 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using a New Nonlinear Gradient Method for Solving Large Scale Convex Optimization Problems with an Application on Arabic Medical Text
Jun 09, 2021
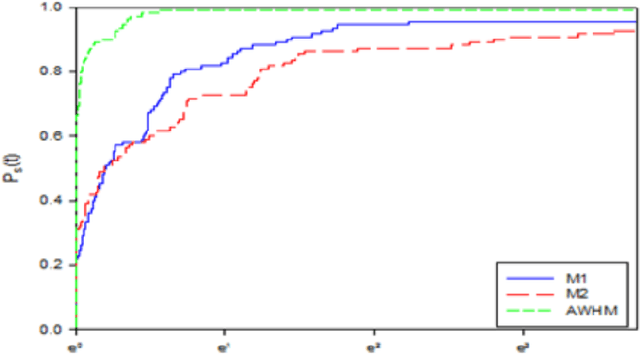

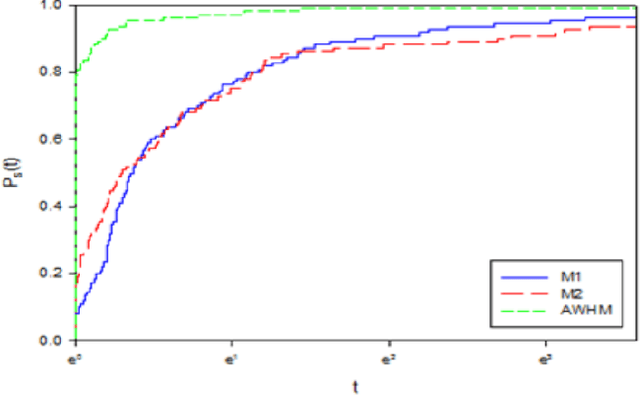

Gradient methods have applications in multiple fields, including signal processing, image processing, and dynamic systems. In this paper, we present a nonlinear gradient method for solving convex supra-quadratic functions by developing the search direction, that done by hybridizing between the two conjugate coefficients HRM [2] and NHS [1]. The numerical results proved the effectiveness of the presented method by applying it to solve standard problems and reaching the exact solution if the objective function is quadratic convex. Also presented in this article, an application to the problem of named entities in the Arabic medical language, as it proved the stability of the proposed method and its efficiency in terms of execution time.
A Meta-Learning Control Algorithm with Provable Finite-Time Guarantees
Sep 10, 2020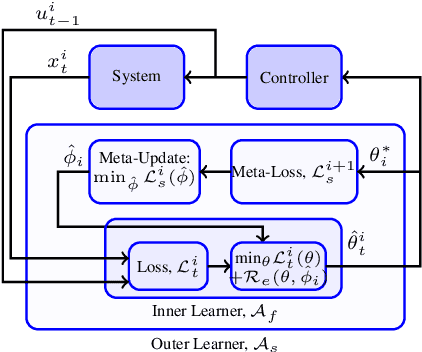
In this work we provide provable regret guarantees for an online meta-learning control algorithm in an iterative control setting, where in each iteration the system to be controlled is a linear deterministic system that is different and unknown, the cost for the controller in an iteration is a general additive cost function and the control input is required to be constrained, which if violated incurs an additional cost. We prove (i) that the algorithm achieves a regret for the controller cost and constraint violation that are $O(T^{3/4})$ for an episode of duration $T$ with respect to the best policy that satisfies the control input control constraints and (ii) that the average of the regret for the controller cost and constraint violation with respect to the same policy vary as $O((1+\log(N)/N)T^{3/4})$ with the number of iterations $N$, showing that the worst regret for the learning within an iteration continuously improves with experience of more iterations.
Predictive and Prescriptive Performance of Bike-Sharing Demand Forecasts for Inventory Management
Jul 28, 2021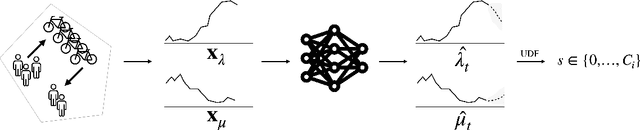
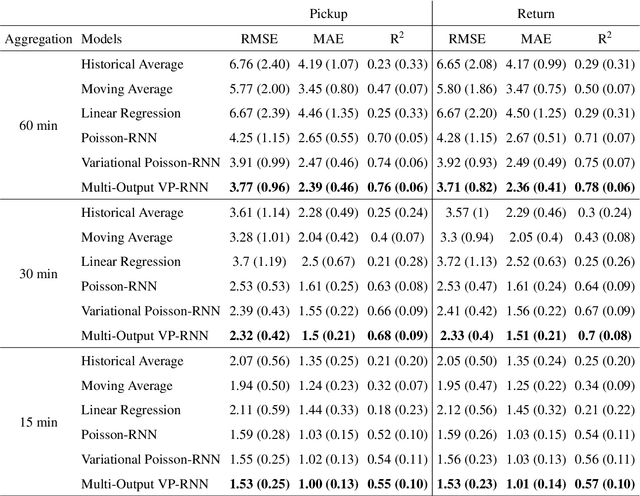
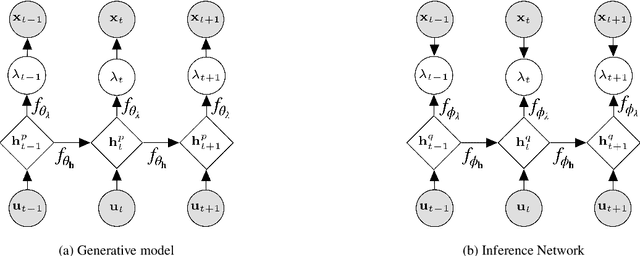

Bike-sharing systems are a rapidly developing mode of transportation and provide an efficient alternative to passive, motorized personal mobility. The asymmetric nature of bike demand causes the need for rebalancing bike stations, which is typically done during night time. To determine the optimal starting inventory level of a station for a given day, a User Dissatisfaction Function (UDF) models user pickups and returns as non-homogeneous Poisson processes with piece-wise linear rates. In this paper, we devise a deep generative model directly applicable in the UDF by introducing a variational Poisson recurrent neural network model (VP-RNN) to forecast future pickup and return rates. We empirically evaluate our approach against both traditional and learning-based forecasting methods on real trip travel data from the city of New York, USA, and show how our model outperforms benchmarks in terms of system efficiency and demand satisfaction. By explicitly focusing on the combination of decision-making algorithms with learning-based forecasting methods, we highlight a number of shortcomings in literature. Crucially, we show how more accurate predictions do not necessarily translate into better inventory decisions. By providing insights into the interplay between forecasts, model assumptions, and decisions, we point out that forecasts and decision models should be carefully evaluated and harmonized to optimally control shared mobility systems.
Exploiting temporal consistency for real-time video depth estimation
Aug 10, 2019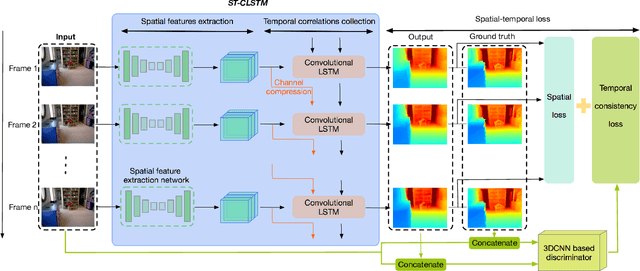
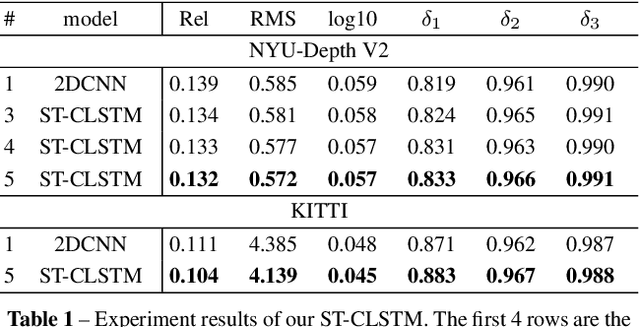
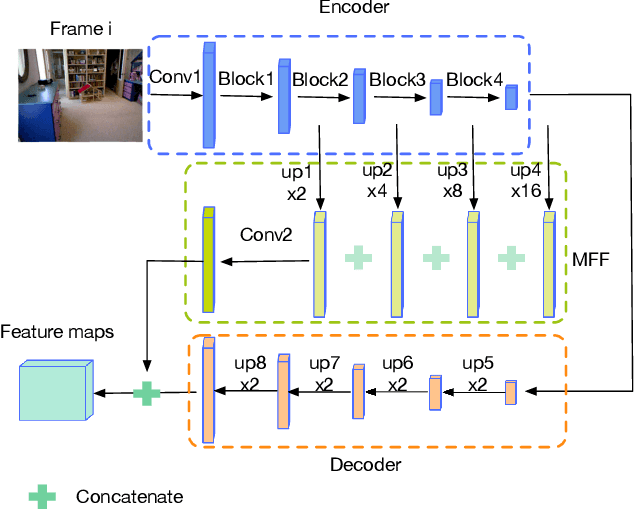
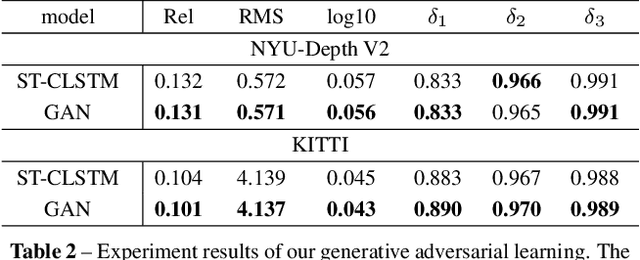
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM
A Physiologically-Adapted Gold Standard for Arousal during Stress
Jul 28, 2021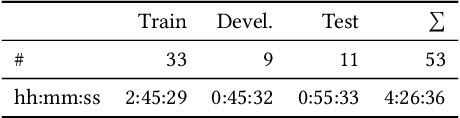
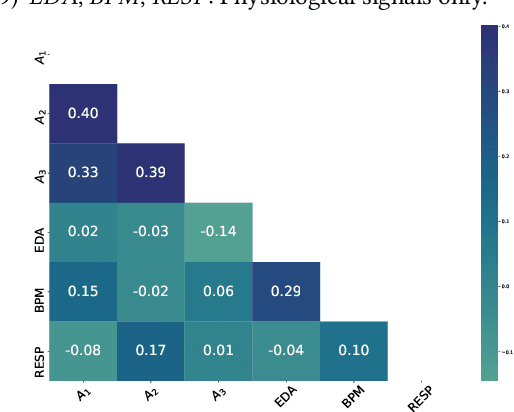
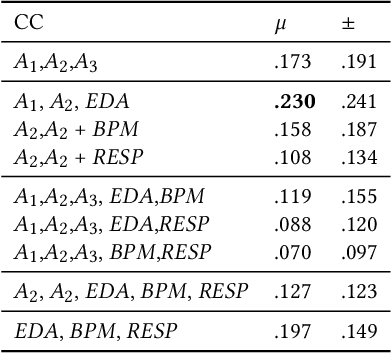
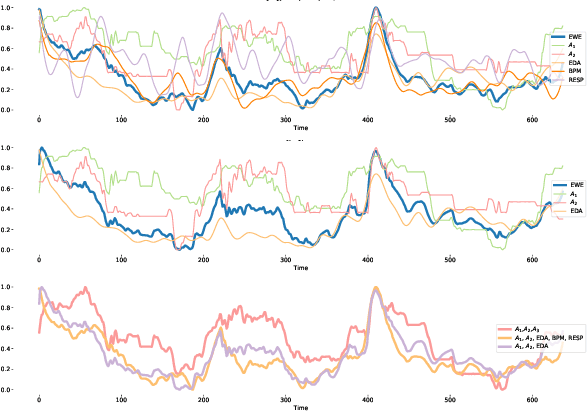
Emotion is an inherently subjective psychophysiological human-state and to produce an agreed-upon representation (gold standard) for continuous emotion requires a time-consuming and costly training procedure of multiple human annotators. There is strong evidence in the literature that physiological signals are sufficient objective markers for states of emotion, particularly arousal. In this contribution, we utilise a dataset which includes continuous emotion and physiological signals - Heartbeats per Minute (BPM), Electrodermal Activity (EDA), and Respiration-rate - captured during a stress inducing scenario (Trier Social Stress Test). We utilise a Long Short-Term Memory, Recurrent Neural Network to explore the benefit of fusing these physiological signals with arousal as the target, learning from various audio, video, and textual based features. We utilise the state-of-the-art MuSe-Toolbox to consider both annotation delay and inter-rater agreement weighting when fusing the target signals. An improvement in Concordance Correlation Coefficient (CCC) is seen across features sets when fusing EDA with arousal, compared to the arousal only gold standard results. Additionally, BERT-based textual features' results improved for arousal plus all physiological signals, obtaining up to .3344 CCC compared to .2118 CCC for arousal only. Multimodal fusion also improves overall CCC with audio plus video features obtaining up to .6157 CCC to recognize arousal plus EDA and BPM.
Rank-based verification for long-term face tracking in crowded scenes
Jul 28, 2021
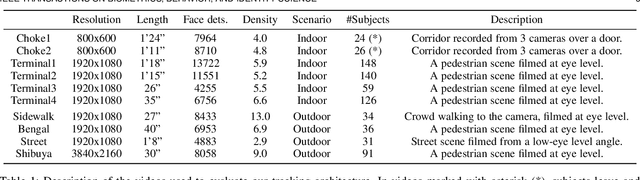
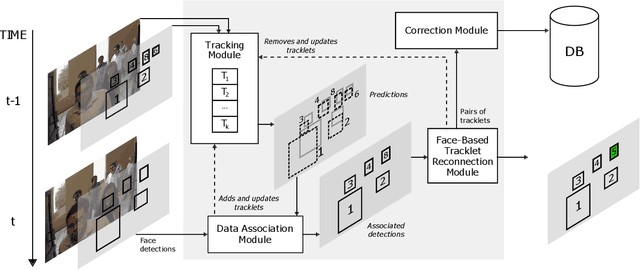
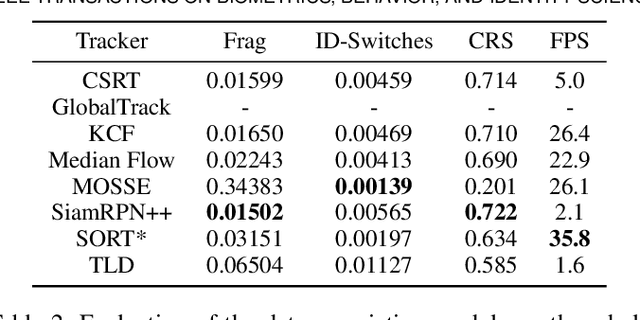
Most current multi-object trackers focus on short-term tracking, and are based on deep and complex systems that often cannot operate in real-time, making them impractical for video-surveillance. In this paper we present a long-term, multi-face tracking architecture conceived for working in crowded contexts where faces are often the only visible part of a person. Our system benefits from advances in the fields of face detection and face recognition to achieve long-term tracking, and is particularly unconstrained to the motion and occlusions of people. It follows a tracking-by-detection approach, combining a fast short-term visual tracker with a novel online tracklet reconnection strategy grounded on rank-based face verification. The proposed rank-based constraint favours higher inter-class distance among tracklets, and reduces the propagation of errors due to wrong reconnections. Additionally, a correction module is included to correct past assignments with no extra computational cost. We present a series of experiments introducing novel specialized metrics for the evaluation of long-term tracking capabilities, and publicly release a video dataset with 10 manually annotated videos and a total length of 8' 54". Our findings validate the robustness of each of the proposed modules, and demonstrate that, in these challenging contexts, our approach yields up to 50% longer tracks than state-of-the-art deep learning trackers.
* arXiv admin note: substantial text overlap with arXiv:2010.08675
Spatial Uncertainty-Aware Semi-Supervised Crowd Counting
Jul 28, 2021
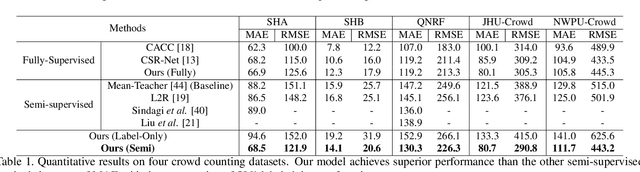
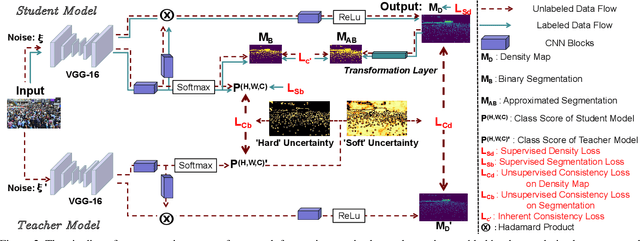
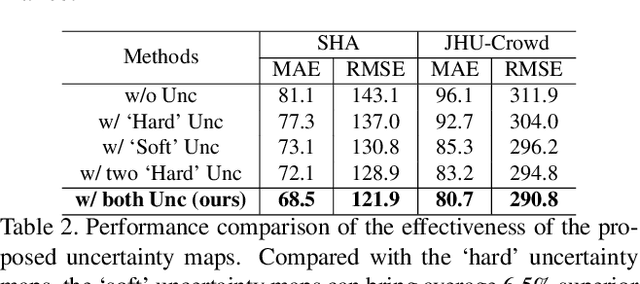
Semi-supervised approaches for crowd counting attract attention, as the fully supervised paradigm is expensive and laborious due to its request for a large number of images of dense crowd scenarios and their annotations. This paper proposes a spatial uncertainty-aware semi-supervised approach via regularized surrogate task (binary segmentation) for crowd counting problems. Different from existing semi-supervised learning-based crowd counting methods, to exploit the unlabeled data, our proposed spatial uncertainty-aware teacher-student framework focuses on high confident regions' information while addressing the noisy supervision from the unlabeled data in an end-to-end manner. Specifically, we estimate the spatial uncertainty maps from the teacher model's surrogate task to guide the feature learning of the main task (density regression) and the surrogate task of the student model at the same time. Besides, we introduce a simple yet effective differential transformation layer to enforce the inherent spatial consistency regularization between the main task and the surrogate task in the student model, which helps the surrogate task to yield more reliable predictions and generates high-quality uncertainty maps. Thus, our model can also address the task-level perturbation problems that occur spatial inconsistency between the primary and surrogate tasks in the student model. Experimental results on four challenging crowd counting datasets demonstrate that our method achieves superior performance to the state-of-the-art semi-supervised methods.
Real Time System for Facial Analysis
Sep 14, 2018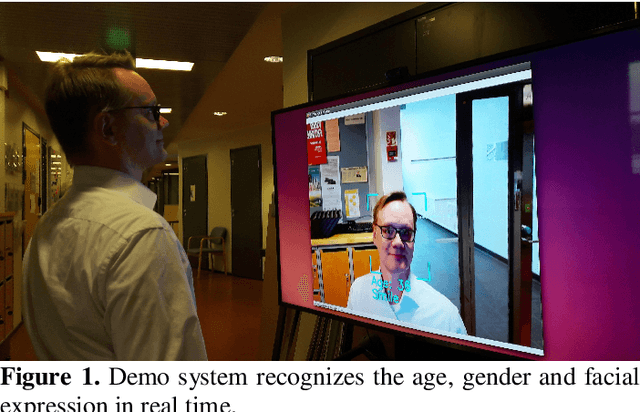
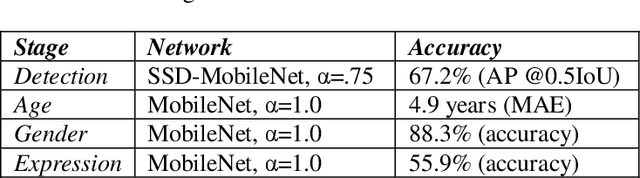
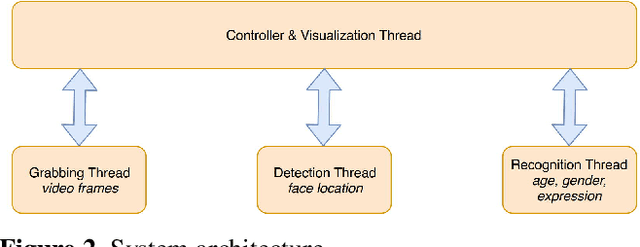
In this paper we describe the anatomy of a real-time facial analysis system. The system recognizes the age, gender and facial expression from users in appearing in front of the camera. All components are based on convolutional neural networks, whose accuracy we study on commonly used training and evaluation sets. A key contribution of the work is the description of the interplay between processing threads for frame grabbing, face detection and the three types of recognition. The python code for executing the system uses common libraries--keras/tensorflow, opencv and dlib--and is available for download.
SCSS-Net: Superpoint Constrained Semi-supervised Segmentation Network for 3D Indoor Scenes
Jul 09, 2021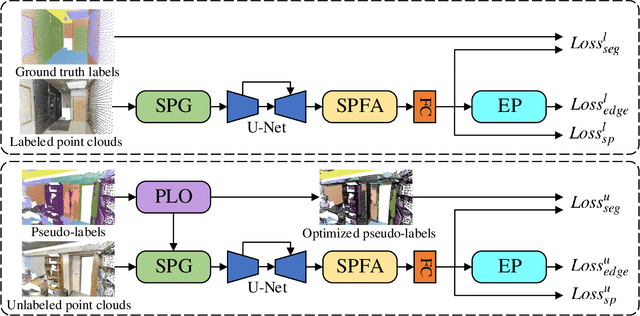

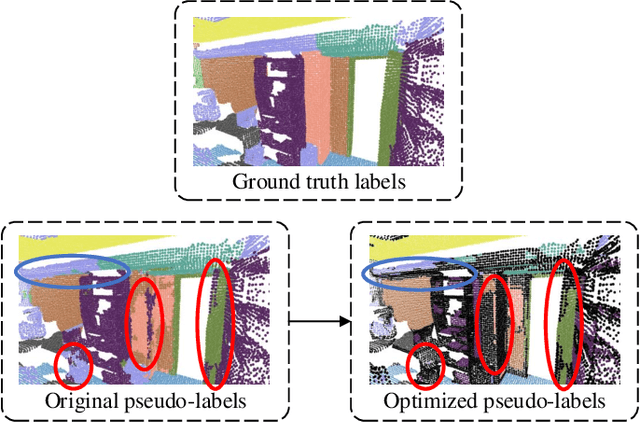

Many existing deep neural networks (DNNs) for 3D point cloud semantic segmentation require a large amount of fully labeled training data. However, manually assigning point-level labels on the complex scenes is time-consuming. While unlabeled point clouds can be easily obtained from sensors or reconstruction, we propose a superpoint constrained semi-supervised segmentation network for 3D point clouds, named as SCSS-Net. Specifically, we use the pseudo labels predicted from unlabeled point clouds for self-training, and the superpoints produced by geometry-based and color-based Region Growing algorithms are combined to modify and delete pseudo labels with low confidence. Additionally, we propose an edge prediction module to constrain the features from edge points of geometry and color. A superpoint feature aggregation module and superpoint feature consistency loss functions are introduced to smooth the point features in each superpoint. Extensive experimental results on two 3D public indoor datasets demonstrate that our method can achieve better performance than some state-of-the-art point cloud segmentation networks and some popular semi-supervised segmentation methods with few labeled scenes.
Goal-Conditioned Reinforcement Learning with Imagined Subgoals
Jul 01, 2021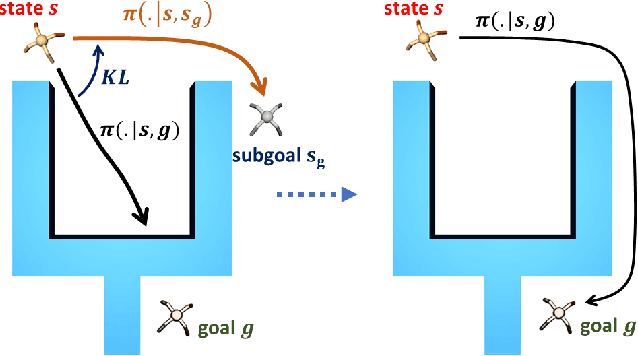
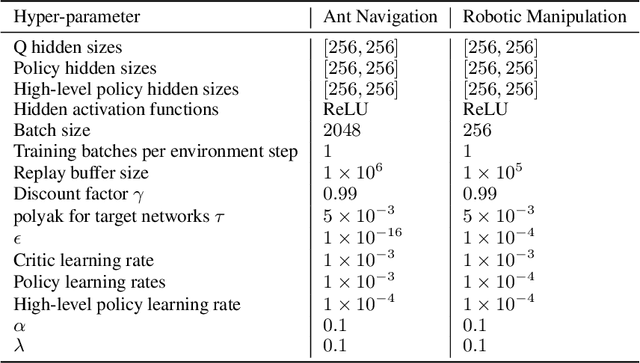
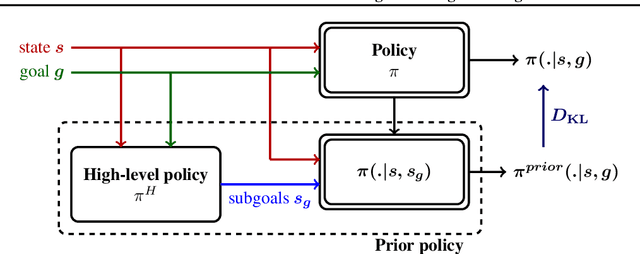

Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don't require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.