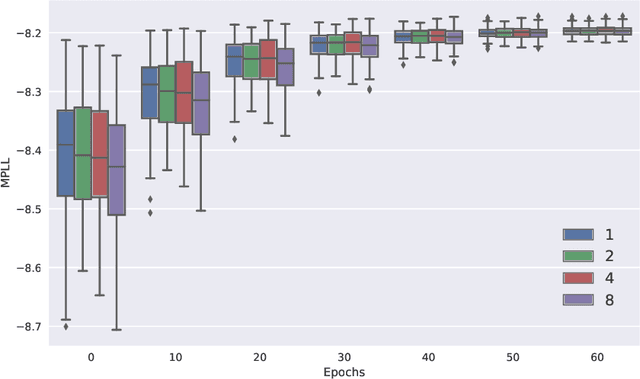

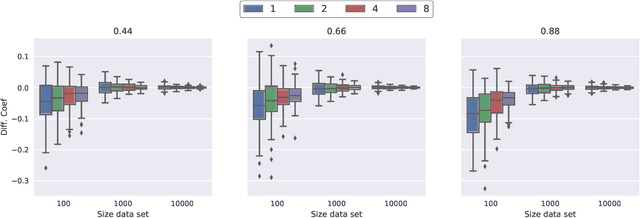
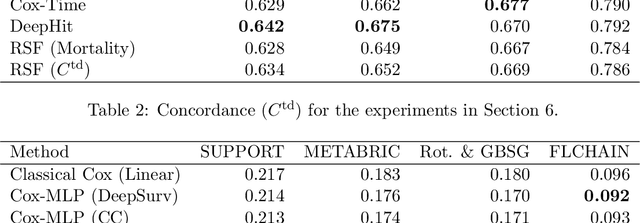
New methods for time-to-event prediction are proposed by extending the Cox proportional hazards model with neural networks. Building on methodology from nested case-control studies, we propose a loss function that scales well to large data sets, and enables fitting of both proportional and non-proportional extensions of the Cox model. Through simulation studies, the proposed loss function is verified to be a good approximation for the Cox partial log-likelihood. The proposed methodology is compared to existing methodologies on real-world data sets, and is found to be highly competitive, typically yielding the best performance in terms of Brier score and binomial log-likelihood. A python package for the proposed methods is available at https://github.com/havakv/pycox.
Finite-time optimality of Bayesian predictors
Dec 20, 2018The problem of sequential probability forecasting is considered in the most general setting: a model set C is given, and it is required to predict as well as possible if any of the measures (environments) in C is chosen to generate the data. No assumptions whatsoever are made on the model class C, in particular, no independence or mixing assumptions; C may not be measurable; there may be no predictor whose loss is sublinear, etc. It is shown that the cumulative loss of any possible predictor can be matched by that of a Bayesian predictor whose prior is discrete and is concentrated on C, up to an additive term of order $\log n$, where $n$ is the time step. The bound holds for every $n$ and every measure in C. This is the first non-asymptotic result of this kind. In addition, a non-matching lower bound is established: it goes to infinity with $n$ but may do so arbitrarily slow.
Time-Domain Audio Source Separation Based on Wave-U-Net Combined with Discrete Wavelet Transform
Jan 28, 2020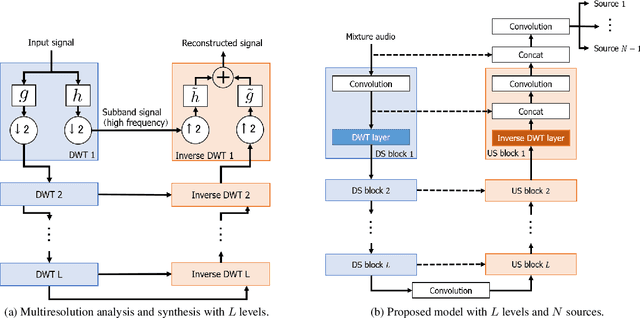

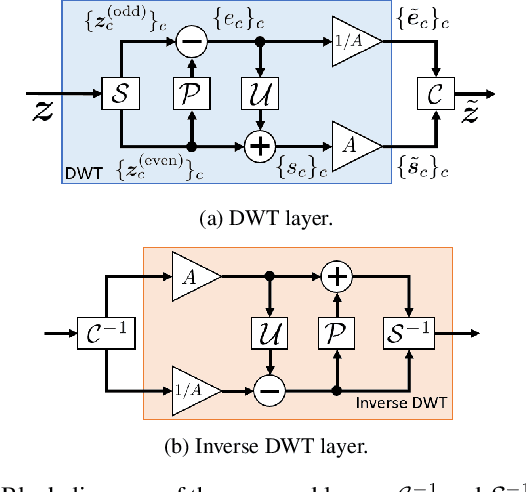
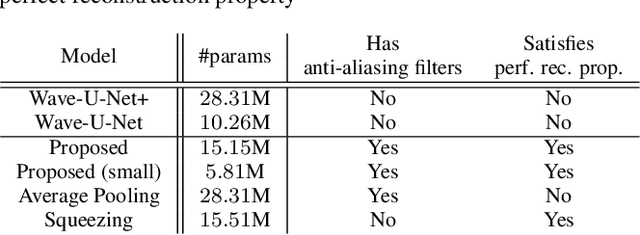
We propose a time-domain audio source separation method using down-sampling (DS) and up-sampling (US) layers based on a discrete wavelet transform (DWT). The proposed method is based on one of the state-of-the-art deep neural networks, Wave-U-Net, which successively down-samples and up-samples feature maps. We find that this architecture resembles that of multiresolution analysis, and reveal that the DS layers of Wave-U-Net cause aliasing and may discard information useful for the separation. Although the effects of these problems may be reduced by training, to achieve a more reliable source separation method, we should design DS layers capable of overcoming the problems. With this belief, focusing on the fact that the DWT has an anti-aliasing filter and the perfect reconstruction property, we design the proposed layers. Experiments on music source separation show the efficacy of the proposed method and the importance of simultaneously considering the anti-aliasing filters and the perfect reconstruction property.
How to track your dragon: A Multi-Attentional Framework for real-time RGB-D 6-DOF Object Pose Tracking
Apr 21, 2020

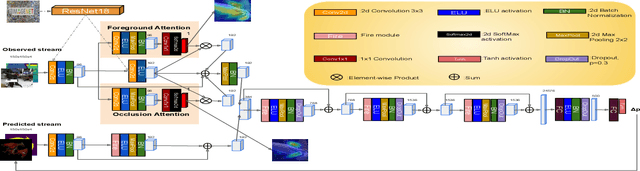

We present a novel multi-attentional convolutional architecture to tackle the problem of real-time RGB-D 6D object pose tracking of single, known objects. Such a problem poses multiple challenges originating both from the objects' nature and their interaction with their environment, which previous approaches have failed to fully address. The proposed framework encapsulates methods for background clutter and occlusion handling by integrating multiple parallel soft spatial attention modules into a multitask Convolutional Neural Network (CNN) architecture. Moreover, we consider the special geometrical properties of both the object's 3D model and the pose space, and we use a more sophisticated approach for data augmentation for training. The provided experimental results confirm the effectiveness of the proposed multi-attentional architecture, as it improves the State-of-the-Art (SoA) tracking performance by an average score of 40.5% for translation and 57.5% for rotation, when testing on the dataset presented in [1], the most complete dataset designed, up to date, for the problem of RGB-D object tracking.
Implementing a LoRa Software-Defined Radio on a General-Purpose ULP Microcontroller
Jul 17, 2021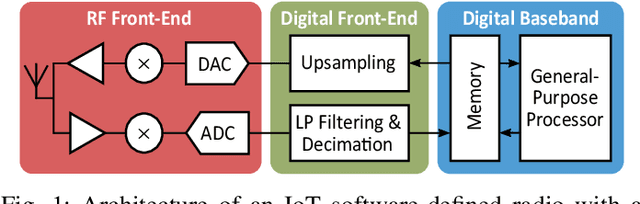
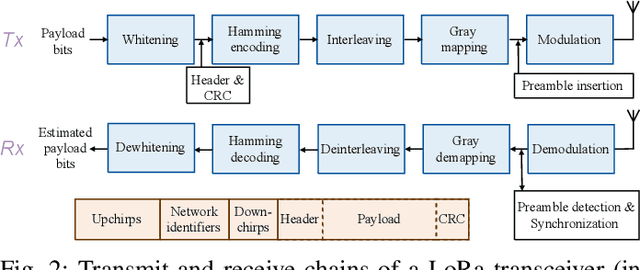
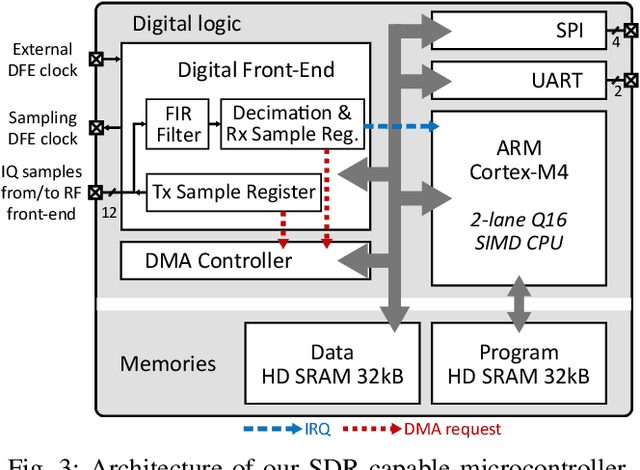
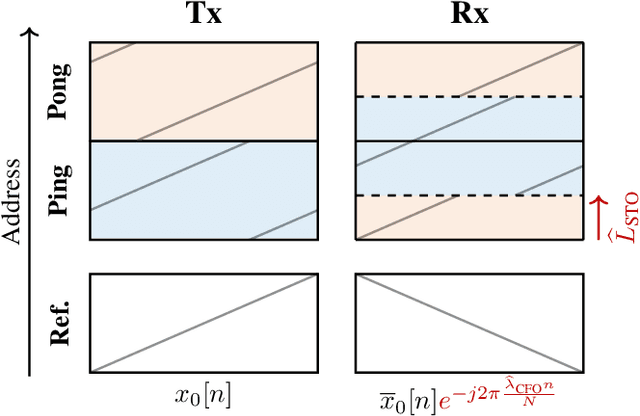
Emerging Internet-of-Things sensing applications rely on ultra low-power (ULP) microcontroller units (MCUs) that wirelessly transmit data to the cloud. Typical MCUs nowadays consist of generic blocks, except for the protocol-specific radios implemented in hardware. Hardware radios however slow down the evolution of wireless protocols due to retrocompatiblity concerns. In this work, we explore a software-defined radio architecture by demonstrating a LoRa transceiver running on custom ULP MCU codenamed SleepRider with an ARM Cortex-M4 CPU. In SleepRider MCU, we offload the generic baseband operations (e.g., low-pass filtering) to a reconfigurable digital front-end block and use the Cortex-M4 CPU to perform the protocol-specific computations. Our software implementation of the LoRa physical layer only uses the native SIMD instructions of the Cortex-M4 to achieve real-time transmission and reception of LoRa packets. SleepRider MCU has been fabricated in a 28nm FDSOI CMOS technology and is used in a testbed to experimentally validate the software implementation. Experimental results show that the proposed software-defined radio requires only a CPU frequency of 20 MHz to correctly receive a LoRa packet, with an ultra-low power consumption of 0.42 mW on average.
Optimizer Fusion: Efficient Training with Better Locality and Parallelism
Apr 01, 2021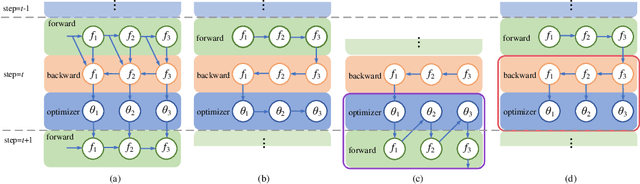


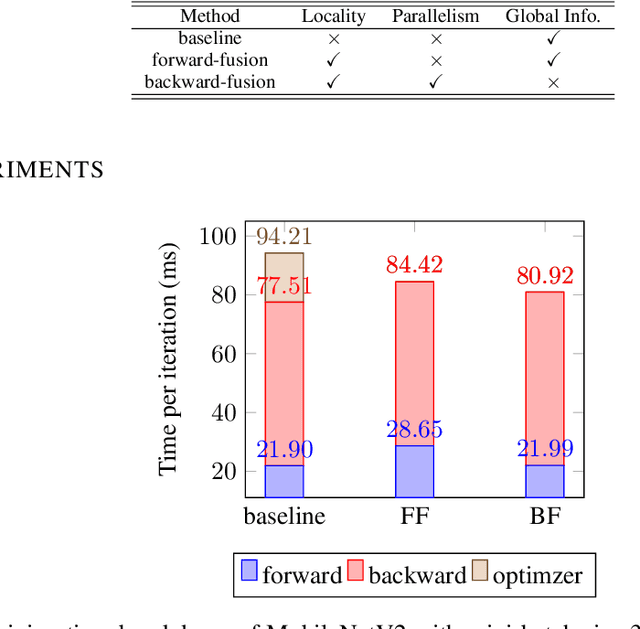
Machine learning frameworks adopt iterative optimizers to train neural networks. Conventional eager execution separates the updating of trainable parameters from forward and backward computations. However, this approach introduces nontrivial training time overhead due to the lack of data locality and computation parallelism. In this work, we propose to fuse the optimizer with forward or backward computation to better leverage locality and parallelism during training. By reordering the forward computation, gradient calculation, and parameter updating, our proposed method improves the efficiency of iterative optimizers. Experimental results demonstrate that we can achieve an up to 20% training time reduction on various configurations. Since our methods do not alter the optimizer algorithm, they can be used as a general "plug-in" technique to the training process.