 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Federated Learning in Robotic and Autonomous Systems
Apr 20, 2021
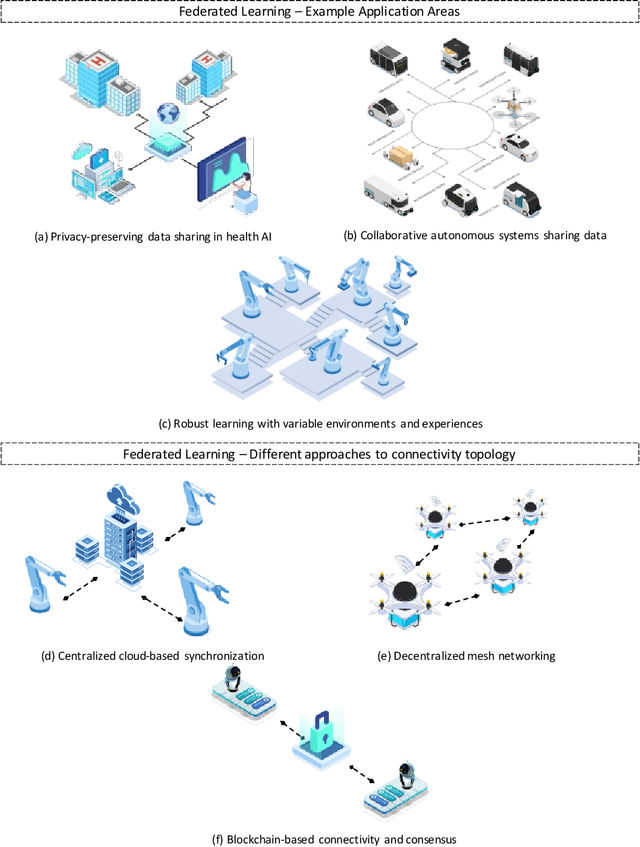
Autonomous systems are becoming inherently ubiquitous with the advancements of computing and communication solutions enabling low-latency offloading and real-time collaboration of distributed devices. Decentralized technologies with blockchain and distributed ledger technologies (DLTs) are playing a key role. At the same time, advances in deep learning (DL) have significantly raised the degree of autonomy and level of intelligence of robotic and autonomous systems. While these technological revolutions were taking place, raising concerns in terms of data security and end-user privacy has become an inescapable research consideration. Federated learning (FL) is a promising solution to privacy-preserving DL at the edge, with an inherently distributed nature by learning on isolated data islands and communicating only model updates. However, FL by itself does not provide the levels of security and robustness required by today's standards in distributed autonomous systems. This survey covers applications of FL to autonomous robots, analyzes the role of DLT and FL for these systems, and introduces the key background concepts and considerations in current research.
Fine-Grained Classroom Activity Detection from Audio with Neural Networks
Jul 29, 2021
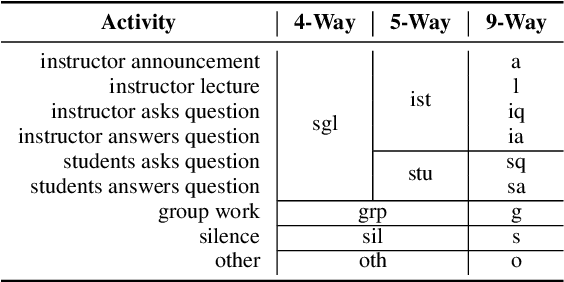
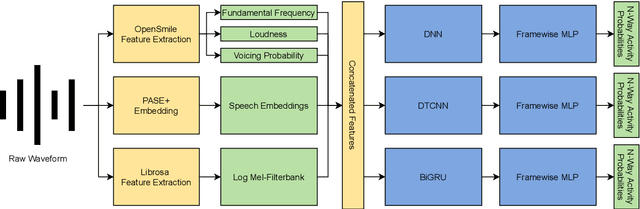
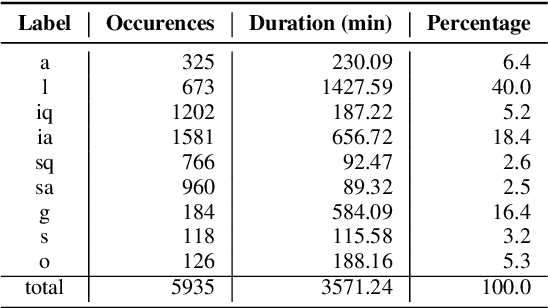
Instructors are increasingly incorporating student-centered learning techniques in their classrooms to improve learning outcomes. In addition to lecture, these class sessions involve forms of individual and group work, and greater rates of student-instructor interaction. Quantifying classroom activity is a key element of accelerating the evaluation and refinement of innovative teaching practices, but manual annotation does not scale. In this manuscript, we present advances to the young application area of automatic classroom activity detection from audio. Using a university classroom corpus with nine activity labels (e.g., "lecture," "group work," "student question"), we propose and evaluate deep fully connected, convolutional, and recurrent neural network architectures, comparing the performance of mel-filterbank, OpenSmile, and self-supervised acoustic features. We compare 9-way classification performance with 5-way and 4-way simplifications of the task and assess two types of generalization: (1) new class sessions from previously seen instructors, and (2) previously unseen instructors. We obtain strong results on the new fine-grained task and state-of-the-art on the 4-way task: our best model obtains frame-level error rates of 6.2%, 7.7% and 28.0% when generalizing to unseen instructors for the 4-way, 5-way, and 9-way classification tasks, respectively (relative reductions of 35.4%, 48.3% and 21.6% over a strong baseline). When estimating the aggregate time spent on classroom activities, our average root mean squared error is 1.64 minutes per class session, a 54.9% relative reduction over the baseline.
On Analyzing Churn Prediction in Mobile Games
Apr 12, 2021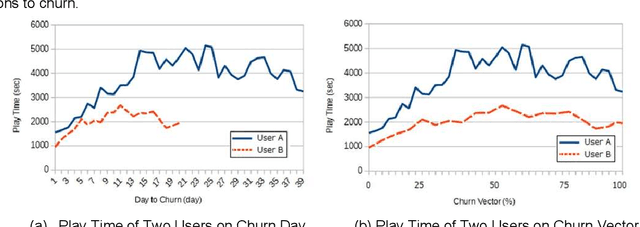

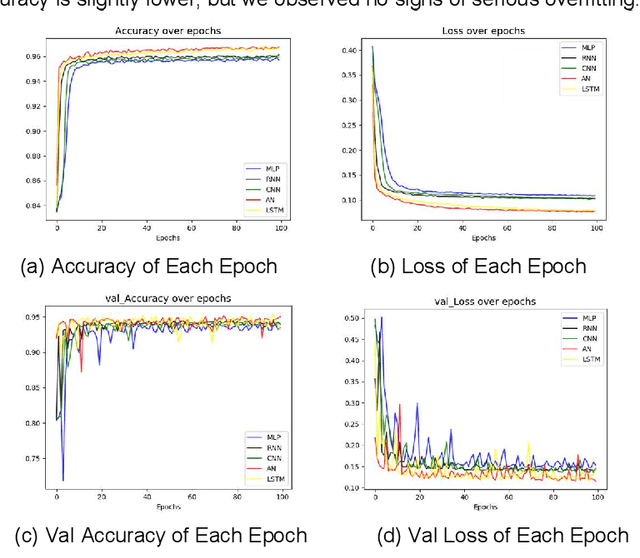
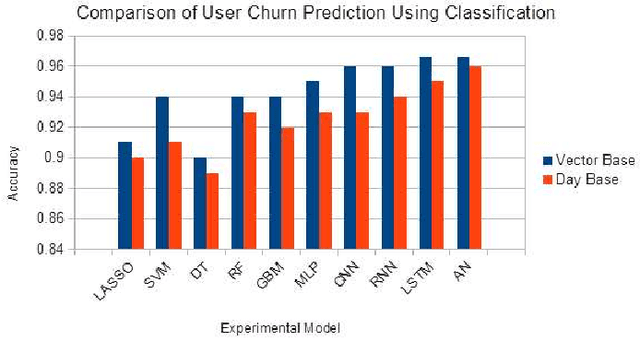
In subscription-based businesses, the churn rate refers to the percentage of customers who discontinue their subscriptions within a given time period. Particularly, in the mobile games industry, the churn rate is often pronounced due to the high competition and cost in customer acquisition; therefore, the process of minimizing the churn rate is crucial. This needs churn prediction, predicting users who will be churning within a given time period. Accurate churn prediction can enable the businesses to devise and engage strategic remediations to maintain a low churn rate. The paper presents our highly accurate churn prediction method. We designed this method to take into account each individual user's distinct usage period in churn prediction. As presented in the paper, this approach was able to achieve 96.6% churn prediction accuracy on a real game business. In addition, the paper shows that other existing churn prediction algorithms are improved in prediction accuracy when this method is applied.
Insights into LSTM Fully Convolutional Networks for Time Series Classification
Mar 01, 2019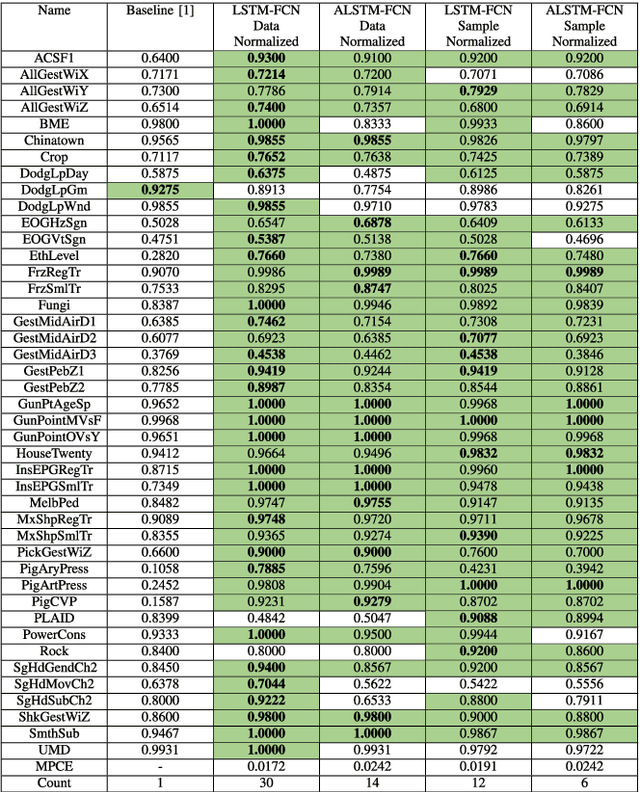
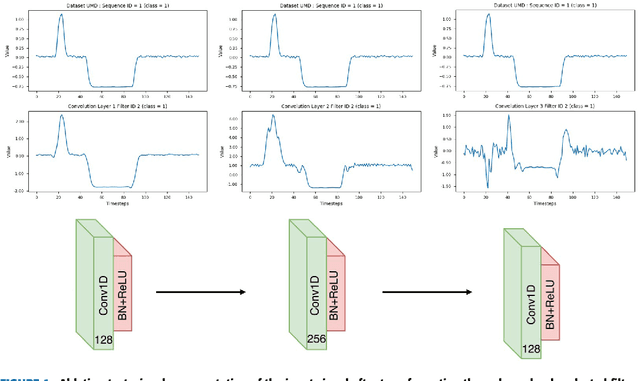
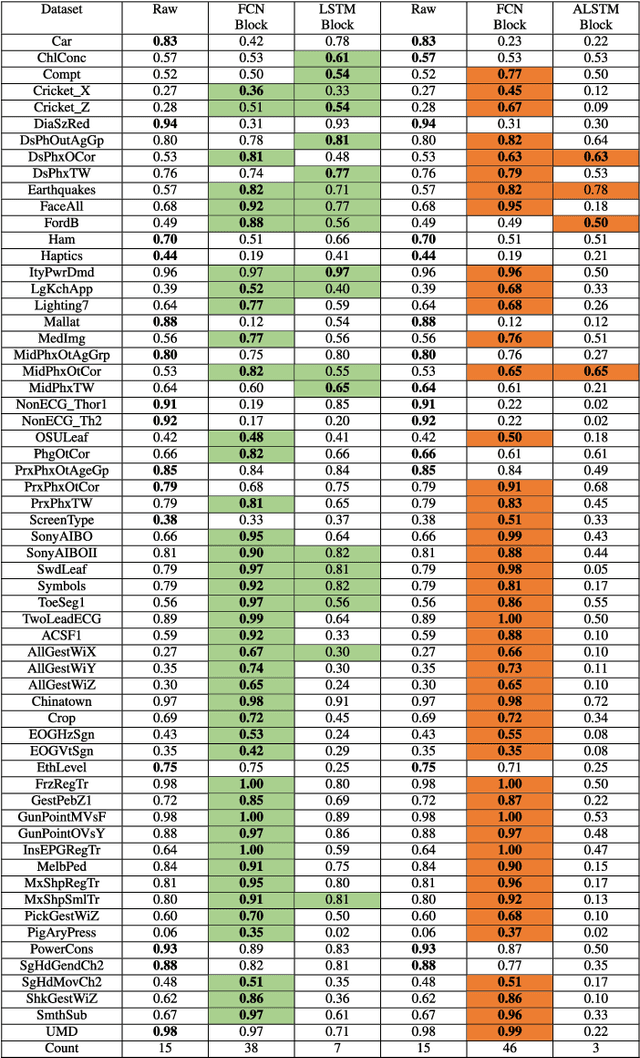
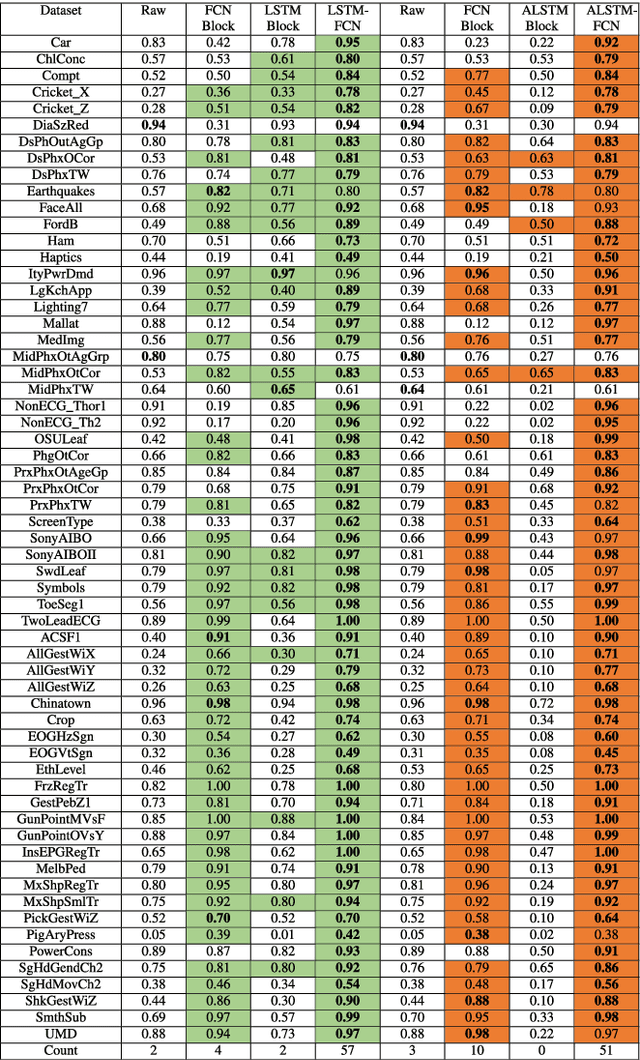
Long Short Term Memory Fully Convolutional Neural Networks (LSTM-FCN) and Attention LSTM-FCN (ALSTM-FCN) have shown to achieve state-of-the-art performance on the task of classifying time series signals on the old University of California-Riverside (UCR) time series repository. However, there has been no study on why LSTM-FCN and ALSTM-FCN perform well. In this paper, we perform a series of ablation tests (3627 experiments) on LSTM-FCN and ALSTM-FCN to provide a better understanding of the model and each of its sub-module. Results from the ablation tests on ALSTM-FCN and LSTM-FCN show that the these blocks perform better when applied in a conjoined manner. Two z-normalizing techniques, z-normalizing each sample independently and z-normalizing the whole dataset, are compared using a Wilcoxson signed-rank test to show a statistical difference in performance. In addition, we provide an understanding of the impact dimension shuffle has on LSTM-FCN by comparing its performance with LSTM-FCN when no dimension shuffle is applied. Finally, we demonstrate the performance of the LSTM-FCN when the LSTM block is replaced by a GRU, basic RNN, and Dense Block.
Going Deeper into Semi-supervised Person Re-identification
Jul 24, 2021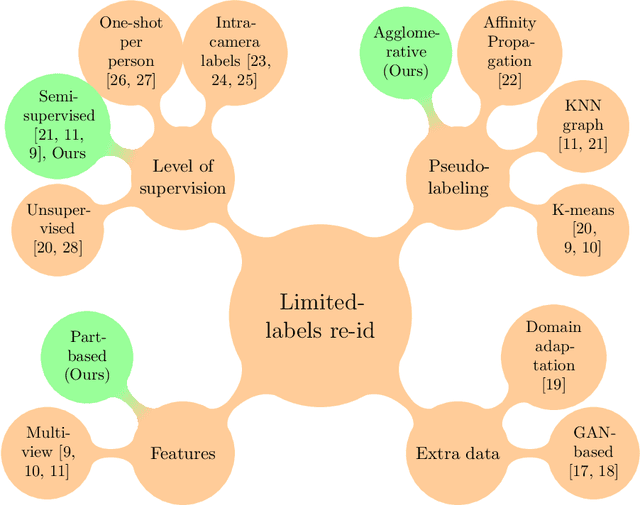
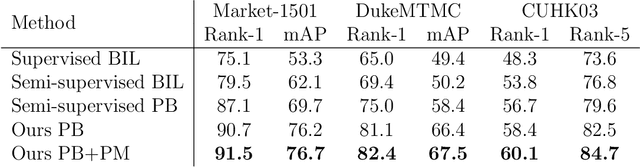
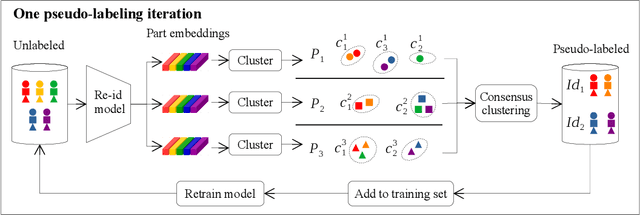

Person re-identification is the challenging task of identifying a person across different camera views. Training a convolutional neural network (CNN) for this task requires annotating a large dataset, and hence, it involves the time-consuming manual matching of people across cameras. To reduce the need for labeled data, we focus on a semi-supervised approach that requires only a subset of the training data to be labeled. We conduct a comprehensive survey in the area of person re-identification with limited labels. Existing works in this realm are limited in the sense that they utilize features from multiple CNNs and require the number of identities in the unlabeled data to be known. To overcome these limitations, we propose to employ part-based features from a single CNN without requiring the knowledge of the label space (i.e., the number of identities). This makes our approach more suitable for practical scenarios, and it significantly reduces the need for computational resources. We also propose a PartMixUp loss that improves the discriminative ability of learned part-based features for pseudo-labeling in semi-supervised settings. Our method outperforms the state-of-the-art results on three large-scale person re-id datasets and achieves the same level of performance as fully supervised methods with only one-third of labeled identities.
Robust Linear Regression: Optimal Rates in Polynomial Time
Jun 29, 2020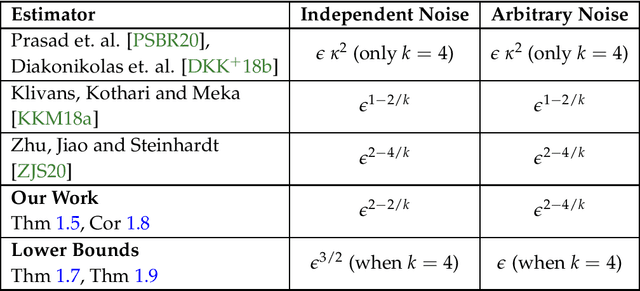
We obtain a robust and computationally efficient estimator for Linear Regression that achieves statistically optimal convergence rate under mild distributional assumptions. Concretely, we assume our data is drawn from a $k$-hypercontractive distribution and an $\epsilon$-fraction is adversarially corrupted. We then describe an estimator that converges to the optimal least-squares minimizer for the true distribution at a rate proportional to $\epsilon^{2-2/k}$, when the noise is independent of the covariates. We note that no such estimator was known prior to our work, even with access to unbounded computation. The rate we achieve is information-theoretically optimal and thus we resolve the main open question in Klivans, Kothari and Meka [COLT'18]. Our key insight is to identify an analytic condition relating the distribution over the noise and covariates that completely characterizes the rate of convergence, regardless of the noise model. In particular, we show that when the moments of the noise and covariates are negatively-correlated, we obtain the same rate as independent noise. Further, when the condition is not satisfied, we obtain a rate proportional to $\epsilon^{2-4/k}$, and again match the information-theoretic lower bound. Our central technical contribution is to algorithmically exploit independence of random variables in the "sum-of-squares" framework by formulating it as a polynomial identity.
A Database for Research on Detection and Enhancement of Speech Transmitted over HF links
Jun 04, 2021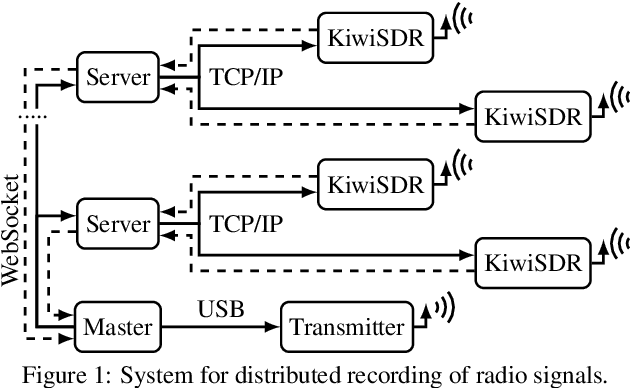
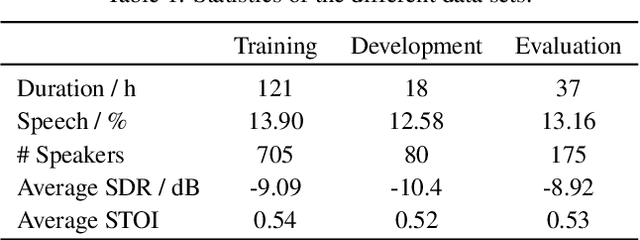
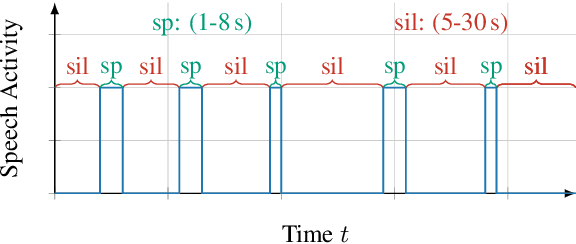

In this paper we present an open database for the development of detection and enhancement algorithms of speech transmitted over HF radio channels. It consists of audio samples recorded by various receivers at different locations across Europe, all monitoring the same single-sideband modulated transmission from a base station in Paderborn, Germany. Transmitted and received speech signals are precisely time aligned to offer parallel data for supervised training of deep learning based detection and enhancement algorithms. For the task of speech activity detection two exemplary baseline systems are presented, one based on statistical methods employing a multi-stage Wiener filter with minimum statistics noise floor estimation, and the other relying on a deep learning approach.
Text-Aware Predictive Monitoring of Business Processes
Apr 20, 2021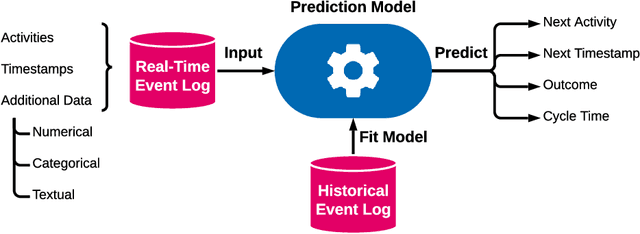

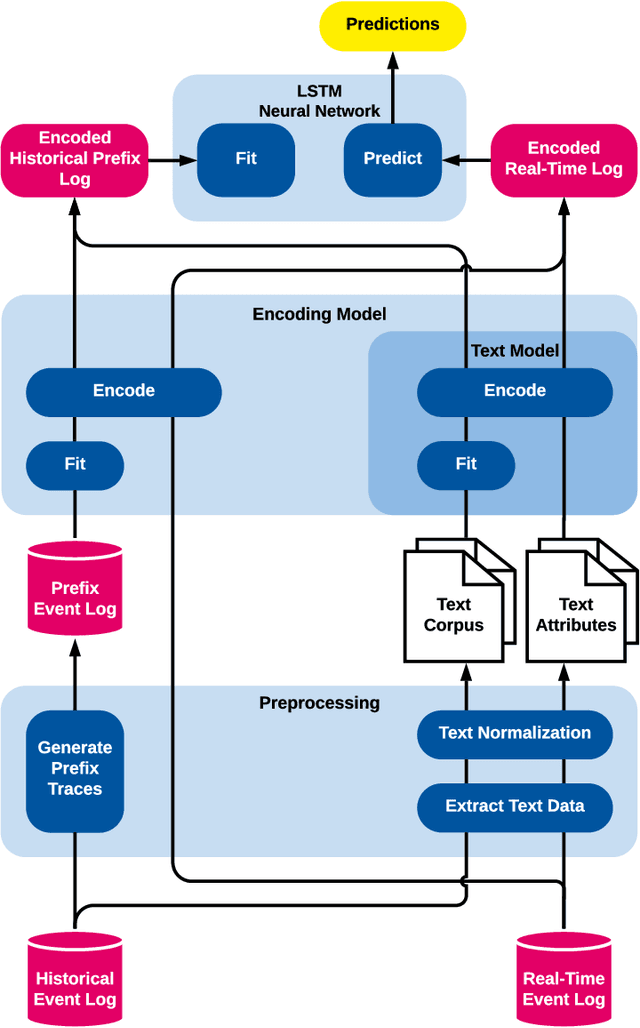
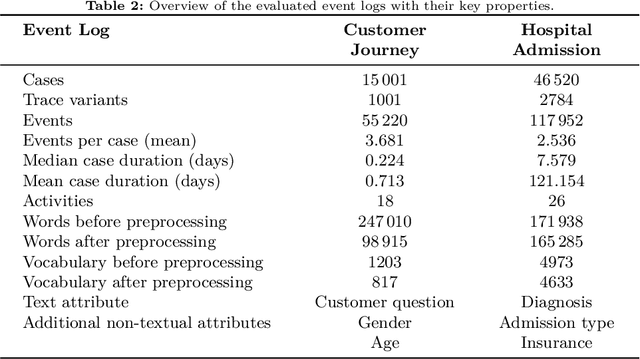
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.
Sample Efficient Social Navigation Using Inverse Reinforcement Learning
Jun 18, 2021
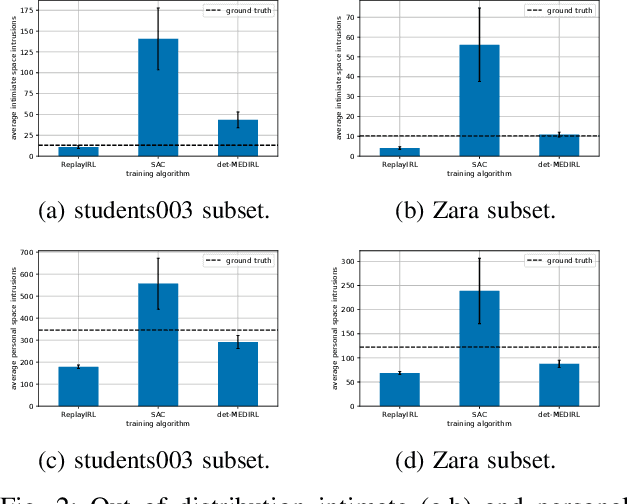
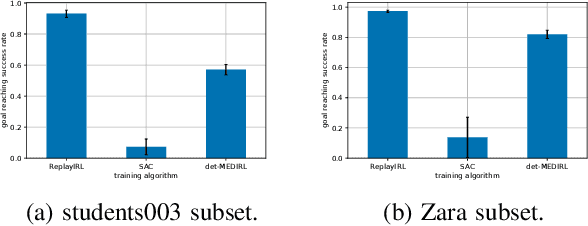
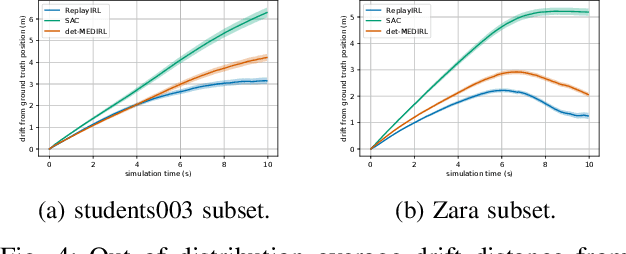
In this paper, we present an algorithm to efficiently learn socially-compliant navigation policies from observations of human trajectories. As mobile robots come to inhabit and traffic social spaces, they must account for social cues and behave in a socially compliant manner. We focus on learning such cues from examples. We describe an inverse reinforcement learning based algorithm which learns from human trajectory observations without knowing their specific actions. We increase the sample-efficiency of our approach over alternative methods by leveraging the notion of a replay buffer (found in many off-policy reinforcement learning methods) to eliminate the additional sample complexity associated with inverse reinforcement learning. We evaluate our method by training agents using publicly available pedestrian motion data sets and compare it to related methods. We show that our approach yields better performance while also decreasing training time and sample complexity.
Partitioned Graph Convolution Using Adversarial and Regression Networks for Road Travel Speed Prediction
Feb 26, 2021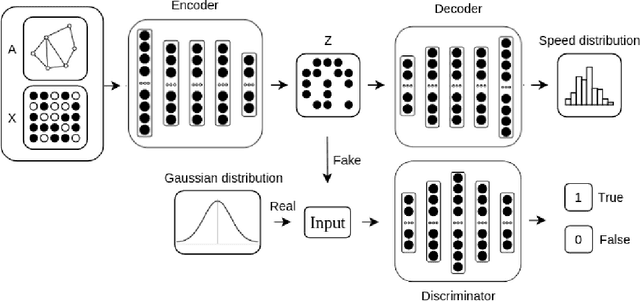

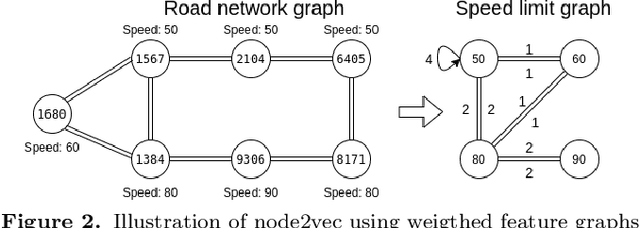
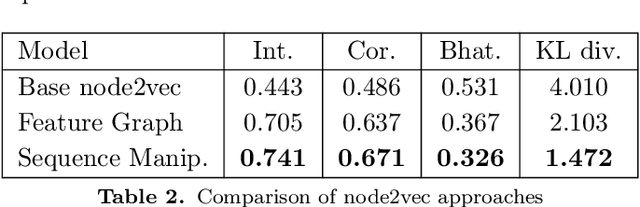
Access to quality travel time information for roads in a road network has become increasingly important with the rising demand for real-time travel time estimation for paths within road networks. In the context of the Danish road network (DRN) dataset used in this paper, the data coverage is sparse and skewed towards arterial roads, with a coverage of 23.88% across 850,980 road segments, which makes travel time estimation difficult. Existing solutions for graph-based data processing often neglect the size of the graph, which is an apparent problem for road networks with a large amount of connected road segments. To this end, we propose a framework for predicting road segment travel speed histograms for dataless edges, based on a latent representation generated by an adversarially regularized convolutional network. We apply a partitioning algorithm to divide the graph into dense subgraphs, and then train a model for each subgraph to predict speed histograms for the nodes. The framework achieves an accuracy of 71.5% intersection and 78.5% correlation on predicting travel speed histograms using the DRN dataset. Furthermore, experiments show that partitioning the dataset into clusters increases the performance of the framework. Specifically, partitioning the road network dataset into 100 clusters, with approximately 500 road segments in each cluster, achieves a better performance than when using 10 and 20 clusters.