 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tackling the Overestimation of Forest Carbon with Deep Learning and Aerial Imagery
Jul 23, 2021
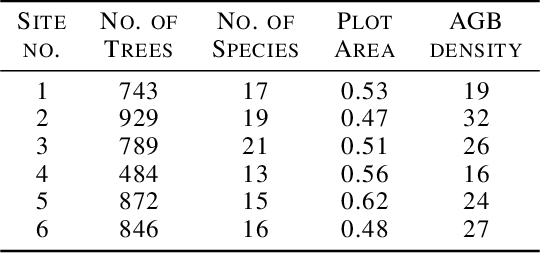
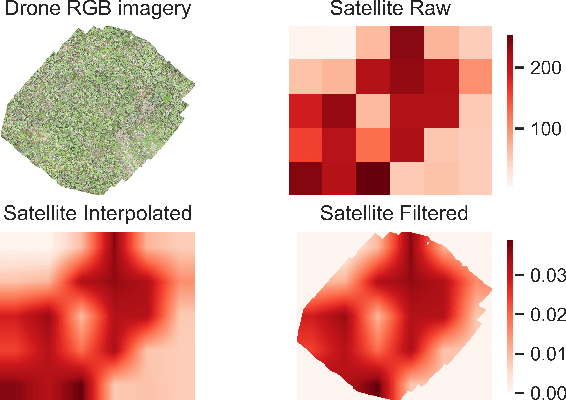
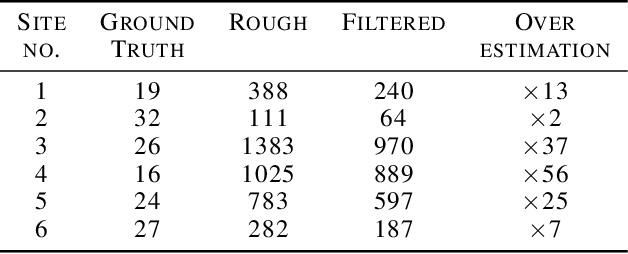
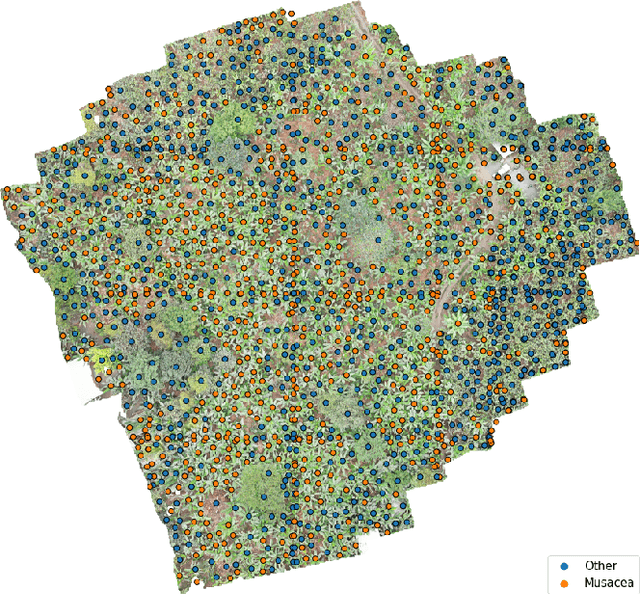
Forest carbon offsets are increasingly popular and can play a significant role in financing climate mitigation, forest conservation, and reforestation. Measuring how much carbon is stored in forests is, however, still largely done via expensive, time-consuming, and sometimes unaccountable field measurements. To overcome these limitations, many verification bodies are leveraging machine learning (ML) algorithms to estimate forest carbon from satellite or aerial imagery. Aerial imagery allows for tree species or family classification, which improves the satellite imagery-based forest type classification. However, aerial imagery is significantly more expensive to collect and it is unclear by how much the higher resolution improves the forest carbon estimation. This proposal paper describes the first systematic comparison of forest carbon estimation from aerial imagery, satellite imagery, and ground-truth field measurements via deep learning-based algorithms for a tropical reforestation project. Our initial results show that forest carbon estimates from satellite imagery can overestimate above-ground biomass by more than 10-times for tropical reforestation projects. The significant difference between aerial and satellite-derived forest carbon measurements shows the potential for aerial imagery-based ML algorithms and raises the importance to extend this study to a global benchmark between options for carbon measurements.
Probabilistic Attention for Interactive Segmentation
Jul 02, 2021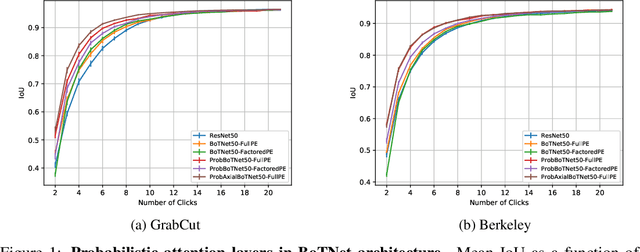
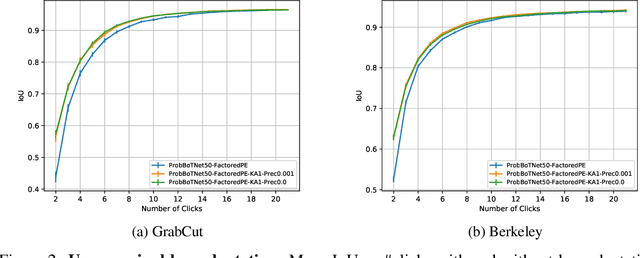
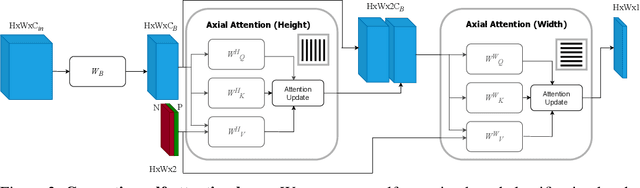
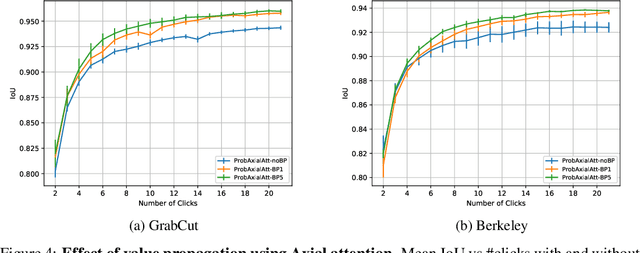
We provide a probabilistic interpretation of attention and show that the standard dot-product attention in transformers is a special case of Maximum A Posteriori (MAP) inference. The proposed approach suggests the use of Expectation Maximization algorithms for online adaptation of key and value model parameters. This approach is useful for cases in which external agents, e.g., annotators, provide inference-time information about the correct values of some tokens, e.g, the semantic category of some pixels, and we need for this new information to propagate to other tokens in a principled manner. We illustrate the approach on an interactive semantic segmentation task in which annotators and models collaborate online to improve annotation efficiency. Using standard benchmarks, we observe that key adaptation boosts model performance ($\sim10\%$ mIoU) in the low feedback regime and value propagation improves model responsiveness in the high feedback regime. A PyTorch layer implementation of our probabilistic attention model will be made publicly available here: https://github.com/apple/ml-probabilistic-attention.
Path Planning in Dynamic Environments Using Time-Warped Grids and a Parallel Implementation
Mar 18, 2019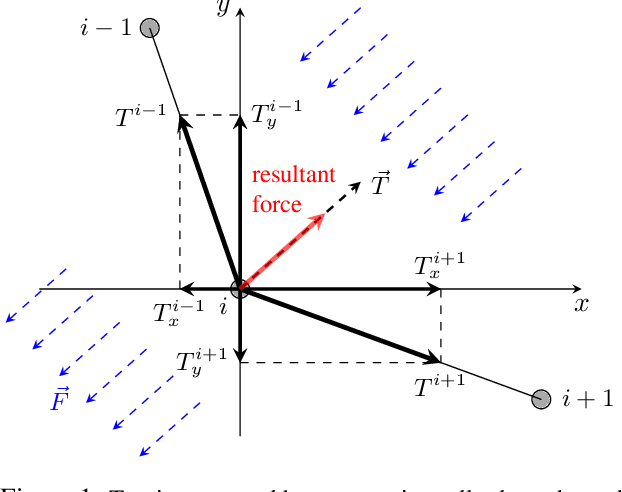
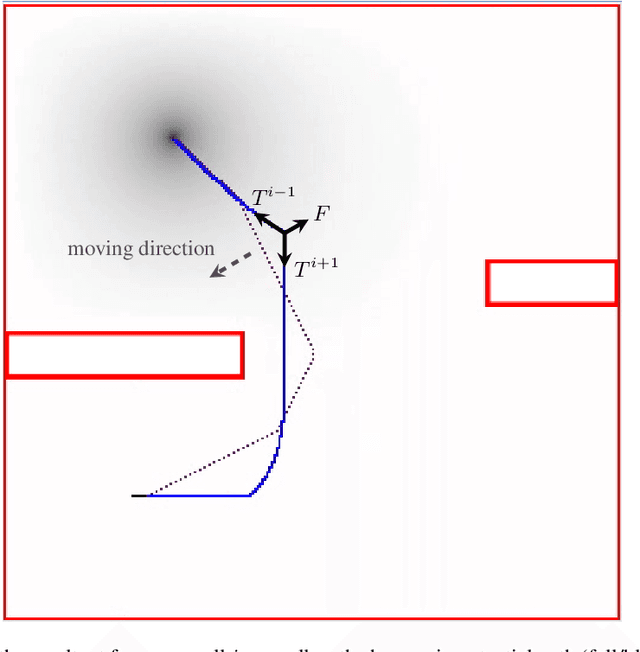
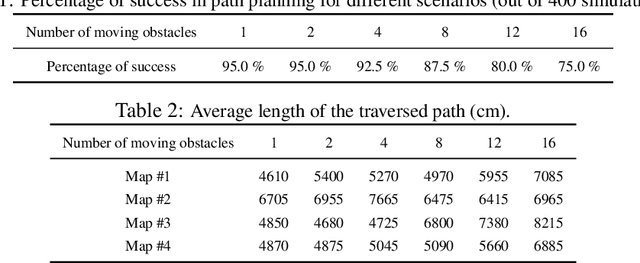
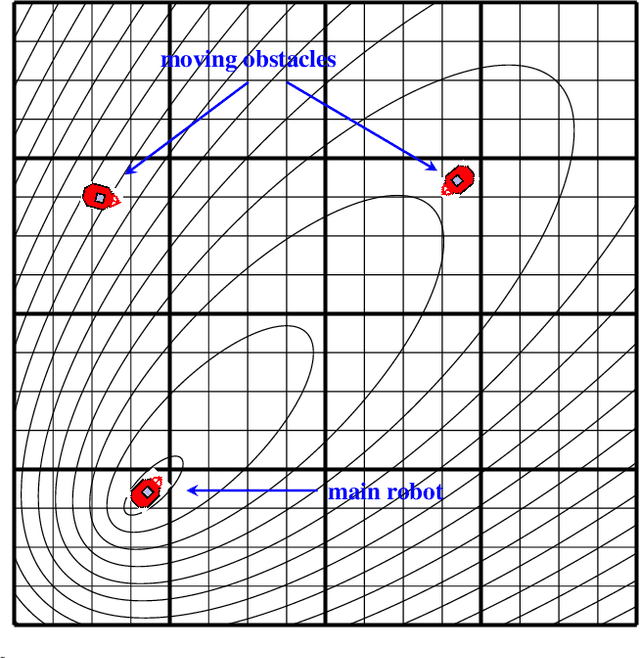
This paper proposes a solution to the problem of smooth path planning for mobile robots in dynamic and unknown environments. A novel concept of Time-Warped Grid is introduced to predict the pose of obstacles in the environment and avoid collisions. The algorithm is implemented using C/C++ and the CUDA programming environment, and combines stochastic estimation (Kalman filter), harmonic potential fields and a rubber band model, and it translates naturally into the parallel paradigm of GPU programming. In simple terms, time-warped grids are progressively wider orbits around the mobile robot. Those orbits represent the variable time intervals estimated by the robot to reach detected obstacles. The proposed method was tested using several simulation scenarios for the Pioneer P3-DX robot, which demonstrated the robustness of the algorithm by finding the optimum path in terms of smoothness, distance, and collision-free, in both static or dynamic environments, and with large number of obstacles.
DPT-FSNet:Dual-path Transformer Based Full-band and Sub-band Fusion Network for Speech Enhancement
Apr 27, 2021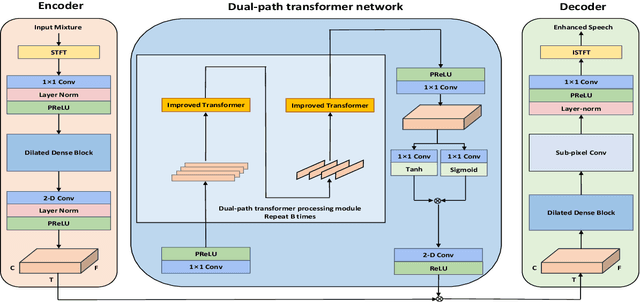
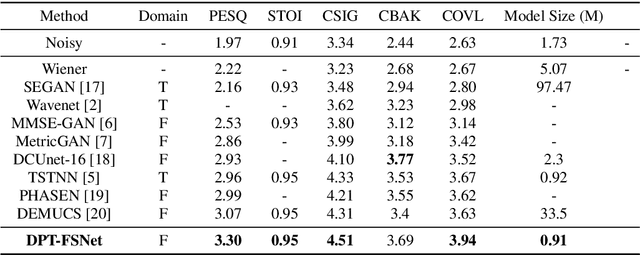

Recently, dual-path networks have achieved promising performance due to their ability to model local and global features of the input sequence. However, previous studies are based on simple time-domain features and do not fully investigate the impact of the input features of the dual-path network on the enhancement performance. In this paper, we propose a dual-path transformer-based full-band and sub-band fusion network (DPT-FSNet) for speech enhancement in the frequency domain. The intra and inter parts of the dual-path transformer network in our model can be seen as sub-band and full-band modeling respectively, which have stronger interpretability as well as more information compared to the features utilized by the time-domain transformer. We conducted experiments on the Voice Bank + DEMAND dataset to evaluate the proposed method. Experimental results show that the proposed method outperforms the current state-of-the-arts in terms of PESQ, STOI, CSIG, COVL. (The PESQ, STOI, CSIG, and COVL scores on the Voice Bank + DEMAND dataset were 3.30, 0.95, 4.51, and 3.94, respectively).
SmartHand: Towards Embedded Smart Hands for Prosthetic and Robotic Applications
Jul 23, 2021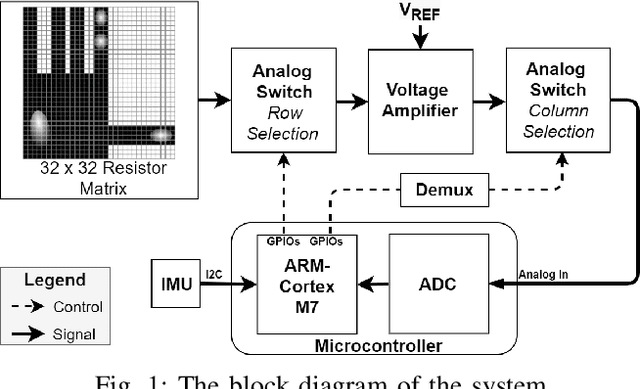
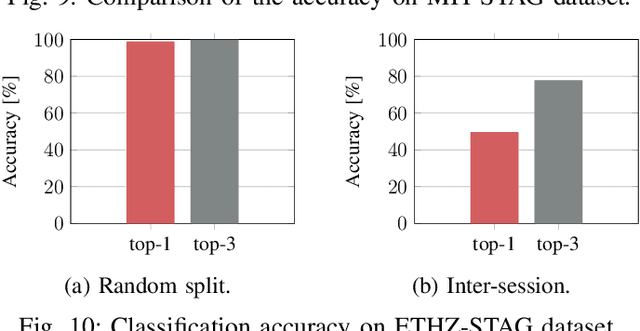


The sophisticated sense of touch of the human hand significantly contributes to our ability to safely, efficiently, and dexterously manipulate arbitrary objects in our environment. Robotic and prosthetic devices lack refined, tactile feedback from their end-effectors, leading to counterintuitive and complex control strategies. To address this lack, tactile sensors have been designed and developed, but they often offer an insufficient spatial and temporal resolution. This paper focuses on overcoming these issues by designing a smart embedded system, called SmartHand, enabling the acquisition and real-time processing of high-resolution tactile information from a hand-shaped multi-sensor array for prosthetic and robotic applications. We acquire a new tactile dataset consisting of 340,000 frames while interacting with 16 everyday objects and the empty hand, i.e., a total of 17 classes. The design of the embedded system minimizes response latency in classification, by deploying a small yet accurate convolutional neural network on a high-performance ARM Cortex-M7 microcontroller. Compared to related work, our model requires one order of magnitude less memory and 15.6x fewer computations while achieving similar inter-session accuracy and up to 98.86% and 99.83% top-1 and top-3 cross-validation accuracy, respectively. Experimental results show a total power consumption of 505mW and a latency of only 100ms.
Spatio-thermal depth correction of RGB-D sensors based on Gaussian Processes in real-time
Jul 01, 2019Commodity RGB-D sensors capture color images along with dense pixel-wise depth information in real-time. Typical RGB-D sensors are provided with a factory calibration and exhibit erratic depth readings due to coarse calibration values, ageing and thermal influence effects. This limits their applicability in computer vision and robotics. We propose a novel method to accurately calibrate depth considering spatial and thermal influences jointly. Our work is based on Gaussian Process Regression in a four dimensional Cartesian and thermal domain. We propose to leverage modern GPUs for dense depth map correction in real-time. For reproducibility we make our dataset and source code publicly available.
Efficacy of BERT embeddings on predicting disaster from Twitter data
Aug 08, 2021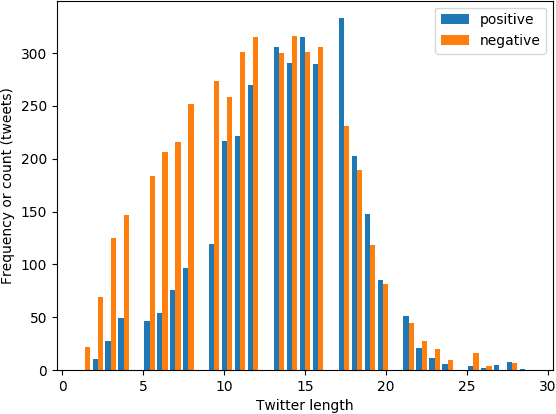
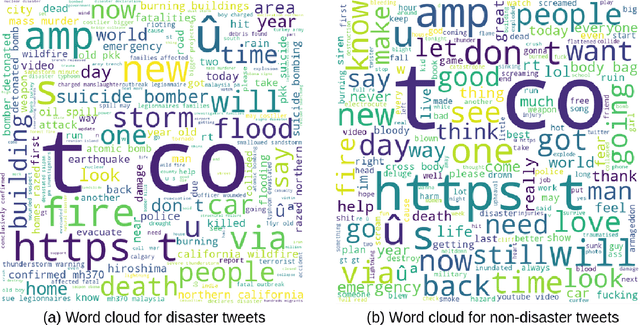
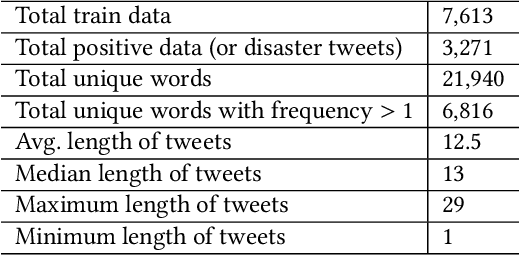
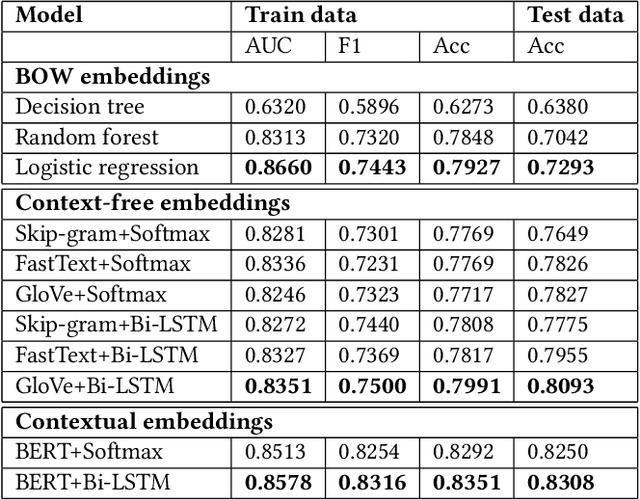
Social media like Twitter provide a common platform to share and communicate personal experiences with other people. People often post their life experiences, local news, and events on social media to inform others. Many rescue agencies monitor this type of data regularly to identify disasters and reduce the risk of lives. However, it is impossible for humans to manually check the mass amount of data and identify disasters in real-time. For this purpose, many research works have been proposed to present words in machine-understandable representations and apply machine learning methods on the word representations to identify the sentiment of a text. The previous research methods provide a single representation or embedding of a word from a given document. However, the recent advanced contextual embedding method (BERT) constructs different vectors for the same word in different contexts. BERT embeddings have been successfully used in different natural language processing (NLP) tasks, yet there is no concrete analysis of how these representations are helpful in disaster-type tweet analysis. In this research work, we explore the efficacy of BERT embeddings on predicting disaster from Twitter data and compare these to traditional context-free word embedding methods (GloVe, Skip-gram, and FastText). We use both traditional machine learning methods and deep learning methods for this purpose. We provide both quantitative and qualitative results for this study. The results show that the BERT embeddings have the best results in disaster prediction task than the traditional word embeddings. Our codes are made freely accessible to the research community.
AGGGEN: Ordering and Aggregating while Generating
Jun 10, 2021We present AGGGEN (pronounced 'again'), a data-to-text model which re-introduces two explicit sentence planning stages into neural data-to-text systems: input ordering and input aggregation. In contrast to previous work using sentence planning, our model is still end-to-end: AGGGEN performs sentence planning at the same time as generating text by learning latent alignments (via semantic facts) between input representation and target text. Experiments on the WebNLG and E2E challenge data show that by using fact-based alignments our approach is more interpretable, expressive, robust to noise, and easier to control, while retaining the advantages of end-to-end systems in terms of fluency. Our code is available at https://github.com/XinnuoXu/AggGen.
Exploiting temporal consistency for real-time video depth estimation
Aug 10, 2019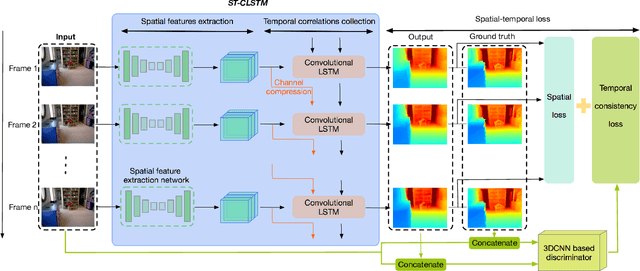
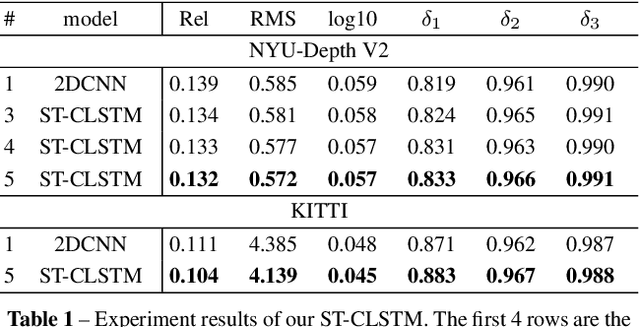
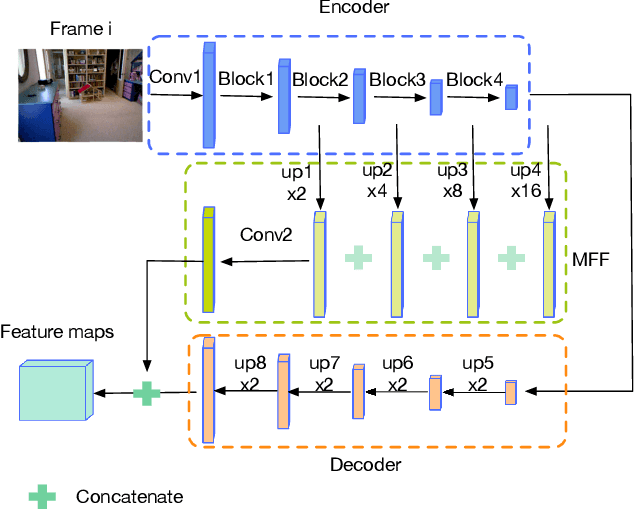
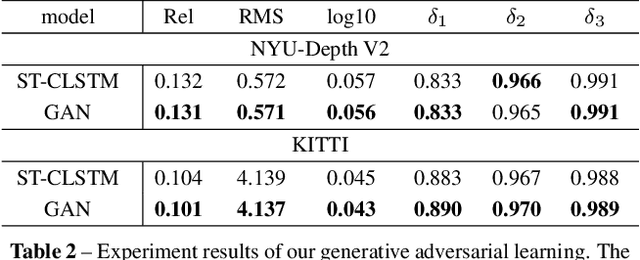
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM
A Deep Learning Approach for Active Anomaly Detection of Extragalactic Transients
Mar 22, 2021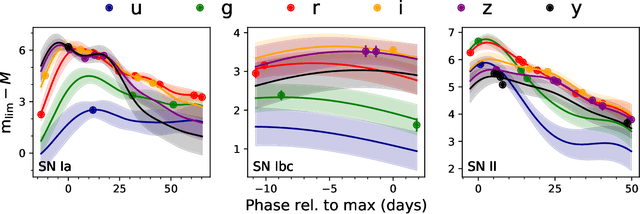
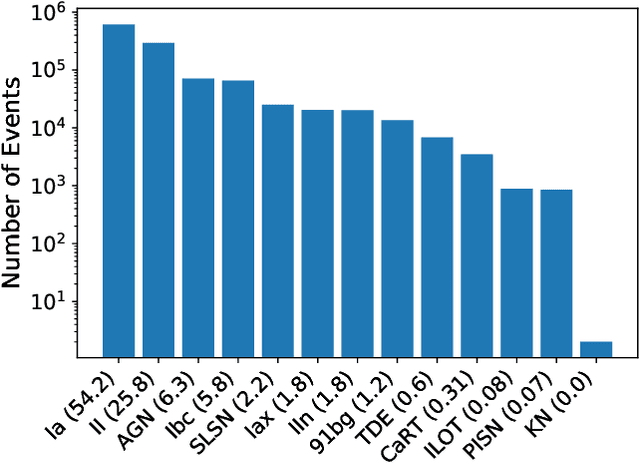
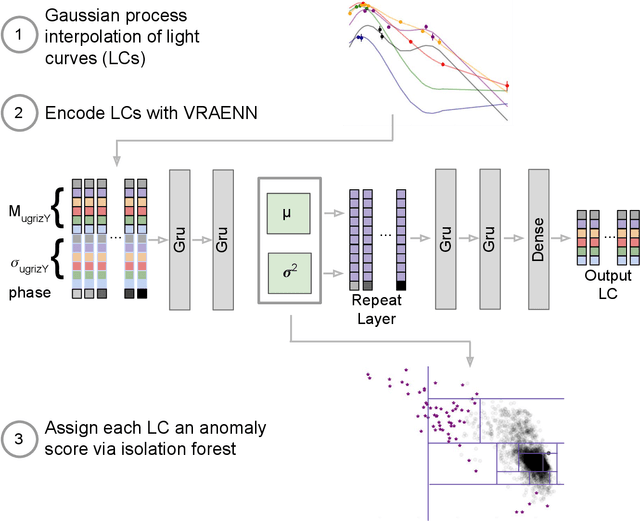
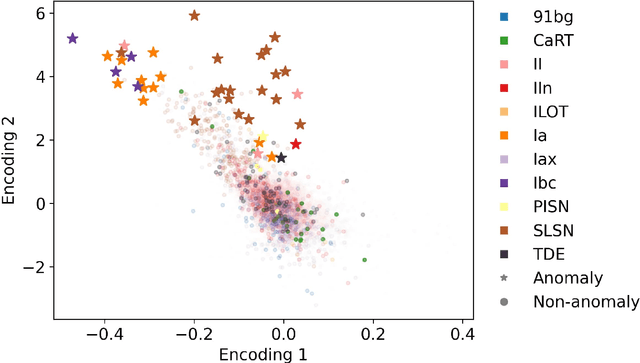
There is a shortage of multi-wavelength and spectroscopic followup capabilities given the number of transient and variable astrophysical events discovered through wide-field, optical surveys such as the upcoming Vera C. Rubin Observatory. From the haystack of potential science targets, astronomers must allocate scarce resources to study a selection of needles in real time. Here we present a variational recurrent autoencoder neural network to encode simulated Rubin Observatory extragalactic transient events using 1% of the PLAsTiCC dataset to train the autoencoder. Our unsupervised method uniquely works with unlabeled, real time, multivariate and aperiodic data. We rank 1,129,184 events based on an anomaly score estimated using an isolation forest. We find that our pipeline successfully ranks rarer classes of transients as more anomalous. Using simple cuts in anomaly score and uncertainty, we identify a pure (~95% pure) sample of rare transients (i.e., transients other than Type Ia, Type II and Type Ibc supernovae) including superluminous and pair-instability supernovae. Finally, our algorithm is able to identify these transients as anomalous well before peak, enabling real-time follow up studies in the era of the Rubin Observatory.