 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combined Person Classification with Airborne Optical Sectioning
Jun 18, 2021
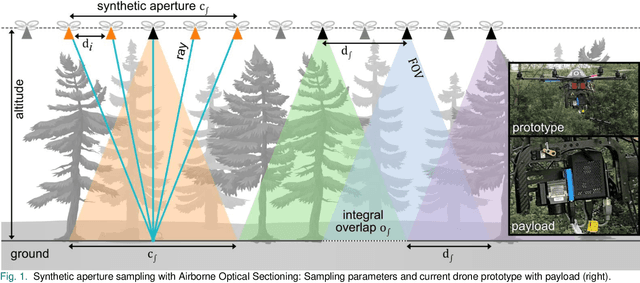
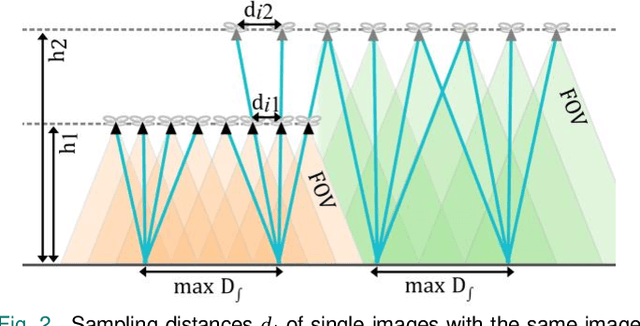
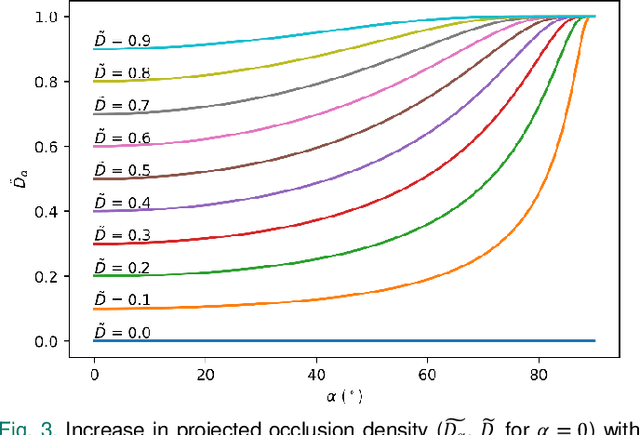

Fully autonomous drones have been demonstrated to find lost or injured persons under strongly occluding forest canopy. Airborne Optical Sectioning (AOS), a novel synthetic aperture imaging technique, together with deep-learning-based classification enables high detection rates under realistic search-and-rescue conditions. We demonstrate that false detections can be significantly suppressed and true detections boosted by combining classifications from multiple AOS rather than single integral images. This improves classification rates especially in the presence of occlusion. To make this possible, we modified the AOS imaging process to support large overlaps between subsequent integrals, enabling real-time and on-board scanning and processing of groundspeeds up to 10 m/s.
Multi-accent Speech Separation with One Shot Learning
Jun 28, 2021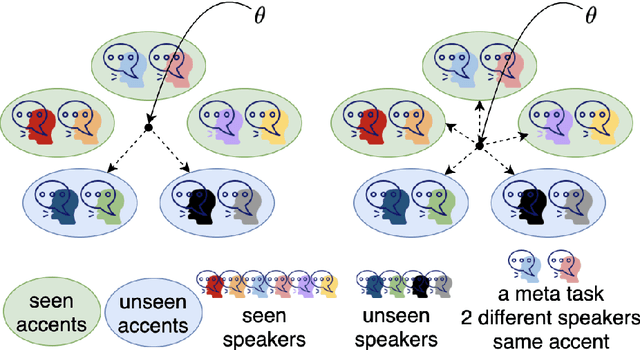
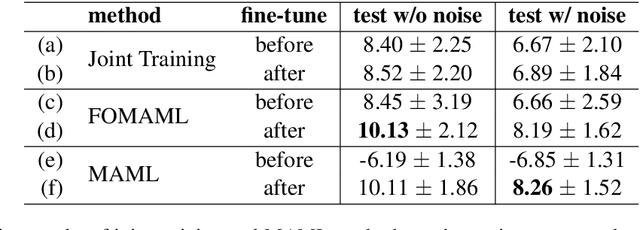
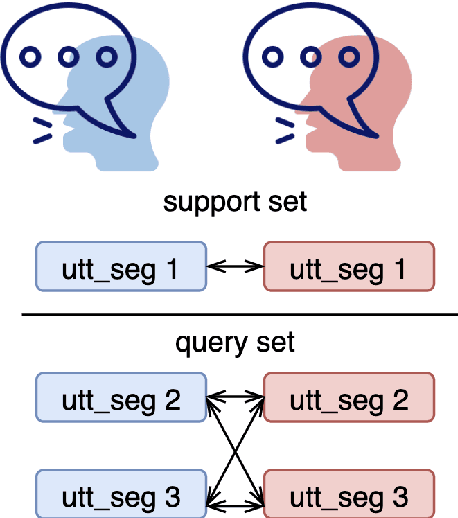
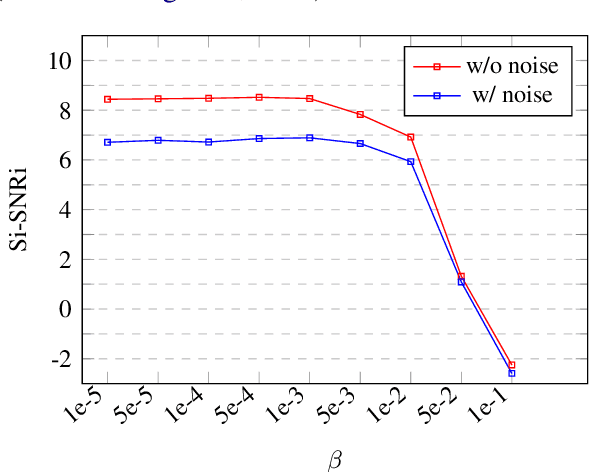
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
Ensemble of CNN classifiers using Sugeno Fuzzy Integral Technique for Cervical Cytology Image Classification
Aug 21, 2021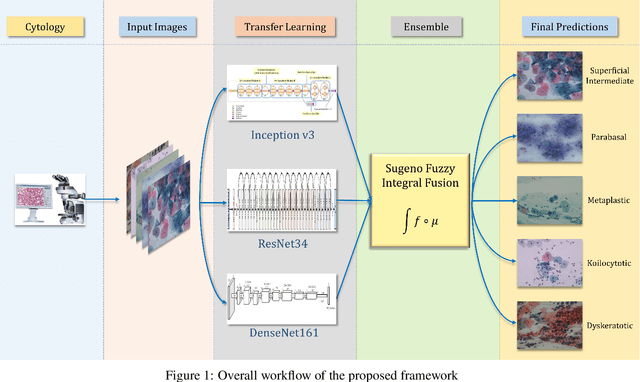
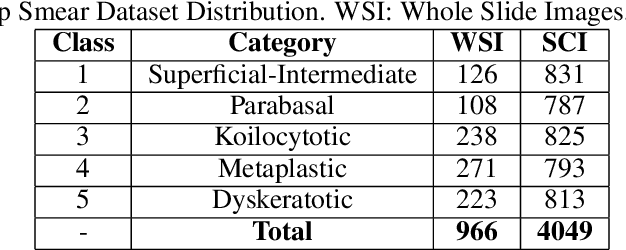
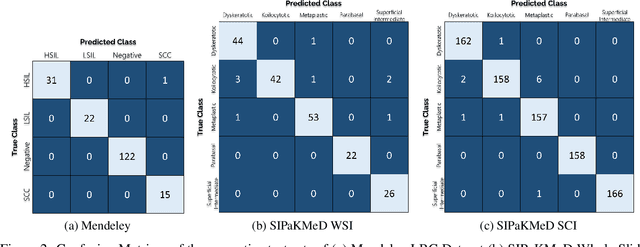
Cervical cancer is the fourth most common category of cancer, affecting more than 500,000 women annually, owing to the slow detection procedure. Early diagnosis can help in treating and even curing cancer, but the tedious, time-consuming testing process makes it impossible to conduct population-wise screening. To aid the pathologists in efficient and reliable detection, in this paper, we propose a fully automated computer-aided diagnosis tool for classifying single-cell and slide images of cervical cancer. The main concern in developing an automatic detection tool for biomedical image classification is the low availability of publicly accessible data. Ensemble Learning is a popular approach for image classification, but simplistic approaches that leverage pre-determined weights to classifiers fail to perform satisfactorily. In this research, we use the Sugeno Fuzzy Integral to ensemble the decision scores from three popular pretrained deep learning models, namely, Inception v3, DenseNet-161 and ResNet-34. The proposed Fuzzy fusion is capable of taking into consideration the confidence scores of the classifiers for each sample, and thus adaptively changing the importance given to each classifier, capturing the complementary information supplied by each, thus leading to superior classification performance. We evaluated the proposed method on three publicly available datasets, the Mendeley Liquid Based Cytology (LBC) dataset, the SIPaKMeD Whole Slide Image (WSI) dataset, and the SIPaKMeD Single Cell Image (SCI) dataset, and the results thus yielded are promising. Analysis of the approach using GradCAM-based visual representations and statistical tests, and comparison of the method with existing and baseline models in literature justify the efficacy of the approach.
Task-Sensitive Concept Drift Detector with Metric Learning
Aug 16, 2021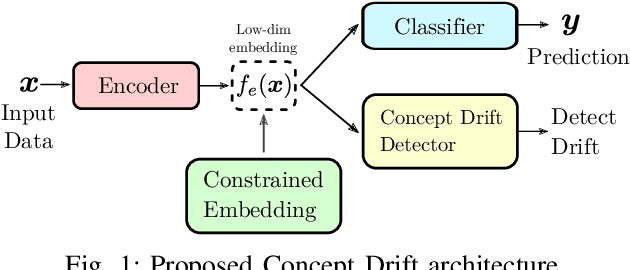
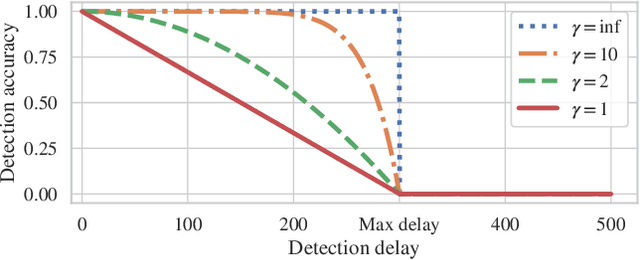
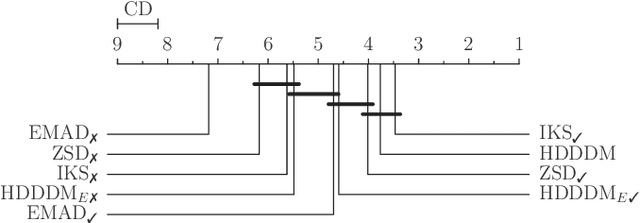
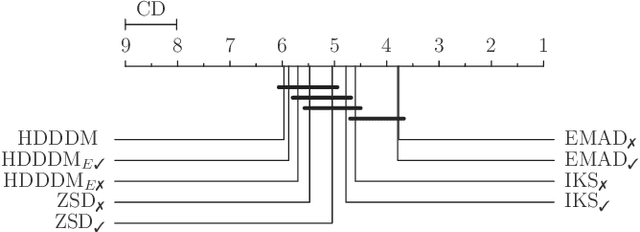
Detecting drifts in data is essential for machine learning applications, as changes in the statistics of processed data typically has a profound influence on the performance of trained models. Most of the available drift detection methods require access to true labels during inference time. In a real-world scenario, true labels usually available only during model training. In this work, we propose a novel task-sensitive drift detection framework, which is able to detect drifts without access to true labels during inference. It utilizes metric learning of a constrained low-dimensional embedding representation of the input data, which is best suited for the classification task. It is able to detect real drift, where the drift affects the classification performance, while it properly ignores virtual drift, where the classification performance is not affected by the drift. In the proposed framework, the actual method to detect a change in the statistics of incoming data samples can be chosen freely. We also propose the two change detection methods, which are based on the exponential moving average and a modified $z$-score, respectively. We evaluate the performance of the proposed framework with a novel metric, which accumulates the standard metrics of detection accuracy, false positive rate and detection delay into one value. Experimental evaluation on nine benchmarks datasets, with different types of drift, demonstrates that the proposed framework can reliably detect drifts, and outperforms state-of-the-art unsupervised drift detection approaches.
Natural Evolution Strategy for Unconstrained and Implicitly Constrained Problems with Ridge Structure
Aug 21, 2021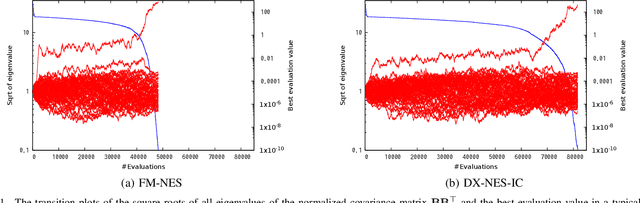


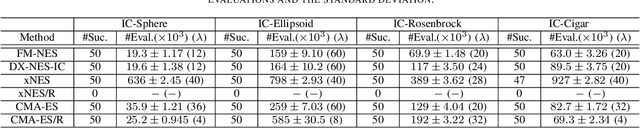
In this paper, we propose a new natural evolution strategy for unconstrained black-box function optimization (BBFO) problems and implicitly constrained BBFO problems. BBFO problems are known to be difficult because explicit representations of objective functions are not available. Implicit constraints make the problems more difficult because whether or not a solution is feasible is revealed when the solution is evaluated with the objective function. DX-NES-IC is one of the promising methods for implicitly constrained BBFO problems. DX-NES-IC has shown better performance than conventional methods on implicitly constrained benchmark problems. However, DX-NES-IC has a problem in that the moving speed of the probability distribution is slow on ridge structure. To address the problem, we propose the Fast Moving Natural Evolution Strategy (FM-NES) that accelerates the movement of the probability distribution on ridge structure by introducing the rank-one update into DX-NES-IC. The rank-one update is utilized in CMA-ES. Since naively introducing the rank-one update makes the search performance deteriorate on implicitly constrained problems, we propose a condition of performing the rank-one update. We also propose to reset the shape of the probability distribution when an infeasible solution is sampled at the first time. In numerical experiments using unconstrained and implicitly constrained benchmark problems, FM-NES showed better performance than DX-NES-IC on problems with ridge structure and almost the same performance as DX-NES-IC on the others. Furthermore, FM-NES outperformed xNES, CMA-ES, xNES with the resampling technique, and CMA-ES with the resampling technique.
Applying Nature-Inspired Optimization Algorithms for Selecting Important Timestamps to Reduce Time Series Dimensionality
Dec 09, 2018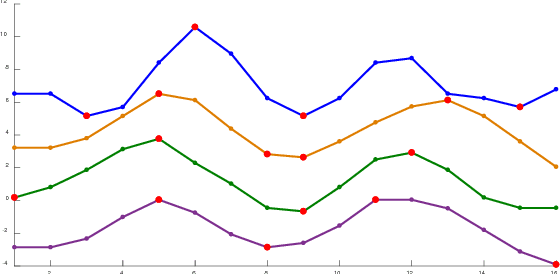
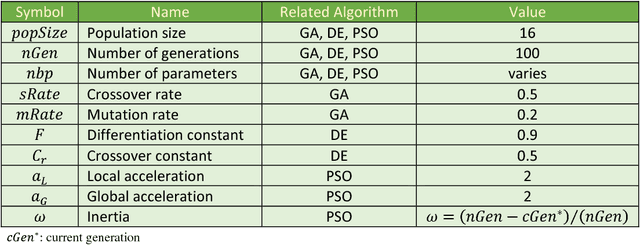
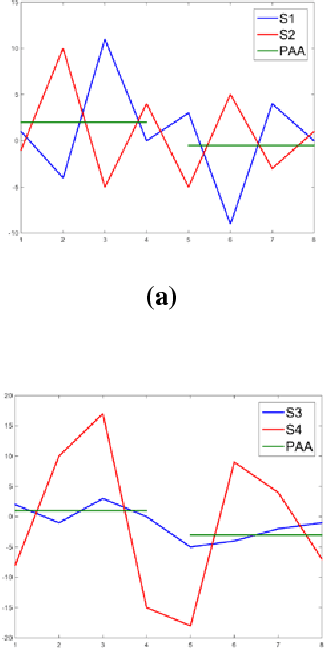
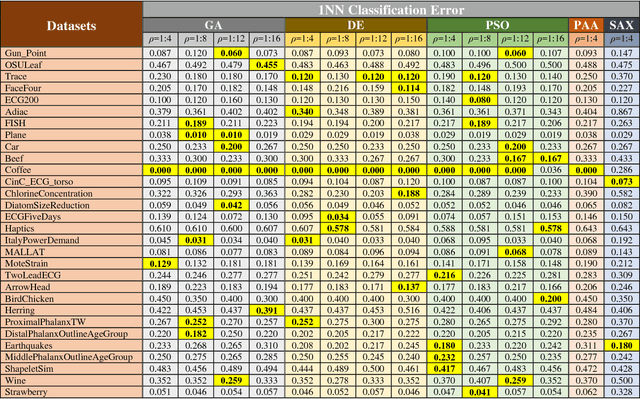
Time series data account for a major part of data supply available today. Time series mining handles several tasks such as classification, clustering, query-by-content, prediction, and others. Performing data mining tasks on raw time series is inefficient as these data are high-dimensional by nature. Instead, time series are first pre-processed using several techniques before different data mining tasks can be performed on them. In general, there are two main approaches to reduce time series dimensionality, the first is what we call landmark methods. These methods are based on finding characteristic features in the target time series. The second is based on data transformations. These methods transform the time series from the original space into a reduced space, where they can be managed more efficiently. The method we present in this paper applies a third approach, as it projects a time series onto a lower-dimensional space by selecting important points in the time series. The novelty of our method is that these points are not chosen according to a geometric criterion, which is subjective in most cases, but through an optimization process. The other important characteristic of our method is that these important points are selected on a dataset-level and not on a single time series-level. The direct advantage of this strategy is that the distance defined on the low-dimensional space lower bounds the original distance applied to raw data. This enables us to apply the popular GEMINI algorithm. The promising results of our experiments on a wide variety of time series datasets, using different optimizers, and applied to the two major data mining tasks, validate our new method.
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 05, 2021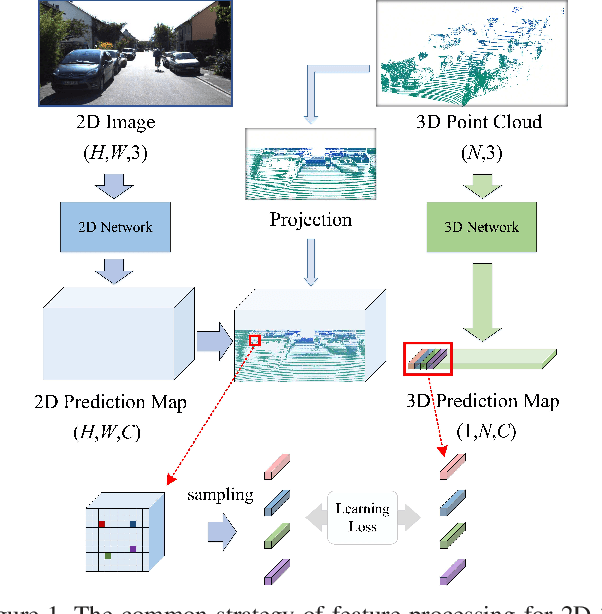
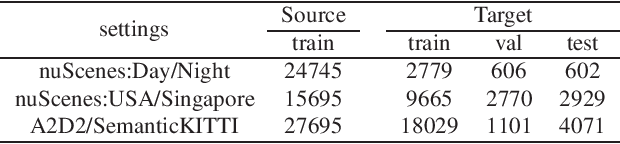
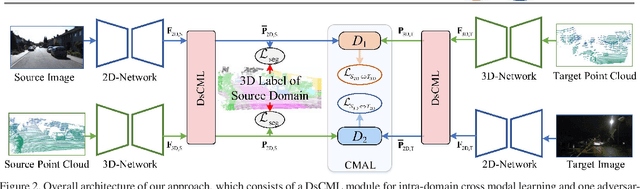
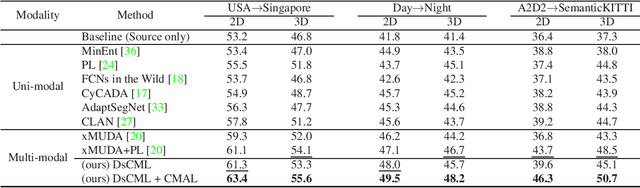
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
Measuring Novelty in Autonomous Vehicles Motion Using Local Outlier Factor Algorithm
Apr 24, 2021
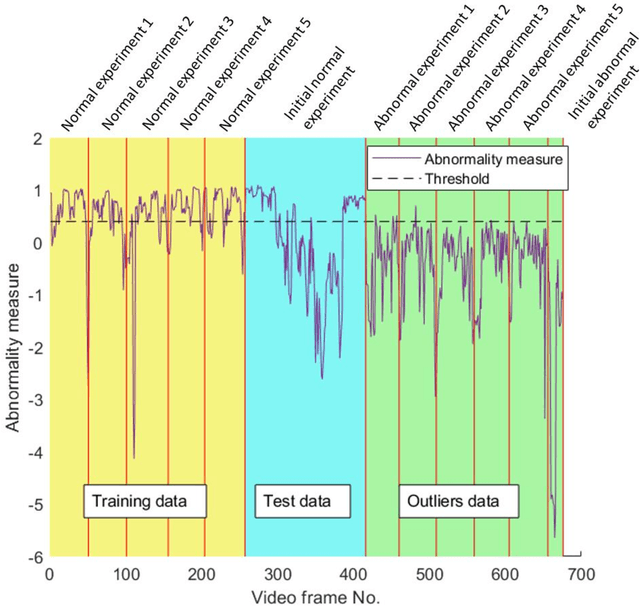
Under unexpected conditions or scenarios, autonomous vehicles (AV) are more likely to follow abnormal unplanned actions, due to the limited set of rules or amount of experience they possess at that time. Enabling AV to measure the degree at which their movements are novel in real-time may help to decrease any possible negative consequences. We propose a method based on the Local Outlier Factor (LOF) algorithm to quantify this novelty measure. We extracted features from the inertial measurement unit (IMU) sensor's readings, which captures the vehicle's motion. We followed a novelty detection approach in which the model is fitted only using the normal data. Using datasets obtained from real-world vehicle missions, we demonstrate that the suggested metric can quantify to some extent the degree of novelty. Finally, a performance evaluation of the model confirms that our novelty metric can be practical.
Advances in Trajectory Optimization for Space Vehicle Control
Aug 05, 2021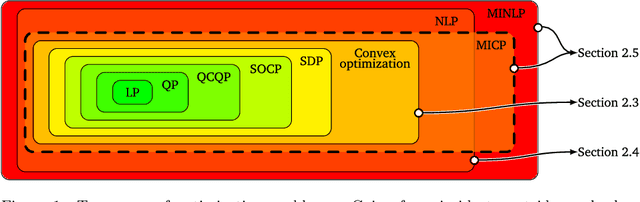
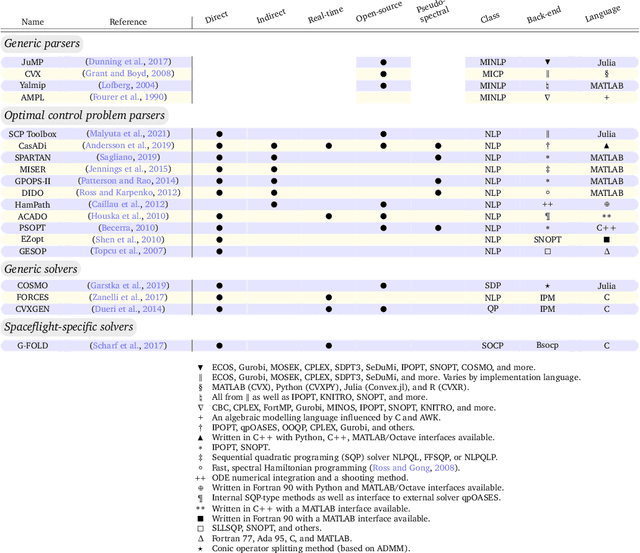
Space mission design places a premium on cost and operational efficiency. The search for new science and life beyond Earth calls for spacecraft that can deliver scientific payloads to geologically rich yet hazardous landing sites. At the same time, the last four decades of optimization research have put a suite of powerful optimization tools at the fingertips of the controls engineer. As we enter the new decade, optimization theory, algorithms, and software tooling have reached a critical mass to start seeing serious application in space vehicle guidance and control systems. This survey paper provides a detailed overview of recent advances, successes, and promising directions for optimization-based space vehicle control. The considered applications include planetary landing, rendezvous and proximity operations, small body landing, constrained reorientation, endo-atmospheric flight including ascent and re-entry, and orbit transfer and injection. The primary focus is on the last ten years of progress, which have seen a veritable rise in the number of applications using three core technologies: lossless convexification, sequential convex programming, and model predictive control. The reader will come away with a well-rounded understanding of the state-of-the-art in each space vehicle control application, and will be well positioned to tackle important current open problems using convex optimization as a core technology.
Generating stable molecules using imitation and reinforcement learning
Jul 11, 2021
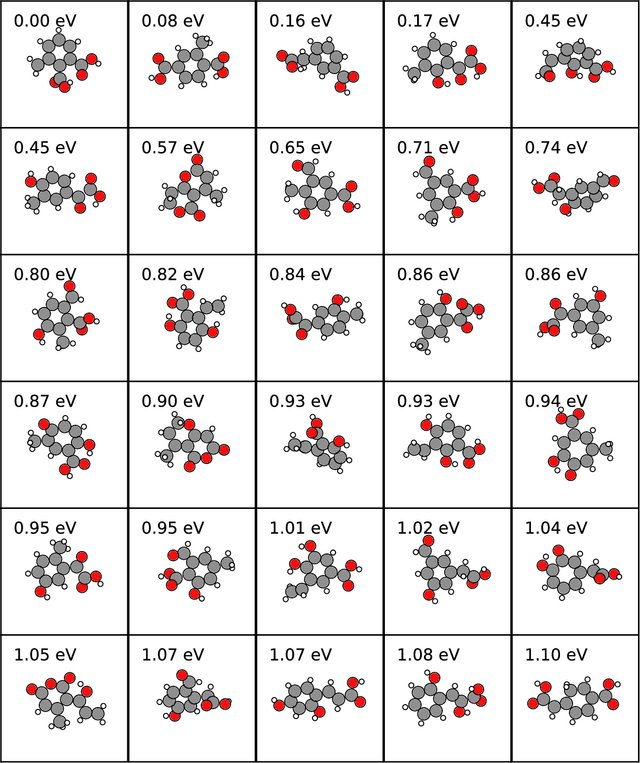
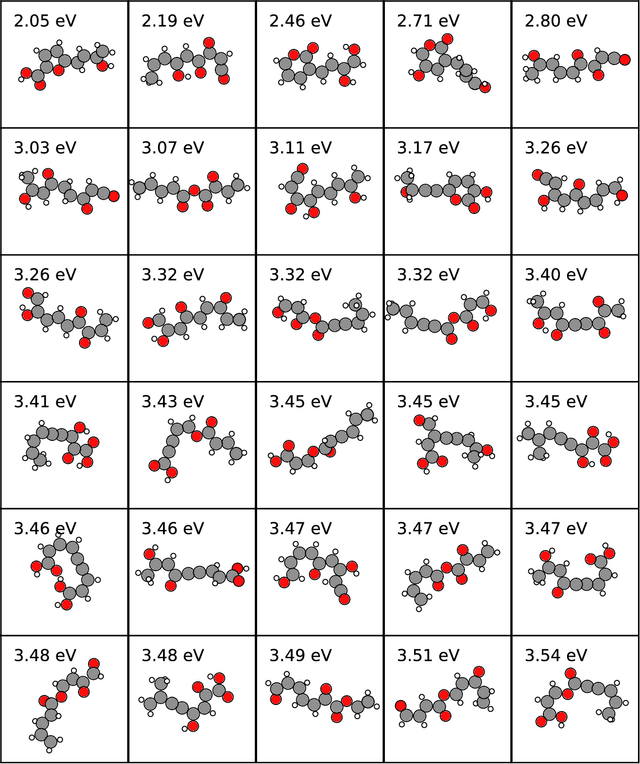
Chemical space is routinely explored by machine learning methods to discover interesting molecules, before time-consuming experimental synthesizing is attempted. However, these methods often rely on a graph representation, ignoring 3D information necessary for determining the stability of the molecules. We propose a reinforcement learning approach for generating molecules in cartesian coordinates allowing for quantum chemical prediction of the stability. To improve sample-efficiency we learn basic chemical rules from imitation learning on the GDB-11 database to create an initial model applicable for all stoichiometries. We then deploy multiple copies of the model conditioned on a specific stoichiometry in a reinforcement learning setting. The models correctly identify low energy molecules in the database and produce novel isomers not found in the training set. Finally, we apply the model to larger molecules to show how reinforcement learning further refines the imitation learning model in domains far from the training data.