 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Angular Velocity Estimation using Non-coplanar Accelerometer Array
Aug 22, 2021
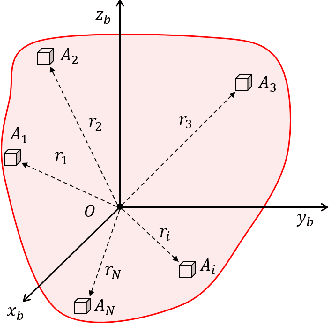
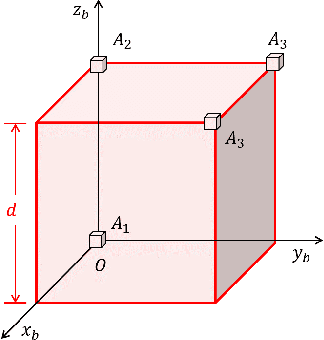
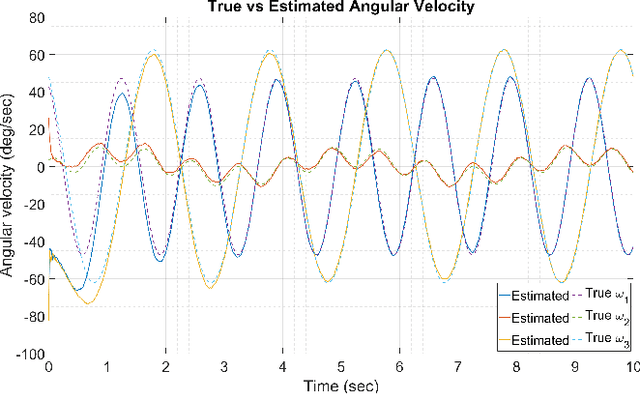
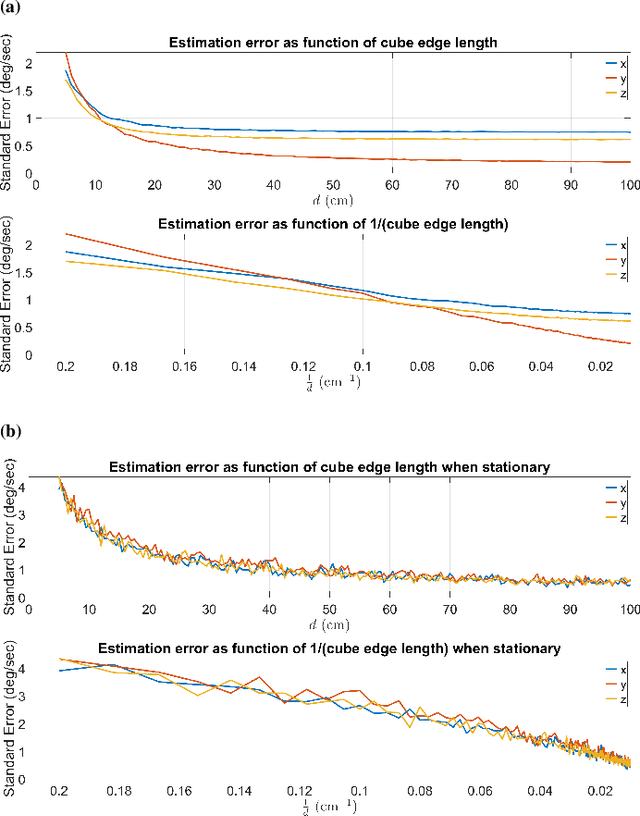
Over the last few decades, Gyro-Free IMUs have been extensively researched to overcome the limitations of gyroscopes. This research presents a Non-coplanar Accelerometer Array (NAA) for estimating angular velocity with non-specific geometric arrangement of four or more triaxial accelerometers with non-coplanarity constraint. The presented proof of non-coplanar spacial arrangement also provides insights into propagation of the sensor noise and construction of the noise covariance matrices. The system noise depends on the singular values of the relative displacement matrix (between the sensors). A dynamical system model with uncorrelated process and measurement noise is proposed where the accelerometer readings are used simultaneously as process and measurement inputs. The angular velocity is estimated using an EKF that discretizes and linearizes the continuous-discrete time dynamical system. The simulations are performed on a Cube-NAA (Cu-NAA) comprising four accelerometers placed at different vertices of a cube. They analyze the estimation error for static and dynamic movement as the distance between the accelerometers is varied. Here, the system noise is observed to decrease inversely with the length of the cube edge as the arrangement is kept identical. Consequently, the simulation results indicate asymptotic decrease in the standard error of estimation with edge length. The experiments are conducted on a Cu-NAA with five reflective optical markers. The reflective markers are visually tracked using VICON to construct the ground truth. This unique experimental setup, apart from providing three degrees of rotational freedom of movement, also allows for three degrees of spacial translation (linear acceleration of the Cu-NAA in space). The simulation and experimental results indicate better performance of the proposed EKF as compared to one with correlated process and measurement noises.
High-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging
Jul 15, 2021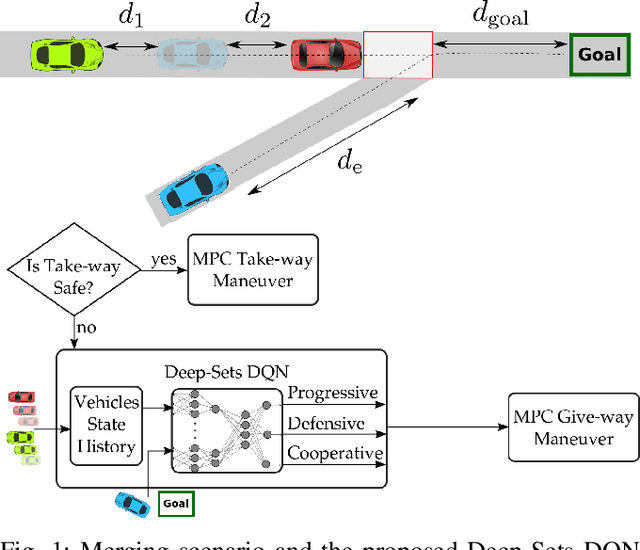
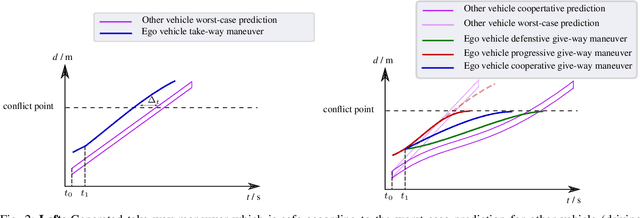
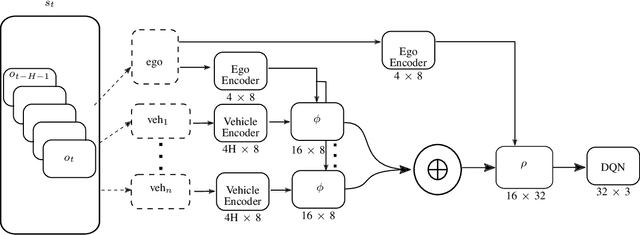
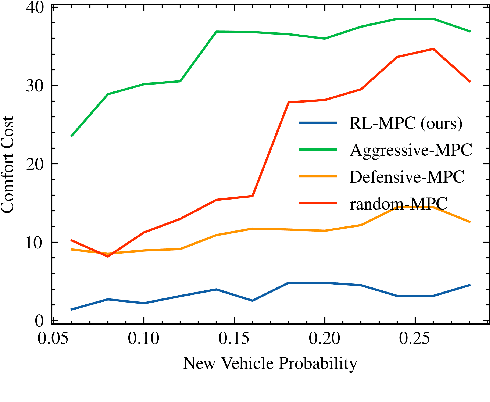
Reinforcement learning (RL) has recently been used for solving challenging decision-making problems in the context of automated driving. However, one of the main drawbacks of the presented RL-based policies is the lack of safety guarantees, since they strive to reduce the expected number of collisions but still tolerate them. In this paper, we propose an efficient RL-based decision-making pipeline for safe and cooperative automated driving in merging scenarios. The RL agent is able to predict the current situation and provide high-level decisions, specifying the operation mode of the low level planner which is responsible for safety. In order to learn a more generic policy, we propose a scalable RL architecture for the merging scenario that is not sensitive to changes in the environment configurations. According to our experiments, the proposed RL agent can efficiently identify cooperative drivers from their vehicle state history and generate interactive maneuvers, resulting in faster and more comfortable automated driving. At the same time, thanks to the safety constraints inside the planner, all of the maneuvers are collision free and safe.
Predicting colorectal polyp recurrence using time-to-event analysis of medical records
Nov 18, 2019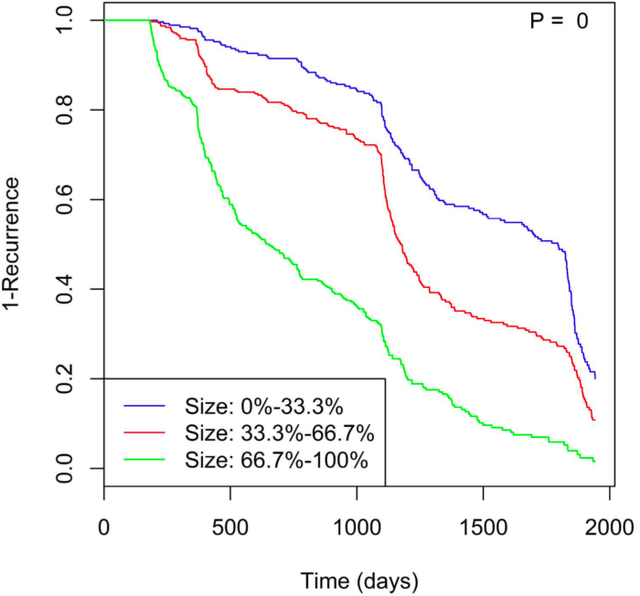
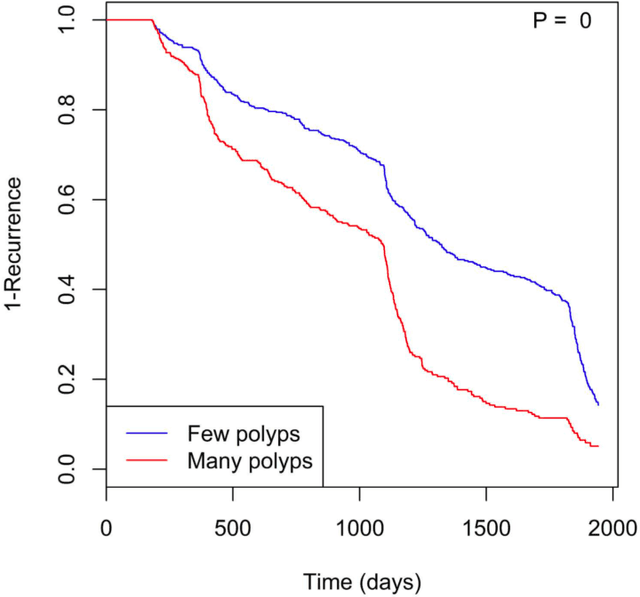
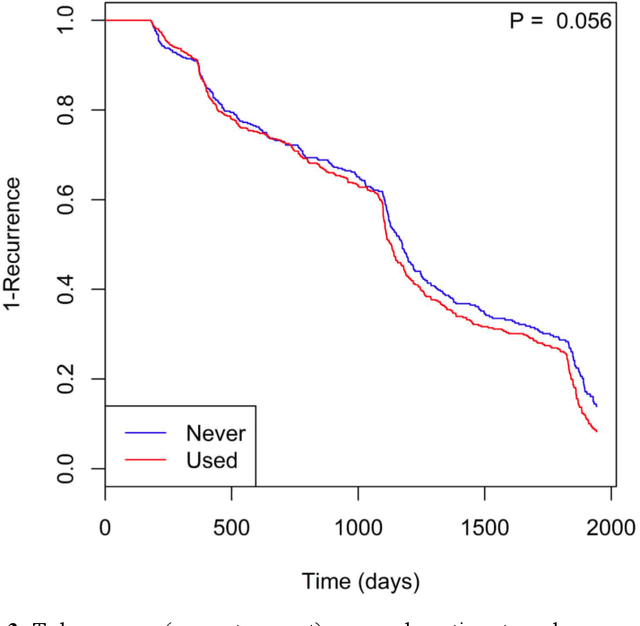
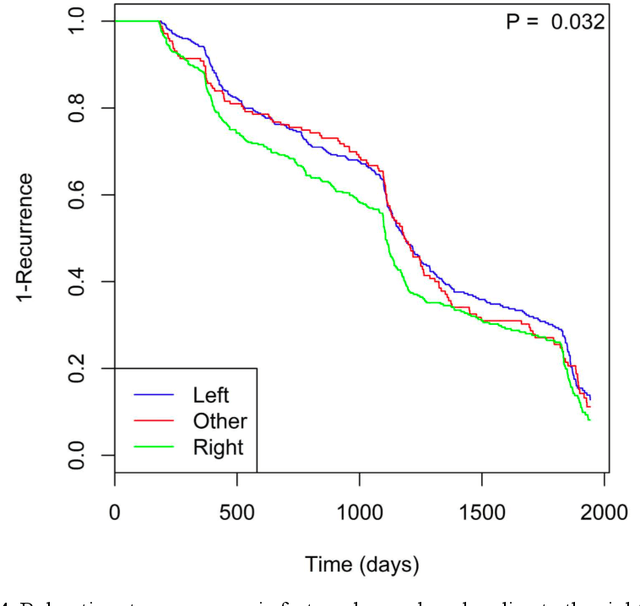
Identifying patient characteristics that influence the rate of colorectal polyp recurrence can provide important insights into which patients are at higher risk for recurrence. We used natural language processing to extract polyp morphological characteristics from 953 polyp-presenting patients' electronic medical records. We used subsequent colonoscopy reports to examine how the time to polyp recurrence (731 patients experienced recurrence) is influenced by these characteristics as well as anthropometric features using Kaplan-Meier curves, Cox proportional hazards modeling, and random survival forest models. We found that the rate of recurrence differed significantly by polyp size, number, and location and patient smoking status. Additionally, right-sided colon polyps increased recurrence risk by 30% compared to left-sided polyps. History of tobacco use increased polyp recurrence risk by 20% compared to never-users. A random survival forest model showed an AUC of 0.65 and identified several other predictive variables, which can inform development of personalized polyp surveillance plans.
Uncertainty-Aware Credit Card Fraud Detection Using Deep Learning
Jul 28, 2021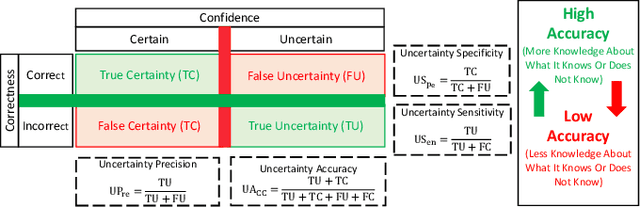
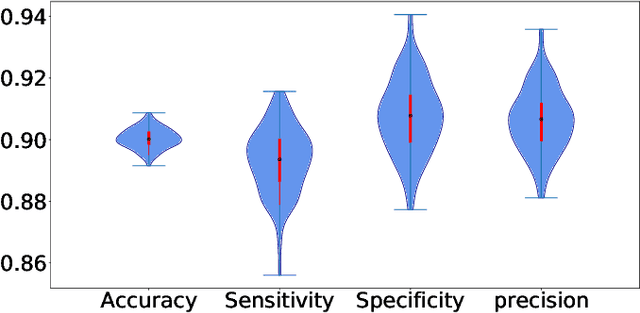
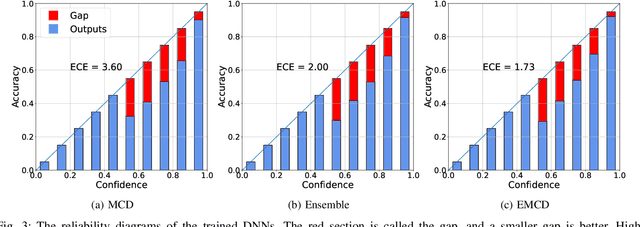
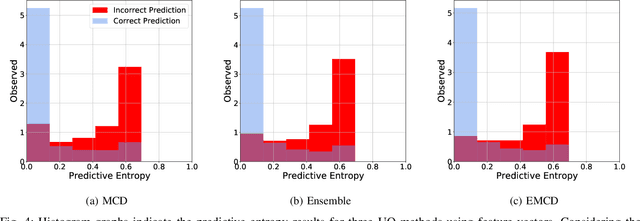
Countless research works of deep neural networks (DNNs) in the task of credit card fraud detection have focused on improving the accuracy of point predictions and mitigating unwanted biases by building different network architectures or learning models. Quantifying uncertainty accompanied by point estimation is essential because it mitigates model unfairness and permits practitioners to develop trustworthy systems which abstain from suboptimal decisions due to low confidence. Explicitly, assessing uncertainties associated with DNNs predictions is critical in real-world card fraud detection settings for characteristic reasons, including (a) fraudsters constantly change their strategies, and accordingly, DNNs encounter observations that are not generated by the same process as the training distribution, (b) owing to the time-consuming process, very few transactions are timely checked by professional experts to update DNNs. Therefore, this study proposes three uncertainty quantification (UQ) techniques named Monte Carlo dropout, ensemble, and ensemble Monte Carlo dropout for card fraud detection applied on transaction data. Moreover, to evaluate the predictive uncertainty estimates, UQ confusion matrix and several performance metrics are utilized. Through experimental results, we show that the ensemble is more effective in capturing uncertainty corresponding to generated predictions. Additionally, we demonstrate that the proposed UQ methods provide extra insight to the point predictions, leading to elevate the fraud prevention process.
Embodied AI-Driven Operation of Smart Cities: A Concise Review
Aug 22, 2021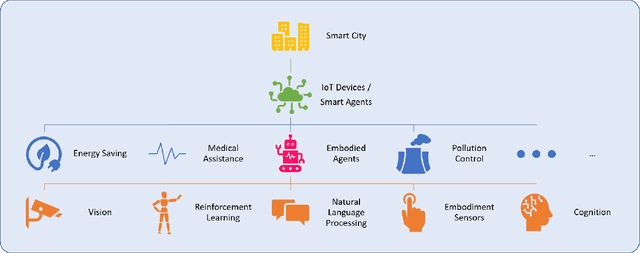
A smart city can be seen as a framework, comprised of Information and Communication Technologies (ICT). An intelligent network of connected devices that collect data with their sensors and transmit them using cloud technologies in order to communicate with other assets in the ecosystem plays a pivotal role in this framework. Maximizing the quality of life of citizens, making better use of resources, cutting costs, and improving sustainability are the ultimate goals that a smart city is after. Hence, data collected from connected devices will continuously get thoroughly analyzed to gain better insights into the services that are being offered across the city; with this goal in mind that they can be used to make the whole system more efficient. Robots and physical machines are inseparable parts of a smart city. Embodied AI is the field of study that takes a deeper look into these and explores how they can fit into real-world environments. It focuses on learning through interaction with the surrounding environment, as opposed to Internet AI which tries to learn from static datasets. Embodied AI aims to train an agent that can See (Computer Vision), Talk (NLP), Navigate and Interact with its environment (Reinforcement Learning), and Reason (General Intelligence), all at the same time. Autonomous driving cars and personal companions are some of the examples that benefit from Embodied AI nowadays. In this paper, we attempt to do a concise review of this field. We will go through its definitions, its characteristics, and its current achievements along with different algorithms, approaches, and solutions that are being used in different components of it (e.g. Vision, NLP, RL). We will then explore all the available simulators and 3D interactable databases that will make the research in this area feasible. Finally, we will address its challenges and identify its potentials for future research.
Multi-Target Tracking with Dependent Likelihood Structures in Labeled Random Finite Set Filters
Aug 08, 2021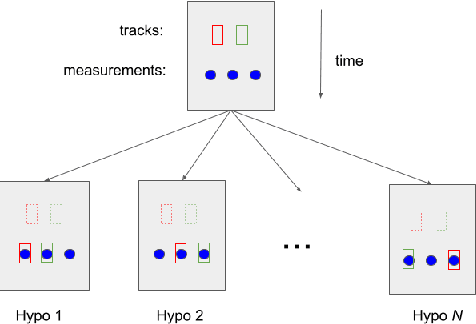
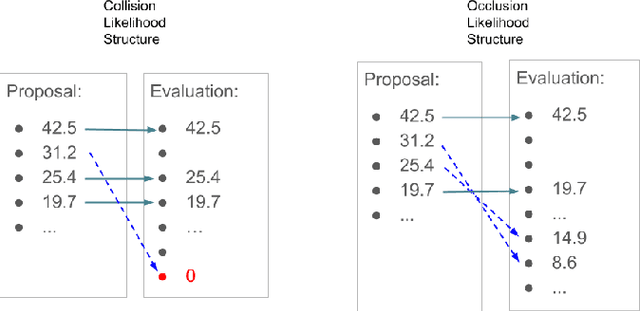
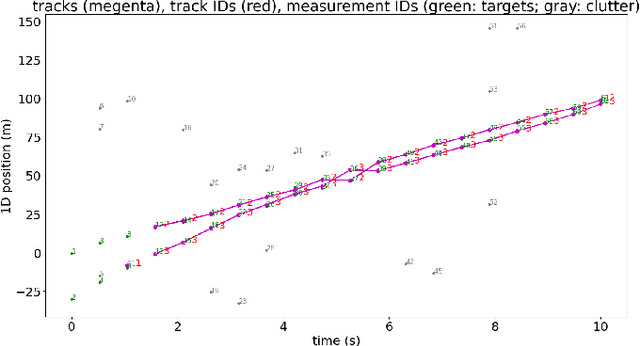
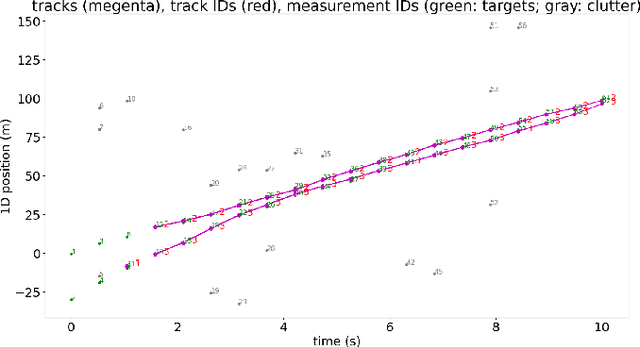
In multi-target tracking, a data association hypothesis assigns measurements to tracks, and the hypothesis likelihood (of the joint target-measurement associations) is used to compare among all hypotheses for truncation under a finite compute budget. It is often assumed however that an individual target-measurement association likelihood is independent of others, i.e., it remains the same in whichever hypothesis it belongs to. In the case of Track Oriented Multiple Hypothesis Tracking (TO-MHT), this leads to a parsimonious representation of the hypothesis space, with a maximum likelihood solution obtained through solving an Integer Linear Programming problem. In Labeled Random Finite Set (Labeled RFS) filters, this leads to an efficient way of obtaining the top ranked hypotheses through solving a ranked assignment problem using Murty's algorithm. In this paper we present a Propose and Verify approach for certain Dependent Likelihood Structures, such that the true hypothesis likelihood is evaluated jointly for the constituent track-measurement associations to account for dependence among them, but at the same time that ranking is still obtained efficiently. This is achieved by proposing a candidate ranking under an assumption of independence, and then evaluating the true likelihood one by one, which is guaranteed, for certain Dependent Likelihood Structures, to not increase from its candidate value, until the desired number of top ranked hypotheses are obtained. Examples of such Dependent Likelihood Structures include the Collision Likelihood Structure and the Occlusion Likelihood Structure, both encountered frequently in applications.
Transfer learning for time series classification
Nov 05, 2018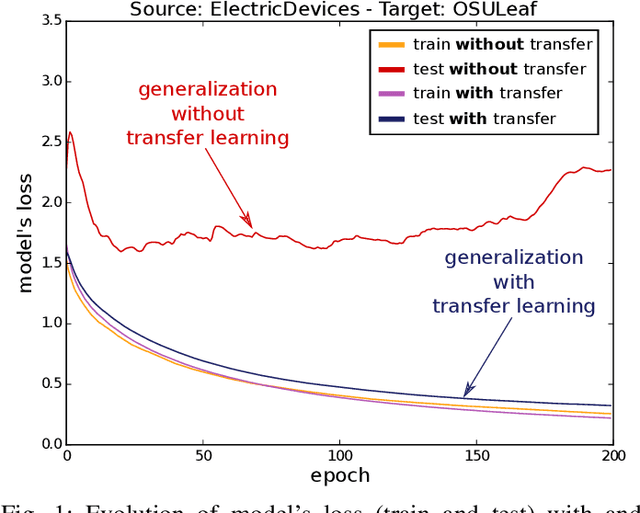
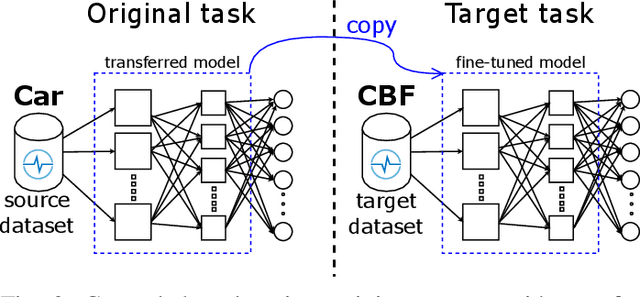
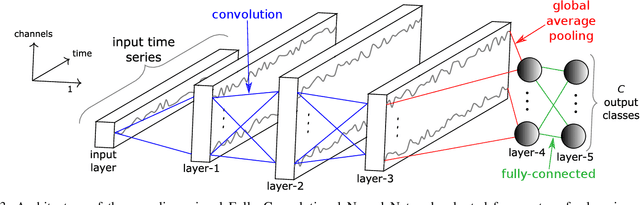
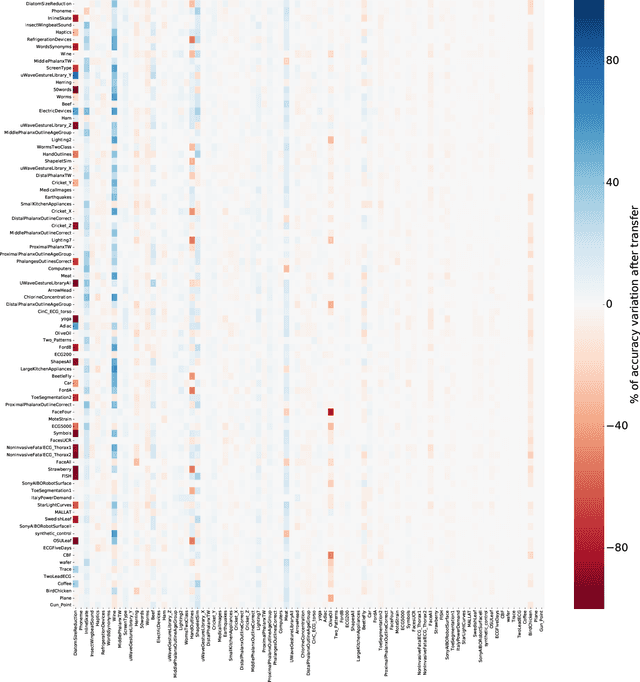
Transfer learning for deep neural networks is the process of first training a base network on a source dataset, and then transferring the learned features (the network's weights) to a second network to be trained on a target dataset. This idea has been shown to improve deep neural network's generalization capabilities in many computer vision tasks such as image recognition and object localization. Apart from these applications, deep Convolutional Neural Networks (CNNs) have also recently gained popularity in the Time Series Classification (TSC) community. However, unlike for image recognition problems, transfer learning techniques have not yet been investigated thoroughly for the TSC task. This is surprising as the accuracy of deep learning models for TSC could potentially be improved if the model is fine-tuned from a pre-trained neural network instead of training it from scratch. In this paper, we fill this gap by investigating how to transfer deep CNNs for the TSC task. To evaluate the potential of transfer learning, we performed extensive experiments using the UCR archive which is the largest publicly available TSC benchmark containing 85 datasets. For each dataset in the archive, we pre-trained a model and then fine-tuned it on the other datasets resulting in 7140 different deep neural networks. These experiments revealed that transfer learning can improve or degrade the model's predictions depending on the dataset used for transfer. Therefore, in an effort to predict the best source dataset for a given target dataset, we propose a new method relying on Dynamic Time Warping to measure inter-datasets similarities. We describe how our method can guide the transfer to choose the best source dataset leading to an improvement in accuracy on 71 out of 85 datasets.
Hybrid Memoised Wake-Sleep: Approximate Inference at the Discrete-Continuous Interface
Jul 04, 2021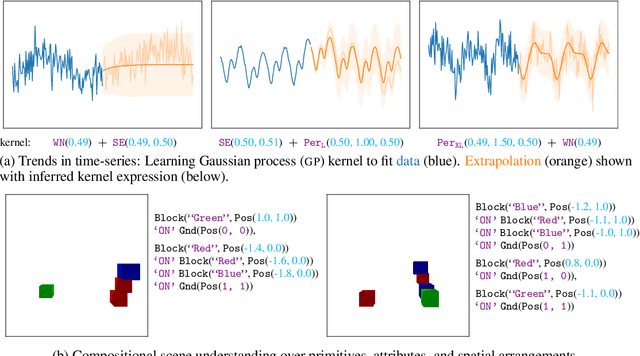
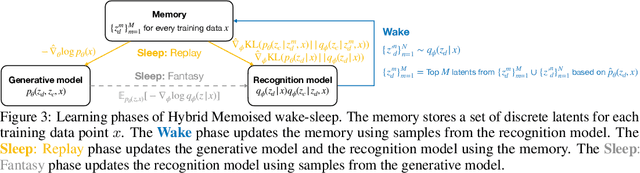
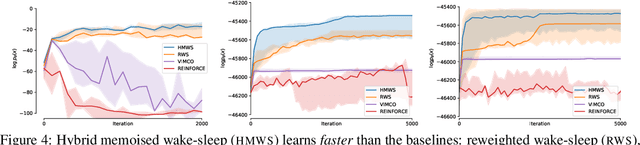
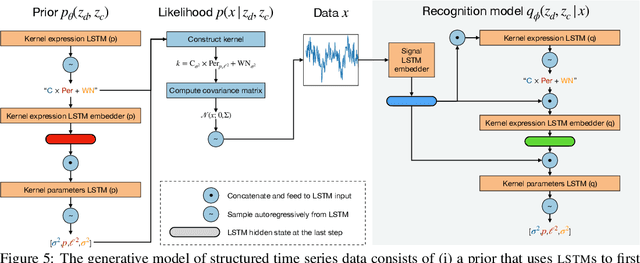
Modeling complex phenomena typically involves the use of both discrete and continuous variables. Such a setting applies across a wide range of problems, from identifying trends in time-series data to performing effective compositional scene understanding in images. Here, we propose Hybrid Memoised Wake-Sleep (HMWS), an algorithm for effective inference in such hybrid discrete-continuous models. Prior approaches to learning suffer as they need to perform repeated expensive inner-loop discrete inference. We build on a recent approach, Memoised Wake-Sleep (MWS), which alleviates part of the problem by memoising discrete variables, and extend it to allow for a principled and effective way to handle continuous variables by learning a separate recognition model used for importance-sampling based approximate inference and marginalization. We evaluate HMWS in the GP-kernel learning and 3D scene understanding domains, and show that it outperforms current state-of-the-art inference methods.
Neural Rays for Occlusion-aware Image-based Rendering
Jul 28, 2021
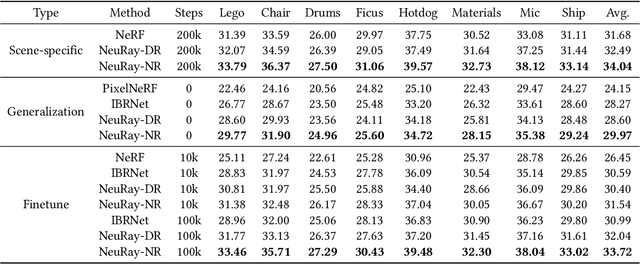
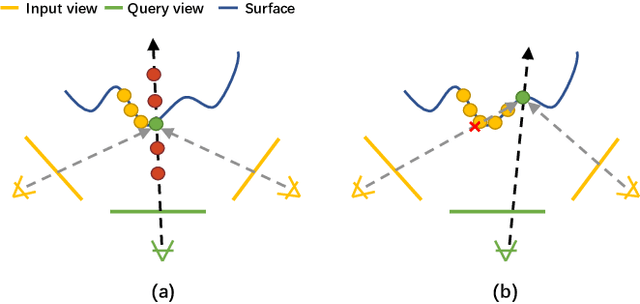
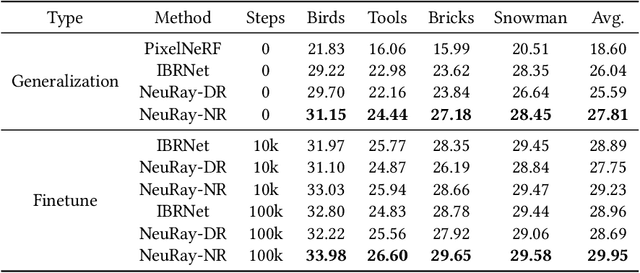
We present a new neural representation, called Neural Ray (NeuRay), for the novel view synthesis (NVS) task with multi-view images as input. Existing neural scene representations for solving the NVS problem, such as NeRF, cannot generalize to new scenes and take an excessively long time on training on each new scene from scratch. The other subsequent neural rendering methods based on stereo matching, such as PixelNeRF, SRF and IBRNet are designed to generalize to unseen scenes but suffer from view inconsistency in complex scenes with self-occlusions. To address these issues, our NeuRay method represents every scene by encoding the visibility of rays associated with the input views. This neural representation can efficiently be initialized from depths estimated by external MVS methods, which is able to generalize to new scenes and achieves satisfactory rendering images without any training on the scene. Then, the initialized NeuRay can be further optimized on every scene with little training timing to enforce spatial coherence to ensure view consistency in the presence of severe self-occlusion. Experiments demonstrate that NeuRay can quickly generate high-quality novel view images of unseen scenes with little finetuning and can handle complex scenes with severe self-occlusions which previous methods struggle with.
Distilling the Knowledge from Normalizing Flows
Jun 25, 2021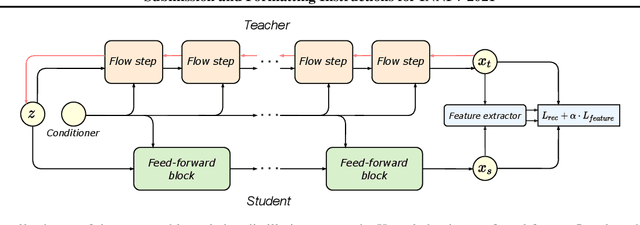
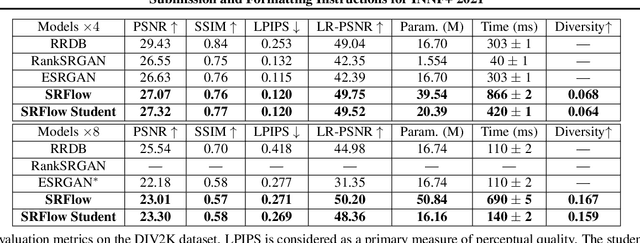
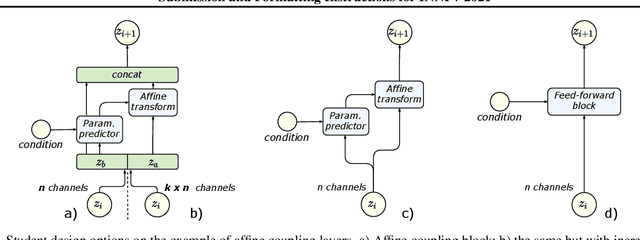
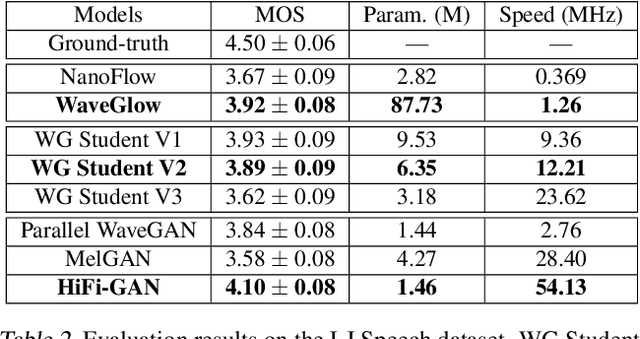
Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.