 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Plan via a Multi-Step Policy Regression Method
Jun 18, 2021
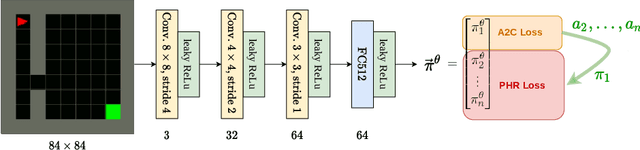
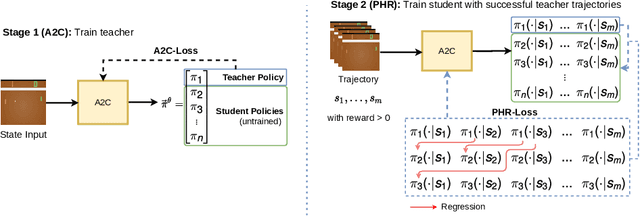

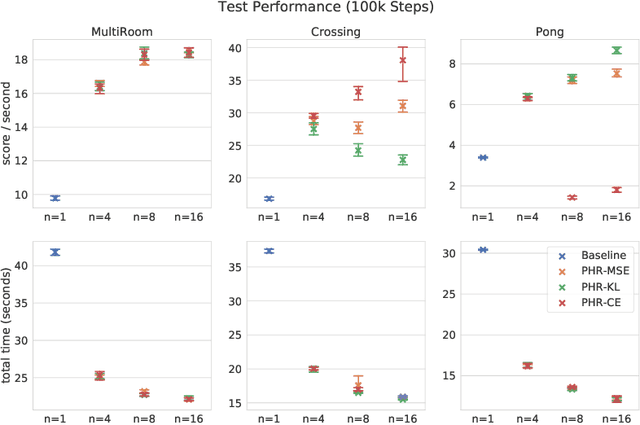
We propose a new approach to increase inference performance in environments that require a specific sequence of actions in order to be solved. This is for example the case for maze environments where ideally an optimal path is determined. Instead of learning a policy for a single step, we want to learn a policy that can predict n actions in advance. Our proposed method called policy horizon regression (PHR) uses knowledge of the environment sampled by A2C to learn an n dimensional policy vector in a policy distillation setup which yields n sequential actions per observation. We test our method on the MiniGrid and Pong environments and show drastic speedup during inference time by successfully predicting sequences of actions on a single observation.
Optimized Object Tracking Technique Using Kalman Filter
Mar 07, 2021
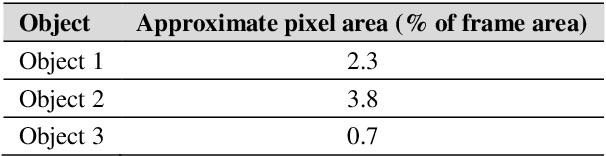
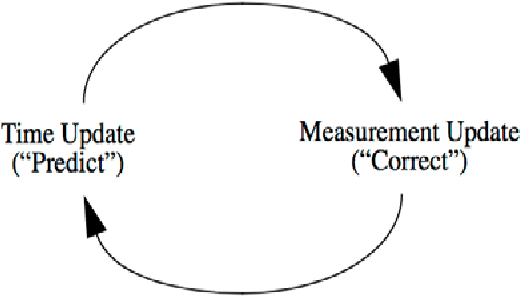
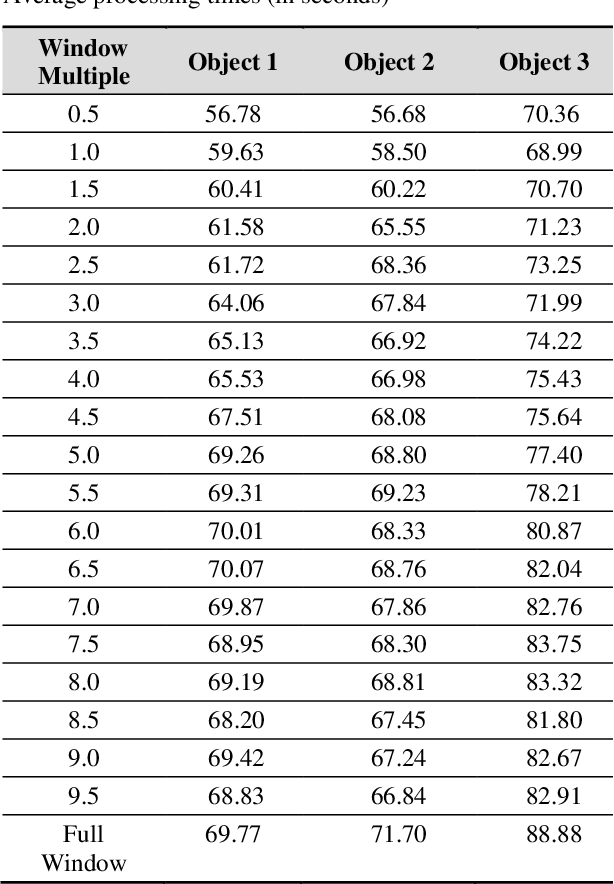
This paper focused on the design of an optimized object tracking technique which would minimize the processing time required in the object detection process while maintaining accuracy in detecting the desired moving object in a cluttered scene. A Kalman filter based cropped image is used for the image detection process as the processing time is significantly less to detect the object when a search window is used that is smaller than the entire video frame. This technique was tested with various sizes of the window in the cropping process. MATLAB was used to design and test the proposed method. This paper found that using a cropped image with 2.16 multiplied by the largest dimension of the object resulted in significantly faster processing time while still providing a high success rate of detection and a detected center of the object that was reasonably close to the actual center.
* 10 pages, 14 figures, published in J. Mechatron. Electr. Power Veh. Technol 07 (2016) 57-66
Robot in a China Shop: Using Reinforcement Learning for Location-Specific Navigation Behaviour
Jun 02, 2021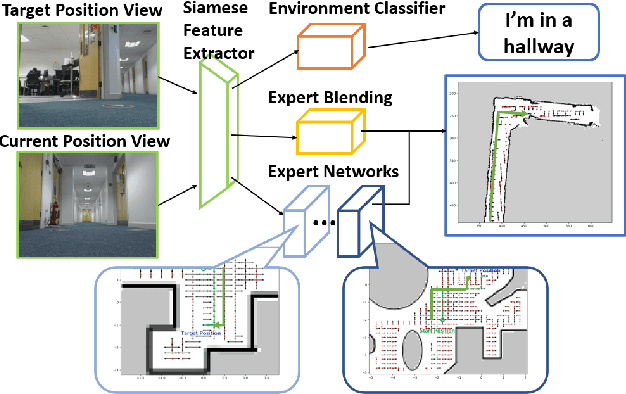
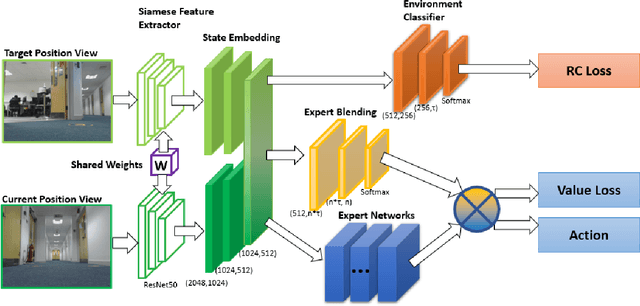
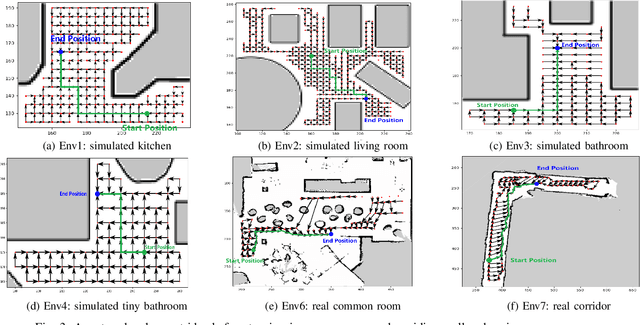
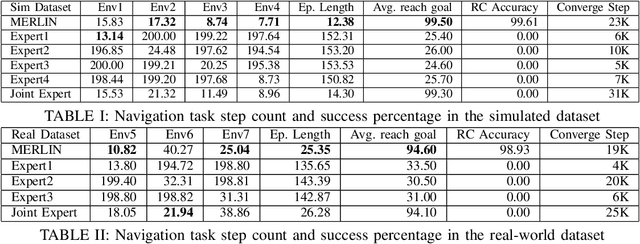
Robots need to be able to work in multiple different environments. Even when performing similar tasks, different behaviour should be deployed to best fit the current environment. In this paper, We propose a new approach to navigation, where it is treated as a multi-task learning problem. This enables the robot to learn to behave differently in visual navigation tasks for different environments while also learning shared expertise across environments. We evaluated our approach in both simulated environments as well as real-world data. Our method allows our system to converge with a 26% reduction in training time, while also increasing accuracy.
On Contrastive Representations of Stochastic Processes
Jun 18, 2021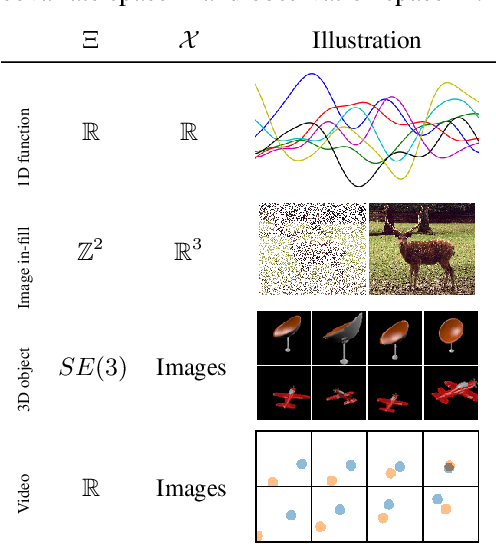


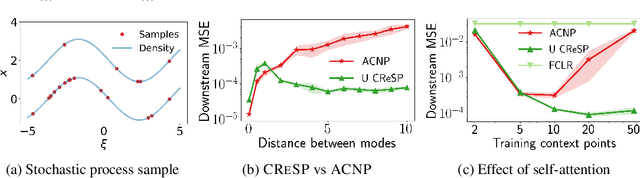
Learning representations of stochastic processes is an emerging problem in machine learning with applications from meta-learning to physical object models to time series. Typical methods rely on exact reconstruction of observations, but this approach breaks down as observations become high-dimensional or noise distributions become complex. To address this, we propose a unifying framework for learning contrastive representations of stochastic processes (CRESP) that does away with exact reconstruction. We dissect potential use cases for stochastic process representations, and propose methods that accommodate each. Empirically, we show that our methods are effective for learning representations of periodic functions, 3D objects and dynamical processes. Our methods tolerate noisy high-dimensional observations better than traditional approaches, and the learned representations transfer to a range of downstream tasks.
Real-time calibration of coherent-state receivers: learning by trial and error
Jan 28, 2020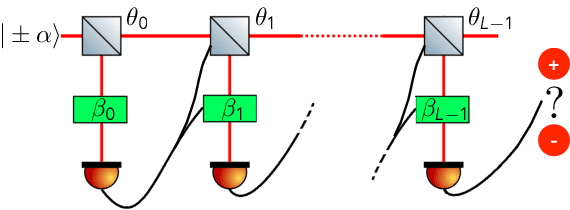
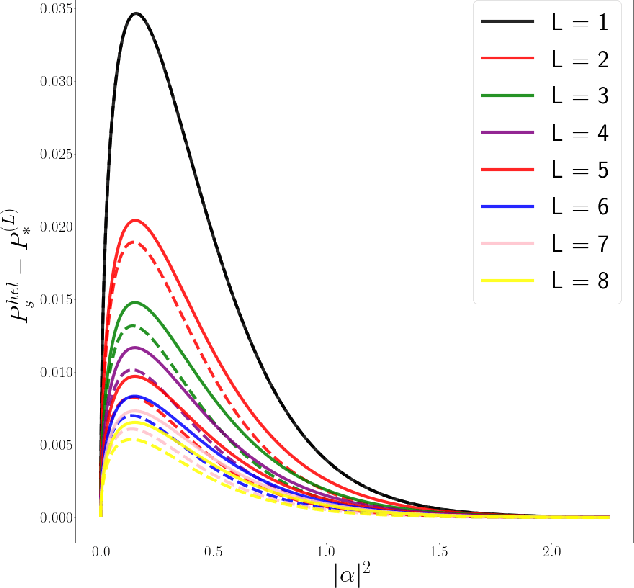
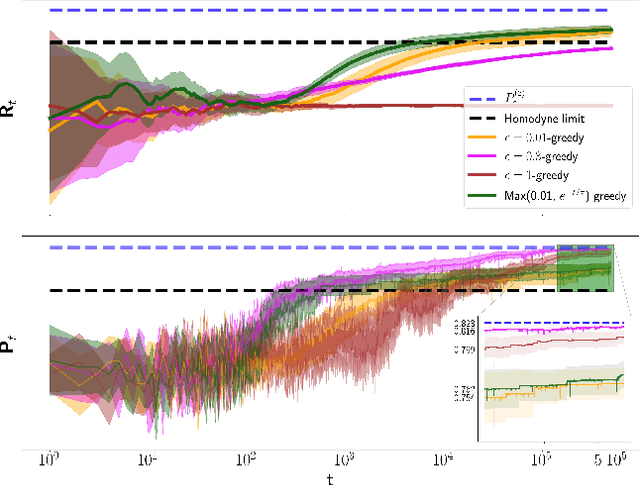
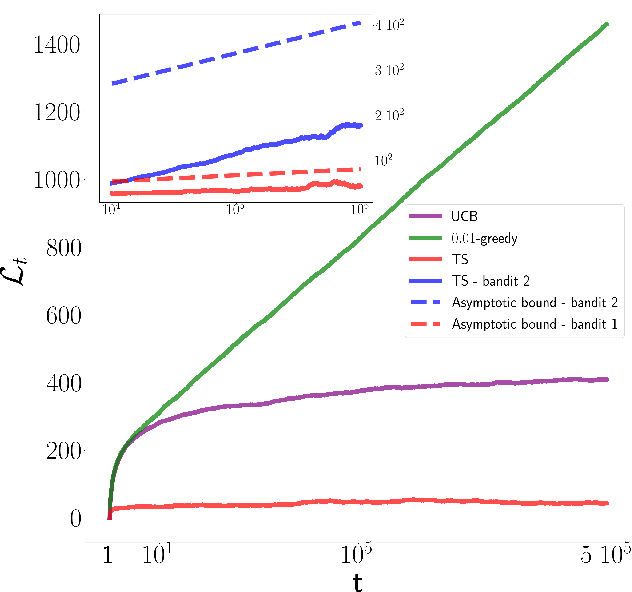
The optimal discrimination of coherent states of light with current technology is a key problem in classical and quantum communication, whose solution would enable the realization of efficient receivers for long-distance communications in free-space and optical fiber channels. In this article, we show that reinforcement learning (RL) protocols allow an agent to learn near-optimal coherent-state receivers made of passive linear optics, photodetectors and classical adaptive control. Each agent is trained and tested in real time over several runs of independent discrimination experiments and has no knowledge about the energy of the states nor the receiver setup nor the quantum-mechanical laws governing the experiments. Based exclusively on the observed photodetector outcomes, the agent adaptively chooses among a set of ~3 10^3 possible receiver setups, and obtains a reward at the end of each experiment if its guess is correct. At variance with previous applications of RL in quantum physics, the information gathered in each run is intrinsically stochastic and thus insufficient to evaluate exactly the performance of the chosen receiver. Nevertheless, we present families of agents that: (i) discover a receiver beating the best Gaussian receiver after ~3 10^2 experiments; (ii) surpass the cumulative reward of the best Gaussian receiver after ~10^3 experiments; (iii) simultaneously discover a near-optimal receiver and attain its cumulative reward after ~10^5 experiments. Our results show that RL techniques are suitable for on-line control of quantum receivers and can be employed for long-distance communications over potentially unknown channels.
Performance Analysis of Synergetic UAV-RIS Communication Networks
Jun 18, 2021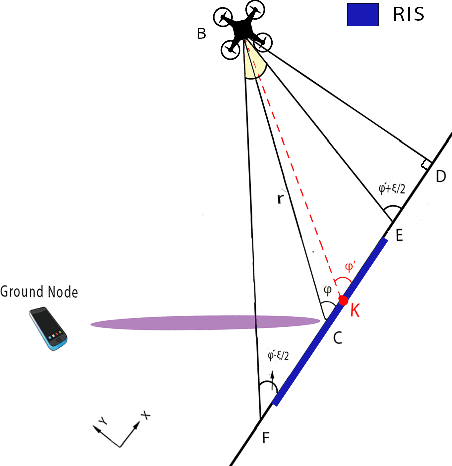
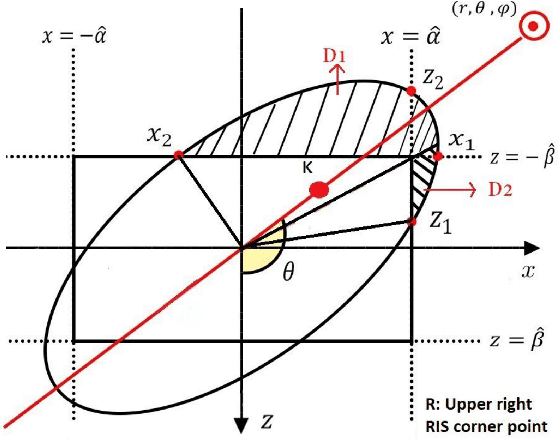
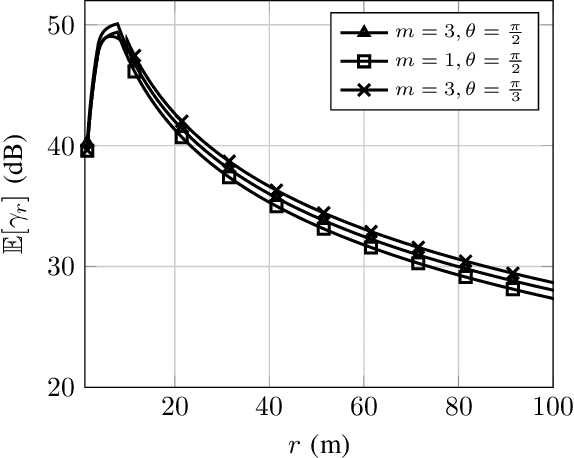
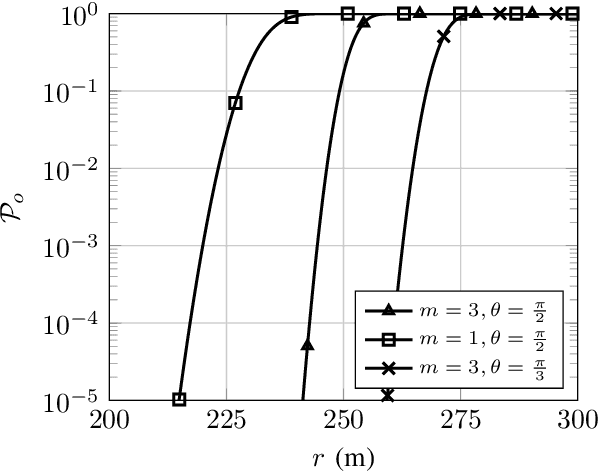
The effective integration of unmanned aerial vehicles (UAVs) in future wireless communication systems depends on the conscious use of their limited energy, which constrains their flight time. Reconfigurable intelligent surfaces (RISs) can be used in combination with UAVs with the aim to improve the communication performance without increasing complexity at the UAVs' side. In this paper, we propose a synergetic UAV-RIS communication system, utilizing a UAV with a directional antenna aiming to the RIS. Also, we present the link budget analysis and closed-form expressions for the outage probability as well as for an important second order statistical parameter of the proposed synergetic UAV-RIS communication system, the average outage duration. Finally, numerical results illustrate the effectiveness of the proposed synergetic system.
High Accuracy Visible Light Positioning Based on Multi-target Tracking Algorithm
Mar 09, 2021
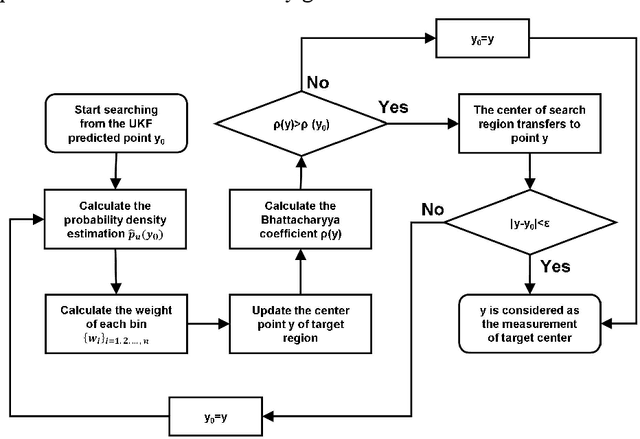

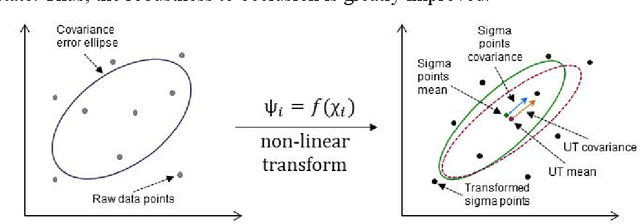
In this paper, we propose a multi-target image tracking algorithm based on continuously apative mean-shift (Cam-shift) and unscented Kalman filter. We improved the single-lamp tracking algorithm proposed in our previous work to multi-target tracking, and achieved better robustness in the case of occlusion, the real-time performance to complete one positioning and relatively high accuracy by dynamically adjusting the weights of the multi-target motion states. Our previous algorithm is limited to the analysis of tracking error. In this paper, the results of the tracking algorithm are evaluated with the tracking error we defined. Then combined with the double-lamp positioning algorithm, the real position of the terminal is calculated and evaluated with the positioning error we defined. Experiments show that the defined tracking error is 0.61cm and the defined positioning error for 3-D positioning is 3.29cm with the average processing time of 91.63ms per frame. Even if nearly half of the LED area is occluded, the tracking error remains at 5.25cm. All of this shows that the proposed visible light positioning (VLP) method can track multiple targets for positioning at the same time with good robustness, real-time performance and accuracy. In addition, the definition and analysis of tracking errors and positioning errors indicates the direction for future efforts to reduce errors.
Point Proposal Network for Reconstructing 3D Particle Positions with Sub-Pixel Precision in Liquid Argon Time Projection Chambers
Jun 26, 2020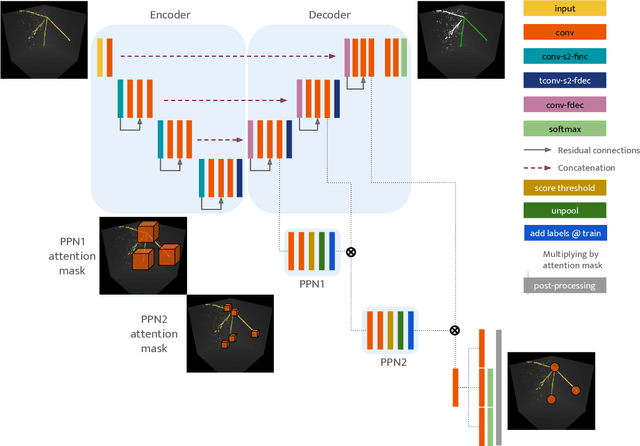

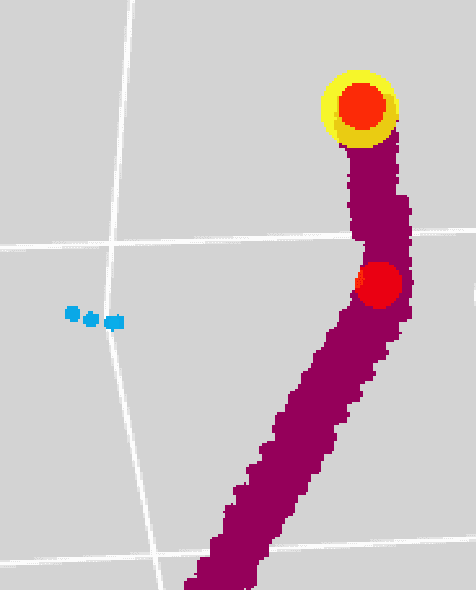
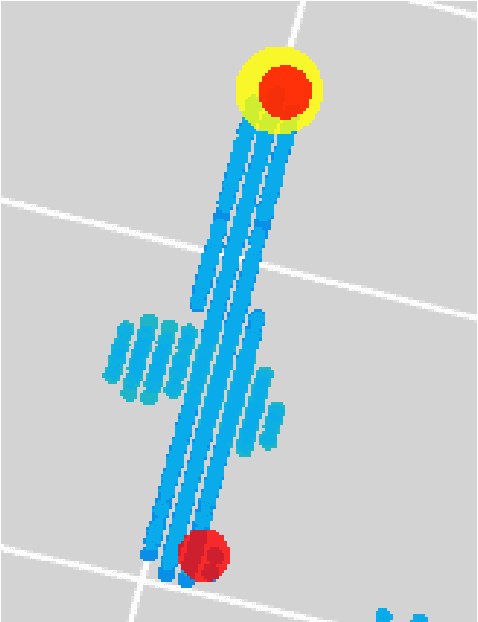
Liquid Argon Time Projection Chambers (LArTPC) are particle imaging detectors recording 2D or 3D images of numerous complex trajectories of charged particles. Identifying points of interest in these images, such as the starting and ending points of particles trajectories, is a crucial step of identifying and analyzing these particles and impacts inference of physics signals such as neutrino interaction. The Point Proposal Network is designed to discover specific points of interest, namely the starting and ending points of track-like particle trajectories such as muons and protons, and the starting points of electromagnetic shower-like particle trajectories such as electrons and gamma rays. The algorithm predicts with a sub-voxel precision their spatial location, and also determines the category of the identified points of interest. Using the PILArNet public LArTPC data sample as a benchmark, our algorithm successfully predicted 96.8%, 97.8%, and 98.1% of 3D points within the voxel distance of 3, 10, and 20 from the provided true point locations respectively. For the predicted 3D points within 3 voxels of the closest true point locations, the median distance is found to be 0.25 voxels, achieving the sub-voxel level precision. We report that the majority of predicted points that are more than 10 voxels away from the closest true point locations are legitimate mistakes, and our algorithm achieved high enough accuracy to identify issues associated with a small fraction of true point locations provided in the dataset. Further, using those predicted points, we demonstrate a set of simple algorithms to cluster 3D voxels into individual track-like particle trajectories at the clustering efficiency, purity, and Adjusted Rand Index of 83.2%, 96.7%, and 94.7% respectively.
Spatio-thermal depth correction of RGB-D sensors based on Gaussian Processes in real-time
Jul 01, 2019Commodity RGB-D sensors capture color images along with dense pixel-wise depth information in real-time. Typical RGB-D sensors are provided with a factory calibration and exhibit erratic depth readings due to coarse calibration values, ageing and thermal influence effects. This limits their applicability in computer vision and robotics. We propose a novel method to accurately calibrate depth considering spatial and thermal influences jointly. Our work is based on Gaussian Process Regression in a four dimensional Cartesian and thermal domain. We propose to leverage modern GPUs for dense depth map correction in real-time. For reproducibility we make our dataset and source code publicly available.
Robust Optimization and Validation of Echo State Networks for learning chaotic dynamics
Feb 09, 2021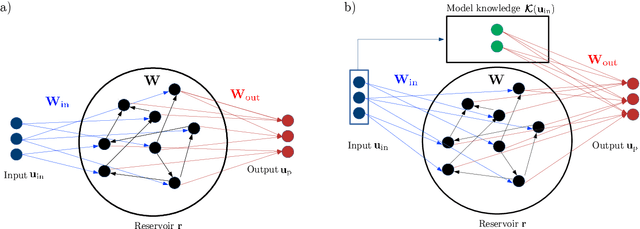
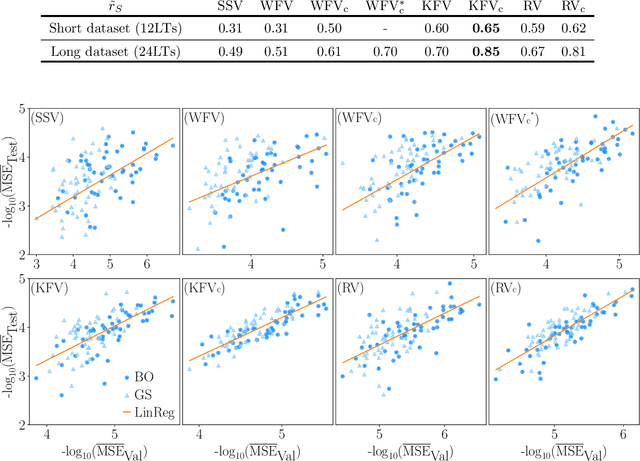
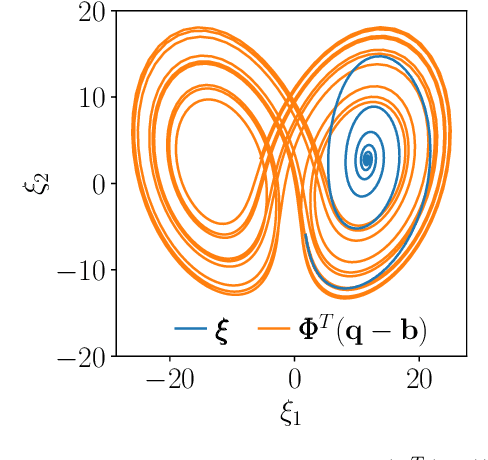
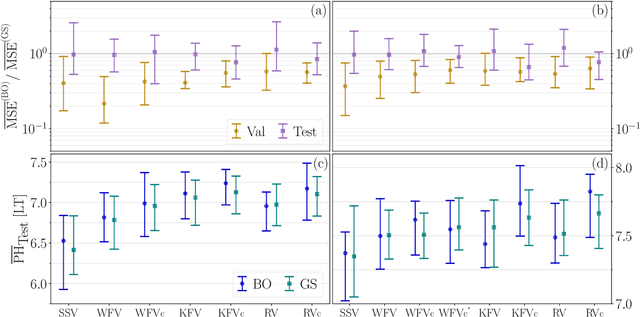
An approach to the time-accurate prediction of chaotic solutions is by learning temporal patterns from data. Echo State Networks (ESNs), which are a class of Reservoir Computing, can accurately predict the chaotic dynamics well beyond the predictability time. Existing studies, however, also showed that small changes in the hyperparameters may markedly affect the network's performance. The aim of this paper is to assess and improve the robustness of Echo State Networks for the time-accurate prediction of chaotic solutions. The goal is three-fold. First, we investigate the robustness of routinely used validation strategies. Second, we propose the Recycle Validation, and the chaotic versions of existing validation strategies, to specifically tackle the forecasting of chaotic systems. Third, we compare Bayesian optimization with the traditional Grid Search for optimal hyperparameter selection. Numerical tests are performed on two prototypical nonlinear systems that have both chaotic and quasiperiodic solutions. Both model-free and model-informed Echo State Networks are analysed. By comparing the network's robustness in learning chaotic versus quasiperiodic solutions, we highlight fundamental challenges in learning chaotic solutions. The proposed validation strategies, which are based on the dynamical systems properties of chaotic time series, are shown to outperform the state-of-the-art validation strategies. Because the strategies are principled-they are based on chaos theory such as the Lyapunov time-they can be applied to other Recurrent Neural Networks architectures with little modification. This work opens up new possibilities for the robust design and application of Echo State Networks, and Recurrent Neural Networks, to the time-accurate prediction of chaotic systems.