 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
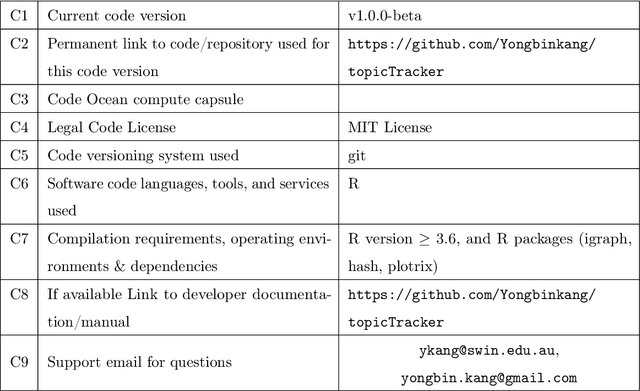
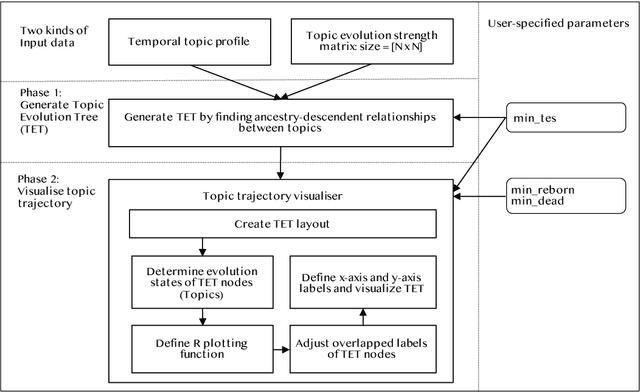
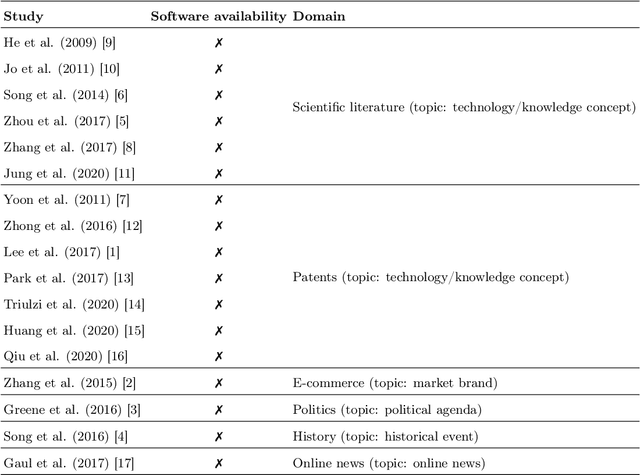
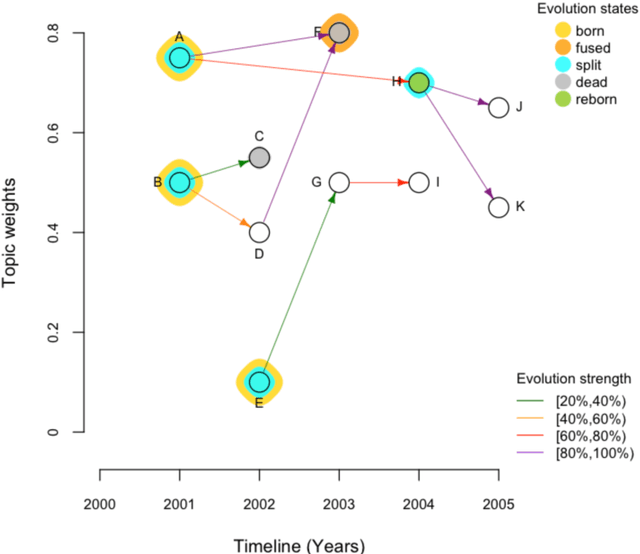
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
Cervical Optical Coherence Tomography Image Classification Based on Contrastive Self-Supervised Texture Learning
Aug 11, 2021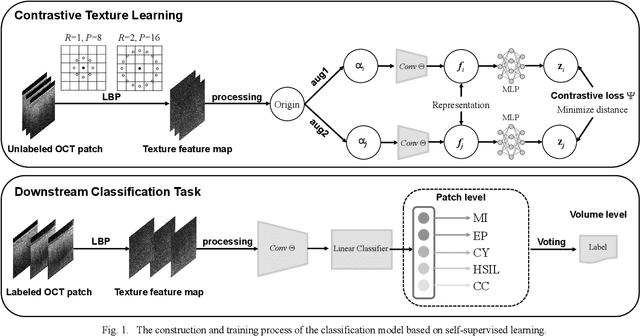
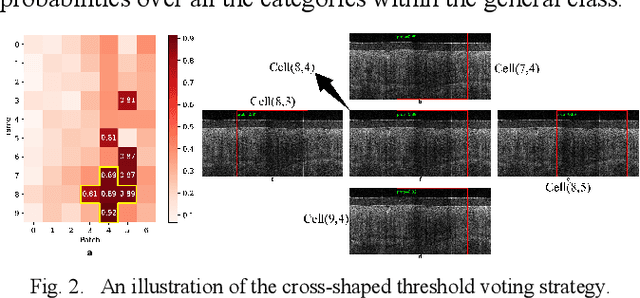
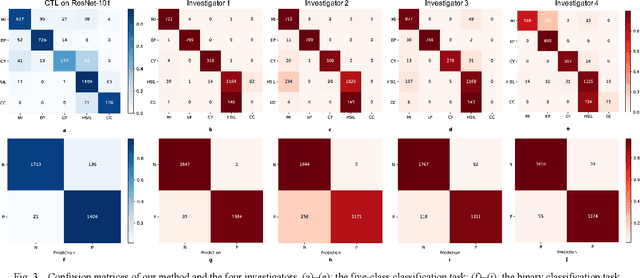
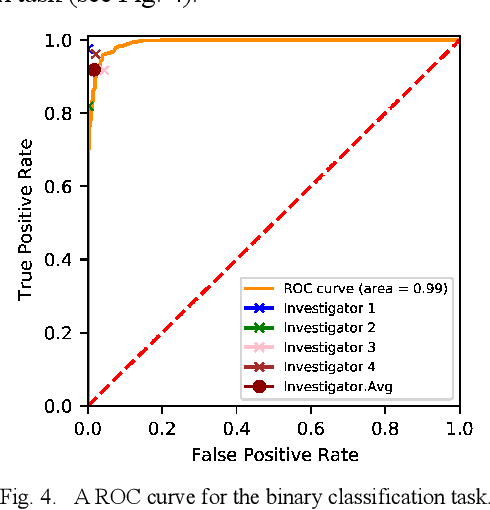
Background: Cervical cancer seriously affects the health of the female reproductive system. Optical coherence tomography (OCT) emerges as a non-invasive, high-resolution imaging technology for cervical disease detection. However, OCT image annotation is knowledge-intensive and time-consuming, which impedes the training process of deep-learning-based classification models. Objective: This study aims to develop a computer-aided diagnosis (CADx) approach to classifying in-vivo cervical OCT images based on self-supervised learning. Methods: Besides high-level semantic features extracted by a convolutional neural network (CNN), the proposed CADx approach leverages unlabeled cervical OCT images' texture features learned by contrastive texture learning. We conducted ten-fold cross-validation on the OCT image dataset from a multi-center clinical study on 733 patients from China. Results: In a binary classification task for detecting high-risk diseases, including high-grade squamous intraepithelial lesion (HSIL) and cervical cancer, our method achieved an area-under-the-curve (AUC) value of 0.9798 Plus or Minus 0.0157 with a sensitivity of 91.17 Plus or Minus 4.99% and a specificity of 93.96 Plus or Minus 4.72% for OCT image patches; also, it outperformed two out of four medical experts on the test set. Furthermore, our method achieved a 91.53% sensitivity and 97.37% specificity on an external validation dataset containing 287 3D OCT volumes from 118 Chinese patients in a new hospital using a cross-shaped threshold voting strategy. Conclusion: The proposed contrastive-learning-based CADx method outperformed the end-to-end CNN models and provided better interpretability based on texture features, which holds great potential to be used in the clinical protocol of "see-and-treat."
Informed Machine Learning for Improved Similarity Assessment in Process-Oriented Case-Based Reasoning
Jun 30, 2021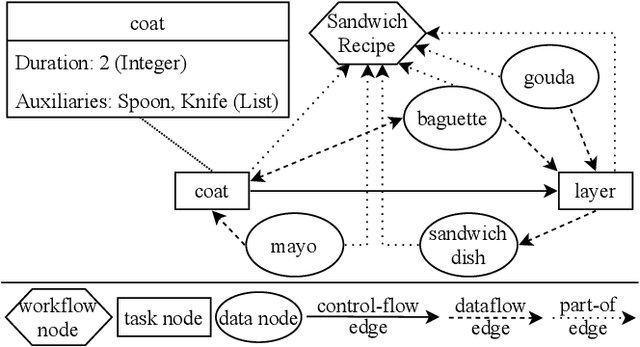

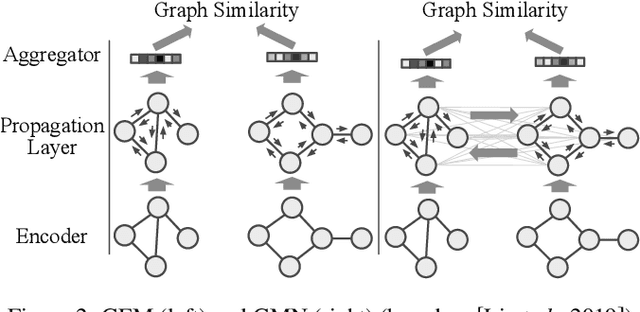
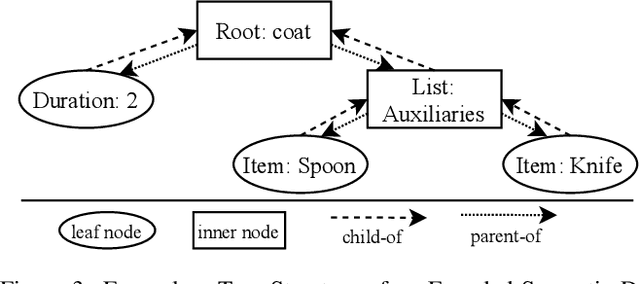
Currently, Deep Learning (DL) components within a Case-Based Reasoning (CBR) application often lack the comprehensive integration of available domain knowledge. The trend within machine learning towards so-called Informed machine learning can help to overcome this limitation. In this paper, we therefore investigate the potential of integrating domain knowledge into Graph Neural Networks (GNNs) that are used for similarity assessment between semantic graphs within process-oriented CBR applications. We integrate knowledge in two ways: First, a special data representation and processing method is used that encodes structural knowledge about the semantic annotations of each graph node and edge. Second, the message-passing component of the GNNs is constrained by knowledge on legal node mappings. The evaluation examines the quality and training time of the extended GNNs, compared to the stock models. The results show that both extensions are capable of providing better quality, shorter training times, or in some configurations both advantages at once.
A New Class of Time Dependent Latent Factor Models with Applications
Apr 18, 2019
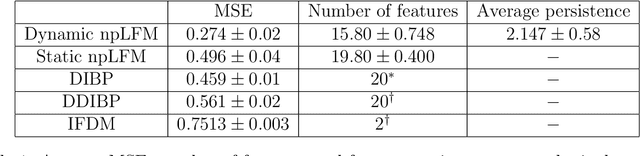
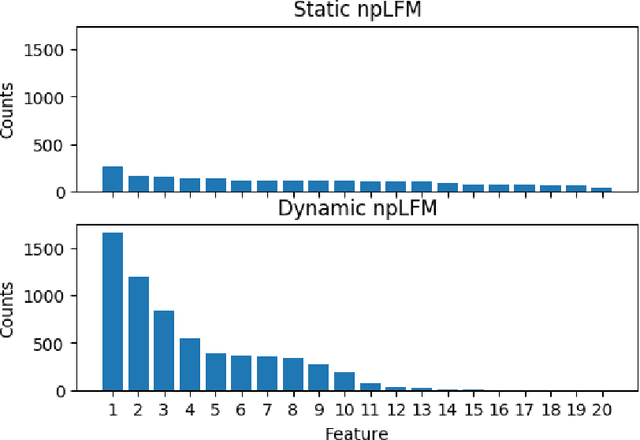

In many applications, observed data are influenced by some combination of latent causes. For example, suppose sensors are placed inside a building to record responses such as temperature, humidity, power consumption and noise levels. These random, observed responses are typically affected by many unobserved, latent factors (or features) within the building such as the number of individuals, the turning on and off of electrical devices, power surges, etc. These latent factors are usually present for a contiguous period of time before disappearing; further, multiple factors could be present at a time. This paper develops new probabilistic methodology and inference methods for random object generation influenced by latent features exhibiting temporal persistence. Every datum is associated with subsets of a potentially infinite number of hidden, persistent features that account for temporal dynamics in an observation. The ensuing class of dynamic models constructed by adapting the Indian Buffet Process --- a probability measure on the space of random, unbounded binary matrices --- finds use in a variety of applications arising in operations, signal processing, biomedicine, marketing, image analysis, etc. Illustrations using synthetic and real data are provided.
ULTRA: An Unbiased Learning To Rank Algorithm Toolbox
Aug 11, 2021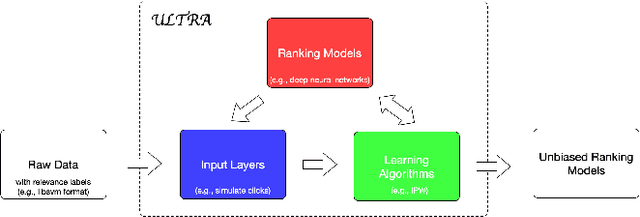
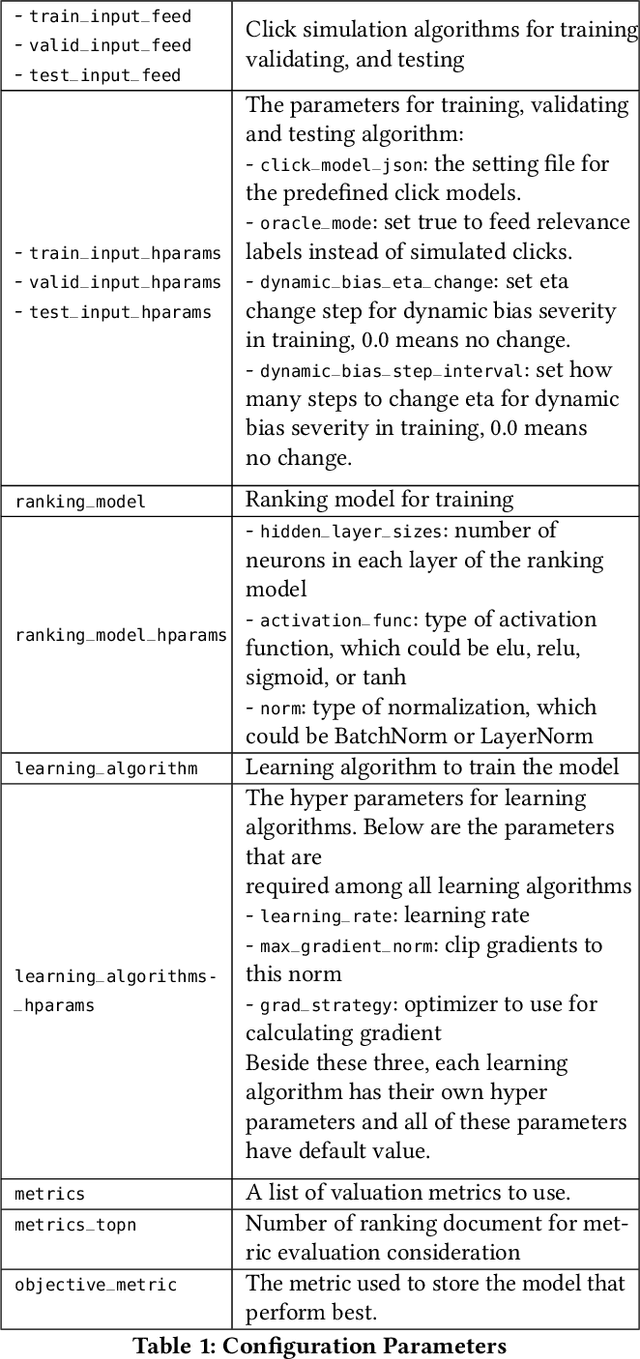
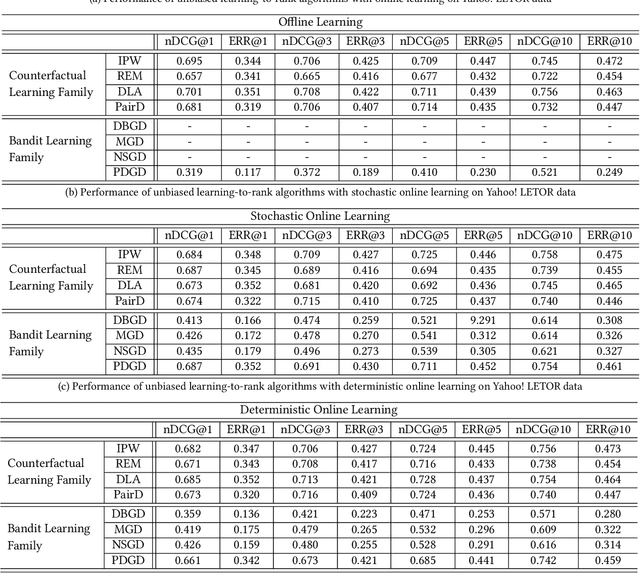
Learning to rank systems has become an important aspect of our daily life. However, the implicit user feedback that is used to train many learning to rank models is usually noisy and suffered from user bias (i.e., position bias). Thus, obtaining an unbiased model using biased feedback has become an important research field for IR. Existing studies on unbiased learning to rank (ULTR) can be generalized into two families-algorithms that attain unbiasedness with logged data, offline learning, and algorithms that achieve unbiasedness by estimating unbiased parameters with real-time user interactions, namely online learning. While there exist many algorithms from both families, there lacks a unified way to compare and benchmark them. As a result, it can be challenging for researchers to choose the right technique for their problems or for people who are new to the field to learn and understand existing algorithms. To solve this problem, we introduced ULTRA, which is a flexible, extensible, and easily configure ULTR toolbox. Its key features include support for multiple ULTR algorithms with configurable hyperparameters, a variety of built-in click models that can be used separately to simulate clicks, different ranking model architecture and evaluation metrics, and simple learning to rank pipeline creation. In this paper, we discuss the general framework of ULTR, briefly describe the algorithms in ULTRA, detailed the structure, and pipeline of the toolbox. We experimented on all the algorithms supported by ultra and showed that the toolbox performance is reasonable. Our toolbox is an important resource for researchers to conduct experiments on ULTR algorithms with different configurations as well as testing their own algorithms with the supported features.
Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 11, 2021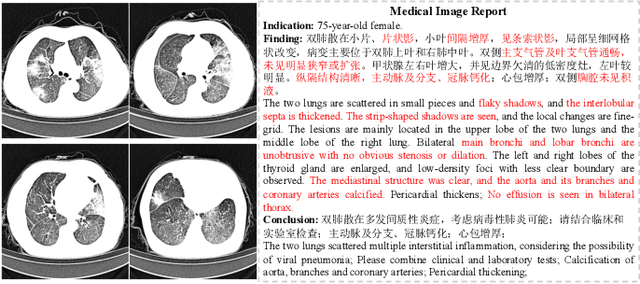
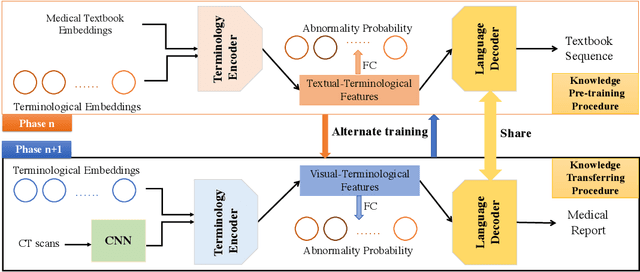
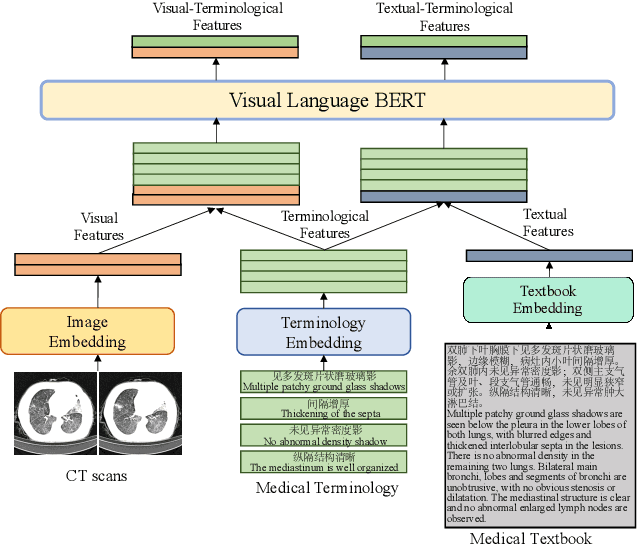
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
SELM: Siamese Extreme Learning Machine with Application to Face Biometrics
Aug 06, 2021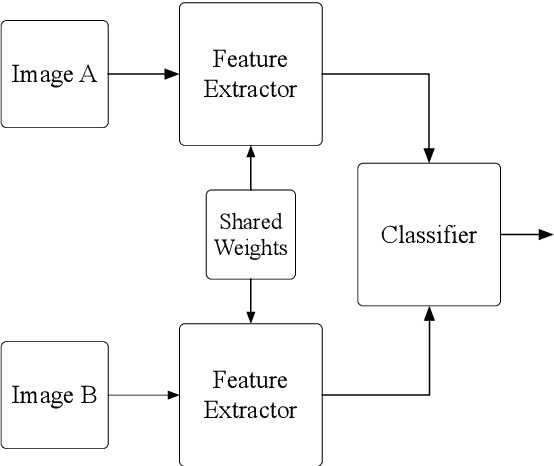
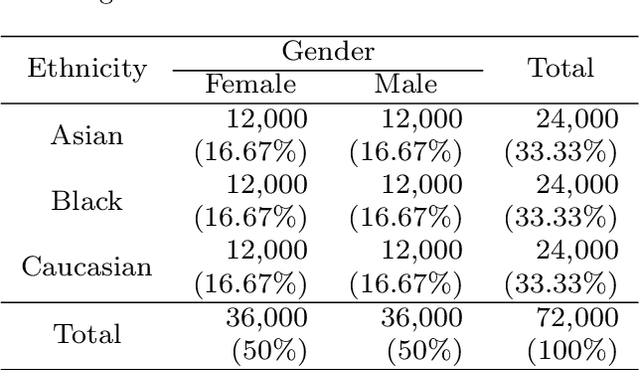
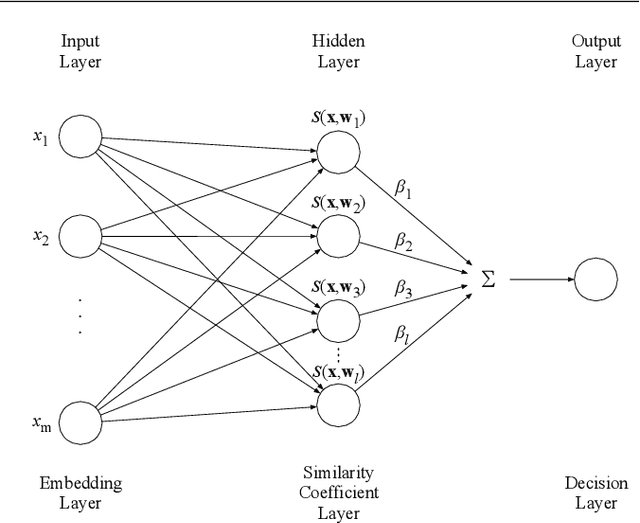
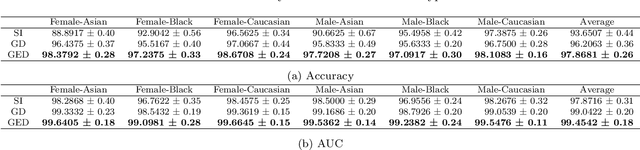
Extreme Learning Machine is a powerful classification method very competitive existing classification methods. It is extremely fast at training. Nevertheless, it cannot perform face verification tasks properly because face verification tasks require comparison of facial images of two individuals at the same time and decide whether the two faces identify the same person. The structure of Extreme Leaning Machine was not designed to feed two input data streams simultaneously, thus, in 2-input scenarios Extreme Learning Machine methods are normally applied using concatenated inputs. However, this setup consumes two times more computational resources and it is not optimized for recognition tasks where learning a separable distance metric is critical. For these reasons, we propose and develop a Siamese Extreme Learning Machine (SELM). SELM was designed to be fed with two data streams in parallel simultaneously. It utilizes a dual-stream Siamese condition in the extra Siamese layer to transform the data before passing it along to the hidden layer. Moreover, we propose a Gender-Ethnicity-Dependent triplet feature exclusively trained on a variety of specific demographic groups. This feature enables learning and extracting of useful facial features of each group. Experiments were conducted to evaluate and compare the performances of SELM, Extreme Learning Machine, and DCNN. The experimental results showed that the proposed feature was able to perform correct classification at 97.87% accuracy and 99.45% AUC. They also showed that using SELM in conjunction with the proposed feature provided 98.31% accuracy and 99.72% AUC. They outperformed the well-known DCNN and Extreme Leaning Machine methods by a wide margin.
Deep Memory Update
Jun 17, 2021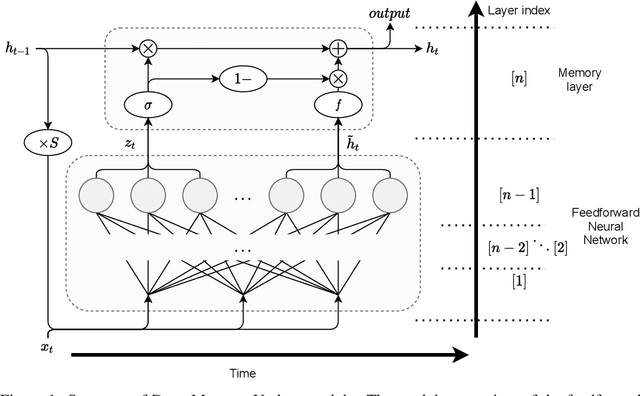
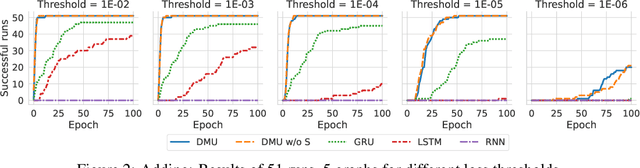
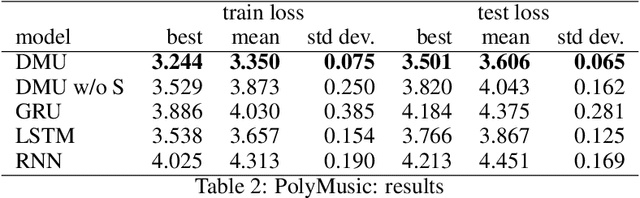
Recurrent neural networks are key tools for sequential data processing. Existing architectures support only a limited class of operations that these networks can apply to their memory state. In this paper, we address this issue and introduce a recurrent neural module called Deep Memory Update (DMU). This module is an alternative to well-established LSTM and GRU. However, it uses a universal function approximator to process its lagged memory state. In addition, the module normalizes the lagged memory to avoid gradient exploding or vanishing in backpropagation through time. The subnetwork that transforms the memory state of DMU can be arbitrary. Experimental results presented here confirm that the previously mentioned properties of the network allow it to compete with and often outperform state-of-the-art architectures such as LSTM and GRU.
Distribution-dependent and Time-uniform Bounds for Piecewise i.i.d Bandits
Jun 07, 2019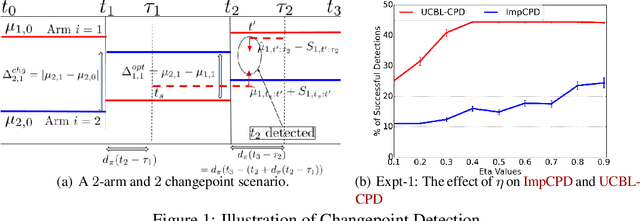

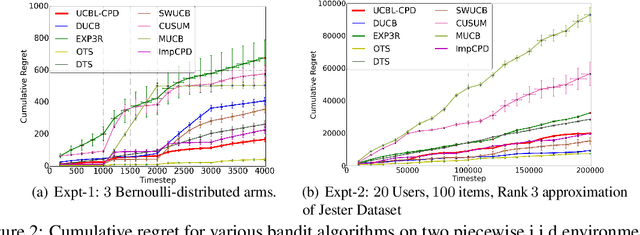
We consider the setup of stochastic multi-armed bandits in the case when reward distributions are piecewise i.i.d. and bounded with unknown changepoints. We focus on the case when changes happen simultaneously on all arms, and in stark contrast with the existing literature, we target gap-dependent (as opposed to only gap-independent) regret bounds involving the magnitude of changes $(\Delta^{chg}_{i,g})$ and optimality-gaps ($\Delta^{opt}_{i,g}$). Diverging from previous works, we assume the more realistic scenario that there can be undetectable changepoint gaps and under a different set of assumptions, we show that as long as the compounded delayed detection for each changepoint is bounded there is no need for forced exploration to actively detect changepoints. We introduce two adaptations of UCB-strategies that employ scan-statistics in order to actively detect the changepoints, without knowing in advance the changepoints and also the mean before and after any change. Our first method \UCBLCPD does not know the number of changepoints $G$ or time horizon $T$ and achieves the first time-uniform concentration bound for this setting using the Laplace method of integration. The second strategy \ImpCPD makes use of the knowledge of $T$ to achieve the order optimal regret bound of $\min\big\lbrace O(\sum\limits_{i=1}^{K} \sum\limits_{g=1}^{G}\frac{\log(T/H_{1,g})}{\Delta^{opt}_{i,g}}), O(\sqrt{GT})\big\rbrace$, (where $H_{1,g}$ is the problem complexity) thereby closing an important gap with respect to the lower bound in a specific challenging setting. Our theoretical findings are supported by numerical experiments on synthetic and real-life datasets.
* Proceedings of the Reinforcement Learning for Real Life (RL4RealLife) Workshop in the 36th International Conference on Machine Learning, Long Beach, California, USA, 2019
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021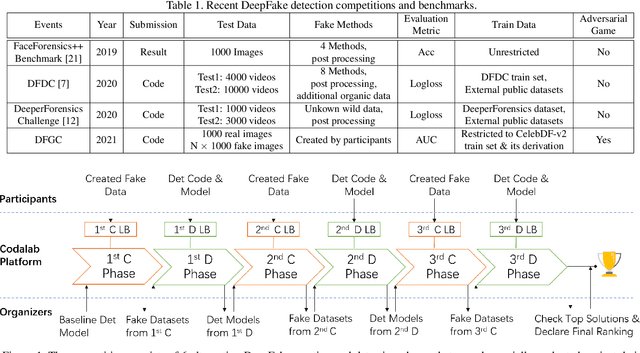
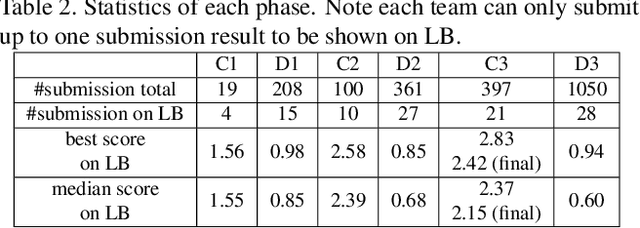
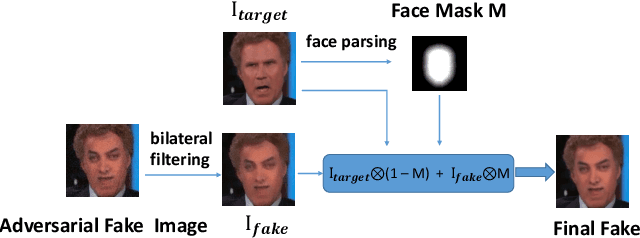
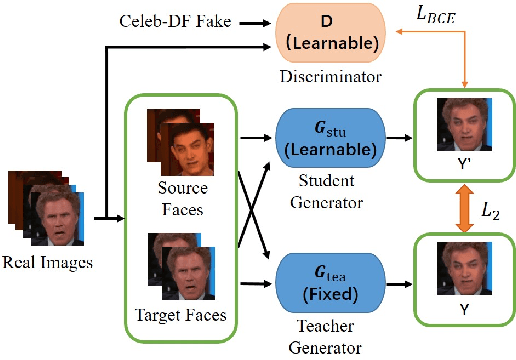
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.