 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HYPER-SNN: Towards Energy-efficient Quantized Deep Spiking Neural Networks for Hyperspectral Image Classification
Jul 28, 2021
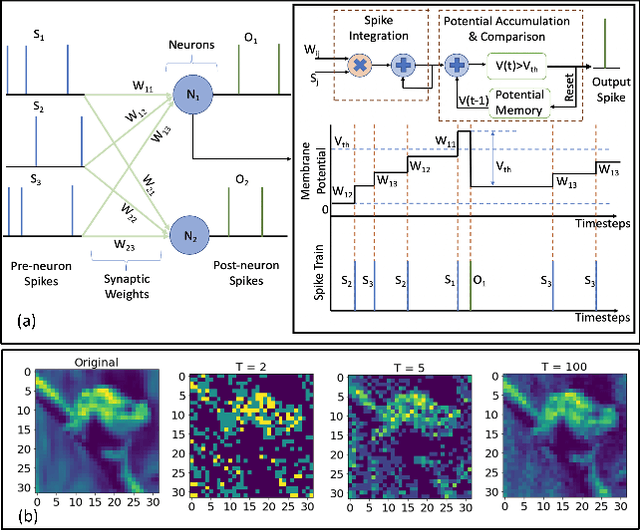
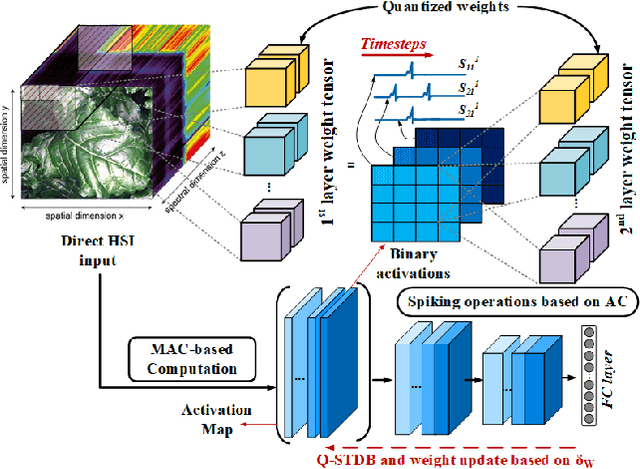
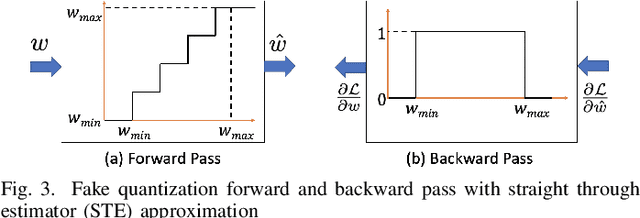
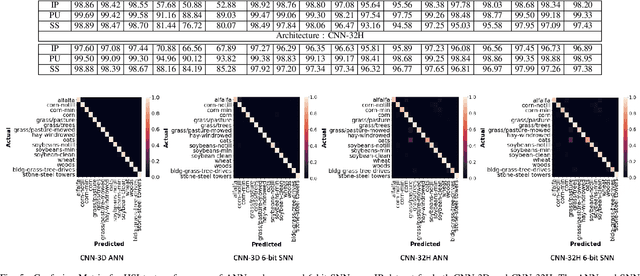
Hyper spectral images (HSI) provide rich spectral and spatial information across a series of contiguous spectral bands. However, the accurate processing of the spectral and spatial correlation between the bands requires the use of energy-expensive 3-D Convolutional Neural Networks (CNNs). To address this challenge, we propose the use of Spiking Neural Networks (SNNs) that are generated from iso-architecture CNNs and trained with quantization-aware gradient descent to optimize their weights, membrane leak, and firing thresholds. During both training and inference, the analog pixel values of a HSI are directly applied to the input layer of the SNN without the need to convert to a spike-train. The reduced latency of our training technique combined with high activation sparsity yields significant improvements in computational efficiency. We evaluate our proposal using three HSI datasets on a 3-D and a 3-D/2-D hybrid convolutional architecture. We achieve overall accuracy, average accuracy, and kappa coefficient of 98.68%, 98.34%, and 98.20% respectively with 5 time steps (inference latency) and 6-bit weight quantization on the Indian Pines dataset. In particular, our models achieved accuracies similar to state-of-the-art (SOTA) with 560.6 and 44.8 times less compute energy on average over three HSI datasets than an iso-architecture full-precision and 6-bit quantized CNN, respectively.
Neuromechanical model-based control of bi-lateral ankle exoskeletons: biological joint torque and electromyogram reduction across walking conditions
Aug 02, 2021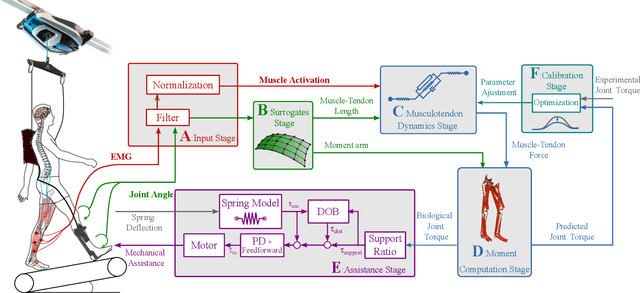
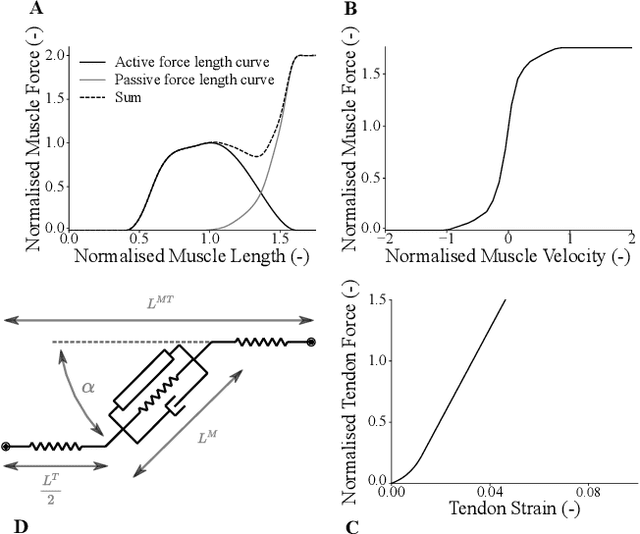
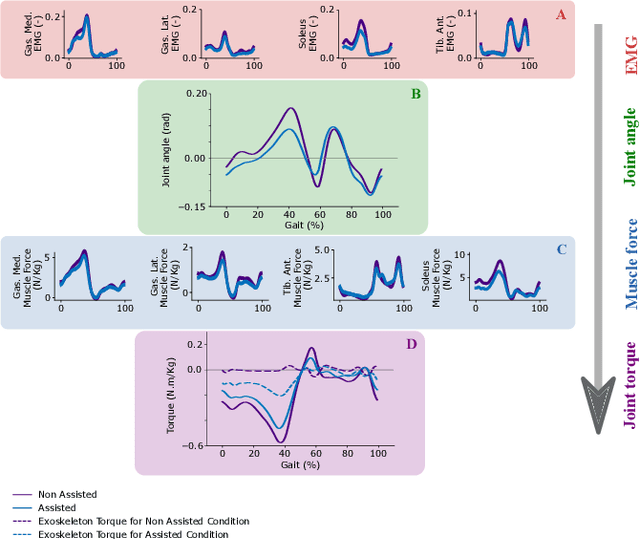
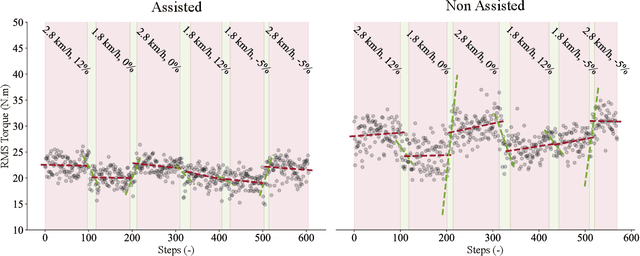
To enable the broad adoption of wearable robotic exoskeletons in medical and industrial settings, it is crucial they can effectively support large repertoires of movements. We propose a new human-machine interface to drive bilateral ankle exoskeletons during a range of 'unseen' walking conditions that were not used for establishing the control interface. The proposed approach uses person-specific neuromechanical models of the human body to estimate biological ankle torques in real-time from electromyograms (EMGS) and joint angles. A low-level controller based on a disturbance observer translates biological torque estimates into exoskeleton commands. We call this 'neuromechanical model-based control' (NMBC). NMBC enabled five individuals to voluntarily control exoskeletons across two walking speeds performed at three ground elevations with no need for predefined torque profiles, nor a prior chosen neuromuscular reflex rules, or state machines as common in literature. Furthermore, a single subject case study was carried out on a dexterous moonwalk task, showing reduction in muscular effort. NMBC enabled reducing biological ankle torques as well as eight ankle muscle EMGs both within (22% for the torque; 13% for the EMG) and between walking conditions (22% for the torque; 13% for the EMG) when compared to non-assisted conditions. Torque and EMG reduction in novel walking conditions indicated the exoskeleton operated symbiotically as an exomuscle controlled by the operator's neuromuscular system. This will open new avenues for systematic adoption of wearable robots in out-of-the-lab medical and occupational settings.
PDL Impact on Linearly Coded Digital Phase Conjugation Techniques in CO-OFDM Systems
Jun 27, 2021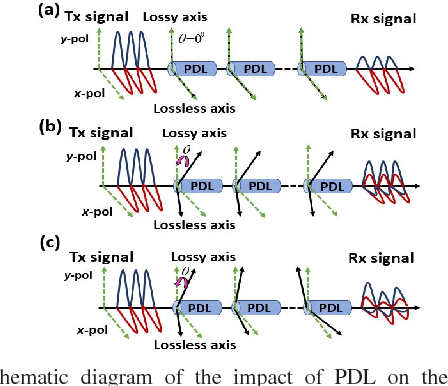
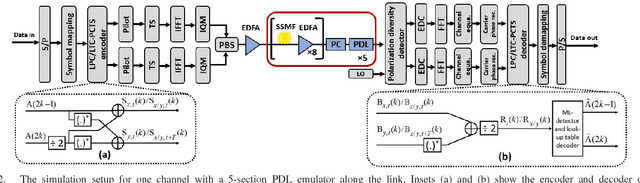
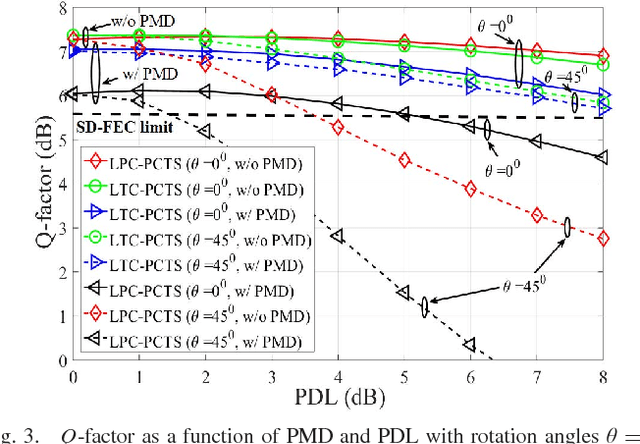
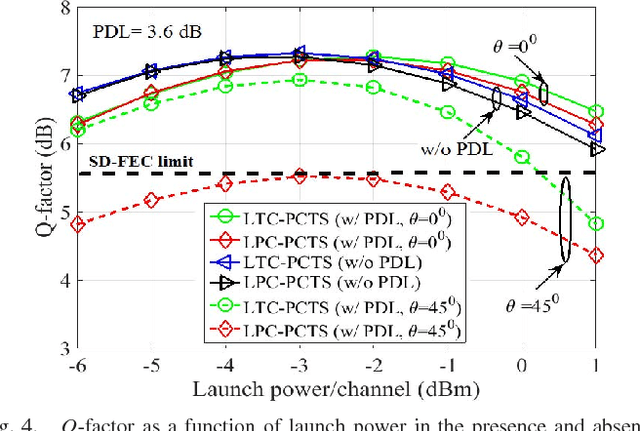
We investigate the impact of polarization-dependent loss (PDL) on the linearly coded digital phase conjugation (DPC) techniques in coherent optical orthogonal frequency division multiplexing (CO-OFDM) superchannel systems. We consider two DPC approaches: one uses orthogonal polarizations to transmit the linearly coded signal and its phase conjugate, while the other uses two orthogonal time slots of the same polarization. We compare the performances of these DPC approaches by considering both aligned- and statistical-PDL models. The investigation with aligned-PDL model indicates that the latter approach is more tolerant to PDL-induced distortions when compared to the former. Furthermore, the study using statistical-PDL model shows that the outage probability of the latter approach tends to zero at a root mean square PDL value of 3.6 dB. On the other hand, the former shows an outage probability of 0.63 for the same PDL value.
Aerial Vehicles Tracking Using Noncoherent Crowdsourced Wireless Networks
Aug 02, 2021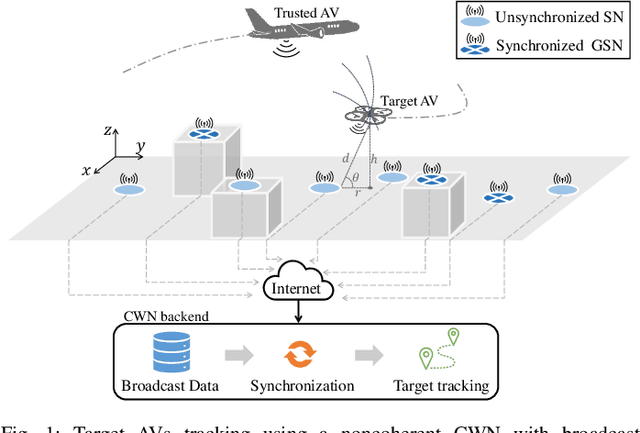
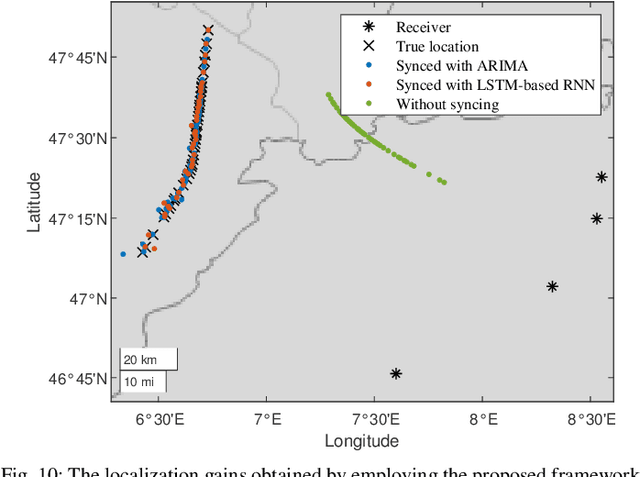
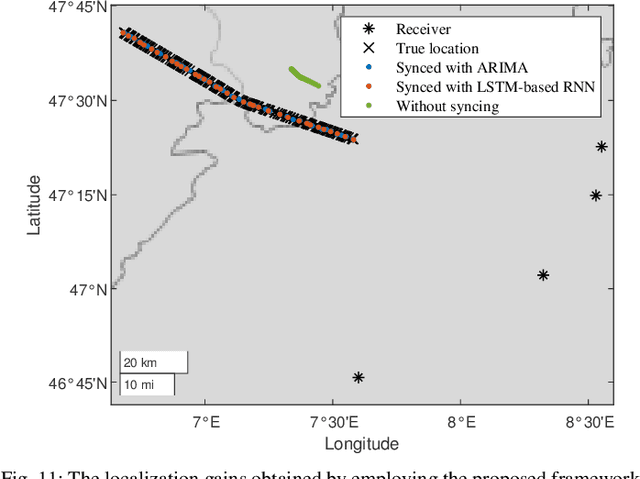
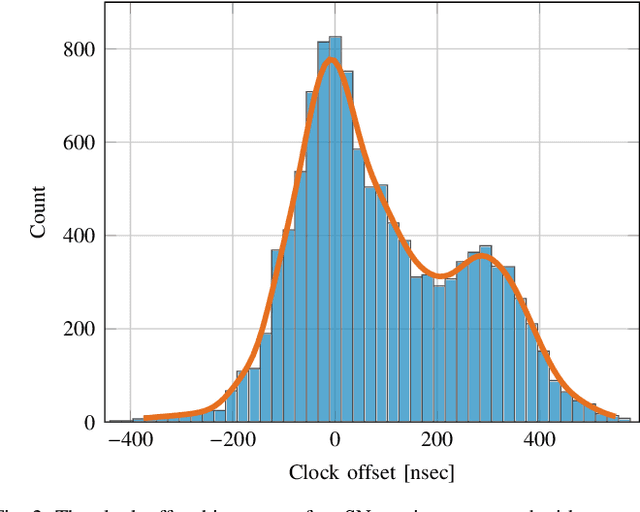
Air traffic management (ATM) of manned and unmanned aerial vehicles (AVs) relies critically on ubiquitous location tracking. While technologies exist for AVs to broadcast their location periodically and for airports to track and detect AVs, methods to verify the broadcast locations and complement the ATM coverage are urgently needed, addressing anti-spoofing and safe coexistence concerns. In this work, we propose an ATM solution by exploiting noncoherent crowdsourced wireless networks (CWNs) and correcting the inherent clock-synchronization problems present in such non-coordinated sensor networks. While CWNs can provide a great number of measurements for ubiquitous ATM, these are normally obtained from unsynchronized sensors. This article first presents an analysis of the effects of lack of clock synchronization in ATM with CWN and provides solutions based on the presence of few trustworthy sensors in a large non-coordinated network. Secondly, autoregressive-based and long short-term memory (LSTM)-based approaches are investigated to achieve the time synchronization needed for localization of the AVs. Finally, a combination of a multilateration (MLAT) method and a Kalman filter is employed to provide an anti-spoofing tracking solution for AVs. We demonstrate the performance advantages of our framework through a dataset collected by a real-world CWN. Our results show that the proposed framework achieves localization accuracy comparable to that acquired using only GPS-synchronized sensors and outperforms the localization accuracy obtained based on state-of-the-art CWN synchronization methods.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021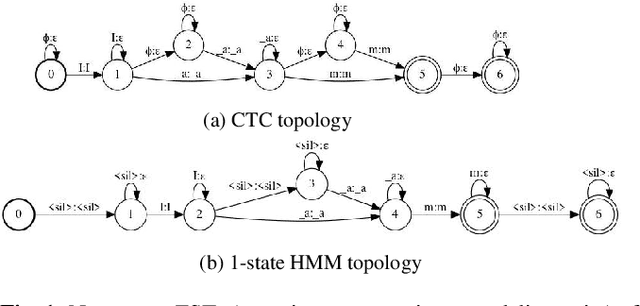
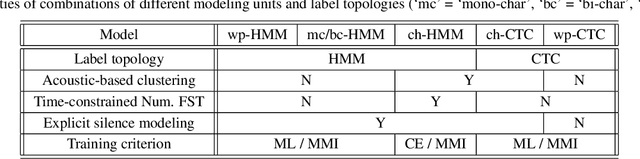
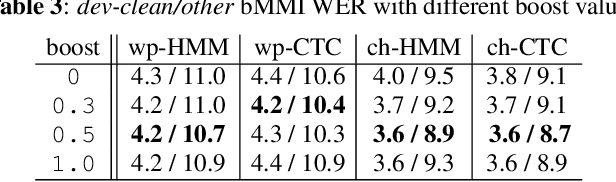
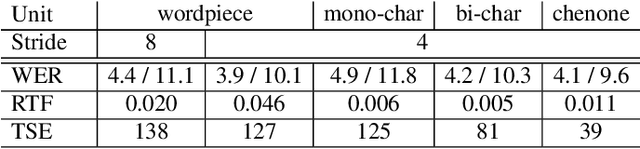
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
PoliTO-IIT Submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition
Jul 01, 2021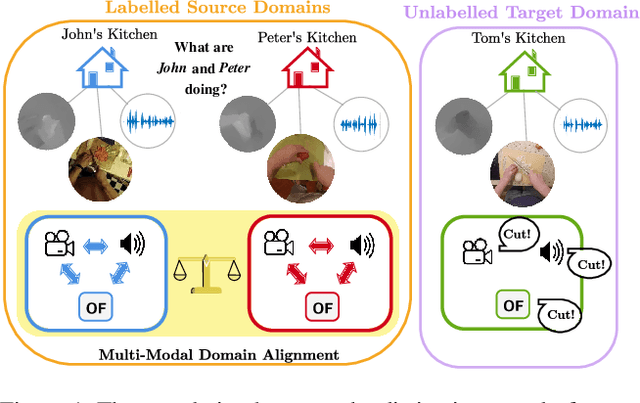


In this report, we describe the technical details of our submission to the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. To tackle the domain-shift which exists under the UDA setting, we first exploited a recent Domain Generalization (DG) technique, called Relative Norm Alignment (RNA). It consists in designing a model able to generalize well to any unseen domain, regardless of the possibility to access target data at training time. Then, in a second phase, we extended the approach to work on unlabelled target data, allowing the model to adapt to the target distribution in an unsupervised fashion. For this purpose, we included in our framework existing UDA algorithms, such as Temporal Attentive Adversarial Adaptation Network (TA3N), jointly with new multi-stream consistency losses, namely Temporal Hard Norm Alignment (T-HNA) and Min-Entropy Consistency (MEC). Our submission (entry 'plnet') is visible on the leaderboard and it achieved the 1st position for 'verb', and the 3rd position for both 'noun' and 'action'.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021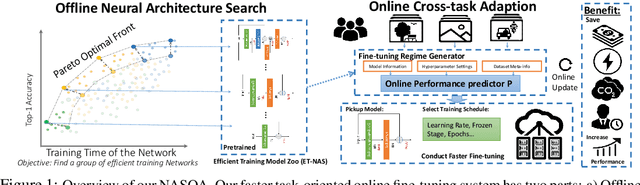

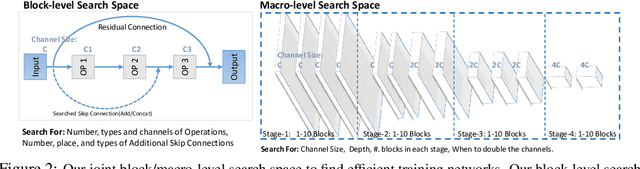
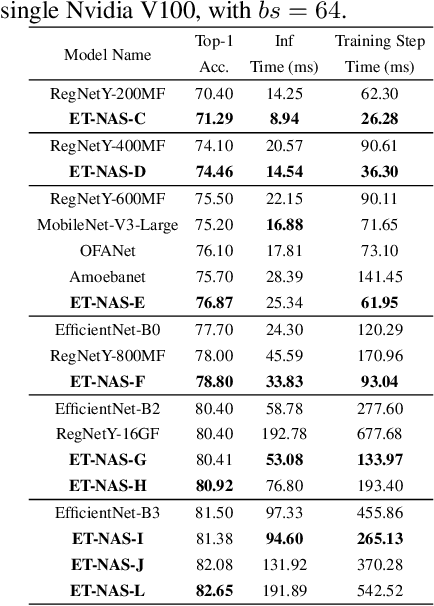
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
Leveraging Language to Learn Program Abstractions and Search Heuristics
Jun 18, 2021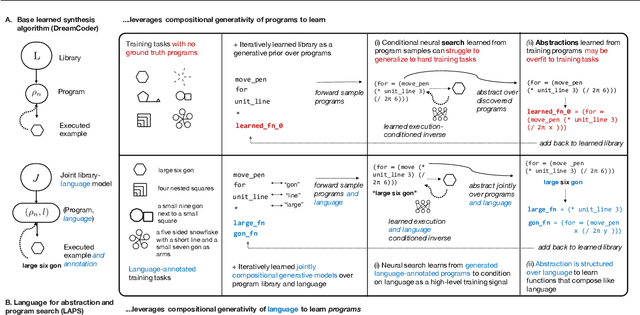
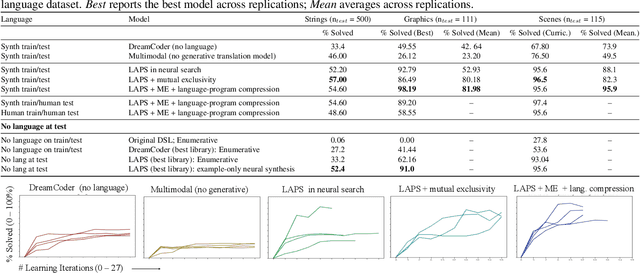


Inductive program synthesis, or inferring programs from examples of desired behavior, offers a general paradigm for building interpretable, robust, and generalizable machine learning systems. Effective program synthesis depends on two key ingredients: a strong library of functions from which to build programs, and an efficient search strategy for finding programs that solve a given task. We introduce LAPS (Language for Abstraction and Program Search), a technique for using natural language annotations to guide joint learning of libraries and neurally-guided search models for synthesis. When integrated into a state-of-the-art library learning system (DreamCoder), LAPS produces higher-quality libraries and improves search efficiency and generalization on three domains -- string editing, image composition, and abstract reasoning about scenes -- even when no natural language hints are available at test time.
CausCF: Causal Collaborative Filtering for RecommendationEffect Estimation
May 28, 2021
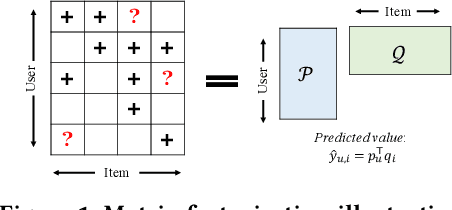
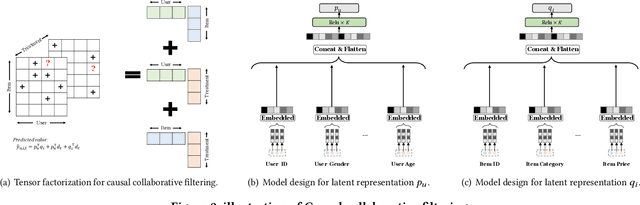
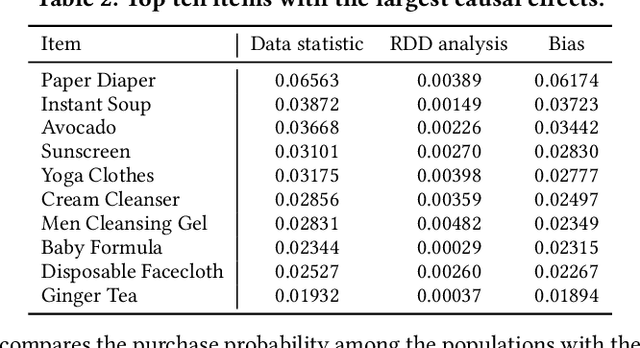
To improve user experience and profits of corporations, modern industrial recommender systems usually aim to select the items that are most likely to be interacted with (e.g., clicks and purchases). However, they overlook the fact that users may purchase the items even without recommendations. To select these effective items, it is essential to estimate the causal effect of recommendations. The real effective items are the ones which can contribute to purchase probability uplift. Nevertheless, it is difficult to obtain the real causal effect since we can only recommend or not recommend an item to a user at one time. Furthermore, previous works usually rely on the randomized controlled trial~(RCT) experiment to evaluate their performance. However, it is usually not practicable in the recommendation scenario due to its unavailable time consuming. To tackle these problems, in this paper, we propose a causal collaborative filtering~(CausCF) method inspired by the widely adopted collaborative filtering~(CF) technique. It is based on the idea that similar users not only have a similar taste on items, but also have similar treatment effect under recommendations. CausCF extends the classical matrix factorization to the tensor factorization with three dimensions -- user, item, and treatment. Furthermore, we also employs regression discontinuity design (RDD) to evaluate the precision of the estimated causal effects from different models. With the testable assumptions, RDD analysis can provide an unbiased causal conclusion without RCT experiments. Through dedicated experiments on both the public datasets and the industrial application, we demonstrate the effectiveness of our proposed CausCF on the causal effect estimation and ranking performance improvement.
Vision Transformers for femur fracture classification
Aug 07, 2021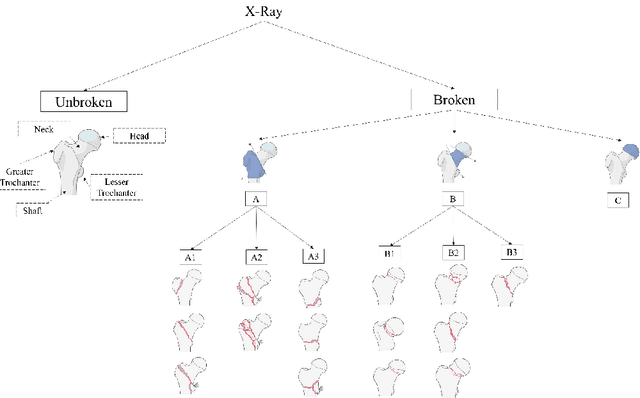

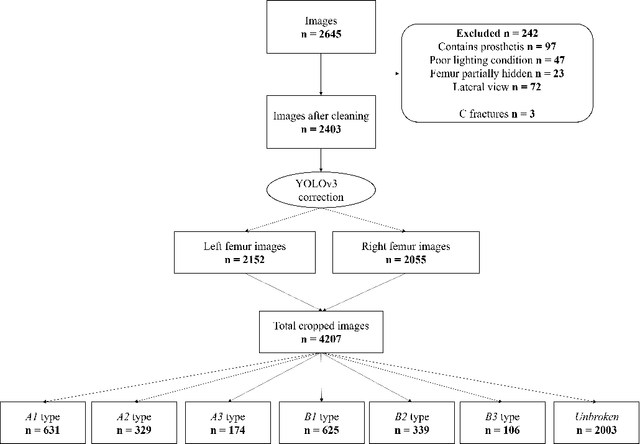
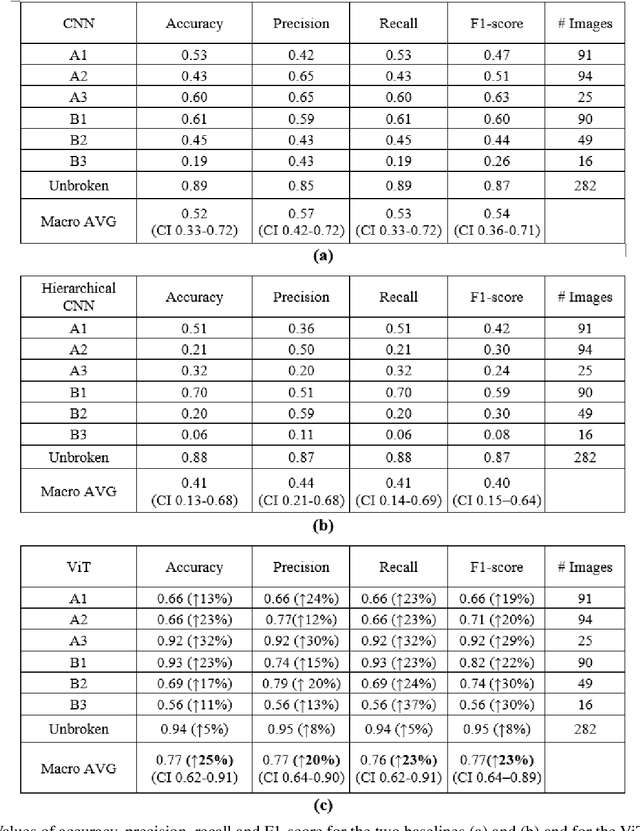
Objectives: In recent years, the scientific community has focused on the development of Computer-Aided Diagnosis (CAD) tools that could improve bone fractures' classification. However, the results of the classification of fractures in subtypes with the proposed datasets were far from optimal. This paper proposes a very recent and outperforming deep learning technique, the Vision Transformer (ViT), in order to improve the fracture classification, by exploiting its self-attention mechanism. Methods: 4207 manually annotated images were used and distributed, by following the AO/OTA classification, in different fracture types, the largest labeled dataset of proximal femur fractures used in literature. The ViT architecture was used and compared with a classic Convolutional Neural Network (CNN) and a multistage architecture composed by successive CNNs in cascade. To demonstrate the reliability of this approach, 1) the attention maps were used to visualize the most relevant areas of the images, 2) the performance of a generic CNN and ViT was also compared through unsupervised learning techniques, and 3) 11 specialists were asked to evaluate and classify 150 proximal femur fractures' images with and without the help of the ViT. Results: The ViT was able to correctly predict 83% of the test images. Precision, recall and F1-score were 0.77 (CI 0.64-0.90), 0.76 (CI 0.62-0.91) and 0.77 (CI 0.64-0.89), respectively. The average specialists' diagnostic improvement was 29%. Conclusions: This paper showed the potential of Transformers in bone fracture classification. For the first time, good results were obtained in sub-fractures with the largest and richest dataset ever.