 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Confidence Trigger Detection: An Approach to Build Real-time Tracking-by-detection System
Feb 02, 2019
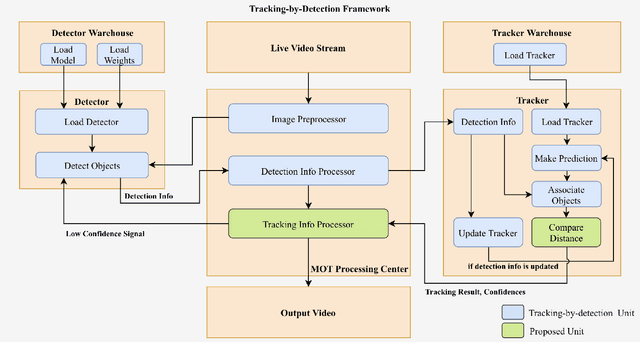
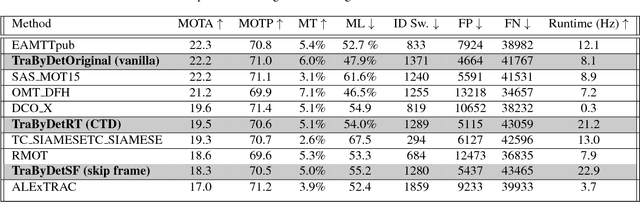
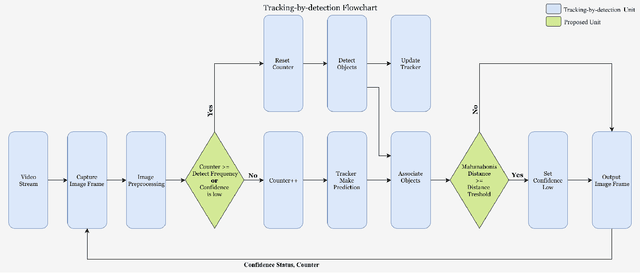

With deep learning based image analysis getting popular in recent years, a lot of multiple objects tracking applications are in demand. Some of these applications (e.g., surveillance camera, intelligent robotics, and autonomous driving) require the system runs in real-time. Though recent proposed methods reach fairly high accuracy, the speed is still slower than real-time application requirement. In order to increase tracking-by-detection system's speed for real-time tracking, we proposed confidence trigger detection (CTD) approach which uses confidence of tracker to decide when to trigger object detection. Using this approach, system can safely skip detection of images frames that objects barely move. We had studied the influence of different confidences in three popular detectors separately. Though we found trade-off between speed and accuracy, our approach reaches higher accuracy at given speed.
Closed-Loop Error Learning Control for Uncertain Nonlinear Systems With Experimental Validation on a Mobile Robot
Mar 16, 2021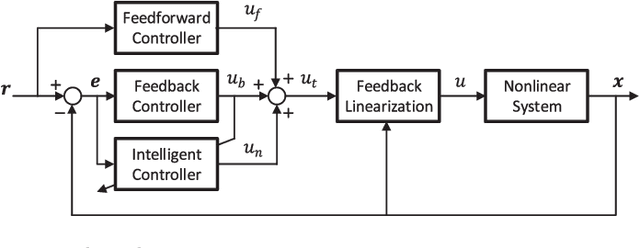
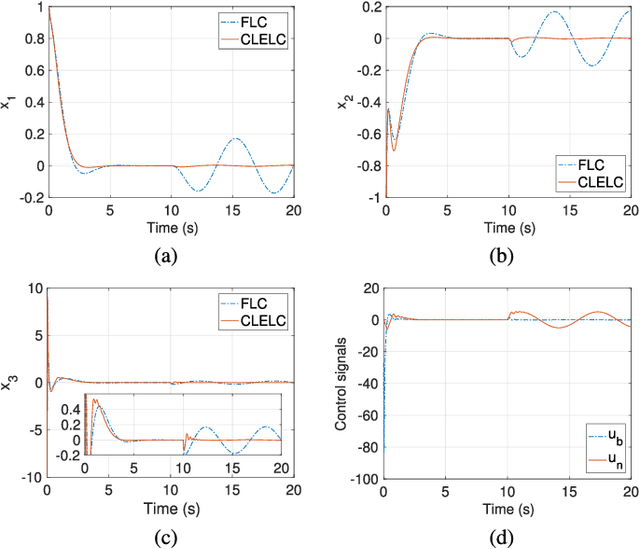

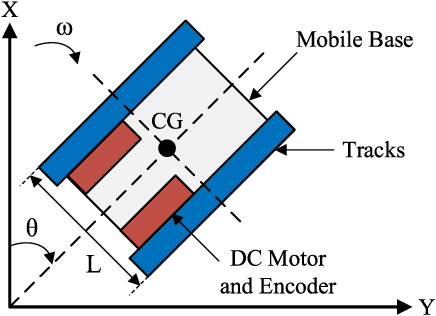
This paper develops a Closed-Loop Error Learning Control (CLELC) algorithm for feedback linearizable systems with experimental validation on a mobile robot. Traditional feedback and feedforward controllers are designed based on the nominal model by using Feedback Linearization Control (FLC) method. Then, an intelligent controller is designed based on sliding mode learning algorithm that utilizes closed-loop error dynamics to learn the system behavior. The controllers are working in parallel, and the intelligent controller can gradually replace the feedback controller from the control of the system. In addition to the stability of the sliding mode learning algorithm, the closed-loop stability of an $n$th order feedback linearizable system is proven. The simulation results demonstrate that CLELC algorithm can improve control performance (e.g., smaller rise time, settling time and overshoot) in the absence of uncertainties, and also provides robust control performance in the presence of uncertainties as compared to traditional FLC method. To test the efficiency and efficacy of CLELC algorithm, the trajectory tracking problem of a tracked mobile robot is studied in real-time. The experimental results demonstrate that CLELC algorithm ensures high-accurate trajectory tracking performance than traditional FLC method.
* 8 pages, 5 figures
Automated Evolutionary Approach for the Design of Composite Machine Learning Pipelines
Jun 26, 2021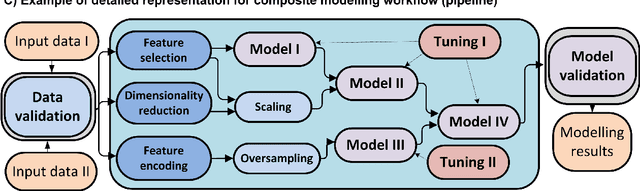
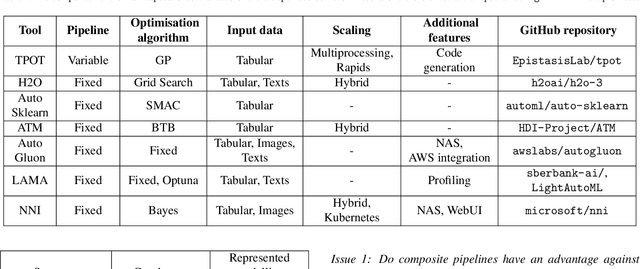
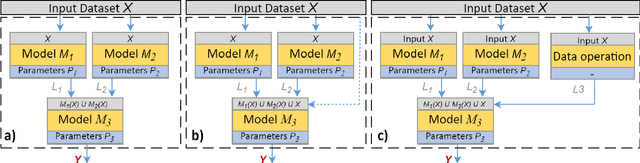
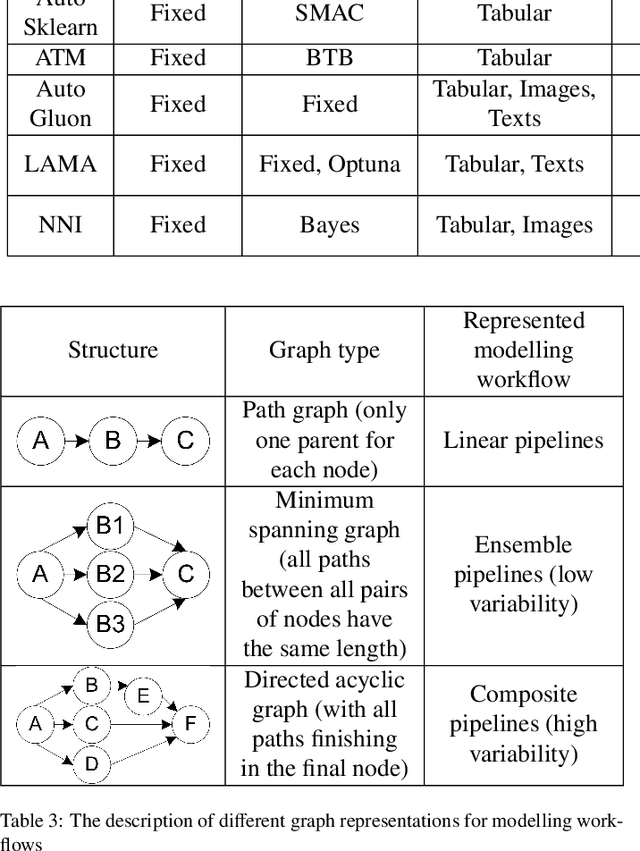
The effectiveness of the machine learning methods for real-world tasks depends on the proper structure of the modeling pipeline. The proposed approach is aimed to automate the design of composite machine learning pipelines, which is equivalent to computation workflows that consist of models and data operations. The approach combines key ideas of both automated machine learning and workflow management systems. It designs the pipelines with a customizable graph-based structure, analyzes the obtained results, and reproduces them. The evolutionary approach is used for the flexible identification of pipeline structure. The additional algorithms for sensitivity analysis, atomization, and hyperparameter tuning are implemented to improve the effectiveness of the approach. Also, the software implementation on this approach is presented as an open-source framework. The set of experiments is conducted for the different datasets and tasks (classification, regression, time series forecasting). The obtained results confirm the correctness and effectiveness of the proposed approach in the comparison with the state-of-the-art competitors and baseline solutions.
Automatic Fairness Testing of Neural Classifiers through Adversarial Sampling
Jul 29, 2021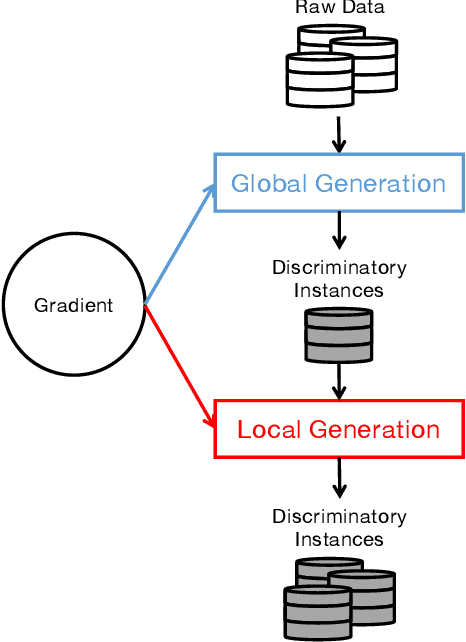

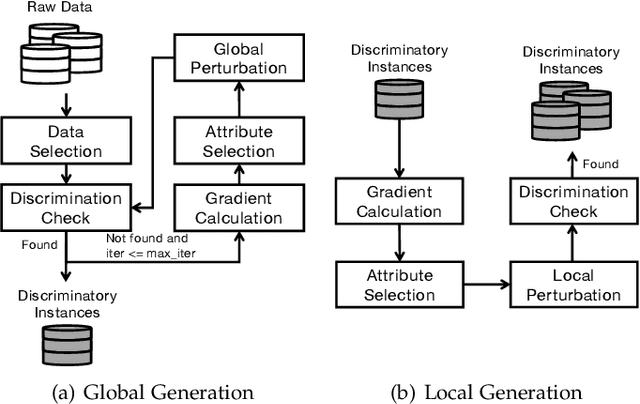
Although deep learning has demonstrated astonishing performance in many applications, there are still concerns about its dependability. One desirable property of deep learning applications with societal impact is fairness (i.e., non-discrimination). Unfortunately, discrimination might be intrinsically embedded into the models due to the discrimination in the training data. As a countermeasure, fairness testing systemically identifies discriminatory samples, which can be used to retrain the model and improve the model's fairness. Existing fairness testing approaches however have two major limitations. Firstly, they only work well on traditional machine learning models and have poor performance (e.g., effectiveness and efficiency) on deep learning models. Secondly, they only work on simple structured (e.g., tabular) data and are not applicable for domains such as text. In this work, we bridge the gap by proposing a scalable and effective approach for systematically searching for discriminatory samples while extending existing fairness testing approaches to address a more challenging domain, i.e., text classification. Compared with state-of-the-art methods, our approach only employs lightweight procedures like gradient computation and clustering, which is significantly more scalable and effective. Experimental results show that on average, our approach explores the search space much more effectively (9.62 and 2.38 times more than the state-of-the-art methods respectively on tabular and text datasets) and generates much more discriminatory samples (24.95 and 2.68 times) within a same reasonable time. Moreover, the retrained models reduce discrimination by 57.2% and 60.2% respectively on average.
Federated Learning in Robotic and Autonomous Systems
Apr 20, 2021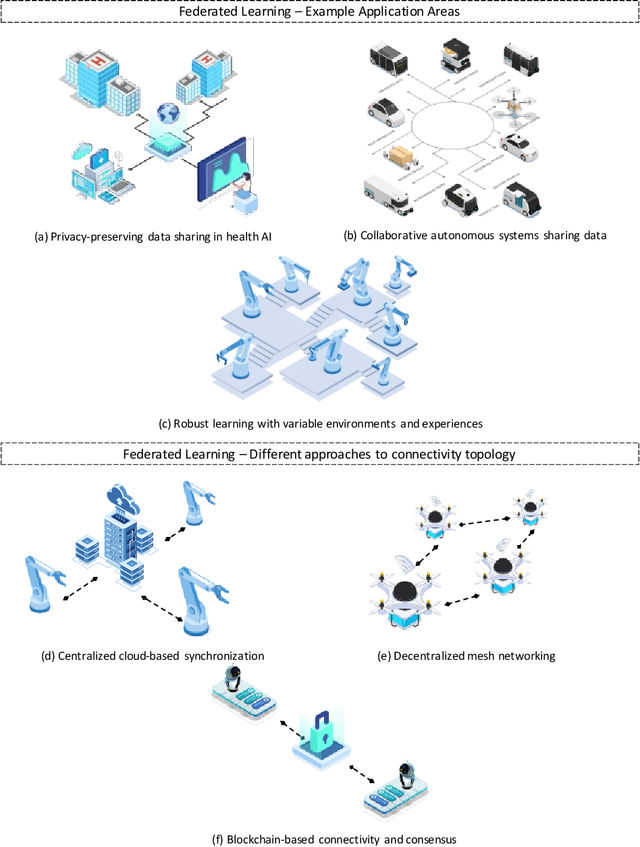
Autonomous systems are becoming inherently ubiquitous with the advancements of computing and communication solutions enabling low-latency offloading and real-time collaboration of distributed devices. Decentralized technologies with blockchain and distributed ledger technologies (DLTs) are playing a key role. At the same time, advances in deep learning (DL) have significantly raised the degree of autonomy and level of intelligence of robotic and autonomous systems. While these technological revolutions were taking place, raising concerns in terms of data security and end-user privacy has become an inescapable research consideration. Federated learning (FL) is a promising solution to privacy-preserving DL at the edge, with an inherently distributed nature by learning on isolated data islands and communicating only model updates. However, FL by itself does not provide the levels of security and robustness required by today's standards in distributed autonomous systems. This survey covers applications of FL to autonomous robots, analyzes the role of DLT and FL for these systems, and introduces the key background concepts and considerations in current research.
PocketVAE: A Two-step Model for Groove Generation and Control
Jul 11, 2021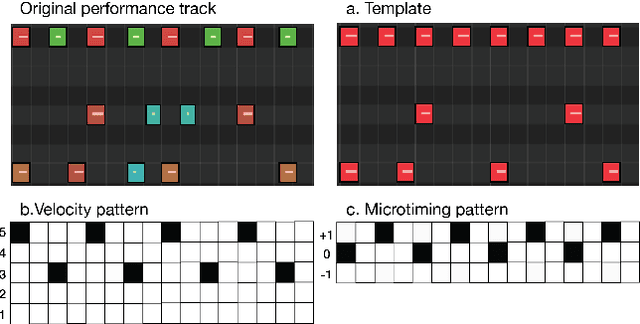

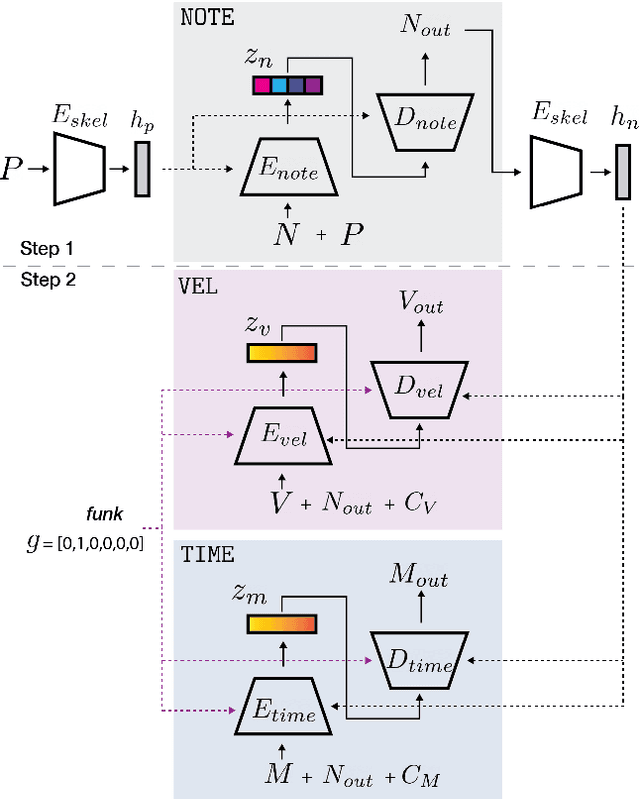
Creating a good drum track to imitate a skilled performer in digital audio workstations (DAWs) can be a time-consuming process, especially for those unfamiliar with drums. In this work, we introduce PocketVAE, a groove generation system that applies grooves to users' rudimentary MIDI tracks, i.e, templates. Grooves can be either transferred from a reference track, generated randomly or with conditions, such as genres. Our system, consisting of different modules for each groove component, takes a two-step approach that is analogous to a music creation process. First, the note module updates the user template through addition and deletion of notes; Second, the velocity and microtiming modules add details to this generated note score. In order to model the drum notes, we apply a discrete latent representation method via Vector Quantized Variational Autoencoder (VQ-VAE), as drum notes have a discrete property, unlike velocity and microtiming values. We show that our two-step approach and the usage of a discrete encoding space improves the learning of the original data distribution. Additionally, we discuss the benefit of incorporating control elements - genre, velocity and microtiming patterns - into the model.
Feature Trajectory Dynamic Time Warping for Clustering of Speech Segments
Oct 30, 2018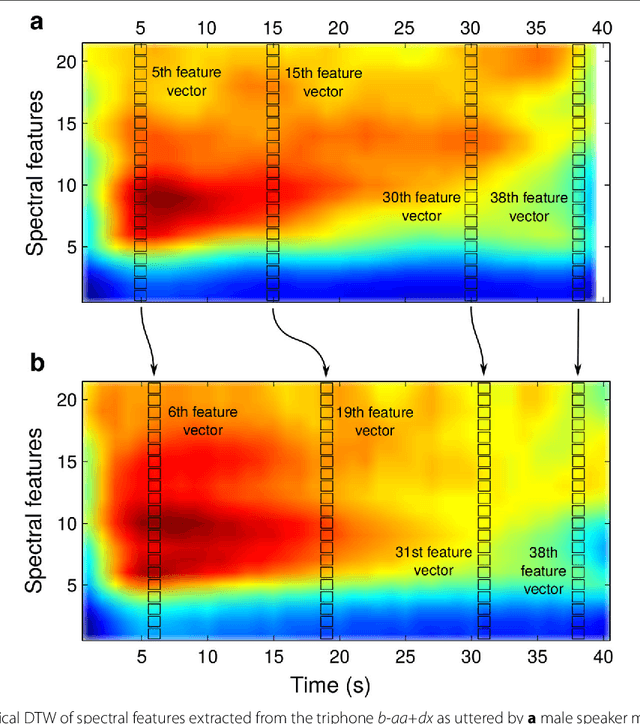

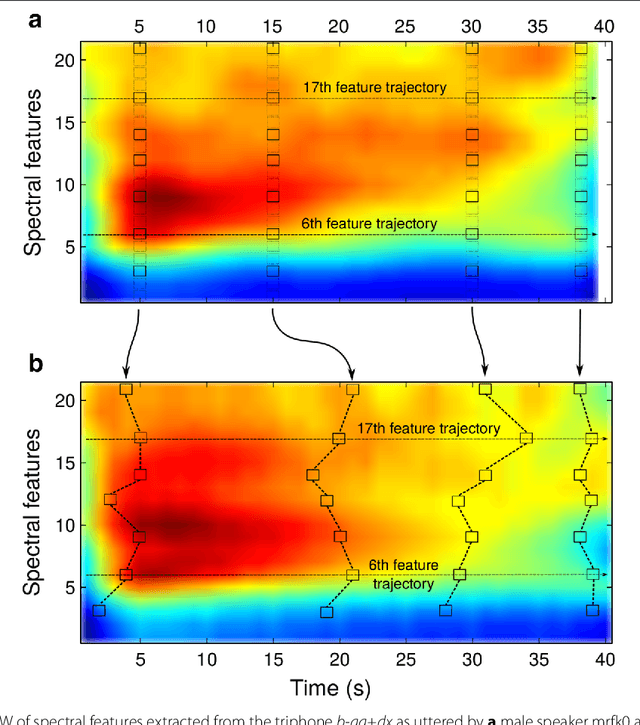
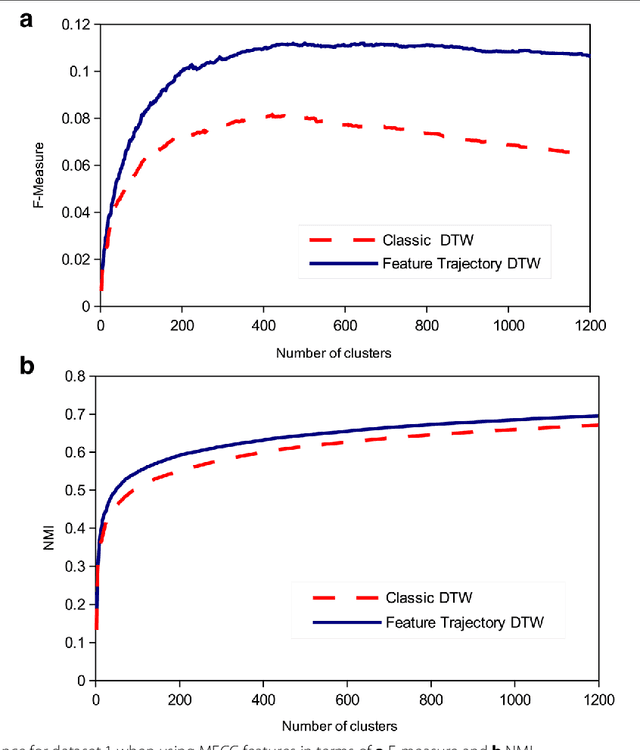
Dynamic time warping (DTW) can be used to compute the similarity between two sequences of generally differing length. We propose a modification to DTW that performs individual and independent pairwise alignment of feature trajectories. The modified technique, termed feature trajectory dynamic time warping (FTDTW), is applied as a similarity measure in the agglomerative hierarchical clustering of speech segments. Experiments using MFCC and PLP parametrisations extracted from TIMIT and from the Spoken Arabic Digit Dataset (SADD) show consistent and statistically significant improvements in the quality of the resulting clusters in terms of F-measure and normalised mutual information (NMI).
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jun 22, 2021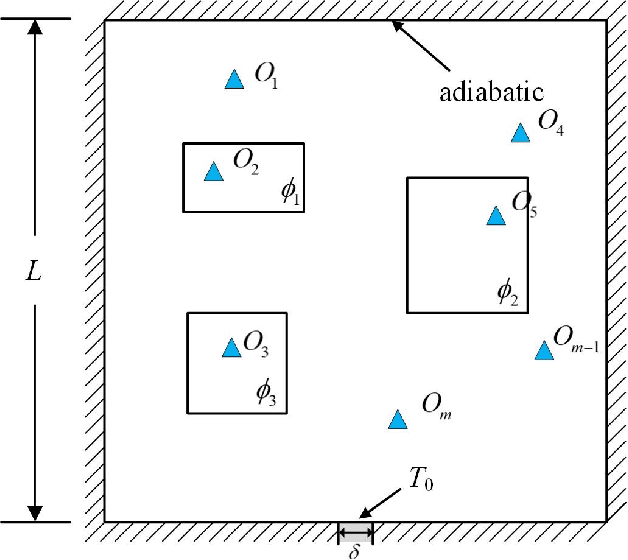
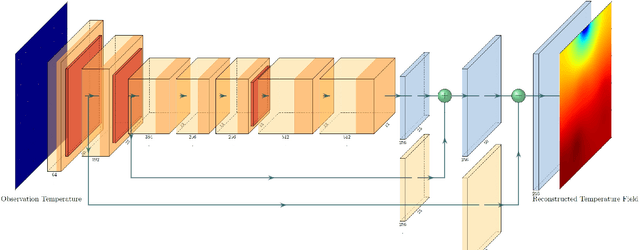
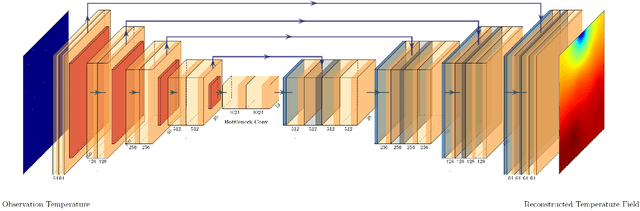
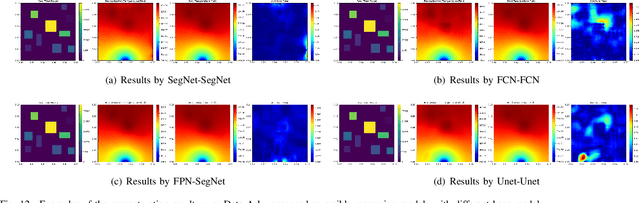
Temperature monitoring during the life time of heat-source components in engineering systems becomes essential to ensure the normal work and even the long working life of the heat sources. However, prior methods, which mainly use the interpolate estimation, require large amounts of temperature tensors for an accurate estimation. To solve this problem, this work develops a novel physics-informed deep surrogate models for temperature field reconstruction. First, we defines the temperature field reconstruction task of heat-source systems. Then, this work develops the deep surrogate model mapping for the proposed task. Finally, considering the physical properties of heat transfer, this work proposes four different losses and joint learns the deep surrogate model with these losses. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness and efficiency of the proposed physics-informed deep surrogate models for temperature field reconstruction.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021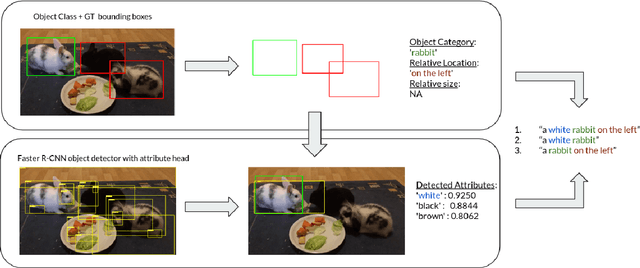



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
Multi-Step Greedy and Approximate Real Time Dynamic Programming
Sep 10, 2019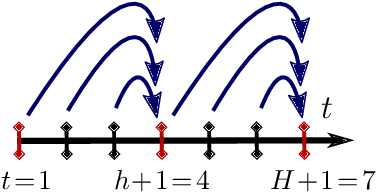

Real Time Dynamic Programming (RTDP) is a well-known Dynamic Programming (DP) based algorithm that combines planning and learning to find an optimal policy for an MDP. It is a planning algorithm because it uses the MDP's model (reward and transition functions) to calculate a 1-step greedy policy w.r.t.~an optimistic value function, by which it acts. It is a learning algorithm because it updates its value function only at the states it visits while interacting with the environment. As a result, unlike DP, RTDP does not require uniform access to the state space in each iteration, which makes it particularly appealing when the state space is large and simultaneously updating all the states is not computationally feasible. In this paper, we study a generalized multi-step greedy version of RTDP, which we call $h$-RTDP, in its exact form, as well as in three approximate settings: approximate model, approximate value updates, and approximate state abstraction. We analyze the sample, computation, and space complexities of $h$-RTDP and establish that increasing $h$ improves sample and space complexity, with the cost of additional offline computational operations. For the approximate cases, we prove that the asymptotic performance of $h$-RTDP is the same as that of a corresponding approximate DP -- the best one can hope for without further assumptions on the approximation errors. $h$-RTDP is the first algorithm with a provably improved sample complexity when increasing the lookahead horizon.