 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Balancing Accuracy and Fairness for Interactive Recommendation with Reinforcement Learning
Jun 25, 2021
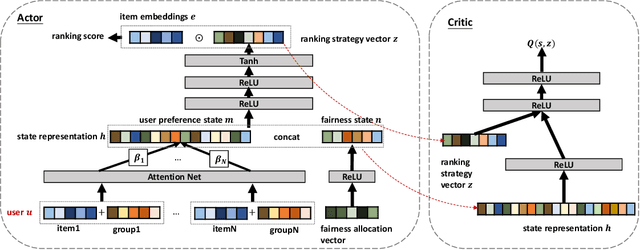
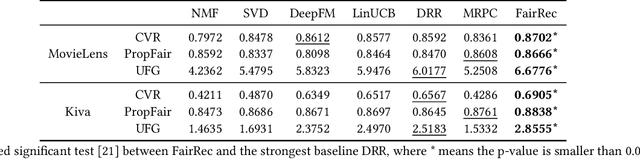
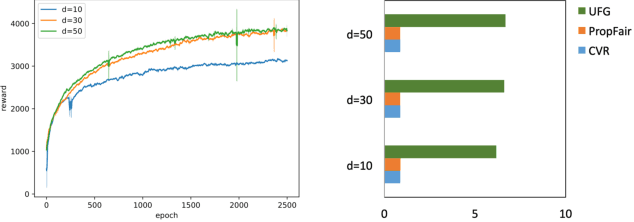
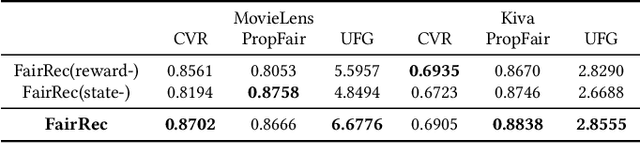
Fairness in recommendation has attracted increasing attention due to bias and discrimination possibly caused by traditional recommenders. In Interactive Recommender Systems (IRS), user preferences and the system's fairness status are constantly changing over time. Existing fairness-aware recommenders mainly consider fairness in static settings. Directly applying existing methods to IRS will result in poor recommendation. To resolve this problem, we propose a reinforcement learning based framework, FairRec, to dynamically maintain a long-term balance between accuracy and fairness in IRS. User preferences and the system's fairness status are jointly compressed into the state representation to generate recommendations. FairRec aims at maximizing our designed cumulative reward that combines accuracy and fairness. Extensive experiments validate that FairRec can improve fairness, while preserving good recommendation quality.
A Mixed-Supervision Multilevel GAN Framework for Image Quality Enhancement
Jun 29, 2021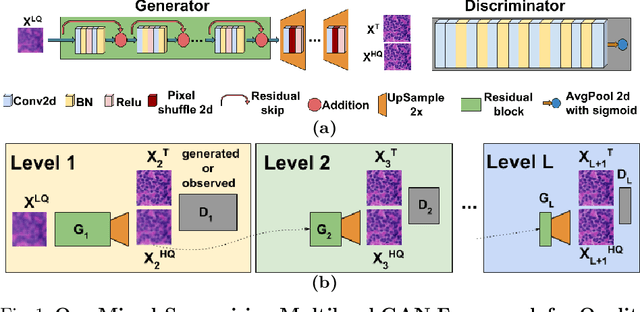
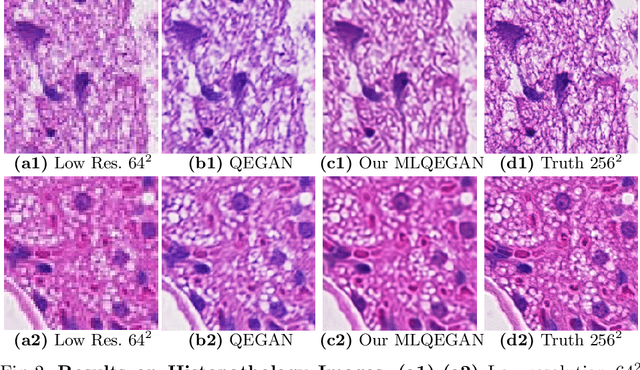
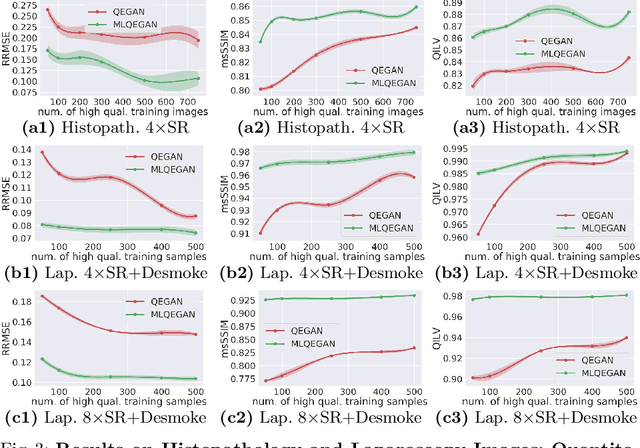
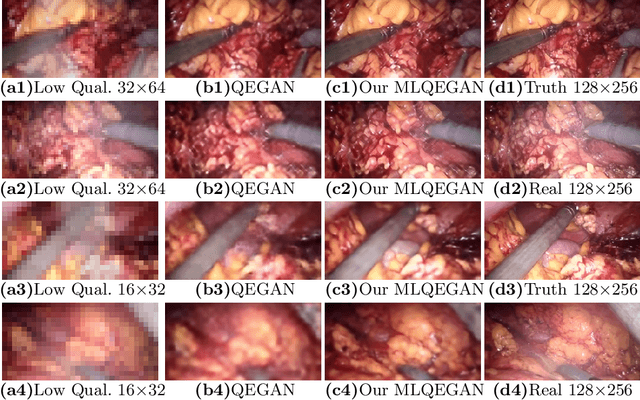
Deep neural networks for image quality enhancement typically need large quantities of highly-curated training data comprising pairs of low-quality images and their corresponding high-quality images. While high-quality image acquisition is typically expensive and time-consuming, medium-quality images are faster to acquire, at lower equipment costs, and available in larger quantities. Thus, we propose a novel generative adversarial network (GAN) that can leverage training data at multiple levels of quality (e.g., high and medium quality) to improve performance while limiting costs of data curation. We apply our mixed-supervision GAN to (i) super-resolve histopathology images and (ii) enhance laparoscopy images by combining super-resolution and surgical smoke removal. Results on large clinical and pre-clinical datasets show the benefits of our mixed-supervision GAN over the state of the art.
Word Embedding Techniques for Malware Evolution Detection
Mar 07, 2021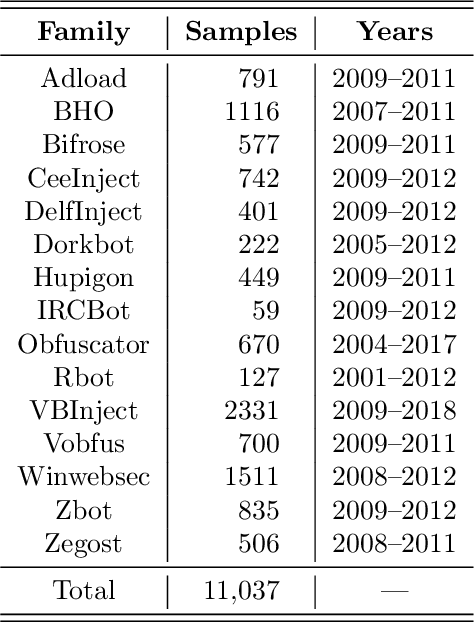
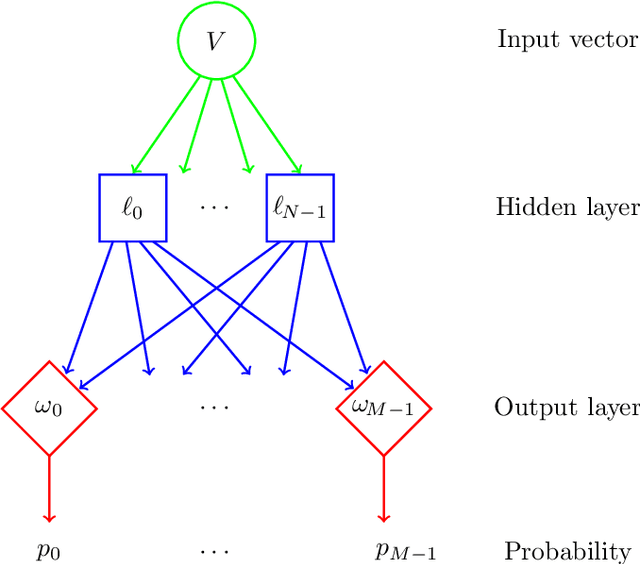
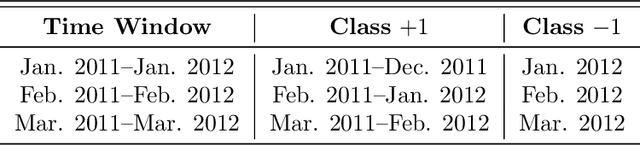
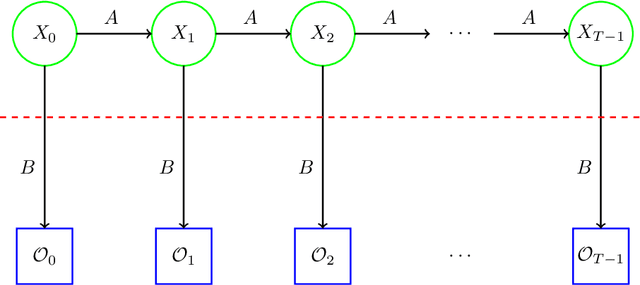
Malware detection is a critical aspect of information security. One difficulty that arises is that malware often evolves over time. To maintain effective malware detection, it is necessary to determine when malware evolution has occurred so that appropriate countermeasures can be taken. We perform a variety of experiments aimed at detecting points in time where a malware family has likely evolved, and we consider secondary tests designed to confirm that evolution has actually occurred. Several malware families are analyzed, each of which includes a number of samples collected over an extended period of time. Our experiments indicate that improved results are obtained using feature engineering based on word embedding techniques. All of our experiments are based on machine learning models, and hence our evolution detection strategies require minimal human intervention and can easily be automated.
Wave-Informed Matrix Factorization withGlobal Optimality Guarantees
Jul 19, 2021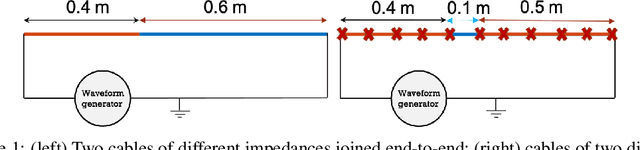

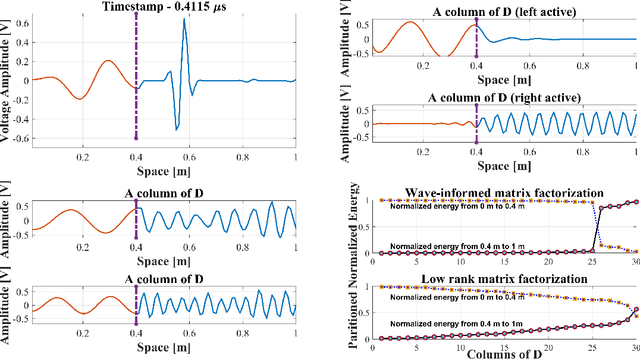
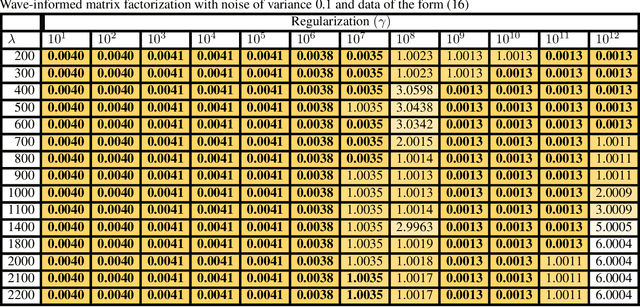
With the recent success of representation learning methods, which includes deep learning as a special case, there has been considerable interest in developing representation learning techniques that can incorporate known physical constraints into the learned representation. As one example, in many applications that involve a signal propagating through physical media (e.g., optics, acoustics, fluid dynamics, etc), it is known that the dynamics of the signal must satisfy constraints imposed by the wave equation. Here we propose a matrix factorization technique that decomposes such signals into a sum of components, where each component is regularized to ensure that it satisfies wave equation constraints. Although our proposed formulation is non-convex, we prove that our model can be efficiently solved to global optimality in polynomial time. We demonstrate the benefits of our work by applications in structural health monitoring, where prior work has attempted to solve this problem using sparse dictionary learning approaches that do not come with any theoretical guarantees regarding convergence to global optimality and employ heuristics to capture desired physical constraints.
Mutually-Constrained Monotonic Multihead Attention for Online ASR
Mar 26, 2021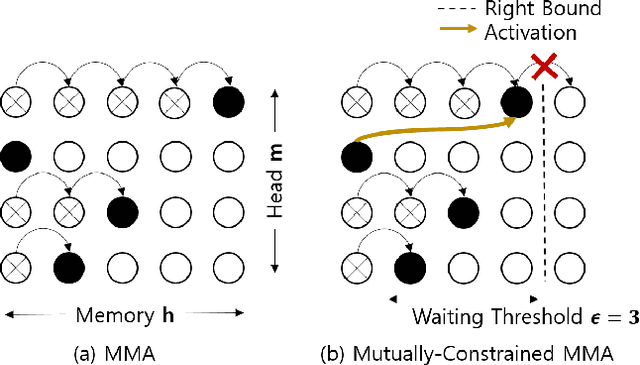
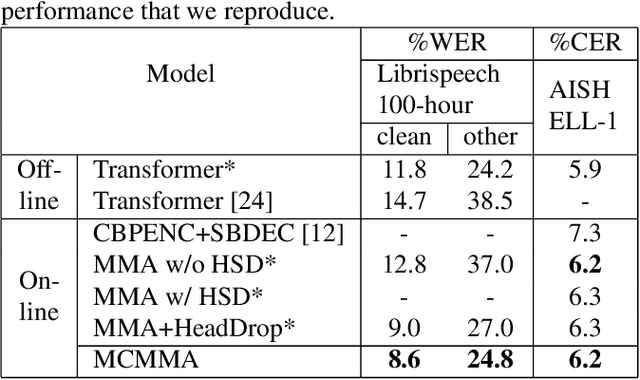
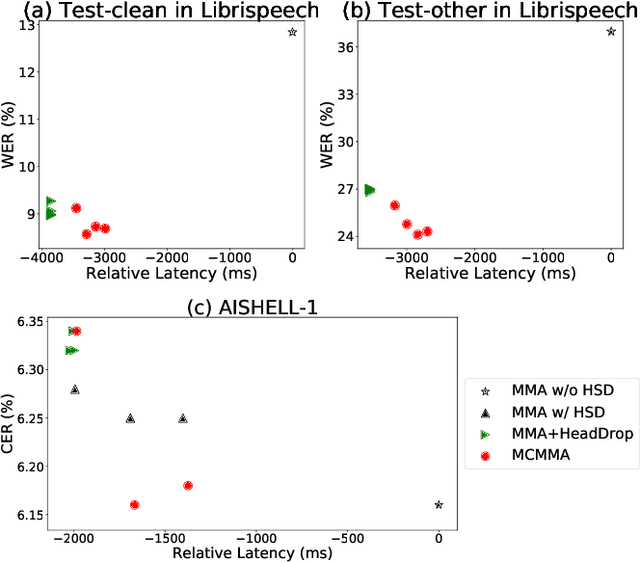
Despite the feature of real-time decoding, Monotonic Multihead Attention (MMA) shows comparable performance to the state-of-the-art offline methods in machine translation and automatic speech recognition (ASR) tasks. However, the latency of MMA is still a major issue in ASR and should be combined with a technique that can reduce the test latency at inference time, such as head-synchronous beam search decoding, which forces all non-activated heads to activate after a small fixed delay from the first head activation. In this paper, we remove the discrepancy between training and test phases by considering, in the training of MMA, the interactions across multiple heads that will occur in the test time. Specifically, we derive the expected alignments from monotonic attention by considering the boundaries of other heads and reflect them in the learning process. We validate our proposed method on the two standard benchmark datasets for ASR and show that our approach, MMA with the mutually-constrained heads from the training stage, provides better performance than baselines.
Accelerating deep neural networks for efficient scene understanding in automotive cyber-physical systems
Jul 19, 2021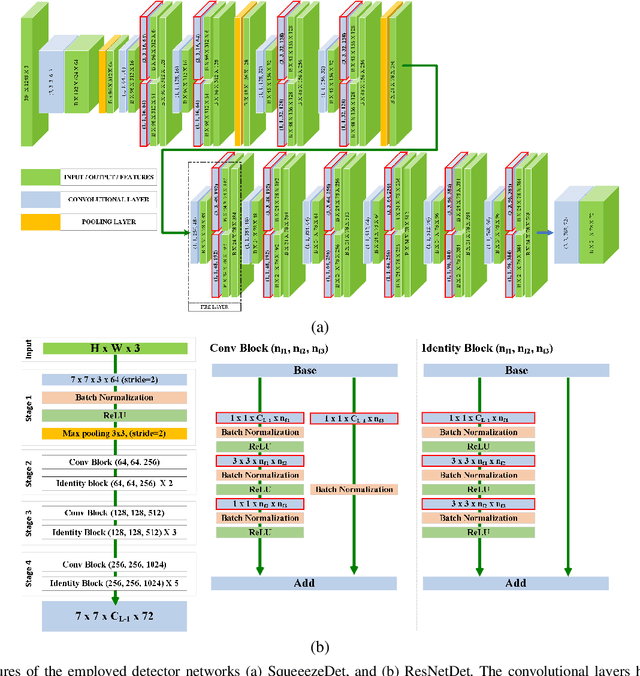
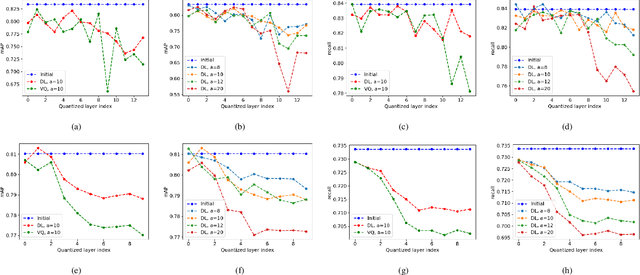

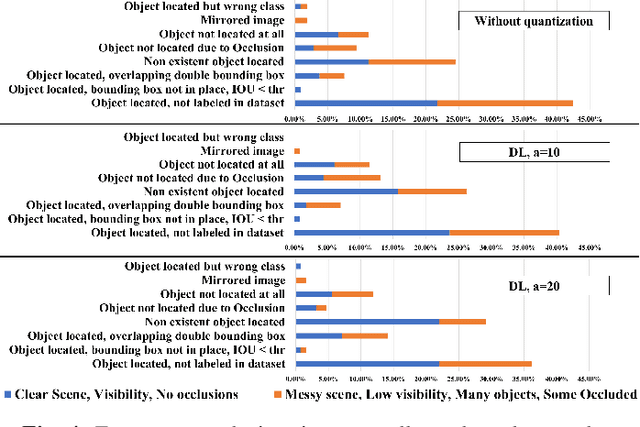
Automotive Cyber-Physical Systems (ACPS) have attracted a significant amount of interest in the past few decades, while one of the most critical operations in these systems is the perception of the environment. Deep learning and, especially, the use of Deep Neural Networks (DNNs) provides impressive results in analyzing and understanding complex and dynamic scenes from visual data. The prediction horizons for those perception systems are very short and inference must often be performed in real time, stressing the need of transforming the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Our goal in this work is to investigate best practices for appropriately applying novel weight sharing techniques, optimizing the available variables and the training procedures towards the significant acceleration of widely adopted DNNs. Extensive evaluation studies carried out using various state-of-the-art DNN models in object detection and tracking experiments, provide details about the type of errors that manifest after the application of weight sharing techniques, resulting in significant acceleration gains with negligible accuracy losses.
Group-based Bi-Directional Recurrent Wavelet Neural Networks for Video Super-Resolution
Jun 14, 2021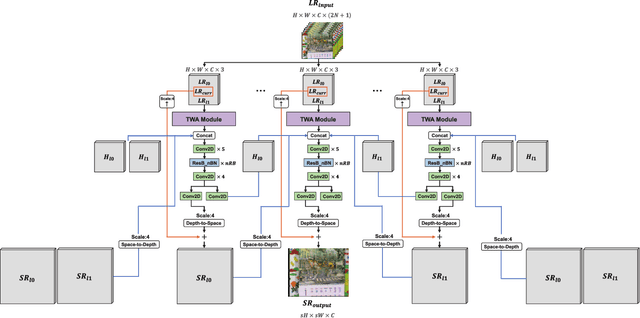
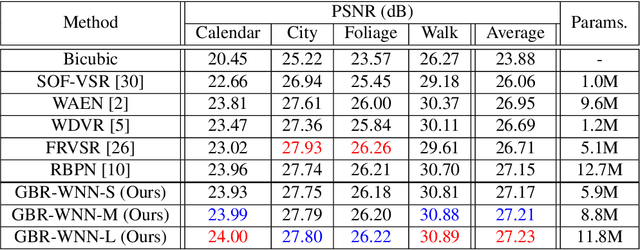
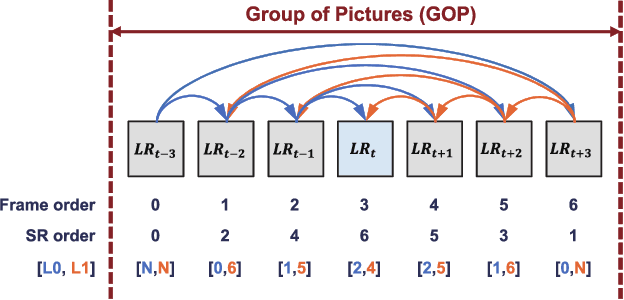
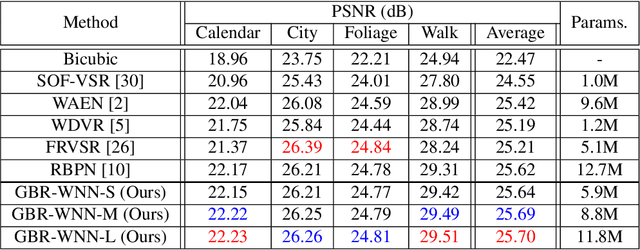
Video super-resolution (VSR) aims to estimate a high-resolution (HR) frame from a low-resolution (LR) frames. The key challenge for VSR lies in the effective exploitation of spatial correlation in an intra-frame and temporal dependency between consecutive frames. However, most of the previous methods treat different types of the spatial features identically and extract spatial and temporal features from the separated modules. It leads to lack of obtaining meaningful information and enhancing the fine details. In VSR, there are three types of temporal modeling frameworks: 2D convolutional neural networks (CNN), 3D CNN, and recurrent neural networks (RNN). Among them, the RNN-based approach is suitable for sequential data. Thus the SR performance can be greatly improved by using the hidden states of adjacent frames. However, at each of time step in a recurrent structure, the RNN-based previous works utilize the neighboring features restrictively. Since the range of accessible motion per time step is narrow, there are still limitations to restore the missing details for dynamic or large motion. In this paper, we propose a group-based bi-directional recurrent wavelet neural networks (GBR-WNN) to exploit the sequential data and spatio-temporal information effectively for VSR. The proposed group-based bi-directional RNN (GBR) temporal modeling framework is built on the well-structured process with the group of pictures (GOP). We propose a temporal wavelet attention (TWA) module, in which attention is adopted for both spatial and temporal features. Experimental results demonstrate that the proposed method achieves superior performance compared with state-of-the-art methods in both of quantitative and qualitative evaluations.
Polynomial-time Algorithms for Combinatorial Pure Exploration with Full-bandit Feedback
Feb 27, 2019
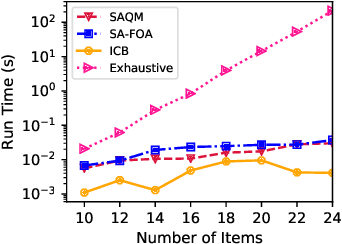
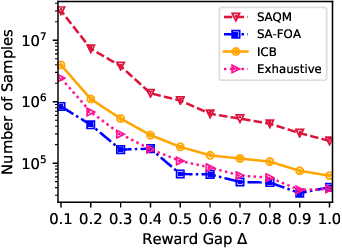
We study the problem of stochastic combinatorial pure exploration (CPE), where an agent sequentially pulls a set of single arms (a.k.a. a super arm) and tries to find the best super arm. Among a variety of problem settings of the CPE, we focus on the full-bandit setting, where we cannot observe the reward of each single arm, but only the sum of the rewards. Although we can regard the CPE with full-bandit feedback as a special case of pure exploration in linear bandits, an approach based on linear bandits is not computationally feasible since the number of super arms may be exponential. In this paper, we first propose a polynomial-time bandit algorithm for the CPE under general combinatorial constraints and provide an upper bound of the sample complexity. Second, we design an approximation algorithm for the 0-1 quadratic maximization problem, which arises in many bandit algorithms with confidence ellipsoids. Based on our approximation algorithm, we propose novel bandit algorithms for the top-k selection problem, and prove that our algorithms run in polynomial time. Finally, we conduct experiments on synthetic and real-world datasets, and confirm the validity of our theoretical analysis in terms of both the computation time and the sample complexity.
Random Warping Series: A Random Features Method for Time-Series Embedding
Sep 14, 2018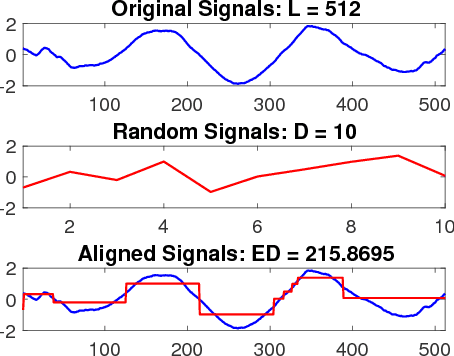
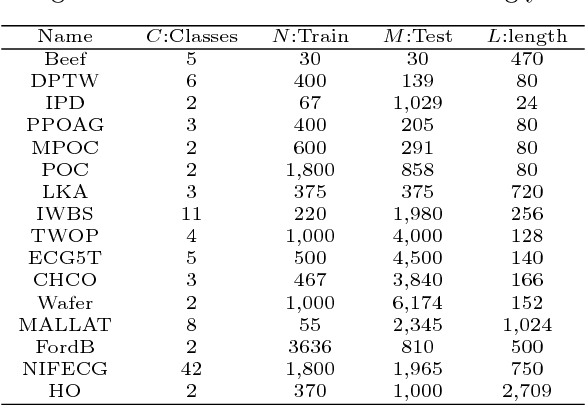
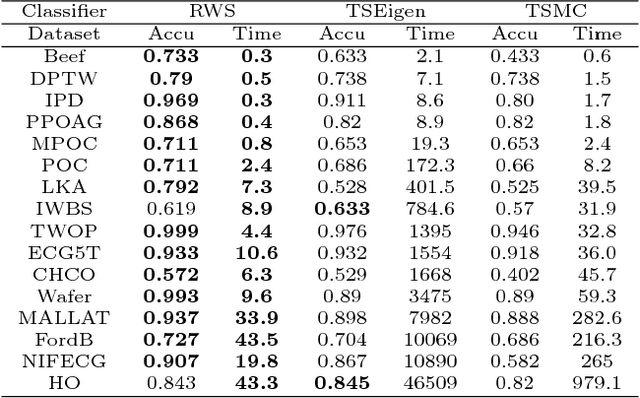
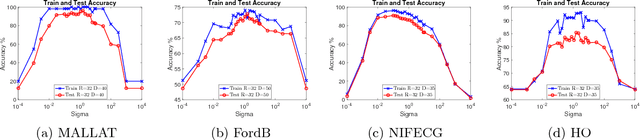
Time series data analytics has been a problem of substantial interests for decades, and Dynamic Time Warping (DTW) has been the most widely adopted technique to measure dissimilarity between time series. A number of global-alignment kernels have since been proposed in the spirit of DTW to extend its use to kernel-based estimation method such as support vector machine. However, those kernels suffer from diagonal dominance of the Gram matrix and a quadratic complexity w.r.t. the sample size. In this work, we study a family of alignment-aware positive definite (p.d.) kernels, with its feature embedding given by a distribution of \emph{Random Warping Series (RWS)}. The proposed kernel does not suffer from the issue of diagonal dominance while naturally enjoys a \emph{Random Features} (RF) approximation, which reduces the computational complexity of existing DTW-based techniques from quadratic to linear in terms of both the number and the length of time-series. We also study the convergence of the RF approximation for the domain of time series of unbounded length. Our extensive experiments on 16 benchmark datasets demonstrate that RWS outperforms or matches state-of-the-art classification and clustering methods in both accuracy and computational time. Our code and data is available at { \url{https://github.com/IBM/RandomWarpingSeries}}.
Convolutional Neural Network(CNN/ConvNet) in Stock Price Movement Prediction
Jun 03, 2021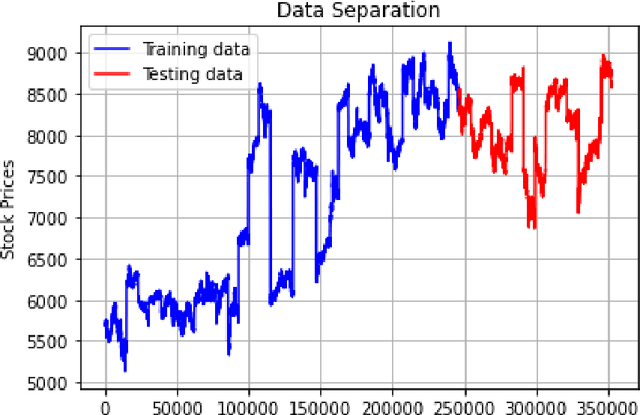
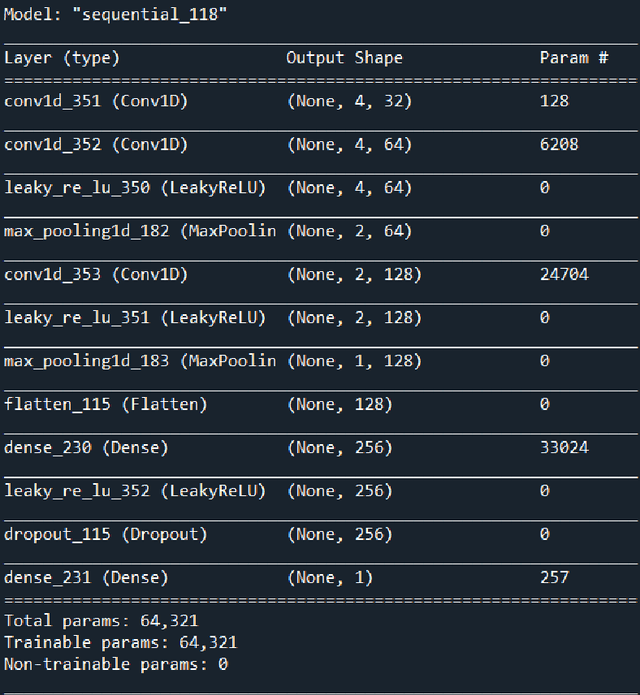
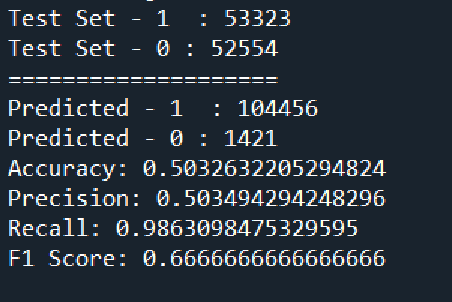
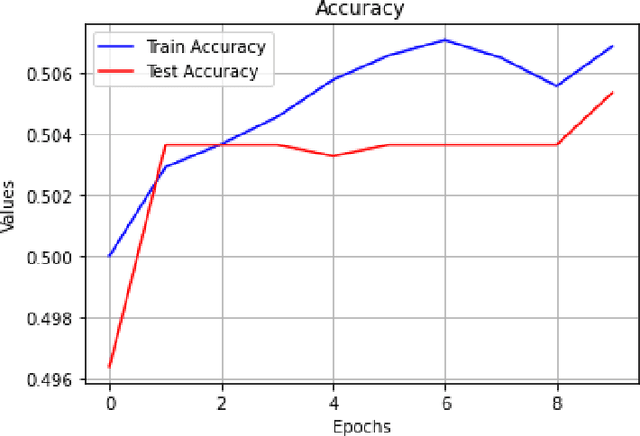
With technological advancements and the exponential growth of data, we have been unfolding different capabilities of neural networks in different sectors. In this paper, I have tried to use a specific type of Neural Network known as Convolutional Neural Network(CNN/ConvNet) in the stock market. In other words, I have tried to construct and train a convolutional neural network on past stock prices data and then tried to predict the movement of stock price i.e. whether the stock price would rise or fall, in the coming time.