 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Apply Artificial Neural Network to Solving Manpower Scheduling Problem
May 07, 2021

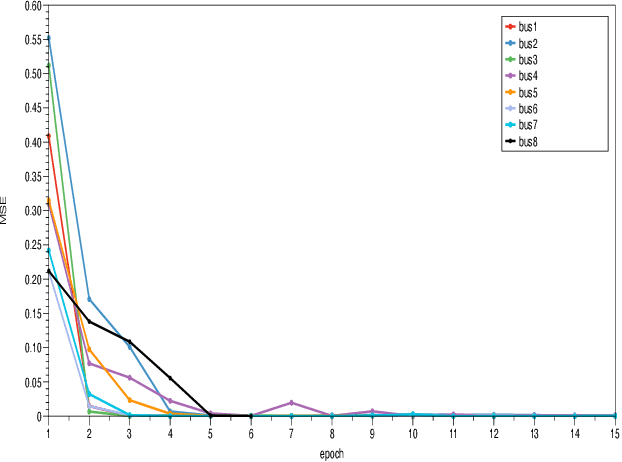
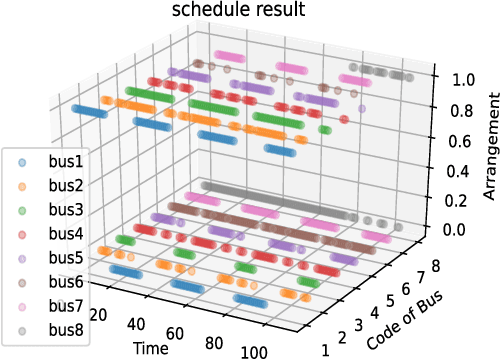
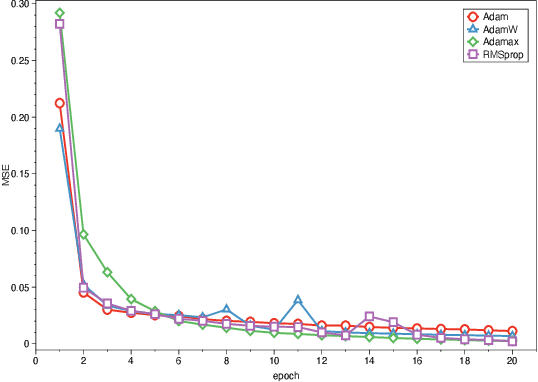
The manpower scheduling problem is a kind of critical combinational optimization problem. Researching solutions to scheduling problems can improve the efficiency of companies, hospitals, and other work units. This paper proposes a new model combined with deep learning to solve the multi-shift manpower scheduling problem based on the existing research. This model first solves the objective function's optimized value according to the current constraints to find the plan of employee arrangement initially. It will then use the scheduling table generation algorithm to obtain the scheduling result in a short time. Moreover, the most prominent feature we propose is that we will use the neural network training method based on the time series to solve long-term and long-period scheduling tasks and obtain manpower arrangement. The selection criteria of the neural network and the training process are also described in this paper. We demonstrate that our model can make a precise forecast based on the improvement of neural networks. This paper also discusses the challenges in the neural network training process and obtains enlightening results after getting the arrangement plan. Our research shows that neural networks and deep learning strategies have the potential to solve similar problems effectively.
* none
3D Iterative Spatiotemporal Filtering for Classification of Multitemporal Satellite Data Sets
Jul 01, 2021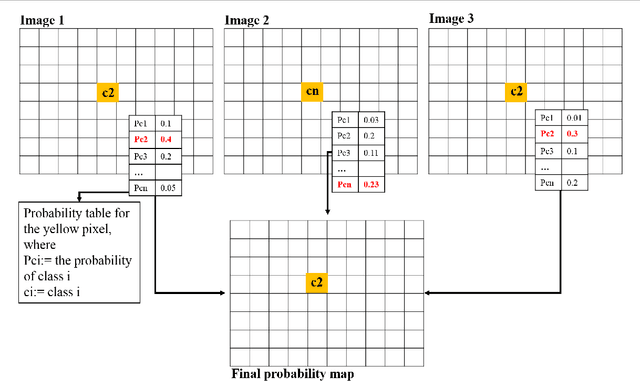

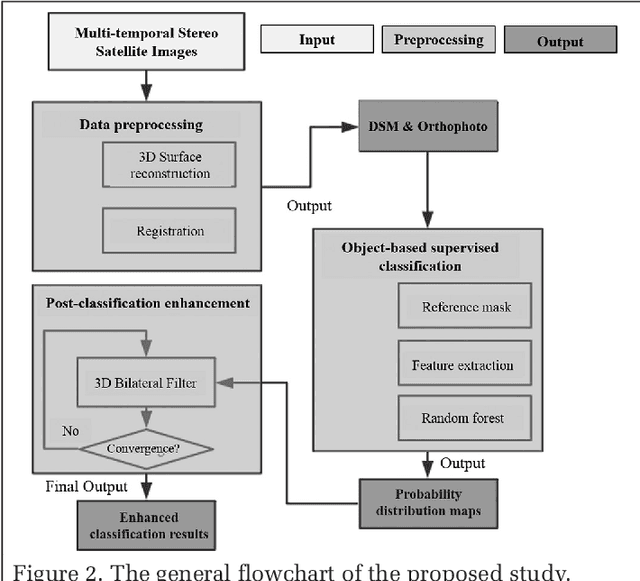
The current practice in land cover/land use change analysis relies heavily on the individually classified maps of the multitemporal data set. Due to varying acquisition conditions (e.g., illumination, sensors, seasonal differences), the classification maps yielded are often inconsistent through time for robust statistical analysis. 3D geometric features have been shown to be stable for assessing differences across the temporal data set. Therefore, in this article we investigate he use of a multitemporal orthophoto and digital surface model derived from satellite data for spatiotemporal classification. Our approach consists of two major steps: generating per-class probability distribution maps using the random-forest classifier with limited training samples, and making spatiotemporal inferences using an iterative 3D spatiotemporal filter operating on per-class probability maps. Our experimental results demonstrate that the proposed methods can consistently improve the individual classification results by 2%-6% and thus can be an important postclassification refinement approach.
Performance Analysis of Synergetic UAV-RIS Communication Networks
Jun 18, 2021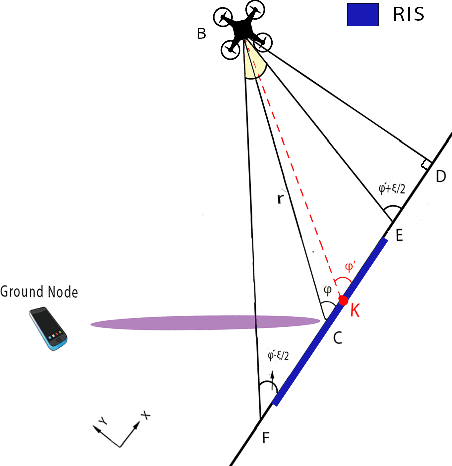
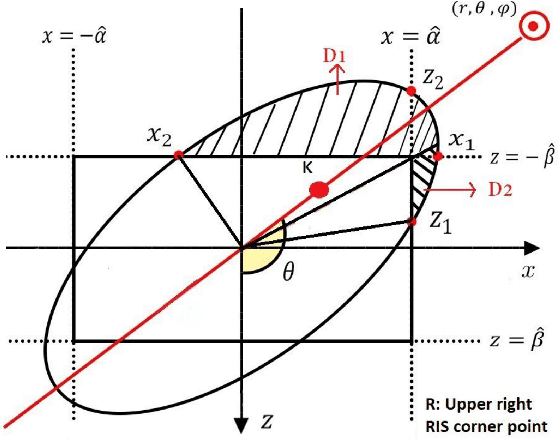
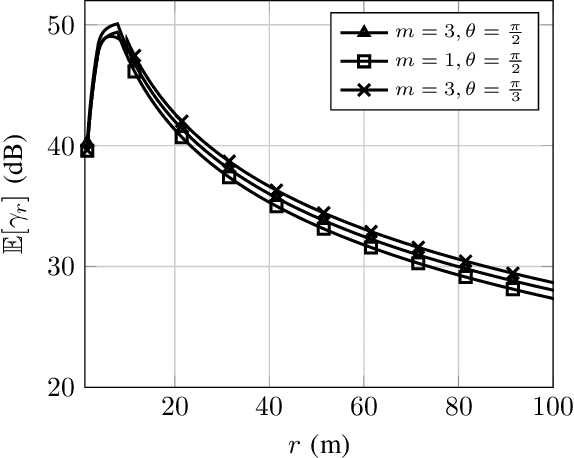
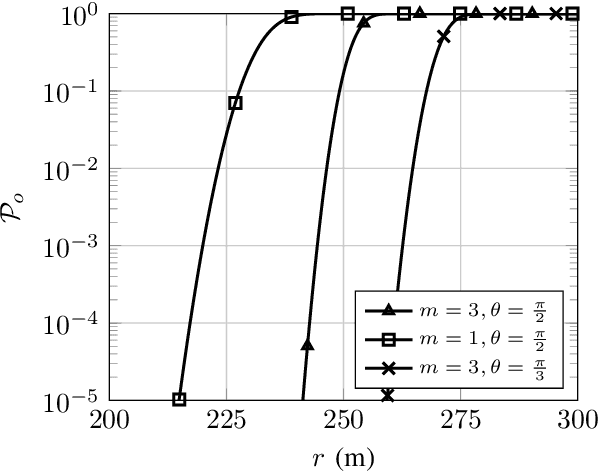
The effective integration of unmanned aerial vehicles (UAVs) in future wireless communication systems depends on the conscious use of their limited energy, which constrains their flight time. Reconfigurable intelligent surfaces (RISs) can be used in combination with UAVs with the aim to improve the communication performance without increasing complexity at the UAVs' side. In this paper, we propose a synergetic UAV-RIS communication system, utilizing a UAV with a directional antenna aiming to the RIS. Also, we present the link budget analysis and closed-form expressions for the outage probability as well as for an important second order statistical parameter of the proposed synergetic UAV-RIS communication system, the average outage duration. Finally, numerical results illustrate the effectiveness of the proposed synergetic system.
Visual Explanations from Spiking Neural Networks using Interspike Intervals
Mar 26, 2021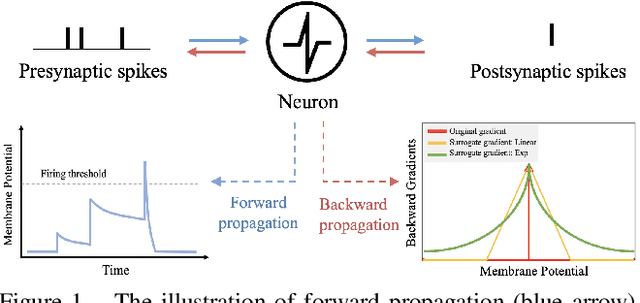
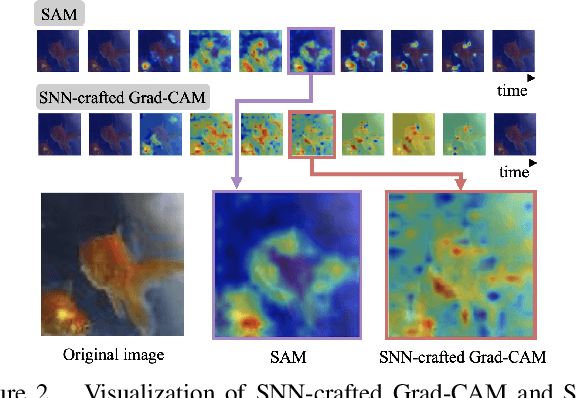
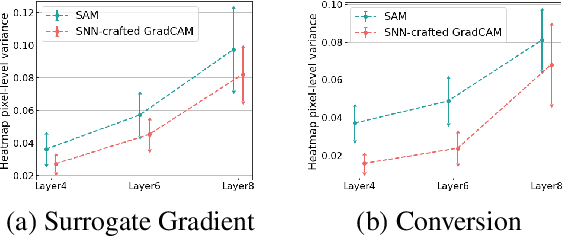
Spiking Neural Networks (SNNs) compute and communicate with asynchronous binary temporal events that can lead to significant energy savings with neuromorphic hardware. Recent algorithmic efforts on training SNNs have shown competitive performance on a variety of classification tasks. However, a visualization tool for analysing and explaining the internal spike behavior of such temporal deep SNNs has not been explored. In this paper, we propose a new concept of bio-plausible visualization for SNNs, called Spike Activation Map (SAM). The proposed SAM circumvents the non-differentiable characteristic of spiking neurons by eliminating the need for calculating gradients to obtain visual explanations. Instead, SAM calculates a temporal visualization map by forward propagating input spikes over different time-steps. SAM yields an attention map corresponding to each time-step of input data by highlighting neurons with short inter-spike interval activity. Interestingly, without both the backpropagation process and the class label, SAM highlights the discriminative region of the image while capturing fine-grained details. With SAM, for the first time, we provide a comprehensive analysis on how internal spikes work in various SNN training configurations depending on optimization types, leak behavior, as well as when faced with adversarial examples.
Robust Linear Regression: Optimal Rates in Polynomial Time
Jul 16, 2020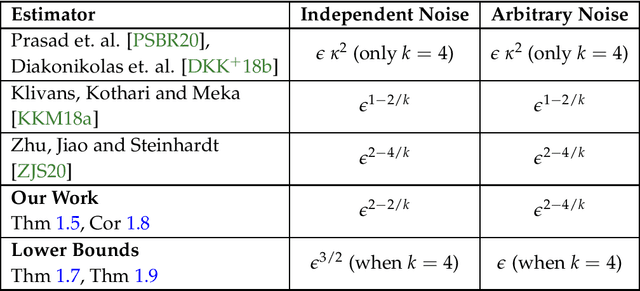
We obtain a robust and computationally efficient estimator for Linear Regression that achieves statistically optimal convergence rate under mild distributional assumptions. Concretely, we assume our data is drawn from a $k$-hypercontractive distribution and an $\epsilon$-fraction is adversarially corrupted. We then describe an estimator that converges to the optimal least-squares minimizer for the true distribution at a rate proportional to $\epsilon^{2-2/k}$, when the noise is independent of the covariates. We note that no such estimator was known prior to our work, even with access to unbounded computation. The rate we achieve is information-theoretically optimal and thus we resolve the main open question in Klivans, Kothari and Meka [COLT'18]. Our key insight is to identify an analytic condition relating the distribution over the noise and covariates that completely characterizes the rate of convergence, regardless of the noise model. In particular, we show that when the moments of the noise and covariates are negatively-correlated, we obtain the same rate as independent noise. Further, when the condition is not satisfied, we obtain a rate proportional to $\epsilon^{2-4/k}$, and again match the information-theoretic lower bound. Our central technical contribution is to algorithmically exploit independence of random variables in the "sum-of-squares" framework by formulating it as a polynomial identity.
A Simple Model for Portable and Fast Prediction of Execution Time and Power Consumption of GPU Kernels
Jan 20, 2020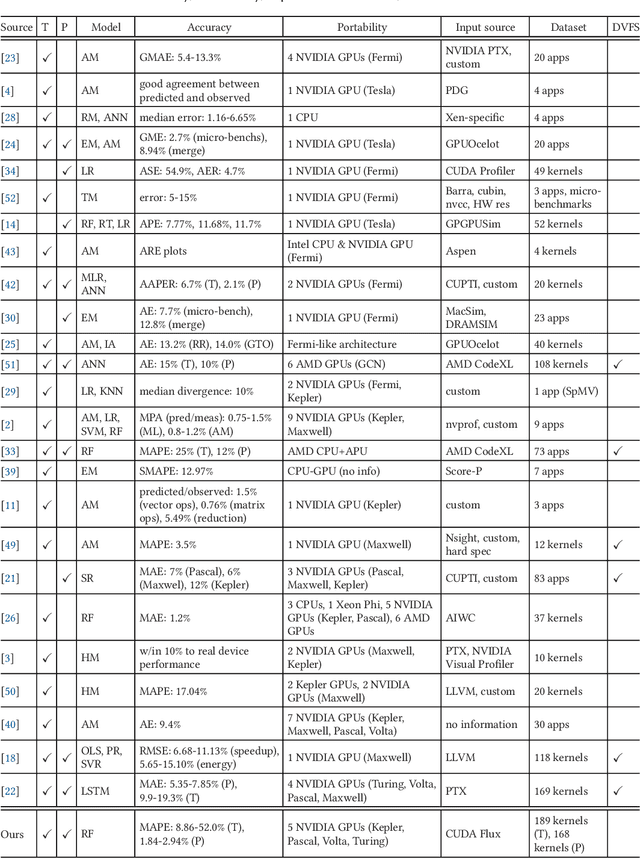
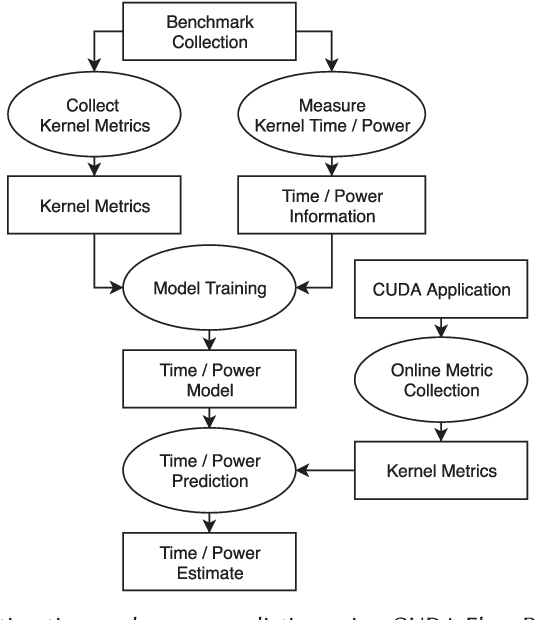
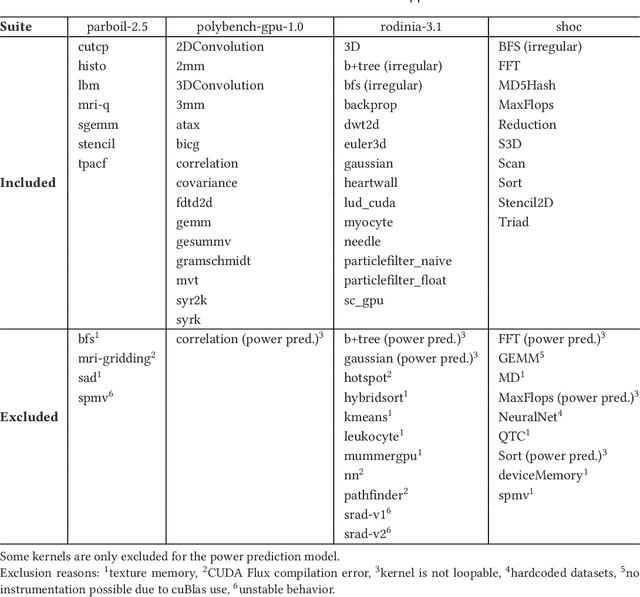
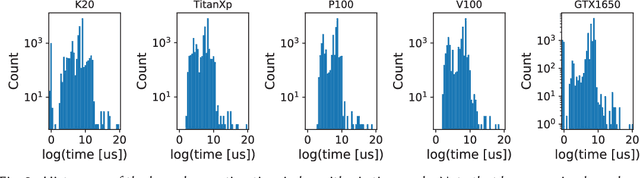
Characterizing compute kernel execution behavior on GPUs for efficient task scheduling is a non trivial task. We address this with a simple model enabling portable and fast predictions among different GPUs using only hardware-independent features extracted. This model is built based on random forests using 189 individual compute kernels from benchmarks such as Parboil, Rodinia, Polybench-GPU and SHOC. Evaluation of the model performance using cross-validation yields a median Mean Average Percentage Error (MAPE) of [13.45%, 44.56%] and [1.81%, 2.91%], for time respectively power prediction on five different GPUs, while latency for a single prediction varies between 0.1 and 0.2 seconds.
Modeling Treatment Delays for Patients using Feature Label Pairs in a Time Series
Dec 03, 2018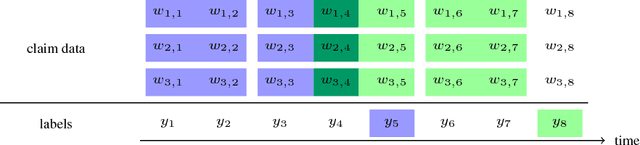
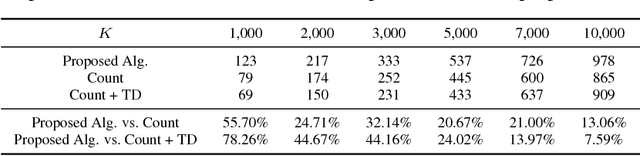
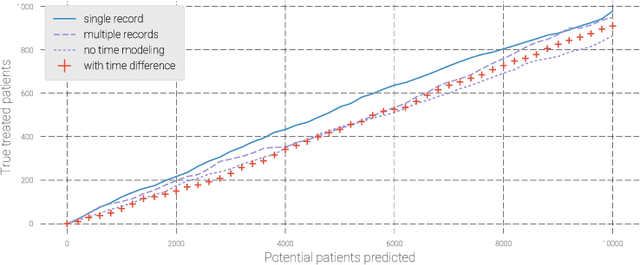
Pharmaceutical targeting is one of key inputs for making sales and marketing strategy planning. Targeting list is built on predicting physician's sales potential of certain type of patient. In this paper, we present a time-sensitive targeting framework leveraging time series model to predict patient's disease and treatment progression. We create time features by extracting service history within a certain period, and record whether the event happens in a look-forward period. Such feature-label pairs are examined across all time periods and all patients to train a model. It keeps the inherent order of services and evaluates features associated to the imminent future, which contribute to improved accuracy.
Real-time coherent diffraction inversion using deep generative networks
Jun 07, 2018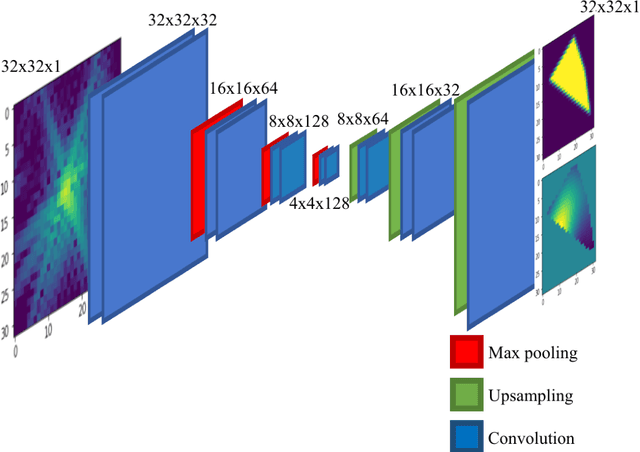
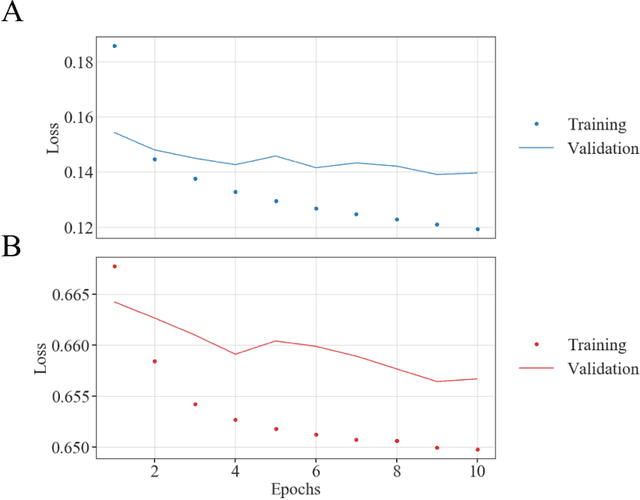
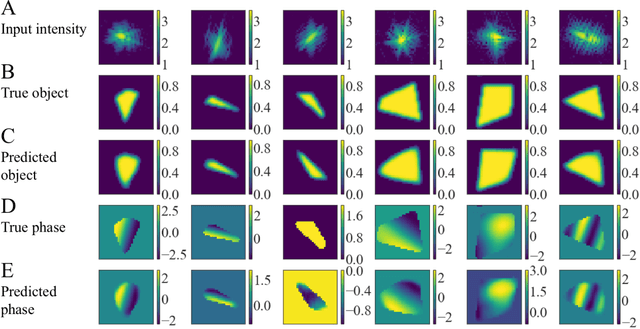
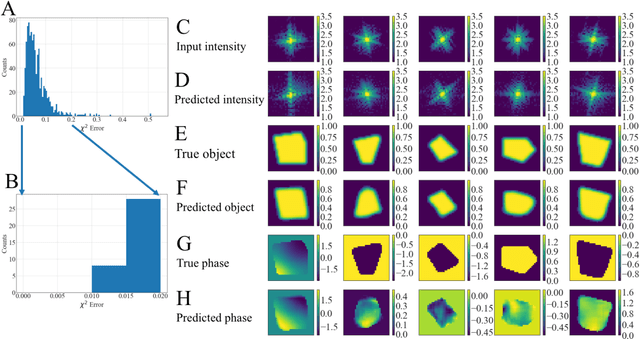
Phase retrieval, or the process of recovering phase information in reciprocal space to reconstruct images from measured intensity alone, is the underlying basis to a variety of imaging applications including coherent diffraction imaging (CDI). Typical phase retrieval algorithms are iterative in nature, and hence, are time-consuming and computationally expensive, precluding real-time imaging. Furthermore, iterative phase retrieval algorithms struggle to converge to the correct solution especially in the presence of strong phase structures. In this work, we demonstrate the training and testing of CDI NN, a pair of deep deconvolutional networks trained to predict structure and phase in real space of a 2D object from its corresponding far-field diffraction intensities alone. Once trained, CDI NN can invert a diffraction pattern to an image within a few milliseconds of compute time on a standard desktop machine, opening the door to real-time imaging.
Omnimatte: Associating Objects and Their Effects in Video
May 14, 2021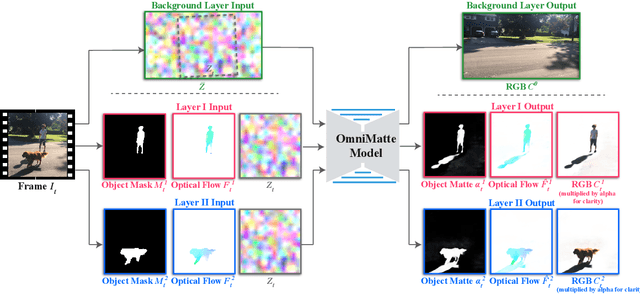



Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects---shadows, reflections, generated smoke, etc---are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject---an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic---it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject.
Compute RAMs: Adaptable Compute and Storage Blocks for DL-Optimized FPGAs
Jul 19, 2021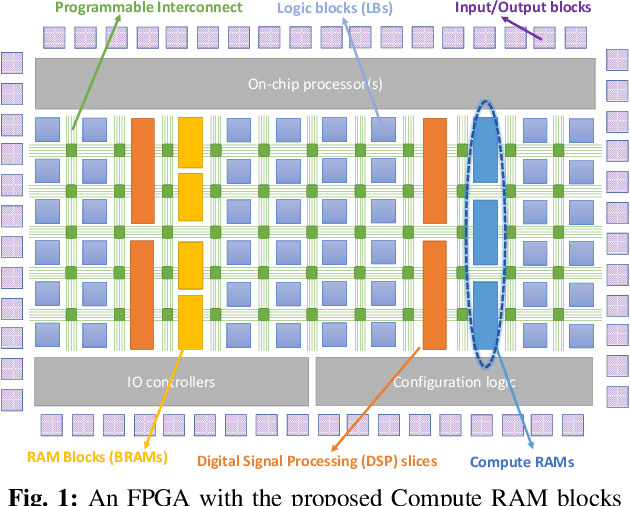
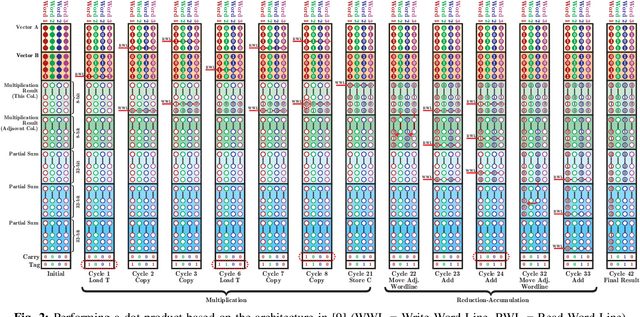
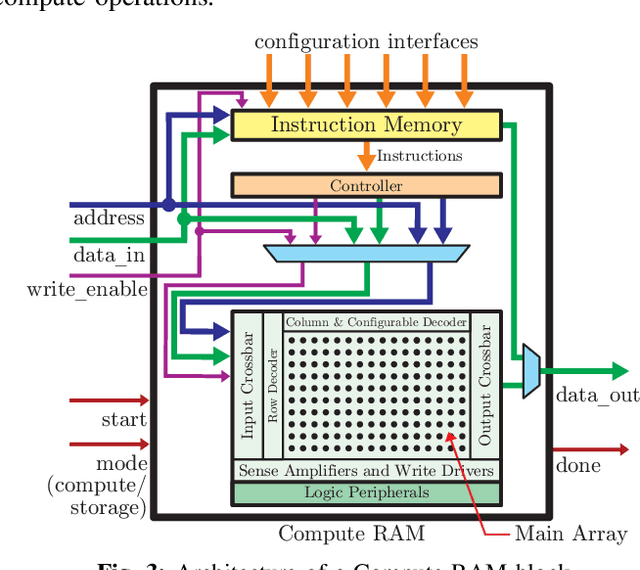
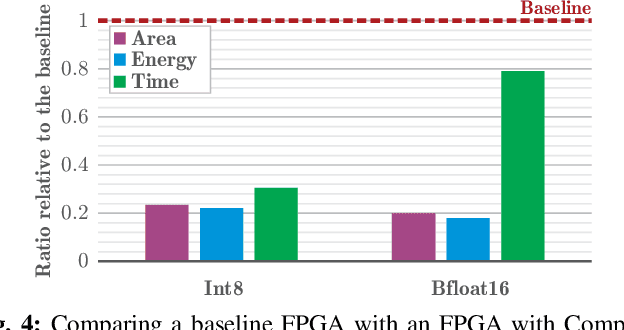
The configurable building blocks of current FPGAs -- Logic blocks (LBs), Digital Signal Processing (DSP) slices, and Block RAMs (BRAMs) -- make them efficient hardware accelerators for the rapid-changing world of Deep Learning (DL). Communication between these blocks happens through an interconnect fabric consisting of switching elements spread throughout the FPGA. In this paper, a new block, Compute RAM, is proposed. Compute RAMs provide highly-parallel processing-in-memory (PIM) by combining computation and storage capabilities in one block. Compute RAMs can be integrated in the FPGA fabric just like the existing FPGA blocks and provide two modes of operation (storage or compute) that can be dynamically chosen. They reduce power consumption by reducing data movement, provide adaptable precision support, and increase the effective on-chip memory bandwidth. Compute RAMs also help increase the compute density of FPGAs. In our evaluation of addition, multiplication and dot-product operations across multiple data precisions (int4, int8 and bfloat16), we observe an average savings of 80% in energy consumption, and an improvement in execution time ranging from 20% to 80%. Adding Compute RAMs can benefit non-DL applications as well, and make FPGAs more efficient, flexible, and performant accelerators.