 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Time Optimal Velocity Control using Prior Knowledge
Nov 28, 2018
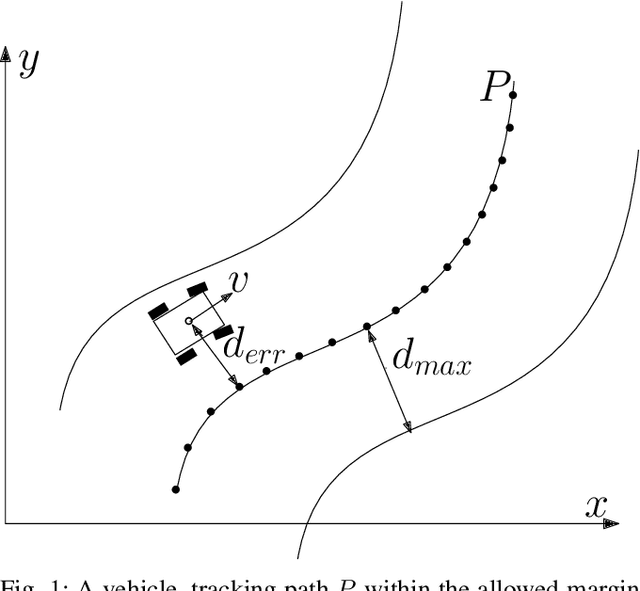
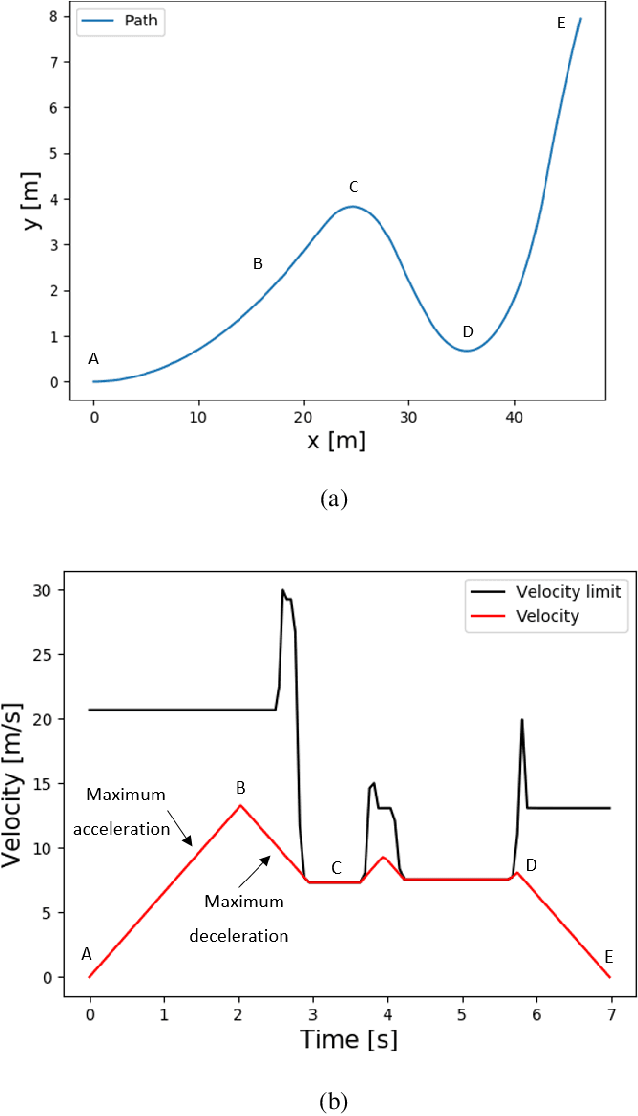
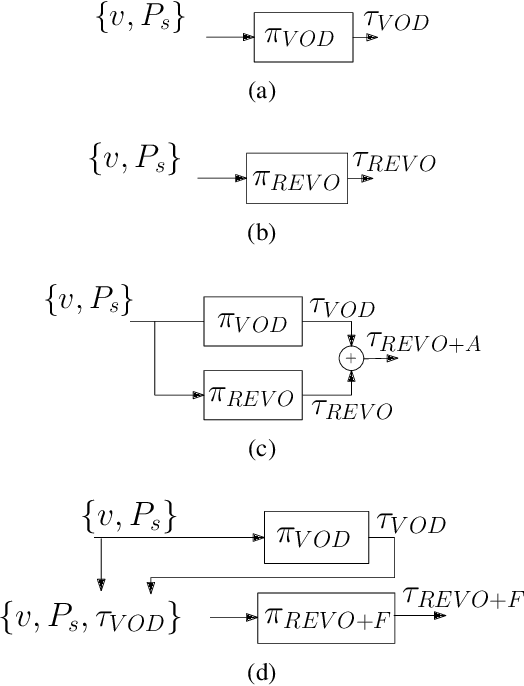
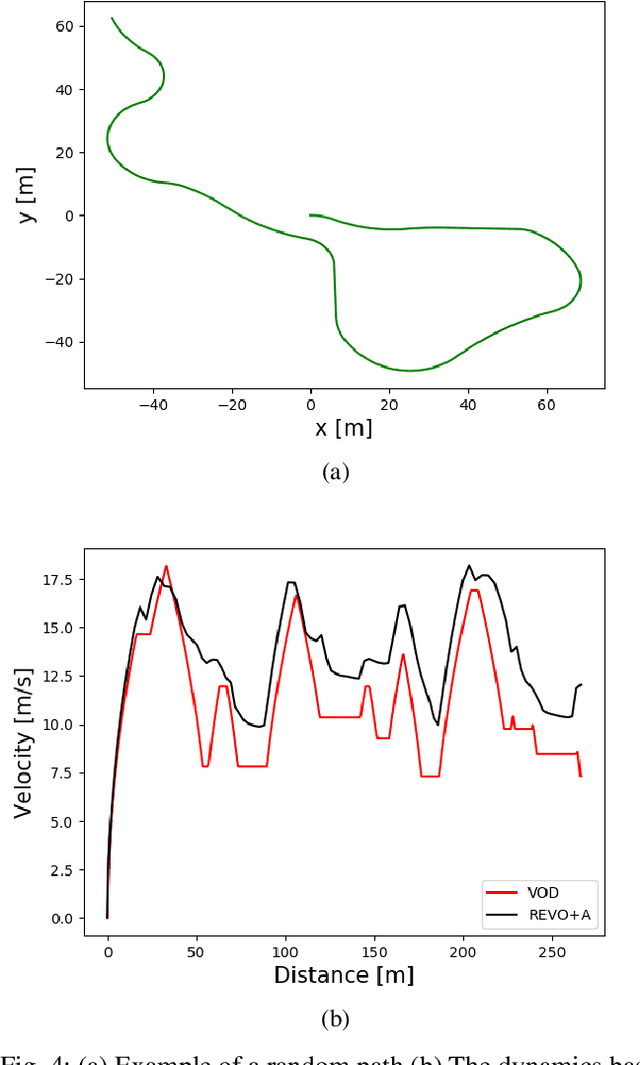
While autonomous navigation has recently gained great interest in the field of reinforcement learning, only a few works in this field have focused on the time optimal velocity control problem, i.e. controlling a vehicle such that it travels at the maximal stable speed. Achieving maximal stable speed is important in many situations, such as emergency vehicles traveling at high speeds to their destinations, and regular vehicles executing emergency maneuvers to avoid imminent collisions. Traditionally, time optimal velocity control is solved by numerical computations that are based on optimal control and vehicle dynamics. In this paper, we show that a deep reinforcement learning method for the time optimal velocity control problem outperforms a numerically derived solution. We propose a method for using the numerical solution to further improve the performance of the reinforcement learner, especially at early stages of learning. This result may contribute to the optimal control of robots in applications where some analytical model is available.
An Autonomous Drone for Search and Rescue in Forests using Airborne Optical Sectioning
May 10, 2021

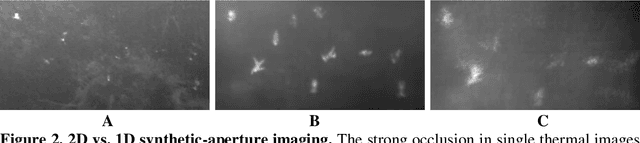
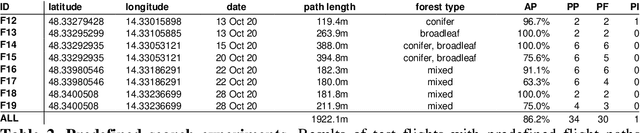
Drones will play an essential role in human-machine teaming in future search and rescue (SAR) missions. We present a first prototype that finds people fully autonomously in densely occluded forests. In the course of 17 field experiments conducted over various forest types and under different flying conditions, our drone found 38 out of 42 hidden persons; average precision was 86% for predefined flight paths, while adaptive path planning (where potential findings are double-checked) increased confidence by 15%. Image processing, classification, and dynamic flight-path adaptation are computed onboard in real-time and while flying. Our finding that deep-learning-based person classification is unaffected by sparse and error-prone sampling within one-dimensional synthetic apertures allows flights to be shortened and reduces recording requirements to one-tenth of the number of images needed for sampling using two-dimensional synthetic apertures. The goal of our adaptive path planning is to find people as reliably and quickly as possible, which is essential in time-critical applications, such as SAR. Our drone enables SAR operations in remote areas without stable network coverage, as it transmits to the rescue team only classification results that indicate detections and can thus operate with intermittent minimal-bandwidth connections (e.g., by satellite). Once received, these results can be visually enhanced for interpretation on remote mobile devices.
Classification Confidence Estimation with Test-Time Data-Augmentation
Jun 30, 2020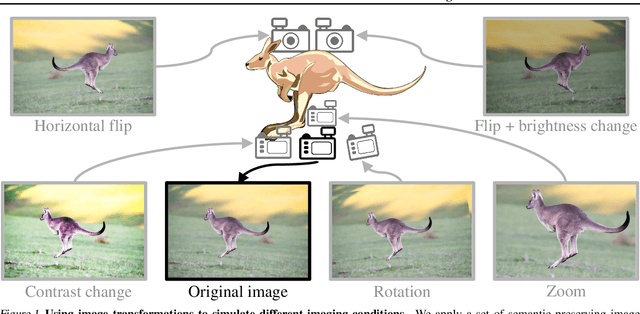
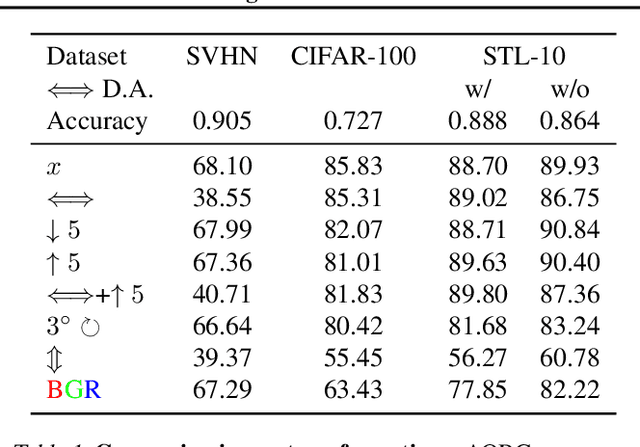
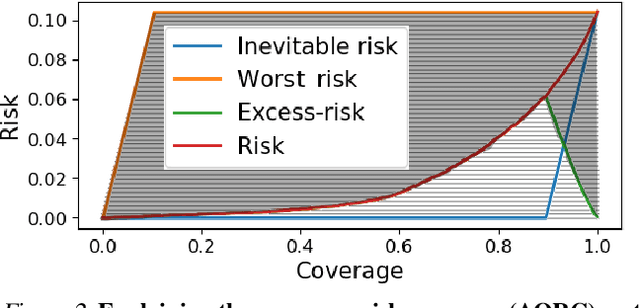
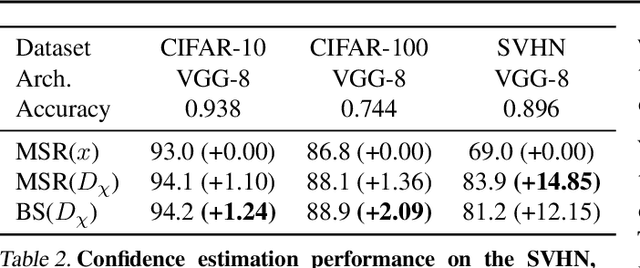
Machine learning plays an increasingly significant role in many aspects of our lives (including medicine, transportation, security, justice and other domains), making the potential consequences of false predictions increasingly devastating. These consequences may be mitigated if we can automatically flag such false predictions and potentially assign them to alternative, more reliable mechanisms, that are possibly more costly and involve human attention. This suggests the task of detecting errors, which we tackle in this paper for the case of visual classification. To this end, we propose a novel approach for classification confidence estimation. We apply a set of semantics-preserving image transformations to the input image, and show how the resulting image sets can be used to estimate confidence in the classifier's prediction. We demonstrate the potential of our approach by extensively evaluating it on a wide variety of classifier architectures and datasets, including ResNext/ImageNet, achieving state of the art performance. This paper constitutes a significant revision of our earlier work in this direction (Bahat & Shakhnarovich, 2018).
Hoechst Is All You Need: Lymphocyte Classification with Deep Learning
Jul 16, 2021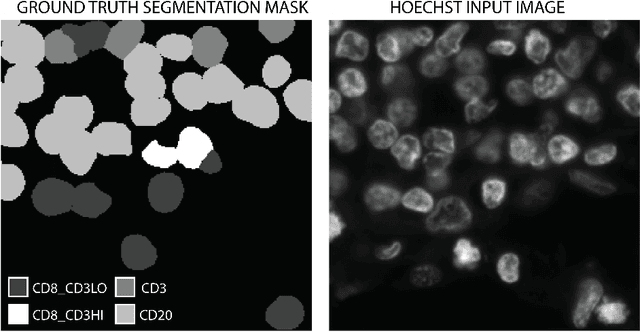

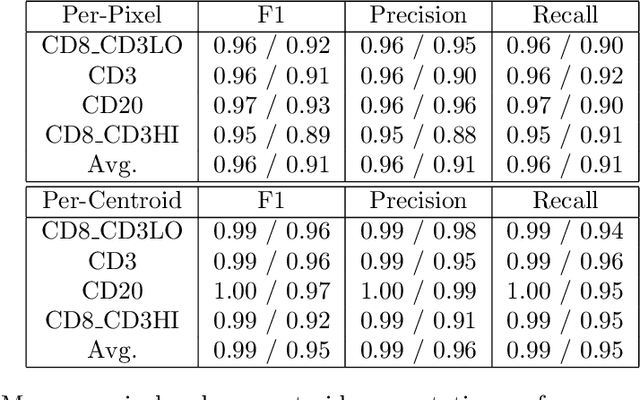
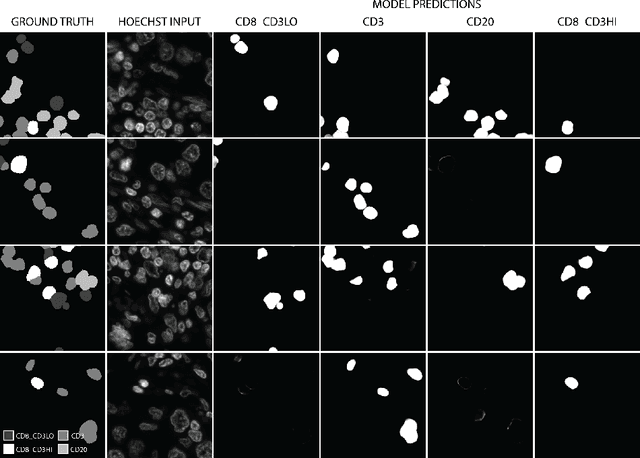
Multiplex immunofluorescence and immunohistochemistry benefit patients by allowing cancer pathologists to identify several proteins expressed on the surface of cells, enabling cell classification, better understanding of the tumour micro-environment, more accurate diagnoses, prognoses, and tailored immunotherapy based on the immune status of individual patients. However, they are expensive and time consuming processes which require complex staining and imaging techniques by expert technicians. Hoechst staining is much cheaper and easier to perform, but is not typically used in this case as it binds to DNA rather than to the proteins targeted by immunofluorescent techniques, and it was not previously thought possible to differentiate cells expressing these proteins based only on DNA morphology. In this work we show otherwise, training a deep convolutional neural network to identify cells expressing three proteins (T lymphocyte markers CD3 and CD8, and the B lymphocyte marker CD20) with greater than 90% precision and recall, from Hoechst 33342 stained tissue only. Our model learns previously unknown morphological features associated with expression of these proteins which can be used to accurately differentiate lymphocyte subtypes for use in key prognostic metrics such as assessment of immune cell infiltration,and thereby predict and improve patient outcomes without the need for costly multiplex immunofluorescence.
Distributed Online Convex Optimization with Time-Varying Coupled Inequality Constraints
Mar 06, 2019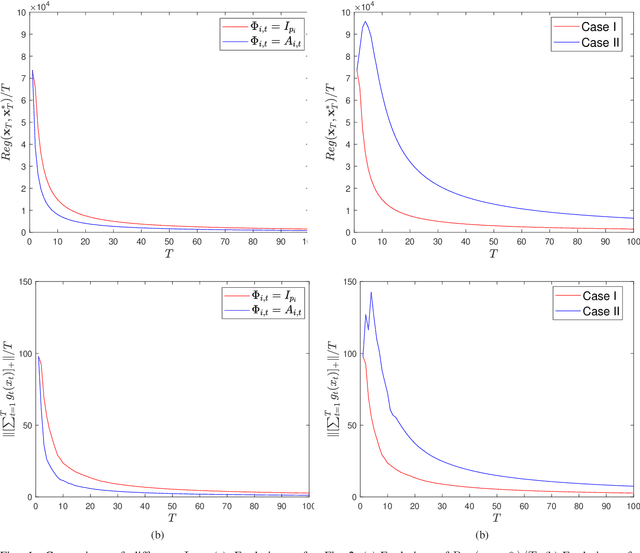
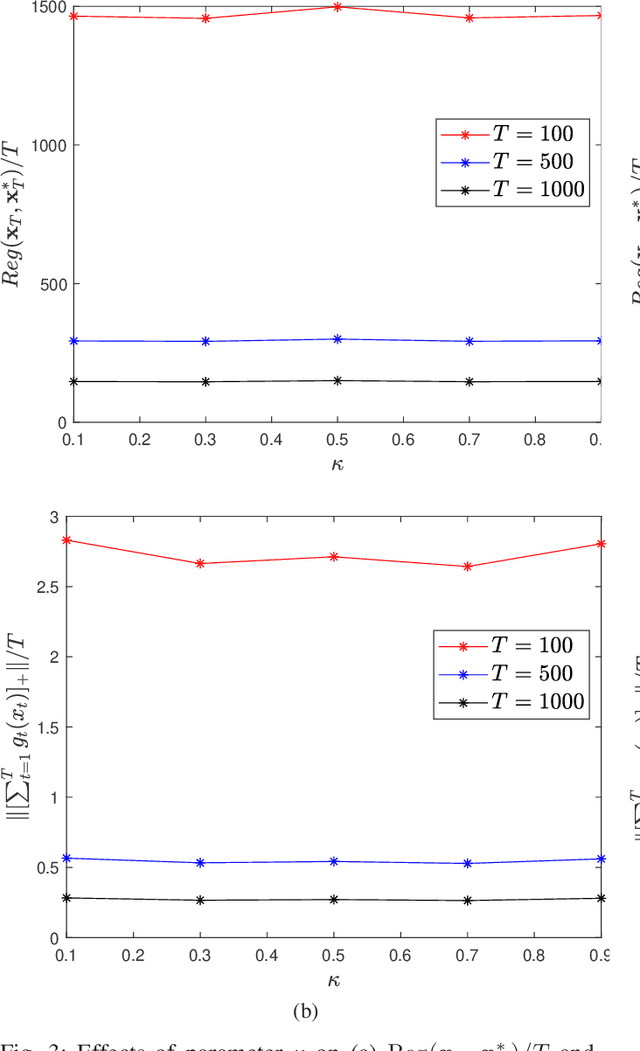
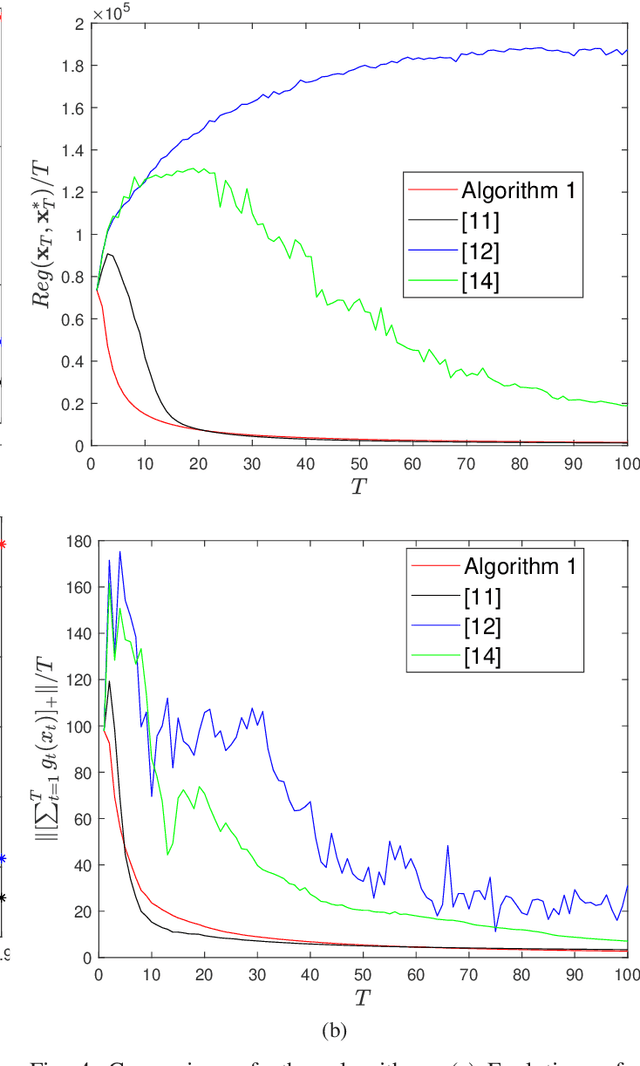

This paper considers distributed online optimization with time-varying coupled inequality constraints. The global objective function is composed of local convex cost and regularization functions and the coupled constraint function is the sum of local convex constraint functions. A distributed online primal-dual dynamic mirror descent algorithm is proposed to solve this problem, where the local cost, regularization, and constraint functions are held privately and revealed only after each time slot. We first derive regret and cumulative constraint violation bounds for the algorithm and show how they depend on the stepsize sequences, the accumulated dynamic variation of the comparator sequence, the number of agents, and the network connectivity. As a result, under some natural decreasing stepsize sequences, we prove that the algorithm achieves sublinear dynamic regret and cumulative constraint violation if the accumulated dynamic variation of the optimal sequence also grows sublinearly. We also prove that the algorithm achieves sublinear static regret and cumulative constraint violation under mild conditions. In addition, smaller bounds on the static regret are achieved when the objective functions are strongly convex. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.
Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time
May 01, 2018

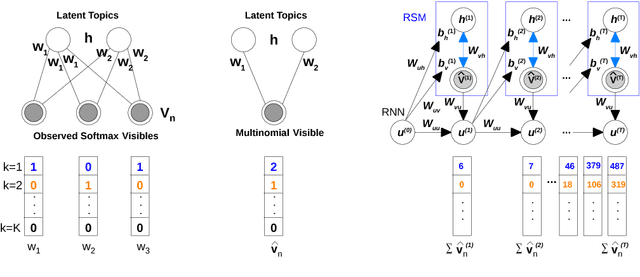
Dynamic topic modeling facilitates the identification of topical trends over time in temporal collections of unstructured documents. We introduce a novel unsupervised neural dynamic topic model named as Recurrent Neural Network-Replicated Softmax Model (RNNRSM), where the discovered topics at each time influence the topic discovery in the subsequent time steps. We account for the temporal ordering of documents by explicitly modeling a joint distribution of latent topical dependencies over time, using distributional estimators with temporal recurrent connections. Applying RNN-RSM to 19 years of articles on NLP research, we demonstrate that compared to state-of-the art topic models, RNNRSM shows better generalization, topic interpretation, evolution and trends. We also introduce a metric (named as SPAN) to quantify the capability of dynamic topic model to capture word evolution in topics over time.
Deep convolutional neural networks for multi-scale time-series classification and application to disruption prediction in fusion devices
Oct 31, 2019
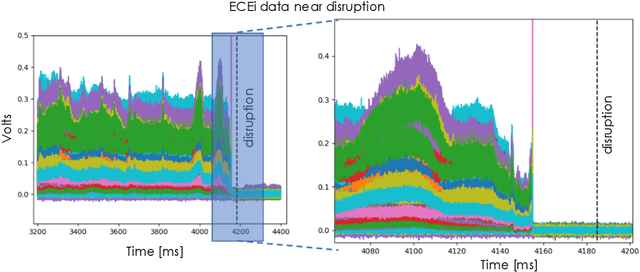
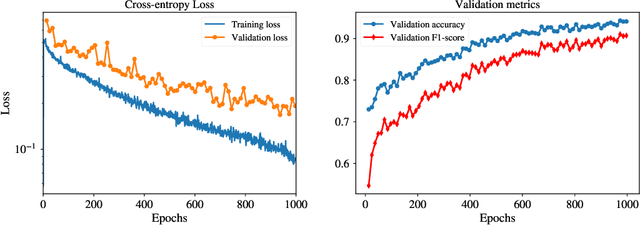
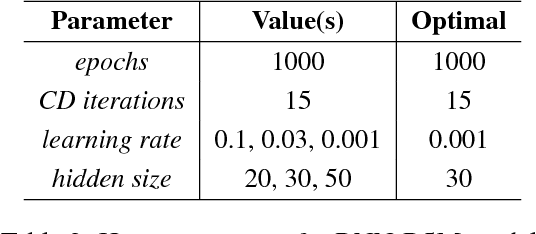
The multi-scale, mutli-physics nature of fusion plasmas makes predicting plasma events challenging. Recent advances in deep convolutional neural network architectures (CNN) utilizing dilated convolutions enable accurate predictions on sequences which have long-range, multi-scale characteristics, such as the time-series generated by diagnostic instruments observing fusion plasmas. Here we apply this neural network architecture to the popular problem of disruption prediction in fusion tokamaks, utilizing raw data from a single diagnostic, the Electron Cyclotron Emission imaging (ECEi) diagnostic from the DIII-D tokamak. ECEi measures a fundamental plasma quantity (electron temperature) with high temporal resolution over the entire plasma discharge, making it sensitive to a number of potential pre-disruptions markers with different temporal and spatial scales. Promising, initial disruption prediction results are obtained training a deep CNN with large receptive field ({$\sim$}30k), achieving an $F_1$-score of {$\sim$}91\% on individual time-slices using only the ECEi data.
Fine-Grained Complexity and Algorithms for the Schulze Voting Method
Mar 05, 2021
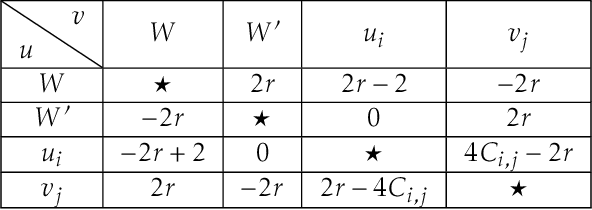
We study computational aspects of a well-known single-winner voting rule called the Schulze method [Schulze, 2003] which is used broadly in practice. In this method the voters give (weak) ordinal preference ballots which are used to define the weighted majority graph (WMG) of direct comparisons between pairs of candidates. The choice of the winner comes from indirect comparisons in the graph, and more specifically from considering directed paths instead of direct comparisons between candidates. When the input is the WMG, to our knowledge, the fastest algorithm for computing all possible winners in the Schulze method uses a folklore reduction to the All-Pairs Bottleneck Paths (APBP) problem and runs in $O(m^{2.69})$ time, where $m$ is the number of candidates. It is an interesting open question whether this can be improved. Our first result is a combinatorial algorithm with a nearly quadratic running time for computing all possible winners. If the input to the possible winners problem is not the WMG but the preference profile, then constructing the WMG is a bottleneck that increases the running time significantly; in the special case when there are $O(m)$ voters and candidates, the running time becomes $O(m^{2.69})$, or $O(m^{2.5})$ if there is a nearly-linear time algorithm for multiplying dense square matrices. To address this bottleneck, we prove a formal equivalence between the well-studied Dominance Product problem and the problem of computing the WMG. We prove a similar connection between the so called Dominating Pairs problem and the problem of verifying whether a given candidate is a possible winner. Our paper is the first to bring fine-grained complexity into the field of computational social choice. Using it we can identify voting protocols that are unlikely to be practical for large numbers of candidates and/or voters, as their complexity is likely, say at least cubic.
Modeling User Behaviour in Research Paper Recommendation System
Jul 16, 2021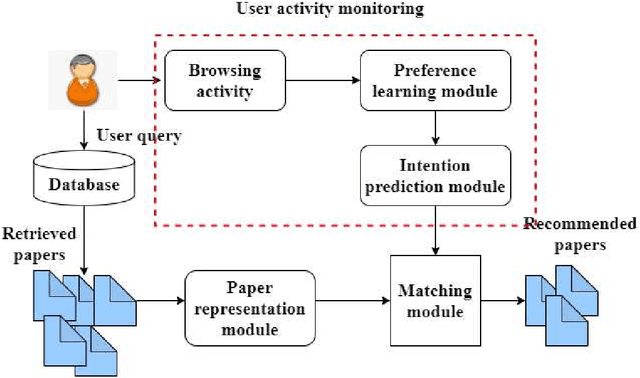
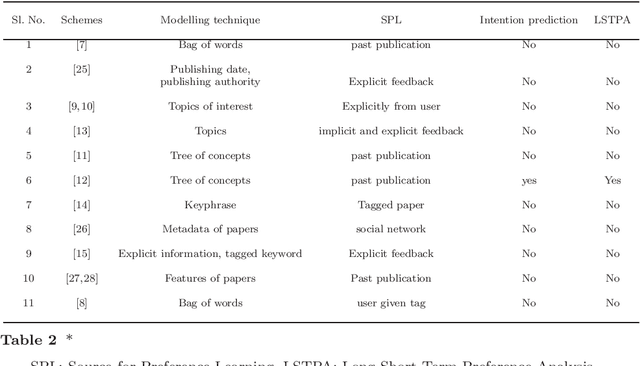
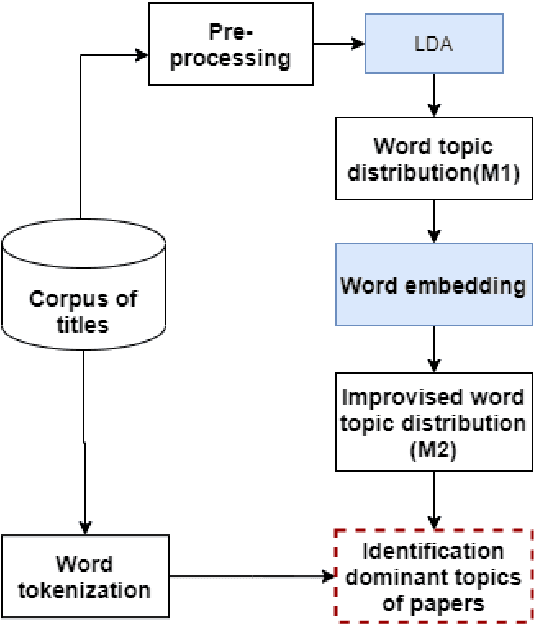
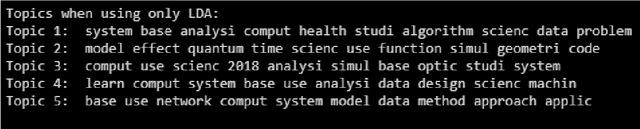
User intention which often changes dynamically is considered to be an important factor for modeling users in the design of recommendation systems. Recent studies are starting to focus on predicting user intention (what users want) beyond user preference (what users like). In this work, a user intention model is proposed based on deep sequential topic analysis. The model predicts a user's intention in terms of the topic of interest. The Hybrid Topic Model (HTM) comprising Latent Dirichlet Allocation (LDA) and Word2Vec is proposed to derive the topic of interest of users and the history of preferences. HTM finds the true topics of papers estimating word-topic distribution which includes syntactic and semantic correlations among words. Next, to model user intention, a Long Short Term Memory (LSTM) based sequential deep learning model is proposed. This model takes into account temporal context, namely the time difference between clicks of two consecutive papers seen by a user. Extensive experiments with the real-world research paper dataset indicate that the proposed approach significantly outperforms the state-of-the-art methods. Further, the proposed approach introduces a new road map to model a user activity suitable for the design of a research paper recommendation system.
Efficient automated U-Net based tree crown delineation using UAV multi-spectral imagery on embedded devices
Jul 16, 2021



Delineation approaches provide significant benefits to various domains, including agriculture, environmental and natural disasters monitoring. Most of the work in the literature utilize traditional segmentation methods that require a large amount of computational and storage resources. Deep learning has transformed computer vision and dramatically improved machine translation, though it requires massive dataset for training and significant resources for inference. More importantly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial in the aforementioned application. In this work, we propose a U-Net based tree delineation method, which is effectively trained using multi-spectral imagery but can then delineate single-spectrum images. The deep architecture that also performs localization, i.e., a class label corresponds to each pixel, has been successfully used to allow training with a small set of segmented images. The ground truth data were generated using traditional image denoising and segmentation approaches. To be able to execute the proposed DNN efficiently in embedded platforms designed for deep learning approaches, we employ traditional model compression and acceleration methods. Extensive evaluation studies using data collected from UAVs equipped with multi-spectral cameras demonstrate the effectiveness of the proposed methods in terms of delineation accuracy and execution efficiency.