 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Grouped Convolutional Neural Networks for Multivariate Time Series
May 31, 2018
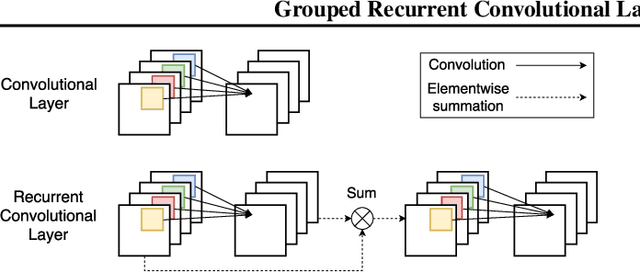
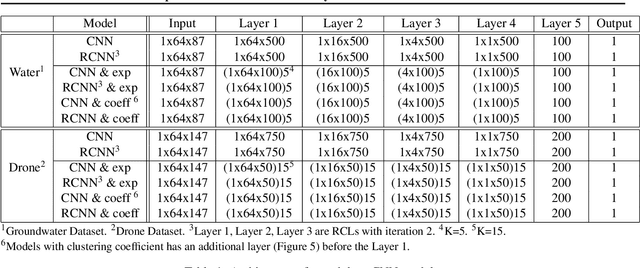
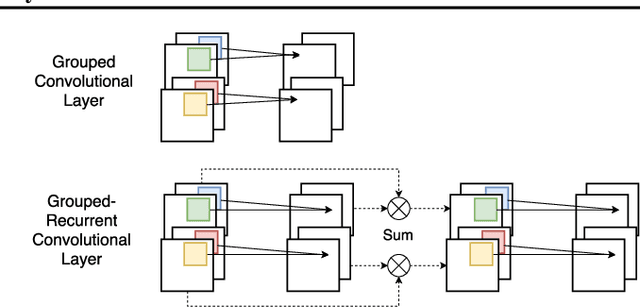
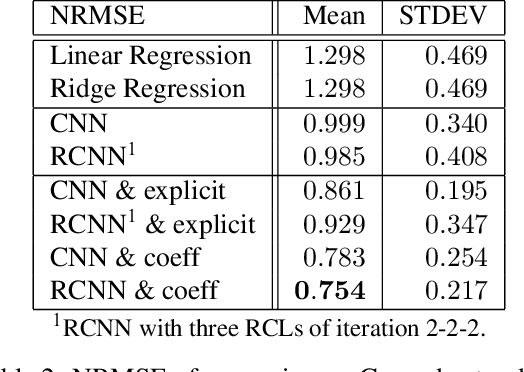
Analyzing multivariate time series data is important for many applications such as automated control, fault diagnosis and anomaly detection. One of the key challenges is to learn latent features automatically from dynamically changing multivariate input. In visual recognition tasks, convolutional neural networks (CNNs) have been successful to learn generalized feature extractors with shared parameters over the spatial domain. However, when high-dimensional multivariate time series is given, designing an appropriate CNN model structure becomes challenging because the kernels may need to be extended through the full dimension of the input volume. To address this issue, we present two structure learning algorithms for deep CNN models. Our algorithms exploit the covariance structure over multiple time series to partition input volume into groups. The first algorithm learns the group CNN structures explicitly by clustering individual input sequences. The second algorithm learns the group CNN structures implicitly from the error backpropagation. In experiments with two real-world datasets, we demonstrate that our group CNNs outperform existing CNN based regression methods.
H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
Jul 26, 2021
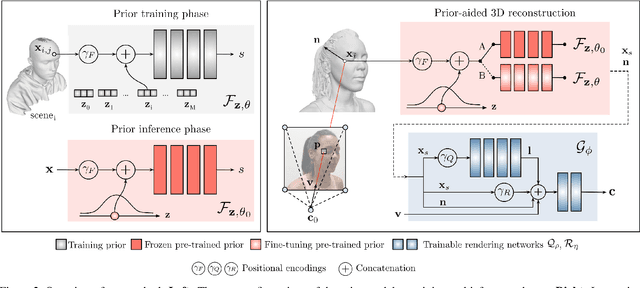


Recent learning approaches that implicitly represent surface geometry using coordinate-based neural representations have shown impressive results in the problem of multi-view 3D reconstruction. The effectiveness of these techniques is, however, subject to the availability of a large number (several tens) of input views of the scene, and computationally demanding optimizations. In this paper, we tackle these limitations for the specific problem of few-shot full 3D head reconstruction, by endowing coordinate-based representations with a probabilistic shape prior that enables faster convergence and better generalization when using few input images (down to three). First, we learn a shape model of 3D heads from thousands of incomplete raw scans using implicit representations. At test time, we jointly overfit two coordinate-based neural networks to the scene, one modeling the geometry and another estimating the surface radiance, using implicit differentiable rendering. We devise a two-stage optimization strategy in which the learned prior is used to initialize and constrain the geometry during an initial optimization phase. Then, the prior is unfrozen and fine-tuned to the scene. By doing this, we achieve high-fidelity head reconstructions, including hair and shoulders, and with a high level of detail that consistently outperforms both state-of-the-art 3D Morphable Models methods in the few-shot scenario, and non-parametric methods when large sets of views are available.
Transfer Learning for Clinical Time Series Analysis using Deep Neural Networks
Apr 01, 2019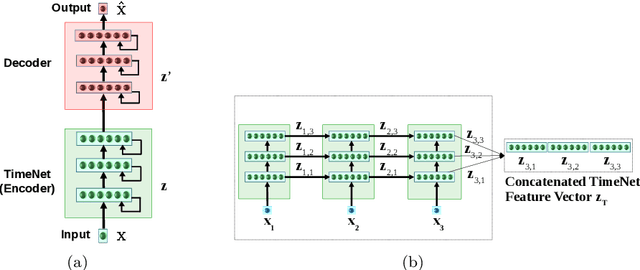
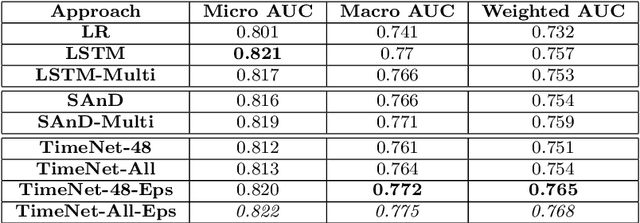
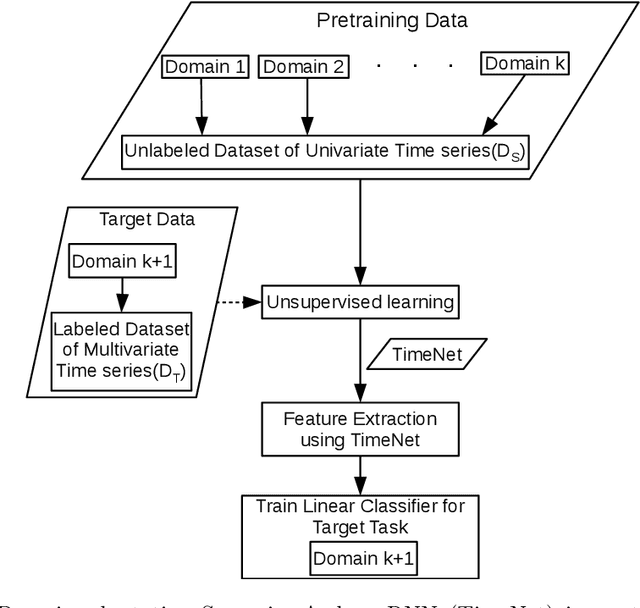
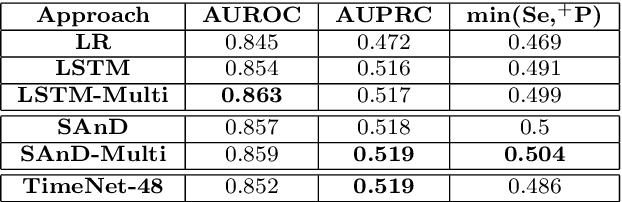
Deep neural networks have shown promising results for various clinical prediction tasks. However, training deep networks such as those based on Recurrent Neural Networks (RNNs) requires large labeled data, significant hyper-parameter tuning effort and expertise, and high computational resources. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider two scenarios for transfer learning using RNNs: i) domain-adaptation, i.e., leveraging a deep RNN - namely, TimeNet - pre-trained for feature extraction on time series from diverse domains, and adapting it for feature extraction and subsequent target tasks in healthcare domain, ii) task-adaptation, i.e., pre-training a deep RNN - namely, HealthNet - on diverse tasks in healthcare domain, and adapting it to new target tasks in the same domain. We evaluate the above approaches on publicly available MIMIC-III benchmark dataset, and demonstrate that (a) computationally-efficient linear models trained using features extracted via pre-trained RNNs outperform or, in the worst case, perform as well as deep RNNs and statistical hand-crafted features based models trained specifically for target task; (b) models obtained by adapting pre-trained models for target tasks are significantly more robust to the size of labeled data compared to task-specific RNNs, while also being computationally efficient. We, therefore, conclude that pre-trained deep models like TimeNet and HealthNet allow leveraging the advantages of deep learning for clinical time series analysis tasks, while also minimize dependence on hand-crafted features, deal robustly with scarce labeled training data scenarios without overfitting, as well as reduce dependence on expertise and resources required to train deep networks from scratch.
Dynamic Imaging using Deep Bi-linear Unsupervised Regularization (DEBLUR)
Jun 30, 2021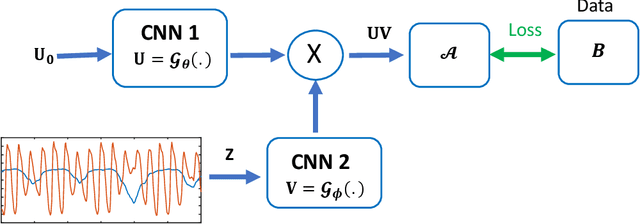
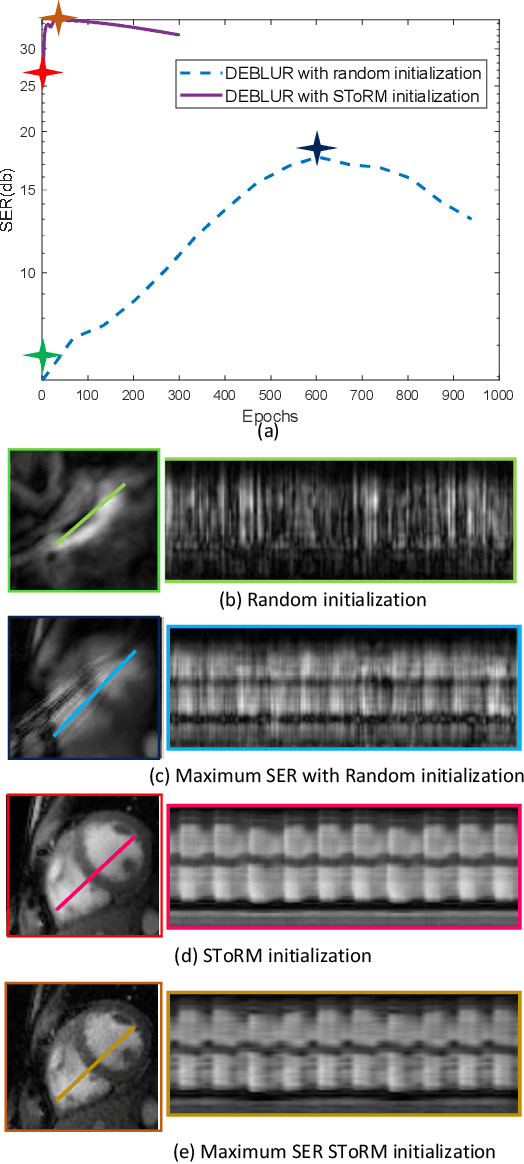
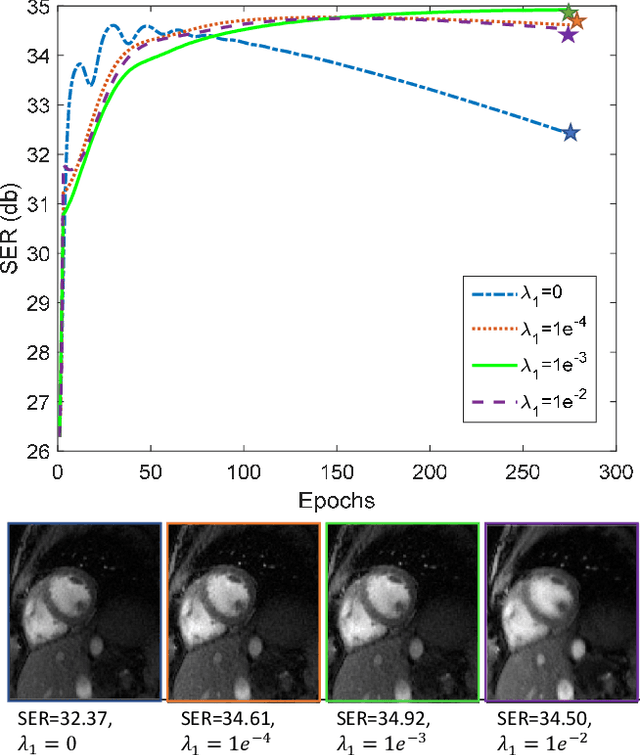
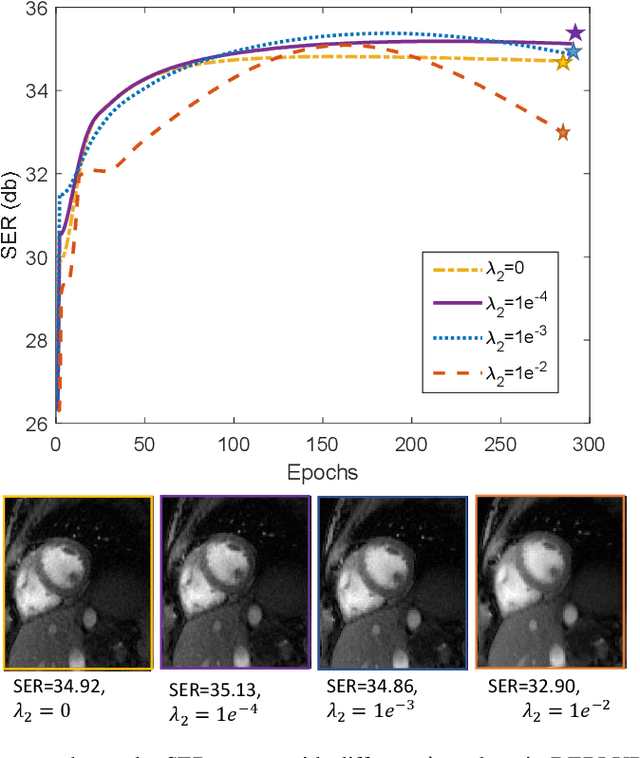
Bilinear models that decompose dynamic data to spatial and temporal factors are powerful and memory-efficient tools for the recovery of dynamic MRI data. These methods rely on sparsity and energy compaction priors on the factors to regularize the recovery. The quality of the recovered images depend on the specific priors. Motivated by deep image prior, we introduce a novel bilinear model whose factors are represented using convolutional neural networks (CNNs). The CNN parameters are learned from the undersampled data off the same subject. To reduce the run time and to improve performance, we initialize the CNN parameters. We use sparsity regularization of the network parameters to minimize the overfitting of the network to measurement noise. Our experiments on free breathing and ungated cardiac cine data acquired using a navigated golden-angle gradient-echo radial sequence show the ability of our method to provide reduced spatial blurring as compared to low-rank and SToRM reconstructions.
Minimum sharpness: Scale-invariant parameter-robustness of neural networks
Jun 26, 2021
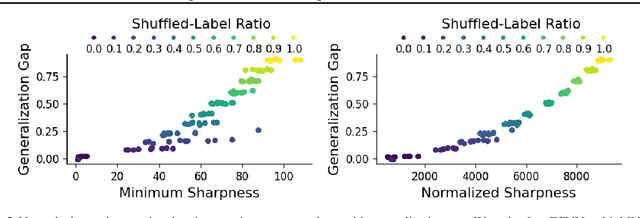
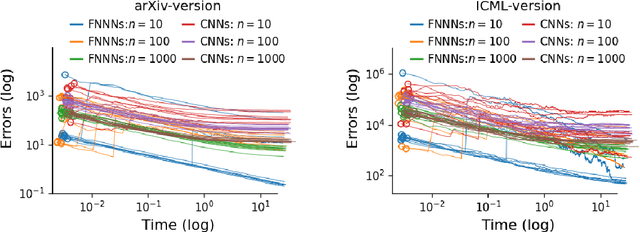
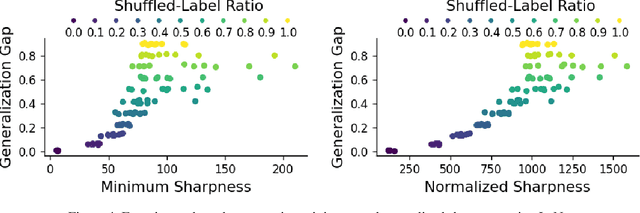
Toward achieving robust and defensive neural networks, the robustness against the weight parameters perturbations, i.e., sharpness, attracts attention in recent years (Sun et al., 2020). However, sharpness is known to remain a critical issue, "scale-sensitivity." In this paper, we propose a novel sharpness measure, Minimum Sharpness. It is known that NNs have a specific scale transformation that constitutes equivalent classes where functional properties are completely identical, and at the same time, their sharpness could change unlimitedly. We define our sharpness through a minimization problem over the equivalent NNs being invariant to the scale transformation. We also develop an efficient and exact technique to make the sharpness tractable, which reduces the heavy computational costs involved with Hessian. In the experiment, we observed that our sharpness has a valid correlation with the generalization of NNs and runs with less computational cost than existing sharpness measures.
Field trial on Ocean Estimation for Multi-Vessel Multi-Float-based Active perception
Jun 17, 2021
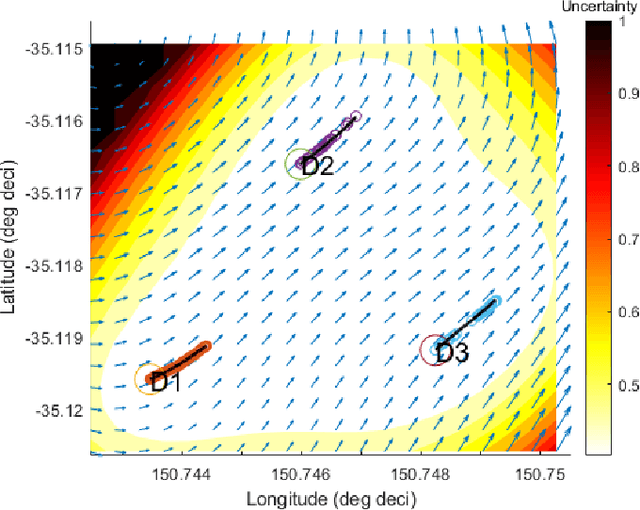
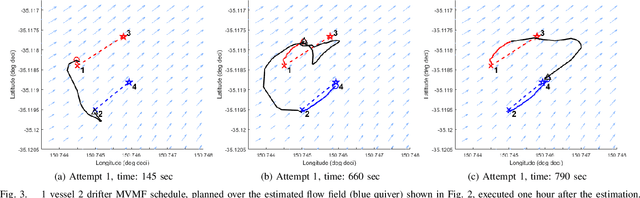
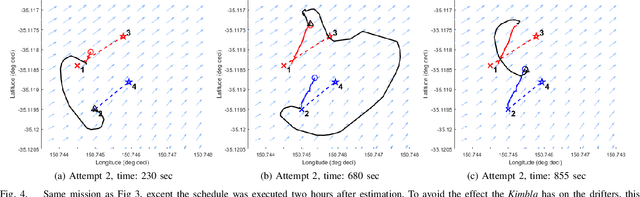
Marine vehicles have been used for various scientific missions where information over features of interest is collected. In order to maximise efficiency in collecting information over a large search space, we should be able to deploy a large number of autonomous vehicles that make a decision based on the latest understanding of the target feature in the environment. In our previous work, we have presented a hierarchical framework for the multi-vessel multi-float (MVMF) problem where surface vessels drop and pick up underactuated floats in a time-minimal way. In this paper, we present the field trial results using the framework with a number of drifters and floats. We discovered a number of important aspects that need to be considered in the proposed framework, and present the potential approaches to address the challenges.
Model-free Reinforcement Learning for Branching Markov Decision Processes
Jun 12, 2021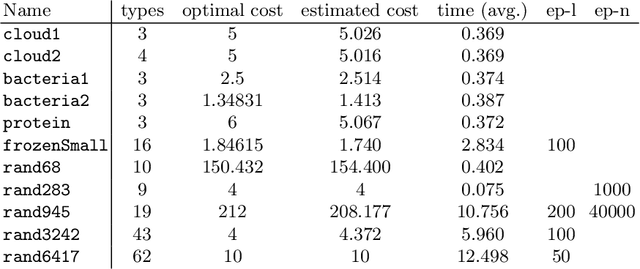
We study reinforcement learning for the optimal control of Branching Markov Decision Processes (BMDPs), a natural extension of (multitype) Branching Markov Chains (BMCs). The state of a (discrete-time) BMCs is a collection of entities of various types that, while spawning other entities, generate a payoff. In comparison with BMCs, where the evolution of a each entity of the same type follows the same probabilistic pattern, BMDPs allow an external controller to pick from a range of options. This permits us to study the best/worst behaviour of the system. We generalise model-free reinforcement learning techniques to compute an optimal control strategy of an unknown BMDP in the limit. We present results of an implementation that demonstrate the practicality of the approach.
Learning Hamiltonian dynamics by reservoir computer
Apr 24, 2021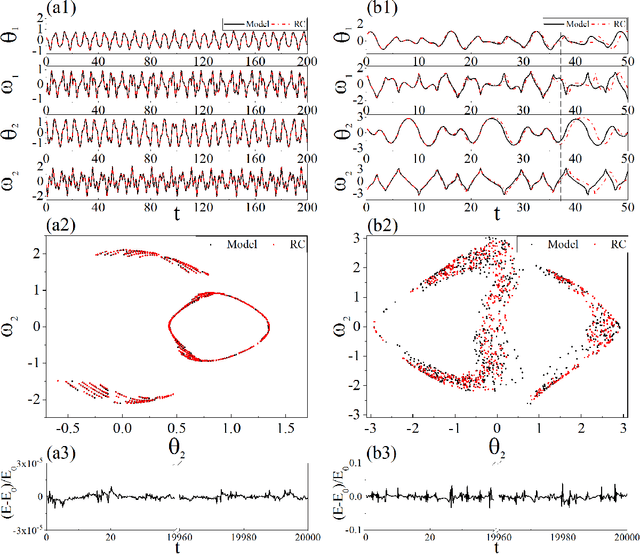
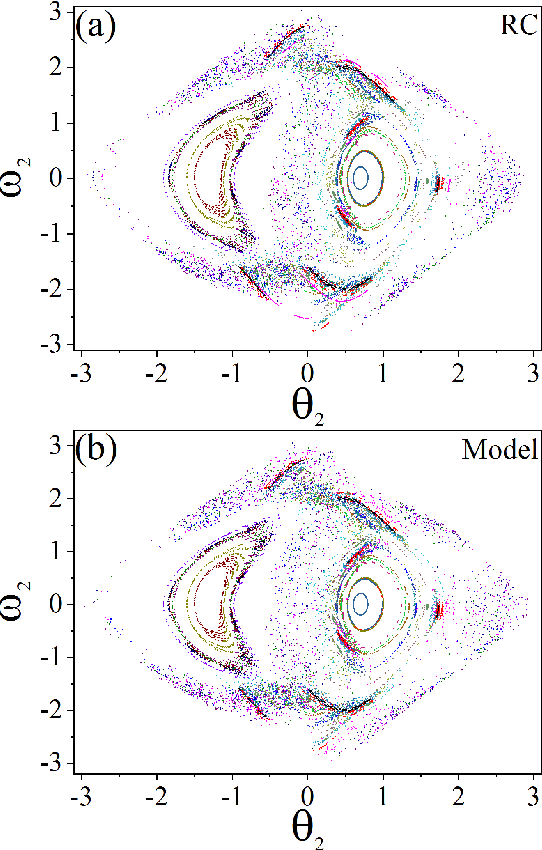
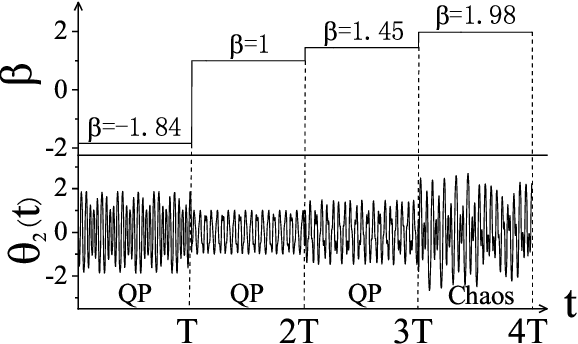
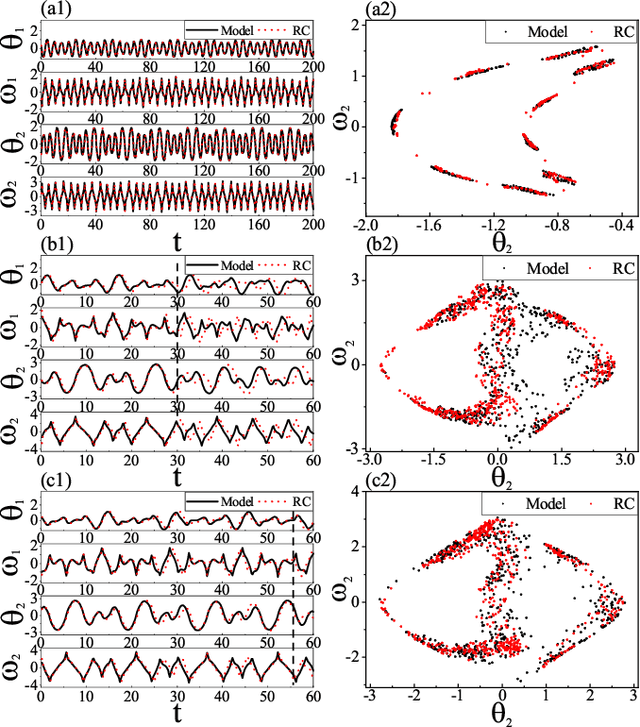
Reconstructing the KAM dynamics diagram of Hamiltonian system from the time series of a limited number of parameters is an outstanding question in nonlinear science, especially when the Hamiltonian governing the system dynamics are unknown. Here, we demonstrate that this question can be addressed by the machine learning approach knowing as reservoir computer (RC). Specifically, we show that without prior knowledge about the Hamilton's equations of motion, the trained RC is able to not only predict the short-term evolution of the system state, but also replicate the long-term ergodic properties of the system dynamics. Furthermore, by the architecture of parameter-aware RC, we also show that the RC trained by the time series acquired at a handful parameters is able to reconstruct the entire KAM dynamics diagram with a high precision by tuning a control parameter externally. The feasibility and efficiency of the learning techniques are demonstrated in two classical nonlinear Hamiltonian systems, namely the double-pendulum oscillator and the standard map. Our study indicates that, as a complex dynamical system, RC is able to learn from data the Hamiltonian.
POLAR: A Polynomial Arithmetic Framework for Verifying Neural-Network Controlled Systems
Jul 07, 2021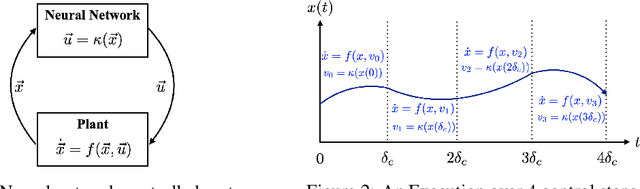
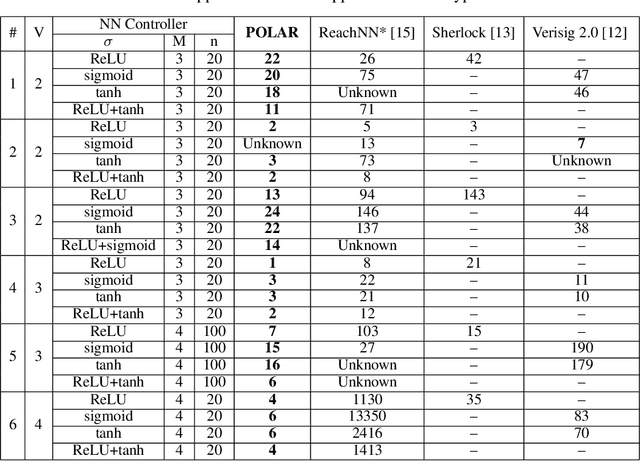
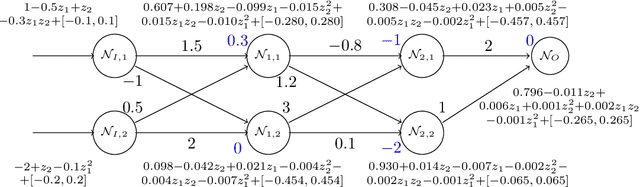
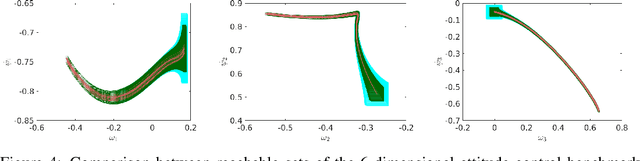
We propose POLAR, a \textbf{pol}ynomial \textbf{ar}ithmetic framework that leverages polynomial overapproximations with interval remainders for bounded-time reachability analysis of neural network-controlled systems (NNCSs). Compared with existing arithmetic approaches that use standard Taylor models, our framework uses a novel approach to iteratively overapproximate the neuron output ranges layer-by-layer with a combination of Bernstein polynomial interpolation for continuous activation functions and Taylor model arithmetic for the other operations. This approach can overcome the main drawback in the standard Taylor model arithmetic, i.e. its inability to handle functions that cannot be well approximated by Taylor polynomials, and significantly improve the accuracy and efficiency of reachable states computation for NNCSs. To further tighten the overapproximation, our method keeps the Taylor model remainders symbolic under the linear mappings when estimating the output range of a neural network. We show that POLAR can be seamlessly integrated with existing Taylor model flowpipe construction techniques, and demonstrate that POLAR significantly outperforms the current state-of-the-art techniques on a suite of benchmarks.
Time-to-Event Prediction with Neural Networks and Cox Regression
Jul 01, 2019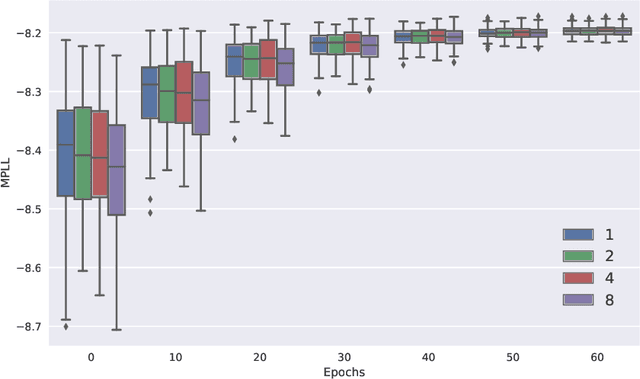

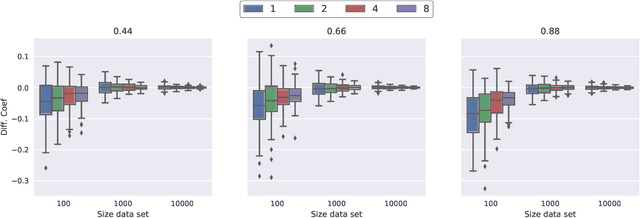
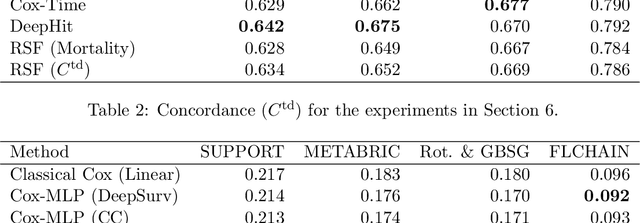
New methods for time-to-event prediction are proposed by extending the Cox proportional hazards model with neural networks. Building on methodology from nested case-control studies, we propose a loss function that scales well to large data sets, and enables fitting of both proportional and non-proportional extensions of the Cox model. Through simulation studies, the proposed loss function is verified to be a good approximation for the Cox partial log-likelihood. The proposed methodology is compared to existing methodologies on real-world data sets, and is found to be highly competitive, typically yielding the best performance in terms of Brier score and binomial log-likelihood. A python package for the proposed methods is available at https://github.com/havakv/pycox.