 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Odometry with an Event Camera Using Continuous Ray Warping and Volumetric Contrast Maximization
Jul 07, 2021
We present a new solution to tracking and mapping with an event camera. The motion of the camera contains both rotation and translation, and the displacements happen in an arbitrarily structured environment. As a result, the image matching may no longer be represented by a low-dimensional homographic warping, thus complicating an application of the commonly used Image of Warped Events (IWE). We introduce a new solution to this problem by performing contrast maximization in 3D. The 3D location of the rays cast for each event is smoothly varied as a function of a continuous-time motion parametrization, and the optimal parameters are found by maximizing the contrast in a volumetric ray density field. Our method thus performs joint optimization over motion and structure. The practical validity of our approach is supported by an application to AGV motion estimation and 3D reconstruction with a single vehicle-mounted event camera. The method approaches the performance obtained with regular cameras, and eventually outperforms in challenging visual conditions.
Drivers' Manoeuvre Modelling and Prediction for Safe HRI
Jun 03, 2021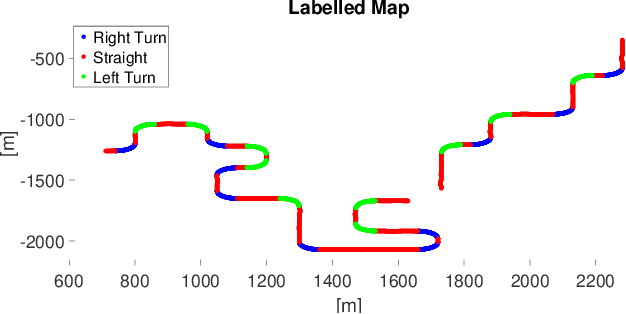
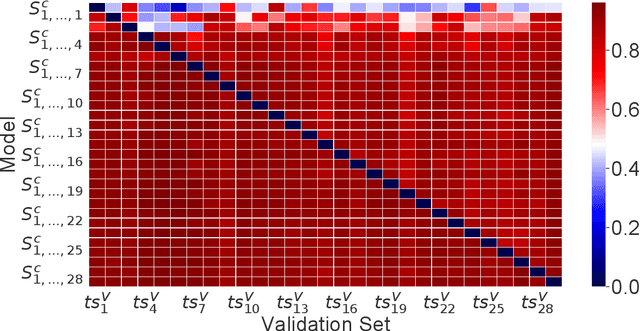
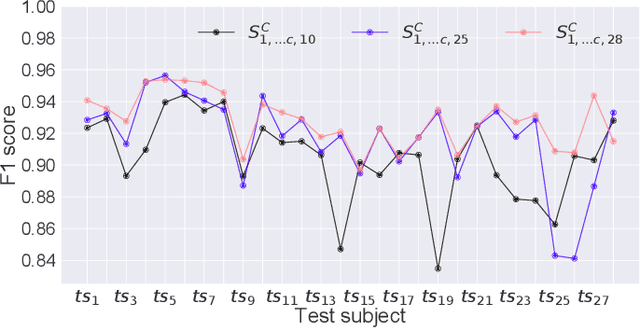
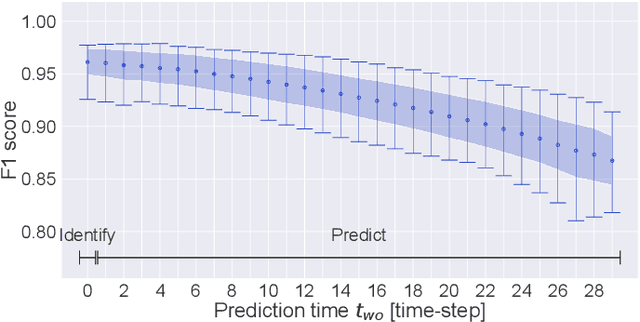
As autonomous machines such as robots and vehicles start performing tasks involving human users, ensuring a safe interaction between them becomes an important issue. Translating methods from human-robot interaction (HRI) studies to the interaction between humans and other highly complex machines (e.g. semi-autonomous vehicles) could help advance the use of those machines in scenarios requiring human interaction. One method involves understanding human intentions and decision-making to estimate the human's present and near-future actions whilst interacting with a robot. This idea originates from the psychological concept of Theory of Mind, which has been broadly explored for robotics and recently for autonomous and semi-autonomous vehicles. In this work, we explored how to predict human intentions before an action is performed by combining data from human-motion, vehicle-state and human inputs (e.g. steering wheel, pedals). A data-driven approach based on Recurrent Neural Network models was used to classify the current driving manoeuvre and to predict the future manoeuvre to be performed. A state-transition model was used with a fixed set of manoeuvres to label data recorded during the trials for real-time applications. Models were trained and tested using drivers of different seat preferences, driving expertise and arm-length; precision and recall metrics over 95% for manoeuvre identification and 86% for manoeuvre prediction were achieved, with prediction time-windows of up to 1 second for both known and unknown test subjects. Compared to our previous results, performance improved and manoeuvre prediction was possible for unknown test subjects without knowing the current manoeuvre.
Local Trend Inconsistency: A Prediction-driven Approach to Unsupervised Anomaly Detection in Multi-seasonal Time Series
Aug 03, 2019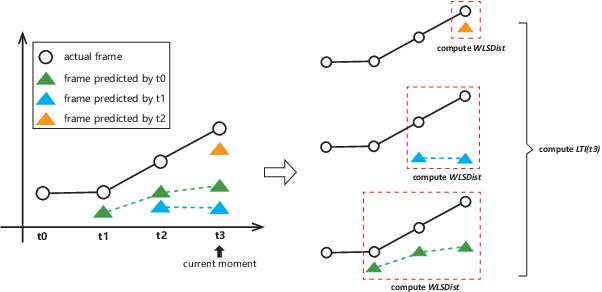
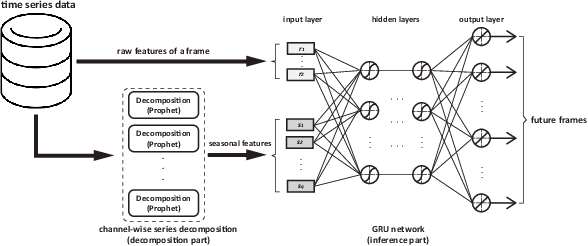
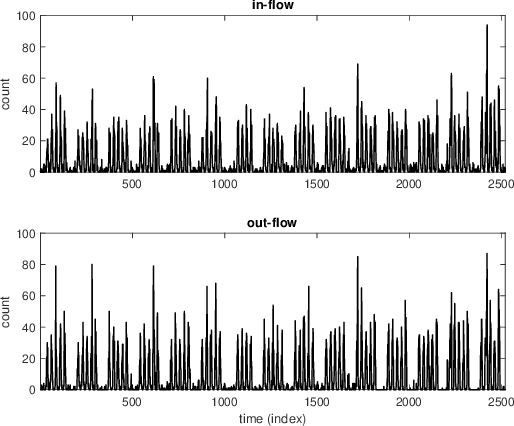
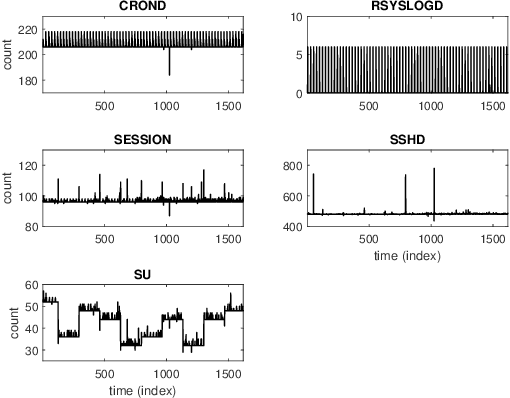
On-line detection of anomalies in time series is a key technique in various event-sensitive scenarios such as robotic system monitoring, smart sensor networks and data center security. However, the increasing diversity of data sources and demands are making this task more challenging than ever. First, the rapid increase of unlabeled data makes supervised learning no longer suitable in many cases. Second, a great portion of time series have complex seasonality features. Third, on-line anomaly detection needs to be fast and reliable. In view of this, we in this paper adopt an unsupervised prediction-driven approach on the basis of a backbone model combining a series decomposition part and an inference part. We then propose a novel metric, Local Trend Inconsistency (LTI), along with a detection algorithm that efficiently computes LTI chronologically along the series and marks each data point with a score indicating its probability of being anomalous. We experimentally evaluated our algorithm on datasets from UCI public repository and a production environment. The result shows that our scheme outperforms several representative anomaly detection algorithms in Area Under Curve (AUC) metric with decent time efficiency.
State and Topology Estimation for Unobservable Distribution Systems using Deep Neural Networks
Apr 15, 2021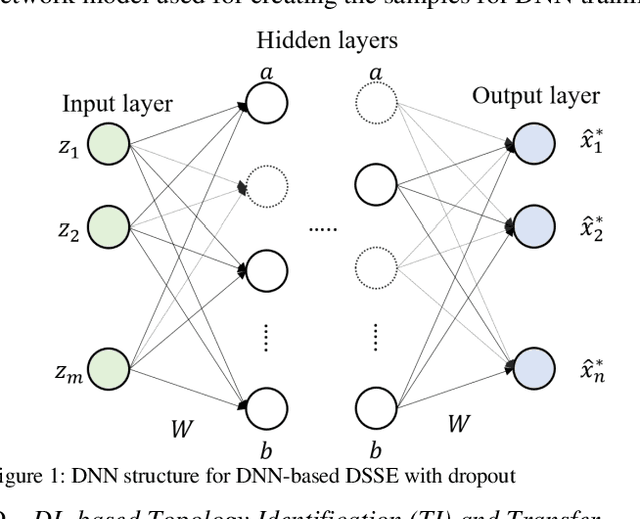
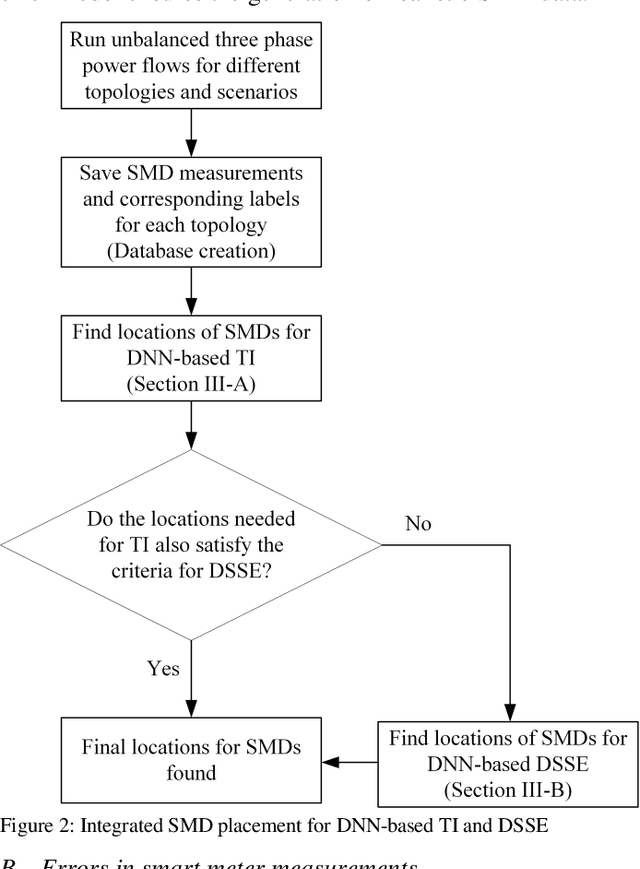
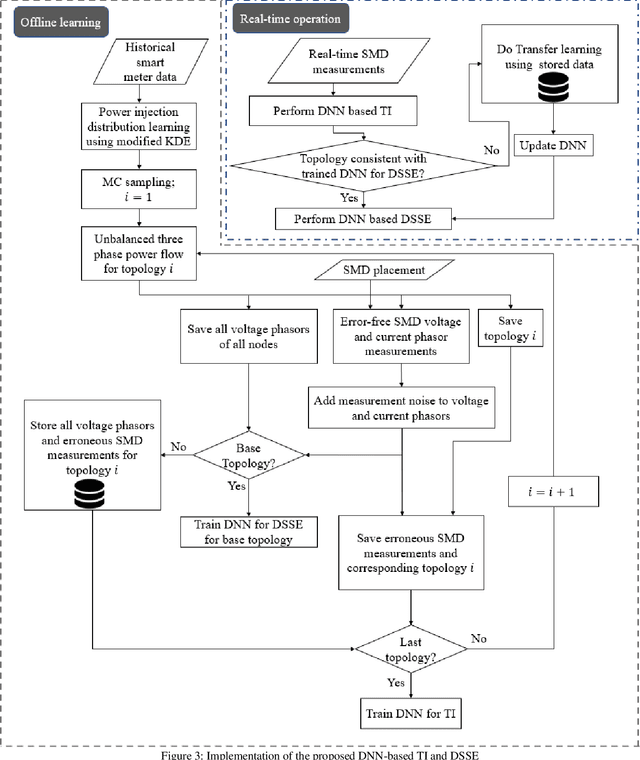
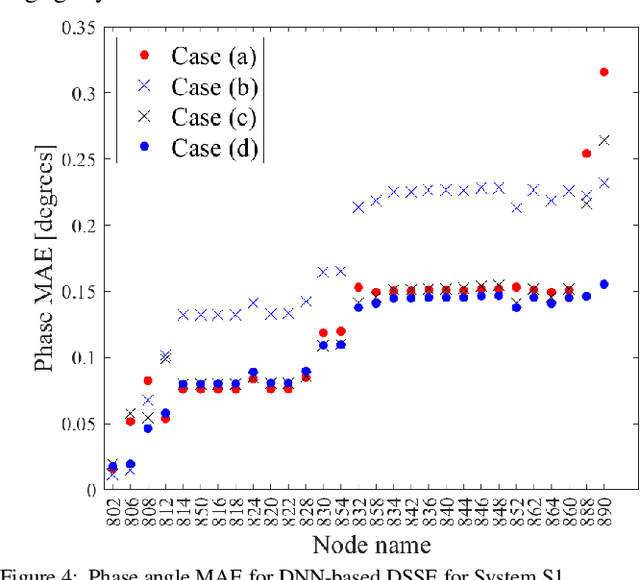
Time-synchronized state estimation for reconfigurable distribution networks is challenging because of limited real-time observability. This paper addresses this challenge by formulating a deep learning (DL)-based approach for topology identification (TI) and unbalanced three-phase distribution system state estimation (DSSE). Two deep neural networks (DNNs) are trained to operate in a sequential manner for implementing DNN-based TI and DSSE for systems that are incompletely observed by synchrophasor measurement devices (SMDs). A data-driven approach for judicious measurement selection to facilitate reliable TI and DSSE is also provided. Robustness of the proposed methodology is demonstrated by considering realistic measurement error models for SMDs as well as presence of renewable energy. A comparative study of the DNN-based DSSE with classical linear state estimation (LSE) indicates that the DL-based approach gives better accuracy with a significantly smaller number of SMDs
Real-time Prediction of Automotive Collision Risk from Monocular Video
Feb 04, 2019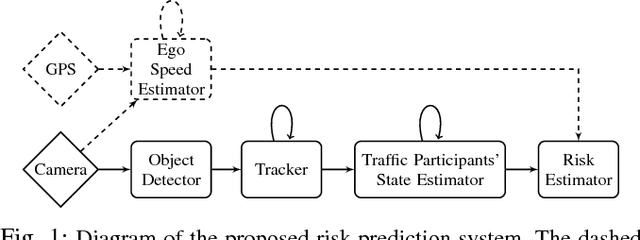

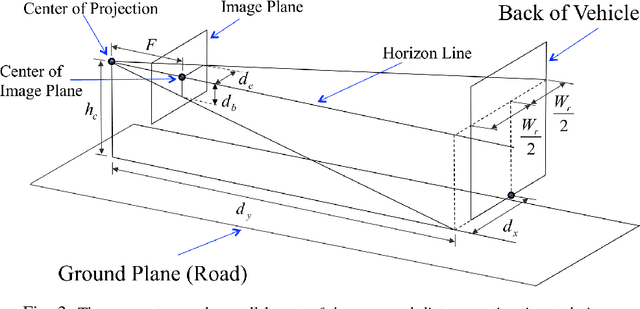
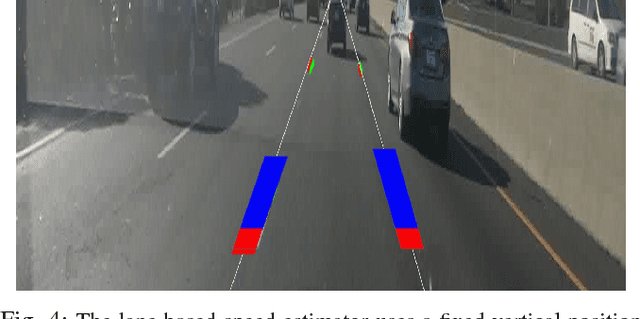
Many automotive applications, such as Advanced Driver Assistance Systems (ADAS) for collision avoidance and warnings, require estimating the future automotive risk of a driving scene. We present a low-cost system that predicts the collision risk over an intermediate time horizon from a monocular video source, such as a dashboard-mounted camera. The modular system includes components for object detection, object tracking, and state estimation. We introduce solutions to the object tracking and distance estimation problems. Advanced approaches to the other tasks are used to produce real-time predictions of the automotive risk for the next 10 s at over 5 Hz. The system is designed such that alternative components can be substituted with minimal effort. It is demonstrated on common physical hardware, specifically an off-the-shelf gaming laptop and a webcam. We extend the framework to support absolute speed estimation and more advanced risk estimation techniques.
An Efficient DP-SGD Mechanism for Large Scale NLP Models
Jul 14, 2021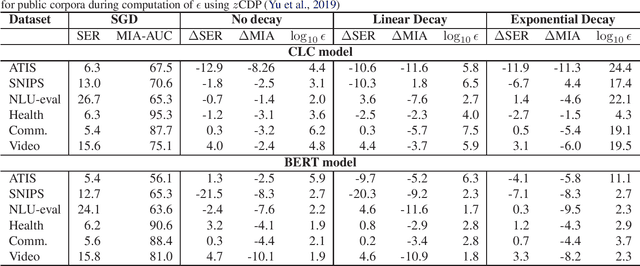
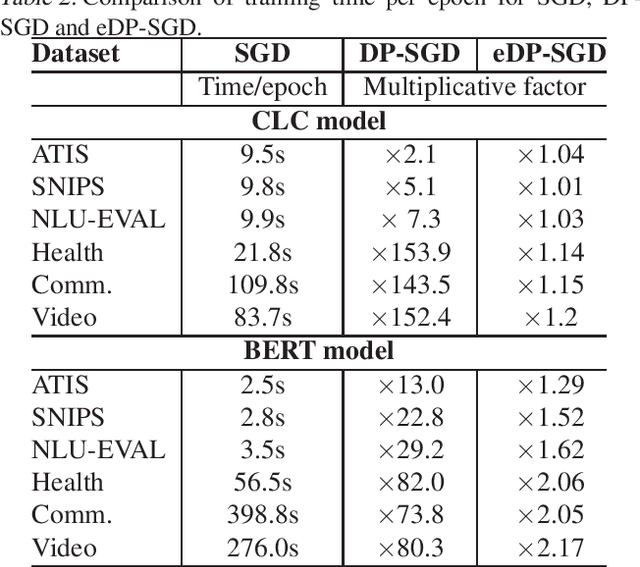
Recent advances in deep learning have drastically improved performance on many Natural Language Understanding (NLU) tasks. However, the data used to train NLU models may contain private information such as addresses or phone numbers, particularly when drawn from human subjects. It is desirable that underlying models do not expose private information contained in the training data. Differentially Private Stochastic Gradient Descent (DP-SGD) has been proposed as a mechanism to build privacy-preserving models. However, DP-SGD can be prohibitively slow to train. In this work, we propose a more efficient DP-SGD for training using a GPU infrastructure and apply it to fine-tuning models based on LSTM and transformer architectures. We report faster training times, alongside accuracy, theoretical privacy guarantees and success of Membership inference attacks for our models and observe that fine-tuning with proposed variant of DP-SGD can yield competitive models without significant degradation in training time and improvement in privacy protection. We also make observations such as looser theoretical $\epsilon, \delta$ can translate into significant practical privacy gains.
Fast and Slow Enigmas and Parental Guidance
Jul 14, 2021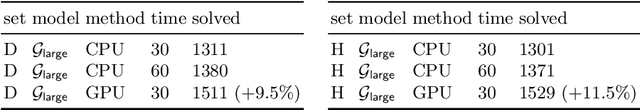
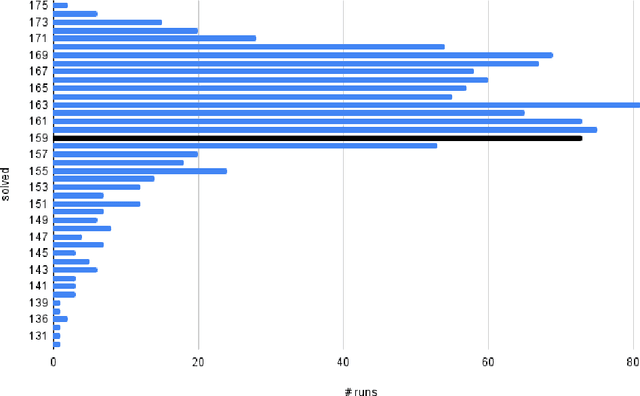
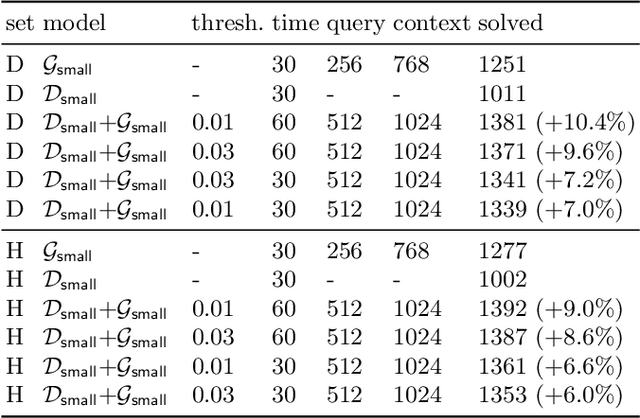
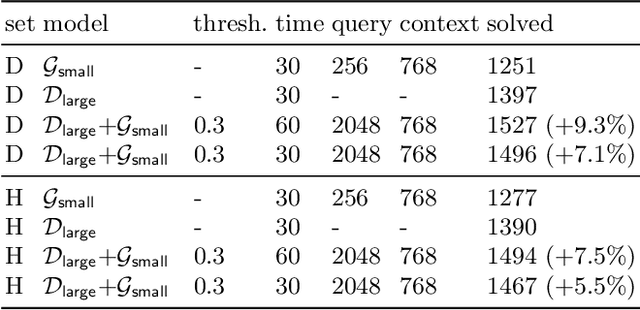
We describe several additions to the ENIGMA system that guides clause selection in the E automated theorem prover. First, we significantly speed up its neural guidance by adding server-based GPU evaluation. The second addition is motivated by fast weight-based rejection filters that are currently used in systems like E and Prover9. Such systems can be made more intelligent by instead training fast versions of ENIGMA that implement more intelligent pre-filtering. This results in combinations of trainable fast and slow thinking that improves over both the fast-only and slow-only methods. The third addition is based on "judging the children by their parents", i.e., possibly rejecting an inference before it produces a clause. This is motivated by standard evolutionary mechanisms, where there is always a cost to producing all possible offsprings in the current population. This saves time by not evaluating all clauses by more expensive methods and provides a complementary view of the generated clauses. The methods are evaluated on a large benchmark coming from the Mizar Mathematical Library, showing good improvements over the state of the art.
Cooperative Online Learning
Jun 09, 2021
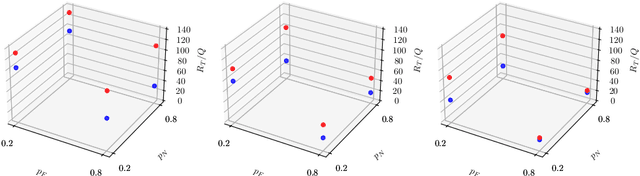
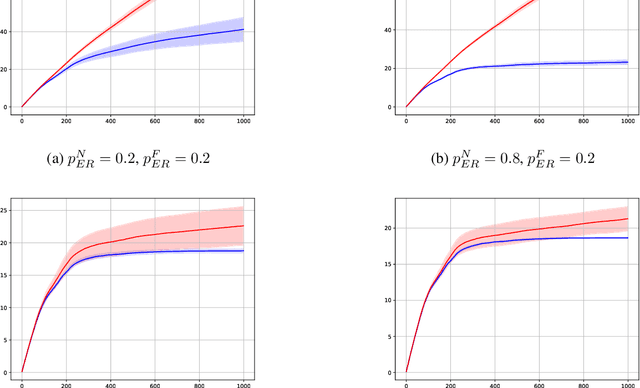
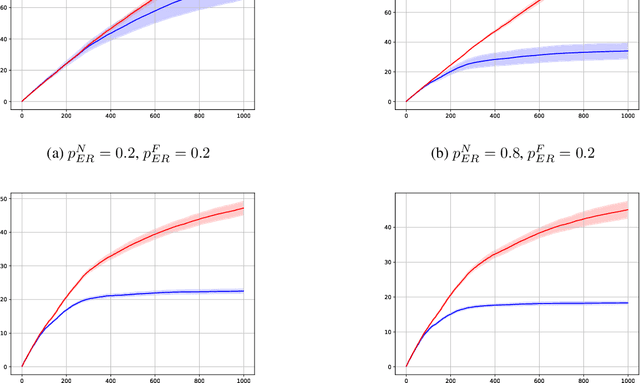
In this preliminary (and unpolished) version of the paper, we study an asynchronous online learning setting with a network of agents. At each time step, some of the agents are activated, requested to make a prediction, and pay the corresponding loss. Some feedback is then revealed to these agents and is later propagated through the network. We consider the case of full, bandit, and semi-bandit feedback. In particular, we construct a reduction to delayed single-agent learning that applies to both the full and the bandit feedback case and allows to obtain regret guarantees for both settings. We complement these results with a near-matching lower bound.
Efficient Learning of Pinball TWSVM using Privileged Information and its applications
Jul 14, 2021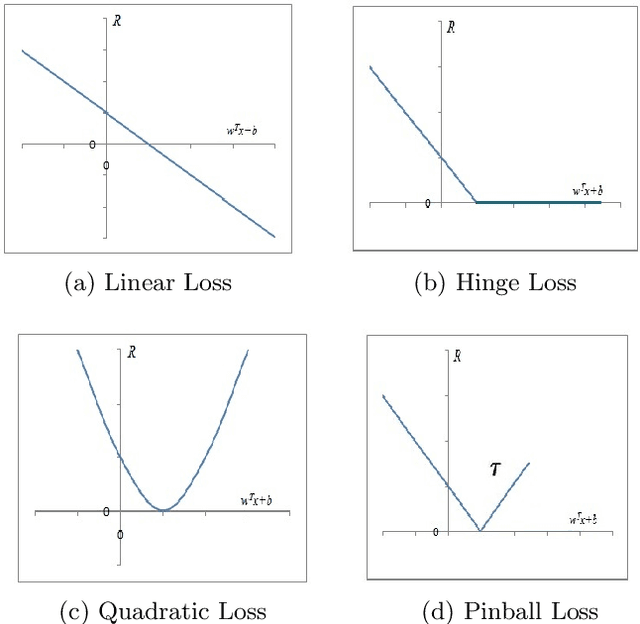

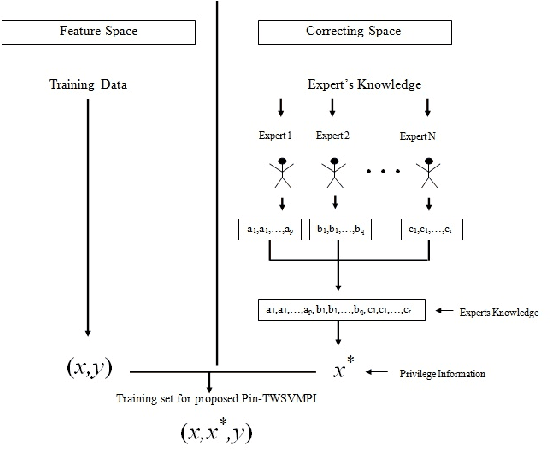

In any learning framework, an expert knowledge always plays a crucial role. But, in the field of machine learning, the knowledge offered by an expert is rarely used. Moreover, machine learning algorithms (SVM based) generally use hinge loss function which is sensitive towards the noise. Thus, in order to get the advantage from an expert knowledge and to reduce the sensitivity towards the noise, in this paper, we propose privileged information based Twin Pinball Support Vector Machine classifier (Pin-TWSVMPI) where expert's knowledge is in the form of privileged information. The proposed Pin-TWSVMPI incorporates privileged information by using correcting function so as to obtain two nonparallel decision hyperplanes. Further, in order to make computations more efficient and fast, we use Sequential Minimal Optimization (SMO) technique for obtaining the classifier and have also shown its application for Pedestrian detection and Handwritten digit recognition. Further, for UCI datasets, we first implement a procedure which extracts privileged information from the features of the dataset which are then further utilized by Pin-TWSVMPI that leads to enhancement in classification accuracy with comparatively lesser computational time.
A New Constructive Heuristic driven by Machine Learning for the Traveling Salesman Problem
Aug 17, 2021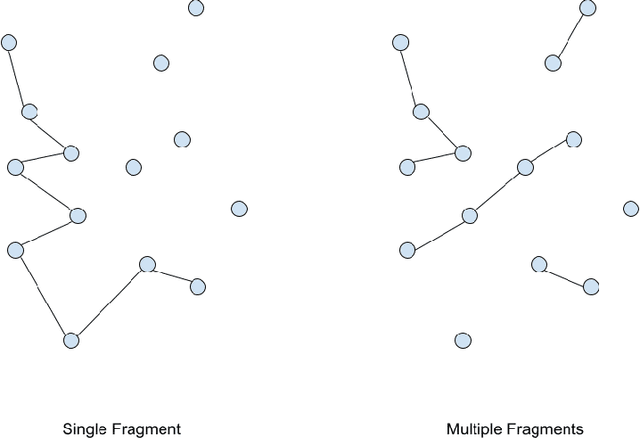
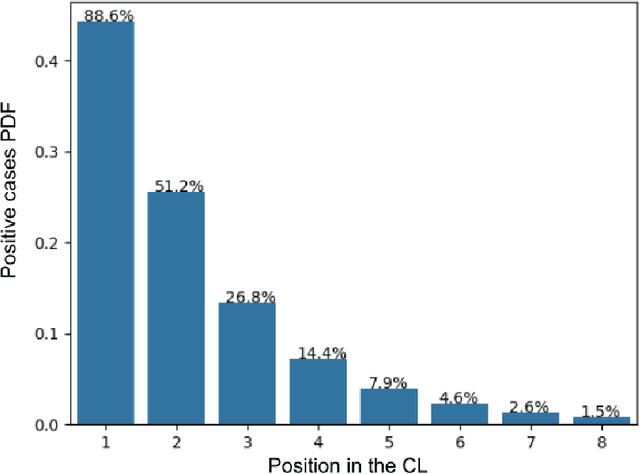
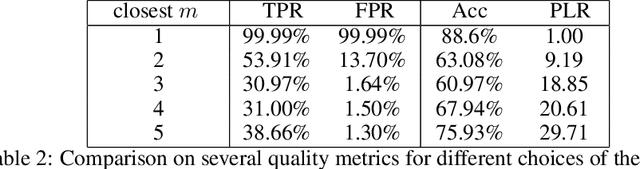
Recent systems applying Machine Learning (ML) to solve the Traveling Salesman Problem (TSP) exhibit issues when they try to scale up to real case scenarios with several hundred vertices. The use of Candidate Lists (CLs) has been brought up to cope with the issues. The procedure allows to restrict the search space during solution creation, consequently reducing the solver computational burden. So far, ML were engaged to create CLs and values on the edges of these CLs expressing ML preferences at solution insertion. Although promising, these systems do not clearly restrict what the ML learns and does to create solutions, bringing with them some generalization issues. Therefore, motivated by exploratory and statistical studies, in this work we instead use a machine learning model to confirm the addition in the solution just for high probable edges. CLs of the high probable edge are employed as input, and the ML is in charge of distinguishing cases where such edges are in the optimal solution from those where they are not. . This strategy enables a better generalization and creates an efficient balance between machine learning and searching techniques. Our ML-Constructive heuristic is trained on small instances. Then, it is able to produce solutions, without losing quality, to large problems as well. We compare our results with classic constructive heuristics, showing good performances for TSPLIB instances up to 1748 cities. Although our heuristic exhibits an expensive constant time operation, we proved that the computational complexity in worst-case scenario, for the solution construction after training, is $O(n^2 \log n^2)$, being $n$ the number of vertices in the TSP instance.