 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Modeling of User Preferences for Stable Recommendations
Apr 11, 2021

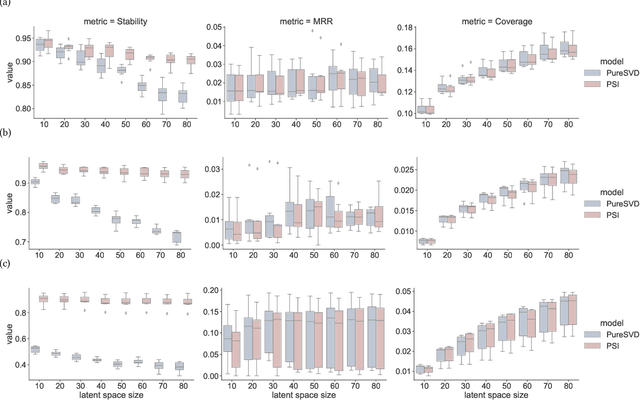
In domains where users tend to develop long-term preferences that do not change too frequently, the stability of recommendations is an important factor of the perceived quality of a recommender system. In such cases, unstable recommendations may lead to poor personalization experience and distrust, driving users away from a recommendation service. We propose an incremental learning scheme that mitigates such problems through the dynamic modeling approach. It incorporates a generalized matrix form of a partial differential equation integrator that yields a dynamic low-rank approximation of time-dependent matrices representing user preferences. The scheme allows extending the famous PureSVD approach to time-aware settings and significantly improves its stability without sacrificing the accuracy in standard top-$n$ recommendations tasks.
Experimental Study of Outdoor UAV Localization and Tracking using Passive RF Sensing
Aug 17, 2021

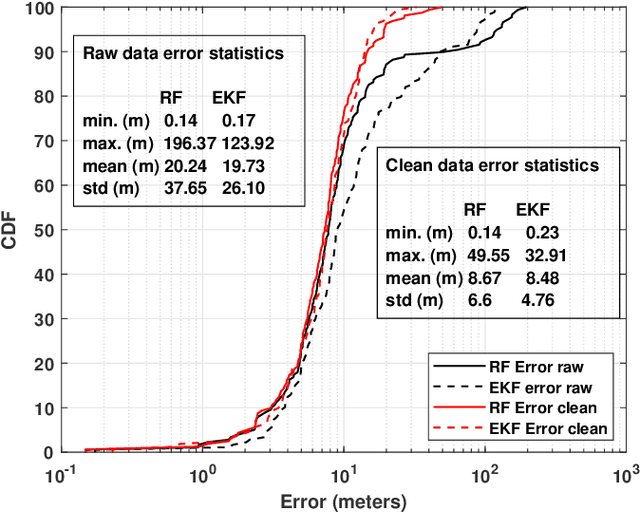
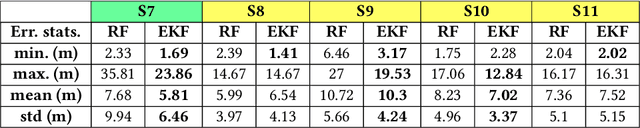
Extensive use of unmanned aerial vehicles (UAVs) is expected to raise privacy and security concerns among individuals and communities. In this context, the detection and localization of UAVs will be critical for maintaining safe and secure airspace in the future. In this work, Keysight N6854A radio frequency (RF) sensors are used to detect and locate a UAV by passively monitoring the signals emitted from the UAV. First, the Keysight sensor detects the UAV by comparing the received RF signature with various other UAVs' RF signatures in the Keysight database using an envelope detection algorithm. Afterward, time difference of arrival (TDoA) based localization is performed by a central controller using the sensor data, and the drone is localized with some error. To mitigate the localization error, implementation of an extended Kalman filter~(EKF) is proposed in this study. The performance of the proposed approach is evaluated on a realistic experimental dataset. EKF requires basic assumptions on the type of motion throughout the trajectory, i.e., the movement of the object is assumed to fit some motion model~(MM) such as constant velocity (CV), constant acceleration (CA), and constant turn (CT). In the experiments, an arbitrary trajectory is followed, therefore it is not feasible to fit the whole trajectory into a single MM. Consequently, the trajectory is segmented into sub-parts and a different MM is assumed in each segment while building the EKF model. Simulation results demonstrate an improvement in error statistics when EKF is used if the MM assumption aligns with the real motion.
When Liebig's Barrel Meets Facial Landmark Detection: A Practical Model
May 27, 2021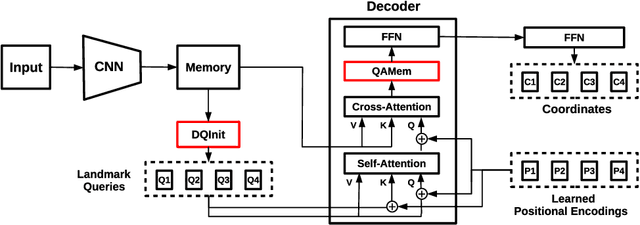
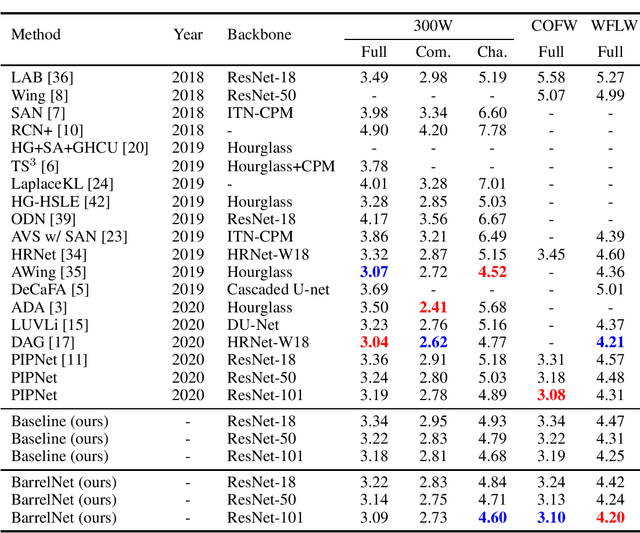
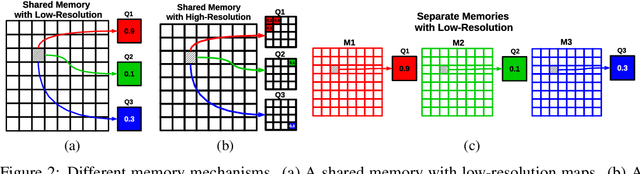
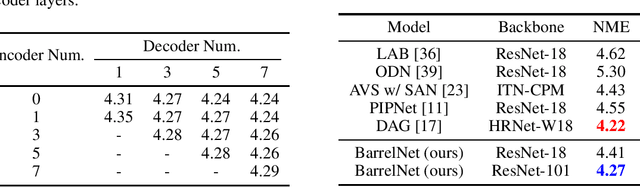
In recent years, significant progress has been made in the research of facial landmark detection. However, few prior works have thoroughly discussed about models for practical applications. Instead, they often focus on improving a couple of issues at a time while ignoring the others. To bridge this gap, we aim to explore a practical model that is accurate, robust, efficient, generalizable, and end-to-end trainable at the same time. To this end, we first propose a baseline model equipped with one transformer decoder as detection head. In order to achieve a better accuracy, we further propose two lightweight modules, namely dynamic query initialization (DQInit) and query-aware memory (QAMem). Specifically, DQInit dynamically initializes the queries of decoder from the inputs, enabling the model to achieve as good accuracy as the ones with multiple decoder layers. QAMem is designed to enhance the discriminative ability of queries on low-resolution feature maps by assigning separate memory values to each query rather than a shared one. With the help of QAMem, our model removes the dependence on high-resolution feature maps and is still able to obtain superior accuracy. Extensive experiments and analysis on three popular benchmarks show the effectiveness and practical advantages of the proposed model. Notably, our model achieves new state of the art on WFLW as well as competitive results on 300W and COFW, while still running at 50+ FPS.
Deep convolutional neural networks for multi-scale time-series classification and application to disruption prediction in fusion devices
Nov 21, 2019
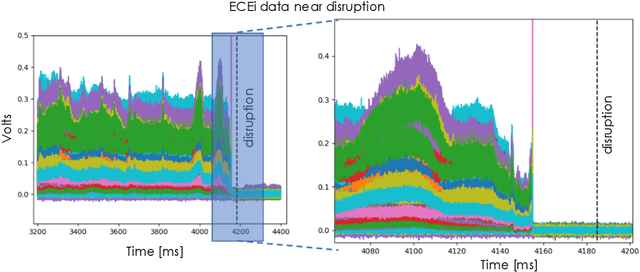
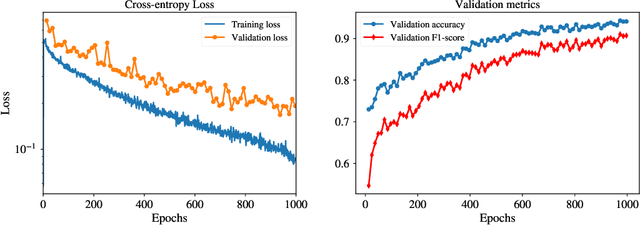
The multi-scale, mutli-physics nature of fusion plasmas makes predicting plasma events challenging. Recent advances in deep convolutional neural network architectures (CNN) utilizing dilated convolutions enable accurate predictions on sequences which have long-range, multi-scale characteristics, such as the time-series generated by diagnostic instruments observing fusion plasmas. Here we apply this neural network architecture to the popular problem of disruption prediction in fusion tokamaks, utilizing raw data from a single diagnostic, the Electron Cyclotron Emission imaging (ECEi) diagnostic from the DIII-D tokamak. ECEi measures a fundamental plasma quantity (electron temperature) with high temporal resolution over the entire plasma discharge, making it sensitive to a number of potential pre-disruptions markers with different temporal and spatial scales. Promising, initial disruption prediction results are obtained training a deep CNN with large receptive field (~30k), achieving an $F_1$-score of ~91% on individual time-slices using only the ECEi data.
RRULES: An improvement of the RULES rule-based classifier
Jun 14, 2021
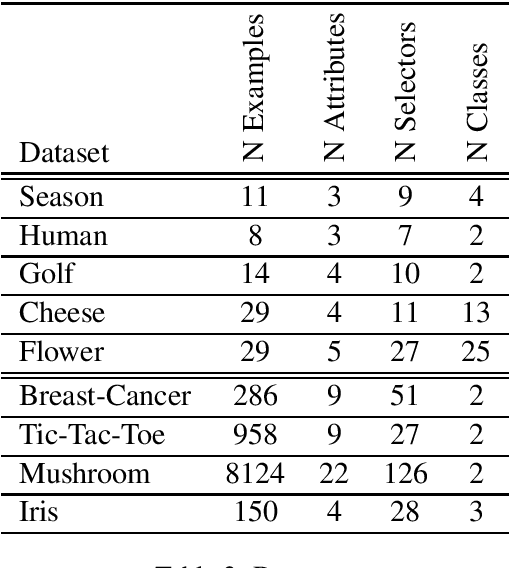
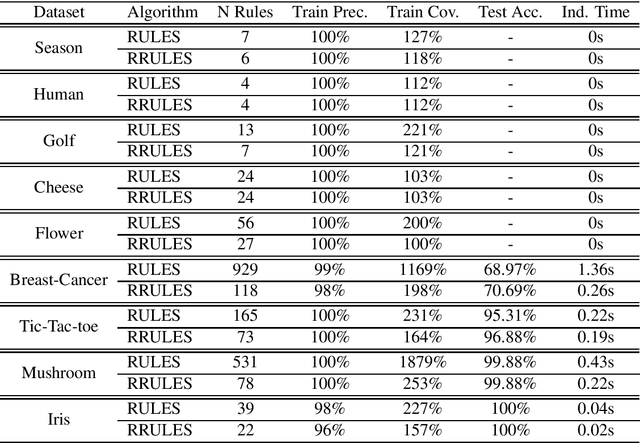
RRULES is presented as an improvement and optimization over RULES, a simple inductive learning algorithm for extracting IF-THEN rules from a set of training examples. RRULES optimizes the algorithm by implementing a more effective mechanism to detect irrelevant rules, at the same time that checks the stopping conditions more often. This results in a more compact rule set containing more general rules which prevent overfitting the training set and obtain a higher test accuracy. Moreover, the results show that RRULES outperforms the original algorithm by reducing the coverage rate up to a factor of 7 while running twice or three times faster consistently over several datasets.
Domain-specific Genetic Algorithm for Multi-tenant DNNAccelerator Scheduling
Apr 28, 2021



As Deep Learning continues to drive a variety of applications in datacenters and HPC, there is a growing trend towards building large accelerators with several sub-accelerator cores/chiplets. This work looks at the problem of supporting multi-tenancy on such accelerators. In particular, we focus on the problem of mapping layers from several DNNs simultaneously on an accelerator. Given the extremely large search space, we formulate the search as an optimization problem and develop a specialized genetic algorithm called G# withcustom operators to enable structured sample-efficient exploration. We quantitatively compare G# with several common heuristics, state-of-the-art optimization methods, and reinforcement learning methods across different accelerator set-tings (large/small accelerators) and different sub-accelerator configurations (homogeneous/heterogeneous), and observeG# can consistently find better solutions. Further, to enable real-time scheduling, we also demonstrate a method to generalize the learnt schedules and transfer them to the next batch of jobs, reducing schedule compute time to near zero.
Streaming Quantiles Algorithms with Small Space and Update Time
Jun 29, 2019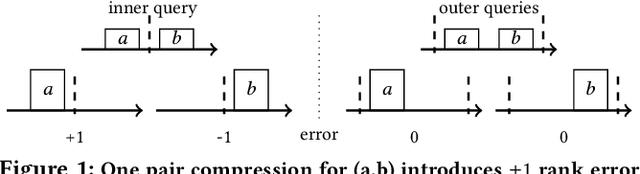
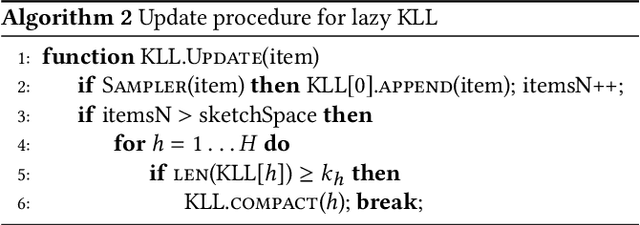

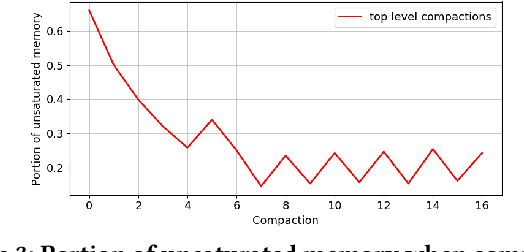
Approximating quantiles and distributions over streaming data has been studied for roughly two decades now. Recently, Karnin, Lang, and Liberty proposed the first asymptotically optimal algorithm for doing so. This manuscript complements their theoretical result by providing a practical variants of their algorithm with improved constants. For a given sketch size, our techniques provably reduce the upper bound on the sketch error by a factor of two. These improvements are verified experimentally. Our modified quantile sketch improves the latency as well by reducing the worst case update time from $O(1/\varepsilon)$ down to $O(\log (1/\varepsilon))$. We also suggest two algorithms for weighted item streams which offer improved asymptotic update times compared to na\"ive extensions. Finally, we provide a specialized data structure for these sketches which reduces both their memory footprints and update times.
Few-Shot Action Localization without Knowing Boundaries
Jun 08, 2021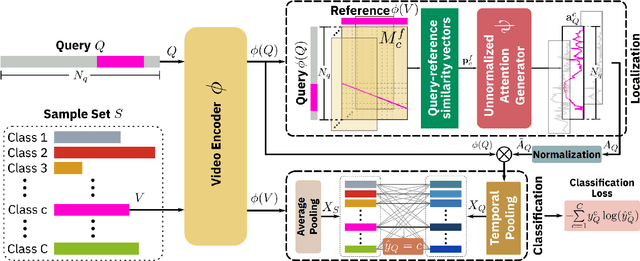

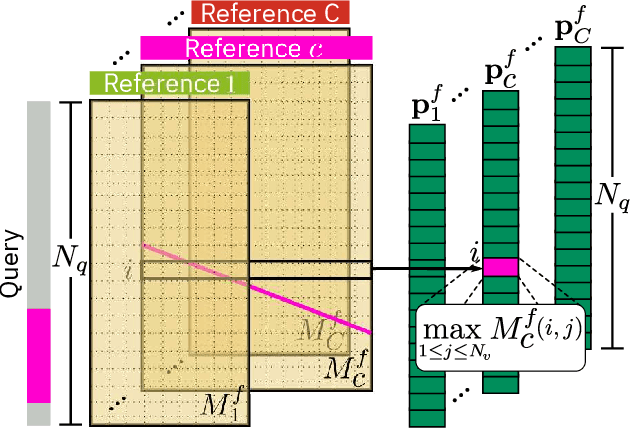
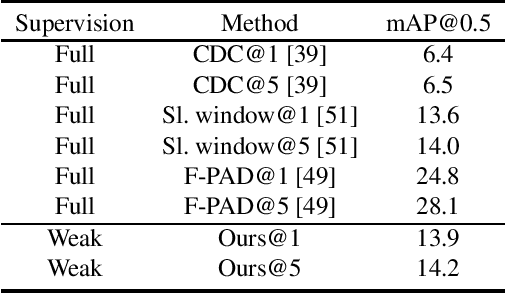
Learning to localize actions in long, cluttered, and untrimmed videos is a hard task, that in the literature has typically been addressed assuming the availability of large amounts of annotated training samples for each class -- either in a fully-supervised setting, where action boundaries are known, or in a weakly-supervised setting, where only class labels are known for each video. In this paper, we go a step further and show that it is possible to learn to localize actions in untrimmed videos when a) only one/few trimmed examples of the target action are available at test time, and b) when a large collection of videos with only class label annotation (some trimmed and some weakly annotated untrimmed ones) are available for training; with no overlap between the classes used during training and testing. To do so, we propose a network that learns to estimate Temporal Similarity Matrices (TSMs) that model a fine-grained similarity pattern between pairs of videos (trimmed or untrimmed), and uses them to generate Temporal Class Activation Maps (TCAMs) for seen or unseen classes. The TCAMs serve as temporal attention mechanisms to extract video-level representations of untrimmed videos, and to temporally localize actions at test time. To the best of our knowledge, we are the first to propose a weakly-supervised, one/few-shot action localization network that can be trained in an end-to-end fashion. Experimental results on THUMOS14 and ActivityNet1.2 datasets, show that our method achieves performance comparable or better to state-of-the-art fully-supervised, few-shot learning methods.
baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
Apr 24, 2021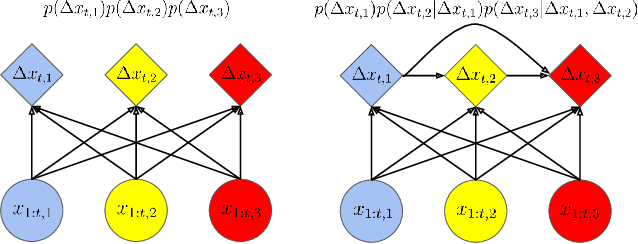
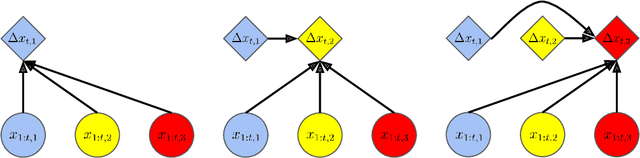
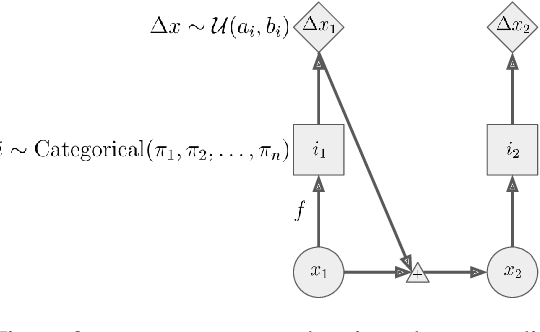
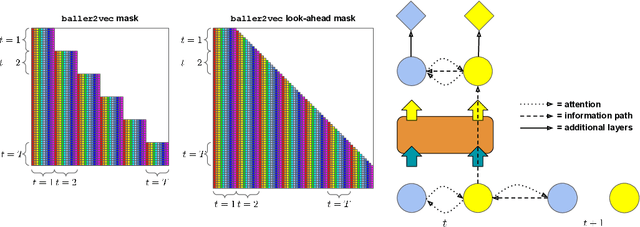
In many multi-agent spatiotemporal systems, the agents are under the influence of shared, unobserved variables (e.g., the play a team is executing in a game of basketball). As a result, the trajectories of the agents are often statistically dependent at any given time step; however, almost universally, multi-agent models implicitly assume the agents' trajectories are statistically independent at each time step. In this paper, we introduce baller2vec++, a multi-entity Transformer that can effectively model coordinated agents. Specifically, baller2vec++ applies a specially designed self-attention mask to a mixture of location and "look-ahead" trajectory sequences to learn the distributions of statistically dependent agent trajectories. We show that, unlike baller2vec (baller2vec++'s predecessor), baller2vec++ can learn to emulate the behavior of perfectly coordinated agents in a simulated toy dataset. Additionally, when modeling the trajectories of professional basketball players, baller2vec++ outperforms baller2vec by a wide margin.
STELA: A Real-Time Scene Text Detector with Learned Anchor
Sep 23, 2019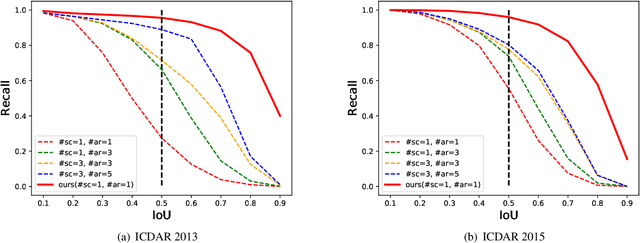
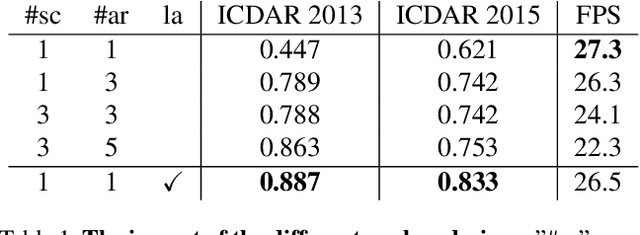
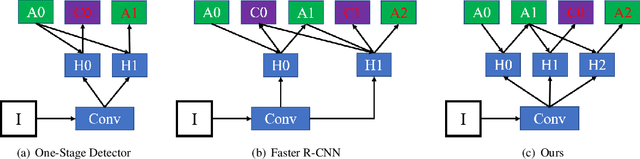
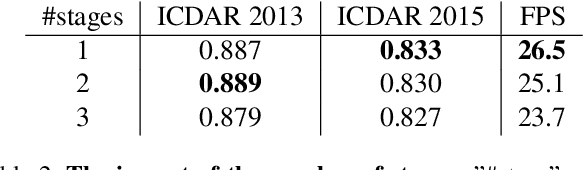
To achieve high coverage of target boxes, a normal strategy of conventional one-stage anchor-based detectors is to utilize multiple priors at each spatial position, especially in scene text detection tasks. In this work, we present a simple and intuitive method for multi-oriented text detection where each location of feature maps only associates with one reference box. The idea is inspired from the twostage R-CNN framework that can estimate the location of objects with any shape by using learned proposals. The aim of our method is to integrate this mechanism into a onestage detector and employ the learned anchor which is obtained through a regression operation to replace the original one into the final predictions. Based on RetinaNet, our method achieves competitive performances on several public benchmarks with a totally real-time efficiency (26:5fps at 800p), which surpasses all of anchor-based scene text detectors. In addition, with less attention on anchor design, we believe our method is easy to be applied on other analogous detection tasks. The code will publicly available at https://github.com/xhzdeng/stela.