 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting colorectal polyp recurrence using time-to-event analysis of medical records
Nov 18, 2019
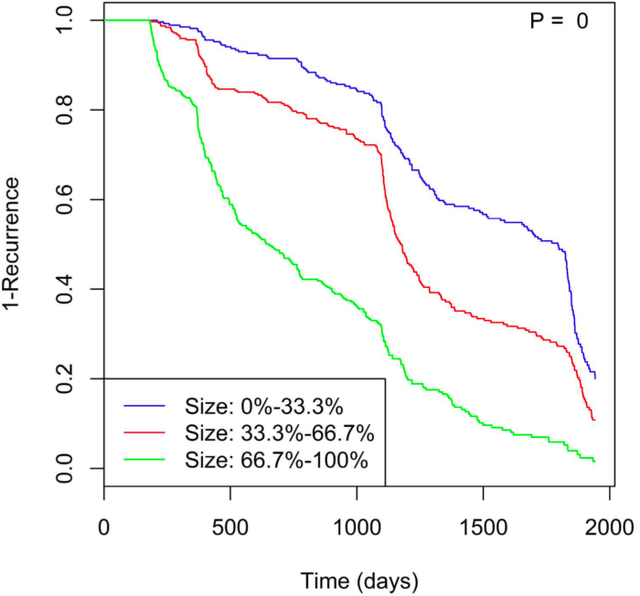
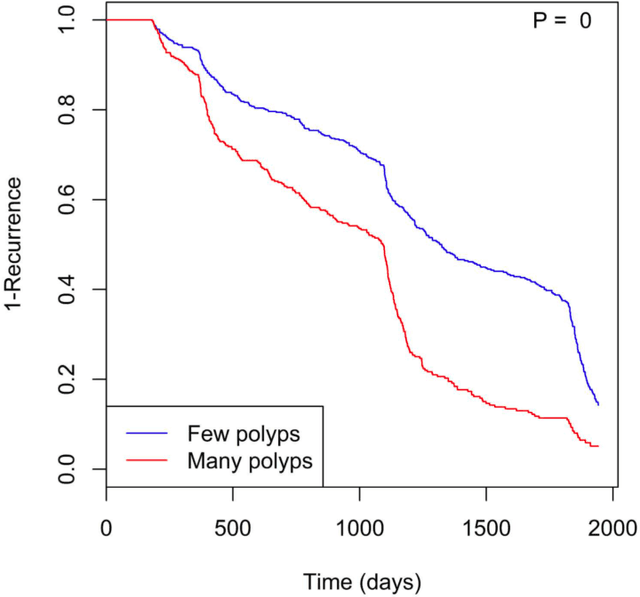
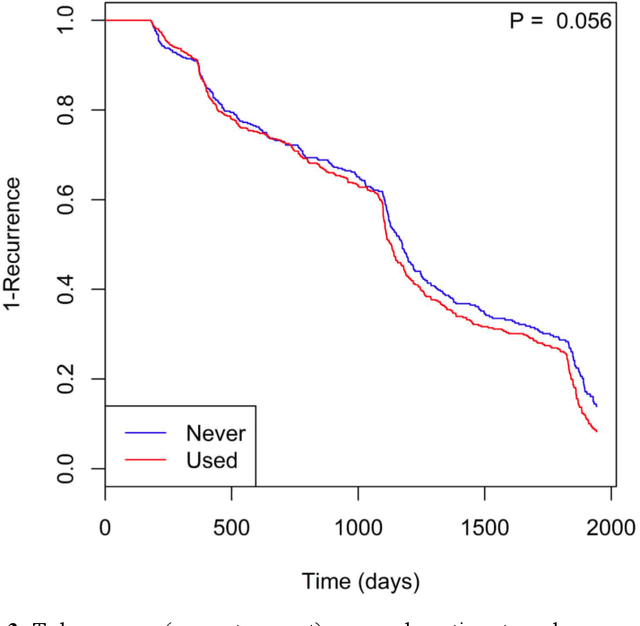
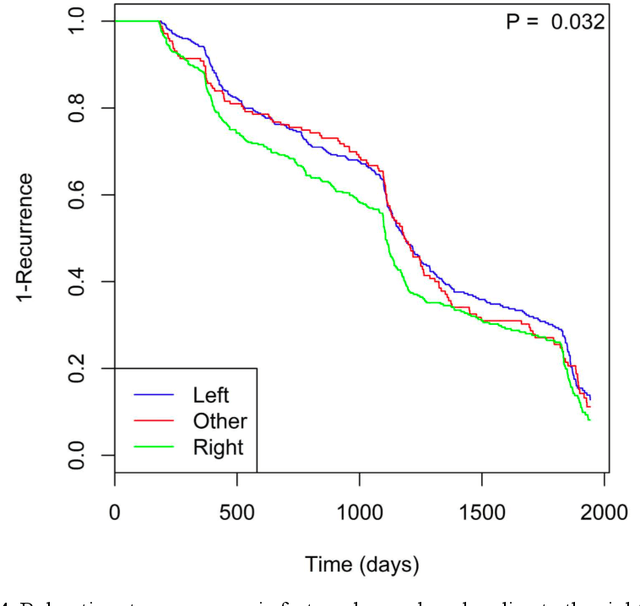
Identifying patient characteristics that influence the rate of colorectal polyp recurrence can provide important insights into which patients are at higher risk for recurrence. We used natural language processing to extract polyp morphological characteristics from 953 polyp-presenting patients' electronic medical records. We used subsequent colonoscopy reports to examine how the time to polyp recurrence (731 patients experienced recurrence) is influenced by these characteristics as well as anthropometric features using Kaplan-Meier curves, Cox proportional hazards modeling, and random survival forest models. We found that the rate of recurrence differed significantly by polyp size, number, and location and patient smoking status. Additionally, right-sided colon polyps increased recurrence risk by 30% compared to left-sided polyps. History of tobacco use increased polyp recurrence risk by 20% compared to never-users. A random survival forest model showed an AUC of 0.65 and identified several other predictive variables, which can inform development of personalized polyp surveillance plans.
A New Method for Features Normalization in Motor Imagery Few-Shot Learning using Resting-State
Mar 17, 2021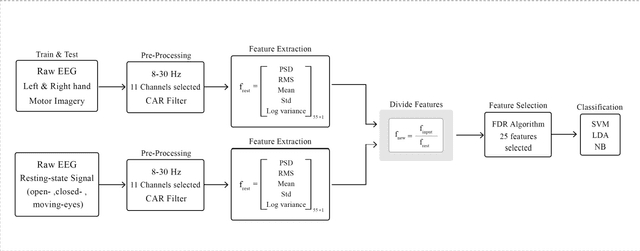
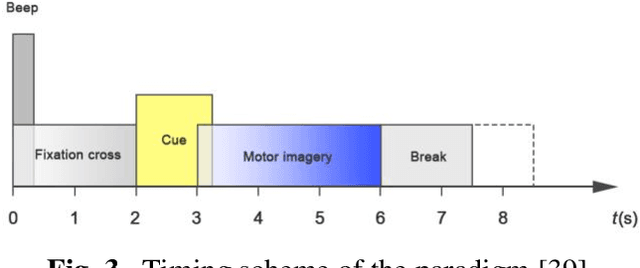
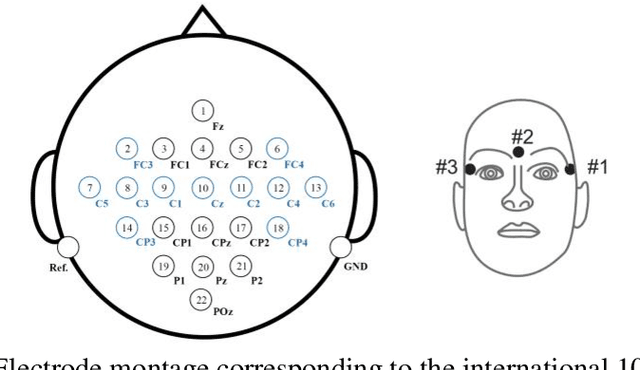
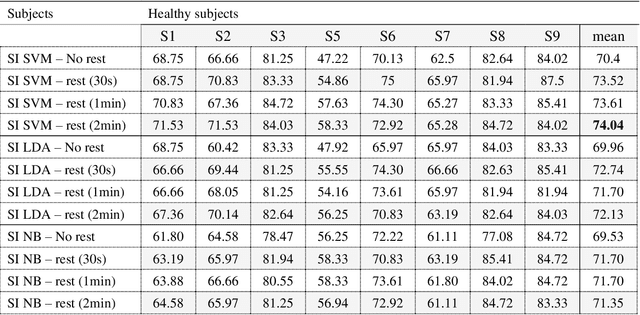
Brain-computer interface (BCI) systems are usually designed specifically for each subject based on motor imagery. Therefore, the usability of these networks has become a significant challenge. The network has to be designed separately for each user, which is time-consuming for the user. Therefore, this study proposes a method by which the calibration time is significantly reduced while the classification accuracy is increased. In this method, we calibrated the features extracted from the motor imagery task by dividing the features extracted from the resting-state into both open-eye and closed-eye modes and the state in which the subject moves his eyes. The best classification accuracy was obtained using the SVM classifier using the resting-state signal in the open eye, which increased by 3.64% to 74.04%. In this paper, we also investigated the effect of recording time of the resting-state signal and the impact of eye state on the classification accuracy.
Real-time Grasp Pose Estimation for Novel Objects in Densely Cluttered Environment
Jan 03, 2020
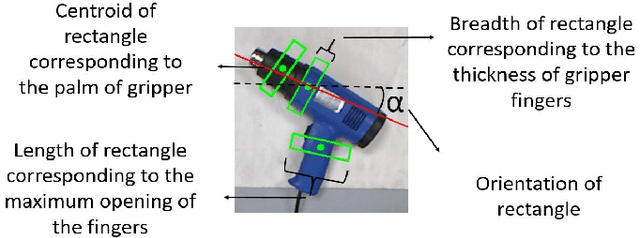
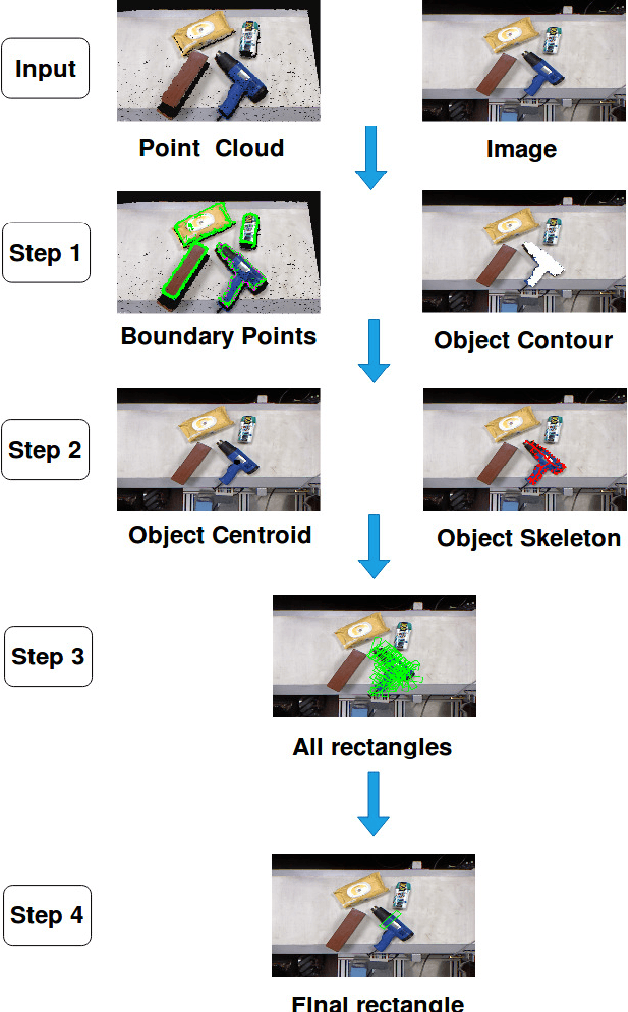
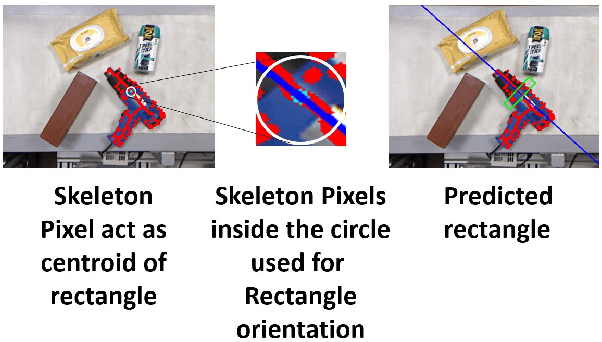
Grasping of novel objects in pick and place applications is a fundamental and challenging problem in robotics, specifically for complex-shaped objects. It is observed that the well-known strategies like \textit{i}) grasping from the centroid of object and \textit{ii}) grasping along the major axis of the object often fails for complex-shaped objects. In this paper, a real-time grasp pose estimation strategy for novel objects in robotic pick and place applications is proposed. The proposed technique estimates the object contour in the point cloud and predicts the grasp pose along with the object skeleton in the image plane. The technique is tested for the objects like ball container, hand weight, tennis ball and even for complex shape objects like blower (non-convex shape). It is observed that the proposed strategy performs very well for complex shaped objects and predicts the valid grasp configurations in comparison with the above strategies. The experimental validation of the proposed grasping technique is tested in two scenarios, when the objects are placed distinctly and when the objects are placed in dense clutter. A grasp accuracy of 88.16\% and 77.03\% respectively are reported. All the experiments are performed with a real UR10 robot manipulator along with WSG-50 two-finger gripper for grasping of objects.
The Care Label Concept: A Certification Suite for Trustworthy and Resource-Aware Machine Learning
Jun 01, 2021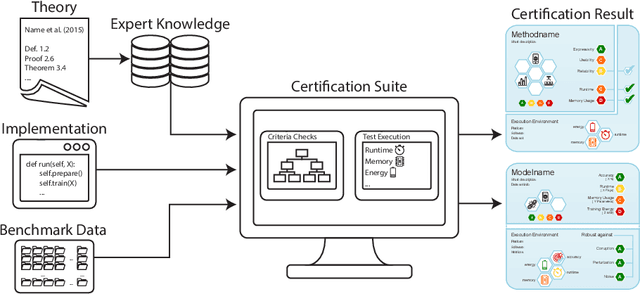
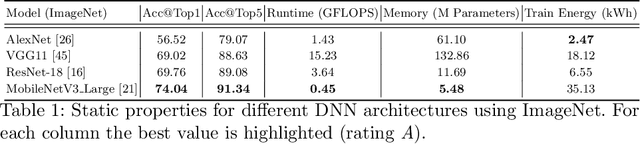
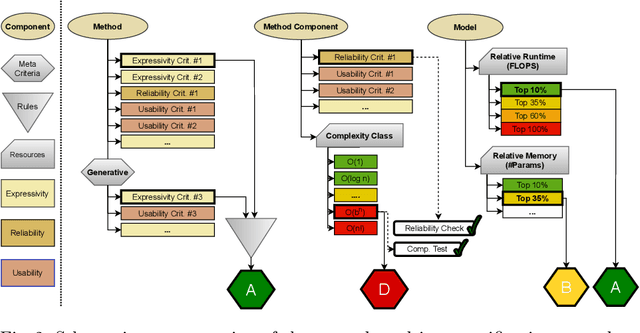
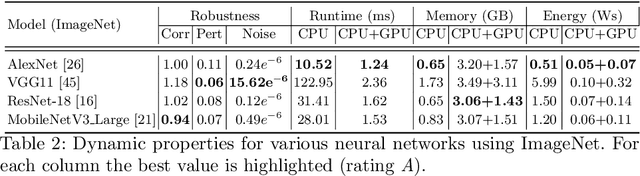
Machine learning applications have become ubiquitous. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. For those who do not want to invest time into understanding the method or the learned model, we offer care labels: easy to understand at a glance, allowing for method or model comparisons, and, at the same time, scientifically well-based. On one hand, this transforms descriptions as given by, e.g., Fact Sheets or Model Cards, into a form that is well-suited for end-users. On the other hand, care labels are the result of a certification suite that tests whether stated guarantees hold. In this paper, we present two experiments with our certification suite. One shows the care labels for configurations of Markov random fields (MRFs). Based on the underlying theory of MRFs, each choice leads to its specific rating of static properties like, e.g., expressivity and reliability. In addition, the implementation is tested and resource consumption is measured yielding dynamic properties. This two-level procedure is followed by another experiment certifying deep neural network (DNN) models. There, we draw the static properties from the literature on a particular model and data set. At the second level, experiments are generated that deliver measurements of robustness against certain attacks. We illustrate this by ResNet-18 and MobileNetV3 applied to ImageNet.
Compressive Representations of Weather Scenes for Strategic Air Traffic Flow Management
Jul 02, 2021
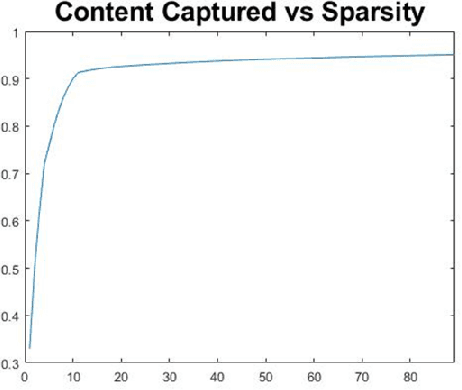
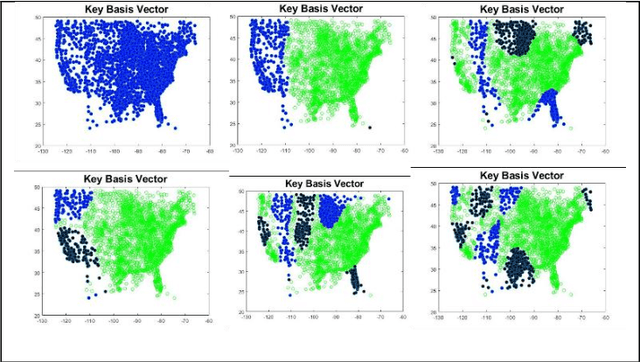
Terse representation of high-dimensional weather scene data is explored, in support of strategic air traffic flow management objectives. Specifically, we consider whether aviation-relevant weather scenes are compressible, in the sense that each scene admits a possibly-different sparse representation in a basis of interest. Here, compression of weather scenes extracted from METAR data (including temperature, flight categories, and visibility profiles for the contiguous United States) is examined, for the graph-spectral basis. The scenes are found to be compressible, with 75-95% of the scene content captured using 0.5-4% of the basis vectors. Further, the dominant basis vectors for each scene are seen to identify time-varying spatial characteristics of the weather, and reconstruction from the compressed representation is demonstrated. Finally, potential uses of the compressive representations in strategic TFM design are briefly scoped.
Geodesic Density Regression for Correcting 4DCT Pulmonary Respiratory Motion Artifacts
Jun 12, 2021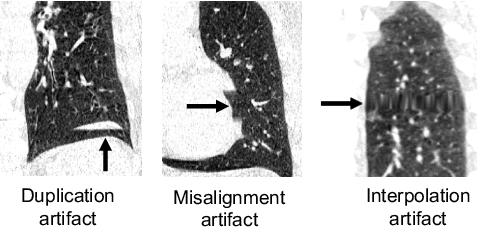
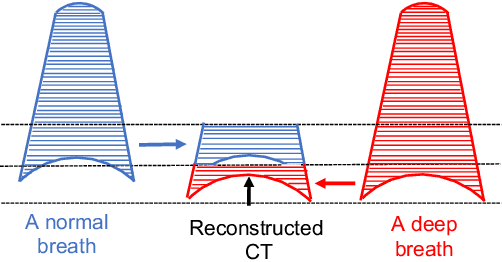
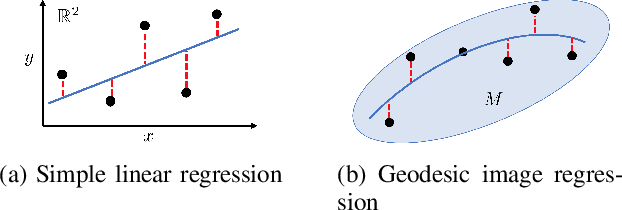
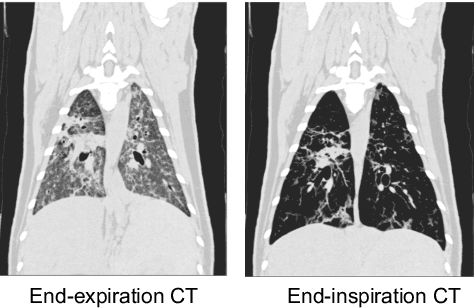
Pulmonary respiratory motion artifacts are common in four-dimensional computed tomography (4DCT) of lungs and are caused by missing, duplicated, and misaligned image data. This paper presents a geodesic density regression (GDR) algorithm to correct motion artifacts in 4DCT by correcting artifacts in one breathing phase with artifact-free data from corresponding regions of other breathing phases. The GDR algorithm estimates an artifact-free lung template image and a smooth, dense, 4D (space plus time) vector field that deforms the template image to each breathing phase to produce an artifact-free 4DCT scan. Correspondences are estimated by accounting for the local tissue density change associated with air entering and leaving the lungs, and using binary artifact masks to exclude regions with artifacts from image regression. The artifact-free lung template image is generated by mapping the artifact-free regions of each phase volume to a common reference coordinate system using the estimated correspondences and then averaging. This procedure generates a fixed view of the lung with an improved signal-to-noise ratio. The GDR algorithm was evaluated and compared to a state-of-the-art geodesic intensity regression (GIR) algorithm using simulated CT time-series and 4DCT scans with clinically observed motion artifacts. The simulation shows that the GDR algorithm has achieved significantly more accurate Jacobian images and sharper template images, and is less sensitive to data dropout than the GIR algorithm. We also demonstrate that the GDR algorithm is more effective than the GIR algorithm for removing clinically observed motion artifacts in treatment planning 4DCT scans. Our code is freely available at https://github.com/Wei-Shao-Reg/GDR.
ECLARE: Extreme Classification with Label Graph Correlations
Jul 31, 2021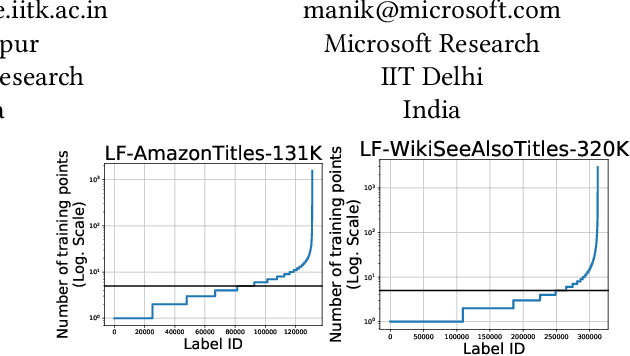
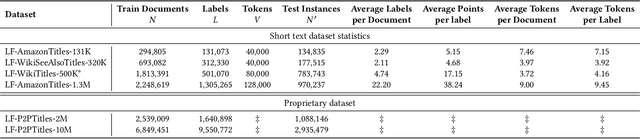
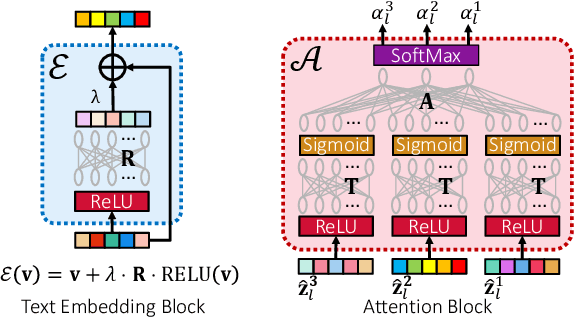
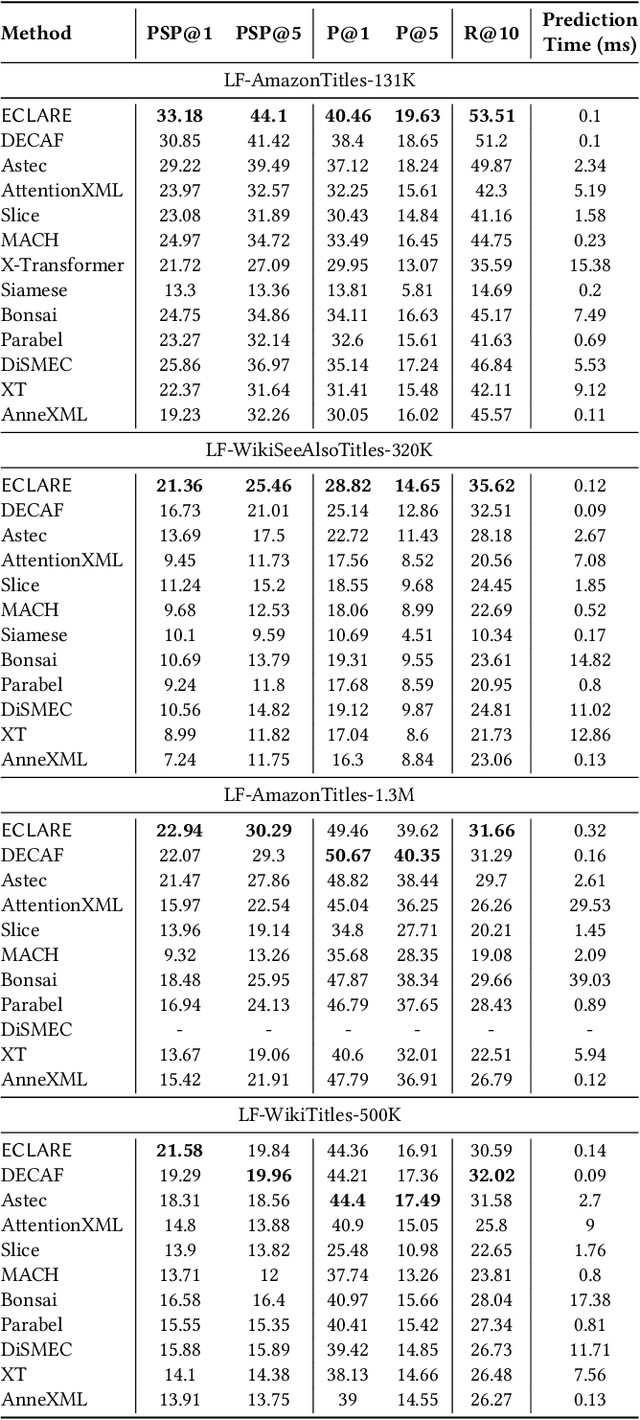
Deep extreme classification (XC) seeks to train deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. The core utility of XC comes from predicting labels that are rarely seen during training. Such rare labels hold the key to personalized recommendations that can delight and surprise a user. However, the large number of rare labels and small amount of training data per rare label offer significant statistical and computational challenges. State-of-the-art deep XC methods attempt to remedy this by incorporating textual descriptions of labels but do not adequately address the problem. This paper presents ECLARE, a scalable deep learning architecture that incorporates not only label text, but also label correlations, to offer accurate real-time predictions within a few milliseconds. Core contributions of ECLARE include a frugal architecture and scalable techniques to train deep models along with label correlation graphs at the scale of millions of labels. In particular, ECLARE offers predictions that are 2 to 14% more accurate on both publicly available benchmark datasets as well as proprietary datasets for a related products recommendation task sourced from the Bing search engine. Code for ECLARE is available at https://github.com/Extreme-classification/ECLARE.
Classification of Common Waveforms Including a Watchdog for Unknown Signals
Aug 16, 2021
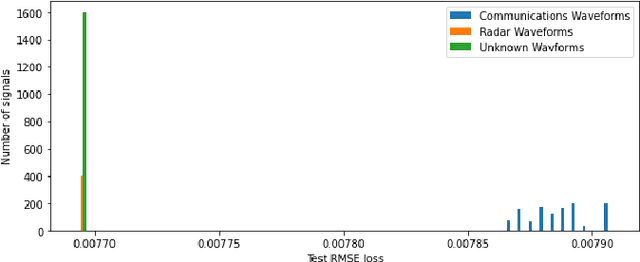
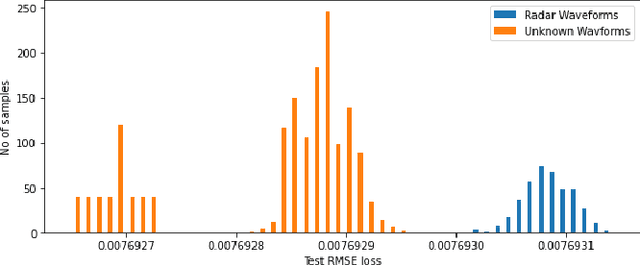

In this paper, we examine the use of a deep multi-layer perceptron model architecture to classify received signal samples as coming from one of four common waveforms, Single Carrier (SC), Single-Carrier Frequency Division Multiple Access (SC-FDMA), Orthogonal Frequency Division Multiplexing (OFDM), and Linear Frequency Modulation (LFM), used in communication and radar networks. Synchronization of the signals is not needed as we assume there is an unknown and uncompensated time and frequency offset. An autoencoder with a deep CNN architecture is also examined to create a new fifth classification category of an unknown waveform type. This is accomplished by calculating a minimum and maximum threshold values from the root mean square error (RMSE) of the radar and communication waveforms. The classifier and autoencoder work together to monitor a spectrum area to identify the common waveforms inside the area of operation along with detecting unknown waveforms. Results from testing showed the classifier had 100\% classification rate above 0 dB with accuracy of 83.2\% and 94.7\% at -10 dB and -5 dB, respectively, with signal impairments present. Results for the anomaly detector showed 85.3\% accuracy at 0 dB with 100\% at SNR greater than 0 dB with signal impairments present when using a high-value Fast Fourier Transform (FFT) size. Accurate detection rates decline as additional noise is introduced to the signals, with 78.1\% at -5 dB and 56.5\% at -10 dB. However, these low rates seen can be potentially mitigated by using even higher FFT sizes also shown in our results.
On the Scheduling and Power Control for Uplink Cellular-Connected UAV Communications
Jul 25, 2021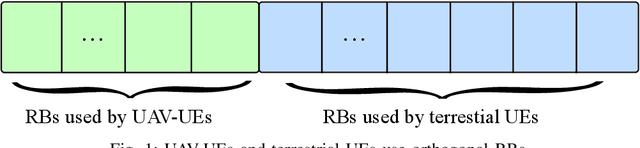
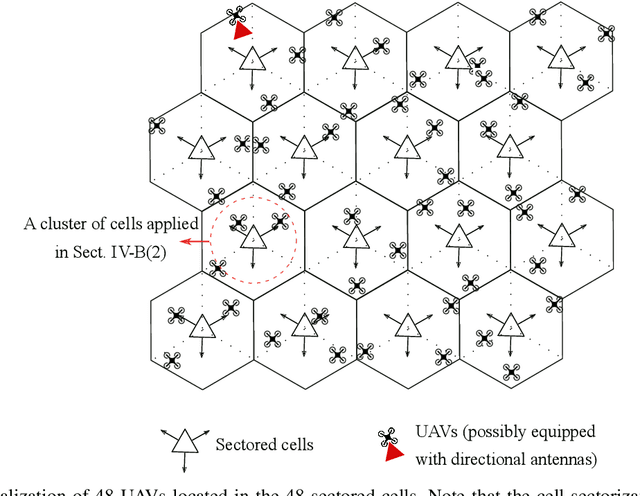
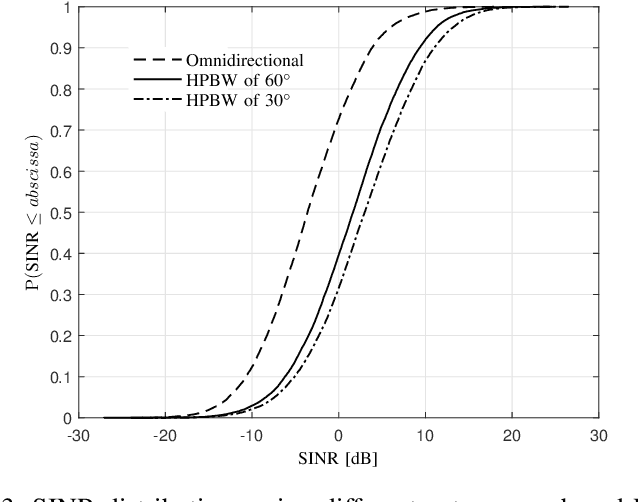
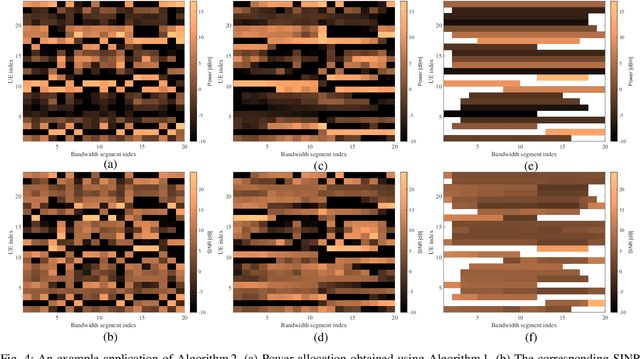
Cellular connected unmanned aerial vehicle (UAV) has been identified as a promising paradigm and attracted a surge of research interest recently. Although the nearly line-of-sight (LoS) channels are favorable to receive higher powers, UAV can in turn cause severe interference to each other and to any other users in the same frequency band. In this contribution, we focus on the uplink communications of cellular-connected UAV. To cope with the severe interference among UAV-UEs, several different scheduling and power control algorithms are proposed to optimize the spectrum efficiency (SE) based on the geometrical programming (GP) principle together with the successive convex approximation (SCA) technique. The proposed schemes include maximizing the sum SE of UAVs, maximizing the minimum SE of UAVs, etc., applied in the frequency domain and/or the time domain. Moreover, the quality of service (QoS) constraint and the uplink single-carrier (SC) constraint are also considered. The performances of these power and resource allocation algorithms are evaluated via extensive simulations in both full buffer transmission mode and bursty traffic mode. Numerical results show that the proposed algorithms can effectively enhance the uplink SEs of cellular-connected UAVs.
Throughput Maximization for IRS-Assisted Wireless Powered Hybrid NOMA and TDMA
Apr 27, 2021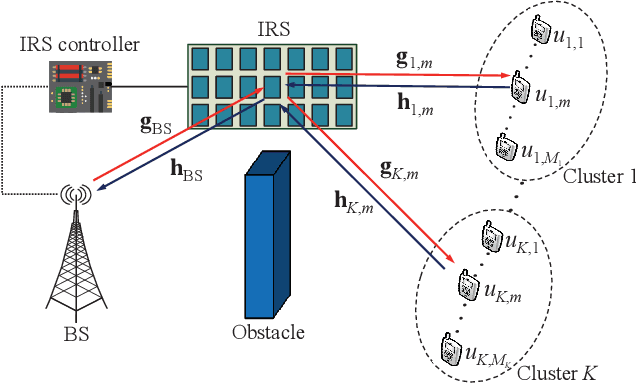
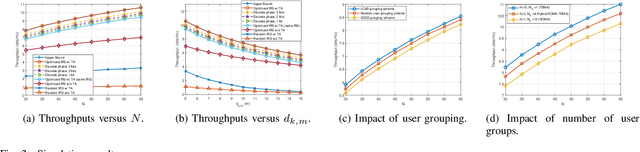
The high reflect beamforming gain of the intelligent reflecting surface (IRS) makes it appealing not only for wireless information transmission but also for wireless power transfer. In this letter, we consider an IRS-assisted wireless powered communication network, where a base station (BS) transmits energy to multiple users grouped into multiple clusters in the downlink, and the clustered users transmit information to the BS in the manner of hybrid non-orthogonal multiple access and time division multiple access in the uplink. We investigate optimizing the reflect beamforming of the IRS and the time allocation among the BS's power transfer and different user clusters' information transmission to maximize the throughput of the network, and we propose an efficient algorithm based on the block coordinate ascent, semidefinite relaxation, and sequential rank-one constraint relaxation techniques to solve the resultant problem. Simulation results have verified the effectiveness of the proposed algorithm and have shown the impact of user clustering setup on the throughput performance of the network.