 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021
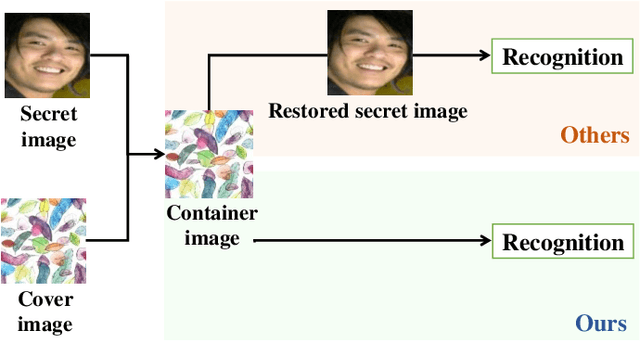

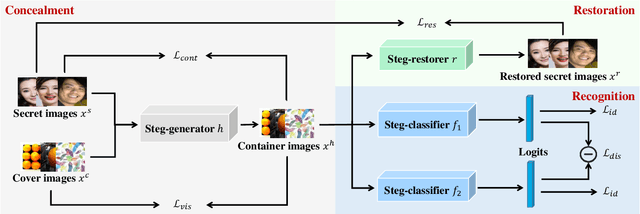
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
Unsupervised Continual Learning via Self-Adaptive Deep Clustering Approach
Jun 28, 2021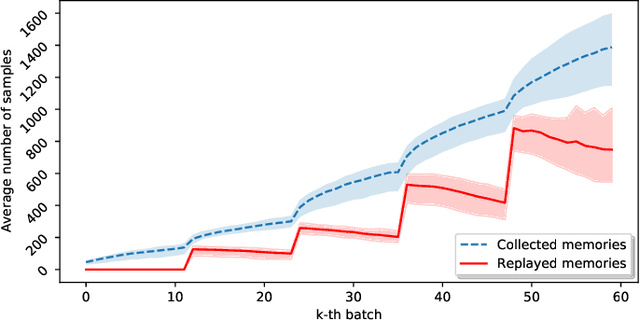
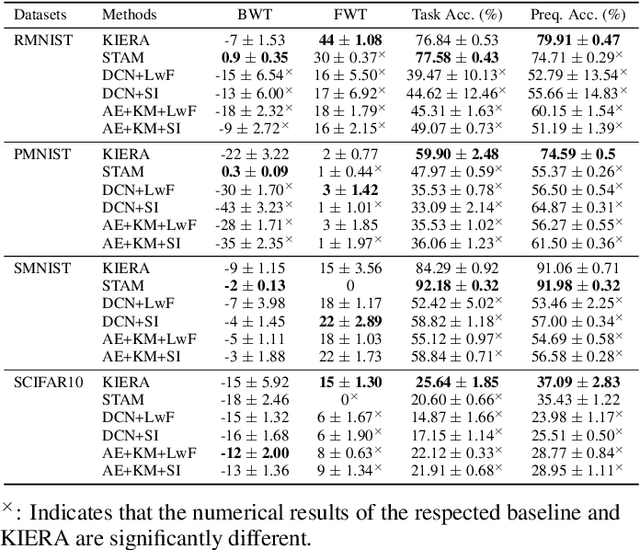
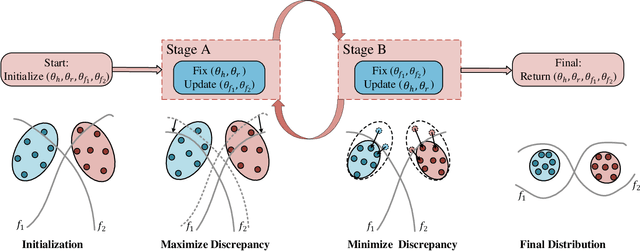
Unsupervised continual learning remains a relatively uncharted territory in the existing literature because the vast majority of existing works call for unlimited access of ground truth incurring expensive labelling cost. Another issue lies in the problem of task boundaries and task IDs which must be known for model's updates or model's predictions hindering feasibility for real-time deployment. Knowledge Retention in Self-Adaptive Deep Continual Learner, (KIERA), is proposed in this paper. KIERA is developed from the notion of flexible deep clustering approach possessing an elastic network structure to cope with changing environments in the timely manner. The centroid-based experience replay is put forward to overcome the catastrophic forgetting problem. KIERA does not exploit any labelled samples for model updates while featuring a task-agnostic merit. The advantage of KIERA has been numerically validated in popular continual learning problems where it shows highly competitive performance compared to state-of-the art approaches. Our implementation is available in \textit{\url{https://github.com/ContinualAL/KIERA}}.
Machine Learning Regression for Operator Dynamics
Feb 23, 2021
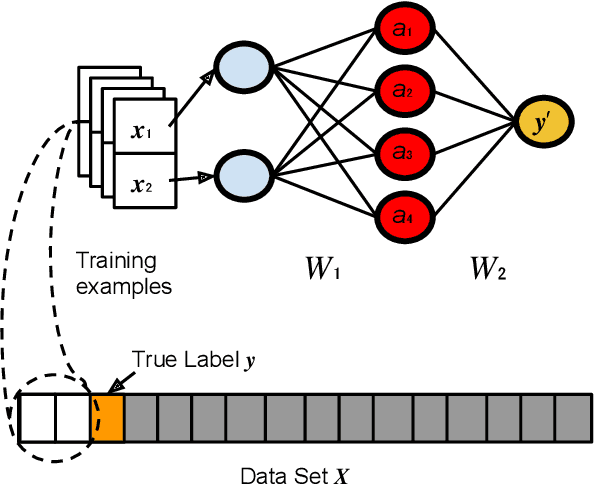
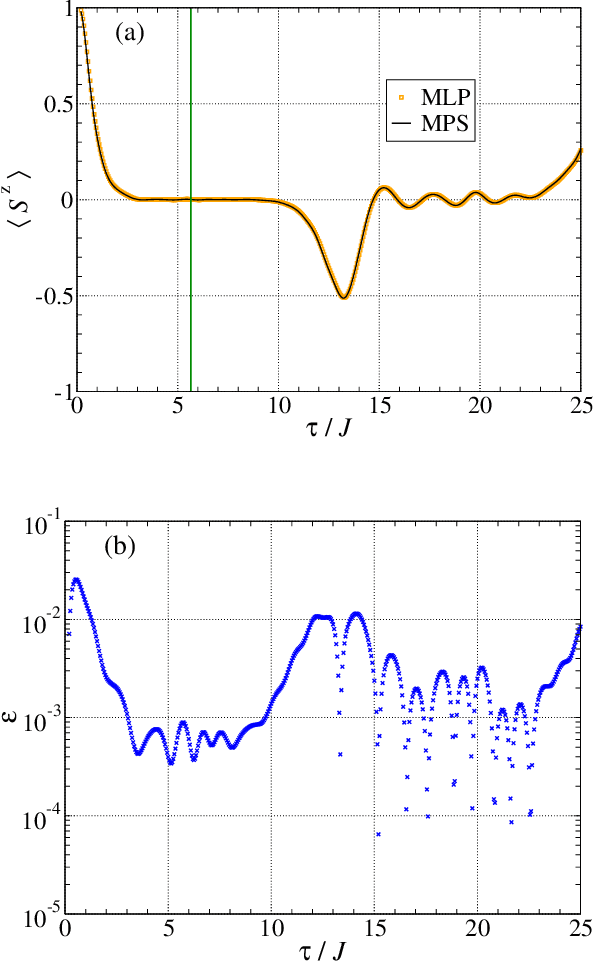
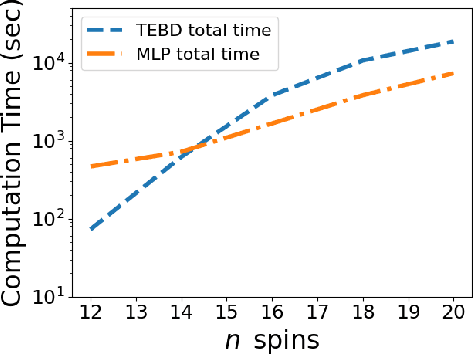
Determining the dynamics of the expectation values for operators acting on a quantum many-body (QMB) system is a challenging task. Matrix product states (MPS) have traditionally been the "go-to" models for these systems because calculating expectation values in this representation can be done with relative simplicity and high accuracy. However, such calculations can become computationally costly when extended to long times. Here, we present a solution for efficiently extending the computation of expectation values to long time intervals. We utilize a multi-layer perceptron (MLP) model as a tool for regression on MPS expectation values calculated within the regime of short time intervals. With this model, the computational cost of generating long-time dynamics is significantly reduced, while maintaining a high accuracy. These results are demonstrated with operators relevant to quantum spin models in one spatial dimension.
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 19, 2021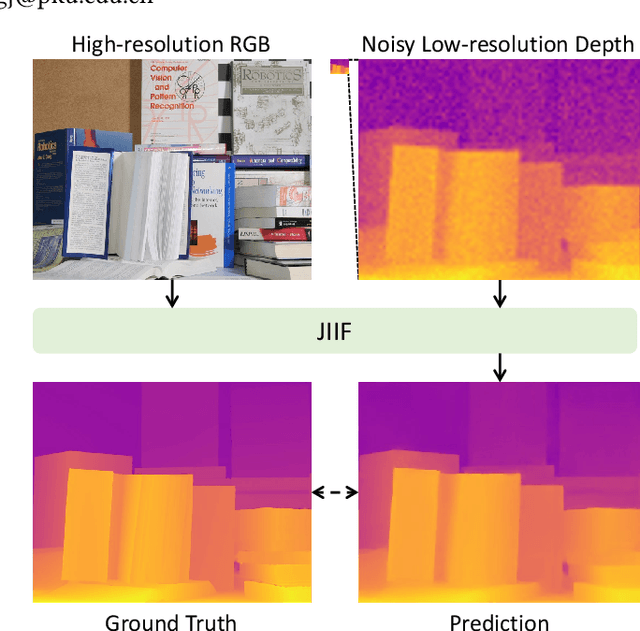
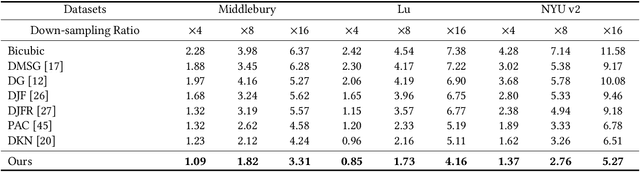
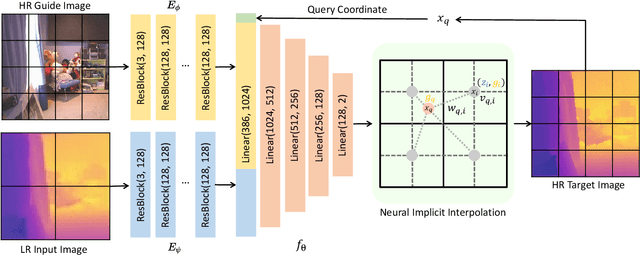
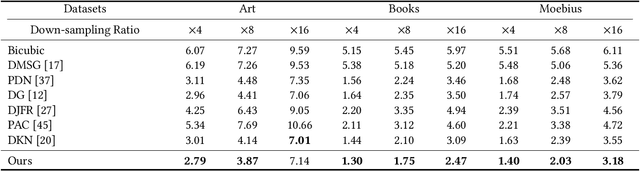
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.
Decentralized Power Allocation for MIMO-NOMA Vehicular Edge Computing Based on Deep Reinforcement Learning
Jul 30, 2021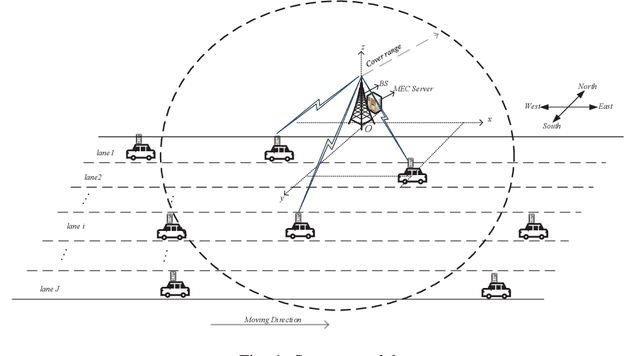
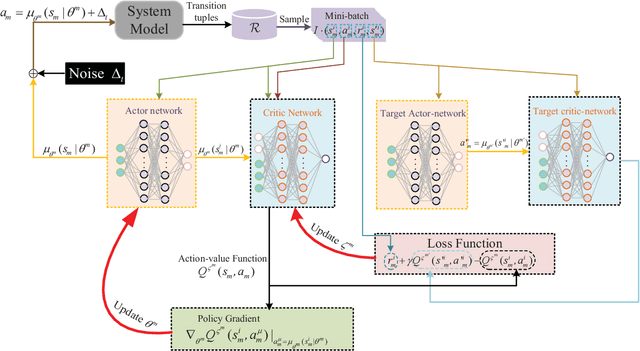
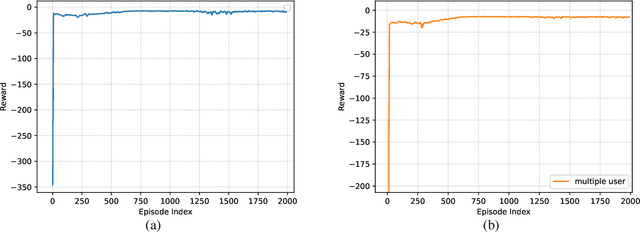
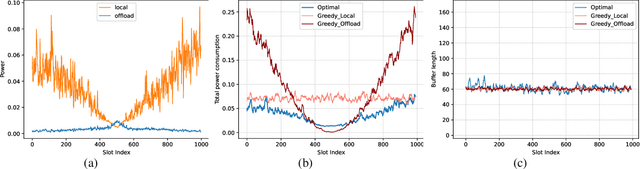
Vehicular edge computing (VEC) is envisioned as a promising approach to process the explosive computation tasks of vehicular user (VU). In the VEC system, each VU allocates power to process partial tasks through offloading and the remaining tasks through local execution. During the offloading, each VU adopts the multi-input multi-out and non-orthogonal multiple access (MIMO-NOMA) channel to improve the channel spectrum efficiency and capacity. However, the channel condition is uncertain due to the channel interference among VUs caused by the MIMO-NOMA channel and the time-varying path-loss caused by the mobility of each VU. In addition, the task arrival of each VU is stochastic in the real world. The stochastic task arrival and uncertain channel condition affect greatly on the power consumption and latency of tasks for each VU. It is critical to design an optimal power allocation scheme considering the stochastic task arrival and channel variation to optimize the long-term reward including the power consumption and latency in the MIMO-NOMA VEC. Different from the traditional centralized deep reinforcement learning (DRL)-based scheme, this paper constructs a decentralized DRL framework to formulate the power allocation optimization problem, where the local observations are selected as the state. The deep deterministic policy gradient (DDPG) algorithm is adopted to learn the optimal power allocation scheme based on the decentralized DRL framework. Simulation results demonstrate that our proposed power allocation scheme outperforms the existing schemes.
Theory and Algorithms for Forecasting Time Series
Mar 15, 2018
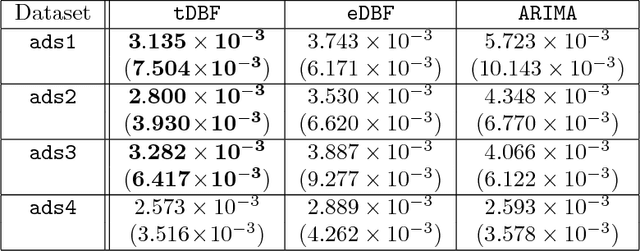
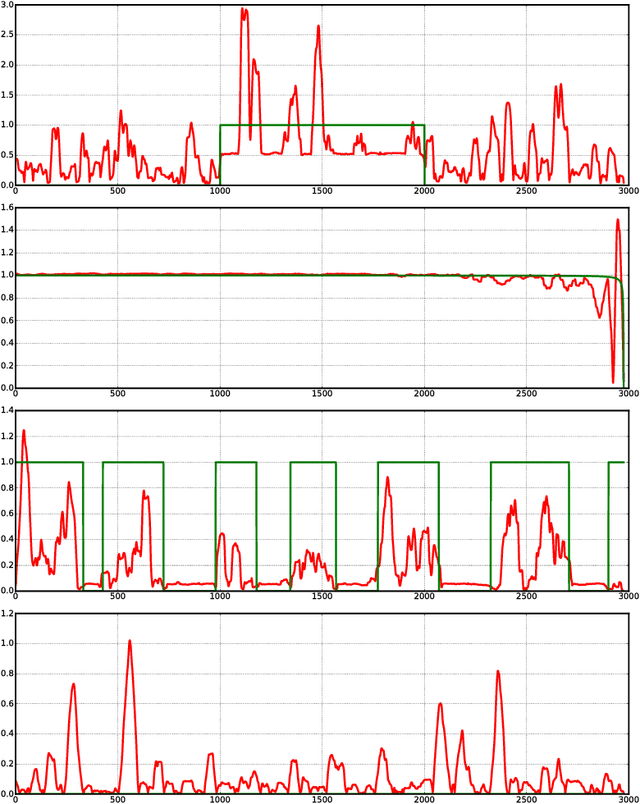

We present data-dependent learning bounds for the general scenario of non-stationary non-mixing stochastic processes. Our learning guarantees are expressed in terms of a data-dependent measure of sequential complexity and a discrepancy measure that can be estimated from data under some mild assumptions. We also also provide novel analysis of stable time series forecasting algorithm using this new notion of discrepancy that we introduce. We use our learning bounds to devise new algorithms for non-stationary time series forecasting for which we report some preliminary experimental results.
An Efficient Deep Distribution Network for Bid Shading in First-Price Auctions
Jul 12, 2021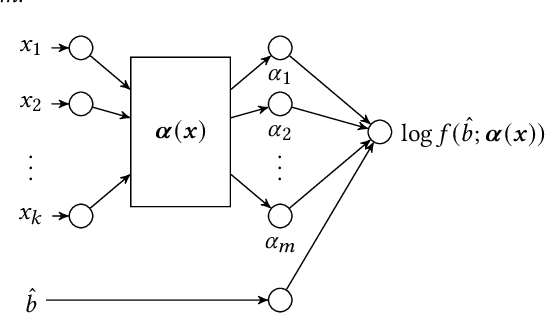
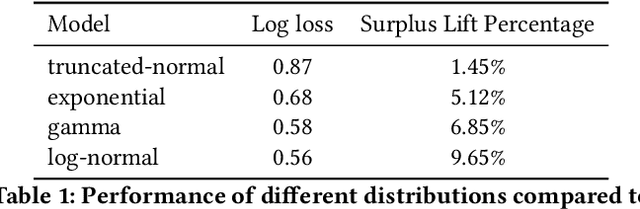
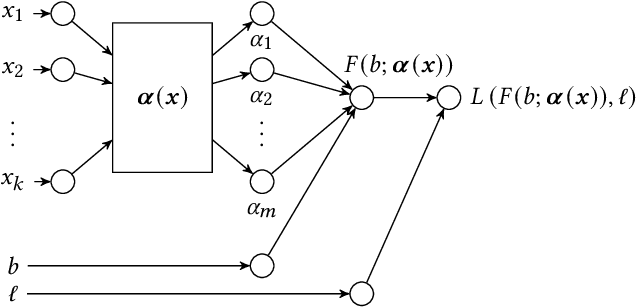
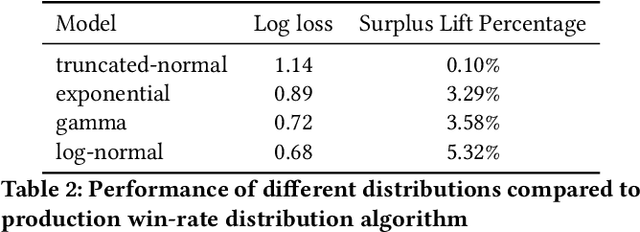
Since 2019, most ad exchanges and sell-side platforms (SSPs), in the online advertising industry, shifted from second to first price auctions. Due to the fundamental difference between these auctions, demand-side platforms (DSPs) have had to update their bidding strategies to avoid bidding unnecessarily high and hence overpaying. Bid shading was proposed to adjust the bid price intended for second-price auctions, in order to balance cost and winning probability in a first-price auction setup. In this study, we introduce a novel deep distribution network for optimal bidding in both open (non-censored) and closed (censored) online first-price auctions. Offline and online A/B testing results show that our algorithm outperforms previous state-of-art algorithms in terms of both surplus and effective cost per action (eCPX) metrics. Furthermore, the algorithm is optimized in run-time and has been deployed into VerizonMedia DSP as production algorithm, serving hundreds of billions of bid requests per day. Online A/B test shows that advertiser's ROI are improved by +2.4%, +2.4%, and +8.6% for impression based (CPM), click based (CPC), and conversion based (CPA) campaigns respectively.
Thermal Neural Networks: Lumped-Parameter Thermal Modeling With State-Space Machine Learning
Mar 30, 2021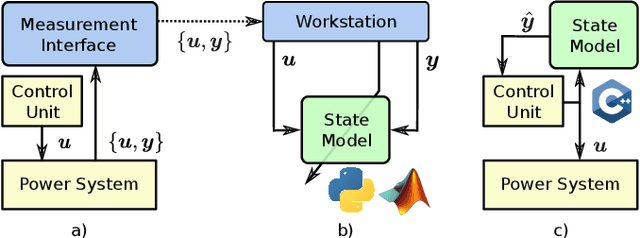
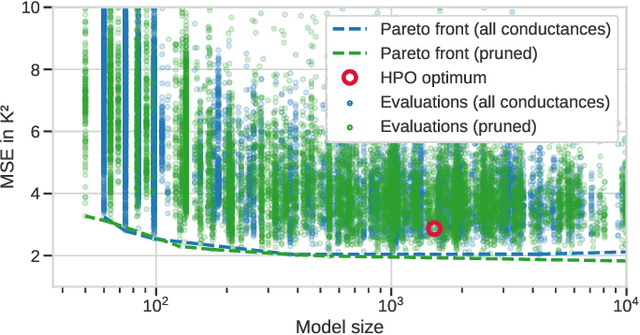
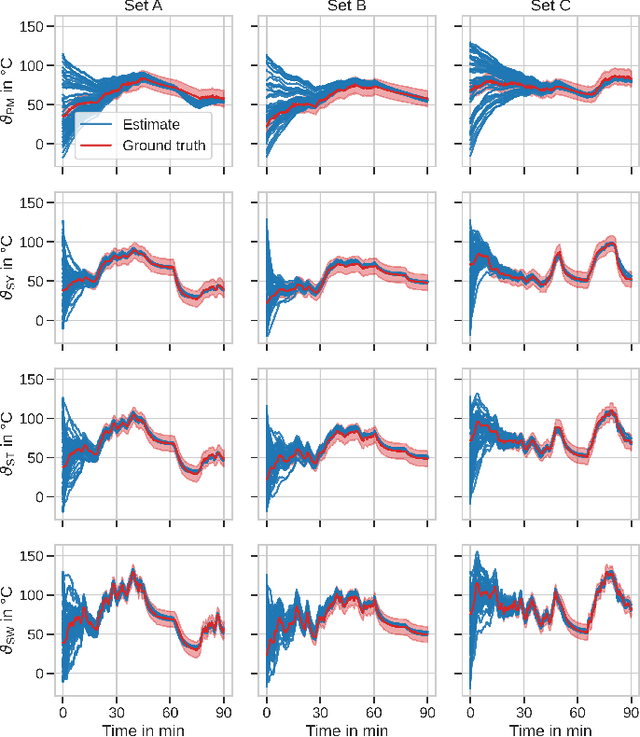
With electric power systems becoming more compact and increasingly powerful, the relevance of thermal stress especially during overload operation is expected to increase ceaselessly. Whenever critical temperatures cannot be measured economically on a sensor base, a thermal model lends itself to estimate those unknown quantities. Thermal models for electric power systems are usually required to be both, real-time capable and of high estimation accuracy. Moreover, ease of implementation and time to production play an increasingly important role. In this work, the thermal neural network (TNN) is introduced, which unifies both, consolidated knowledge in the form of heat-transfer-based lumped-parameter models, and data-driven nonlinear function approximation with supervised machine learning. A quasi-linear parameter-varying system is identified solely from empirical data, where relationships between scheduling variables and system matrices are inferred statistically and automatically. At the same time, a TNN has physically interpretable states through its state-space representation, is end-to-end trainable -- similar to deep learning models -- with automatic differentiation, and requires no material, geometry, nor expert knowledge for its design. Experiments on an electric motor data set show that a TNN achieves higher temperature estimation accuracies than previous white-/grey- or black-box models with a mean squared error of $3.18~\text{K}^2$ and a worst-case error of $5.84~\text{K}$ at 64 model parameters.
Random Offset Block Embedding Array (ROBE) for CriteoTB Benchmark MLPerf DLRM Model : 1000$\times$ Compression and 2.7$\times$ Faster Inference
Aug 04, 2021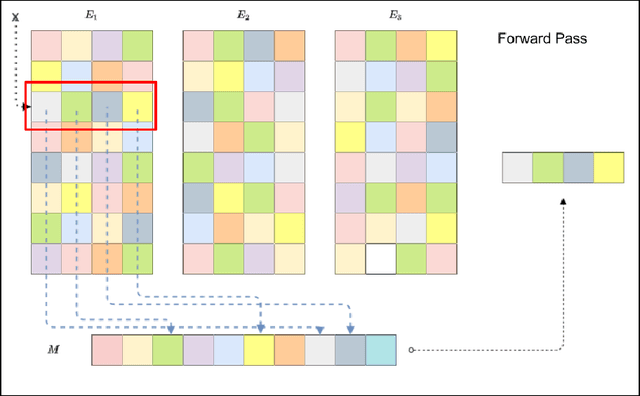

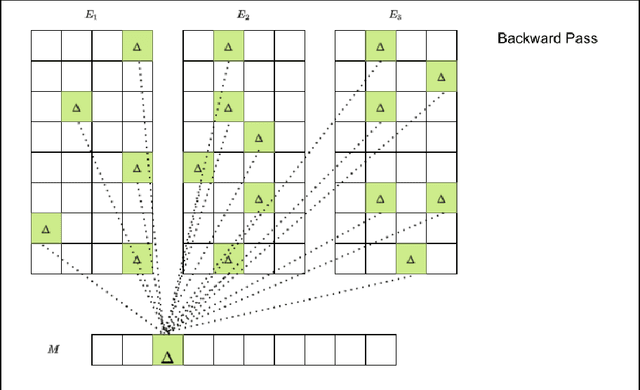
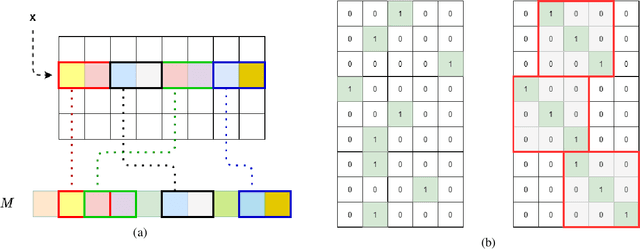
Deep learning for recommendation data is the one of the most pervasive and challenging AI workload in recent times. State-of-the-art recommendation models are one of the largest models rivalling the likes of GPT-3 and Switch Transformer. Challenges in deep learning recommendation models (DLRM) stem from learning dense embeddings for each of the categorical values. These embedding tables in industrial scale models can be as large as hundreds of terabytes. Such large models lead to a plethora of engineering challenges, not to mention prohibitive communication overheads, and slower training and inference times. Of these, slower inference time directly impacts user experience. Model compression for DLRM is gaining traction and the community has recently shown impressive compression results. In this paper, we present Random Offset Block Embedding Array (ROBE) as a low memory alternative to embedding tables which provide orders of magnitude reduction in memory usage while maintaining accuracy and boosting execution speed. ROBE is a simple fundamental approach in improving both cache performance and the variance of randomized hashing, which could be of independent interest in itself. We demonstrate that we can successfully train DLRM models with same accuracy while using $1000 \times$ less memory. A $1000\times$ compressed model directly results in faster inference without any engineering. In particular, we show that we can train DLRM model using ROBE Array of size 100MB on a single GPU to achieve AUC of 0.8025 or higher as required by official MLPerf CriteoTB benchmark DLRM model of 100GB while achieving about $2.7\times$ (170\%) improvement in inference throughput.
FuseMODNet: Real-Time Camera and LiDAR based Moving Object Detection for robust low-light Autonomous Driving
Oct 19, 2019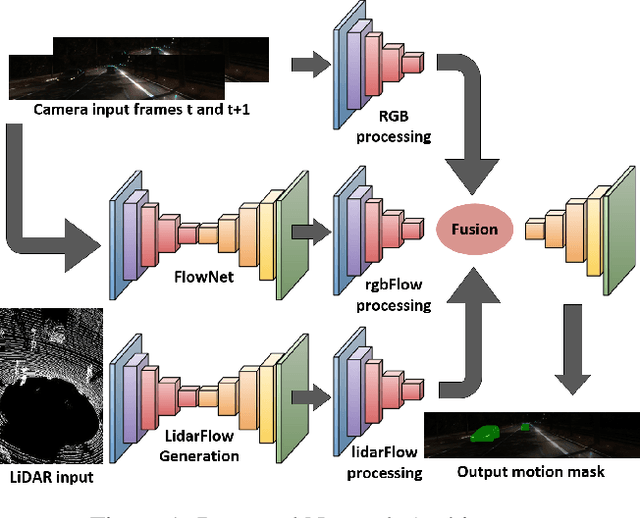
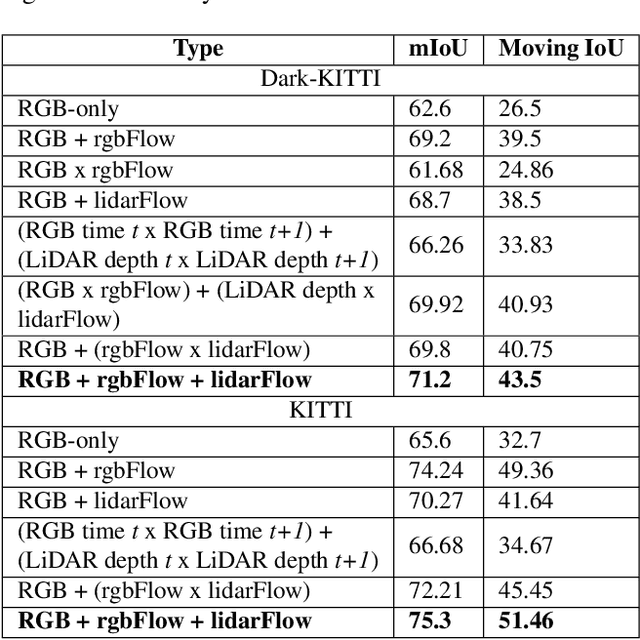


Moving object detection is a critical task for autonomous vehicles. As dynamic objects represent higher collision risk than static ones, our own ego-trajectories have to be planned attending to the future states of the moving elements of the scene. Motion can be perceived using temporal information such as optical flow. Conventional optical flow computation is based on camera sensors only, which makes it prone to failure in conditions with low illumination. On the other hand, LiDAR sensors are independent of illumination, as they measure the time-of-flight of their own emitted lasers. In this work, we propose a robust and real-time CNN architecture for Moving Object Detection (MOD) under low-light conditions by capturing motion information from both camera and LiDAR sensors. We demonstrate the impact of our algorithm on KITTI dataset where we simulate a low-light environment creating a novel dataset "Dark KITTI". We obtain a 10.1% relative improvement on Dark-KITTI, and a 4.25% improvement on standard KITTI relative to our baselines. The proposed algorithm runs at 18 fps on a standard desktop GPU using $256\times1224$ resolution images.