 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Mixed Integer Least-Squares Formulation of the GNSS Snapshot Positioning Problem
Jan 10, 2021
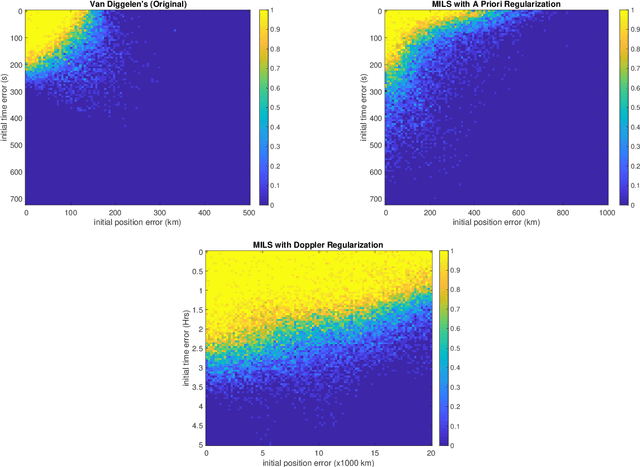
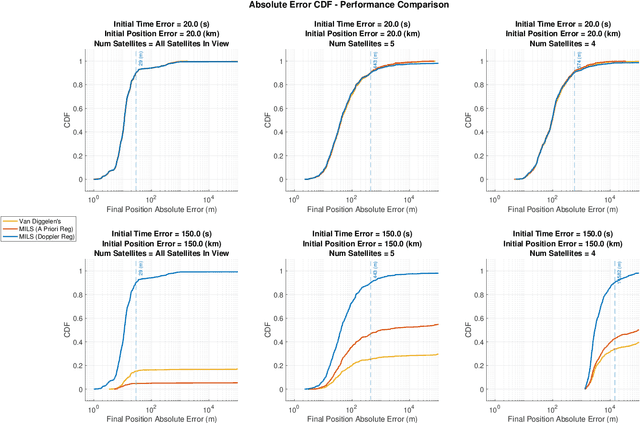
This paper presents a formulation of Snapshot Positioning as a mixed-integer least-squares problem. In snapshot positioning one estimates a position from code-phase and possibly Doppler observations of a Global Navigation Satellite Systems (GNSS) without knowing the time of departure (time stamp) of the codes. Solving the problem allows a receiver to determine a fix from short radio-frequency snapshots missing the time-stamp information embedded in the GNSS data stream. This is used to reduced the time to first fix in some receivers, and it is used in certain wildlife trackers. This paper presents two new formulations of the problem and an algorithm that solves the resulting mixed-integer least-squares problems. We also show that the new formulations can produce fixes even with huge initial errors, much larger than permitted in Van Diggelen's widely-cited coarse-time navigation method.
A Meta-Learning Control Algorithm with Provable Finite-Time Guarantees
Sep 03, 2020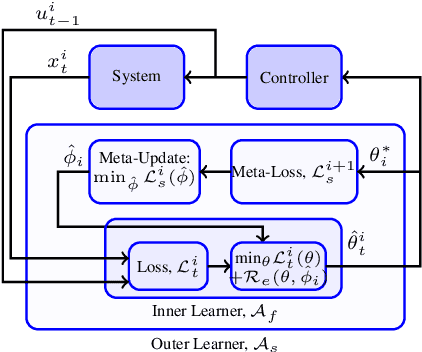
In this work we provide provable regret guarantees for an online meta-learning control algorithm in an iterative control setting, where in each iteration the system to be controlled is a linear deterministic system that is different and unknown, the cost for the controller in an iteration is a general additive cost function and the control input is required to be constrained, which if violated incurs an additional cost. We prove (i) that the algorithm achieves a regret for the controller cost and constraint violation that are $O(T^{3/4})$ for an episode of duration $T$ with respect to the best policy that satisfies the control input control constraints and (ii) that the average of the regret for the controller cost and constraint violation with respect to the same policy vary as $O((1+\log(N)/N)T^{3/4})$ with the number of iterations $N$, showing that the worst regret for the learning within an iteration continuously improves with experience of more iterations.
Time-Optimal Path Tracking for Industrial Robots: A Dynamic Model-Free Reinforcement Learning Approach
Aug 03, 2019

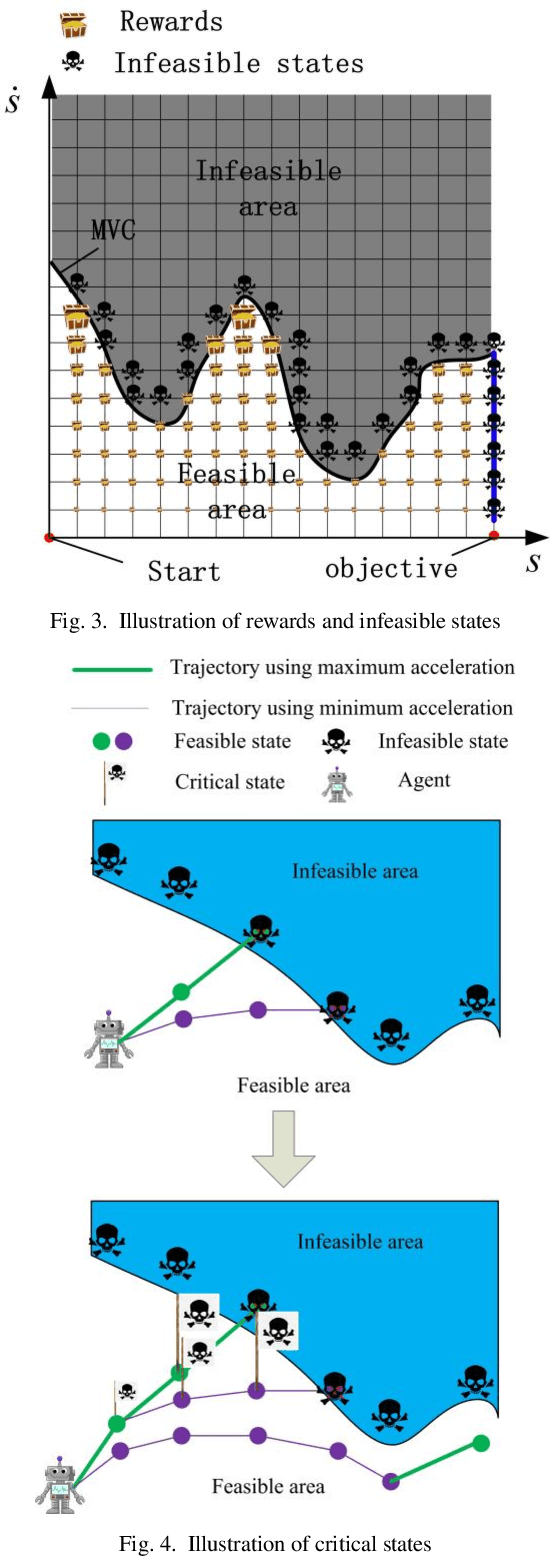

In pursuit of the time-optimal path tracking (TOPT) trajectory of a robot manipulator along a preset path, a beforehand identified robot dynamic model is usually used to obtain the required optimal trajectory for perfect tracking. However, due to the inevitable model-plant mismatch, there may be a big error between the actually measured torques and the calculated torques by the dynamic model, which causes the obtained trajectory to be suboptimal or even be infeasible by exceeding given limits. This paper presents a TOPT-oriented SARSA algorithm (TOPTO-SARSA) and a two-step method for finding the time-optimal motion and ensuring the feasibility : Firstly, using TOPTO-SARSA to find a safe trajectory that satisfies the kinematic constraints through the interaction between reinforcement learning agent and kinematic model. Secondly, using TOPTO-SARSA to find the optimal trajectory through the interaction between the agent and the real world, and assure the actually measured torques satisfy the given limits at the last interaction. The effectiveness of the proposed algorithm has been verified through experiments on a 6-DOF robot manipulator.
SilGAN: Generating driving maneuvers for scenario-based software-in-the-loop testing
Jul 05, 2021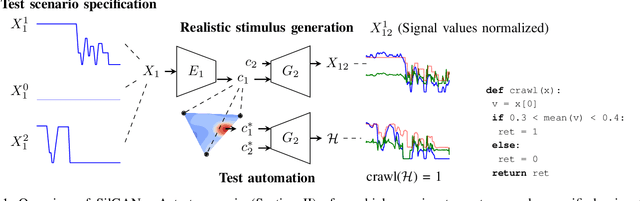
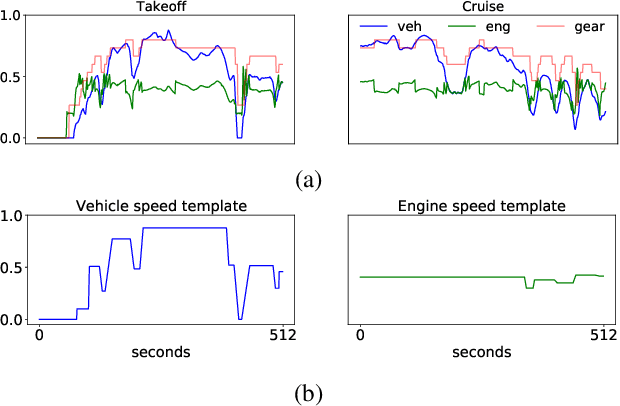
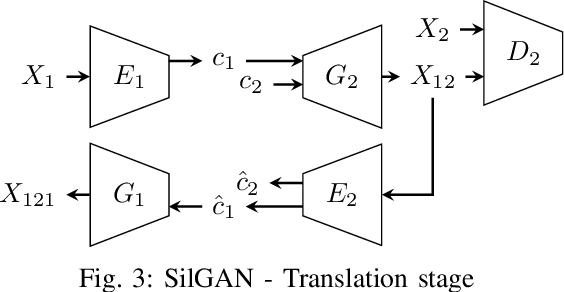
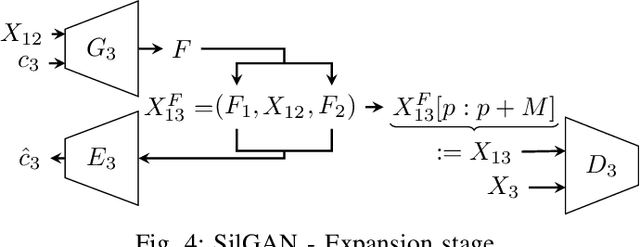
Automotive software testing continues to rely largely upon expensive field tests to ensure quality because alternatives like simulation-based testing are relatively immature. As a step towards lowering reliance on field tests, we present SilGAN, a deep generative model that eases specification, stimulus generation, and automation of automotive software-in-the-loop testing. The model is trained using data recorded from vehicles in the field. Upon training, the model uses a concise specification for a driving scenario to generate realistic vehicle state transitions that can occur during such a scenario. Such authentic emulation of internal vehicle behavior can be used for rapid, systematic and inexpensive testing of vehicle control software. In addition, by presenting a targeted method for searching through the information learned by the model, we show how a test objective like code coverage can be automated. The data driven end-to-end testing pipeline that we present vastly expands the scope and credibility of automotive simulation-based testing. This reduces time to market while helping maintain required standards of quality.
Web-Scale Generic Object Detection at Microsoft Bing
Jul 05, 2021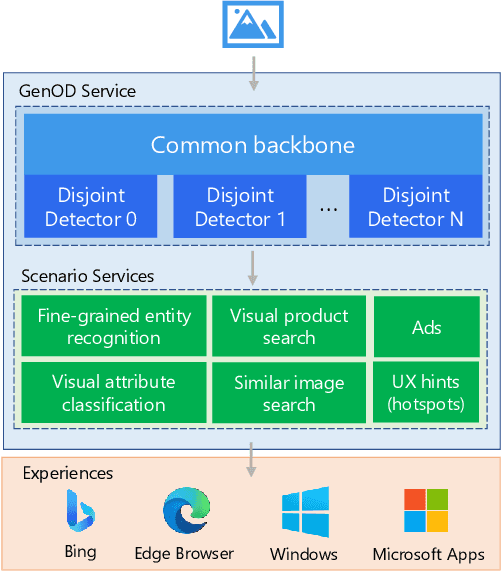

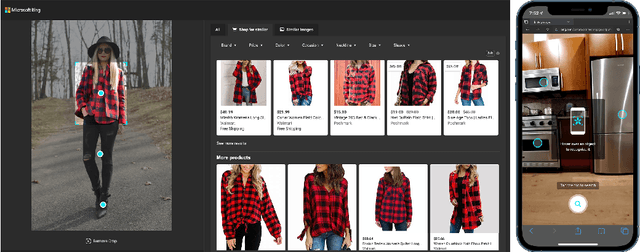

In this paper, we present Generic Object Detection (GenOD), one of the largest object detection systems deployed to a web-scale general visual search engine that can detect over 900 categories for all Microsoft Bing Visual Search queries in near real-time. It acts as a fundamental visual query understanding service that provides object-centric information and shows gains in multiple production scenarios, improving upon domain-specific models. We discuss the challenges of collecting data, training, deploying and updating such a large-scale object detection model with multiple dependencies. We discuss a data collection pipeline that reduces per-bounding box labeling cost by 81.5% and latency by 61.2% while improving on annotation quality. We show that GenOD can improve weighted average precision by over 20% compared to multiple domain-specific models. We also improve the model update agility by nearly 2 times with the proposed disjoint detector training compared to joint fine-tuning. Finally we demonstrate how GenOD benefits visual search applications by significantly improving object-level search relevance by 54.9% and user engagement by 59.9%.
Medical Code Prediction from Discharge Summary: Document to Sequence BERT using Sequence Attention
Jul 05, 2021
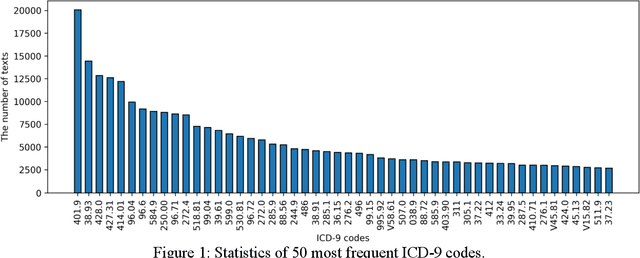
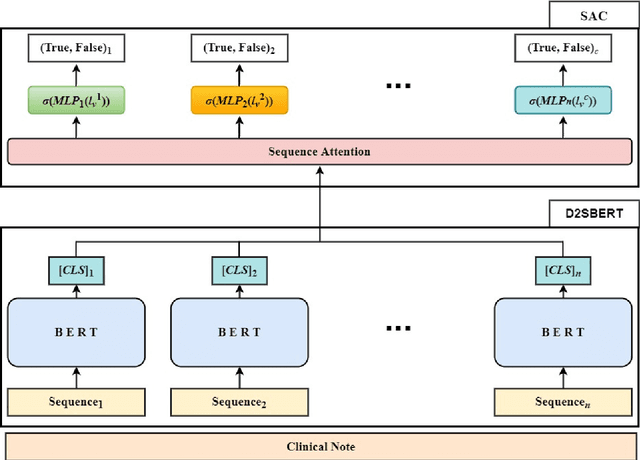

Clinical notes are unstructured text generated by clinicians during patient encounters. Clinical notes are usually accompanied by a set of metadata codes from the International Classification of Diseases(ICD). ICD code is an important code used in various operations, including insurance, reimbursement, medical diagnosis, etc. Therefore, it is important to classify ICD codes quickly and accurately. However, annotating these codes is costly and time-consuming. So we propose a model based on bidirectional encoder representations from transformers (BERT) using the sequence attention method for automatic ICD code assignment. We evaluate our approach on the medical information mart for intensive care III (MIMIC-III) benchmark dataset. Our model achieved performance of macro-averaged F1: 0.62898 and micro-averaged F1: 0.68555 and is performing better than a performance of the state-of-the-art model using the MIMIC-III dataset. The contribution of this study proposes a method of using BERT that can be applied to documents and a sequence attention method that can capture important sequence in-formation appearing in documents.
Fine-Grained Classroom Activity Detection from Audio with Neural Networks
Jul 29, 2021
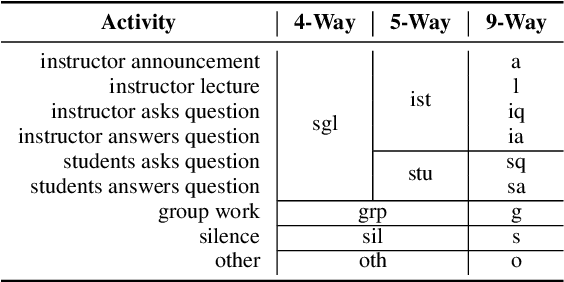
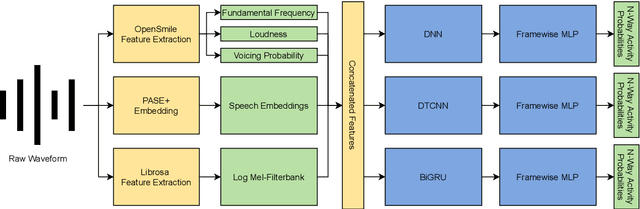
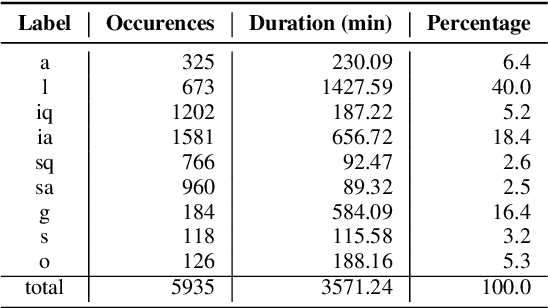
Instructors are increasingly incorporating student-centered learning techniques in their classrooms to improve learning outcomes. In addition to lecture, these class sessions involve forms of individual and group work, and greater rates of student-instructor interaction. Quantifying classroom activity is a key element of accelerating the evaluation and refinement of innovative teaching practices, but manual annotation does not scale. In this manuscript, we present advances to the young application area of automatic classroom activity detection from audio. Using a university classroom corpus with nine activity labels (e.g., "lecture," "group work," "student question"), we propose and evaluate deep fully connected, convolutional, and recurrent neural network architectures, comparing the performance of mel-filterbank, OpenSmile, and self-supervised acoustic features. We compare 9-way classification performance with 5-way and 4-way simplifications of the task and assess two types of generalization: (1) new class sessions from previously seen instructors, and (2) previously unseen instructors. We obtain strong results on the new fine-grained task and state-of-the-art on the 4-way task: our best model obtains frame-level error rates of 6.2%, 7.7% and 28.0% when generalizing to unseen instructors for the 4-way, 5-way, and 9-way classification tasks, respectively (relative reductions of 35.4%, 48.3% and 21.6% over a strong baseline). When estimating the aggregate time spent on classroom activities, our average root mean squared error is 1.64 minutes per class session, a 54.9% relative reduction over the baseline.
Dynamic Resource Management for Providing QoS in Drone Delivery Systems
Mar 06, 2021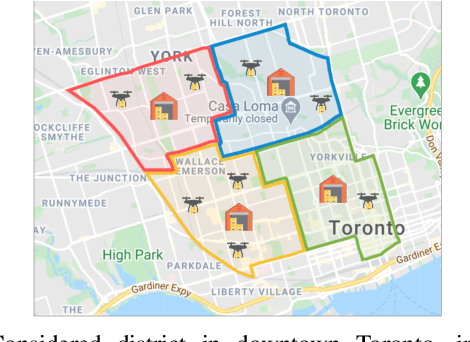
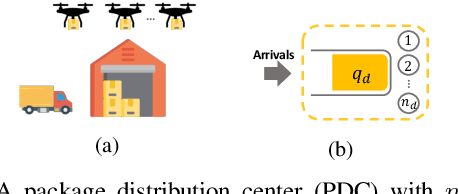
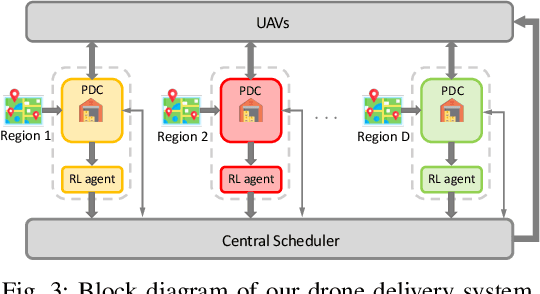
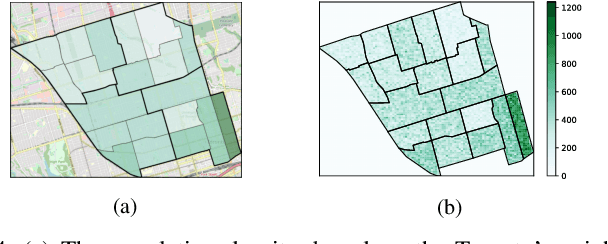
Drones have been considered as an alternative means of package delivery to reduce the delivery cost and time. Due to the battery limitations, the drones are best suited for last-mile delivery, i.e., the delivery from the package distribution centers (PDCs) to the customers. Since a typical delivery system consists of multiple PDCs, each having random and time-varying demands, the dynamic drone-to-PDC allocation would be of great importance in meeting the demand in an efficient manner. In this paper, we study the dynamic UAV assignment problem for a drone delivery system with the goal of providing measurable Quality of Service (QoS) guarantees. We adopt a queueing theoretic approach to model the customer-service nature of the problem. Furthermore, we take a deep reinforcement learning approach to obtain a dynamic policy for the re-allocation of the UAVs. This policy guarantees a probabilistic upper-bound on the queue length of the packages waiting in each PDC, which is beneficial from both the service provider's and the customers' viewpoints. We evaluate the performance of our proposed algorithm by considering three broad arrival classes, including Bernoulli, Time-Varying Bernoulli, and Markov-Modulated Bernoulli arrivals. Our results show that the proposed method outperforms the baselines, particularly in scenarios with Time-Varying and Markov-Modulated Bernoulli arrivals, which are more representative of real-world demand patterns. Moreover, our algorithm satisfies the QoS constraints in all the studied scenarios while minimizing the average number of UAVs in use.
Admissible Time Series Motif Discovery with Missing Data
Feb 15, 2018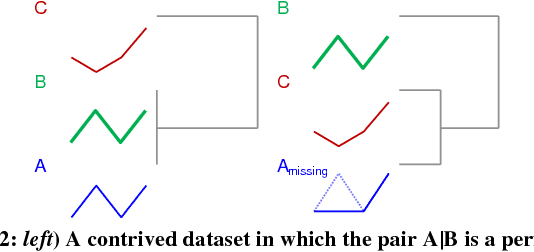
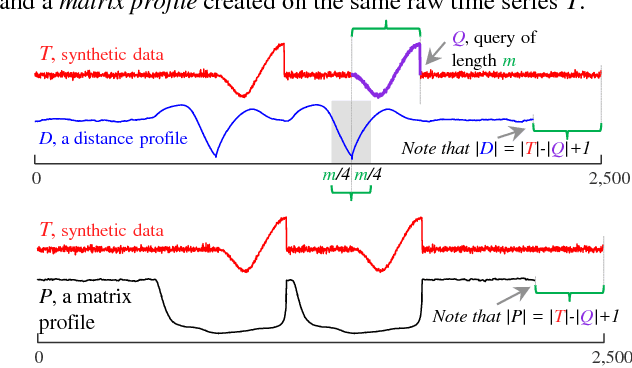
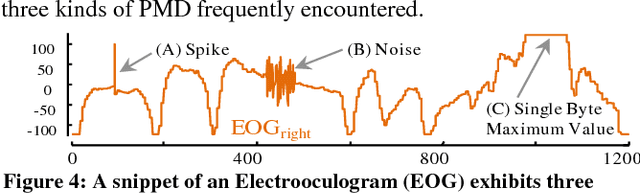
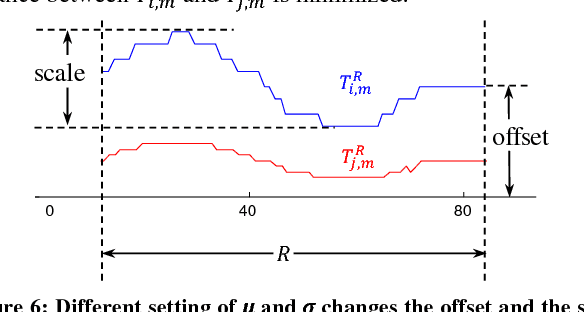
The discovery of time series motifs has emerged as one of the most useful primitives in time series data mining. Researchers have shown its utility for exploratory data mining, summarization, visualization, segmentation, classification, clustering, and rule discovery. Although there has been more than a decade of extensive research, there is still no technique to allow the discovery of time series motifs in the presence of missing data, despite the well-documented ubiquity of missing data in scientific, industrial, and medical datasets. In this work, we introduce a technique for motif discovery in the presence of missing data. We formally prove that our method is admissible, producing no false negatives. We also show that our method can piggy-back off the fastest known motif discovery method with a small constant factor time/space overhead. We will demonstrate our approach on diverse datasets with varying amounts of missing data
Text-Aware Predictive Monitoring of Business Processes
Apr 21, 2021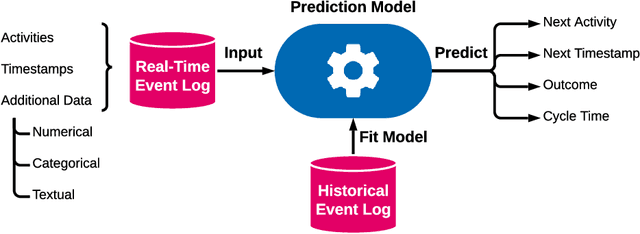

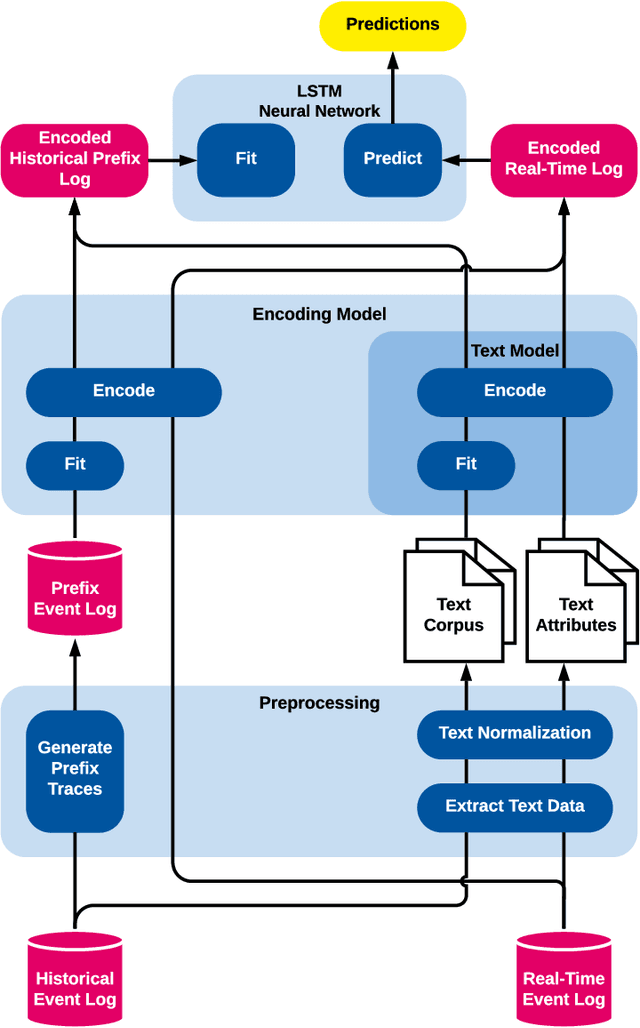
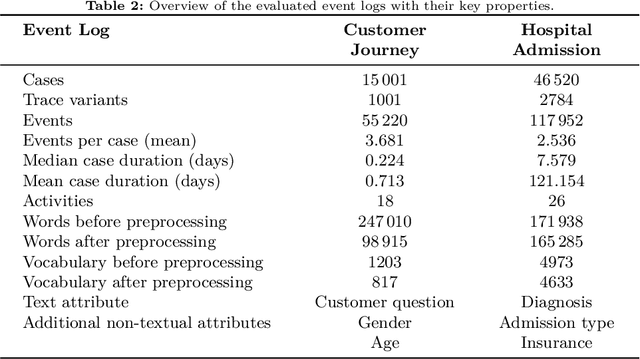
The real-time prediction of business processes using historical event data is an important capability of modern business process monitoring systems. Existing process prediction methods are able to also exploit the data perspective of recorded events, in addition to the control-flow perspective. However, while well-structured numerical or categorical attributes are considered in many prediction techniques, almost no technique is able to utilize text documents written in natural language, which can hold information critical to the prediction task. In this paper, we illustrate the design, implementation, and evaluation of a novel text-aware process prediction model based on Long Short-Term Memory (LSTM) neural networks and natural language models. The proposed model can take categorical, numerical and textual attributes in event data into account to predict the activity and timestamp of the next event, the outcome, and the cycle time of a running process instance. Experiments show that the text-aware model is able to outperform state-of-the-art process prediction methods on simulated and real-world event logs containing textual data.