 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Deep Learning with Dynamic Programming for Embryo Early Development Stage Classification from Time-Lapse Videos
Aug 22, 2019
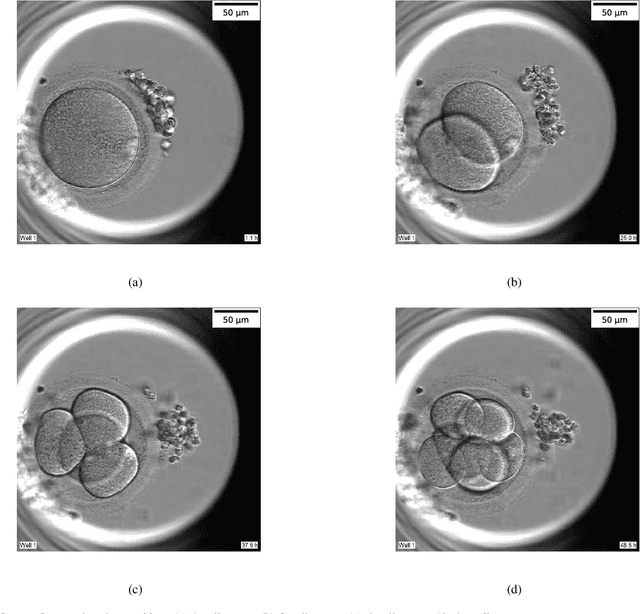
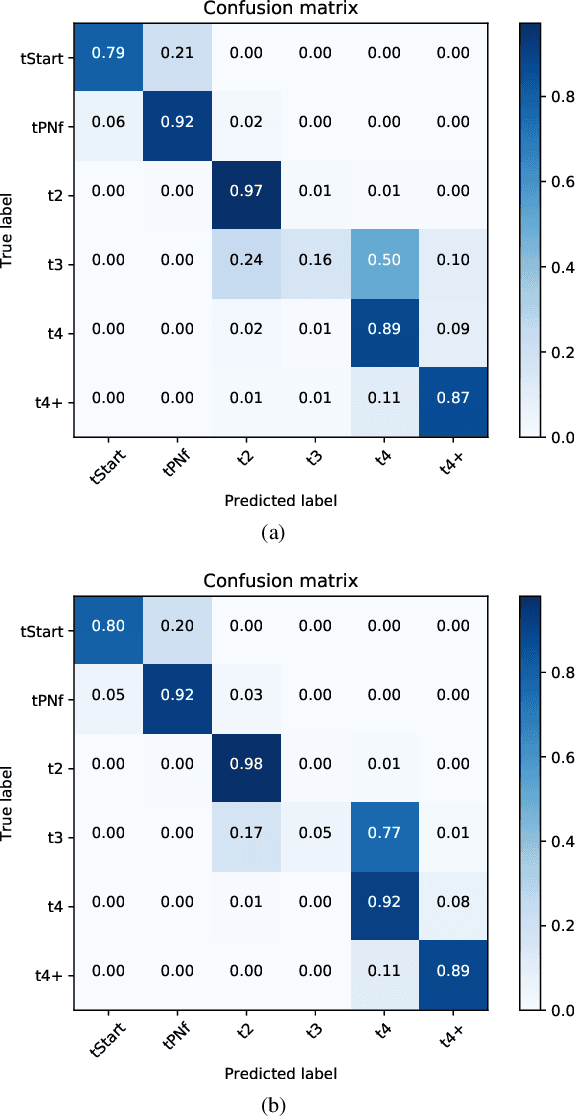
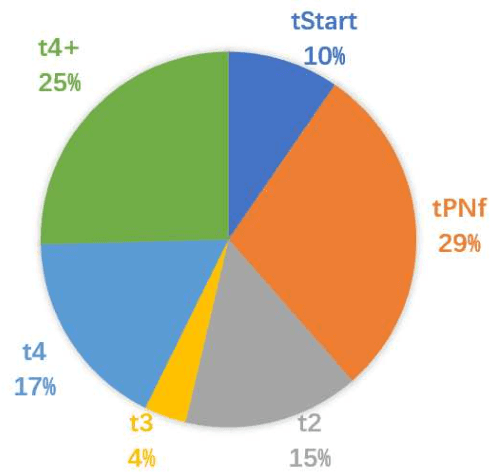
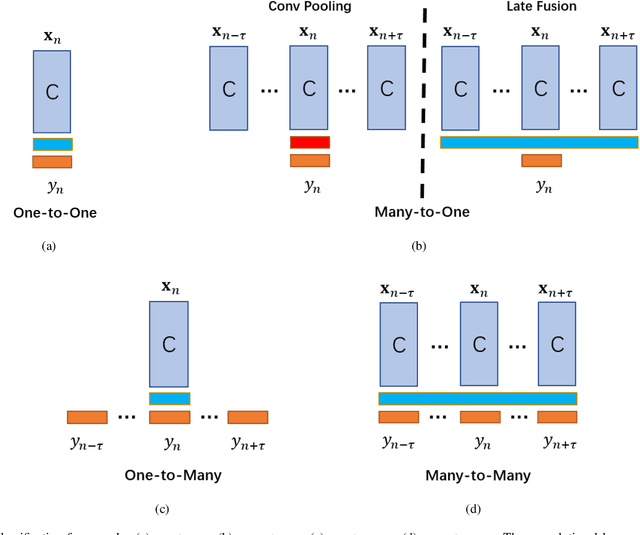
Time-lapse is a technology used to record the development of embryos during in-vitro fertilization (IVF). Accurate classification of embryo early development stages can provide embryologists valuable information for assessing the embryo quality, and hence is critical to the success of IVF. This paper proposes a multi-task deep learning with dynamic programming (MTDL-DP) approach for this purpose. It first uses MTDL to pre-classify each frame in the time-lapse video to an embryo development stage, and then DP to optimize the stage sequence so that the stage number is monotonically non-decreasing, which usually holds in practice. Different MTDL frameworks, e.g., one-to-many, many-to-one, and many-to-many, are investigated. It is shown that the one-to-many MTDL framework achieved the best compromise between performance and computational cost. To our knowledge, this is the first study that applies MTDL to embryo early development stage classification from time-lapse videos.
FuseMODNet: Real-Time Camera and LiDAR based Moving Object Detection for robust low-light Autonomous Driving
Nov 21, 2019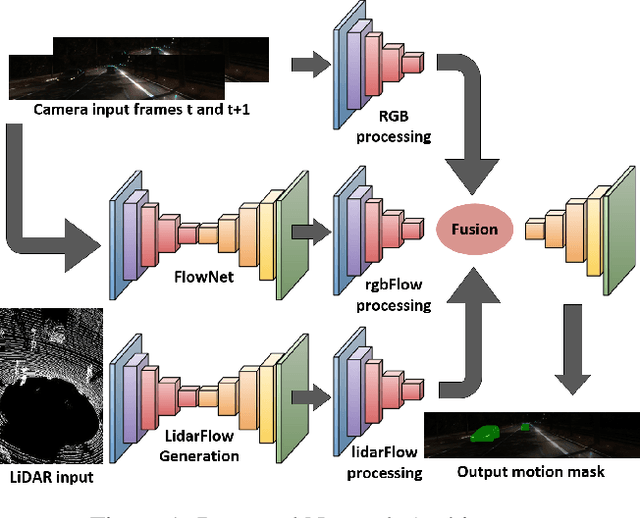
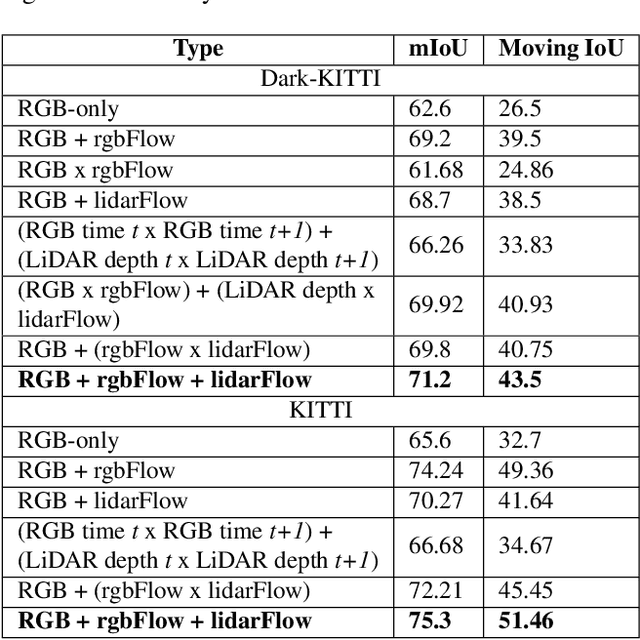


Moving object detection is a critical task for autonomous vehicles. As dynamic objects represent higher collision risk than static ones, our own ego-trajectories have to be planned attending to the future states of the moving elements of the scene. Motion can be perceived using temporal information such as optical flow. Conventional optical flow computation is based on camera sensors only, which makes it prone to failure in conditions with low illumination. On the other hand, LiDAR sensors are independent of illumination, as they measure the time-of-flight of their own emitted lasers. In this work, we propose a robust and real-time CNN architecture for Moving Object Detection (MOD) under low-light conditions by capturing motion information from both camera and LiDAR sensors. We demonstrate the impact of our algorithm on KITTI dataset where we simulate a low-light environment creating a novel dataset "Dark KITTI". We obtain a 10.1% relative improvement on Dark-KITTI, and a 4.25% improvement on standard KITTI relative to our baselines. The proposed algorithm runs at 18 fps on a standard desktop GPU using $256\times1224$ resolution images.
DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion
Aug 30, 2021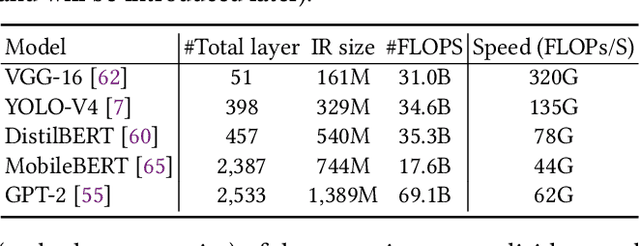
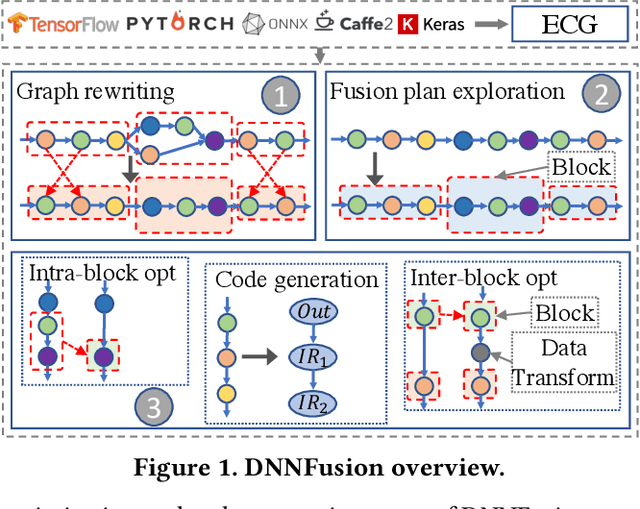

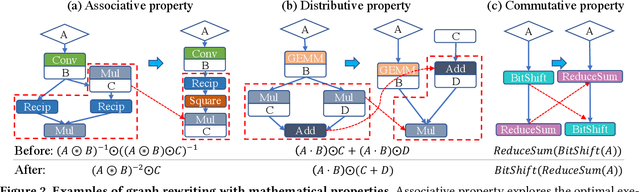
Deep Neural Networks (DNNs) have emerged as the core enabler of many major applications on mobile devices. To achieve high accuracy, DNN models have become increasingly deep with hundreds or even thousands of operator layers, leading to high memory and computational requirements for inference. Operator fusion (or kernel/layer fusion) is key optimization in many state-of-the-art DNN execution frameworks, such as TensorFlow, TVM, and MNN. However, these frameworks usually adopt fusion approaches based on certain patterns that are too restrictive to cover the diversity of operators and layer connections. Polyhedral-based loop fusion techniques, on the other hand, work on a low-level view of the computation without operator-level information, and can also miss potential fusion opportunities. To address this challenge, this paper proposes a novel and extensive loop fusion framework called DNNFusion. The basic idea of this work is to work at an operator view of DNNs, but expand fusion opportunities by developing a classification of both individual operators and their combinations. In addition, DNNFusion includes 1) a novel mathematical-property-based graph rewriting framework to reduce evaluation costs and facilitate subsequent operator fusion, 2) an integrated fusion plan generation that leverages the high-level analysis and accurate light-weight profiling, and 3) additional optimizations during fusion code generation. DNNFusion is extensively evaluated on 15 DNN models with varied types of tasks, model sizes, and layer counts. The evaluation results demonstrate that DNNFusion finds up to 8.8x higher fusion opportunities, outperforms four state-of-the-art DNN execution frameworks with 9.3x speedup. The memory requirement reduction and speedups can enable the execution of many of the target models on mobile devices and even make them part of a real-time application.
Improving the Transient Times for Distributed Stochastic Gradient Methods
May 11, 2021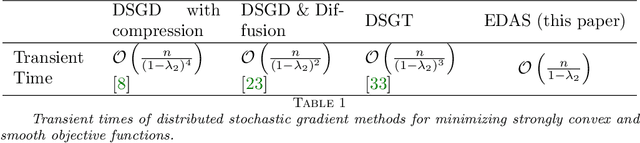
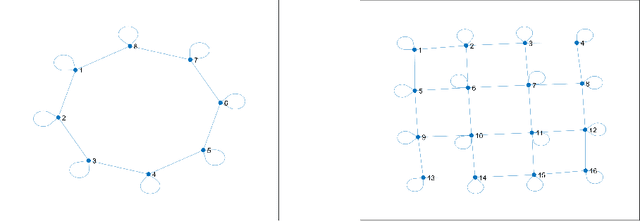
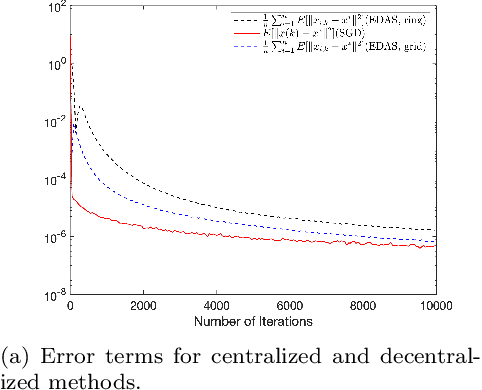
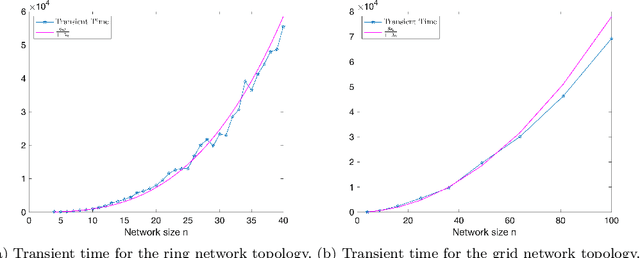
We consider the distributed optimization problem where $n$ agents each possessing a local cost function, collaboratively minimize the average of the $n$ cost functions over a connected network. Assuming stochastic gradient information is available, we study a distributed stochastic gradient algorithm, called exact diffusion with adaptive stepsizes (EDAS) adapted from the Exact Diffusion method and NIDS and perform a non-asymptotic convergence analysis. We not only show that EDAS asymptotically achieves the same network independent convergence rate as centralized stochastic gradient descent (SGD) for minimizing strongly convex and smooth objective functions, but also characterize the transient time needed for the algorithm to approach the asymptotic convergence rate, which behaves as $K_T=\mathcal{O}\left(\frac{n}{1-\lambda_2}\right)$, where $1-\lambda_2$ stands for the spectral gap of the mixing matrix. To the best of our knowledge, EDAS achieves the shortest transient time when the average of the $n$ cost functions is strongly convex and each cost function is smooth. Numerical simulations further corroborate and strengthen the obtained theoretical results.
Low-Rank Autoregressive Tensor Completion for Spatiotemporal Traffic Data Imputation
Apr 30, 2021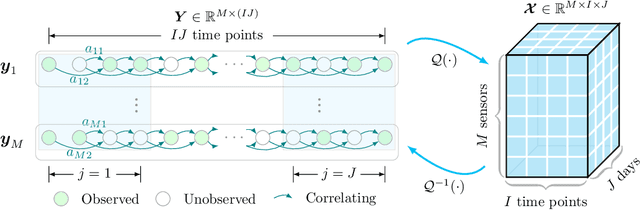
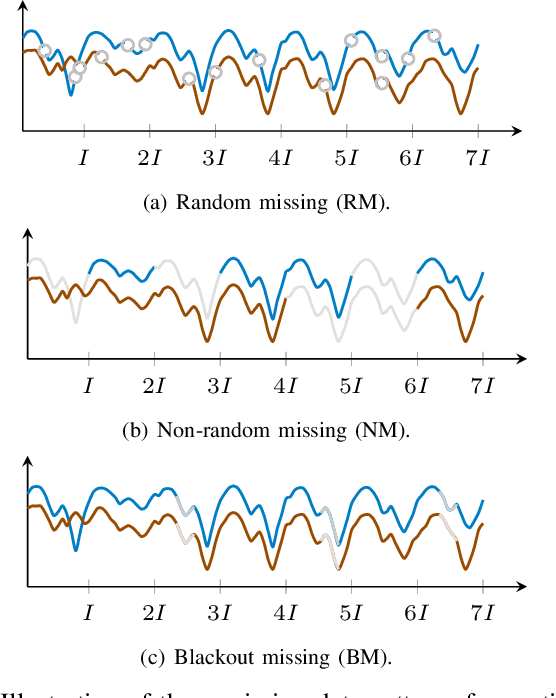
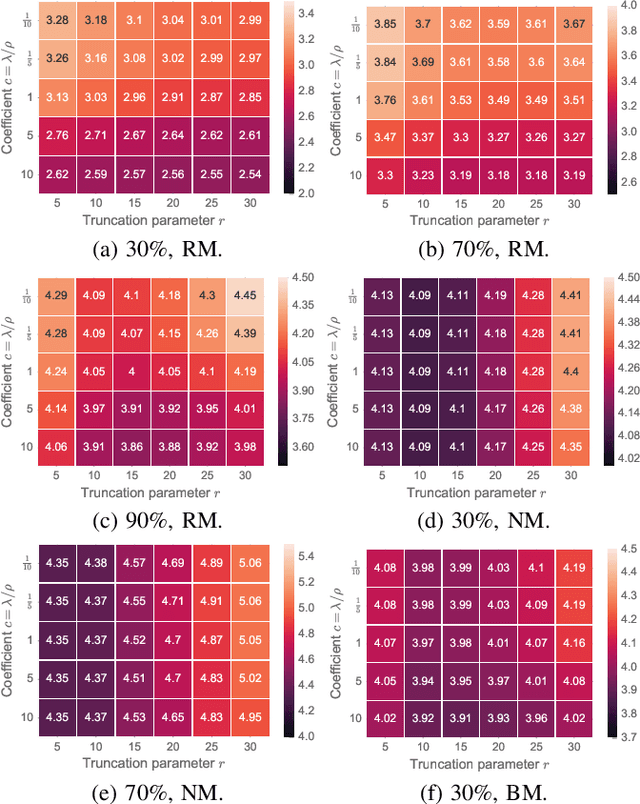
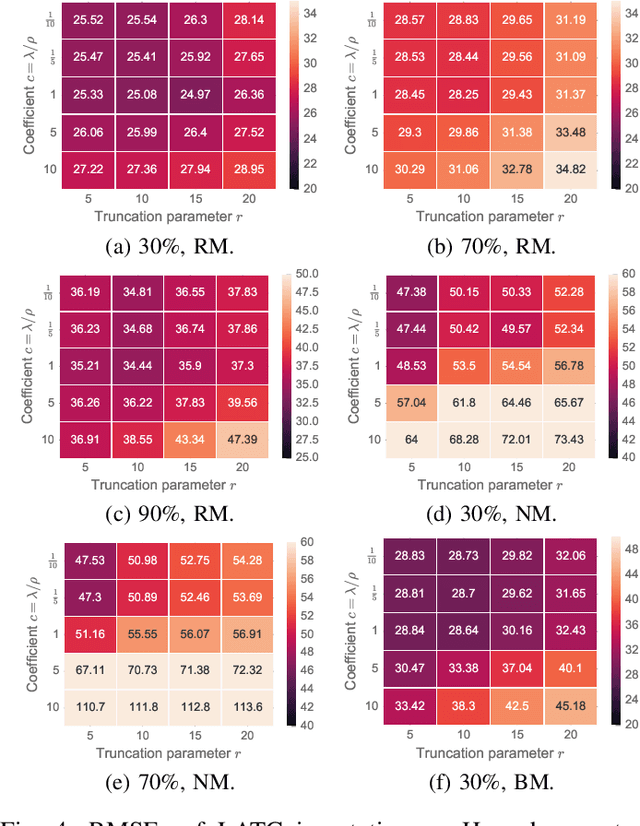
Spatiotemporal traffic time series (e.g., traffic volume/speed) collected from sensing systems are often incomplete with considerable corruption and large amounts of missing values, preventing users from harnessing the full power of the data. Missing data imputation has been a long-standing research topic and critical application for real-world intelligent transportation systems. A widely applied imputation method is low-rank matrix/tensor completion; however, the low-rank assumption only preserves the global structure while ignores the strong local consistency in spatiotemporal data. In this paper, we propose a low-rank autoregressive tensor completion (LATC) framework by introducing \textit{temporal variation} as a new regularization term into the completion of a third-order (sensor $\times$ time of day $\times$ day) tensor. The third-order tensor structure allows us to better capture the global consistency of traffic data, such as the inherent seasonality and day-to-day similarity. To achieve local consistency, we design the temporal variation by imposing an AR($p$) model for each time series with coefficients as learnable parameters. Different from previous spatial and temporal regularization schemes, the minimization of temporal variation can better characterize temporal generative mechanisms beyond local smoothness, allowing us to deal with more challenging scenarios such "blackout" missing. To solve the optimization problem in LATC, we introduce an alternating minimization scheme that estimates the low-rank tensor and autoregressive coefficients iteratively. We conduct extensive numerical experiments on several real-world traffic data sets, and our results demonstrate the effectiveness of LATC in diverse missing scenarios.
Uncover Common Facial Expressions in Terracotta Warriors: A Deep Learning Approach
May 11, 2021
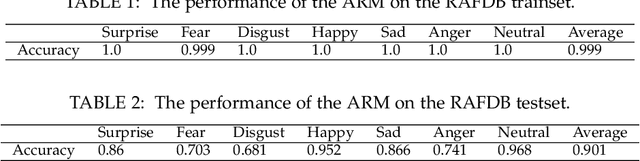


Can advanced deep learning technologies be applied to analyze some ancient humanistic arts? Can deep learning technologies be directly applied to special scenes such as facial expression analysis of Terracotta Warriors? The big challenging is that the facial features of the Terracotta Warriors are very different from today's people. We found that it is very poor to directly use the models that have been trained on other classic facial expression datasets to analyze the facial expressions of the Terracotta Warriors. At the same time, the lack of public high-quality facial expression data of the Terracotta Warriors also limits the use of deep learning technologies. Therefore, we firstly use Generative Adversarial Networks (GANs) to generate enough high-quality facial expression data for subsequent training and recognition. We also verify the effectiveness of this approach. For the first time, this paper uses deep learning technologies to find common facial expressions of general and postured Terracotta Warriors. These results will provide an updated technical means for the research of art of the Terracotta Warriors and shine lights on the research of other ancient arts.
A Modulation Front-End for Music Audio Tagging
May 25, 2021
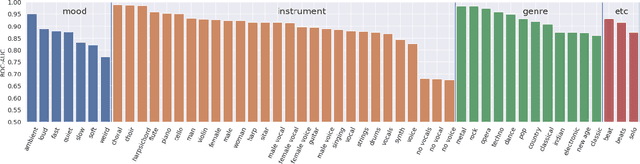
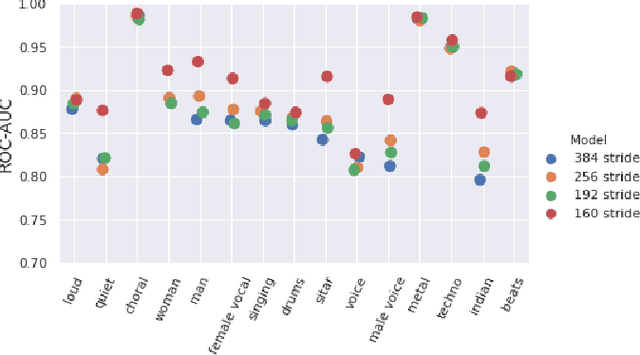
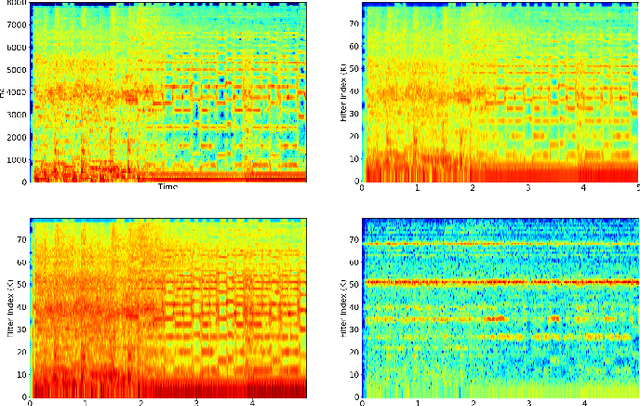
Convolutional Neural Networks have been extensively explored in the task of automatic music tagging. The problem can be approached by using either engineered time-frequency features or raw audio as input. Modulation filter bank representations that have been actively researched as a basis for timbre perception have the potential to facilitate the extraction of perceptually salient features. We explore end-to-end learned front-ends for audio representation learning, ModNet and SincModNet, that incorporate a temporal modulation processing block. The structure is effectively analogous to a modulation filter bank, where the FIR filter center frequencies are learned in a data-driven manner. The expectation is that a perceptually motivated filter bank can provide a useful representation for identifying music features. Our experimental results provide a fully visualisable and interpretable front-end temporal modulation decomposition of raw audio. We evaluate the performance of our model against the state-of-the-art of music tagging on the MagnaTagATune dataset. We analyse the impact on performance for particular tags when time-frequency bands are subsampled by the modulation filters at a progressively reduced rate. We demonstrate that modulation filtering provides promising results for music tagging and feature representation, without using extensive musical domain knowledge in the design of this front-end.
Increased Complexity and Fitness of Artificial Cells that Reproduce Using Spatially Distributed Asynchronous Parallel Processes
Mar 15, 2021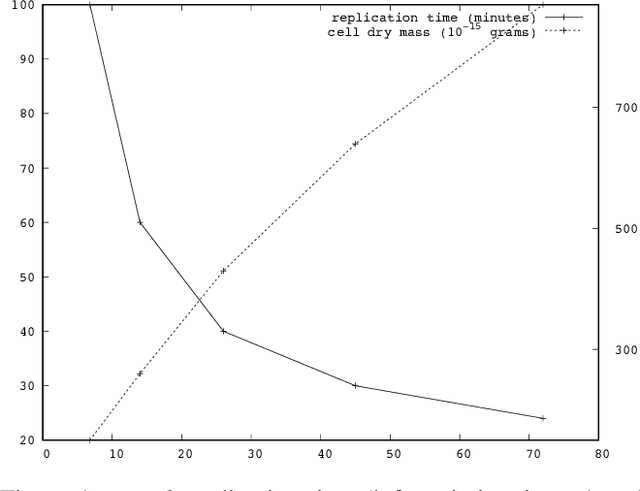
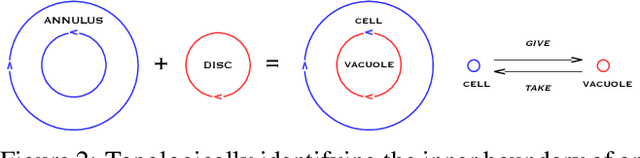
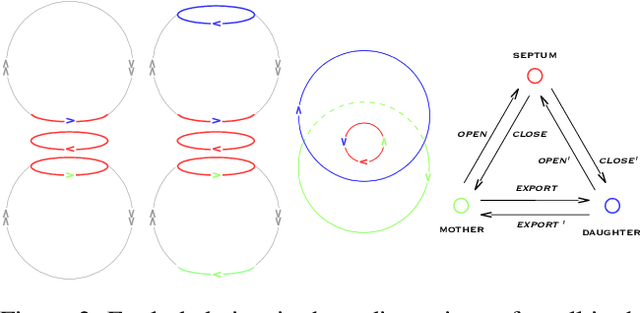
Replication time is among the most important components of a bacterial cell's reproductive fitness. Paradoxically, larger cells replicate in less time than smaller cells despite the fact that building a larger cell requires increased quantities of raw materials and energy. This feat is primarily accomplished by the massive over expression of ribosomes, which permits translation of mRNA into protein, the limiting step in reproduction, to occur at a scale that would be impossible were it not for the use of parallel processing. In computer science, spatial parallelism is the distribution of work across the nodes of a distributed-memory multicomputer system. Despite the fact that a non-negligible fraction of artificial life research is grounded in formulations based on spatially parallel substrates, there have been no examples of artificial organisms that use spatial parallelism to replicate in less time than smaller organisms. This paper describes artificial cells defined using a combinator-based artificial chemistry that replicate in less time than smaller cells. This is achieved by employing extra copies of programs implementing the limiting steps in the process used by the cells to synthesize their component parts. Significant speedup is demonstrated, despite the increased complexity of control and export processes necessitated by the use of a parallel replication strategy.
A Kinematic Bottleneck Approach For Pose Regression of Flexible Surgical Instruments directly from Images
Feb 28, 2021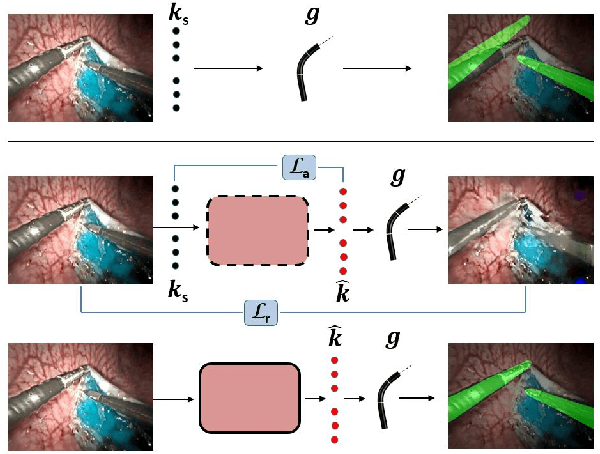
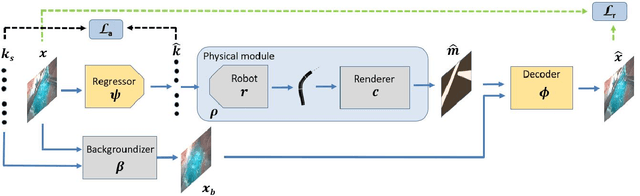
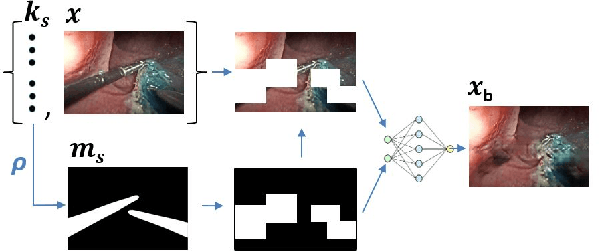
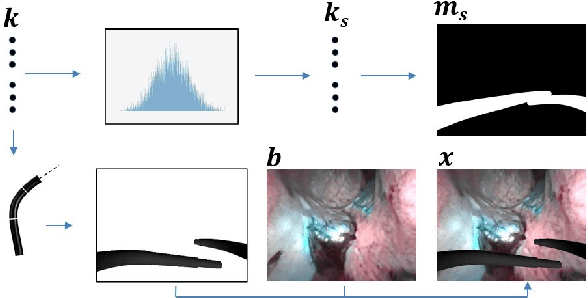
3-D pose estimation of instruments is a crucial step towards automatic scene understanding in robotic minimally invasive surgery. Although robotic systems can potentially directly provide joint values, this information is not commonly exploited inside the operating room, due to its possible unreliability, limited access and the time-consuming calibration required, especially for continuum robots. For this reason, standard approaches for 3-D pose estimation involve the use of external tracking systems. Recently, image-based methods have emerged as promising, non-invasive alternatives. While many image-based approaches in the literature have shown accurate results, they generally require either a complex iterative optimization for each processed image, making them unsuitable for real-time applications, or a large number of manually-annotated images for efficient learning. In this paper we propose a self-supervised image-based method, exploiting, at training time only, the imprecise kinematic information provided by the robot. In order to avoid introducing time-consuming manual annotations, the problem is formulated as an auto-encoder, smartly bottlenecked by the presence of a physical model of the robotic instruments and surgical camera, forcing a separation between image background and kinematic content. Validation of the method was performed on semi-synthetic, phantom and in-vivo datasets, obtained using a flexible robotized endoscope, showing promising results for real-time image-based 3-D pose estimation of surgical instruments.
Meta-Learning for Few-Shot Time Series Classification
Sep 13, 2019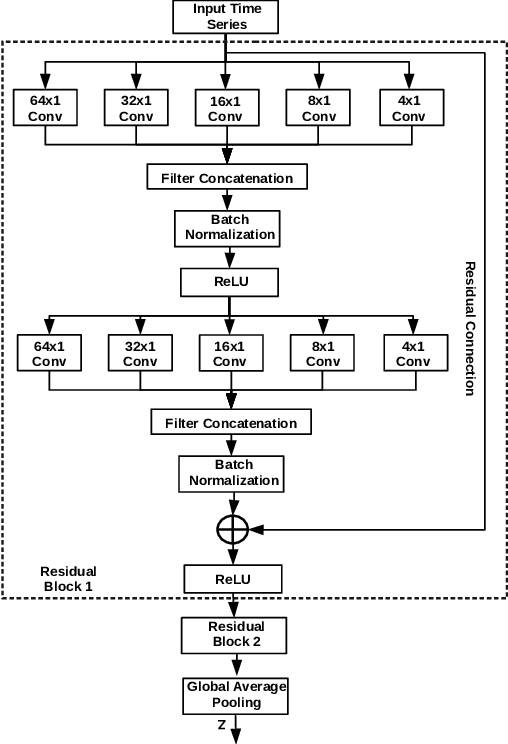
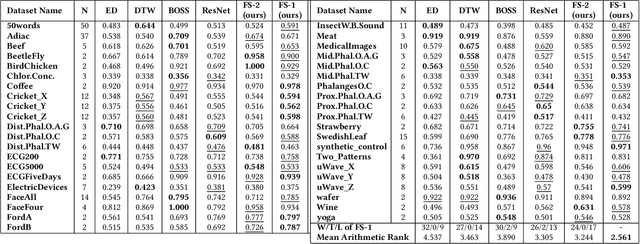
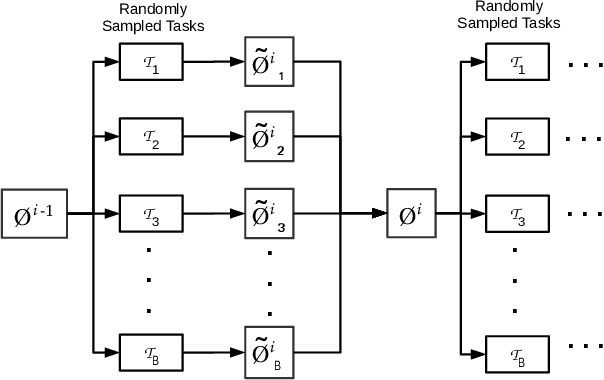
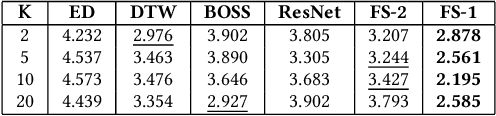
Deep neural networks (DNNs) have achieved state-of-the-art results on time series classification (TSC) tasks. In this work, we focus on leveraging DNNs in the often-encountered practical scenario where access to labeled training data is difficult, and where DNNs would be prone to overfitting. We leverage recent advancements in gradient-based meta-learning, and propose an approach to train a residual neural network with convolutional layers as a meta-learning agent for few-shot TSC. The network is trained on a diverse set of few-shot tasks sampled from various domains (e.g. healthcare, activity recognition, etc.) such that it can solve a target task from another domain using only a small number of training samples from the target task. Most existing meta-learning approaches are limited in practice as they assume a fixed number of target classes across tasks. We overcome this limitation in order to train a common agent across domains with each domain having different number of target classes, we utilize a triplet-loss based learning procedure that does not require any constraints to be enforced on the number of classes for the few-shot TSC tasks. To the best of our knowledge, we are the first to use meta-learning based pre-training for TSC. Our approach sets a new benchmark for few-shot TSC, outperforming several strong baselines on few-shot tasks sampled from 41 datasets in UCR TSC Archive. We observe that pre-training under the meta-learning paradigm allows the network to quickly adapt to new unseen tasks with small number of labeled instances.