 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ProfileSR-GAN: A GAN based Super-Resolution Method for Generating High-Resolution Load Profiles
Jul 18, 2021
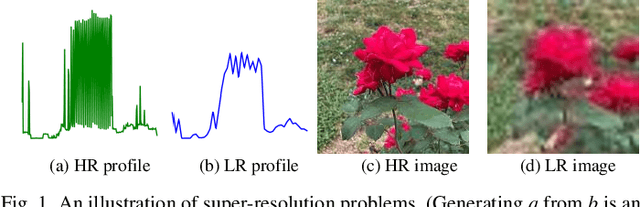
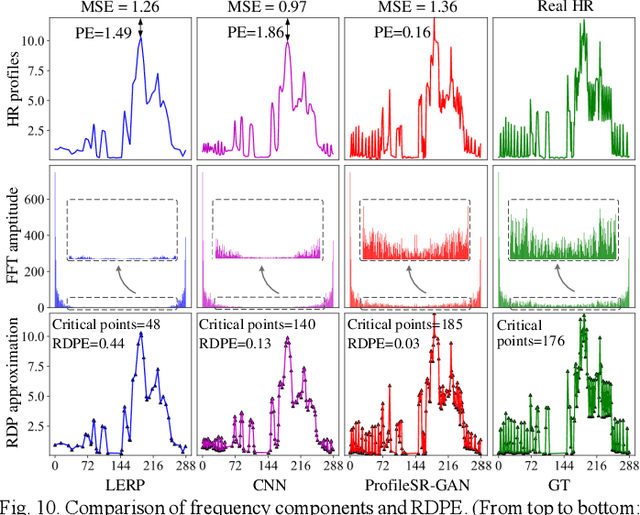
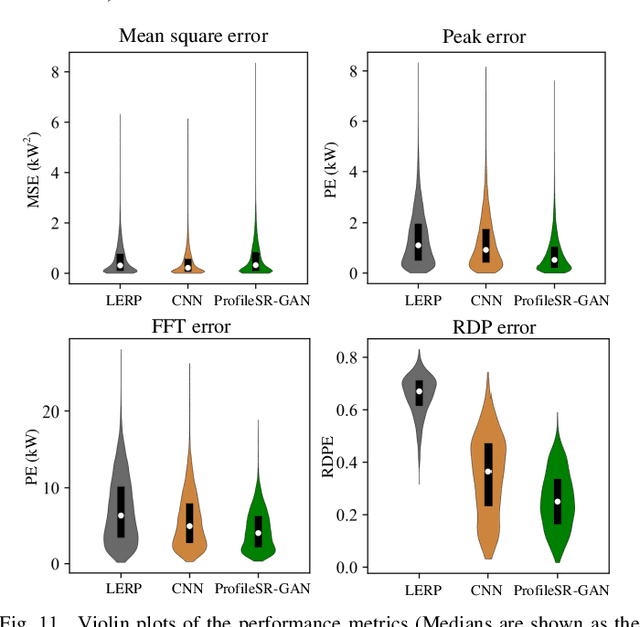
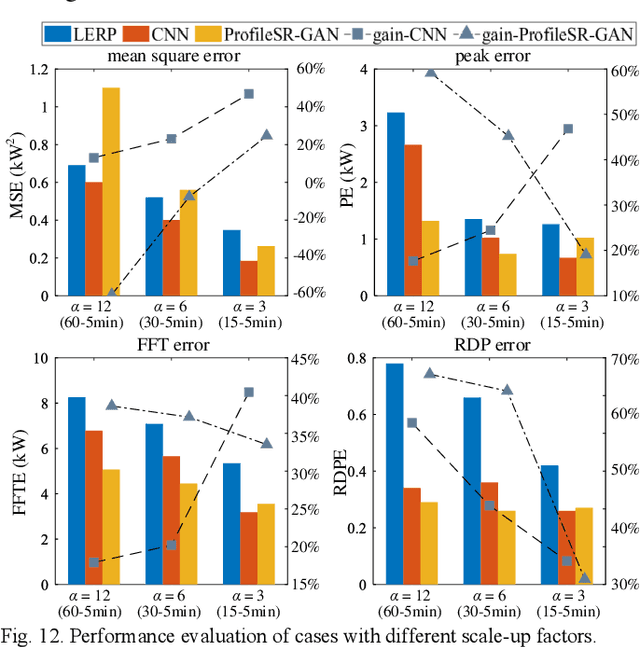
It is a common practice for utilities to down-sample smart meter measurements from high resolution (e.g. 1-min or 1-sec) to low resolution (e.g. 15-, 30- or 60-min) to lower the data transmission and storage cost. However, down-sampling can remove high-frequency components from time-series load profiles, making them unsuitable for in-depth studies such as quasi-static power flow analysis or non-intrusive load monitoring (NILM). Thus, in this paper, we propose ProfileSR-GAN: a Generative Adversarial Network (GAN) based load profile super-resolution (LPSR) framework for restoring high-frequency components lost through the smoothing effect of the down-sampling process. The LPSR problem is formulated as a Maximum-a-Prior problem. When training the ProfileSR-GAN generator network, to make the generated profiles more realistic, we introduce two new shape-related losses in addition to conventionally used content loss: adversarial loss and feature-matching loss. Moreover, a new set of shape-based evaluation metrics are proposed to evaluate the realisticness of the generated profiles. Simulation results show that ProfileSR-GAN outperforms Mean-Square Loss based methods in all shape-based metrics. The successful application in NILM further demonstrates that ProfileSR-GAN is effective in recovering high-resolution realistic waveforms.
Time-Optimal Path Tracking for Industrial Robots: A Dynamic Model-Free Reinforcement Learning Approach
Aug 03, 2019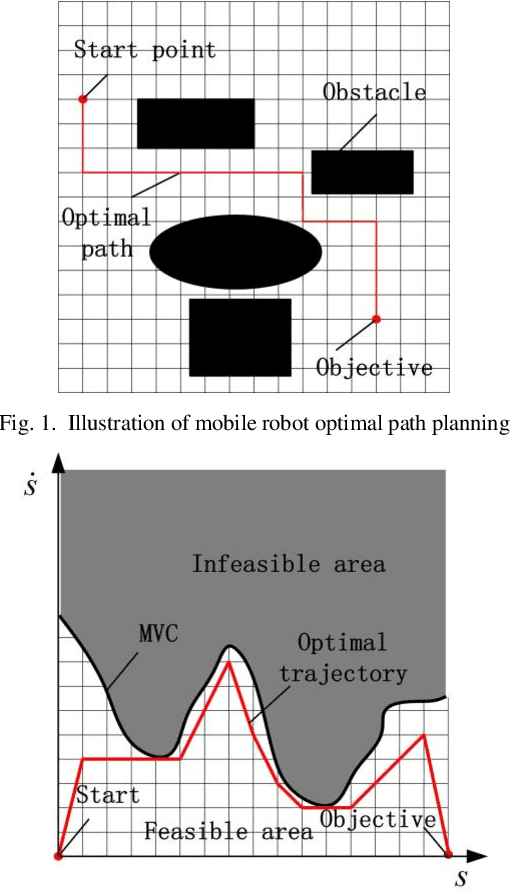

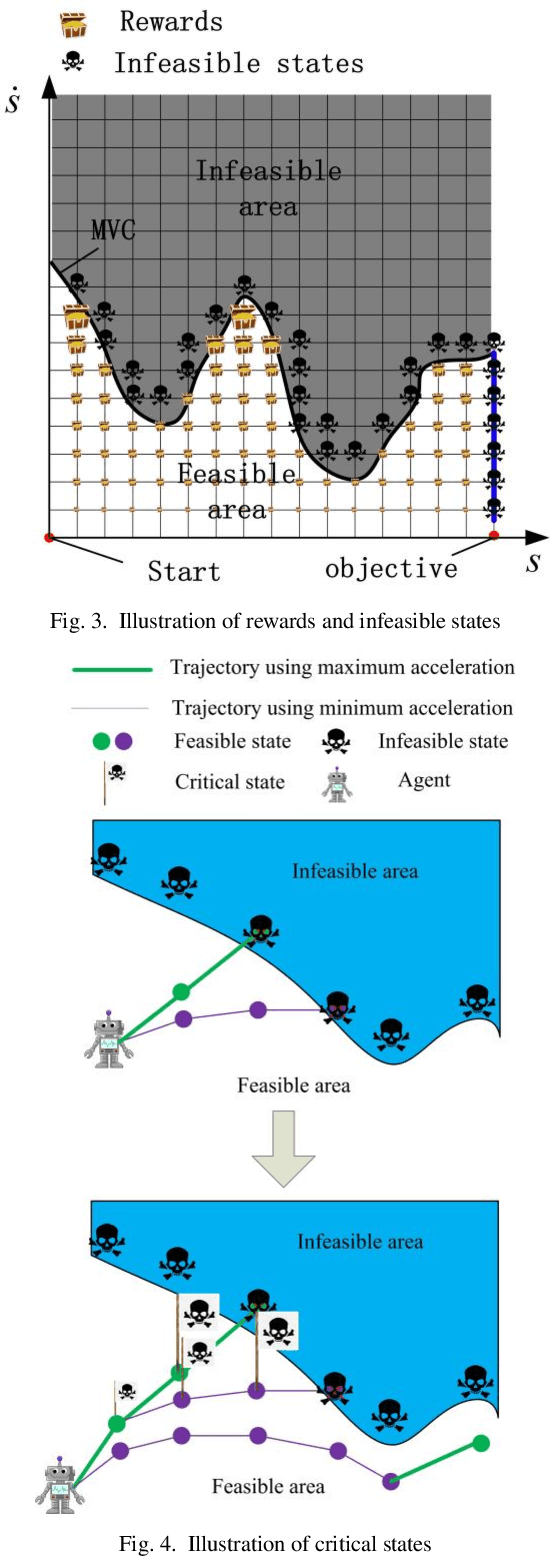

In pursuit of the time-optimal path tracking (TOPT) trajectory of a robot manipulator along a preset path, a beforehand identified robot dynamic model is usually used to obtain the required optimal trajectory for perfect tracking. However, due to the inevitable model-plant mismatch, there may be a big error between the actually measured torques and the calculated torques by the dynamic model, which causes the obtained trajectory to be suboptimal or even be infeasible by exceeding given limits. This paper presents a TOPT-oriented SARSA algorithm (TOPTO-SARSA) and a two-step method for finding the time-optimal motion and ensuring the feasibility : Firstly, using TOPTO-SARSA to find a safe trajectory that satisfies the kinematic constraints through the interaction between reinforcement learning agent and kinematic model. Secondly, using TOPTO-SARSA to find the optimal trajectory through the interaction between the agent and the real world, and assure the actually measured torques satisfy the given limits at the last interaction. The effectiveness of the proposed algorithm has been verified through experiments on a 6-DOF robot manipulator.
Imbalanced Big Data Oversampling: Taxonomy, Algorithms, Software, Guidelines and Future Directions
Jul 24, 2021
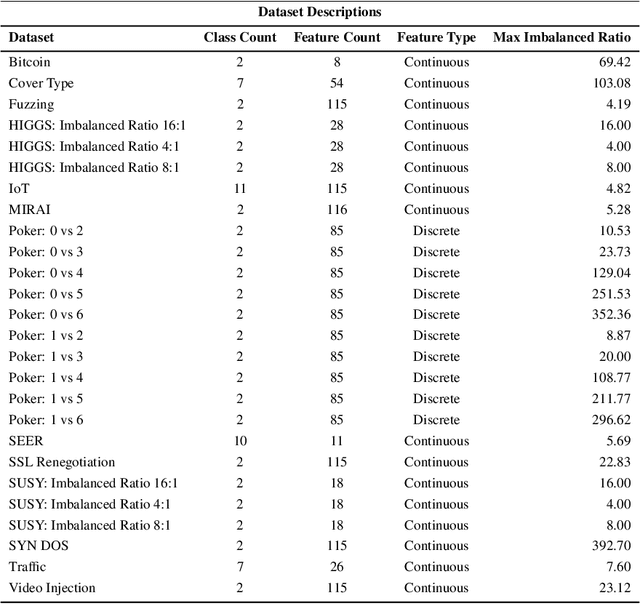
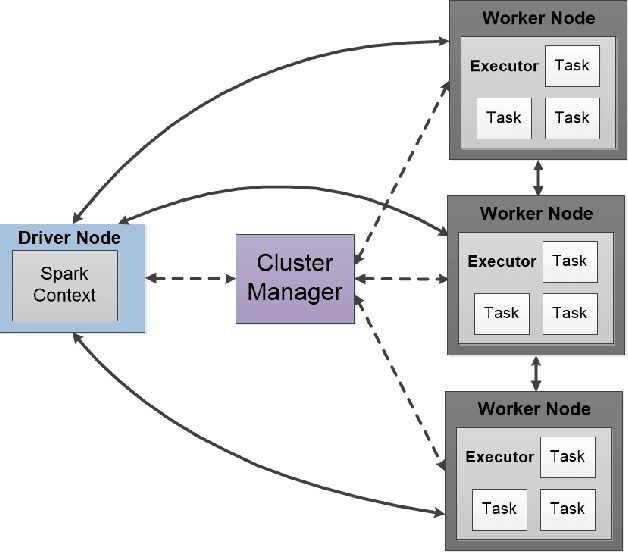

Learning from imbalanced data is among the most challenging areas in contemporary machine learning. This becomes even more difficult when considered the context of big data that calls for dedicated architectures capable of high-performance processing. Apache Spark is a highly efficient and popular architecture, but it poses specific challenges for algorithms to be implemented for it. While oversampling algorithms are an effective way for handling class imbalance, they have not been designed for distributed environments. In this paper, we propose a holistic look on oversampling algorithms for imbalanced big data. We discuss the taxonomy of oversampling algorithms and their mechanisms used to handle skewed class distributions. We introduce a Spark library with 14 state-of-the-art oversampling algorithms implemented and evaluate their efficacy via extensive experimental study. Using binary and multi-class massive data sets, we analyze the effectiveness of oversampling algorithms and their relationships with different types of classifiers. We evaluate the trade-off between accuracy and time complexity of oversampling algorithms, as well as their scalability when increasing the size of data. This allows us to gain insight into the usefulness of specific components of oversampling algorithms for big data, as well as formulate guidelines and recommendations for designing future resampling approaches for massive imbalanced data. Our library can be downloaded from https://github.com/fsleeman/spark-class-balancing.git.
Autoencoder based Randomized Learning of Feedforward Neural Networks for Regression
Jul 04, 2021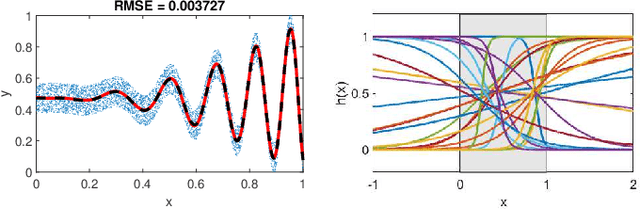
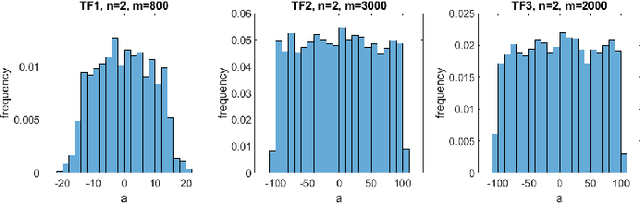
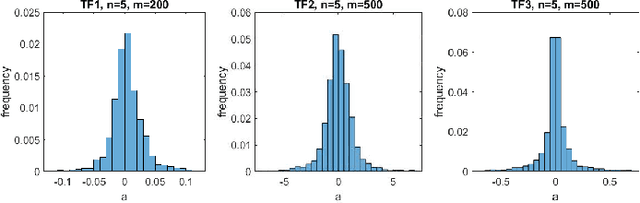
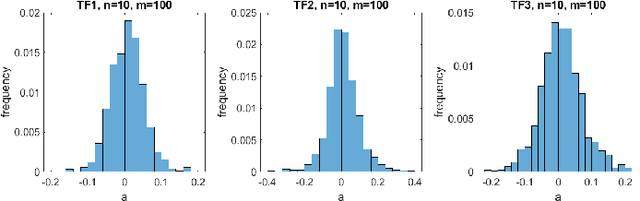
Feedforward neural networks are widely used as universal predictive models to fit data distribution. Common gradient-based learning, however, suffers from many drawbacks making the training process ineffective and time-consuming. Alternative randomized learning does not use gradients but selects hidden node parameters randomly. This makes the training process extremely fast. However, the problem in randomized learning is how to determine the random parameters. A recently proposed method uses autoencoders for unsupervised parameter learning. This method showed superior performance on classification tasks. In this work, we apply this method to regression problems, and, finding that it has some drawbacks, we show how to improve it. We propose a learning method of autoencoders that controls the produced random weights. We also propose how to determine the biases of hidden nodes. We empirically compare autoencoder based learning with other randomized learning methods proposed recently for regression and find that despite the proposed improvement of the autoencoder based learning, it does not outperform its competitors in fitting accuracy. Moreover, the method is much more complex than its competitors.
Sample Efficient Social Navigation Using Inverse Reinforcement Learning
Jun 18, 2021
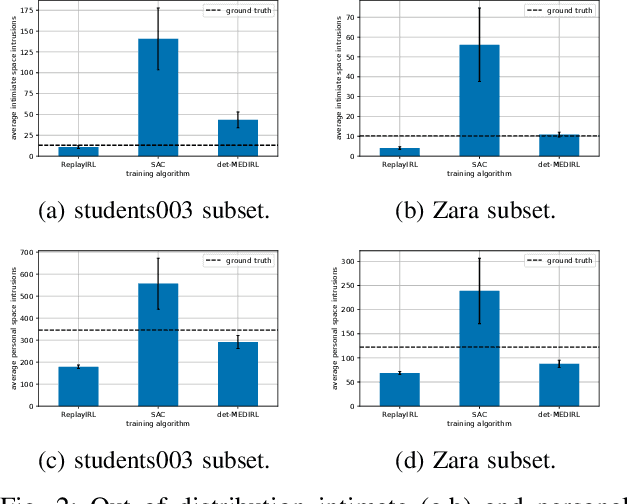
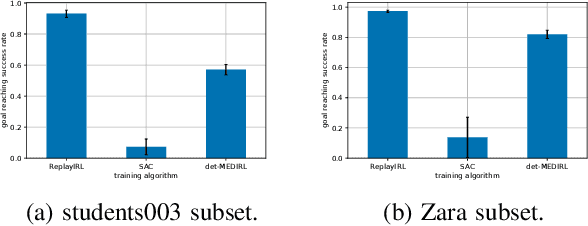
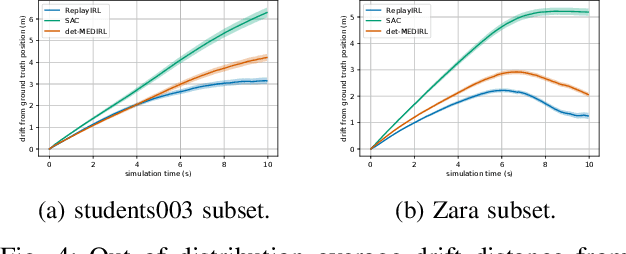
In this paper, we present an algorithm to efficiently learn socially-compliant navigation policies from observations of human trajectories. As mobile robots come to inhabit and traffic social spaces, they must account for social cues and behave in a socially compliant manner. We focus on learning such cues from examples. We describe an inverse reinforcement learning based algorithm which learns from human trajectory observations without knowing their specific actions. We increase the sample-efficiency of our approach over alternative methods by leveraging the notion of a replay buffer (found in many off-policy reinforcement learning methods) to eliminate the additional sample complexity associated with inverse reinforcement learning. We evaluate our method by training agents using publicly available pedestrian motion data sets and compare it to related methods. We show that our approach yields better performance while also decreasing training time and sample complexity.
Inductive Guided Filter: Real-time Deep Image Matting with Weakly Annotated Masks on Mobile Devices
May 16, 2019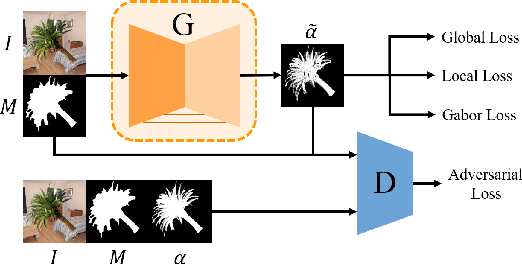
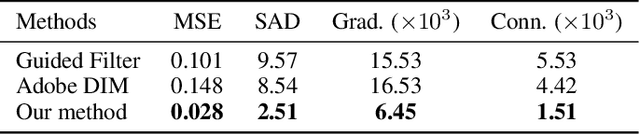
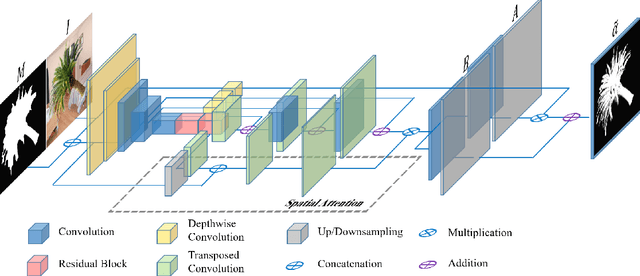
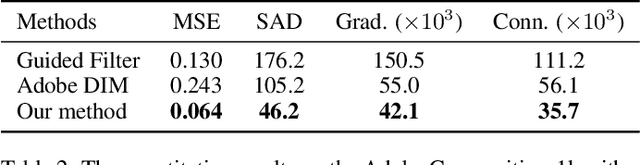
Recently, significant progress has been achieved in deep image matting. Most of the classical image matting methods are time-consuming and require an ideal trimap which is difficult to attain in practice. A high efficient image matting method based on a weakly annotated mask is in demand for mobile applications. In this paper, we propose a novel method based on Deep Learning and Guided Filter, called Inductive Guided Filter, which can tackle the real-time general image matting task on mobile devices. We design a lightweight hourglass network to parameterize the original Guided Filter method that takes an image and a weakly annotated mask as input. Further, the use of Gabor loss is proposed for training networks for complicated textures in image matting. Moreover, we create an image matting dataset MAT-2793 with a variety of foreground objects. Experimental results demonstrate that our proposed method massively reduces running time with robust accuracy.
Nonperturbative renormalization for the neural network-QFT correspondence
Aug 03, 2021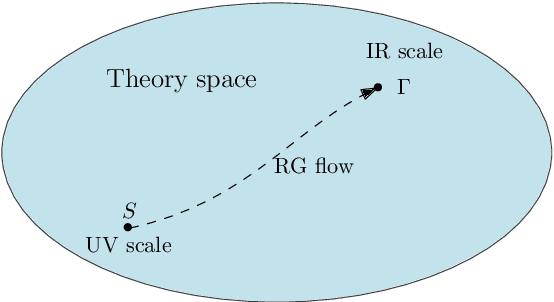
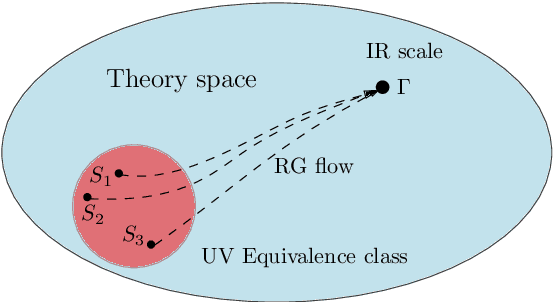
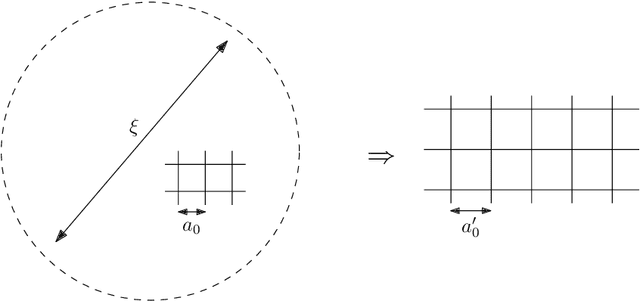
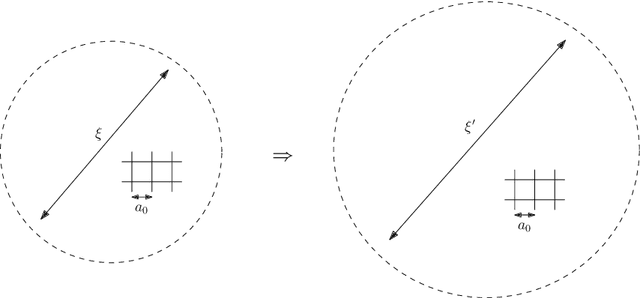
In a recent work arXiv:2008.08601, Halverson, Maiti and Stoner proposed a description of neural networks in terms of a Wilsonian effective field theory. The infinite-width limit is mapped to a free field theory, while finite $N$ corrections are taken into account by interactions (non-Gaussian terms in the action). In this paper, we study two related aspects of this correspondence. First, we comment on the concepts of locality and power-counting in this context. Indeed, these usual space-time notions may not hold for neural networks (since inputs can be arbitrary), however, the renormalization group provides natural notions of locality and scaling. Moreover, we comment on several subtleties, for example, that data components may not have a permutation symmetry: in that case, we argue that random tensor field theories could provide a natural generalization. Second, we improve the perturbative Wilsonian renormalization from arXiv:2008.08601 by providing an analysis in terms of the nonperturbative renormalization group using the Wetterich-Morris equation. An important difference with usual nonperturbative RG analysis is that only the effective (IR) 2-point function is known, which requires setting the problem with care. Our aim is to provide a useful formalism to investigate neural networks behavior beyond the large-width limit (i.e.~far from Gaussian limit) in a nonperturbative fashion. A major result of our analysis is that changing the standard deviation of the neural network weight distribution can be interpreted as a renormalization flow in the space of networks. We focus on translations invariant kernels and provide preliminary numerical results.
Time series cluster kernels to exploit informative missingness and incomplete label information
Jul 10, 2019
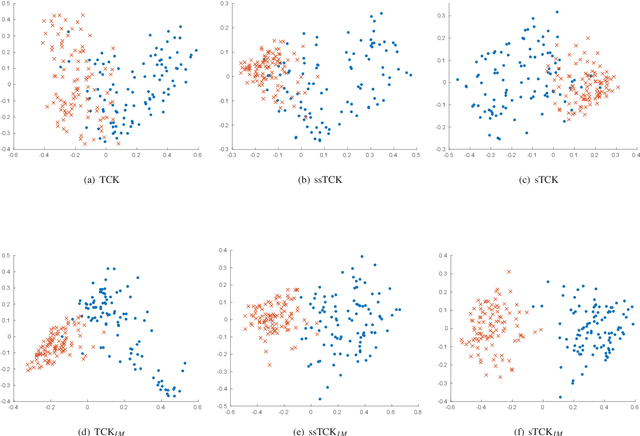
The time series cluster kernel (TCK) provides a powerful tool for analysing multivariate time series subject to missing data. TCK is designed using an ensemble learning approach in which Bayesian mixture models form the base models. Because of the Bayesian approach, TCK can naturally deal with missing values without resorting to imputation and the ensemble strategy ensures robustness to hyperparameters, making it particularly well suited for unsupervised learning. However, TCK assumes missing at random and that the underlying missingness mechanism is ignorable, i.e. uninformative, an assumption that does not hold in many real-world applications, such as e.g. medicine. To overcome this limitation, we present a kernel capable of exploiting the potentially rich information in the missing values and patterns, as well as the information from the observed data. In our approach, we create a representation of the missing pattern, which is incorporated into mixed mode mixture models in such a way that the information provided by the missing patterns is effectively exploited. Moreover, we also propose a semi-supervised kernel, capable of taking advantage of incomplete label information to learn more accurate similarities. Experiments on benchmark data, as well as a real-world case study of patients described by longitudinal electronic health record data who potentially suffer from hospital-acquired infections, demonstrate the effectiveness of the proposed methods.
A Database for Research on Detection and Enhancement of Speech Transmitted over HF links
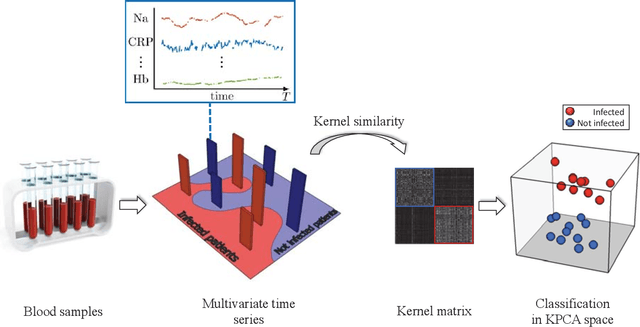
Jun 04, 2021
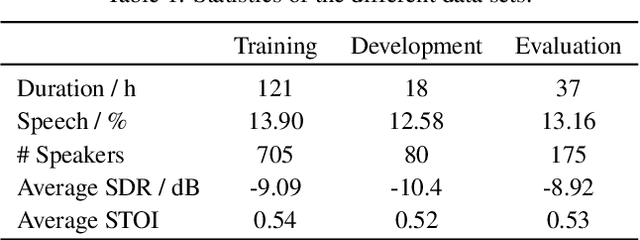
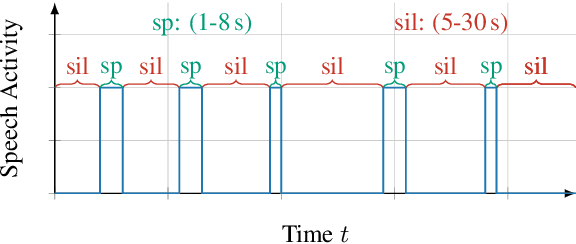

In this paper we present an open database for the development of detection and enhancement algorithms of speech transmitted over HF radio channels. It consists of audio samples recorded by various receivers at different locations across Europe, all monitoring the same single-sideband modulated transmission from a base station in Paderborn, Germany. Transmitted and received speech signals are precisely time aligned to offer parallel data for supervised training of deep learning based detection and enhancement algorithms. For the task of speech activity detection two exemplary baseline systems are presented, one based on statistical methods employing a multi-stage Wiener filter with minimum statistics noise floor estimation, and the other relying on a deep learning approach.
Admissible Time Series Motif Discovery with Missing Data
Feb 15, 2018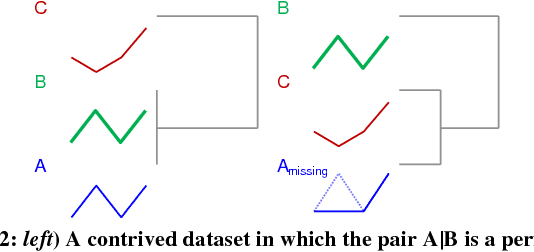
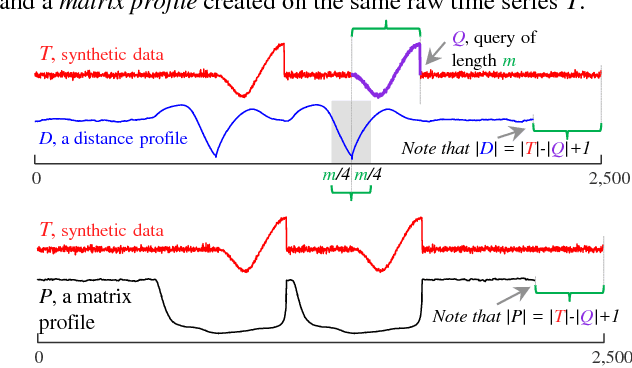
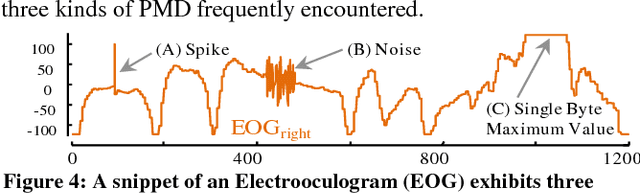
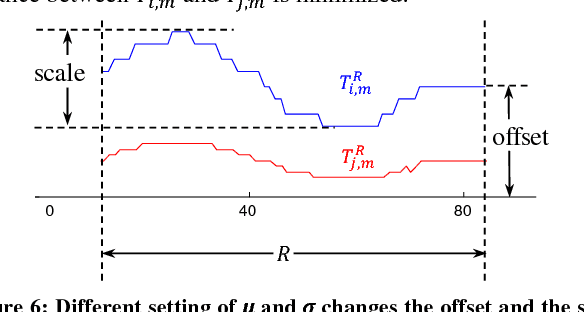
The discovery of time series motifs has emerged as one of the most useful primitives in time series data mining. Researchers have shown its utility for exploratory data mining, summarization, visualization, segmentation, classification, clustering, and rule discovery. Although there has been more than a decade of extensive research, there is still no technique to allow the discovery of time series motifs in the presence of missing data, despite the well-documented ubiquity of missing data in scientific, industrial, and medical datasets. In this work, we introduce a technique for motif discovery in the presence of missing data. We formally prove that our method is admissible, producing no false negatives. We also show that our method can piggy-back off the fastest known motif discovery method with a small constant factor time/space overhead. We will demonstrate our approach on diverse datasets with varying amounts of missing data