 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Numerical influence of ReLU'(0) on backpropagation
Jun 29, 2021
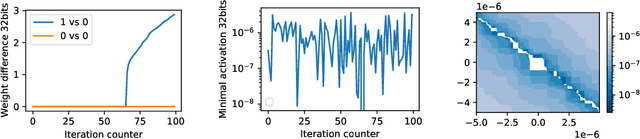
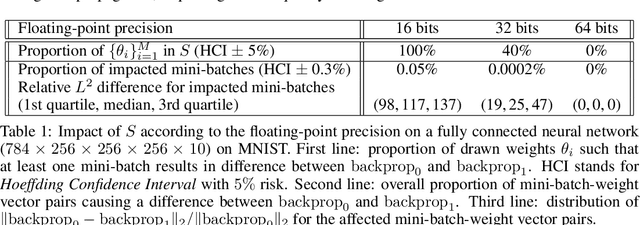
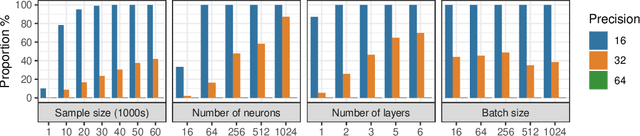
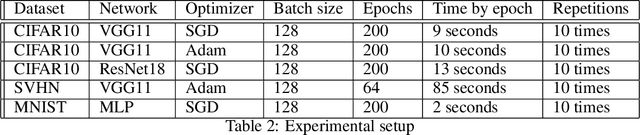
In theory, the choice of ReLU'(0) in [0, 1] for a neural network has a negligible influence both on backpropagation and training. Yet, in the real world, 32 bits default precision combined with the size of deep learning problems makes it a hyperparameter of training methods. We investigate the importance of the value of ReLU'(0) for several precision levels (16, 32, 64 bits), on various networks (fully connected, VGG, ResNet) and datasets (MNIST, CIFAR10, SVHN). We observe considerable variations of backpropagation outputs which occur around half of the time in 32 bits precision. The effect disappears with double precision, while it is systematic at 16 bits. For vanilla SGD training, the choice ReLU'(0) = 0 seems to be the most efficient. We also evidence that reconditioning approaches as batch-norm or ADAM tend to buffer the influence of ReLU'(0)'s value. Overall, the message we want to convey is that algorithmic differentiation of nonsmooth problems potentially hides parameters that could be tuned advantageously.
Development, Implementation, and Experimental Outdoor Evaluation of Quadcopter Controllers for Computationally Limited Embedded Systems
Jun 01, 2021
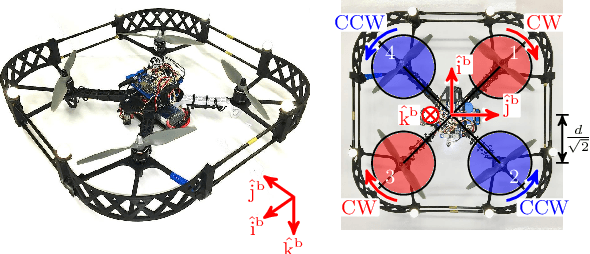
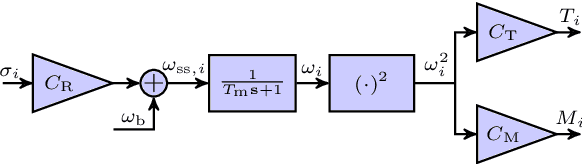
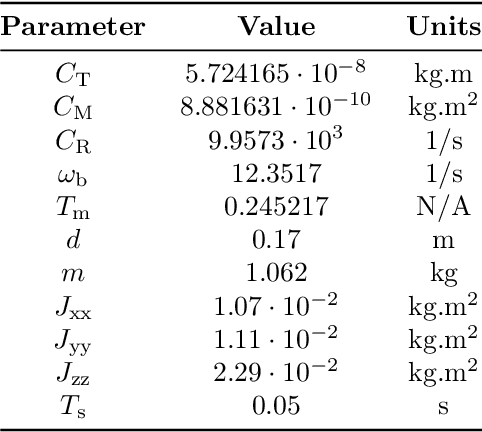
Quadcopters are increasingly used for applications ranging from hobby to industrial products and services. This paper serves as a tutorial on the design, simulation, implementation, and experimental outdoor testing of digital quadcopter flight controllers, including Explicit Model Predictive Control, Linear Quadratic Regulator, and Proportional Integral Derivative. A quadcopter was flown in an outdoor testing facility and made to track an inclined, circular path at different tangential velocities under ambient wind conditions. Controller performance was evaluated via multiple metrics, such as position tracking error, velocity tracking error, and onboard computation time. Challenges related to the use of computationally limited embedded hardware and flight in an outdoor environment are addressed with proposed solutions.
Multiplying Matrices Without Multiplying
Jun 21, 2021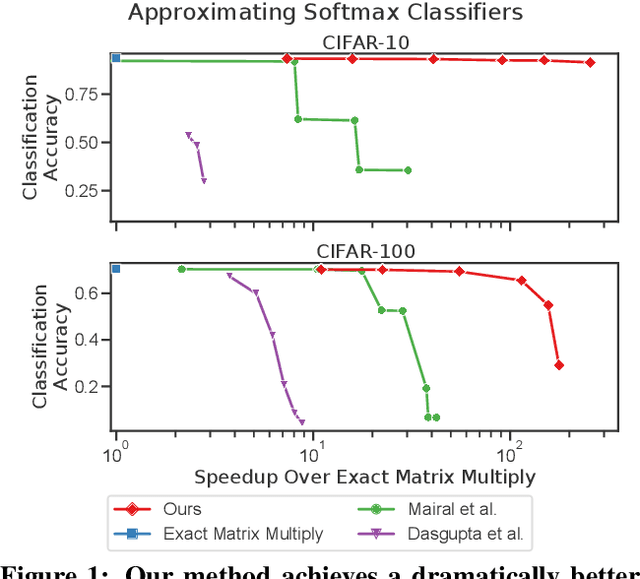
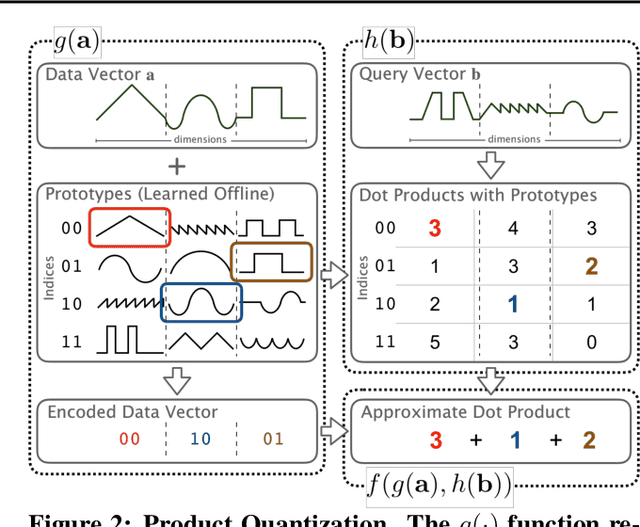
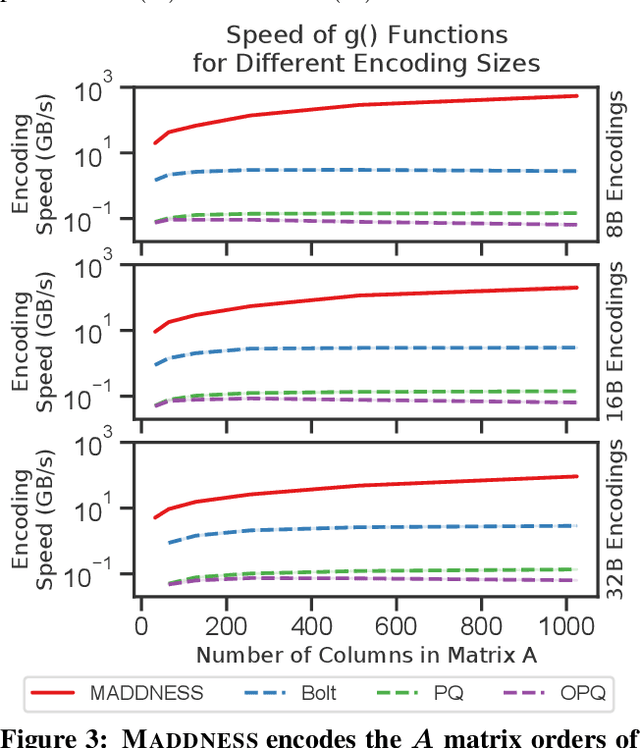
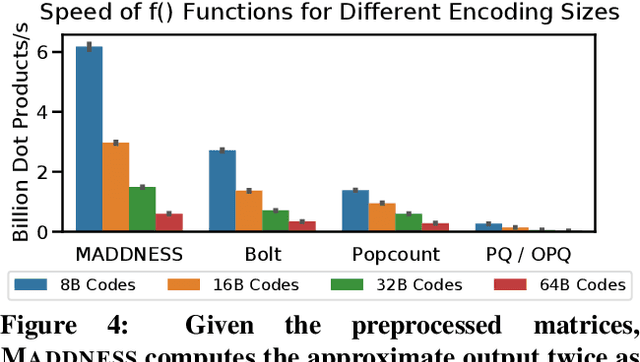
Multiplying matrices is among the most fundamental and compute-intensive operations in machine learning. Consequently, there has been significant work on efficiently approximating matrix multiplies. We introduce a learning-based algorithm for this task that greatly outperforms existing methods. Experiments using hundreds of matrices from diverse domains show that it often runs $100\times$ faster than exact matrix products and $10\times$ faster than current approximate methods. In the common case that one matrix is known ahead of time, our method also has the interesting property that it requires zero multiply-adds. These results suggest that a mixture of hashing, averaging, and byte shuffling$-$the core operations of our method$-$could be a more promising building block for machine learning than the sparsified, factorized, and/or scalar quantized matrix products that have recently been the focus of substantial research and hardware investment.
Explaining Deep Classification of Time-Series Data with Learned Prototypes
Apr 18, 2019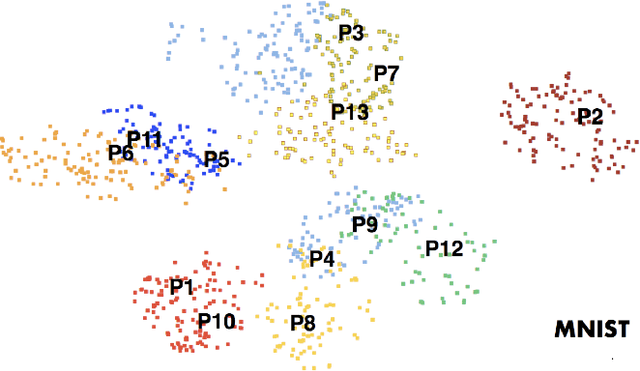

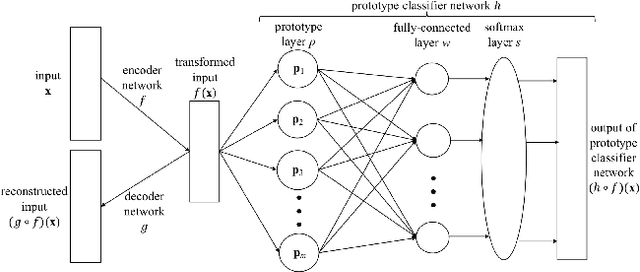
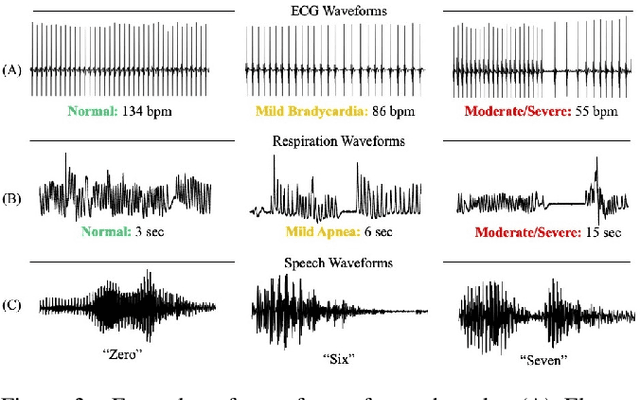
The emergence of deep learning networks raises a need for algorithms to explain their decisions so that users and domain experts can be confident using algorithmic recommendations for high-risk decisions. In this paper we leverage the information-rich latent space induced by such models to learn data representations or prototypes within such networks to elucidate their internal decision-making process. We introduce a novel application of case-based reasoning using prototypes to understand the decisions leading to the classification of time-series data, specifically investigating electrocardiogram (ECG) waveforms for classification of bradycardia, a slowing of heart rate, in infants. We improve upon existing models by explicitly optimizing for increased prototype diversity which in turn improves model accuracy by learning regions of the latent space that highlight features for distinguishing classes. We evaluate the hyperparameter space of our model to show robustness in diversity prototype generation and additionally, explore the resultant latent space of a deep classification network on ECG waveforms via an interactive tool to visualize the learned prototypical waveforms therein. We show that the prototypes are capable of learning real-world features - in our case-study ECG morphology related to bradycardia - as well as features within sub-classes. Our novel work leverages learned prototypical framework on two dimensional time-series data to produce explainable insights during classification tasks.
Modeling continuous-time stochastic processes using $\mathcal{N}$-Curve mixtures
Sep 16, 2019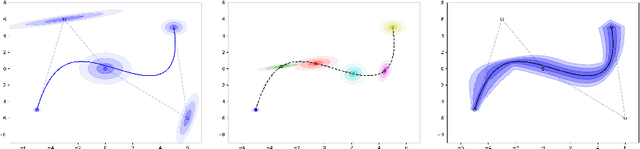

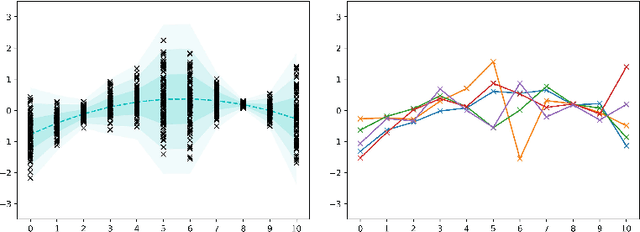
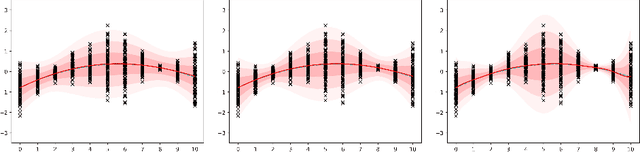
Representations of sequential data are commonly based on the assumption that observed sequences are realizations of an unknown underlying stochastic process, where the learning problem includes determination of the model parameters. In this context the model must be able to capture the multi-modal nature of the data, without blurring between modes. This property is essential for applications like trajectory prediction or human motion modeling. Towards this end, a neural network model for continuous-time stochastic processes usable for sequence prediction is proposed. The model is based on Mixture Density Networks using B\'ezier curves with Gaussian random variables as control points (abbrev.: $\mathcal{N}$-Curves). Key advantages of the model include the ability of generating smooth multi-mode predictions in a single inference step which reduces the need for Monte Carlo simulation, as required in many multi-step prediction models, based on state-of-the-art neural networks. Essential properties of the proposed approach are illustrated by several toy examples and the task of multi-step sequence prediction. Further, the model performance is evaluated on two real world use-cases, i.e. human trajectory prediction and human motion modeling, outperforming different state-of-the-art models.
Similarity metrics for Different Market Scenarios in Abides
Jul 20, 2021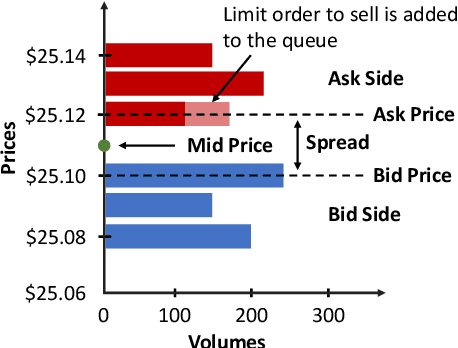
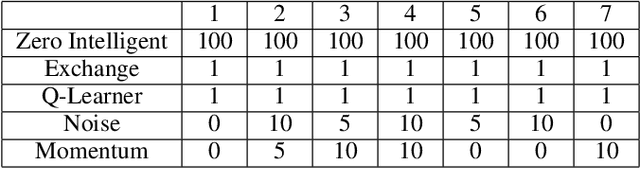
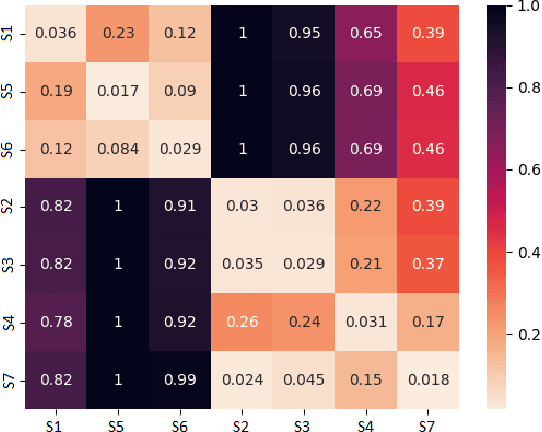
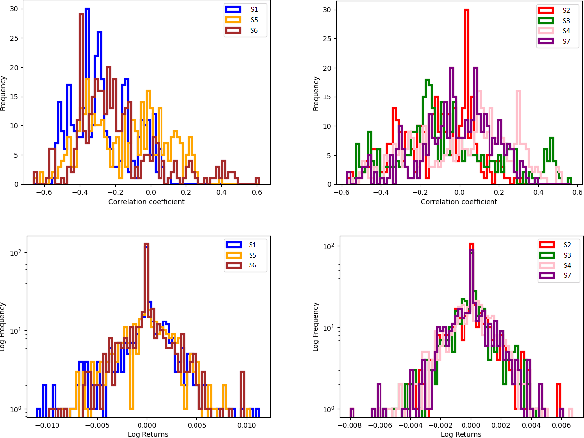
Markov Decision Processes (MDPs) are an effective way to formally describe many Machine Learning problems. In fact, recently MDPs have also emerged as a powerful framework to model financial trading tasks. For example, financial MDPs can model different market scenarios. However, the learning of a (near-)optimal policy for each of these financial MDPs can be a very time-consuming process, especially when nothing is known about the policy to begin with. An alternative approach is to find a similar financial MDP for which we have already learned its policy, and then reuse such policy in the learning of a new policy for a new financial MDP. Such a knowledge transfer between market scenarios raises several issues. On the one hand, how to measure the similarity between financial MDPs. On the other hand, how to use this similarity measurement to effectively transfer the knowledge between financial MDPs. This paper addresses both of these issues. Regarding the first one, this paper analyzes the use of three similarity metrics based on conceptual, structural and performance aspects of the financial MDPs. Regarding the second one, this paper uses Probabilistic Policy Reuse to balance the exploitation/exploration in the learning of a new financial MDP according to the similarity of the previous financial MDPs whose knowledge is reused.
RotLSTM: Rotating Memories in Recurrent Neural Networks
May 01, 2021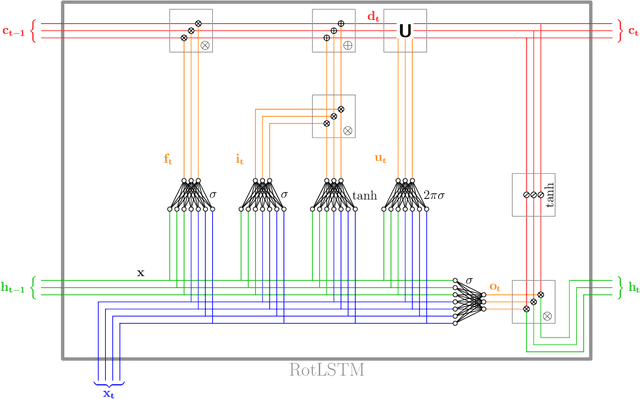


Long Short-Term Memory (LSTM) units have the ability to memorise and use long-term dependencies between inputs to generate predictions on time series data. We introduce the concept of modifying the cell state (memory) of LSTMs using rotation matrices parametrised by a new set of trainable weights. This addition shows significant increases of performance on some of the tasks from the bAbI dataset.
Interactive query expansion for professional search applications
Jun 25, 2021
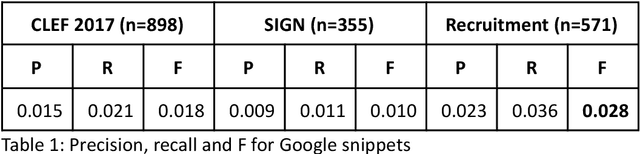
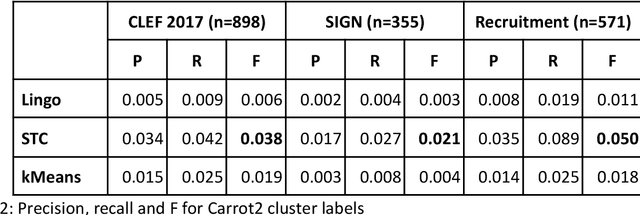
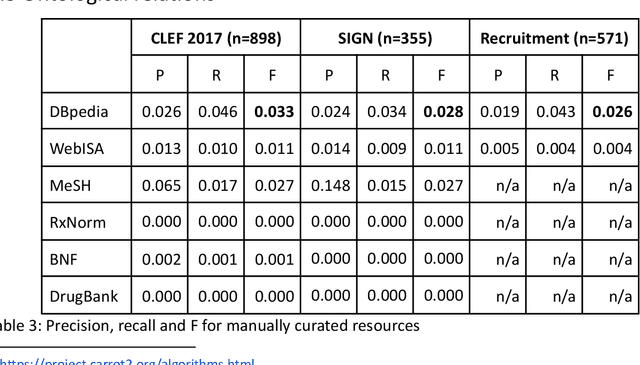
Knowledge workers (such as healthcare information professionals, patent agents and recruitment professionals) undertake work tasks where search forms a core part of their duties. In these instances, the search task is often complex and time-consuming and requires specialist expert knowledge to formulate accurate search strategies. Interactive features such as query expansion can play a key role in supporting these tasks. However, generating query suggestions within a professional search context requires that consideration be given to the specialist, structured nature of the search strategies they employ. In this paper, we investigate a variety of query expansion methods applied to a collection of Boolean search strategies used in a variety of real-world professional search tasks. The results demonstrate the utility of context-free distributional language models and the value of using linguistic cues such as ngram order to optimise the balance between precision and recall.
Dynamic Grasping with Reachability and Motion Awareness
Mar 18, 2021
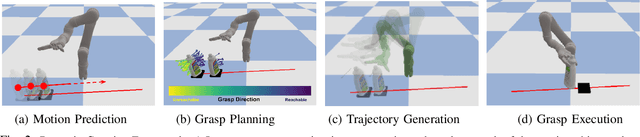
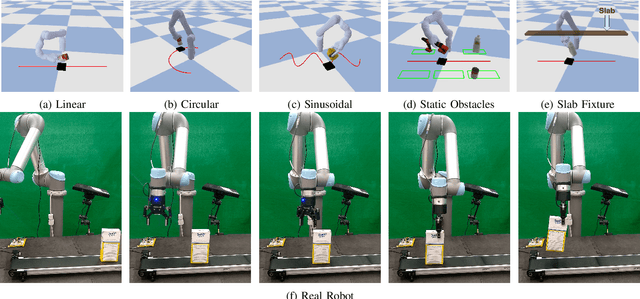
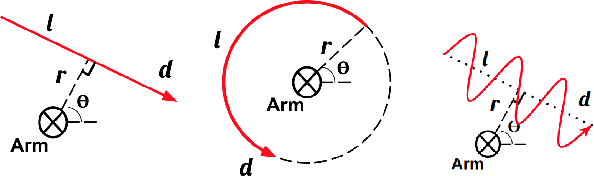
Grasping in dynamic environments presents a unique set of challenges. A stable and reachable grasp can become unreachable and unstable as the target object moves, motion planning needs to be adaptive and in real time, the delay in computation makes prediction necessary. In this paper, we present a dynamic grasping framework that is reachability-aware and motion-aware. Specifically, we model the reachability space of the robot using a signed distance field which enables us to quickly screen unreachable grasps. Also, we train a neural network to predict the grasp quality conditioned on the current motion of the target. Using these as ranking functions, we quickly filter a large grasp database to a few grasps in real time. In addition, we present a seeding approach for arm motion generation that utilizes solution from previous time step. This quickly generates a new arm trajectory that is close to the previous plan and prevents fluctuation. We implement a recurrent neural network (RNN) for modelling and predicting the object motion. Our extensive experiments demonstrate the importance of each of these components and we validate our pipeline on a real robot.
Travel Time Prediction using Tree-Based Ensembles
May 28, 2020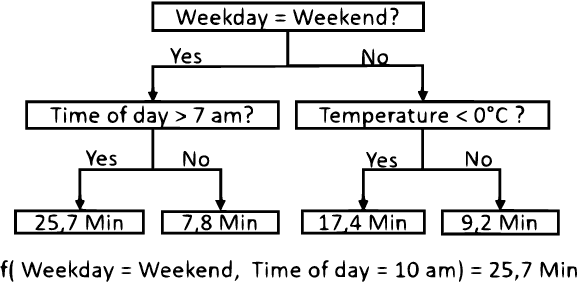
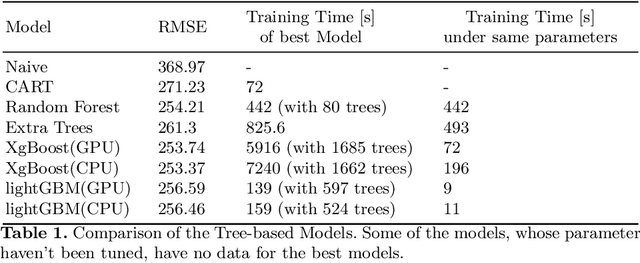
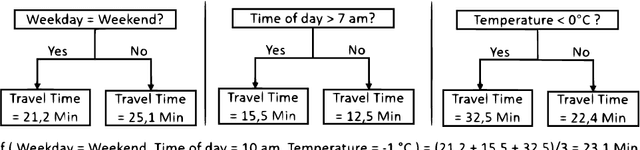
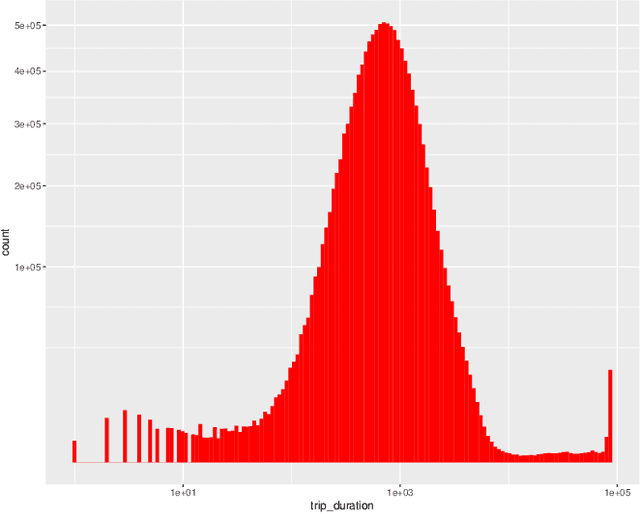
In this paper, we consider the task of predicting travel times between two arbitrary points in an urban scenario. We view this problem from two temporal perspectives: long-term forecasting with a horizon of several days and short-term forecasting with a horizon of one hour. Both of these perspectives are relevant for planning tasks in the context of urban mobility and transportation services. We utilize tree-based ensemble methods that we train and evaluate on a dataset of taxi trip records from New York City. Through extensive data analysis, we identify relevant temporal and spatial features. We also engineer additional features based on weather and routing data. The latter is obtained via a routing solver operating on the road network. The computational results show that the addition of this routing data can be beneficial to the model performance. Moreover, employing different models for short and long-term prediction is useful as short-term models are better suited to mirror current traffic conditions. In fact, we show that accurate short-term predictions may be obtained with only little training data.