 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 05, 2021
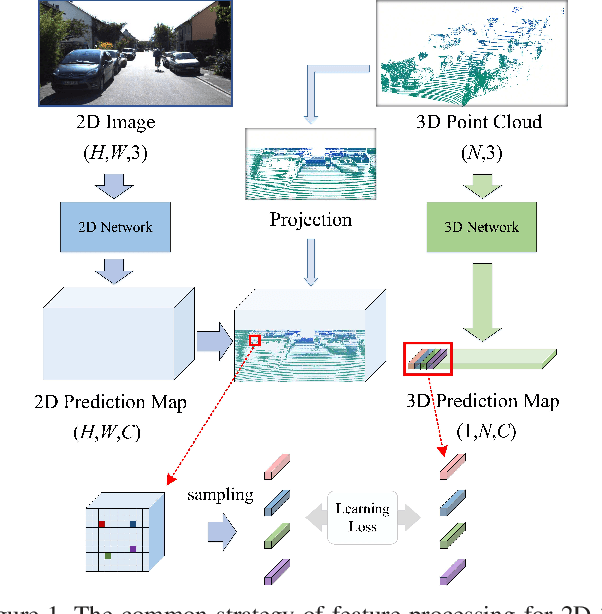
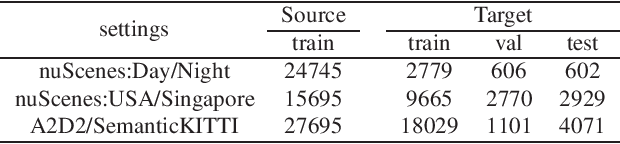
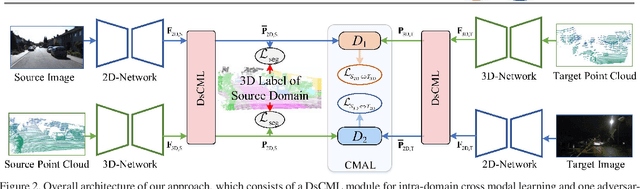
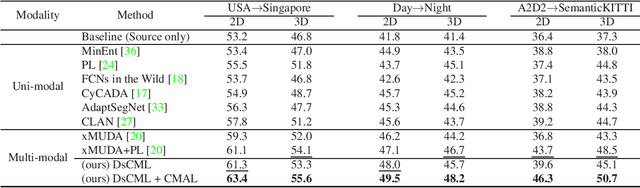
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
Advances in Trajectory Optimization for Space Vehicle Control
Aug 05, 2021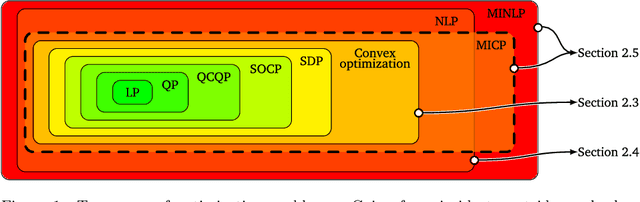
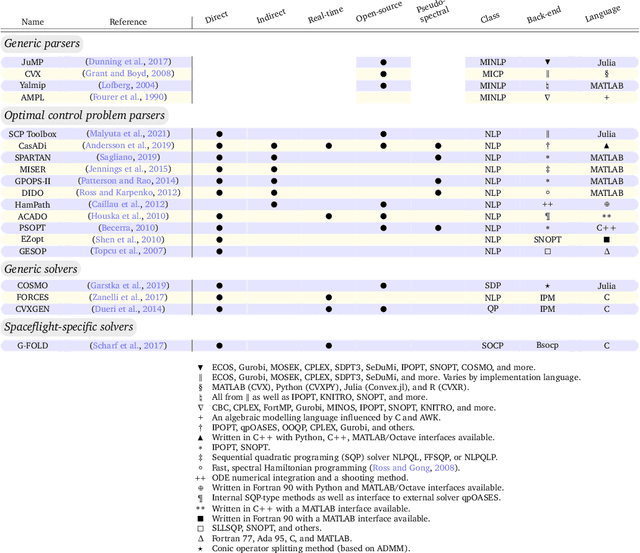
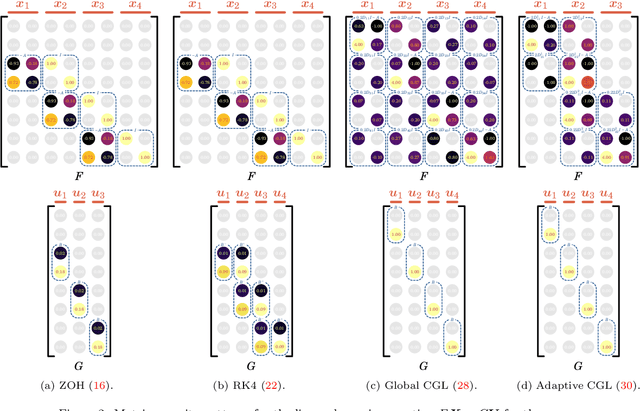
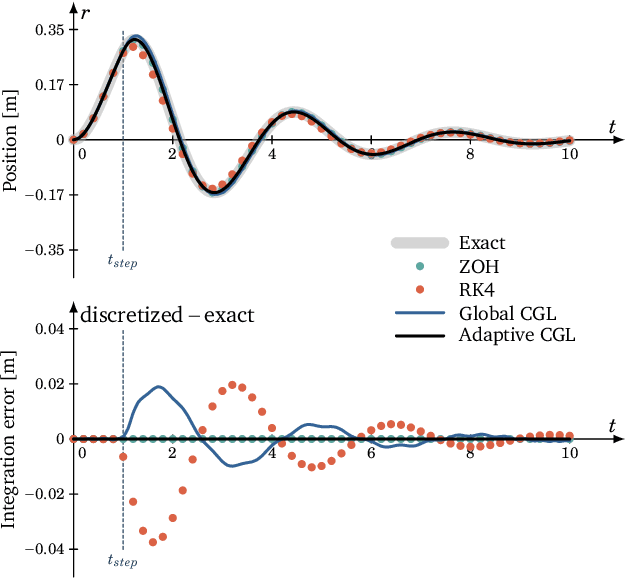
Space mission design places a premium on cost and operational efficiency. The search for new science and life beyond Earth calls for spacecraft that can deliver scientific payloads to geologically rich yet hazardous landing sites. At the same time, the last four decades of optimization research have put a suite of powerful optimization tools at the fingertips of the controls engineer. As we enter the new decade, optimization theory, algorithms, and software tooling have reached a critical mass to start seeing serious application in space vehicle guidance and control systems. This survey paper provides a detailed overview of recent advances, successes, and promising directions for optimization-based space vehicle control. The considered applications include planetary landing, rendezvous and proximity operations, small body landing, constrained reorientation, endo-atmospheric flight including ascent and re-entry, and orbit transfer and injection. The primary focus is on the last ten years of progress, which have seen a veritable rise in the number of applications using three core technologies: lossless convexification, sequential convex programming, and model predictive control. The reader will come away with a well-rounded understanding of the state-of-the-art in each space vehicle control application, and will be well positioned to tackle important current open problems using convex optimization as a core technology.
Hitting Time of Stochastic Gradient Langevin Dynamics to Stationary Points: A Direct Analysis
Apr 30, 2019Stochastic gradient Langevin dynamics (SGLD) is a fundamental algorithm in stochastic optimization. Recent work by Zhang et al. [2017] presents an analysis for the hitting time of SGLD for the first and second order stationary points. The proof in Zhang et al. [2017] is a two-stage procedure through bounding the Cheeger's constant, which is rather complicated and leads to loose bounds. In this paper, using intuitions from stochastic differential equations, we provide a direct analysis for the hitting times of SGLD to the first and second order stationary points. Our analysis is straightforward. It only relies on basic linear algebra and probability theory tools. Our direct analysis also leads to tighter bounds comparing to Zhang et al. [2017] and shows the explicit dependence of the hitting time on different factors, including dimensionality, smoothness, noise strength, and step size effects. Under suitable conditions, we show that the hitting time of SGLD to first-order stationary points can be dimension-independent. Moreover, we apply our analysis to study several important online estimation problems in machine learning, including linear regression, matrix factorization, and online PCA.
Generating stable molecules using imitation and reinforcement learning
Jul 11, 2021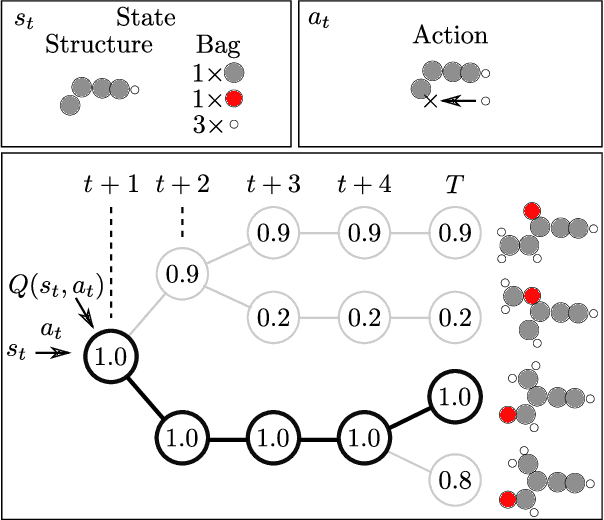
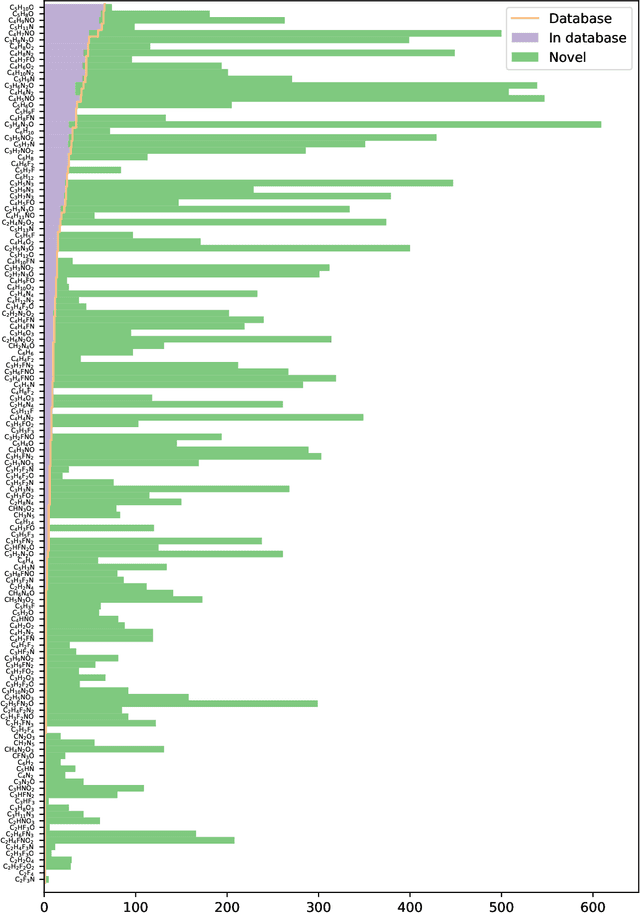
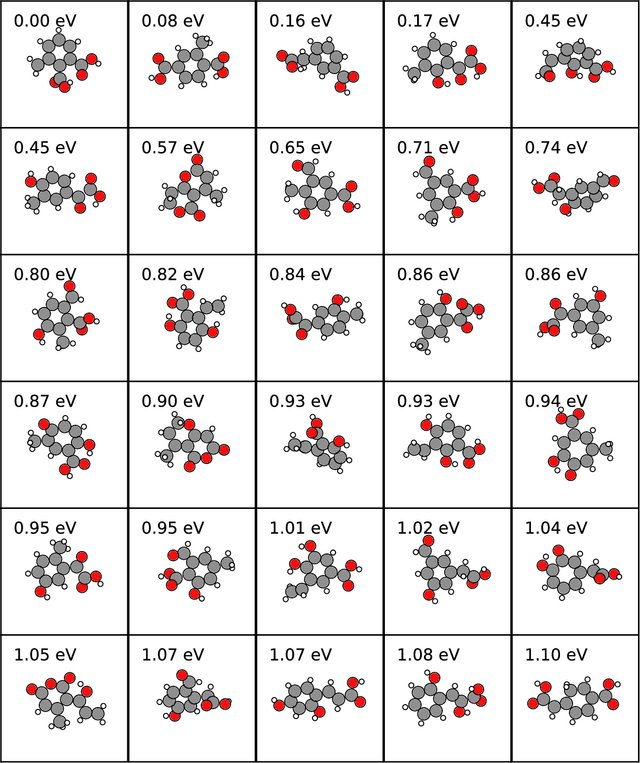
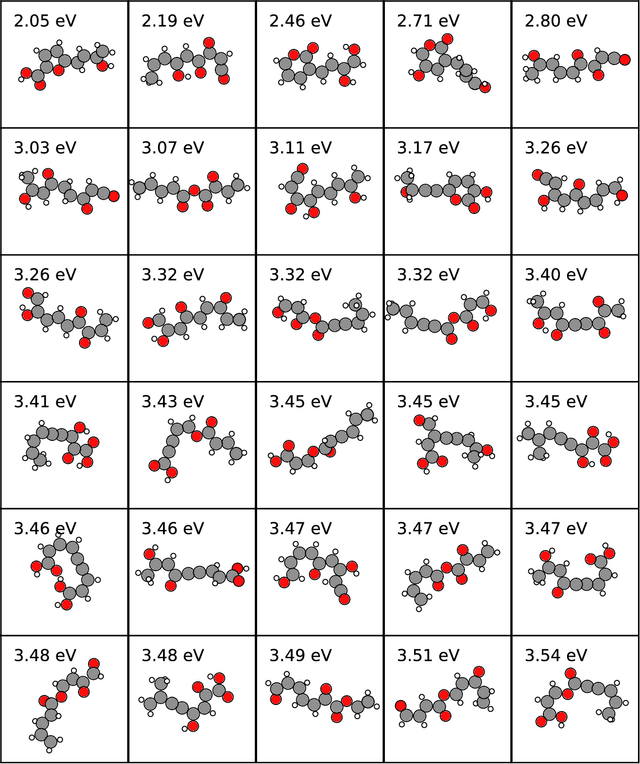
Chemical space is routinely explored by machine learning methods to discover interesting molecules, before time-consuming experimental synthesizing is attempted. However, these methods often rely on a graph representation, ignoring 3D information necessary for determining the stability of the molecules. We propose a reinforcement learning approach for generating molecules in cartesian coordinates allowing for quantum chemical prediction of the stability. To improve sample-efficiency we learn basic chemical rules from imitation learning on the GDB-11 database to create an initial model applicable for all stoichiometries. We then deploy multiple copies of the model conditioned on a specific stoichiometry in a reinforcement learning setting. The models correctly identify low energy molecules in the database and produce novel isomers not found in the training set. Finally, we apply the model to larger molecules to show how reinforcement learning further refines the imitation learning model in domains far from the training data.
Real-Time Shape Tracking of Facial Landmarks
Jul 14, 2018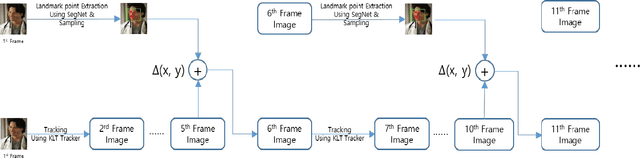
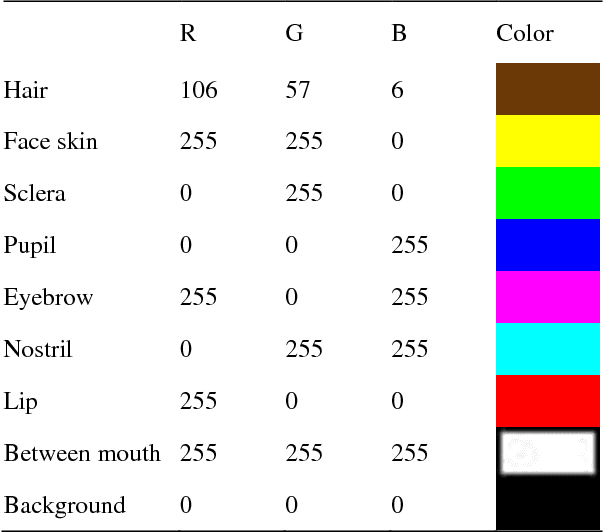
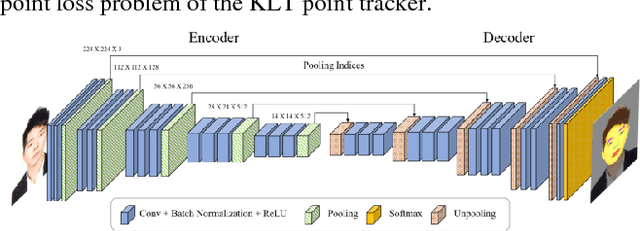
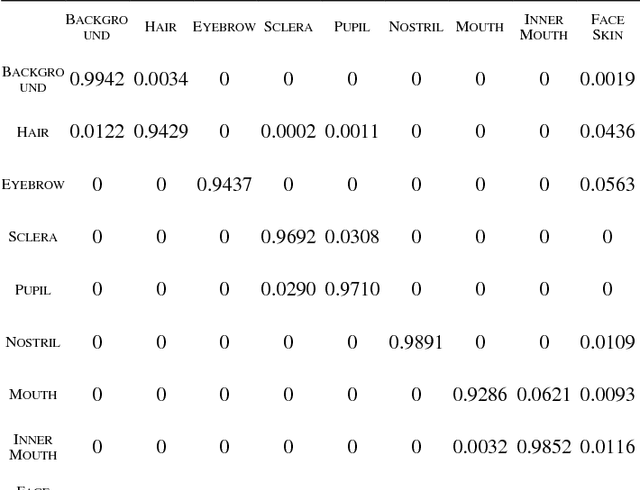
Detection of facial landmarks and accurate tracking of their shape are essential in real-time virtual makeup applications, where users can see the makeups effect by moving their face in different directions. Typical face tracking techniques detect diverse facial landmarks and track them using a point tracker such as the Kanade-Lucas-Tomasi (KLT) point tracker. Typically, 5 or 64 points are used for tracking a face. Even though these points are sufficient to track the approximate locations of facial landmarks, they are not sufficient to track the exact shape of facial landmarks. In this paper, we propose a method that can track the exact shape of facial landmarks in real-time by combining a deep learning technique and a point tracker. We detect facial landmarks accurately using SegNet, which performs semantic segmentation based on deep learning. Edge points of detected landmarks are tracked using the KLT point tracker. In spite of its popularity, the KLT point tracker suffers from the point loss problem. We solve this problem by executing SegNet periodically to calculate the shape of facial landmarks. That is, by combining the two techniques, we can avoid the computational overhead of SegNet for real-time shape tracking and the point loss problem of the KLT point tracker. We performed several experiments to evaluate the performance of our method and report some of the results herein.
A reinforcement learning approach to resource allocation in genomic selection
Jul 22, 2021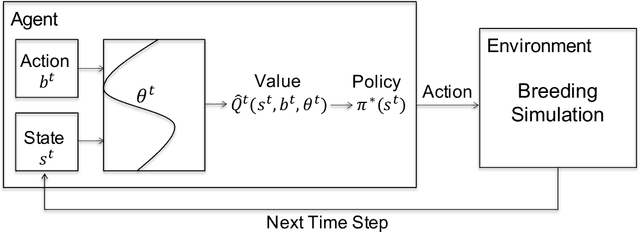
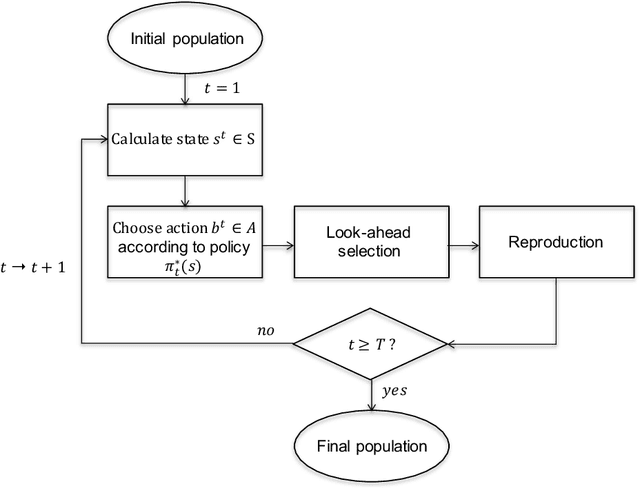
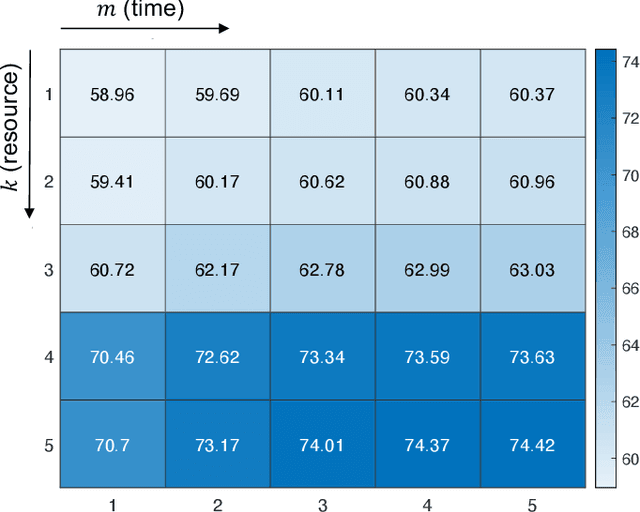
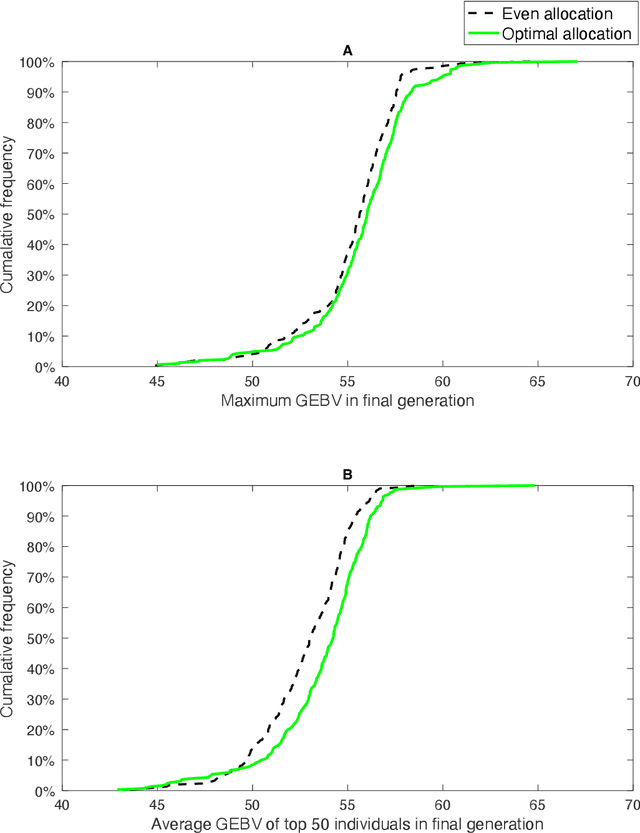
Genomic selection (GS) is a technique that plant breeders use to select individuals to mate and produce new generations of species. Allocation of resources is a key factor in GS. At each selection cycle, breeders are facing the choice of budget allocation to make crosses and produce the next generation of breeding parents. Inspired by recent advances in reinforcement learning for AI problems, we develop a reinforcement learning-based algorithm to automatically learn to allocate limited resources across different generations of breeding. We mathematically formulate the problem in the framework of Markov Decision Process (MDP) by defining state and action spaces. To avoid the explosion of the state space, an integer linear program is proposed that quantifies the trade-off between resources and time. Finally, we propose a value function approximation method to estimate the action-value function and then develop a greedy policy improvement technique to find the optimal resources. We demonstrate the effectiveness of the proposed method in enhancing genetic gain using a case study with realistic data.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021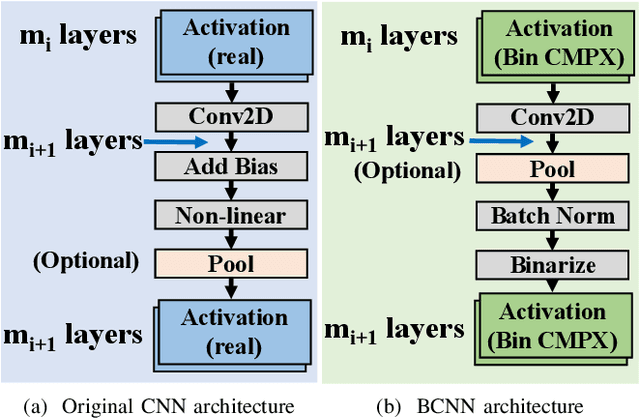
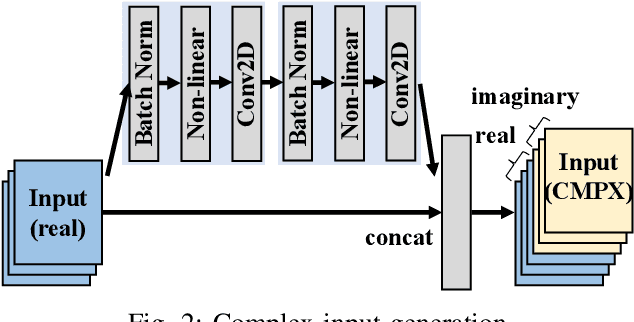

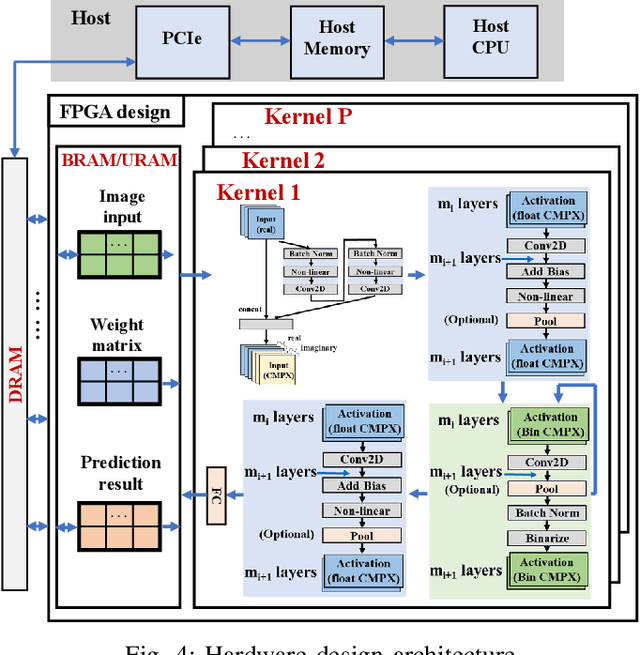
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.
Incentivized Bandit Learning with Self-Reinforcing User Preferences
May 31, 2021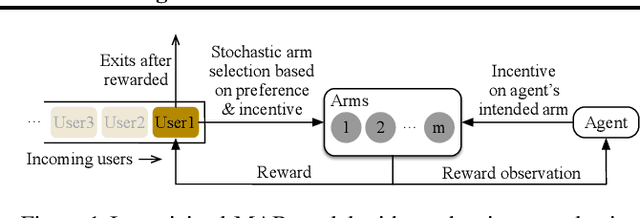
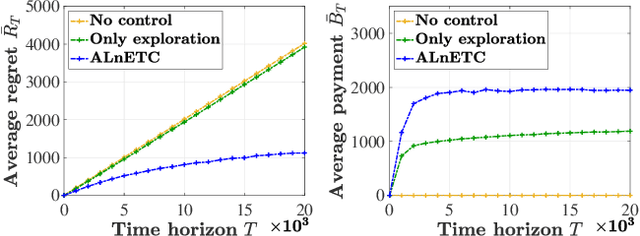
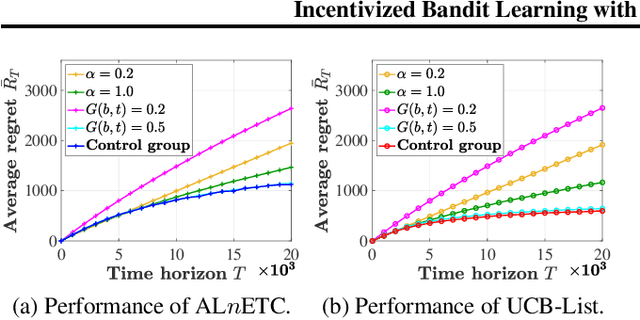
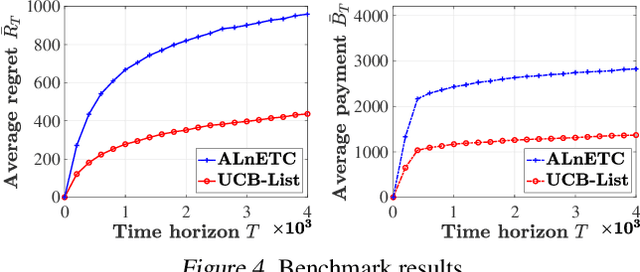
In this paper, we investigate a new multi-armed bandit (MAB) online learning model that considers real-world phenomena in many recommender systems: (i) the learning agent cannot pull the arms by itself and thus has to offer rewards to users to incentivize arm-pulling indirectly; and (ii) if users with specific arm preferences are well rewarded, they induce a "self-reinforcing" effect in the sense that they will attract more users of similar arm preferences. Besides addressing the tradeoff of exploration and exploitation, another key feature of this new MAB model is to balance reward and incentivizing payment. The goal of the agent is to maximize the total reward over a fixed time horizon $T$ with a low total payment. Our contributions in this paper are two-fold: (i) We propose a new MAB model with random arm selection that considers the relationship of users' self-reinforcing preferences and incentives; and (ii) We leverage the properties of a multi-color Polya urn with nonlinear feedback model to propose two MAB policies termed "At-Least-$n$ Explore-Then-Commit" and "UCB-List". We prove that both policies achieve $O(log T)$ expected regret with $O(log T)$ expected payment over a time horizon $T$. We conduct numerical simulations to demonstrate and verify the performances of these two policies and study their robustness under various settings.
Model Compression for Dynamic Forecast Combination
Apr 05, 2021



The predictive advantage of combining several different predictive models is widely accepted. Particularly in time series forecasting problems, this combination is often dynamic to cope with potential non-stationary sources of variation present in the data. Despite their superior predictive performance, ensemble methods entail two main limitations: high computational costs and lack of transparency. These issues often preclude the deployment of such approaches, in favour of simpler yet more efficient and reliable ones. In this paper, we leverage the idea of model compression to address this problem in time series forecasting tasks. Model compression approaches have been mostly unexplored for forecasting. Their application in time series is challenging due to the evolving nature of the data. Further, while the literature focuses on neural networks, we apply model compression to distinct types of methods. In an extensive set of experiments, we show that compressing dynamic forecasting ensembles into an individual model leads to a comparable predictive performance and a drastic reduction in computational costs. Further, the compressed individual model with best average rank is a rule-based regression model. Thus, model compression also leads to benefits in terms of model interpretability. The experiments carried in this paper are fully reproducible.
Minimax Regret for Bandit Convex Optimisation of Ridge Functions
Jun 06, 2021
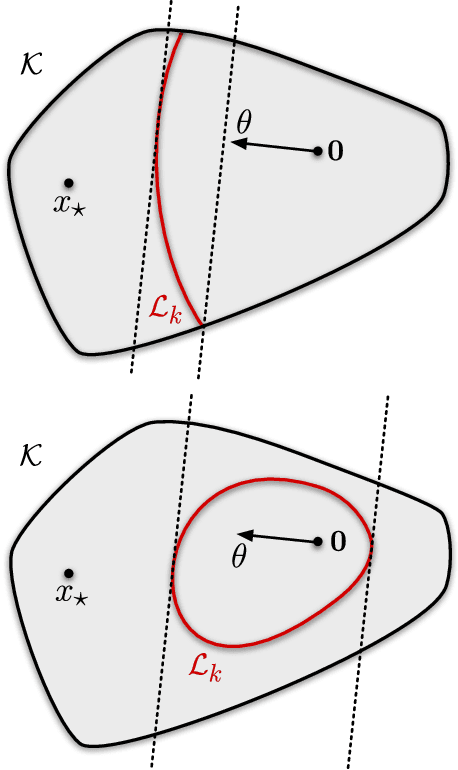
We analyse adversarial bandit convex optimisation with an adversary that is restricted to playing functions of the form $f_t(x) = g_t(\langle x, \theta\rangle)$ for convex $g_t : \mathbb R \to \mathbb R$ and unknown $\theta \in \mathbb R^d$ that is homogeneous over time. We provide a short information-theoretic proof that the minimax regret is at most $O(d \sqrt{n} \log(n \operatorname{diam}(\mathcal K)))$ where $n$ is the number of interactions, $d$ the dimension and $\operatorname{diam}(\mathcal K)$ is the diameter of the constraint set.