 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Properties of an N Time-Slice Dynamic Chain Event Graph
Oct 22, 2018
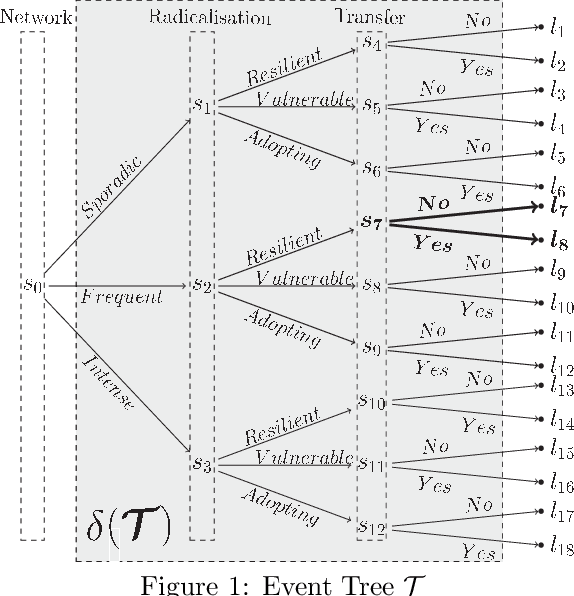
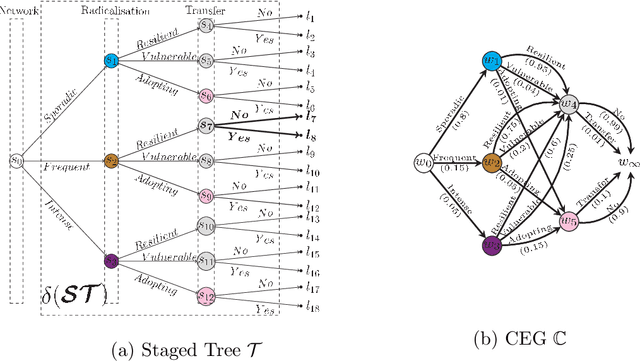
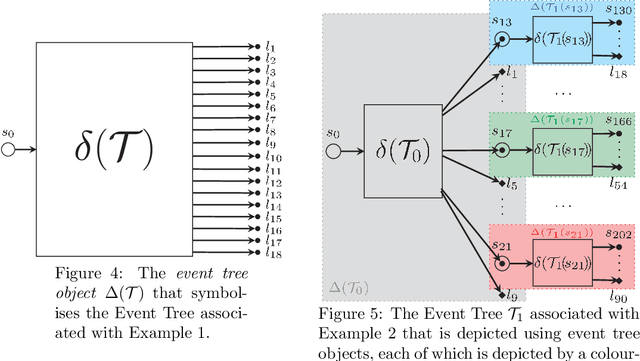
A Dynamic Chain Event Graph (DCEG) provides a rich tree-based framework for modelling a dynamic process with highly asymmetric developments. An N Time-Slice DCEG (NT-DCEG) is a useful subclass of the DCEG class that exhibits a specific type of periodicity in its supporting tree graph and embodies a time-homogeneity assumption. Here some desired properties of an NT-DCEG is explored. In particular, we prove that the class of NT-DCEGs contains all discrete N time-slice Dynamic Bayesian Networks as special cases. We also develop a method to distributively construct an NT-DCEG model. By exploiting the topology of an NT-DCEG graph, we show how to construct intrinsic random variables which exhibit context-specific independences that can then be checked by domain experts. We also show how an NT-DCEG can be used to depict various structural and Granger causal hypotheses about a given process. Our methods are illustrated throughout using examples of dynamic multivariate processes describing inmate radicalisation in a prison.
Path Planning in Dynamic Environments Using Time-Warped Grids and a Parallel Implementation
Mar 18, 2019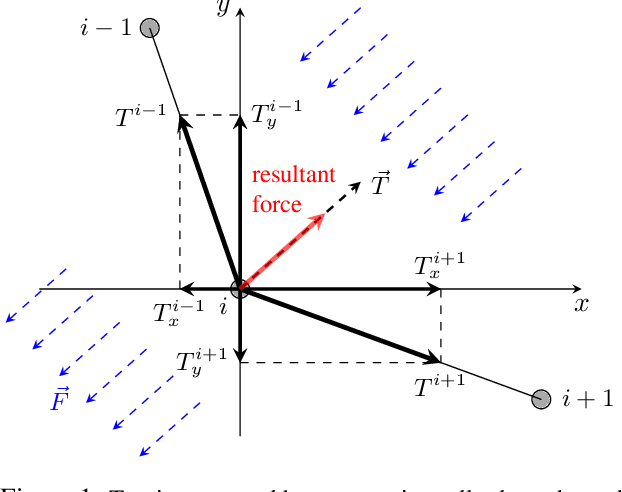
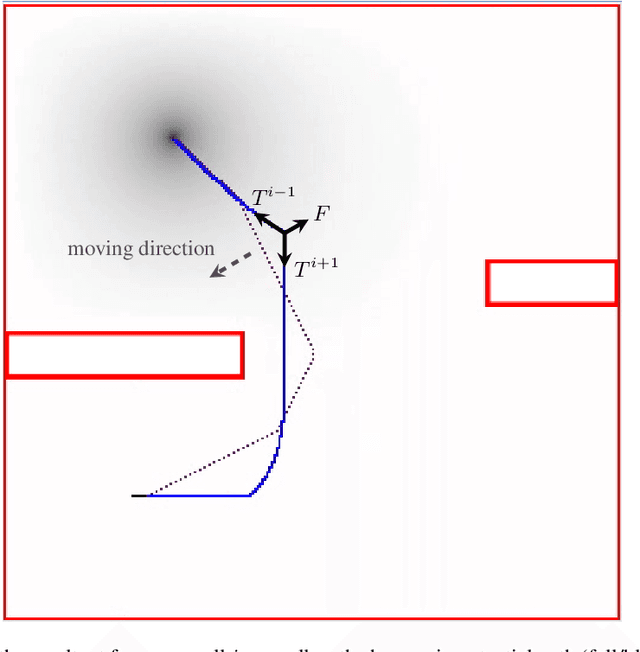
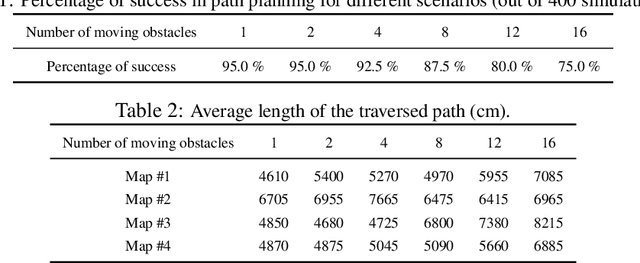
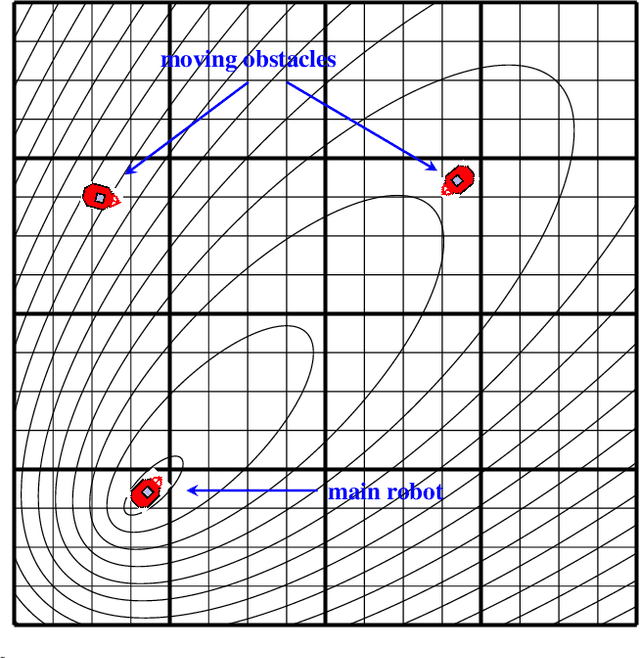
This paper proposes a solution to the problem of smooth path planning for mobile robots in dynamic and unknown environments. A novel concept of Time-Warped Grid is introduced to predict the pose of obstacles in the environment and avoid collisions. The algorithm is implemented using C/C++ and the CUDA programming environment, and combines stochastic estimation (Kalman filter), harmonic potential fields and a rubber band model, and it translates naturally into the parallel paradigm of GPU programming. In simple terms, time-warped grids are progressively wider orbits around the mobile robot. Those orbits represent the variable time intervals estimated by the robot to reach detected obstacles. The proposed method was tested using several simulation scenarios for the Pioneer P3-DX robot, which demonstrated the robustness of the algorithm by finding the optimum path in terms of smoothness, distance, and collision-free, in both static or dynamic environments, and with large number of obstacles.
Information Bottleneck Approach to Spatial Attention Learning
Aug 07, 2021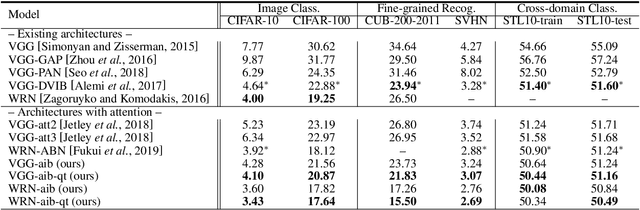

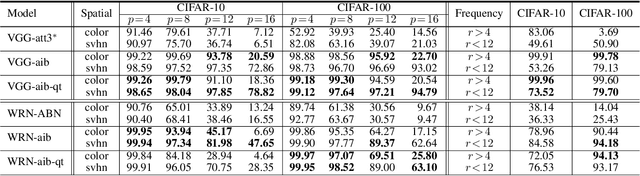
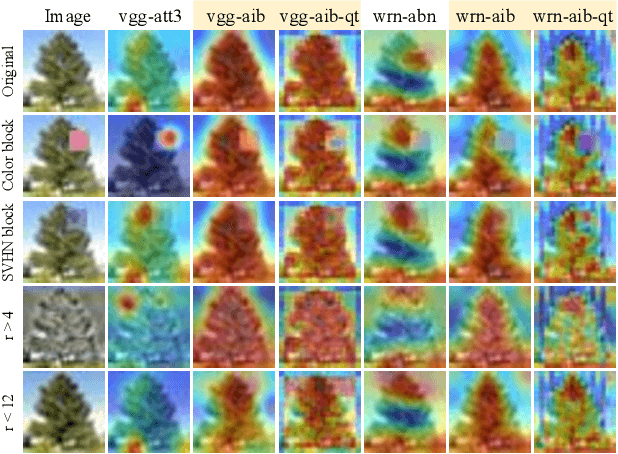
The selective visual attention mechanism in the human visual system (HVS) restricts the amount of information to reach visual awareness for perceiving natural scenes, allowing near real-time information processing with limited computational capacity [Koch and Ullman, 1987]. This kind of selectivity acts as an 'Information Bottleneck (IB)', which seeks a trade-off between information compression and predictive accuracy. However, such information constraints are rarely explored in the attention mechanism for deep neural networks (DNNs). In this paper, we propose an IB-inspired spatial attention module for DNN structures built for visual recognition. The module takes as input an intermediate representation of the input image, and outputs a variational 2D attention map that minimizes the mutual information (MI) between the attention-modulated representation and the input, while maximizing the MI between the attention-modulated representation and the task label. To further restrict the information bypassed by the attention map, we quantize the continuous attention scores to a set of learnable anchor values during training. Extensive experiments show that the proposed IB-inspired spatial attention mechanism can yield attention maps that neatly highlight the regions of interest while suppressing backgrounds, and bootstrap standard DNN structures for visual recognition tasks (e.g., image classification, fine-grained recognition, cross-domain classification). The attention maps are interpretable for the decision making of the DNNs as verified in the experiments. Our code is available at https://github.com/ashleylqx/AIB.git.
Modeling Irregularly Sampled Clinical Time Series
Dec 03, 2018
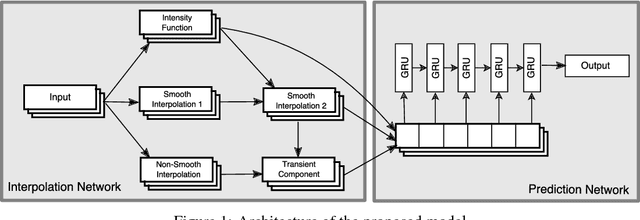
While the volume of electronic health records (EHR) data continues to grow, it remains rare for hospital systems to capture dense physiological data streams, even in the data-rich intensive care unit setting. Instead, typical EHR records consist of sparse and irregularly observed multivariate time series, which are well understood to present particularly challenging problems for machine learning methods. In this paper, we present a new deep learning architecture for addressing this problem based on the use of a semi-parametric interpolation network followed by the application of a prediction network. The interpolation network allows for information to be shared across multiple dimensions during the interpolation stage, while any standard deep learning model can be used for the prediction network. We investigate the performance of this architecture on the problems of mortality and length of stay prediction.
Omnimatte: Associating Objects and Their Effects in Video
May 14, 2021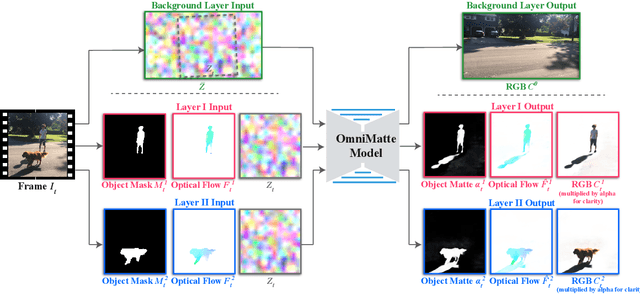



Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects---shadows, reflections, generated smoke, etc---are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject---an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic---it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject.
Real Time System for Facial Analysis
Sep 14, 2018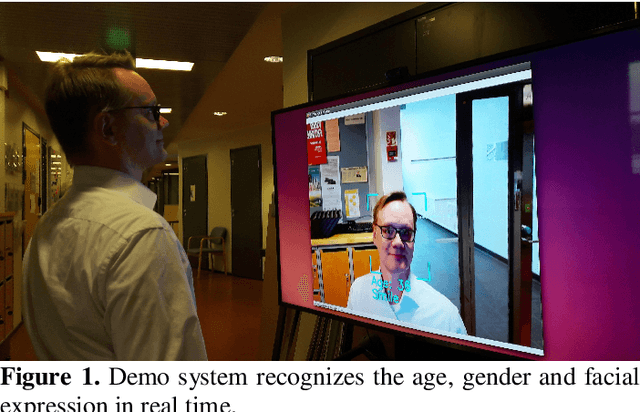
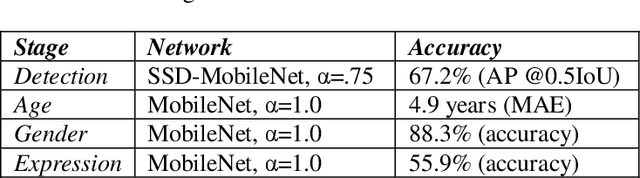
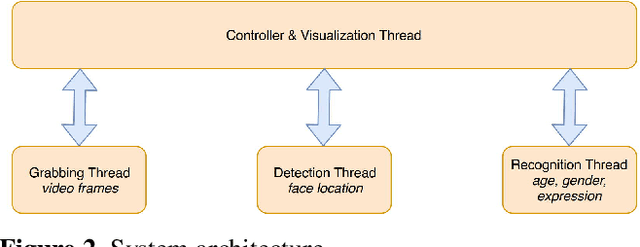
In this paper we describe the anatomy of a real-time facial analysis system. The system recognizes the age, gender and facial expression from users in appearing in front of the camera. All components are based on convolutional neural networks, whose accuracy we study on commonly used training and evaluation sets. A key contribution of the work is the description of the interplay between processing threads for frame grabbing, face detection and the three types of recognition. The python code for executing the system uses common libraries--keras/tensorflow, opencv and dlib--and is available for download.
Reconsidering CO2 emissions from Computer Vision
Apr 18, 2021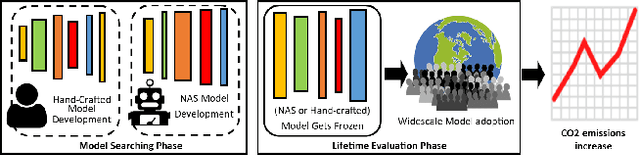
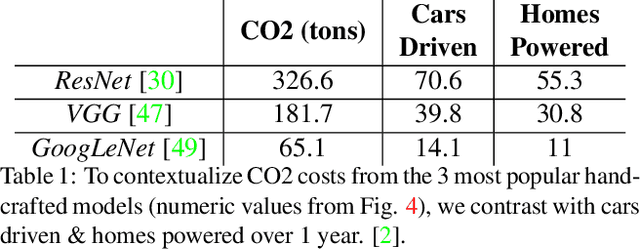
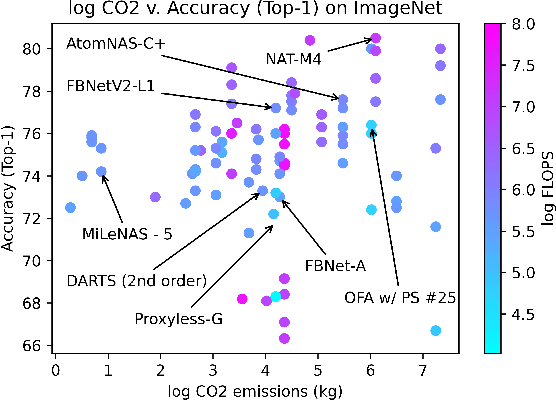
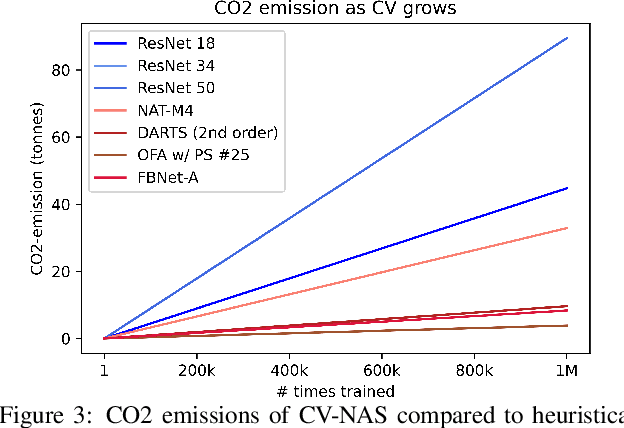
Climate change is a pressing issue that is currently affecting and will affect every part of our lives. It's becoming incredibly vital we, as a society, address the climate crisis as a universal effort, including those in the Computer Vision (CV) community. In this work, we analyze the total cost of CO2 emissions by breaking it into (1) the architecture creation cost and (2) the life-time evaluation cost. We show that over time, these costs are non-negligible and are having a direct impact on our future. Importantly, we conduct an ethical analysis of how the CV-community is unintentionally overlooking its own ethical AI principles by emitting this level of CO2. To address these concerns, we propose adding "enforcement" as a pillar of ethical AI and provide some recommendations for how architecture designers and broader CV community can curb the climate crisis.
Backdoor Attacks on Self-Supervised Learning
May 21, 2021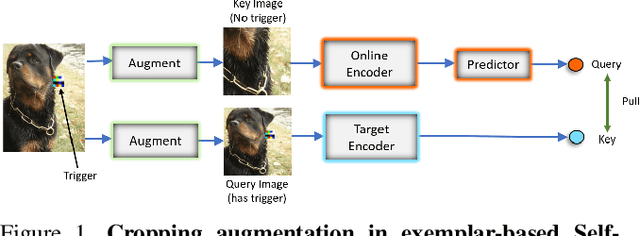
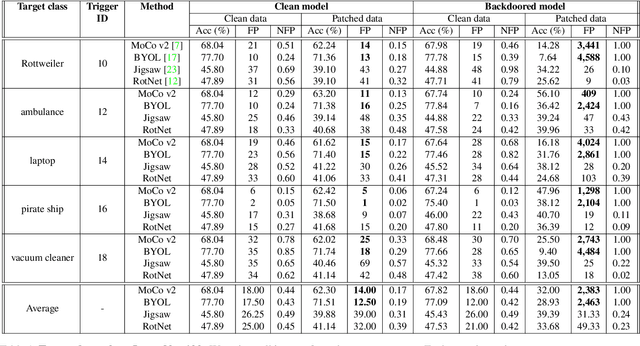
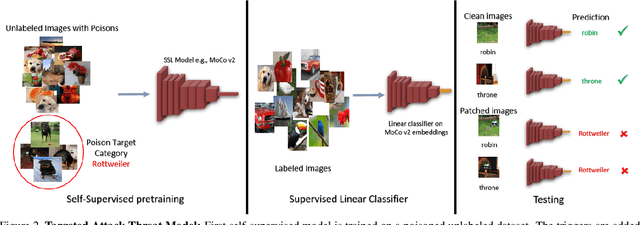
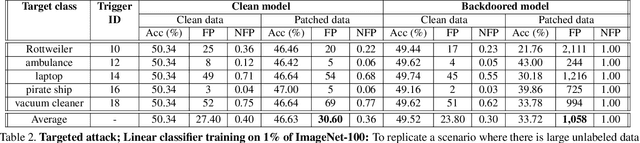
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Bias-Variance Reduced Local SGD for Less Heterogeneous Federated Learning
Feb 05, 2021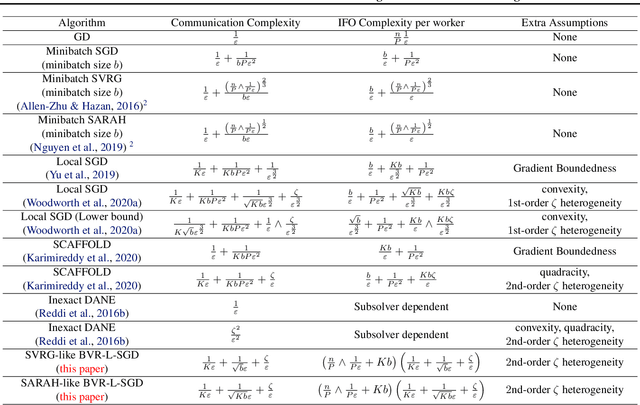
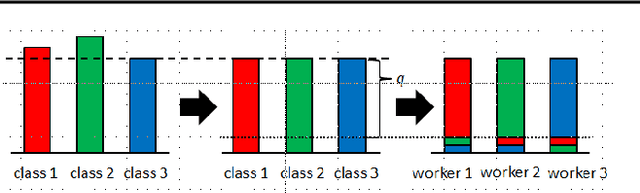

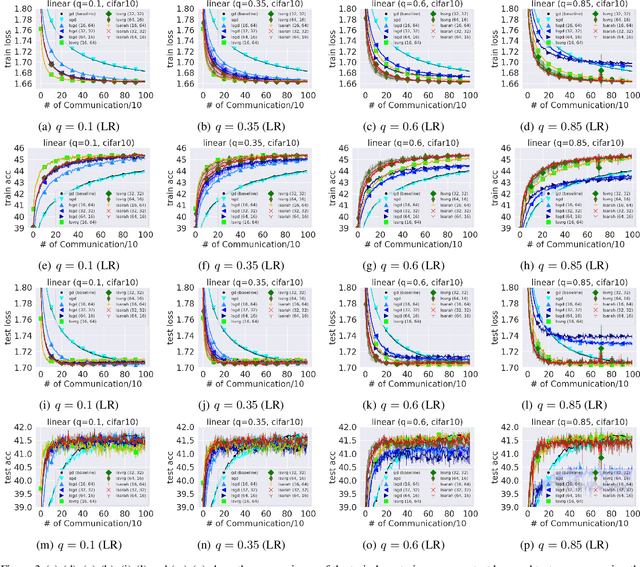
Federated learning is one of the important learning scenarios in distributed learning, in which we aim at learning heterogeneous local datasets efficiently in terms of communication and computational cost. In this paper, we study new local algorithms called Bias-Variance Reduced Local SGD (BVR-L-SGD) for nonconvex federated learning. One of the novelties of this paper is in the analysis of our bias and variance reduced local gradient estimators which fully utilize small second-order heterogeneity of local objectives and suggests to randomly pick up one of the local models instead of taking average of them when workers are synchronized. Under small heterogeneity of local objectives, we show that our methods achieve smaller communication complexity than both the previous non-local and local methods for general nonconvex objectives. Furthermore, we also compare the total execution time, that is the sum of total communication time and total computational time per worker, and show the superiority of our methods to the existing methods when the heterogeneity is small and single communication time is more time consuming than single stochastic gradient computation. Numerical results are provided to verify our theoretical findings and give empirical evidence of the superiority of our algorithms.
You too Brutus! Trapping Hateful Users in Social Media: Challenges, Solutions & Insights
Aug 01, 2021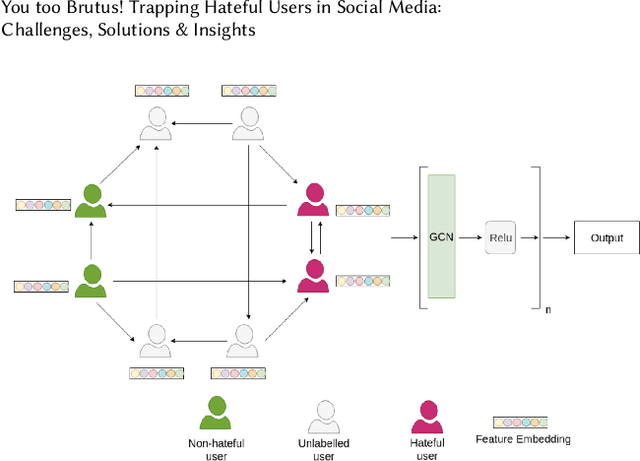
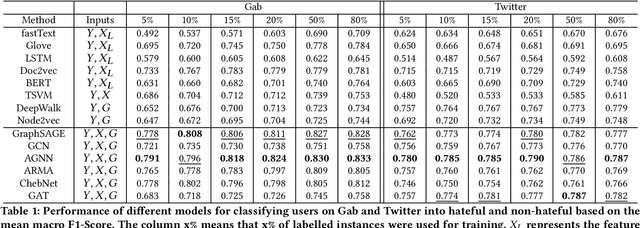
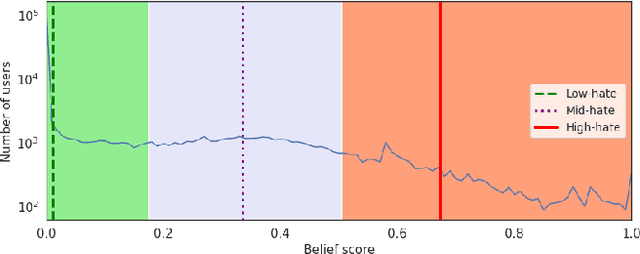
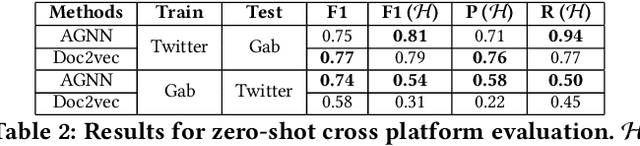
Hate speech is regarded as one of the crucial issues plaguing the online social media. The current literature on hate speech detection leverages primarily the textual content to find hateful posts and subsequently identify hateful users. However, this methodology disregards the social connections between users. In this paper, we run a detailed exploration of the problem space and investigate an array of models ranging from purely textual to graph based to finally semi-supervised techniques using Graph Neural Networks (GNN) that utilize both textual and graph-based features. We run exhaustive experiments on two datasets -- Gab, which is loosely moderated and Twitter, which is strictly moderated. Overall the AGNN model achieves 0.791 macro F1-score on the Gab dataset and 0.780 macro F1-score on the Twitter dataset using only 5% of the labeled instances, considerably outperforming all the other models including the fully supervised ones. We perform detailed error analysis on the best performing text and graph based models and observe that hateful users have unique network neighborhood signatures and the AGNN model benefits by paying attention to these signatures. This property, as we observe, also allows the model to generalize well across platforms in a zero-shot setting. Lastly, we utilize the best performing GNN model to analyze the evolution of hateful users and their targets over time in Gab.