 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Risk Model: A Deep Learning Solution for Mining Latent Risk Factors to Improve Covariance Matrix Estimation
Jul 12, 2021
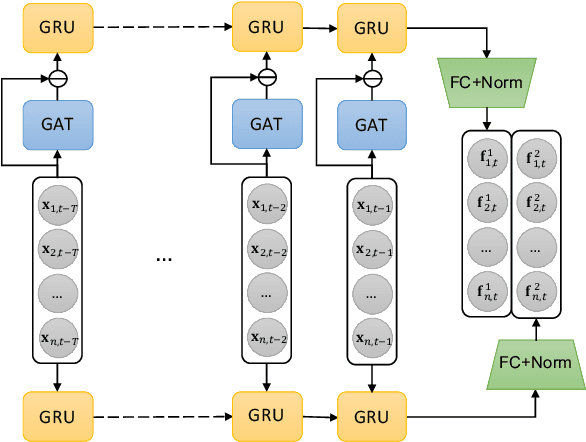
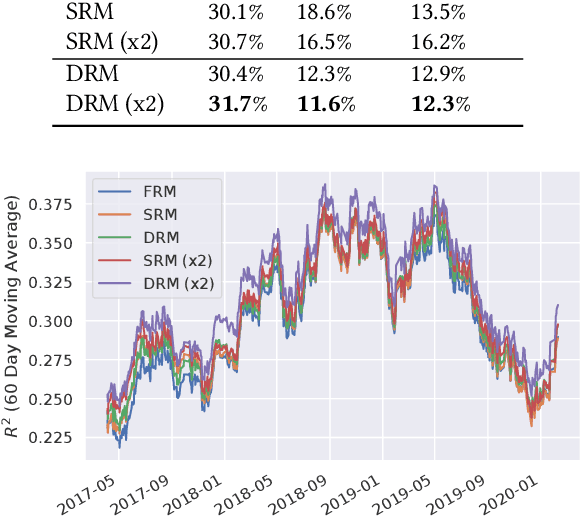
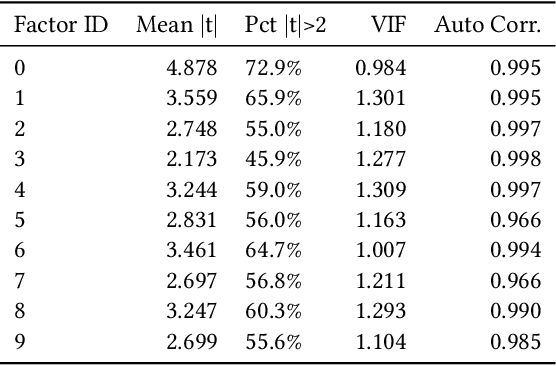
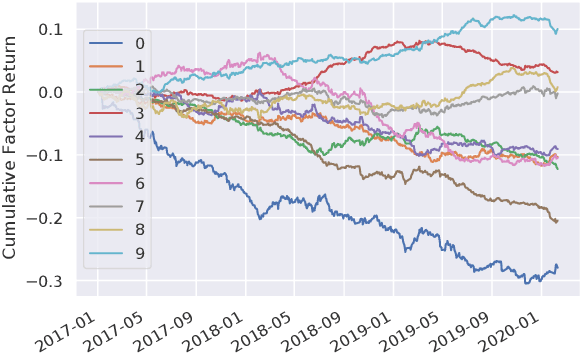
Modeling and managing portfolio risk is perhaps the most important step to achieve growing and preserving investment performance. Within the modern portfolio construction framework that built on Markowitz's theory, the covariance matrix of stock returns is required to model the portfolio risk. Traditional approaches to estimate the covariance matrix are based on human designed risk factors, which often requires tremendous time and effort to design better risk factors to improve the covariance estimation. In this work, we formulate the quest of mining risk factors as a learning problem and propose a deep learning solution to effectively "design" risk factors with neural networks. The learning objective is carefully set to ensure the learned risk factors are effective in explaining stock returns as well as have desired orthogonality and stability. Our experiments on the stock market data demonstrate the effectiveness of the proposed method: our method can obtain $1.9\%$ higher explained variance measured by $R^2$ and also reduce the risk of a global minimum variance portfolio. Incremental analysis further supports our design of both the architecture and the learning objective.
Incentivized Bandit Learning with Self-Reinforcing User Preferences
May 20, 2021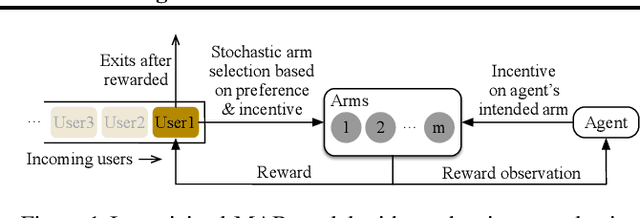
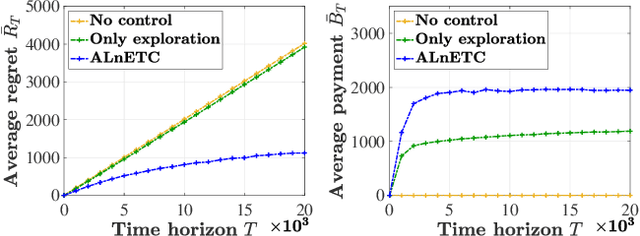
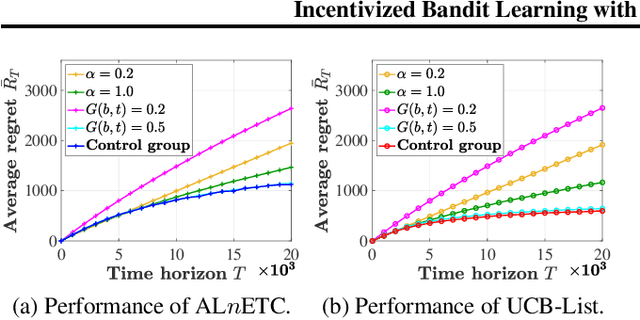
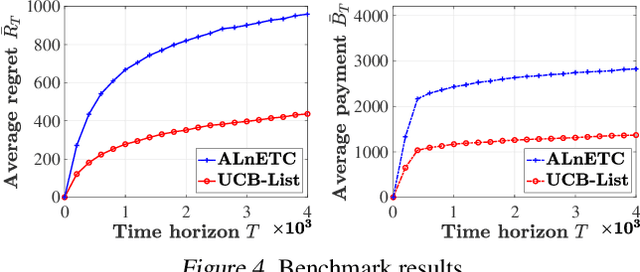
In this paper, we investigate a new multi-armed bandit (MAB) online learning model that considers real-world phenomena in many recommender systems: (i) the learning agent cannot pull the arms by itself and thus has to offer rewards to users to incentivize arm-pulling indirectly; and (ii) if users with specific arm preferences are well rewarded, they induce a "self-reinforcing" effect in the sense that they will attract more users of similar arm preferences. Besides addressing the tradeoff of exploration and exploitation, another key feature of this new MAB model is to balance reward and incentivizing payment. The goal of the agent is to maximize the total reward over a fixed time horizon $T$ with a low total payment. Our contributions in this paper are two-fold: (i) We propose a new MAB model with random arm selection that considers the relationship of users' self-reinforcing preferences and incentives; and (ii) We leverage the properties of a multi-color Polya urn with nonlinear feedback model to propose two MAB policies termed "At-Least-$n$ Explore-Then-Commit" and "UCB-List". We prove that both policies achieve $O(log T)$ expected regret with $O(log T)$ expected payment over a time horizon $T$. We conduct numerical simulations to demonstrate and verify the performances of these two policies and study their robustness under various settings.
Zero Shot Learning for Multi-Modal Real Time Image Registration
Aug 17, 2019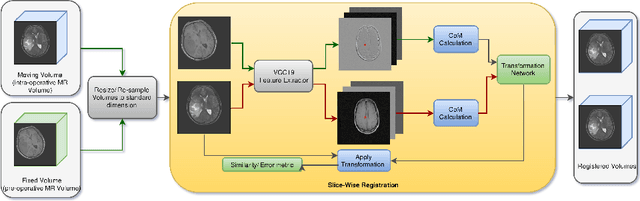
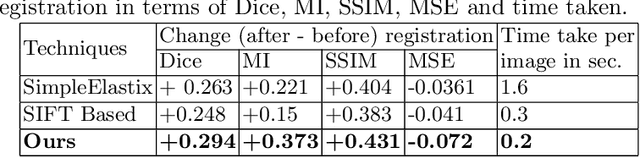
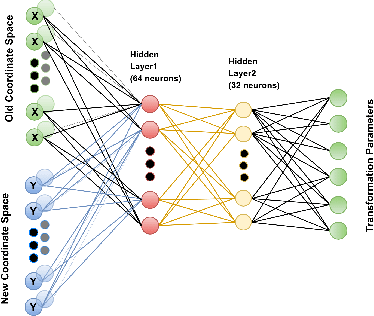

In this report we present an unsupervised image registration framework, using a pre-trained deep neural network as a feature extractor. We refer this to zero-shot learning, due to nonoverlap between training and testing dataset (none of the network modules in the processing pipeline were trained specifically for the task of medical image registration). Highlights of our technique are: (a) No requirement of a training dataset (b) Keypoints i.e.locations of important features are automatically estimated (c) The number of key points in this model is fixed and can possibly be tuned as a hyperparameter. (d) Uncertaintycalculation of the proposed, transformation estimates (e) Real-time registration of images. Our technique was evaluated on BraTS, ALBERT, and collaborative hospital Brain MRI data. Results suggest that the method proved to be robust for affine transformation models and the results are practically instantaneous, irrespective of the size of the input image
Large-scale Augmented Granger Causality (lsAGC) for Connectivity Analysis in Complex Systems: From Computer Simulations to Functional MRI (fMRI)
Jan 10, 2021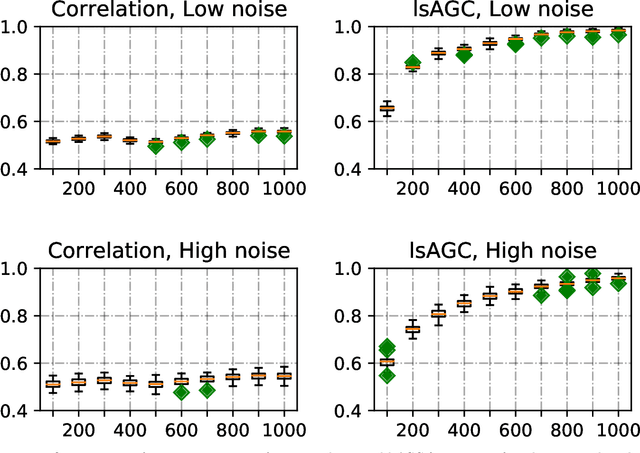
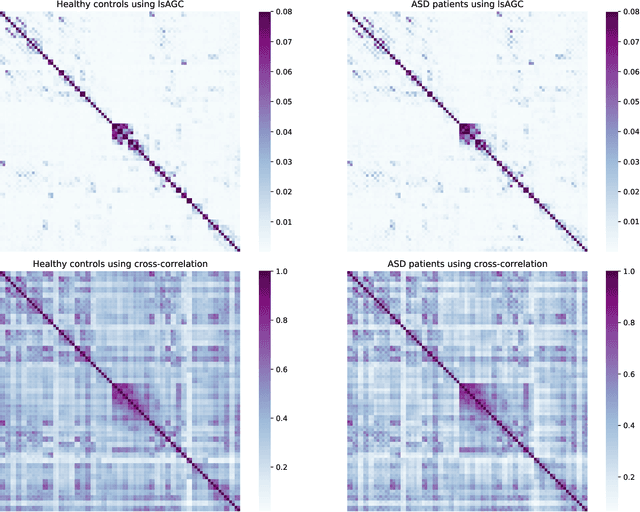
We introduce large-scale Augmented Granger Causality (lsAGC) as a method for connectivity analysis in complex systems. The lsAGC algorithm combines dimension reduction with source time-series augmentation and uses predictive time-series modeling for estimating directed causal relationships among time-series. This method is a multivariate approach, since it is capable of identifying the influence of each time-series on any other time-series in the presence of all other time-series of the underlying dynamic system. We quantitatively evaluate the performance of lsAGC on synthetic directional time-series networks with known ground truth. As a reference method, we compare our results with cross-correlation, which is typically used as a standard measure of connectivity in the functional MRI (fMRI) literature. Using extensive simulations for a wide range of time-series lengths and two different signal-to-noise ratios of 5 and 15 dB, lsAGC consistently outperforms cross-correlation at accurately detecting network connections, using Receiver Operator Characteristic Curve (ROC) analysis, across all tested time-series lengths and noise levels. In addition, as an outlook to possible clinical application, we perform a preliminary qualitative analysis of connectivity matrices for fMRI data of Autism Spectrum Disorder (ASD) patients and typical controls, using a subset of 59 subjects of the Autism Brain Imaging Data Exchange II (ABIDE II) data repository. Our results suggest that lsAGC, by extracting sparse connectivity matrices, may be useful for network analysis in complex systems, and may be applicable to clinical fMRI analysis in future research, such as targeting disease-related classification or regression tasks on clinical data.
Optimized Object Tracking Technique Using Kalman Filter
Mar 07, 2021
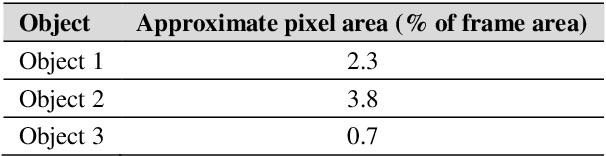
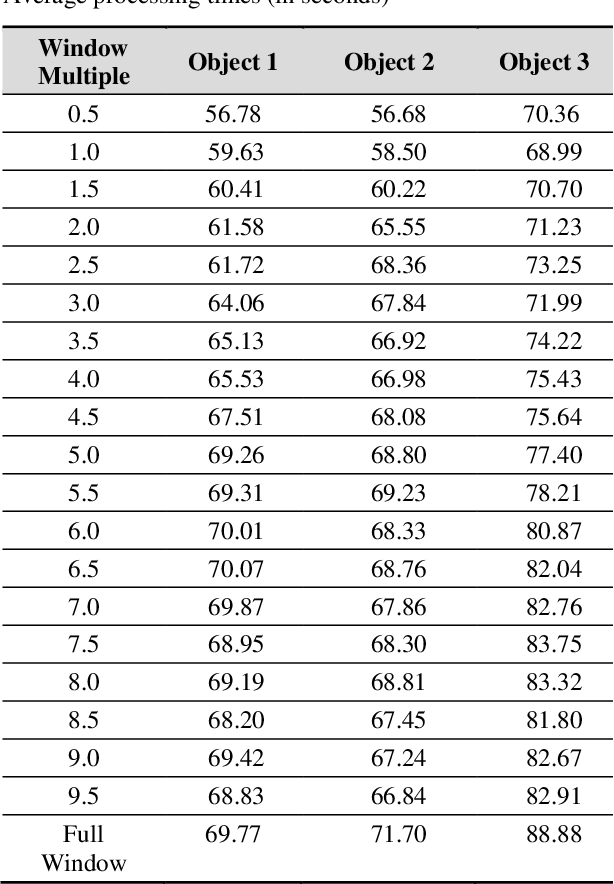
This paper focused on the design of an optimized object tracking technique which would minimize the processing time required in the object detection process while maintaining accuracy in detecting the desired moving object in a cluttered scene. A Kalman filter based cropped image is used for the image detection process as the processing time is significantly less to detect the object when a search window is used that is smaller than the entire video frame. This technique was tested with various sizes of the window in the cropping process. MATLAB was used to design and test the proposed method. This paper found that using a cropped image with 2.16 multiplied by the largest dimension of the object resulted in significantly faster processing time while still providing a high success rate of detection and a detected center of the object that was reasonably close to the actual center.
* 10 pages, 14 figures, published in J. Mechatron. Electr. Power Veh. Technol 07 (2016) 57-66
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 17, 2021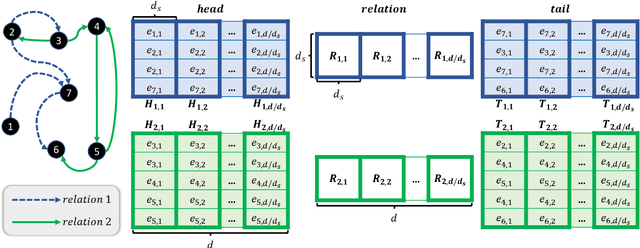
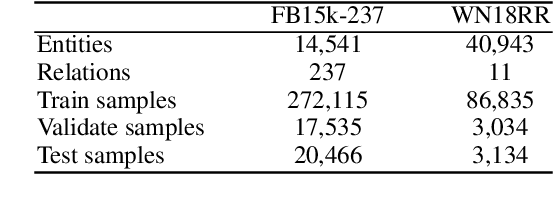
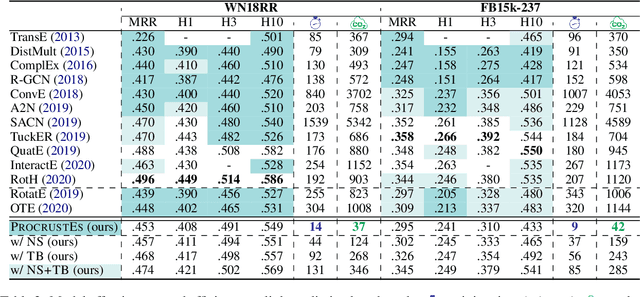
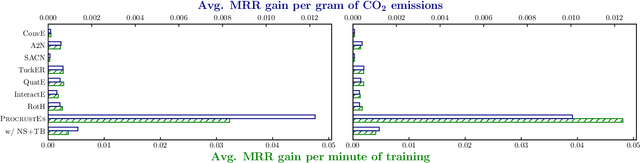
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.
High Accuracy Visible Light Positioning Based on Multi-target Tracking Algorithm
Mar 09, 2021
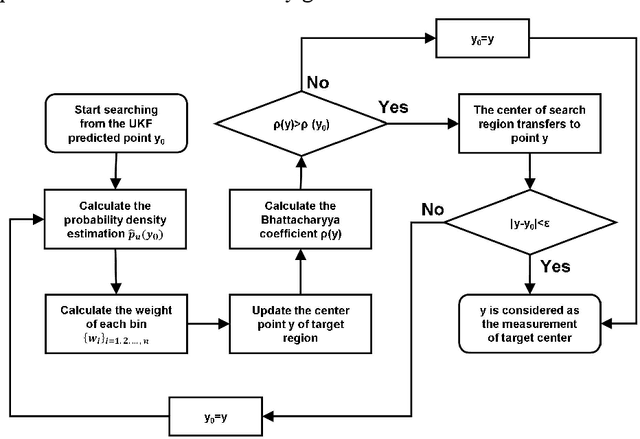

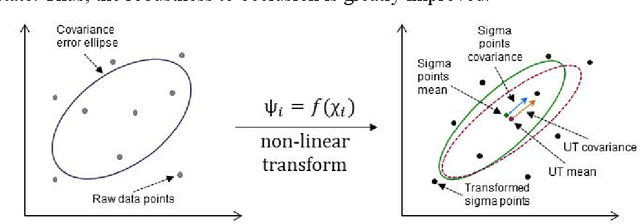
In this paper, we propose a multi-target image tracking algorithm based on continuously apative mean-shift (Cam-shift) and unscented Kalman filter. We improved the single-lamp tracking algorithm proposed in our previous work to multi-target tracking, and achieved better robustness in the case of occlusion, the real-time performance to complete one positioning and relatively high accuracy by dynamically adjusting the weights of the multi-target motion states. Our previous algorithm is limited to the analysis of tracking error. In this paper, the results of the tracking algorithm are evaluated with the tracking error we defined. Then combined with the double-lamp positioning algorithm, the real position of the terminal is calculated and evaluated with the positioning error we defined. Experiments show that the defined tracking error is 0.61cm and the defined positioning error for 3-D positioning is 3.29cm with the average processing time of 91.63ms per frame. Even if nearly half of the LED area is occluded, the tracking error remains at 5.25cm. All of this shows that the proposed visible light positioning (VLP) method can track multiple targets for positioning at the same time with good robustness, real-time performance and accuracy. In addition, the definition and analysis of tracking errors and positioning errors indicates the direction for future efforts to reduce errors.
Online Preconditioning of Experimental Inkjet Hardware by Bayesian Optimization in Loop
May 06, 2021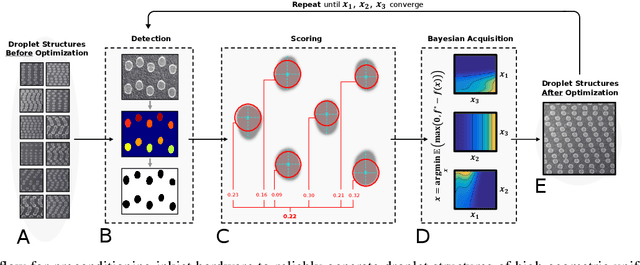
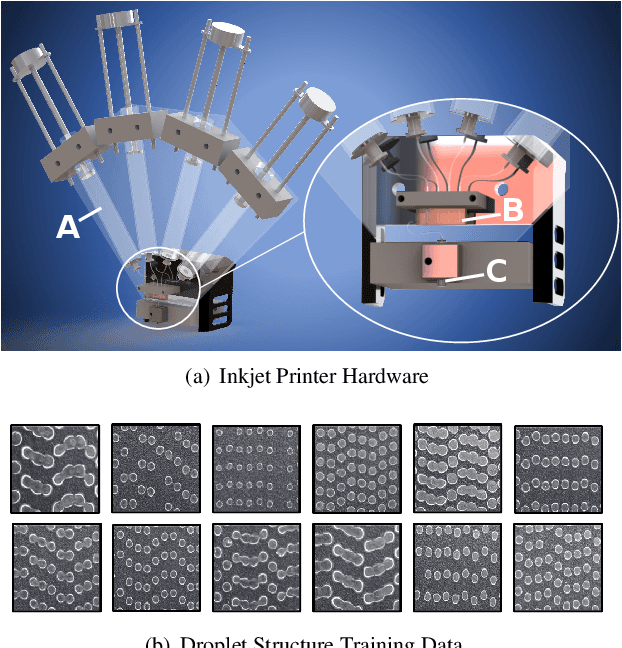
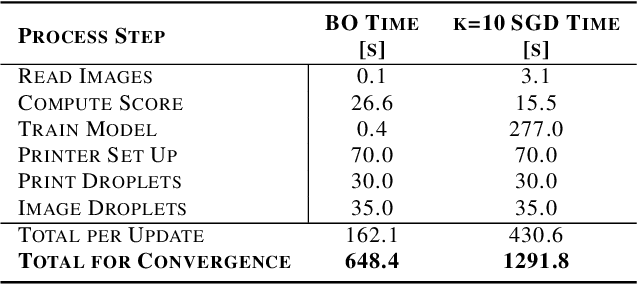
High-performance semiconductor optoelectronics such as perovskites have high-dimensional and vast composition spaces that govern the performance properties of the material. To cost-effectively search these composition spaces, we utilize a high-throughput experimentation method of rapidly printing discrete droplets via inkjet deposition, in which each droplet is comprised of a unique permutation of semiconductor materials. However, inkjet printer systems are not optimized to run high-throughput experimentation on semiconductor materials. Thus, in this work, we develop a computer vision-driven Bayesian optimization framework for optimizing the deposited droplet structures from an inkjet printer such that it is tuned to perform high-throughput experimentation on semiconductor materials. The goal of this framework is to tune to the hardware conditions of the inkjet printer in the shortest amount of time using the fewest number of droplet samples such that we minimize the time and resources spent on setting the system up for material discovery applications. We demonstrate convergence on optimum inkjet hardware conditions in 10 minutes using Bayesian optimization of computer vision-scored droplet structures. We compare our Bayesian optimization results with stochastic gradient descent.
Summary Grounded Conversation Generation
Jun 07, 2021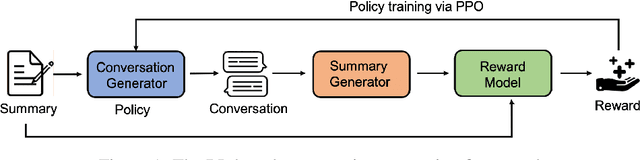
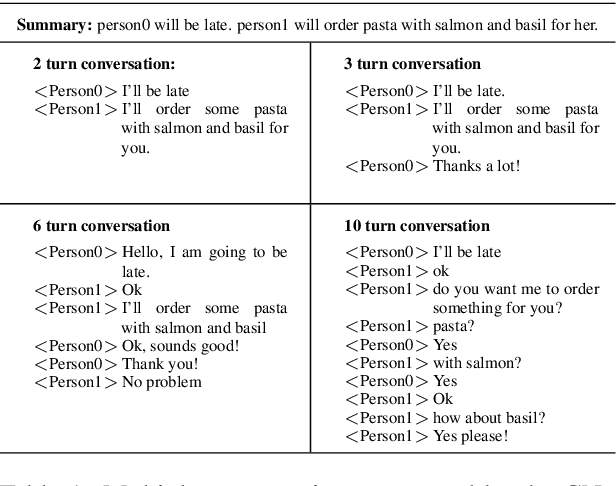
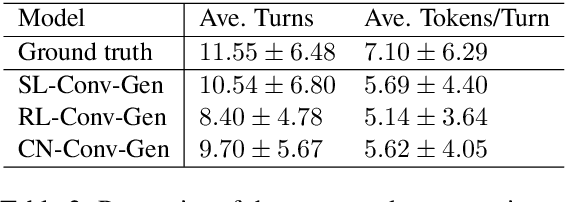
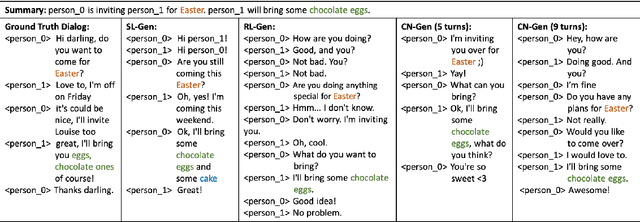
Many conversation datasets have been constructed in the recent years using crowdsourcing. However, the data collection process can be time consuming and presents many challenges to ensure data quality. Since language generation has improved immensely in recent years with the advancement of pre-trained language models, we investigate how such models can be utilized to generate entire conversations, given only a summary of a conversation as the input. We explore three approaches to generate summary grounded conversations, and evaluate the generated conversations using automatic measures and human judgements. We also show that the accuracy of conversation summarization can be improved by augmenting a conversation summarization dataset with generated conversations.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
May 26, 2021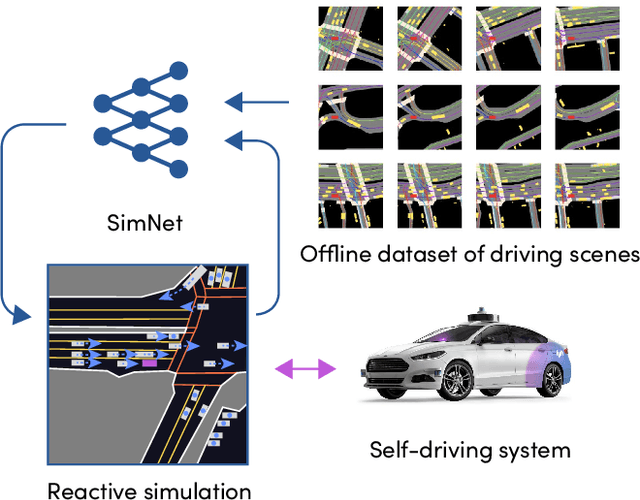
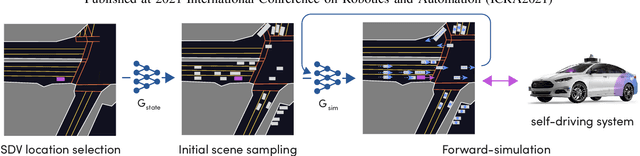
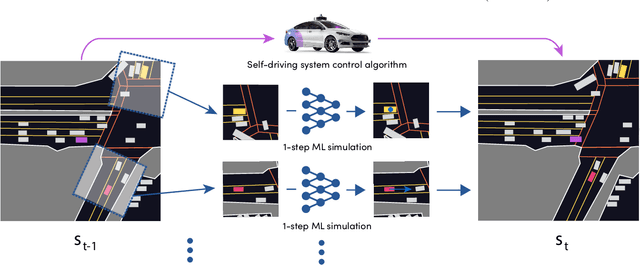
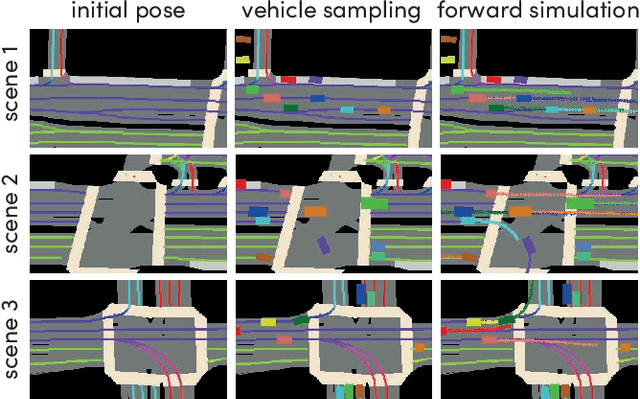
In this work, we present a simple end-to-end trainable machine learning system capable of realistically simulating driving experiences. This can be used for the verification of self-driving system performance without relying on expensive and time-consuming road testing. In particular, we frame the simulation problem as a Markov Process, leveraging deep neural networks to model both state distribution and transition function. These are trainable directly from the existing raw observations without the need for any handcrafting in the form of plant or kinematic models. All that is needed is a dataset of historical traffic episodes. Our formulation allows the system to construct never seen scenes that unfold realistically reacting to the self-driving car's behaviour. We train our system directly from 1,000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation. At the same time, we apply the method to evaluate the performance of a recently proposed state-of-the-art ML planning system trained from human driving logs. We discover this planning system is prone to previously unreported causal confusion issues that are difficult to test by non-reactive simulation. To the best of our knowledge, this is the first work that directly merges highly realistic data-driven simulations with a closed-loop evaluation for self-driving vehicles. We make the data, code, and pre-trained models publicly available to further stimulate simulation development.