 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inferring micro-bubble dynamics with physics-informed deep learning
May 15, 2021
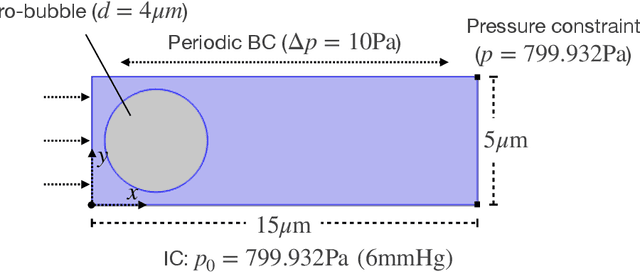
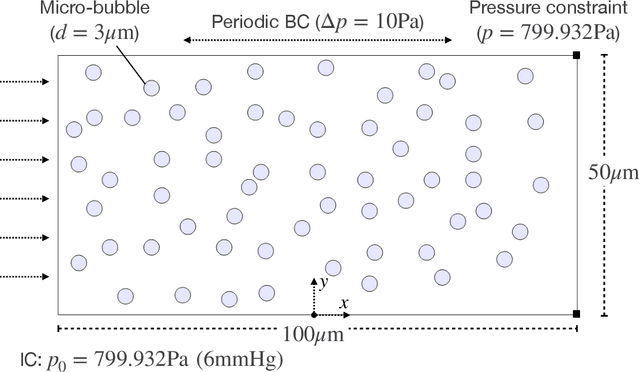
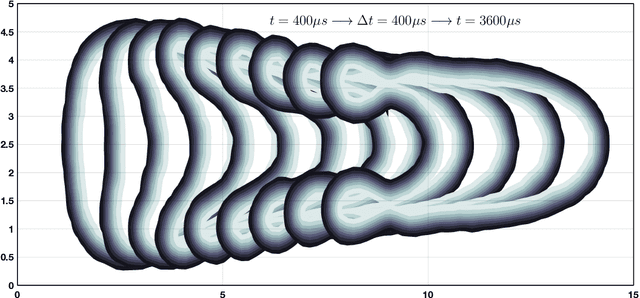
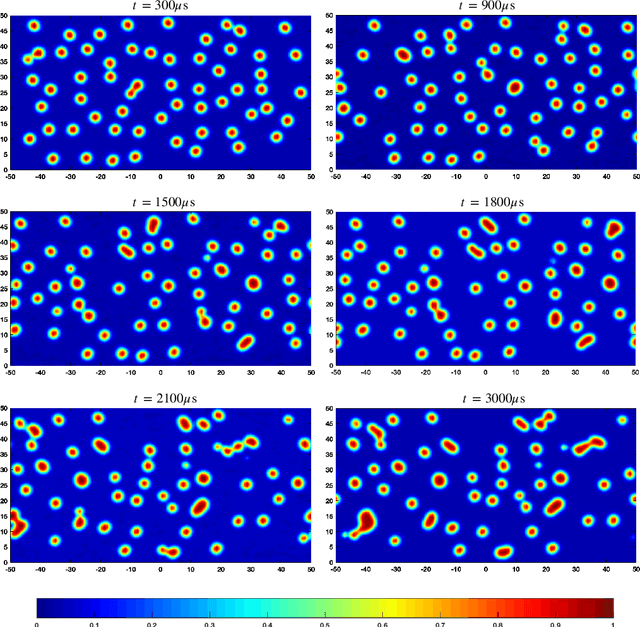
Micro-bubbles and bubbly flows are widely observed and applied to medicine, involves deformation, rupture, and collision of bubbles, phase mixture, etc. We study bubble dynamics by setting up two numerical simulation cases: bubbly flow with a single bubble and multiple bubbles, both confined in the microtube, with parameters corresponding to their medical backgrounds. Both the cases have their medical background applications. Multiphase flow simulation requires high computation accuracy due to possible component losses that may be caused by sparse meshing during the computation. Hence, data-driven methods can be adopted as a useful tool. Based on physics-informed neural networks (PINNs), we propose a novel deep learning framework BubbleNet, which entails three main parts: deep neural networks (DNN) with sub nets for predicting different physics fields; the physics-informed part, with the fluid continuum condition encoded within; the time discretized normalizer (TDN), an algorithm to normalize field data per time step before training. We apply the traditional DNN and our BubbleNet to train the simulation data and predict the physics fields of both the two bubbly flow cases. Results indicate our framework can predict the physics fields more accurately, estimating the prediction absolute errors. The proposed network can potentially be applied to many other engineering fields.
TumorCP: A Simple but Effective Object-Level Data Augmentation for Tumor Segmentation
Jul 21, 2021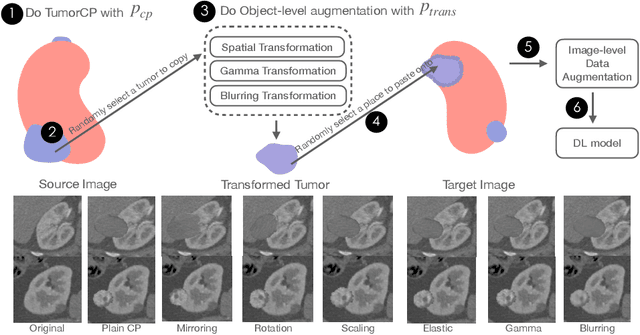
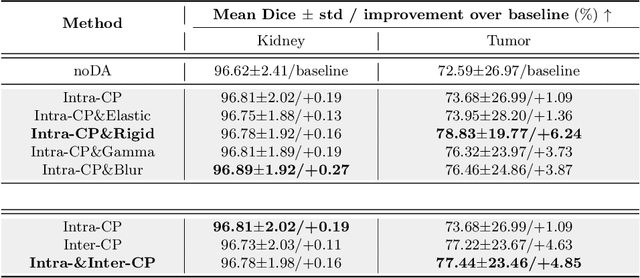


Deep learning models are notoriously data-hungry. Thus, there is an urging need for data-efficient techniques in medical image analysis, where well-annotated data are costly and time consuming to collect. Motivated by the recently revived "Copy-Paste" augmentation, we propose TumorCP, a simple but effective object-level data augmentation method tailored for tumor segmentation. TumorCP is online and stochastic, providing unlimited augmentation possibilities for tumors' subjects, locations, appearances, as well as morphologies. Experiments on kidney tumor segmentation task demonstrate that TumorCP surpasses the strong baseline by a remarkable margin of 7.12% on tumor Dice. Moreover, together with image-level data augmentation, it beats the current state-of-the-art by 2.32% on tumor Dice. Comprehensive ablation studies are performed to validate the effectiveness of TumorCP. Meanwhile, we show that TumorCP can lead to striking improvements in extremely low-data regimes. Evaluated with only 10% labeled data, TumorCP significantly boosts tumor Dice by 21.87%. To the best of our knowledge, this is the very first work exploring and extending the "Copy-Paste" design in medical imaging domain. Code is available at: https://github.com/YaoZhang93/TumorCP.
Visual Explanations from Spiking Neural Networks using Interspike Intervals
Mar 26, 2021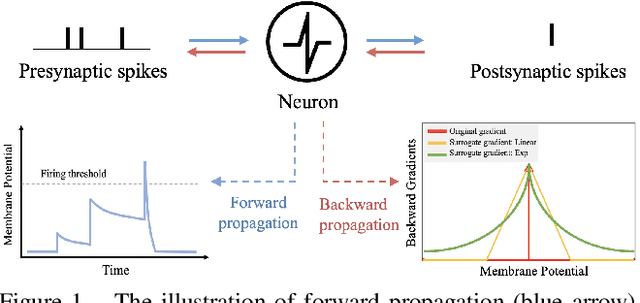
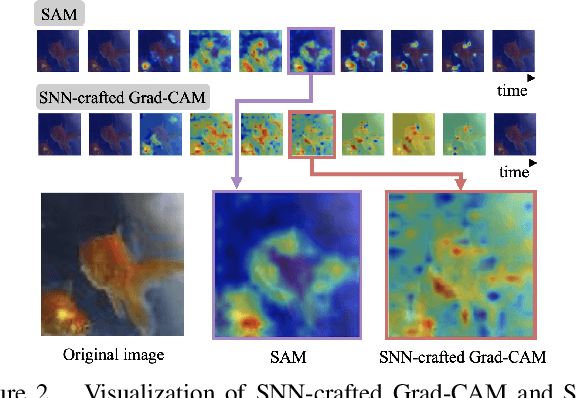
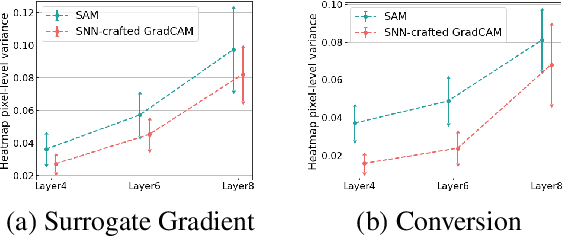
Spiking Neural Networks (SNNs) compute and communicate with asynchronous binary temporal events that can lead to significant energy savings with neuromorphic hardware. Recent algorithmic efforts on training SNNs have shown competitive performance on a variety of classification tasks. However, a visualization tool for analysing and explaining the internal spike behavior of such temporal deep SNNs has not been explored. In this paper, we propose a new concept of bio-plausible visualization for SNNs, called Spike Activation Map (SAM). The proposed SAM circumvents the non-differentiable characteristic of spiking neurons by eliminating the need for calculating gradients to obtain visual explanations. Instead, SAM calculates a temporal visualization map by forward propagating input spikes over different time-steps. SAM yields an attention map corresponding to each time-step of input data by highlighting neurons with short inter-spike interval activity. Interestingly, without both the backpropagation process and the class label, SAM highlights the discriminative region of the image while capturing fine-grained details. With SAM, for the first time, we provide a comprehensive analysis on how internal spikes work in various SNN training configurations depending on optimization types, leak behavior, as well as when faced with adversarial examples.
Dynamic Sparse Training for Deep Reinforcement Learning
Jun 08, 2021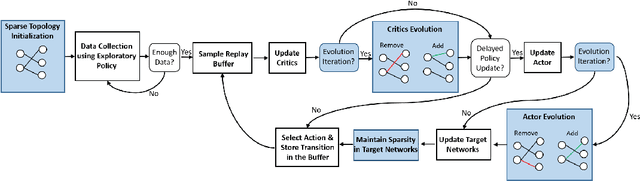
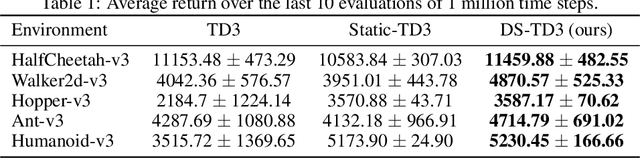
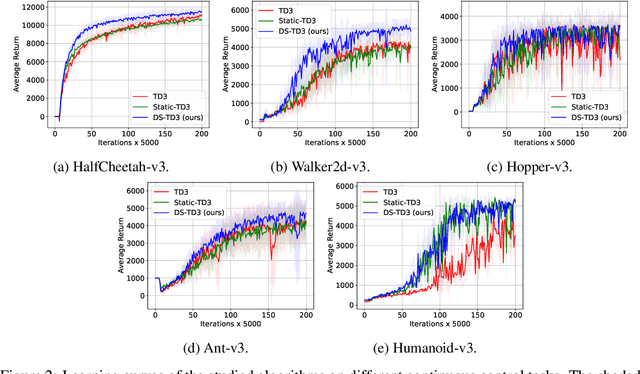

Deep reinforcement learning has achieved significant success in many decision-making tasks in various fields. However, it requires a large training time of dense neural networks to obtain a good performance. This hinders its applicability on low-resource devices where memory and computation are strictly constrained. In a step towards enabling deep reinforcement learning agents to be applied to low-resource devices, in this work, we propose for the first time to dynamically train deep reinforcement learning agents with sparse neural networks from scratch. We adopt the evolution principles of dynamic sparse training in the reinforcement learning paradigm and introduce a training algorithm that optimizes the sparse topology and the weight values jointly to dynamically fit the incoming data. Our approach is easy to be integrated into existing deep reinforcement learning algorithms and has many favorable advantages. First, it allows for significant compression of the network size which reduces the memory and computation costs substantially. This would accelerate not only the agent inference but also its training process. Second, it speeds up the agent learning process and allows for reducing the number of required training steps. Third, it can achieve higher performance than training the dense counterpart network. We evaluate our approach on OpenAI gym continuous control tasks. The experimental results show the effectiveness of our approach in achieving higher performance than one of the state-of-art baselines with a 50\% reduction in the network size and floating-point operations (FLOPs). Moreover, our proposed approach can reach the same performance achieved by the dense network with a 40-50\% reduction in the number of training steps.
An efficient approach for tracking the aerosol-cloud interactions formed by ship emissions using GOES-R satellite imagery and AIS ship tracking information
Aug 12, 2021
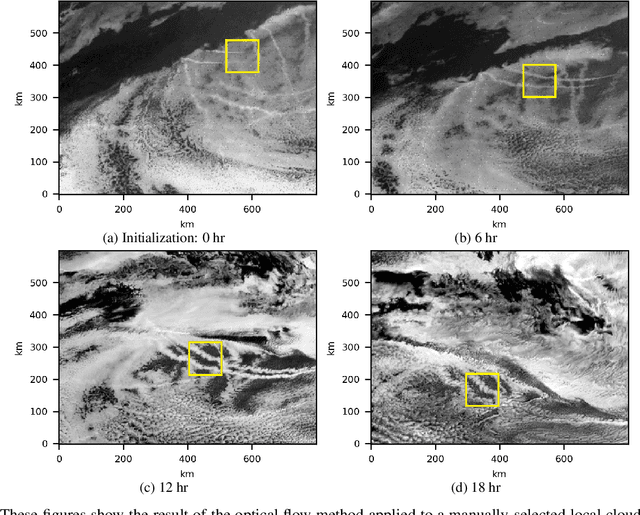

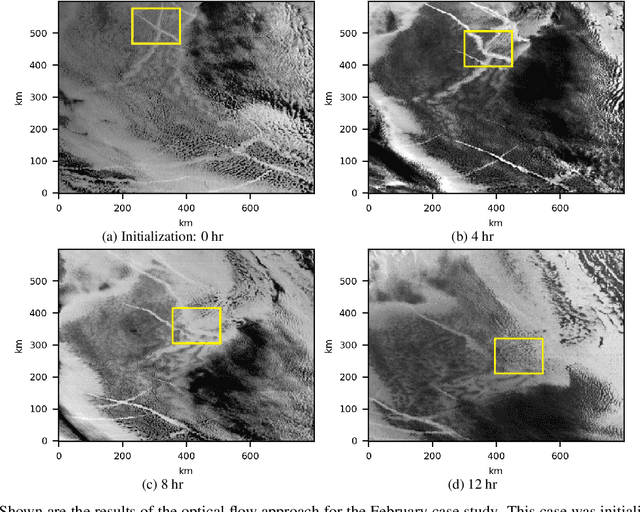
Ship emissions can form linear cloud features, or ship tracks, when atmospheric water vapor condenses on aerosols in the ship exhaust. These features are of interest because they are observable and traceable examples of marine cloud brightening, a mechanism that has been studied as a potential approach for solar climate intervention. Ship tracks can be observed throughout the diurnal cycle via space-borne assets like the Advanced Baseline Imagers on the National Oceanic and Atmospheric Administration Geostationary Operational Environmental Satellites, the GOES-R series. Due to complex atmospheric dynamics, it can be difficult to track these aerosol perturbations over space and time to precisely characterize how long a single emission source can significantly contribute to indirect radiative forcing. We combine GOES-17 satellite imagery with ship location information to demonstrate two feasible methods of tracing the trajectories of ship-emitted aerosols after they begin mixing with low boundary layer clouds in three test cases. The first method uses the parcel trajectory model HYSPLIT, which was driven by well-studied physical processes but often could not follow the ship track beyond 8 hours. The second method uses the image processing technique, optical flow, which could follow the track throughout its lifetime, but requires high contrast features for best performance. These approaches show that ship tracks persist as visible, linear features beyond 9 hr and sometimes longer than 24 hr. This research sets the stage for a more thorough exploration of the atmospheric conditions and exhaust compositions that produce ship tracks and factors that determine track persistence.
Making grains tangible: microtouch for microsound
Jul 27, 2021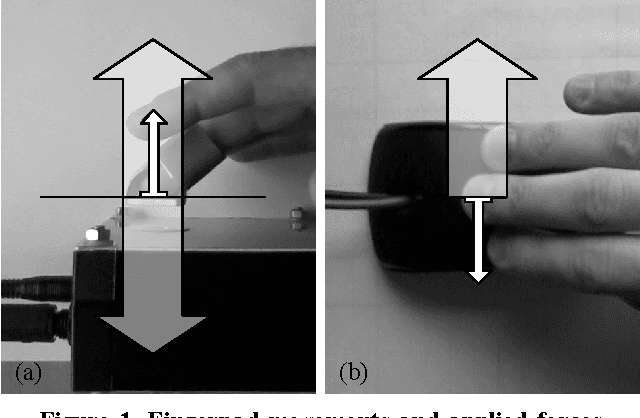

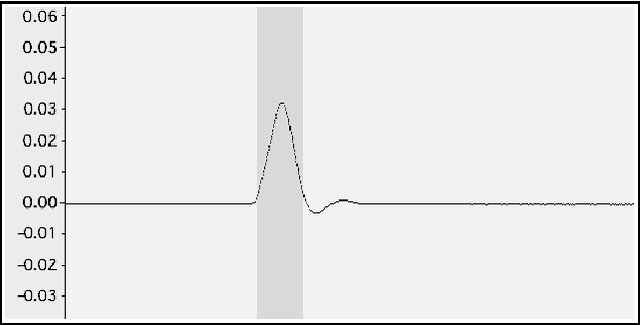
This paper proposes a new research direction for the large family of instrumental musical interfaces where sound is generated using digital granular synthesis, and where interaction and control involve the (fine) operation of stiff, flat contact surfaces. First, within a historical context, a general absence of, and clear need for, tangible output that is dynamically instantiated by the grain-generating process itself is identified. Second, to fill this gap, a concrete general approach is proposed based on the careful construction of non-vibratory and vibratory force pulses, in a one-to-one relationship with sonic grains. An informal pilot psychophysics experiment initiating the approach was conducted, which took into account the two main cases for applying forces to the human skin: perpendicular, and lateral. Initial results indicate that the force pulse approach can enable perceivably multidimensional, tangible display of the ongoing grain-generating process. Moreover, it was found that this can be made to meaningfully happen (in real time) in the same timescale of basic sonic grain generation. This is not a trivial property, and provides an important and positive fundament for further developing this type of enhanced display. It also leads to the exciting prospect of making arbitrary sonic grains actual physical manipulanda.
Florida Wildlife Camera Trap Dataset
Jun 23, 2021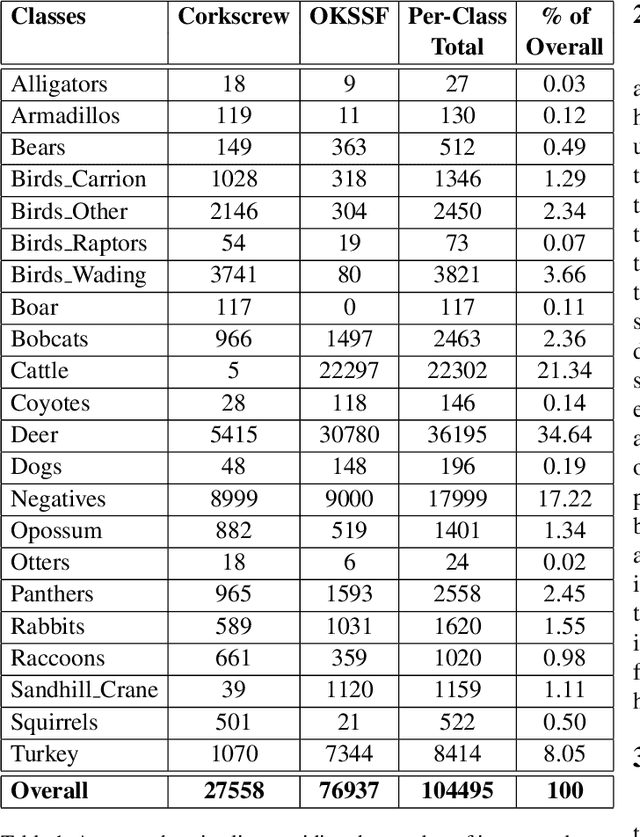

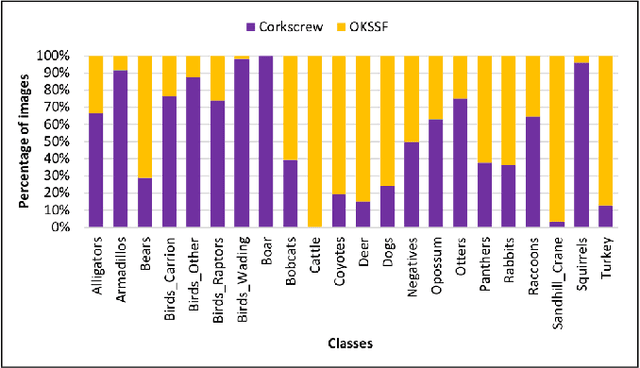

Trail camera imagery has increasingly gained popularity amongst biologists for conservation and ecological research. Minimal human interference required to operate camera traps allows capturing unbiased species activities. Several studies - based on human and wildlife interactions, migratory patterns of various species, risk of extinction in endangered populations - are limited by the lack of rich data and the time-consuming nature of manually annotating trail camera imagery. We introduce a challenging wildlife camera trap classification dataset collected from two different locations in Southwestern Florida, consisting of 104,495 images featuring visually similar species, varying illumination conditions, skewed class distribution, and including samples of endangered species, i.e. Florida panthers. Experimental evaluations with ResNet-50 architecture indicate that this image classification-based dataset can further push the advancements in wildlife statistical modeling. We will make the dataset publicly available.
A unified framework for coordination of thermostatically controlled loads
Aug 12, 2021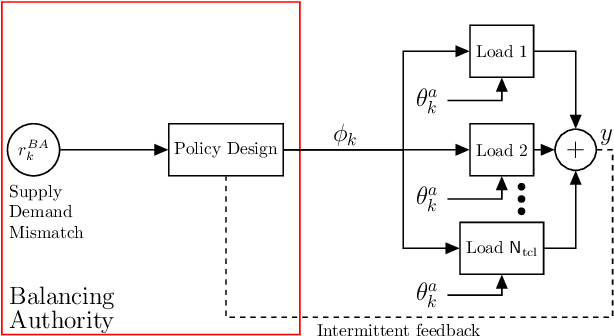
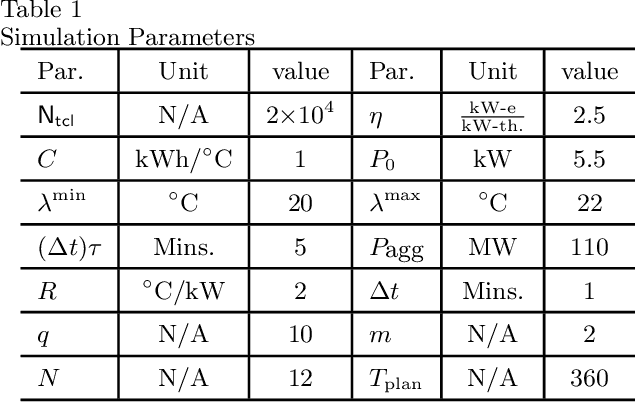
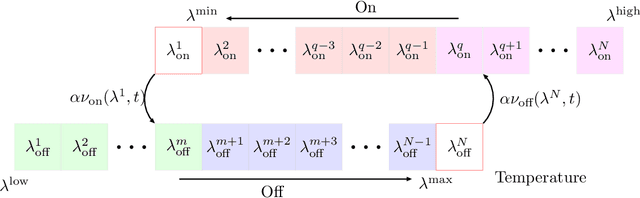
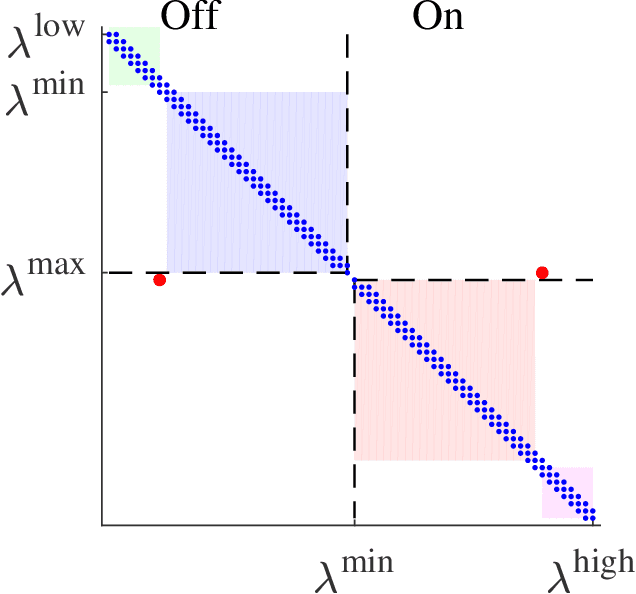
A collection of thermostatically controlled loads (TCLs) -- such as air conditioners and water heaters -- can vary their power consumption within limits to help the balancing authority of a power grid maintain demand supply balance. Doing so requires loads to coordinate their on/off decisions so that the aggregate power consumption profile tracks a grid-supplied reference. At the same time, each consumer's quality of service (QoS) must be maintained. While there is a large body of work on TCL coordination, there are several limitations. One is that they do not provide guarantees on the reference tracking performance and QoS maintenance. A second limitation of past work is that they do not provide a means to compute a suitable reference signal for power demand of a collection of TCLs. In this work we provide a framework that addresses these weaknesses. The framework enables coordination of an arbitrary number of TCLs that: (i) is computationally efficient, (ii) is implementable at the TCLs with local feedback and low communication, and (iii) enables reference tracking by the collection while ensuring that temperature and cycling constraints are satisfied at every TCL at all times. The framework is based on a Markov model obtained by discretizing a pair of Fokker-Planck equations derived in earlier work by Malhame and Chong [21]. We then use this model to design randomized policies for TCLs. The balancing authority broadcasts the same policy to all TCLs, and each TCL implements this policy which requires only local measurement to make on/off decisions. Simulation results are provided to support these claims.
Simple and Cheap Setup for Timing Tapping Responses Synchronized to Auditory Stimuli
Apr 30, 2021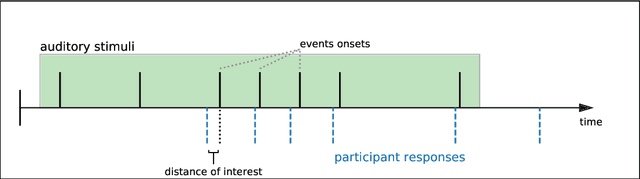
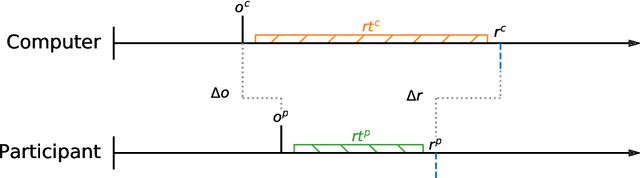
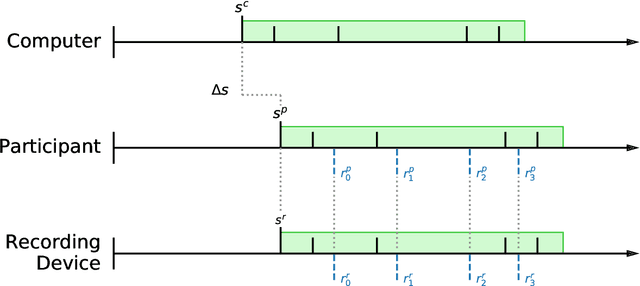
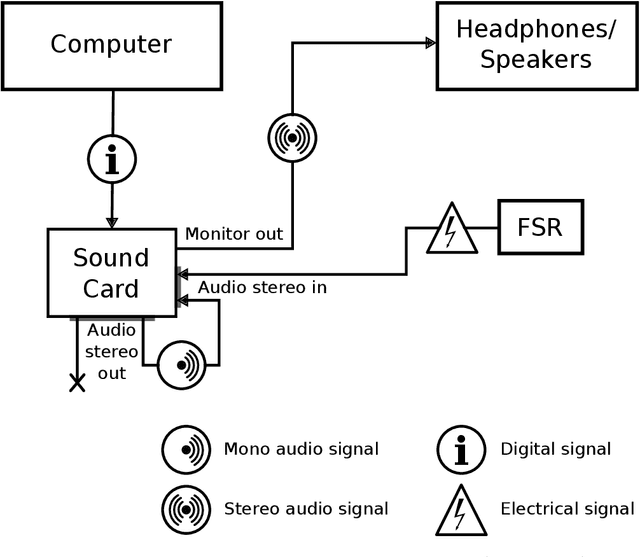
Measuring human capabilities to synchronize in time, adapt to perturbations to timing sequences or reproduce time intervals often require experimental setups that allow recording response times with millisecond precision. Most setups present auditory stimuli using either MIDI devices or specialized hardware such as Arduino and are often expensive or require calibration and advanced programming skills. Here, we present in detail an experimental setup that only requires an external sound card and minor electronic skills, works on a conventional PC, is cheaper than alternatives and requires almost no programming skills. It is intended for presenting any auditory stimuli and recording tapping response times with within 2 milliseconds precision (up to -2ms lag). This paper shows why desired accuracy in recording response times against auditory stimuli is difficult to achieve in conventional computer setups, presents an experimental setup to overcome this and explains in detail how to set it up and use the provided code. Finally, the code for analyzing the recorded tapping responses was evaluated, showing that no spurious or missing events were found in 94% of the analyzed recordings.
Predicting Critical Nodes in Temporal Networks by Dynamic Graph Convolutional Networks
Jul 06, 2021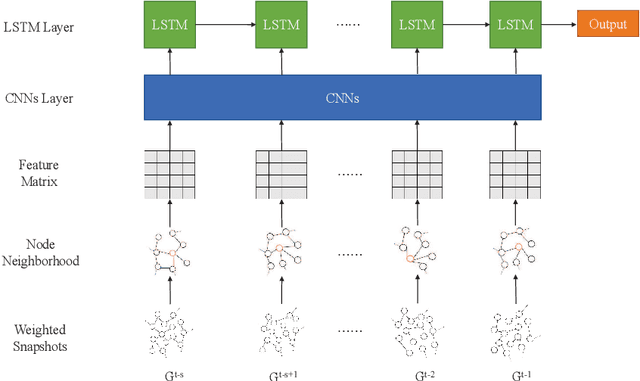
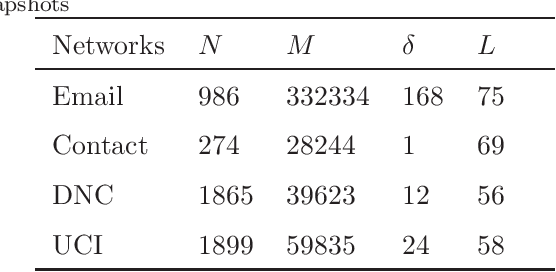
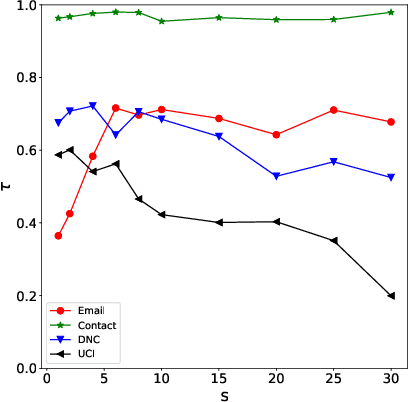

Many real-world systems can be expressed in temporal networks with nodes playing far different roles in structure and function and edges representing the relationships between nodes. Identifying critical nodes can help us control the spread of public opinions or epidemics, predict leading figures in academia, conduct advertisements for various commodities, and so on. However, it is rather difficult to identify critical nodes because the network structure changes over time in temporal networks. In this paper, considering the sequence topological information of temporal networks, a novel and effective learning framework based on the combination of special GCNs and RNNs is proposed to identify nodes with the best spreading ability. The effectiveness of the approach is evaluated by weighted Susceptible-Infected-Recovered model. Experimental results on four real-world temporal networks demonstrate that the proposed method outperforms both traditional and deep learning benchmark methods in terms of the Kendall $\tau$ coefficient and top $k$ hit rate.