 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RRULES: An improvement of the RULES rule-based classifier
Jun 14, 2021

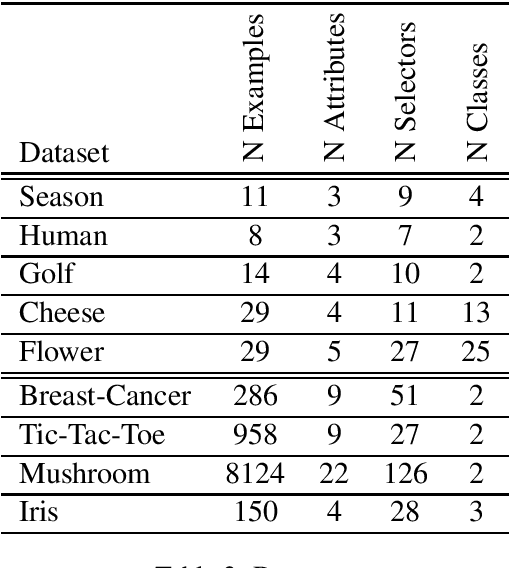
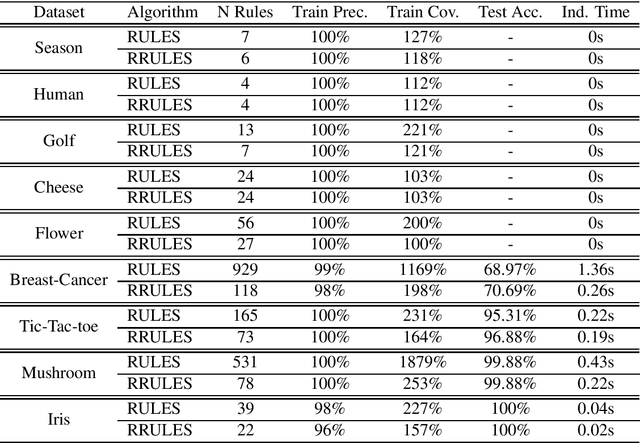
RRULES is presented as an improvement and optimization over RULES, a simple inductive learning algorithm for extracting IF-THEN rules from a set of training examples. RRULES optimizes the algorithm by implementing a more effective mechanism to detect irrelevant rules, at the same time that checks the stopping conditions more often. This results in a more compact rule set containing more general rules which prevent overfitting the training set and obtain a higher test accuracy. Moreover, the results show that RRULES outperforms the original algorithm by reducing the coverage rate up to a factor of 7 while running twice or three times faster consistently over several datasets.
baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
Apr 24, 2021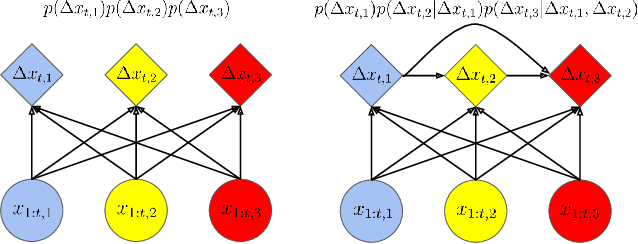
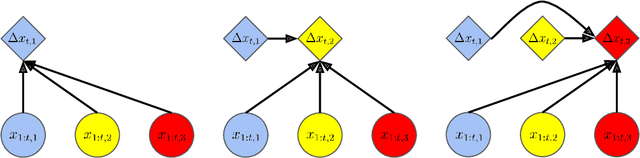
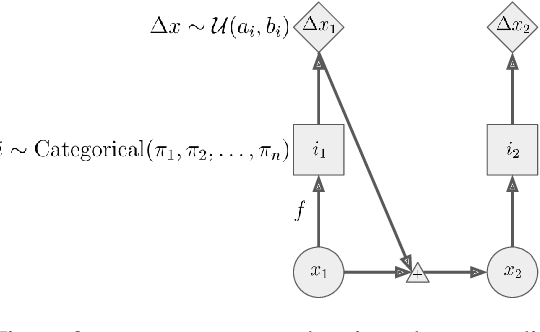
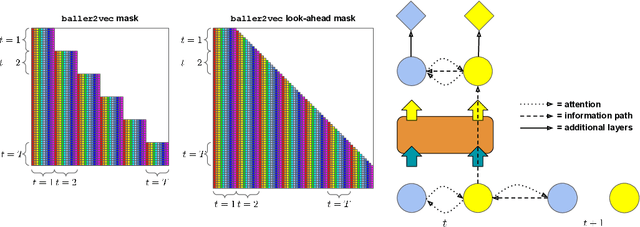
In many multi-agent spatiotemporal systems, the agents are under the influence of shared, unobserved variables (e.g., the play a team is executing in a game of basketball). As a result, the trajectories of the agents are often statistically dependent at any given time step; however, almost universally, multi-agent models implicitly assume the agents' trajectories are statistically independent at each time step. In this paper, we introduce baller2vec++, a multi-entity Transformer that can effectively model coordinated agents. Specifically, baller2vec++ applies a specially designed self-attention mask to a mixture of location and "look-ahead" trajectory sequences to learn the distributions of statistically dependent agent trajectories. We show that, unlike baller2vec (baller2vec++'s predecessor), baller2vec++ can learn to emulate the behavior of perfectly coordinated agents in a simulated toy dataset. Additionally, when modeling the trajectories of professional basketball players, baller2vec++ outperforms baller2vec by a wide margin.
Few-Shot Action Localization without Knowing Boundaries
Jun 08, 2021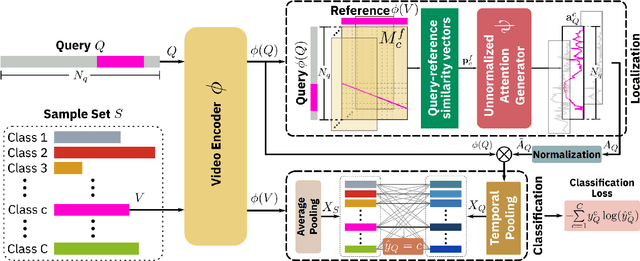

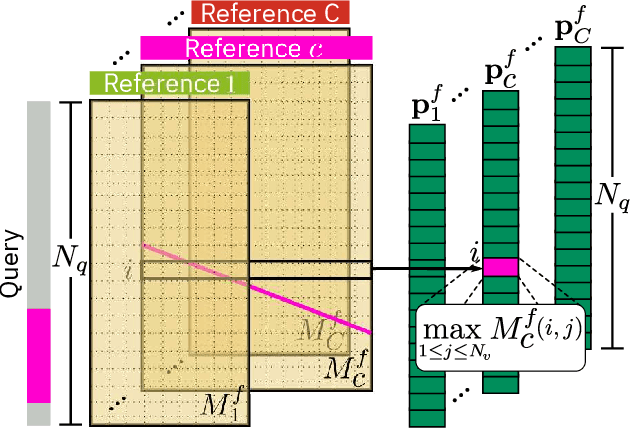
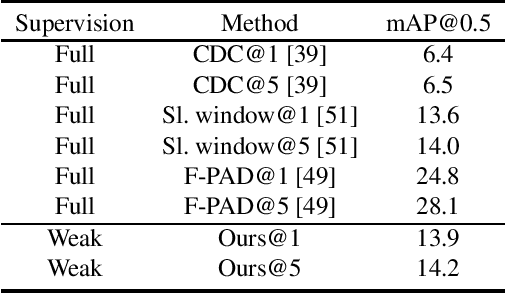
Learning to localize actions in long, cluttered, and untrimmed videos is a hard task, that in the literature has typically been addressed assuming the availability of large amounts of annotated training samples for each class -- either in a fully-supervised setting, where action boundaries are known, or in a weakly-supervised setting, where only class labels are known for each video. In this paper, we go a step further and show that it is possible to learn to localize actions in untrimmed videos when a) only one/few trimmed examples of the target action are available at test time, and b) when a large collection of videos with only class label annotation (some trimmed and some weakly annotated untrimmed ones) are available for training; with no overlap between the classes used during training and testing. To do so, we propose a network that learns to estimate Temporal Similarity Matrices (TSMs) that model a fine-grained similarity pattern between pairs of videos (trimmed or untrimmed), and uses them to generate Temporal Class Activation Maps (TCAMs) for seen or unseen classes. The TCAMs serve as temporal attention mechanisms to extract video-level representations of untrimmed videos, and to temporally localize actions at test time. To the best of our knowledge, we are the first to propose a weakly-supervised, one/few-shot action localization network that can be trained in an end-to-end fashion. Experimental results on THUMOS14 and ActivityNet1.2 datasets, show that our method achieves performance comparable or better to state-of-the-art fully-supervised, few-shot learning methods.
Learning in Modal Space: Solving Time-Dependent Stochastic PDEs Using Physics-Informed Neural Networks
May 03, 2019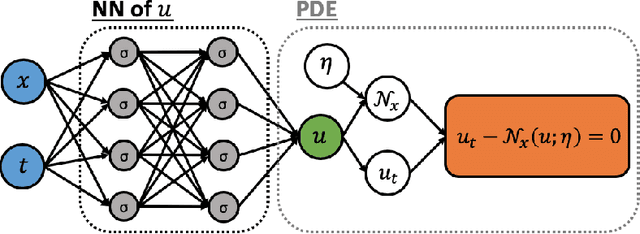
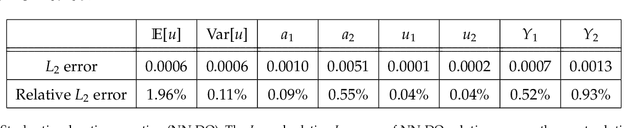
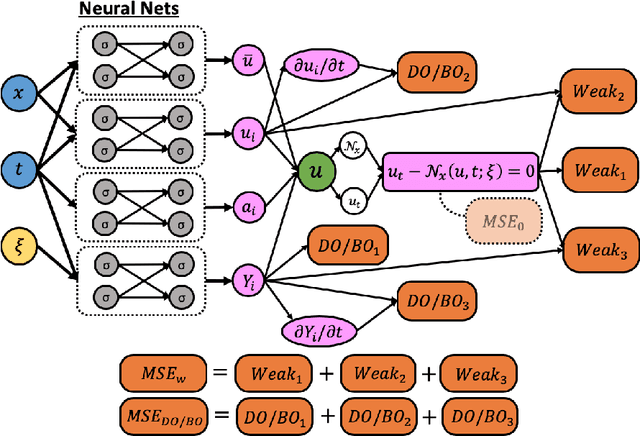

One of the open problems in scientific computing is the long-time integration of nonlinear stochastic partial differential equations (SPDEs). We address this problem by taking advantage of recent advances in scientific machine learning and the dynamically orthogonal (DO) and bi-orthogonal (BO) methods for representing stochastic processes. Specifically, we propose two new Physics-Informed Neural Networks (PINNs) for solving time-dependent SPDEs, namely the NN-DO/BO methods, which incorporate the DO/BO constraints into the loss function with an implicit form instead of generating explicit expressions for the temporal derivatives of the DO/BO modes. Hence, the proposed methods overcome some of the drawbacks of the original DO/BO methods: we do not need the assumption that the covariance matrix of the random coefficients is invertible as in the original DO method, and we can remove the assumption of no eigenvalue crossing as in the original BO method. Moreover, the NN-DO/BO methods can be used to solve time-dependent stochastic inverse problems with the same formulation and computational complexity as for forward problems. We demonstrate the capability of the proposed methods via several numerical examples: (1) A linear stochastic advection equation with deterministic initial condition where the original DO/BO method would fail; (2) Long-time integration of the stochastic Burgers' equation with many eigenvalue crossings during the whole time evolution where the original BO method fails. (3) Nonlinear reaction diffusion equation: we consider both the forward and the inverse problem, including noisy initial data, to investigate the flexibility of the NN-DO/BO methods in handling inverse and mixed type problems. Taken together, these simulation results demonstrate that the NN-DO/BO methods can be employed to effectively quantify uncertainty propagation in a wide range of physical problems.
Sleep syndromes onset detection based on automatic sleep staging algorithm
Jul 07, 2021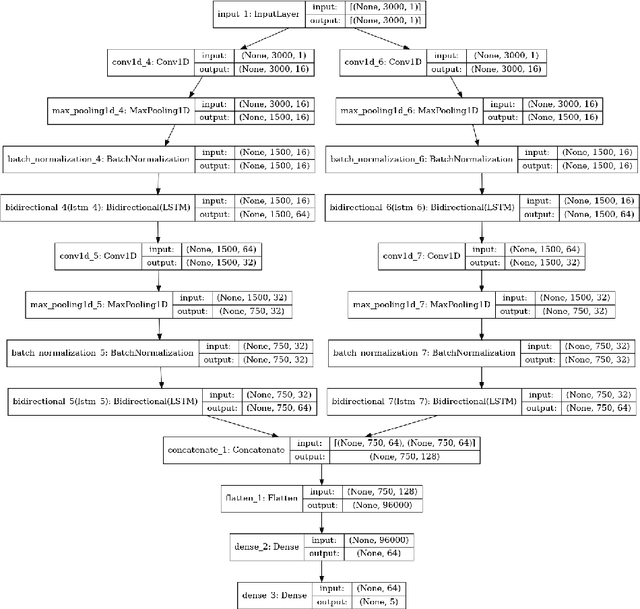
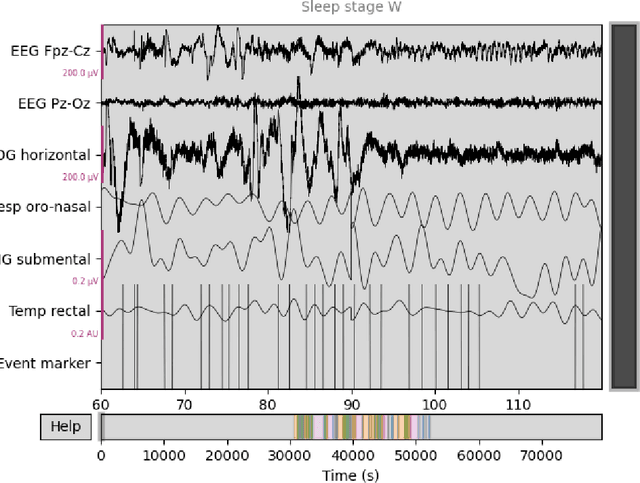
In this paper, we propose a novel method and a practical approach to predicting early onsets of sleep syndromes, including restless leg syndrome, insomnia, based on an algorithm that is comprised of two modules. A Fast Fourier Transform is applied to 30 seconds long epochs of EEG recordings to provide localized time-frequency information, and a deep convolutional LSTM neural network is trained for sleep stage classification. Automating sleep stages detection from EEG data offers great potential to tackling sleep irregularities on a daily basis. Thereby, a novel approach for sleep stage classification is proposed which combines the best of signal processing and statistics. In this study, we used the PhysioNet Sleep European Data Format (EDF) Database. The code evaluation showed impressive results, reaching an accuracy of 86.43, precision of 77.76, recall of 93,32, F1-score of 89.12 with the final mean false error loss of 0.09.
Improving Accuracy of Permutation DAG Search using Best Order Score Search
Aug 17, 2021The Sparsest Permutation (SP) algorithm is accurate but limited to about 9 variables in practice; the Greedy Sparest Permutation (GSP) algorithm is faster but less weak theoretically. A compromise can be given, the Best Order Score Search, which gives results as accurate as SP but for much larger and denser graphs. BOSS (Best Order Score Search) is more accurate for two reason: (a) It assumes the "brute faithfuness" assumption, which is weaker than faithfulness, and (b) it uses a different traversal of permutations than the depth first traversal used by GSP, obtained by taking each variable in turn and moving it to the position in the permutation that optimizes the model score. Results are given comparing BOSS to several related papers in the literature in terms of performance, for linear, Gaussian data. In all cases, with the proper parameter settings, accuracy of BOSS is lifted considerably with respect to competing approaches. In configurations tested, models with 60 variables are feasible with large samples out to about an average degree of 12 in reasonable time, with near-perfect accuracy, and sparse models with an average degree of 4 are feasible out to about 300 variables on a laptop, again with near-perfect accuracy. Mixed continuous discrete and all-discrete datasets were also tested. The mixed data analysis showed advantage for BOSS over GES more apparent at higher depths with the same score; the discrete data analysis showed a very small advantage for BOSS over GES with the same score, perhaps not enough to prefer it.
EA-LSTM: Evolutionary Attention-based LSTM for Time Series Prediction
Nov 09, 2018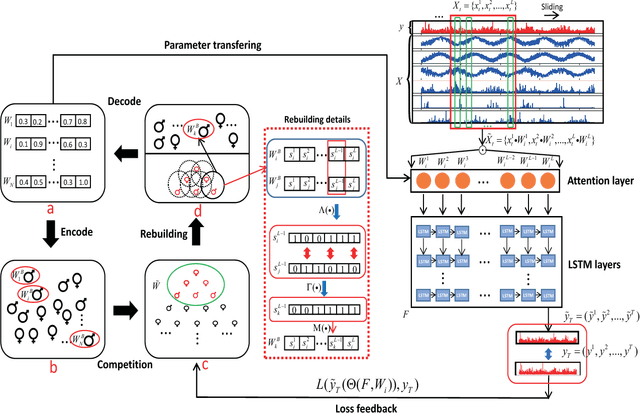

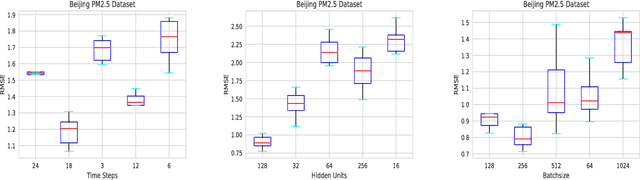
Time series prediction with deep learning methods, especially long short-term memory neural networks (LSTMs), have scored significant achievements in recent years. Despite the fact that the LSTMs can help to capture long-term dependencies, its ability to pay different degree of attention on sub-window feature within multiple time-steps is insufficient. To address this issue, an evolutionary attention-based LSTM training with competitive random search is proposed for multivariate time series prediction. By transferring shared parameters, an evolutionary attention learning approach is introduced to the LSTMs model. Thus, like that for biological evolution, the pattern for importance-based attention sampling can be confirmed during temporal relationship mining. To refrain from being trapped into partial optimization like traditional gradient-based methods, an evolutionary computation inspired competitive random search method is proposed, which can well configure the parameters in the attention layer. Experimental results have illustrated that the proposed model can achieve competetive prediction performance compared with other baseline methods.
Segmentation of Shoulder Muscle MRI Using a New Region and Edge based Deep Auto-Encoder
Aug 26, 2021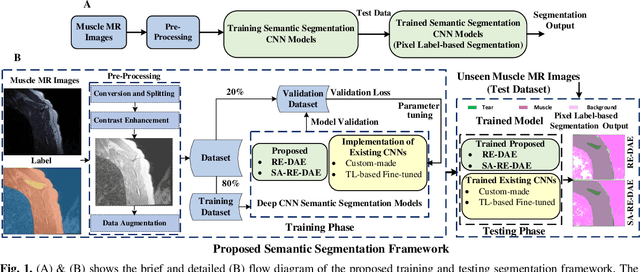
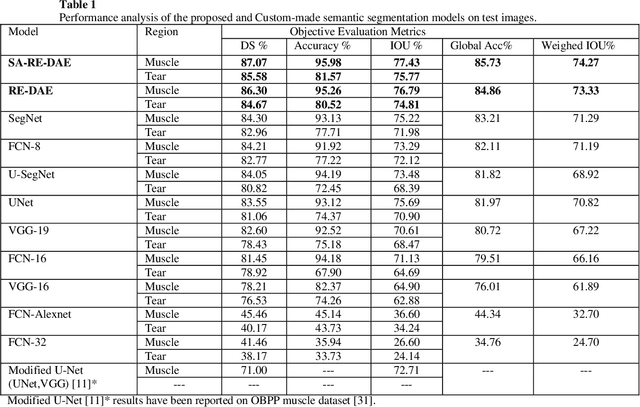
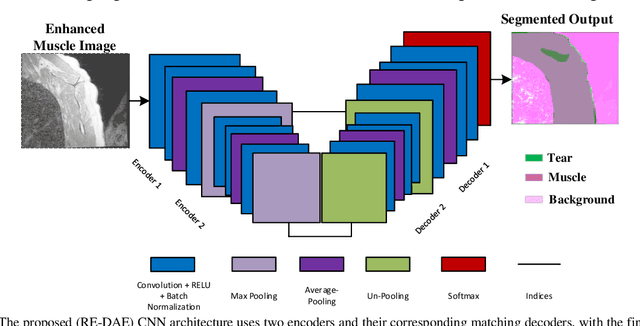
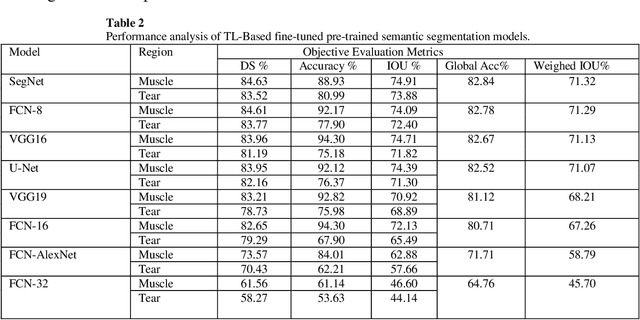
Automatic segmentation of shoulder muscle MRI is challenging due to the high variation in muscle size, shape, texture, and spatial position of tears. Manual segmentation of tear and muscle portion is hard, time-consuming, and subjective to pathological expertise. This work proposes a new Region and Edge-based Deep Auto-Encoder (RE-DAE) for shoulder muscle MRI segmentation. The proposed RE-DAE harmoniously employs average and max-pooling operation in the encoder and decoder blocks of the Convolutional Neural Network (CNN). Region-based segmentation incorporated in the Deep Auto-Encoder (DAE) encourages the network to extract smooth and homogenous regions. In contrast, edge-based segmentation tries to learn the boundary and anatomical information. These two concepts, systematically combined in a DAE, generate a discriminative and sparse hybrid feature space (exploiting both region homogeneity and boundaries). Moreover, the concept of static attention is exploited in the proposed RE-DAE that helps in effectively learning the tear region. The performances of the proposed MRI segmentation based DAE architectures have been tested using a 3D MRI shoulder muscle dataset using the hold-out cross-validation technique. The MRI data has been collected from the Korea University Anam Hospital, Seoul, South Korea. Experimental comparisons have been conducted by employing innovative custom-made and existing pre-trained CNN architectures both using transfer learning and fine-tuning. Objective evaluation on the muscle datasets using the proposed SA-RE-DAE showed a dice similarity of 85.58% and 87.07%, an accuracy of 81.57% and 95.58% for tear and muscle regions, respectively. The high visual quality and the objective result suggest that the proposed SA-RE-DAE is able to correctly segment tear and muscle regions in shoulder muscle MRI for better clinical decisions.
Structured World Belief for Reinforcement Learning in POMDP
Jul 19, 2021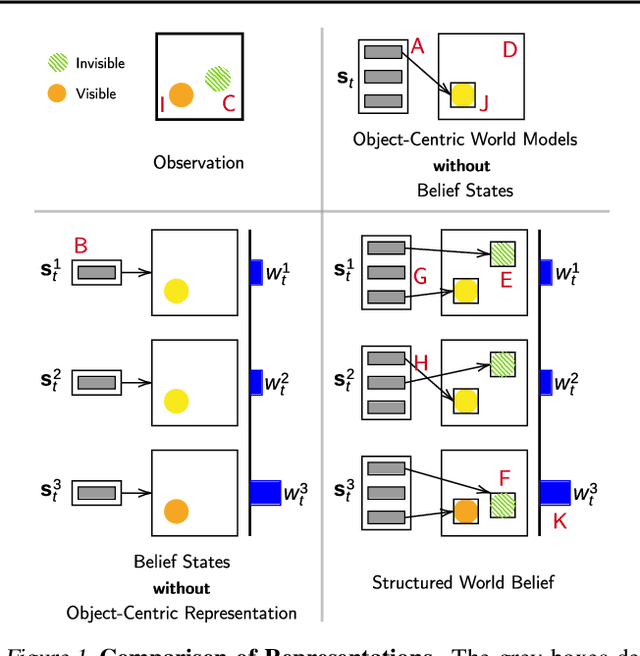
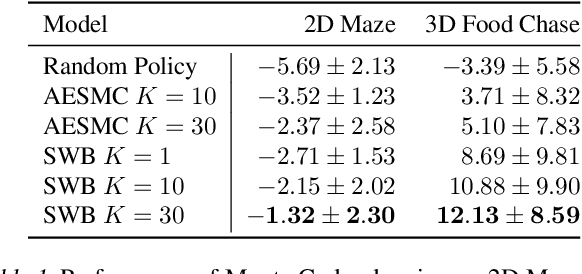
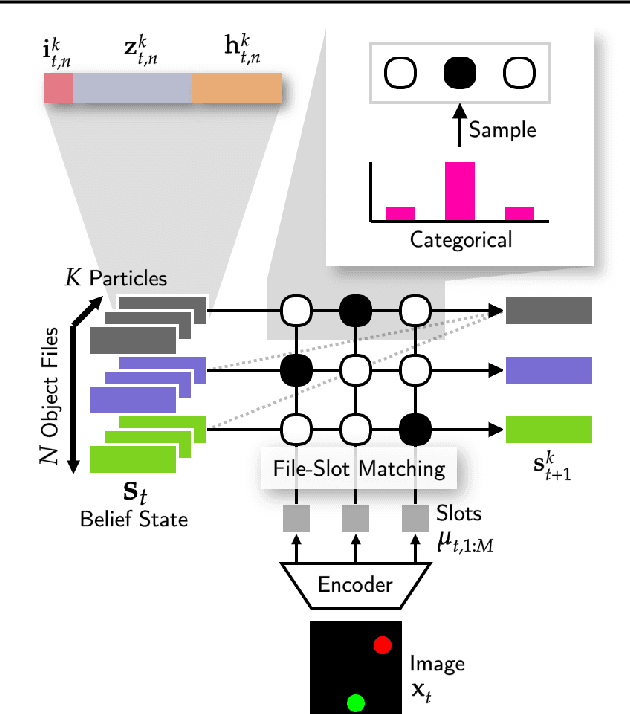

Object-centric world models provide structured representation of the scene and can be an important backbone in reinforcement learning and planning. However, existing approaches suffer in partially-observable environments due to the lack of belief states. In this paper, we propose Structured World Belief, a model for learning and inference of object-centric belief states. Inferred by Sequential Monte Carlo (SMC), our belief states provide multiple object-centric scene hypotheses. To synergize the benefits of SMC particles with object representations, we also propose a new object-centric dynamics model that considers the inductive bias of object permanence. This enables tracking of object states even when they are invisible for a long time. To further facilitate object tracking in this regime, we allow our model to attend flexibly to any spatial location in the image which was restricted in previous models. In experiments, we show that object-centric belief provides a more accurate and robust performance for filtering and generation. Furthermore, we show the efficacy of structured world belief in improving the performance of reinforcement learning, planning and supervised reasoning.
HOTR: End-to-End Human-Object Interaction Detection with Transformers
Apr 28, 2021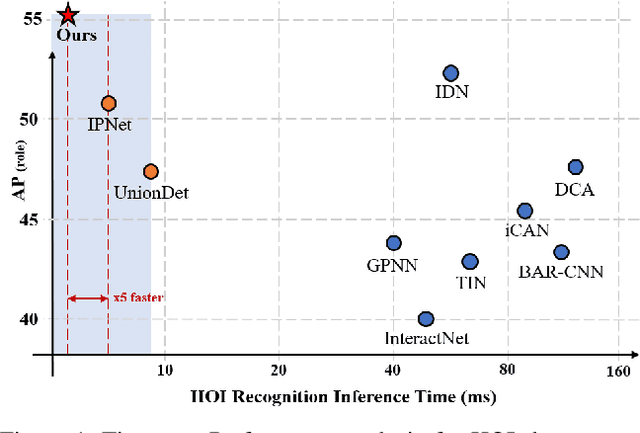
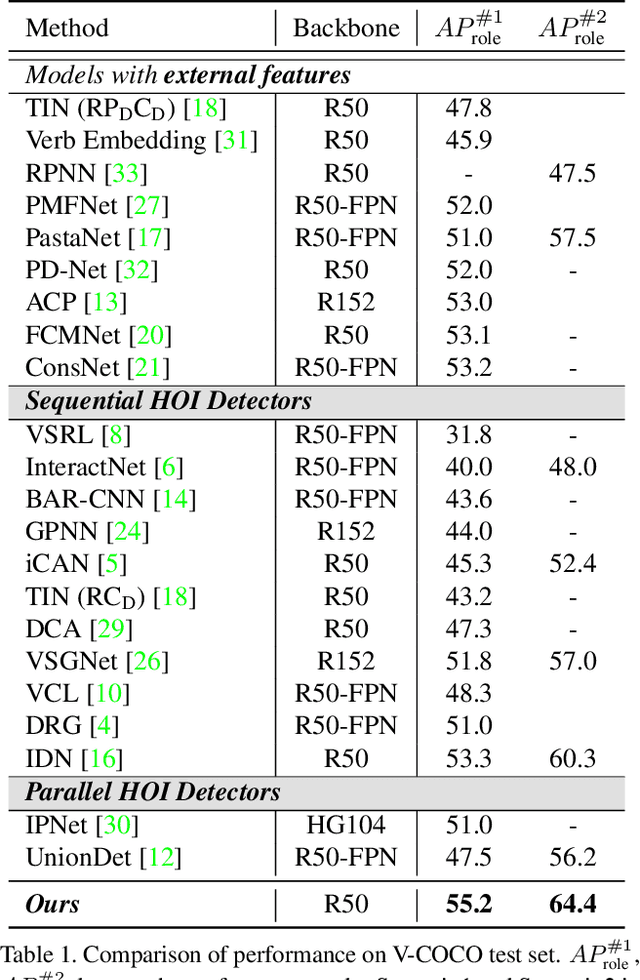
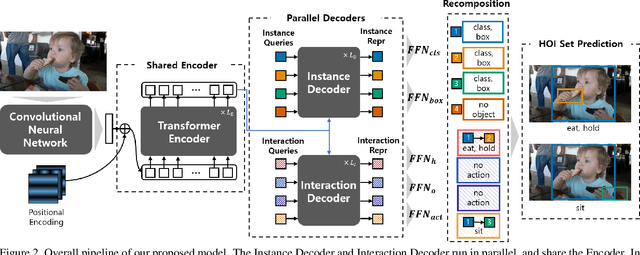
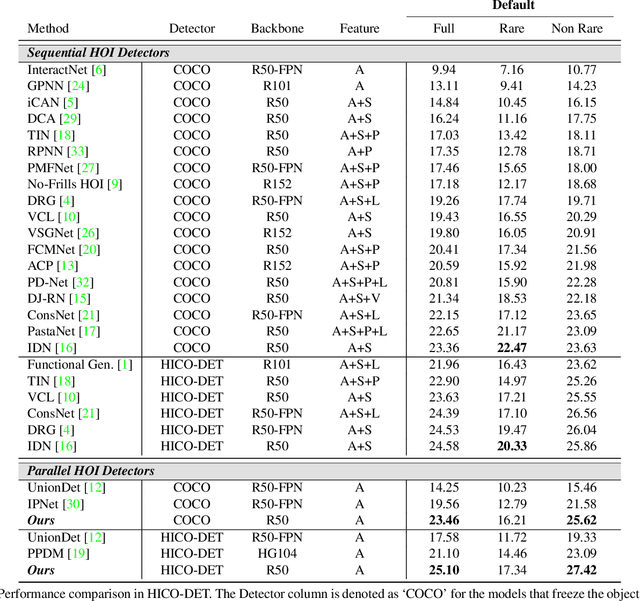
Human-Object Interaction (HOI) detection is a task of identifying "a set of interactions" in an image, which involves the i) localization of the subject (i.e., humans) and target (i.e., objects) of interaction, and ii) the classification of the interaction labels. Most existing methods have indirectly addressed this task by detecting human and object instances and individually inferring every pair of the detected instances. In this paper, we present a novel framework, referred to by HOTR, which directly predicts a set of <human, object, interaction> triplets from an image based on a transformer encoder-decoder architecture. Through the set prediction, our method effectively exploits the inherent semantic relationships in an image and does not require time-consuming post-processing which is the main bottleneck of existing methods. Our proposed algorithm achieves the state-of-the-art performance in two HOI detection benchmarks with an inference time under 1 ms after object detection.