 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Temporal Piecewise-Linear Numeric Planning with Lazy Consistency Checking
May 21, 2021
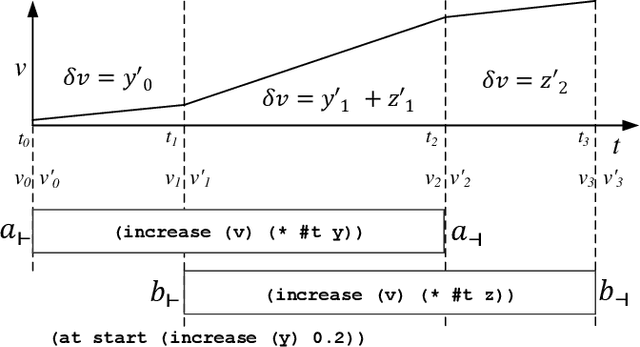

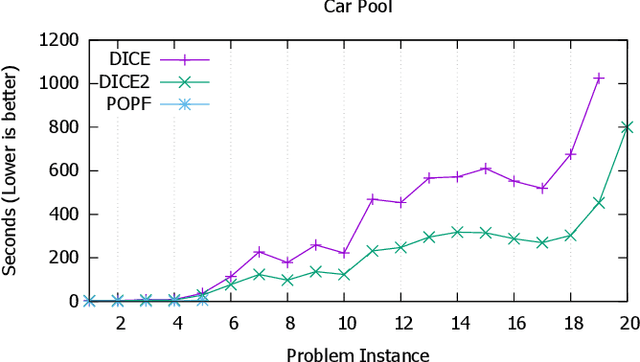
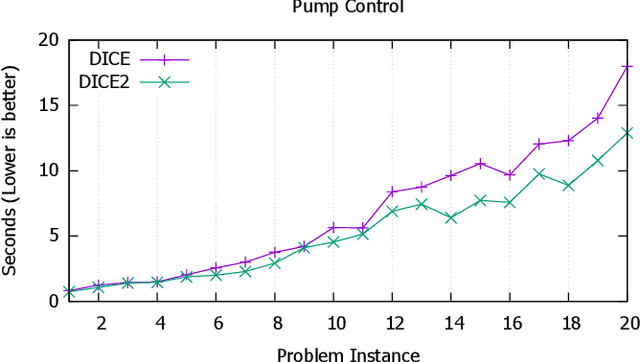
State-of-the-art temporal planners that support continuous numeric effects typically interweave search with scheduling to ensure temporal consistency. If such effects are linear, this process often makes use of Linear Programming (LP) to model the relationship between temporal constraints and conditions on numeric fluents that are subject to duration-dependent effects. While very effective on benchmark domains, this approach does not scale well when solving real-world problems that require long plans. We propose a set of techniques that allow the planner to compute LP consistency checks lazily where possible, significantly reducing the computation time required, thus allowing the planner to solve larger problem instances within an acceptable time-frame. We also propose an algorithm to perform duration-dependent goal checking more selectively. Furthermore, we propose an LP formulation with a smaller footprint that removes linearity restrictions on discrete effects applied within segments of the plan where a numeric fluent is not duration dependent. The effectiveness of these techniques is demonstrated on domains that use a mix of discrete and continuous effects, which is typical of real-world planning problems. The resultant planner is not only more efficient, but outperforms most state-of-the-art temporal-numeric and hybrid planners, in terms of both coverage and scalability.
BigGraphVis: Leveraging Streaming Algorithms and GPU Acceleration for Visualizing Big Graphs
Aug 01, 2021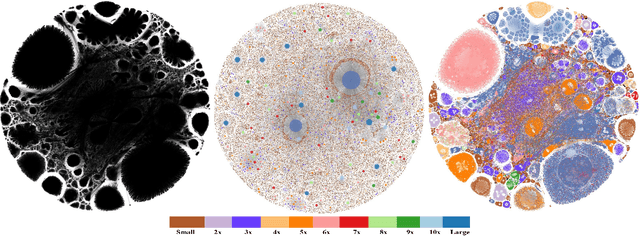
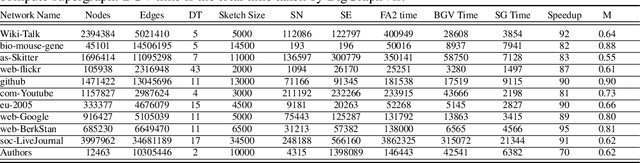
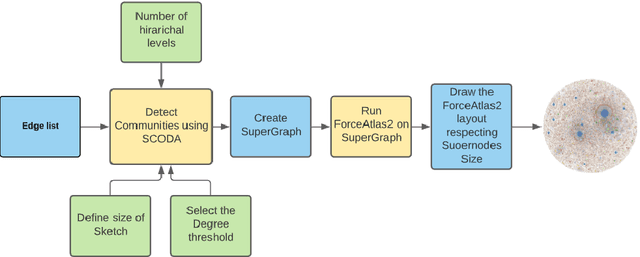
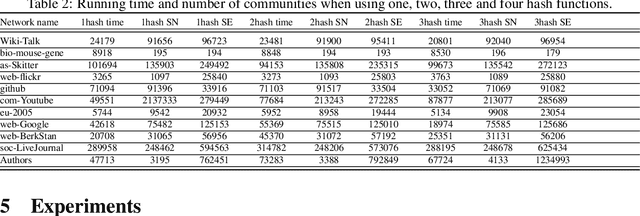
Graph layouts are key to exploring massive graphs. An enormous number of nodes and edges do not allow network analysis software to produce meaningful visualization of the pervasive networks. Long computation time, memory and display limitations encircle the software's ability to explore massive graphs. This paper introduces BigGraphVis, a new parallel graph visualization method that uses GPU parallel processing and community detection algorithm to visualize graph communities. We combine parallelized streaming community detection algorithm and probabilistic data structure to leverage parallel processing of Graphics Processing Unit (GPU). To the best of our knowledge, this is the first attempt to combine the power of streaming algorithms coupled with GPU computing to tackle big graph visualization challenges. Our method extracts community information in a few passes on the edge list, and renders the community structures using the ForceAtlas2 algorithm. Our experiment with massive real-life graphs indicates that about 70 to 95 percent speedup can be achieved by visualizing graph communities, and the visualization appears to be meaningful and reliable. The biggest graph that we examined contains above 3 million nodes and 34 million edges, and the layout computation took about five minutes. We also observed that the BigGraphVis coloring strategy can be successfully applied to produce a more informative ForceAtlas2 layout.
Real-Time Optimal Guidance and Control for Interplanetary Transfers Using Deep Networks
Feb 20, 2020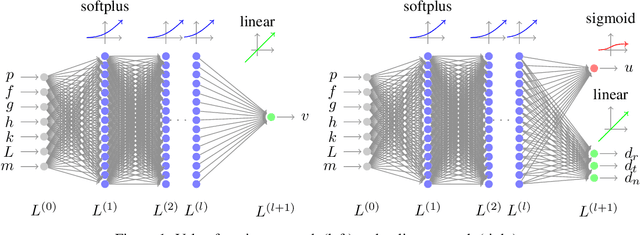

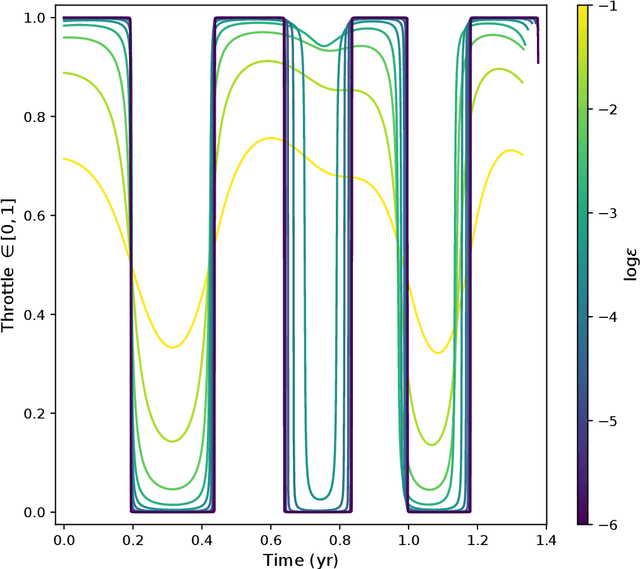

We consider the Earth-Venus mass-optimal interplanetary transfer of a low-thrust spacecraft and show how the optimal guidance can be represented by deep networks in a large portion of the state space and to a high degree of accuracy. Imitation (supervised) learning of optimal examples is used as a network training paradigm. The resulting models are suitable for an on-board, real-time, implementation of the optimal guidance and control system of the spacecraft and are called G&CNETs. A new general methodology called Backward Generation of Optimal Examples is introduced and shown to be able to efficiently create all the optimal state action pairs necessary to train G&CNETs without solving optimal control problems. With respect to previous works, we are able to produce datasets containing a few orders of magnitude more optimal trajectories and obtain network performances compatible with real missions requirements. Several schemes able to train representations of either the optimal policy (thrust profile) or the value function (optimal mass) are proposed and tested. We find that both policy learning and value function learning successfully and accurately learn the optimal thrust and that a spacecraft employing the learned thrust is able to reach the target conditions orbit spending only 2 permil more propellant than in the corresponding mathematically optimal transfer. Moreover, the optimal propellant mass can be predicted (in case of value function learning) within an error well within 1%. All G&CNETs produced are tested during simulations of interplanetary transfers with respect to their ability to reach the target conditions optimally starting from nominal and off-nominal conditions.
Deep learning mediated single time-point image-based prediction of embryo developmental outcome at the cleavage stage
May 21, 2020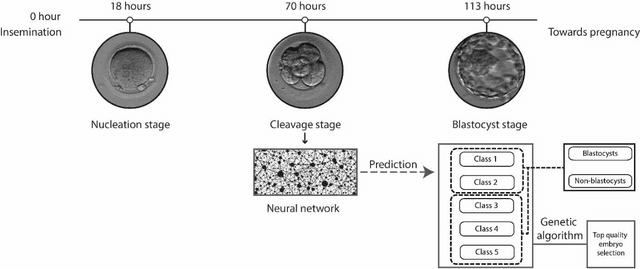
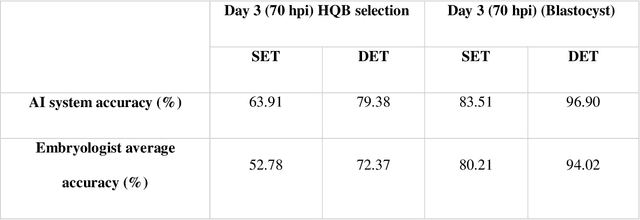
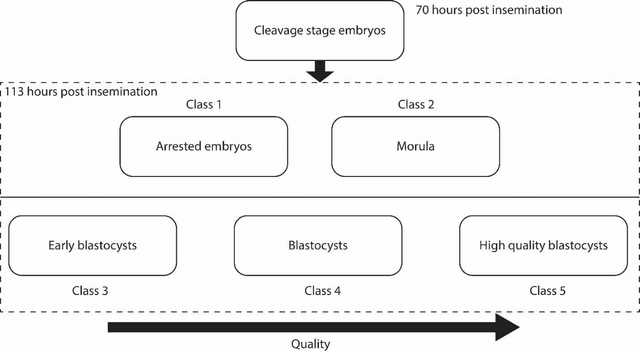
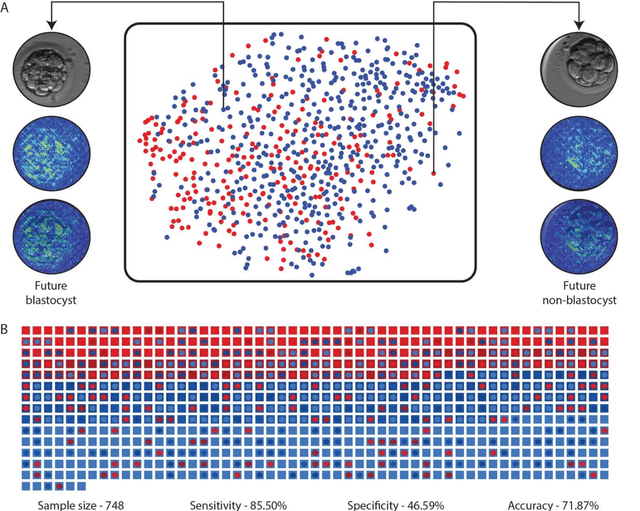
In conventional clinical in-vitro fertilization practices embryos are transferred either at the cleavage or blastocyst stages of development. Cleavage stage transfers, particularly, are beneficial for patients with relatively poor prognosis and at fertility centers in resource-limited settings where there is a higher chance of developmental failure in embryos in-vitro. However, one of the major limitations of embryo selections at the cleavage stage is the availability of very low number of manually discernable features to predict developmental outcomes. Although, time-lapse imaging systems have been proposed as possible solutions, they are cost-prohibitive and require bulky and expensive hardware, and labor-intensive. Advances in convolutional neural networks (CNNs) have been utilized to provide accurate classifications across many medical and non-medical object categories. Here, we report an automated system for classification and selection of human embryos at the cleavage stage using a trained CNN combined with a genetic algorithm. The system selected the cleavage stage embryo at 70 hours post insemination (hpi) that ultimately developed into top-quality blastocyst at 70 hpi with 64% accuracy, outperforming the abilities of embryologists in identifying embryos with the highest developmental potential. Such systems can have a significant impact on IVF procedures by empowering embryologists for accurate and consistent embryo assessment in both resource-poor and resource-rich settings.
A Scalable Federated Multi-agent Architecture for Networked Connected Communication Network
Aug 01, 2021
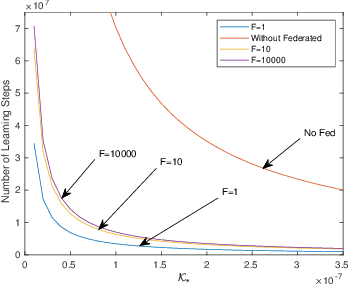
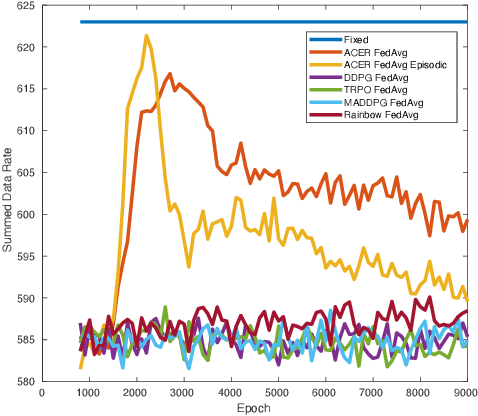
Scalability is the key roadstone towards the application of cooperative intelligent algorithms in large-scale networks. Reinforcement learning (RL) is known as model-free and high efficient intelligent algorithm for communication problems and proved useful in the communication network. However, when coming to large-scale networks with limited centralization, it is not possible to employ a centralized entity to perform joint real-time decision making for entire network. This introduces the scalability challenges, while multi-agent reinforcement shows the opportunity to cope this challenges and extend the intelligent algorithm to cooperative large-scale network. In this paper, we introduce the federated mean-field multi-agent reinforcement learning structure to capture the problem in large scale multi-agent communication scenarios, where agents share parameters to form consistency. We present the theoretical basis of our architecture and show the influence of federated frequency with an informational multi-agent model. We then exam the performance of our architecture with a coordinated multi-point environment which requires handshakes between neighbour access-points to realise the cooperation gain. Our result shows that the learning structure can effectively solve the cooperation problem in a large scale network with decent scalability. We also show the effectiveness of federated algorithms and highlight the importance of maintaining personality in each access-point.
Robust Regularized Locality Preserving Indexing for Fiedler Vector Estimation
Jul 26, 2021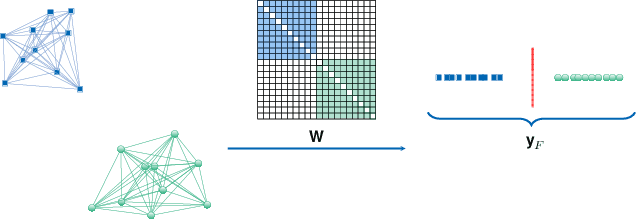
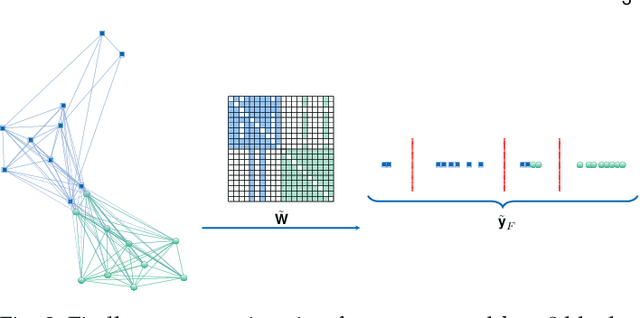
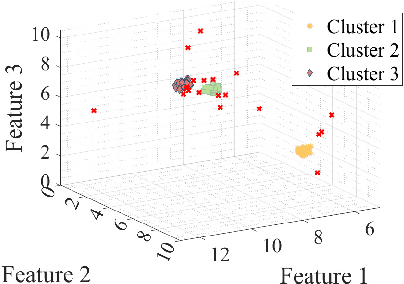
The Fiedler vector of a connected graph is the eigenvector associated with the algebraic connectivity of the graph Laplacian and it provides substantial information to learn the latent structure of a graph. In real-world applications, however, the data may be subject to heavy-tailed noise and outliers which results in deteriorations in the structure of the Fiedler vector estimate. We design a Robust Regularized Locality Preserving Indexing (RRLPI) method for Fiedler vector estimation that aims to approximate the nonlinear manifold structure of the Laplace Beltrami operator while minimizing the negative impact of outliers. First, an analysis of the effects of two fundamental outlier types on the eigen-decomposition for block affinity matrices which are essential in cluster analysis is conducted. Then, an error model is formulated and a robust Fiedler vector estimation algorithm is developed. An unsupervised penalty parameter selection algorithm is proposed that leverages the geometric structure of the projection space to perform robust regularized Fiedler estimation. The performance of RRLPI is benchmarked against existing competitors in terms of detection probability, partitioning quality, image segmentation capability, robustness and computation time using a large variety of synthetic and real data experiments.
Measuring diachronic sense change: new models and Monte Carlo methods for Bayesian inference
Apr 14, 2021
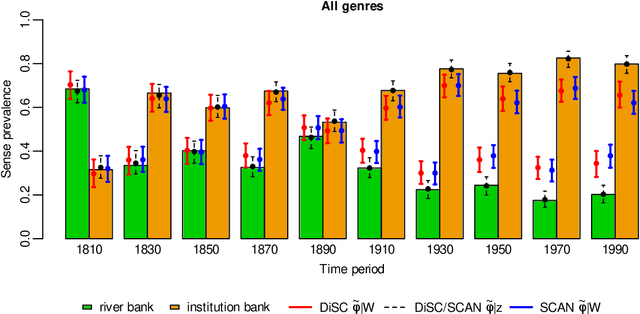

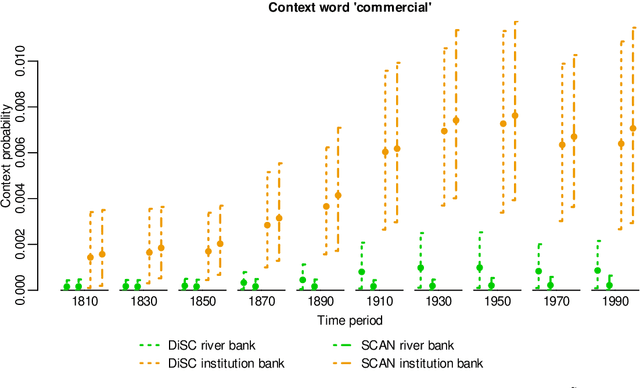
In a bag-of-words model, the senses of a word with multiple meanings, e.g. "bank" (used either in a river-bank or an institution sense), are represented as probability distributions over context words, and sense prevalence is represented as a probability distribution over senses. Both of these may change with time. Modelling and measuring this kind of sense change is challenging due to the typically high-dimensional parameter space and sparse datasets. A recently published corpus of ancient Greek texts contains expert-annotated sense labels for selected target words. Automatic sense-annotation for the word "kosmos" (meaning decoration, order or world) has been used as a test case in recent work with related generative models and Monte Carlo methods. We adapt an existing generative sense change model to develop a simpler model for the main effects of sense and time, and give MCMC methods for Bayesian inference on all these models that are more efficient than existing methods. We carry out automatic sense-annotation of snippets containing "kosmos" using our model, and measure the time-evolution of its three senses and their prevalence. As far as we are aware, ours is the first analysis of this data, within the class of generative models we consider, that quantifies uncertainty and returns credible sets for evolving sense prevalence in good agreement with those given by expert annotation.
High-Power and High-Capacity Mobile Optical SWIPT
Jul 26, 2021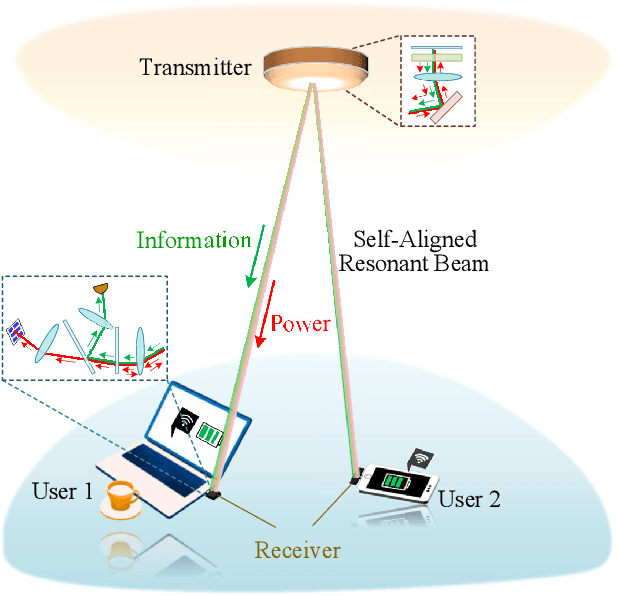
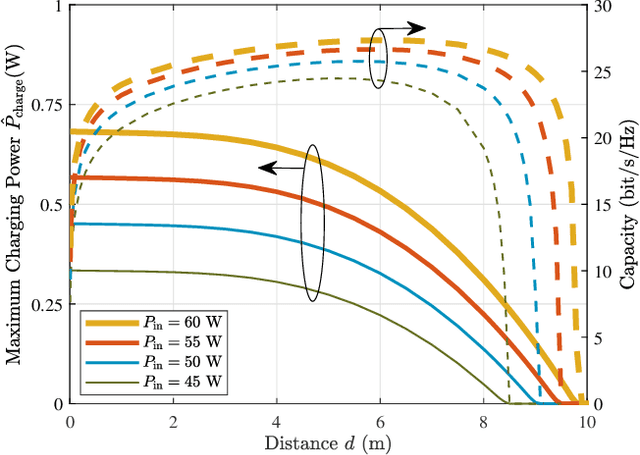
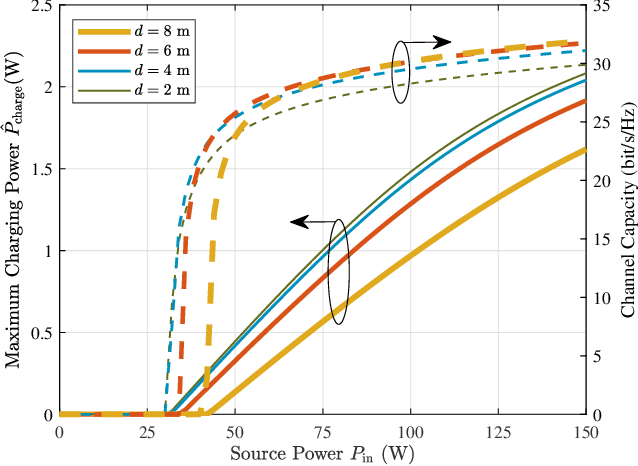
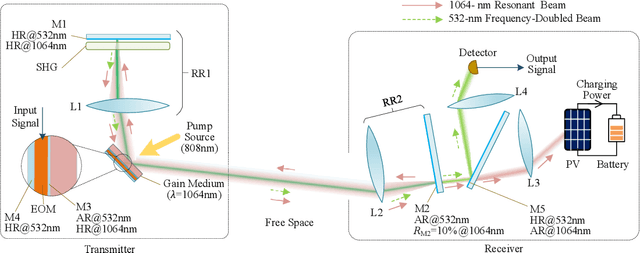
The increasing demands of power supply and data rate for mobile devices promote the research of simultaneous information and power transfer (SWIPT). Optical SWIPT, as known as simultaneous light information and power transfer (SLIPT), can provide high-capacity communication and high-power charging. However, light emitting diodes (LEDs)-based SLIPT technologies have low efficiency due to energy dissipation over the air. Laser-based SLIPT technologies face the challenge in mobility, as it needs accurate positioning, fast beam steering, and real-time tracking. In this paper, we propose a mobile SLIPT scheme based on spatially separated laser resonator (SSLR) and intra-cavity second harmonic generation (SHG). The power and data are transferred via separated frequencies, while they share the same self-aligned resonant beam path, without the needs of receiver positioning and beam steering. We establish the analysis model of the resonant beam power and its second harmonic power. We also evaluate the system performance on deliverable power and channel capacity. Numerical results show that the proposed system can achieve watt-level battery charging power and above 20-bit/s/Hz communication capacity over 8-m distance, which satisfies the requirements of most indoor mobile devices.
Species Distribution Modeling for Machine Learning Practitioners: A Review
Jul 03, 2021
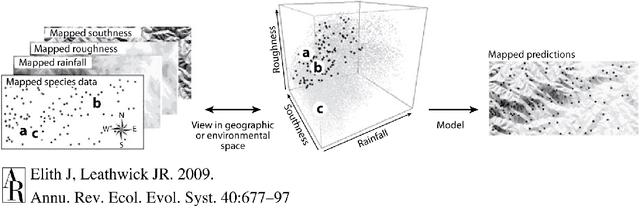

Conservation science depends on an accurate understanding of what's happening in a given ecosystem. How many species live there? What is the makeup of the population? How is that changing over time? Species Distribution Modeling (SDM) seeks to predict the spatial (and sometimes temporal) patterns of species occurrence, i.e. where a species is likely to be found. The last few years have seen a surge of interest in applying powerful machine learning tools to challenging problems in ecology. Despite its considerable importance, SDM has received relatively little attention from the computer science community. Our goal in this work is to provide computer scientists with the necessary background to read the SDM literature and develop ecologically useful ML-based SDM algorithms. In particular, we introduce key SDM concepts and terminology, review standard models, discuss data availability, and highlight technical challenges and pitfalls.
UR Channel-Robust Synthetic Speech Detection System for ASVspoof 2021
Jul 26, 2021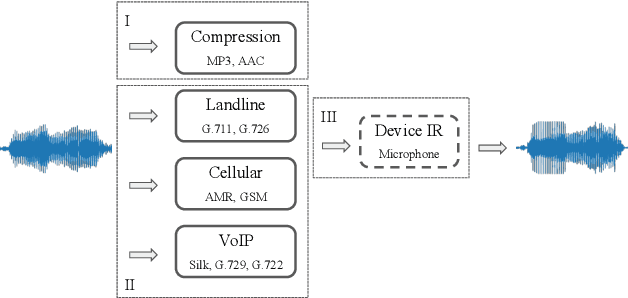
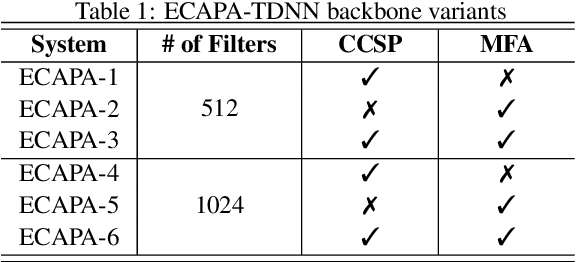
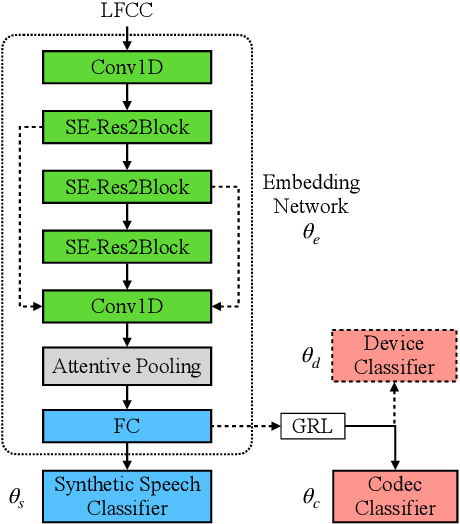
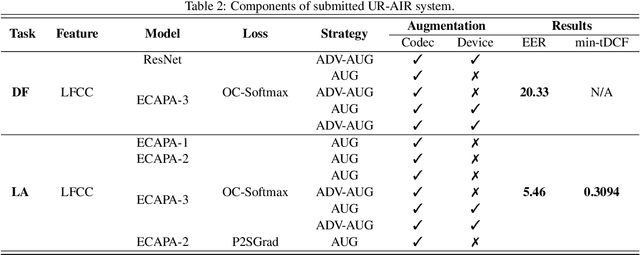
In this paper, we present UR-AIR system submission to the logical access (LA) and the speech deepfake (DF) tracks of the ASVspoof 2021 Challenge. The LA and DF tasks focus on synthetic speech detection (SSD), i.e. detecting text-to-speech and voice conversion as spoofing attacks. Different from previous ASVspoof challenges, the LA task this year presents codec and transmission channel variability, while the new task DF presents general audio compression. Built upon our previous research work on improving the robustness of the SSD systems to channel effects, we propose a channel-robust synthetic speech detection system for the challenge. To mitigate the channel variability issue, we use an acoustic simulator to apply transmission codec, compression codec, and convolutional impulse responses to the original datasets. For the neural network backbone, we propose to use Emphasized Channel Attention, Propagation and Aggregation Time Delay Neural Networks (ECAPA-TDNN) as our primary model. We also incorporate one-class learning with channel-robust training strategies to further learn a channel-invariant speech representation. Our submission achieved EER 20.33% in the DF task; EER 5.46% and min-tDCF 0.3094 in the LA task.