 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 23, 2021
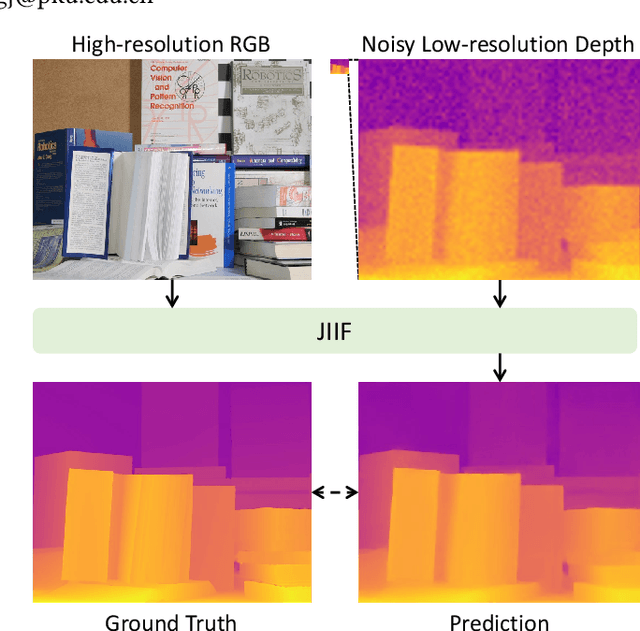
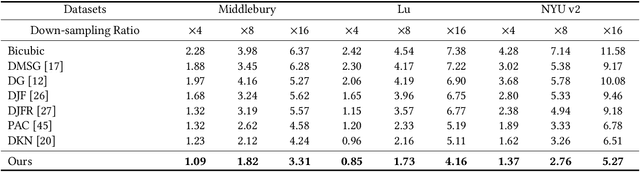
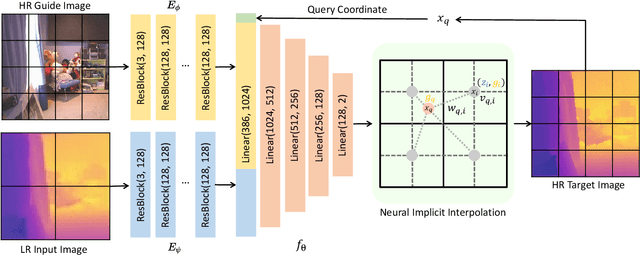
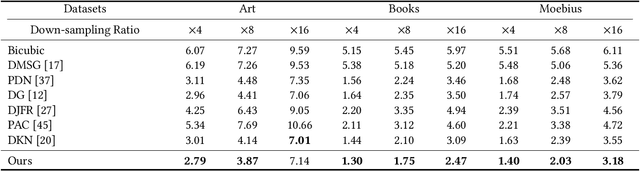
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.
Grouped Convolutional Neural Networks for Multivariate Time Series
May 31, 2018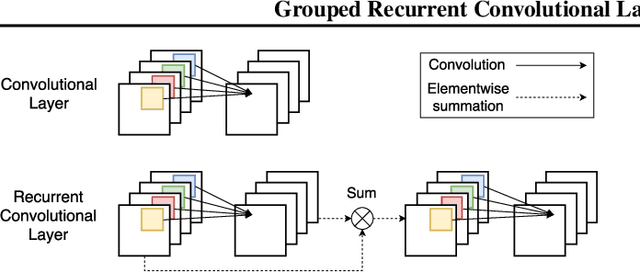
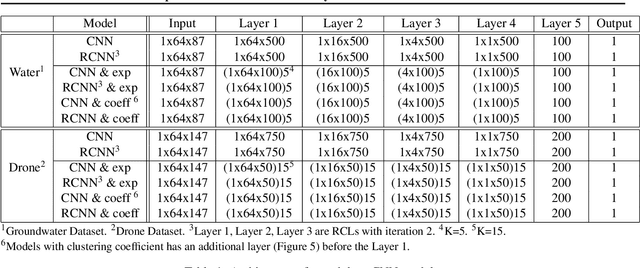
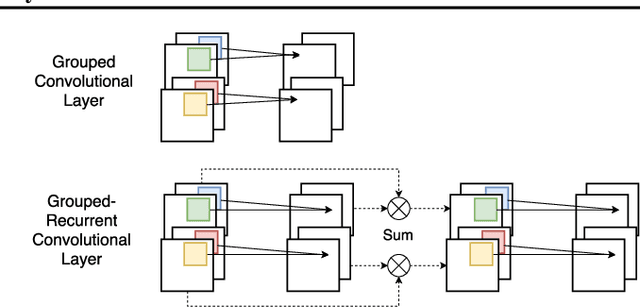
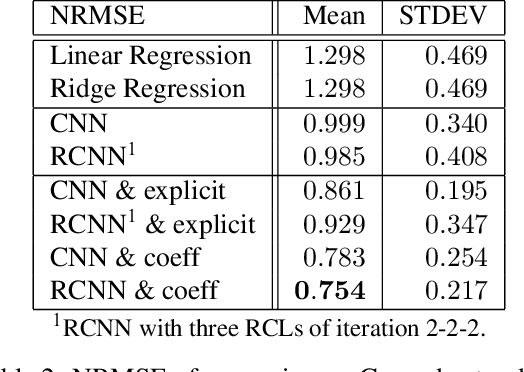
Analyzing multivariate time series data is important for many applications such as automated control, fault diagnosis and anomaly detection. One of the key challenges is to learn latent features automatically from dynamically changing multivariate input. In visual recognition tasks, convolutional neural networks (CNNs) have been successful to learn generalized feature extractors with shared parameters over the spatial domain. However, when high-dimensional multivariate time series is given, designing an appropriate CNN model structure becomes challenging because the kernels may need to be extended through the full dimension of the input volume. To address this issue, we present two structure learning algorithms for deep CNN models. Our algorithms exploit the covariance structure over multiple time series to partition input volume into groups. The first algorithm learns the group CNN structures explicitly by clustering individual input sequences. The second algorithm learns the group CNN structures implicitly from the error backpropagation. In experiments with two real-world datasets, we demonstrate that our group CNNs outperform existing CNN based regression methods.
Real-time Power System State Estimation and Forecasting via Deep Neural Networks
Nov 30, 2018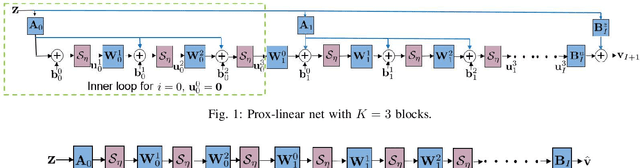
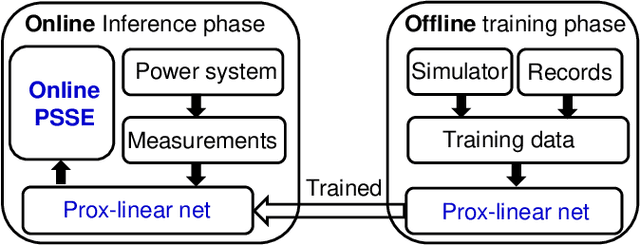
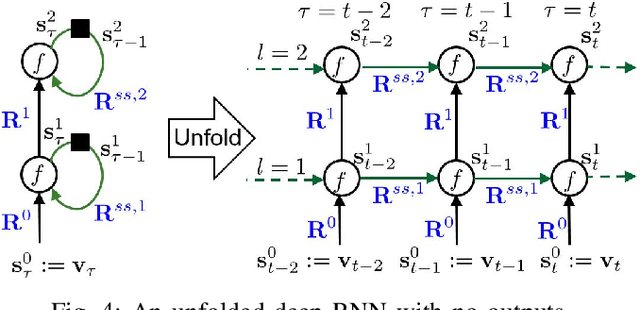
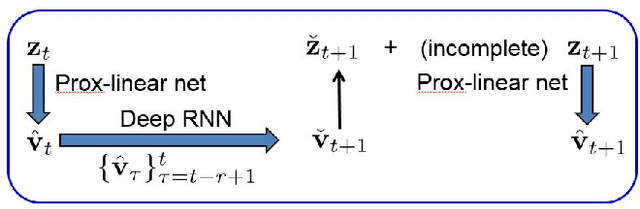
Contemporary power grids are being challenged by rapid voltage fluctuations that are caused by large-scale deployment of renewable generation, electric vehicles, and demand response programs. In this context, monitoring the grid's operating conditions in real time becomes increasingly critical. With the emergent large scale and nonconvexity however, the existing power system state estimation (PSSE) schemes become computationally expensive or yield suboptimal performance. To bypass these hurdles, this paper advocates deep neural networks (DNNs) for real-time power system monitoring. By unrolling an iterative physics-based prox-linear solver, a novel model-specific DNN is developed for real-time PSSE with affordable training and minimal tuning effort. To further enable system awareness even ahead of the time horizon, as well as to endow the DNN-based estimator with resilience, deep recurrent neural networks (RNNs) are also pursued for power system state forecasting. Deep RNNs leverage the long-term nonlinear dependencies present in the historical voltage time series to enable forecasting, and they are easy to implement. Numerical tests showcase improved performance of the proposed DNN-based estimation and forecasting approaches compared with existing alternatives. In real load data experiments on the IEEE 118-bus benchmark system, the novel model-specific DNN-based PSSE scheme outperforms nearly by an order-of-magnitude the competing alternatives, including the widely adopted Gauss-Newton PSSE solver.
Resource Constrained Neural Networks for 5G Direction-of-Arrival Estimation in Micro-controllers
Jul 23, 2021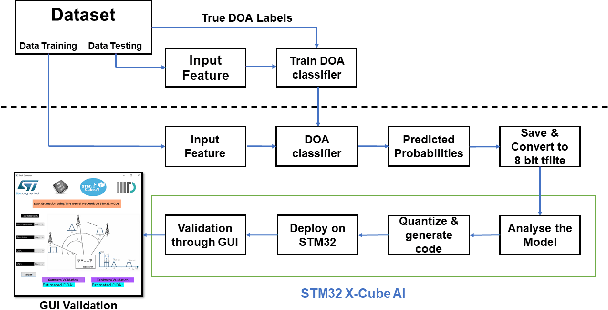
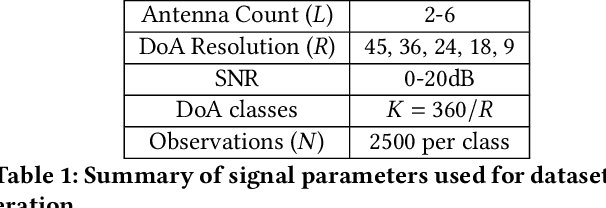
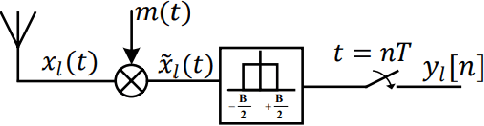
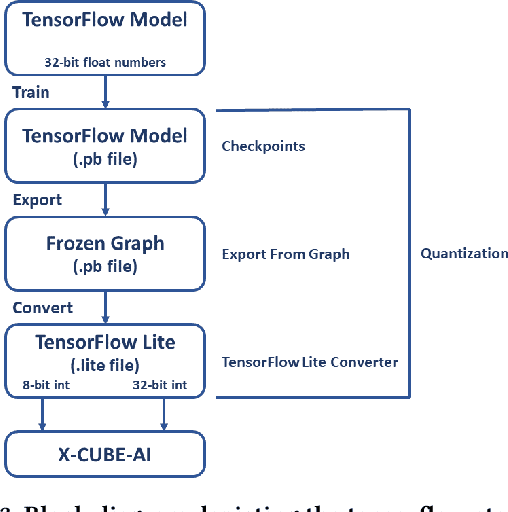
With the introduction of shared spectrum sensing and beam-forming based multi-antenna transceivers, 5G networks demand spectrum sensing to identify opportunities in time, frequency, and spatial domains. Narrow beam-forming makes it difficult to have spatial sensing (direction-of-arrival, DoA, estimation) in a centralized manner, and with the evolution of paradigms such as artificial intelligence of Things (AIOT), ultra-reliable low latency communication (URLLC) services and distributed networks, intelligence for edge devices (Edge-AI) is highly desirable. It helps to reduce the data-communication overhead compared to cloud-AI-centric networks and is more secure and free from scalability limitations. However, achieving desired functional accuracy is a challenge on edge devices such as microcontroller units (MCU) due to area, memory, and power constraints. In this work, we propose low complexity neural network-based algorithm for accurate DoA estimation and its efficient mapping on the off-the-self MCUs. An ad-hoc graphical-user interface (GUI) is developed to configure the STM32 NUCLEO-H743ZI2 MCU with the proposed algorithm and to validate its functionality. The performance of the proposed algorithm is analyzed for different signal-to-noise ratios (SNR), word-length, the number of antennas, and DoA resolution. In-depth experimental results show that it outperforms the conventional statistical spatial sensing approach.
Efficacy of BERT embeddings on predicting disaster from Twitter data
Aug 08, 2021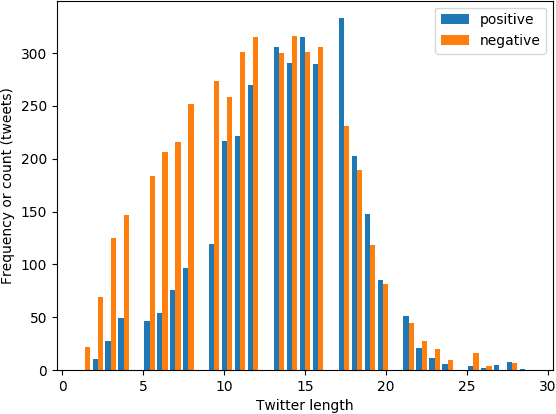
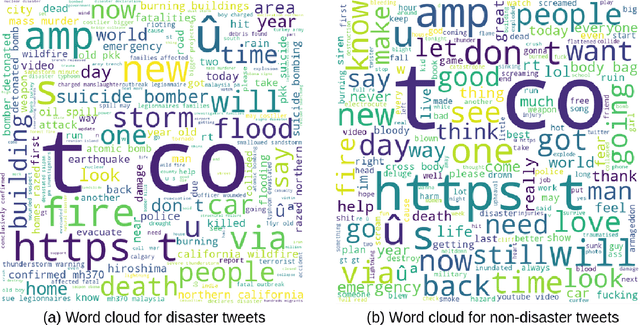
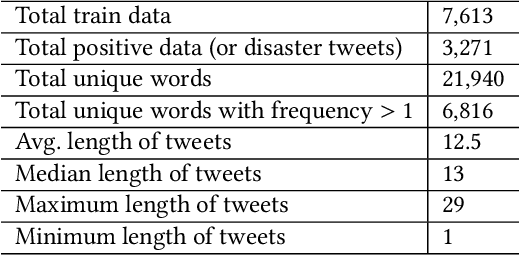
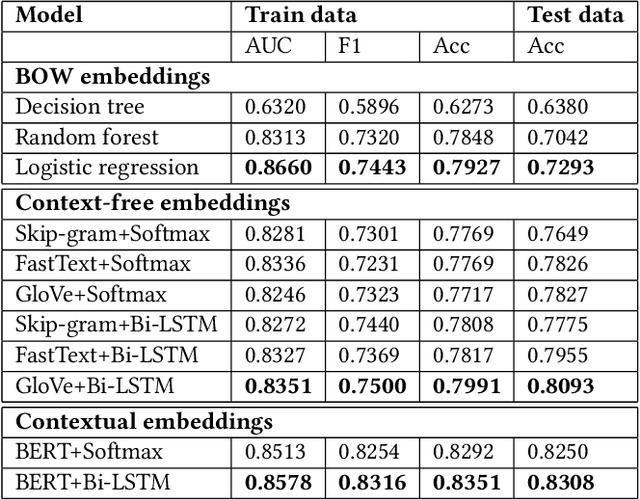
Social media like Twitter provide a common platform to share and communicate personal experiences with other people. People often post their life experiences, local news, and events on social media to inform others. Many rescue agencies monitor this type of data regularly to identify disasters and reduce the risk of lives. However, it is impossible for humans to manually check the mass amount of data and identify disasters in real-time. For this purpose, many research works have been proposed to present words in machine-understandable representations and apply machine learning methods on the word representations to identify the sentiment of a text. The previous research methods provide a single representation or embedding of a word from a given document. However, the recent advanced contextual embedding method (BERT) constructs different vectors for the same word in different contexts. BERT embeddings have been successfully used in different natural language processing (NLP) tasks, yet there is no concrete analysis of how these representations are helpful in disaster-type tweet analysis. In this research work, we explore the efficacy of BERT embeddings on predicting disaster from Twitter data and compare these to traditional context-free word embedding methods (GloVe, Skip-gram, and FastText). We use both traditional machine learning methods and deep learning methods for this purpose. We provide both quantitative and qualitative results for this study. The results show that the BERT embeddings have the best results in disaster prediction task than the traditional word embeddings. Our codes are made freely accessible to the research community.
Numerical Solution of Stiff Ordinary Differential Equations with Random Projection Neural Networks
Aug 03, 2021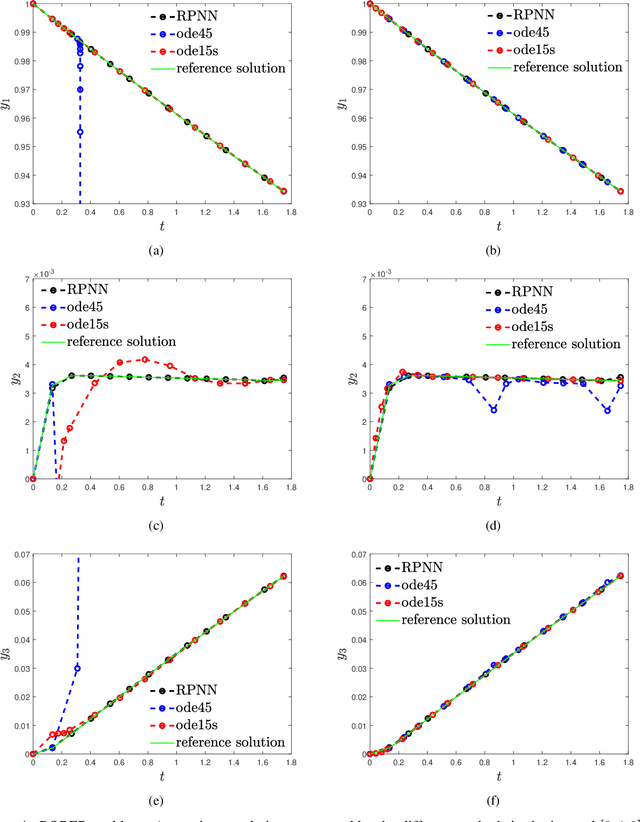


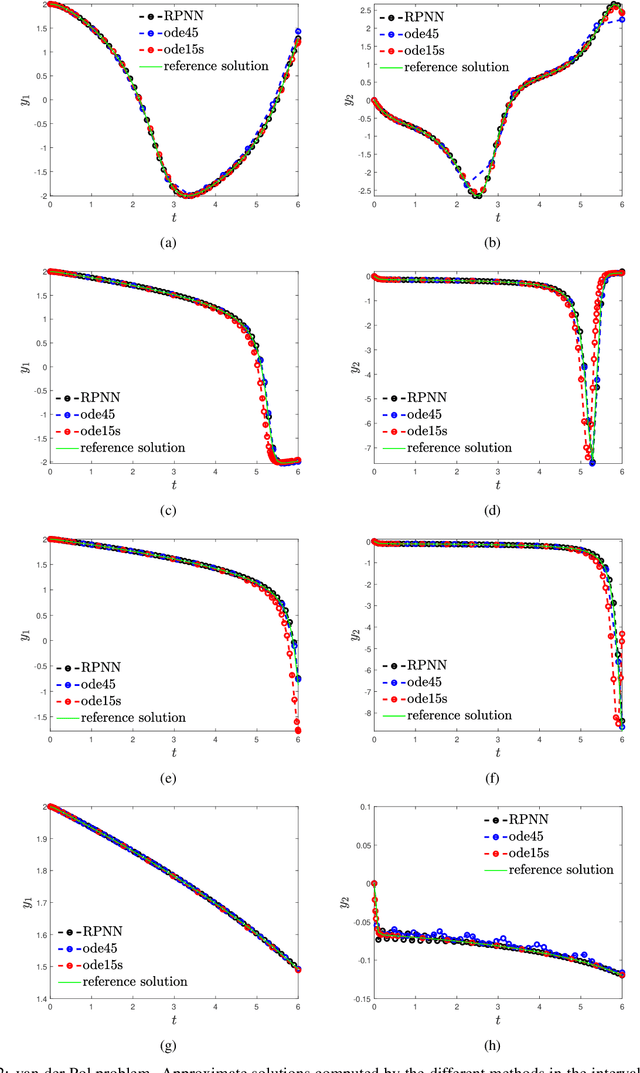
We propose a numerical scheme based on Random Projection Neural Networks (RPNN) for the solution of Ordinary Differential Equations (ODEs) with a focus on stiff problems. In particular, we use an Extreme Learning Machine, a single-hidden layer Feedforward Neural Network with Radial Basis Functions which widths are uniformly distributed random variables, while the values of the weights between the input and the hidden layer are set equal to one. The numerical solution is obtained by constructing a system of nonlinear algebraic equations, which is solved with respect to the output weights using the Gauss-Newton method. For our illustrations, we apply the proposed machine learning approach to solve two benchmark stiff problems, namely the Rober and the van der Pol ones (the latter with large values of the stiffness parameter), and we perform a comparison with well-established methods such as the adaptive Runge-Kutta method based on the Dormand-Prince pair, and a variable-step variable-order multistep solver based on numerical differentiation formulas, as implemented in the \texttt{ode45} and \texttt{ode15s} MATLAB functions, respectively. We show that our proposed scheme yields good numerical approximation accuracy without being affected by the stiffness, thus outperforming in same cases the \texttt{ode45} and \texttt{ode15s} functions. Importantly, upon training using a fixed number of collocation points, the proposed scheme approximates the solution in the whole domain in contrast to the classical time integration methods.
Transformer-Based Behavioral Representation Learning Enables Transfer Learning for Mobile Sensing in Small Datasets
Jul 09, 2021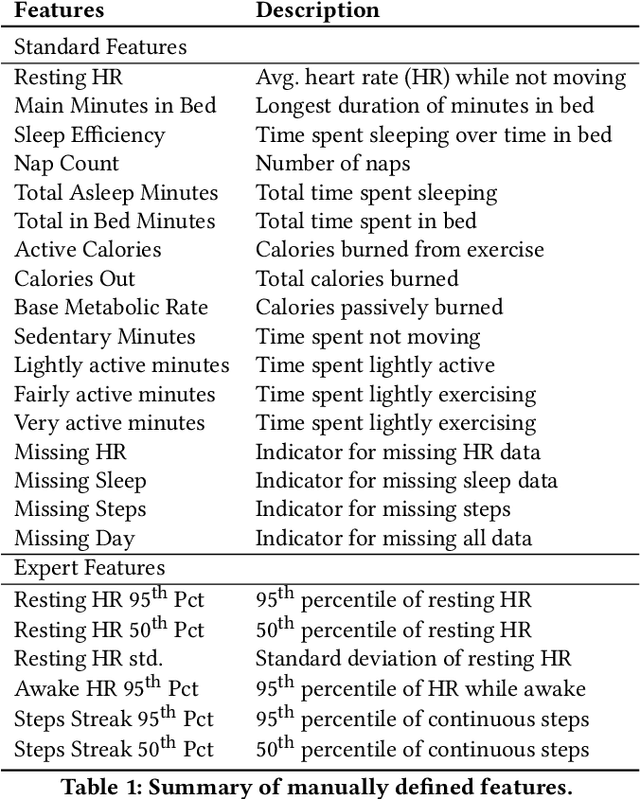

While deep learning has revolutionized research and applications in NLP and computer vision, this has not yet been the case for behavioral modeling and behavioral health applications. This is because the domain's datasets are smaller, have heterogeneous datatypes, and typically exhibit a large degree of missingness. Therefore, off-the-shelf deep learning models require significant, often prohibitive, adaptation. Accordingly, many research applications still rely on manually coded features with boosted tree models, sometimes with task-specific features handcrafted by experts. Here, we address these challenges by providing a neural architecture framework for mobile sensing data that can learn generalizable feature representations from time series and demonstrates the feasibility of transfer learning on small data domains through finetuning. This architecture combines benefits from CNN and Trans-former architectures to (1) enable better prediction performance by learning directly from raw minute-level sensor data without the need for handcrafted features by up to 0.33 ROC AUC, and (2) use pretraining to outperform simpler neural models and boosted decision trees with data from as few a dozen participants.
Sexing Caucasian 2D footprints using convolutional neural networks
Jul 23, 2021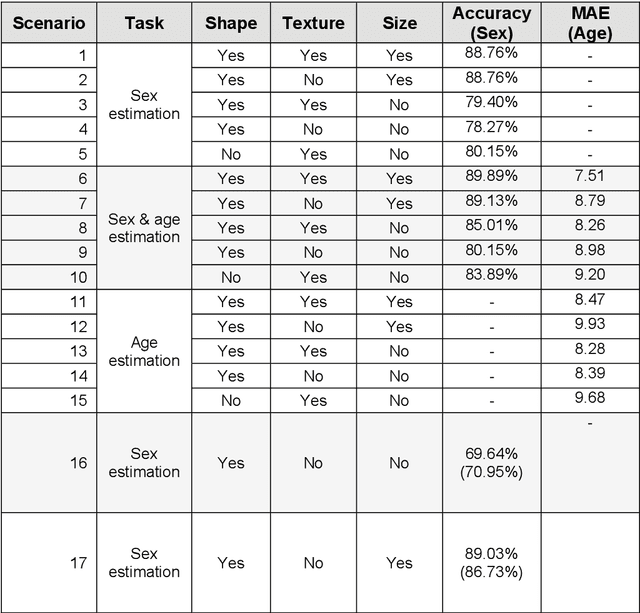
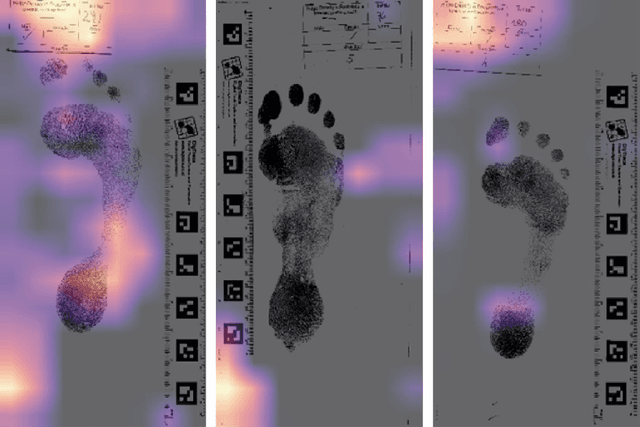
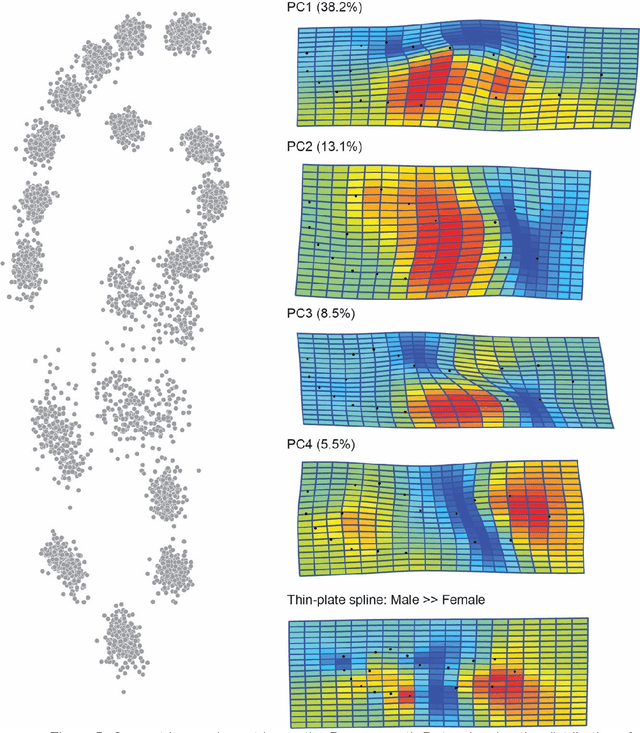
Footprints are left, or obtained, in a variety of scenarios from crime scenes to anthropological investigations. Determining the sex of a footprint can be useful in screening such impressions and attempts have been made to do so using single or multi landmark distances, shape analyses and via the density of friction ridges. Here we explore the relative importance of different components in sexing two-dimensional foot impressions namely, size, shape and texture. We use a machine learning approach and compare this to more traditional methods of discrimination. Two datasets are used, a pilot data set collected from students at Bournemouth University (N=196) and a larger data set collected by podiatrists at Sheffield NHS Teaching Hospital (N=2677). Our convolutional neural network can sex a footprint with accuracy of around 90% on a test set of N=267 footprint images using all image components, which is better than an expert can achieve. However, the quality of the impressions impacts on this success rate, but the results are promising and in time it may be possible to create an automated screening algorithm in which practitioners of whatever sort (medical or forensic) can obtain a first order sexing of a two-dimensional footprint.
Partially Coherent Radar Unties Range Resolution from Bandwidth Limitations
Jun 28, 2021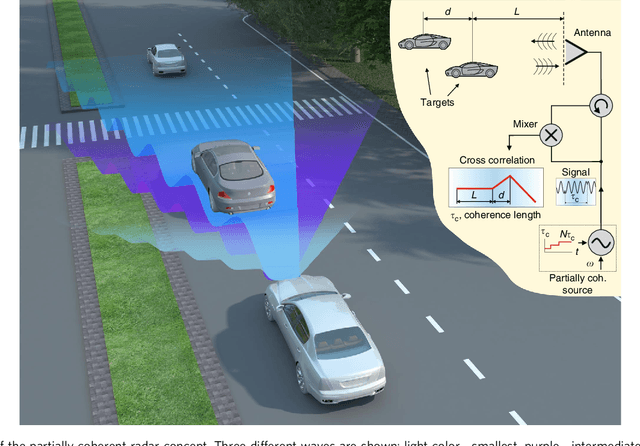
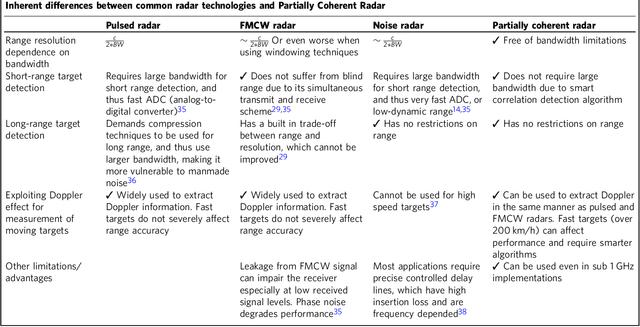
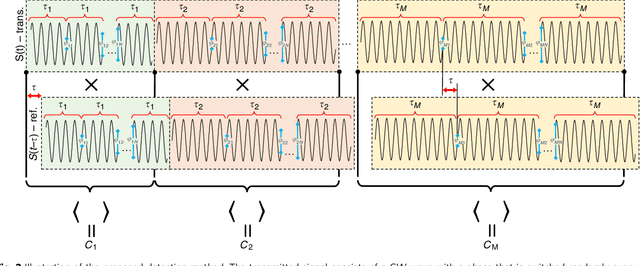
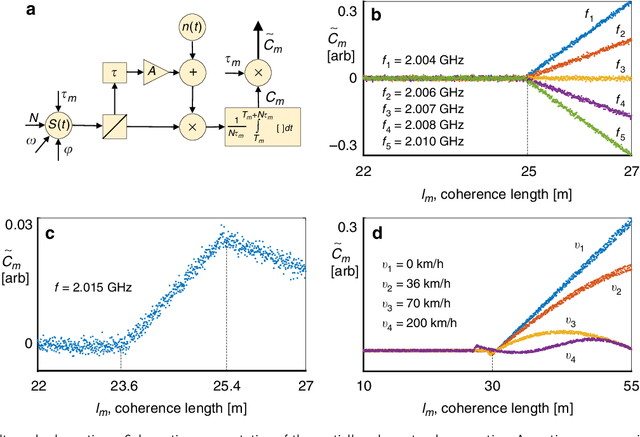
It is widely believed that range resolution, the ability to distinguish between two closely situated targets, depends inversely on the bandwidth of the transmitted radar signal. Here we demonstrate a different type of ranging system, which possesses superior range resolution that is almost completely free of bandwidth limitations. By sweeping over the coherence length of the transmitted signal, the partially coherent radar experimentally demonstrates an improvement of over an order of magnitude in resolving targets, compared to standard coherent radars with the same bandwidth.. A theoretical framework is developed to show that the resolution could be further improved without a bound, revealing a tradeoff between bandwidth and sweep time. This concept offers solutions to problems which require high range resolution and accuracy but available bandwidth is limited, as is the case for the autonomous car industry, optical imaging, and astronomy to name just few.
LensID: A CNN-RNN-Based Framework Towards Lens Irregularity Detection in Cataract Surgery Videos
Jul 02, 2021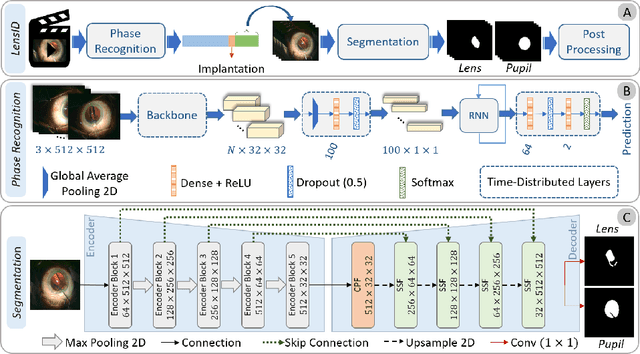
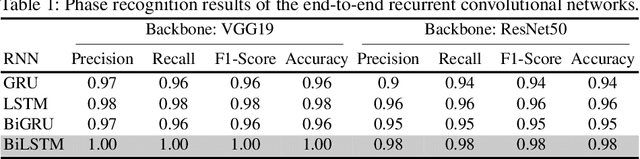
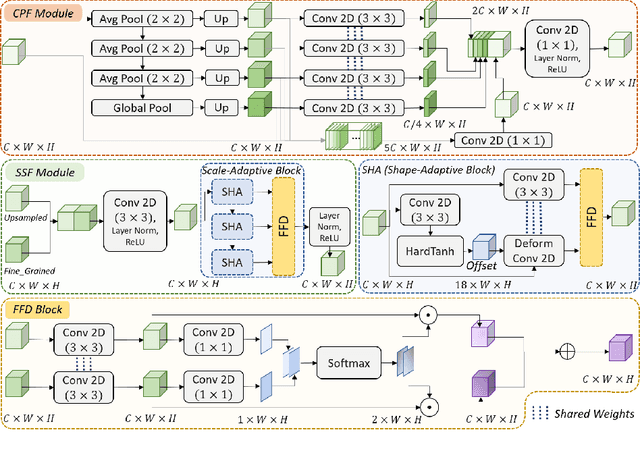
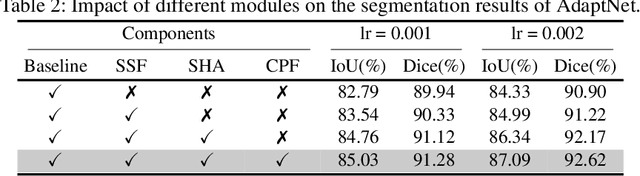
A critical complication after cataract surgery is the dislocation of the lens implant leading to vision deterioration and eye trauma. In order to reduce the risk of this complication, it is vital to discover the risk factors during the surgery. However, studying the relationship between lens dislocation and its suspicious risk factors using numerous videos is a time-extensive procedure. Hence, the surgeons demand an automatic approach to enable a larger-scale and, accordingly, more reliable study. In this paper, we propose a novel framework as the major step towards lens irregularity detection. In particular, we propose (I) an end-to-end recurrent neural network to recognize the lens-implantation phase and (II) a novel semantic segmentation network to segment the lens and pupil after the implantation phase. The phase recognition results reveal the effectiveness of the proposed surgical phase recognition approach. Moreover, the segmentation results confirm the proposed segmentation network's effectiveness compared to state-of-the-art rival approaches.