 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021


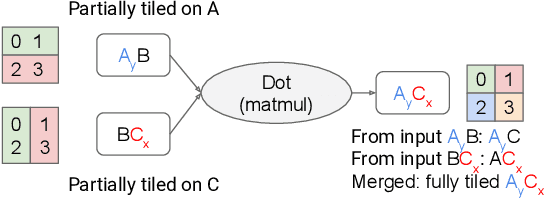
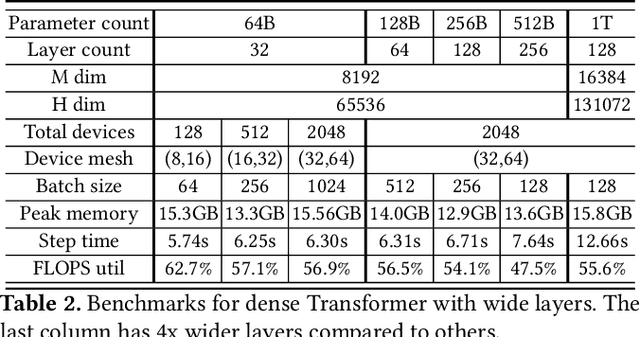
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Physics-informed generative neural network: an application to troposphere temperature prediction
Jul 08, 2021The troposphere is one of the atmospheric layers where most weather phenomena occur. Temperature variations in the troposphere, especially at 500 hPa, a typical level of the middle troposphere, are significant indicators of future weather changes. Numerical weather prediction is effective for temperature prediction, but its computational complexity hinders a timely response. This paper proposes a novel temperature prediction approach in framework ofphysics-informed deep learning. The new model, called PGnet, builds upon a generative neural network with a mask matrix. The mask is designed to distinguish the low-quality predicted regions generated by the first physical stage. The generative neural network takes the mask as prior for the second-stage refined predictions. A mask-loss and a jump pattern strategy are developed to train the generative neural network without accumulating errors during making time-series predictions. Experiments on ERA5 demonstrate that PGnet can generate more refined temperature predictions than the state-of-the-art.
Improving Sound Event Classification by Increasing Shift Invariance in Convolutional Neural Networks
Jul 22, 2021
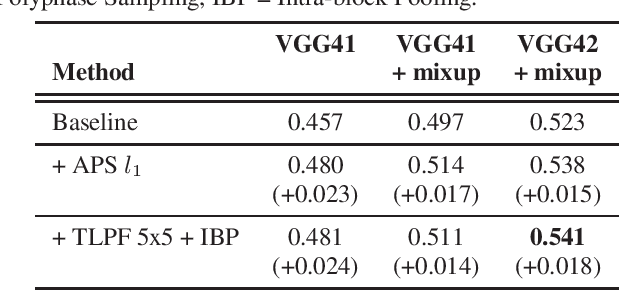

Recent studies have put into question the commonly assumed shift invariance property of convolutional networks, showing that small shifts in the input can affect the output predictions substantially. In this paper, we analyze the benefits of addressing lack of shift invariance in CNN-based sound event classification. Specifically, we evaluate two pooling methods to improve shift invariance in CNNs, based on low-pass filtering and adaptive sampling of incoming feature maps. These methods are implemented via small architectural modifications inserted into the pooling layers of CNNs. We evaluate the effect of these architectural changes on the FSD50K dataset using models of different capacity and in presence of strong regularization. We show that these modifications consistently improve sound event classification in all cases considered. We also demonstrate empirically that the proposed pooling methods increase shift invariance in the network, making it more robust against time/frequency shifts in input spectrograms. This is achieved by adding a negligible amount of trainable parameters, which makes these methods an appealing alternative to conventional pooling layers. The outcome is a new state-of-the-art mAP of 0.541 on the FSD50K classification benchmark.
Learning in Modal Space: Solving Time-Dependent Stochastic PDEs Using Physics-Informed Neural Networks
May 03, 2019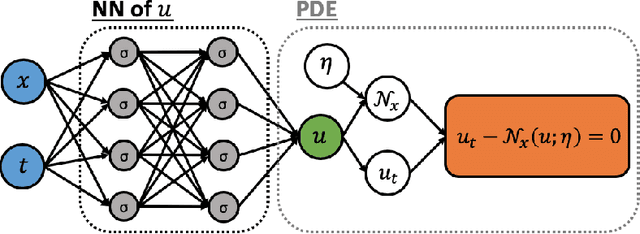
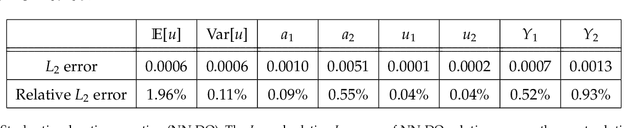
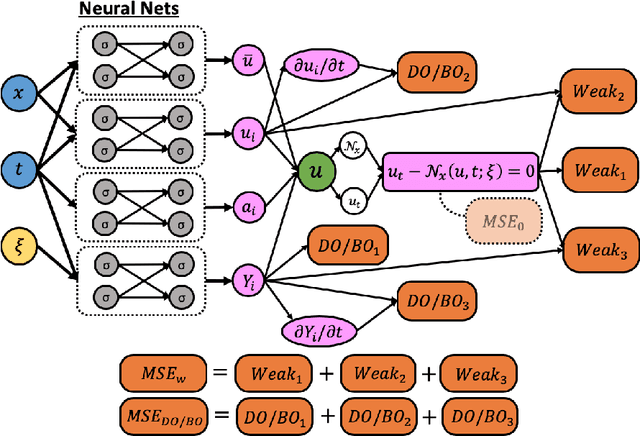

One of the open problems in scientific computing is the long-time integration of nonlinear stochastic partial differential equations (SPDEs). We address this problem by taking advantage of recent advances in scientific machine learning and the dynamically orthogonal (DO) and bi-orthogonal (BO) methods for representing stochastic processes. Specifically, we propose two new Physics-Informed Neural Networks (PINNs) for solving time-dependent SPDEs, namely the NN-DO/BO methods, which incorporate the DO/BO constraints into the loss function with an implicit form instead of generating explicit expressions for the temporal derivatives of the DO/BO modes. Hence, the proposed methods overcome some of the drawbacks of the original DO/BO methods: we do not need the assumption that the covariance matrix of the random coefficients is invertible as in the original DO method, and we can remove the assumption of no eigenvalue crossing as in the original BO method. Moreover, the NN-DO/BO methods can be used to solve time-dependent stochastic inverse problems with the same formulation and computational complexity as for forward problems. We demonstrate the capability of the proposed methods via several numerical examples: (1) A linear stochastic advection equation with deterministic initial condition where the original DO/BO method would fail; (2) Long-time integration of the stochastic Burgers' equation with many eigenvalue crossings during the whole time evolution where the original BO method fails. (3) Nonlinear reaction diffusion equation: we consider both the forward and the inverse problem, including noisy initial data, to investigate the flexibility of the NN-DO/BO methods in handling inverse and mixed type problems. Taken together, these simulation results demonstrate that the NN-DO/BO methods can be employed to effectively quantify uncertainty propagation in a wide range of physical problems.
TSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity
Aug 18, 2021
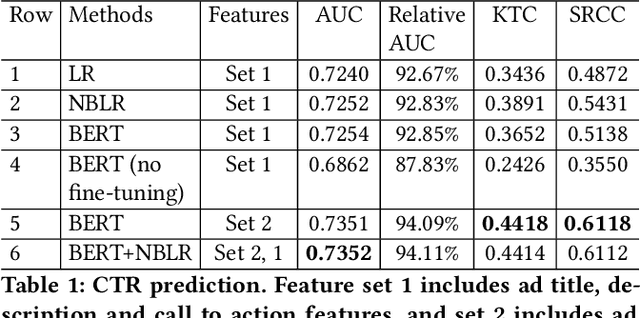
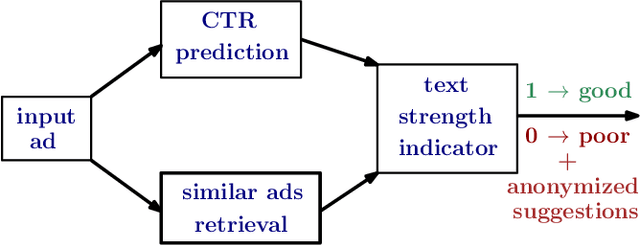

Coming up with effective ad text is a time consuming process, and particularly challenging for small businesses with limited advertising experience. When an inexperienced advertiser onboards with a poorly written ad text, the ad platform has the opportunity to detect low performing ad text, and provide improvement suggestions. To realize this opportunity, we propose an ad text strength indicator (TSI) which: (i) predicts the click-through-rate (CTR) for an input ad text, (ii) fetches similar existing ads to create a neighborhood around the input ad, (iii) and compares the predicted CTRs in the neighborhood to declare whether the input ad is strong or weak. In addition, as suggestions for ad text improvement, TSI shows anonymized versions of superior ads (higher predicted CTR) in the neighborhood. For (i), we propose a BERT based text-to-CTR model trained on impressions and clicks associated with an ad text. For (ii), we propose a sentence-BERT based semantic-ad-similarity model trained using weak labels from ad campaign setup data. Offline experiments demonstrate that our BERT based text-to-CTR model achieves a significant lift in CTR prediction AUC for cold start (new) advertisers compared to bag-of-words based baselines. In addition, our semantic-textual-similarity model for similar ads retrieval achieves a precision@1 of 0.93 (for retrieving ads from the same product category); this is significantly higher compared to unsupervised TF-IDF, word2vec, and sentence-BERT baselines. Finally, we share promising online results from advertisers in the Yahoo (Verizon Media) ad platform where a variant of TSI was implemented with sub-second end-to-end latency.
Internet-Augmented Dialogue Generation
Jul 15, 2021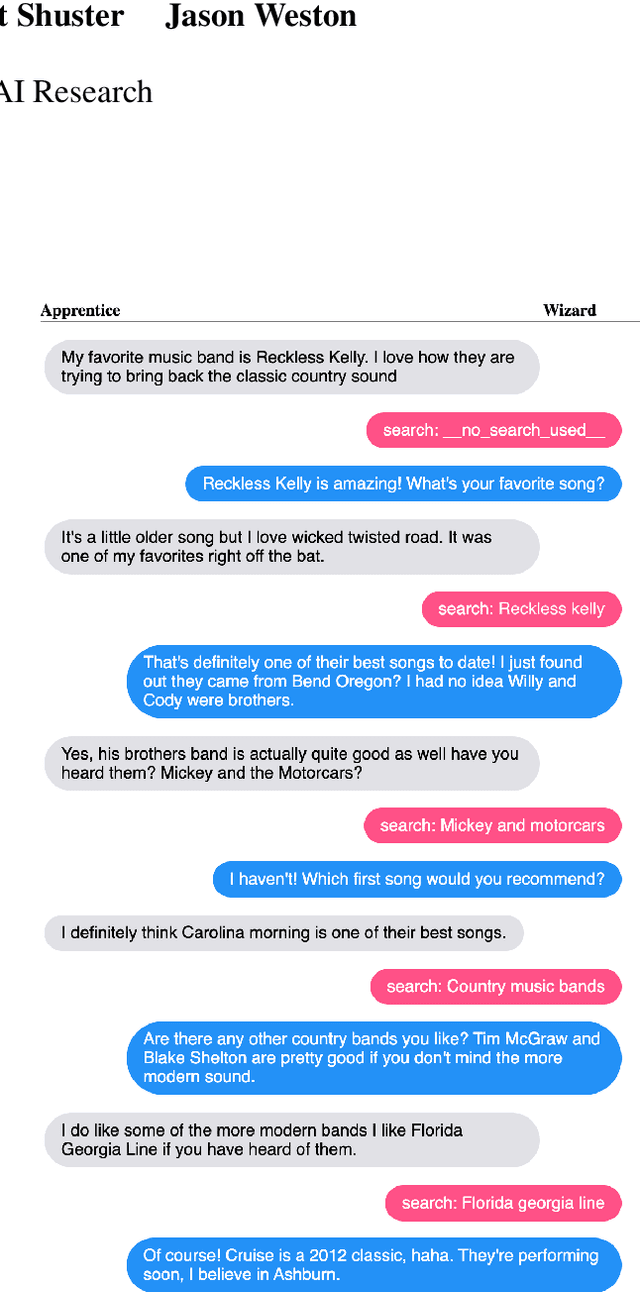
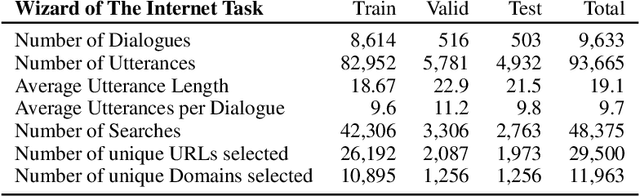
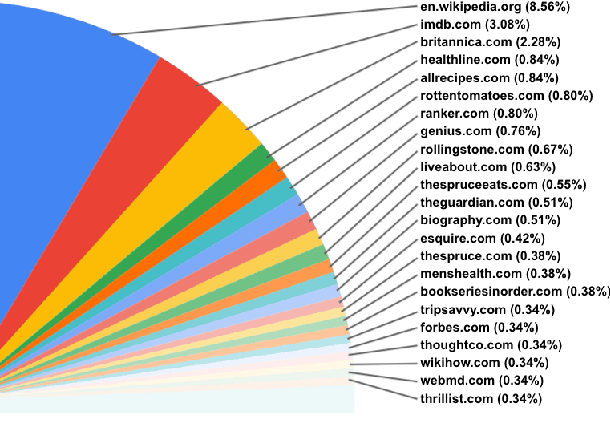
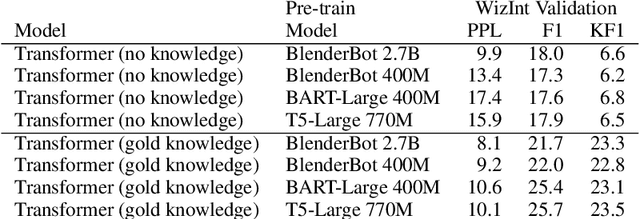
The largest store of continually updating knowledge on our planet can be accessed via internet search. In this work we study giving access to this information to conversational agents. Large language models, even though they store an impressive amount of knowledge within their weights, are known to hallucinate facts when generating dialogue (Shuster et al., 2021); moreover, those facts are frozen in time at the point of model training. In contrast, we propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information. We train and evaluate such models on a newly collected dataset of human-human conversations whereby one of the speakers is given access to internet search during knowledgedriven discussions in order to ground their responses. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval (Lewis et al., 2020).
Predicting colorectal polyp recurrence using time-to-event analysis of medical records
Nov 18, 2019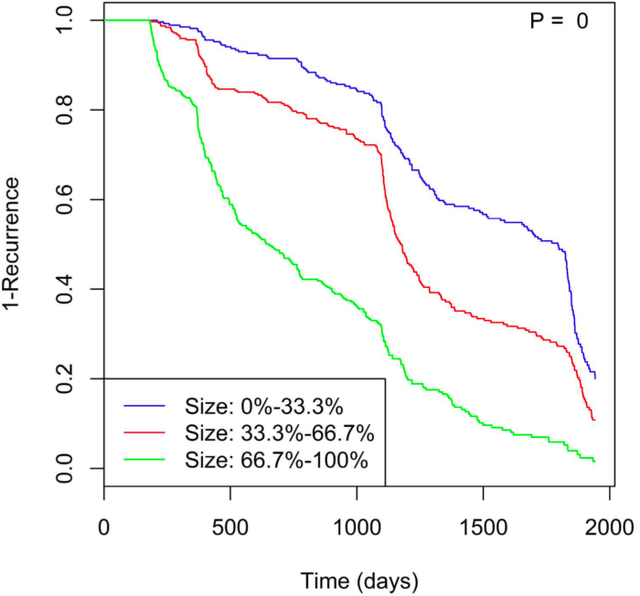
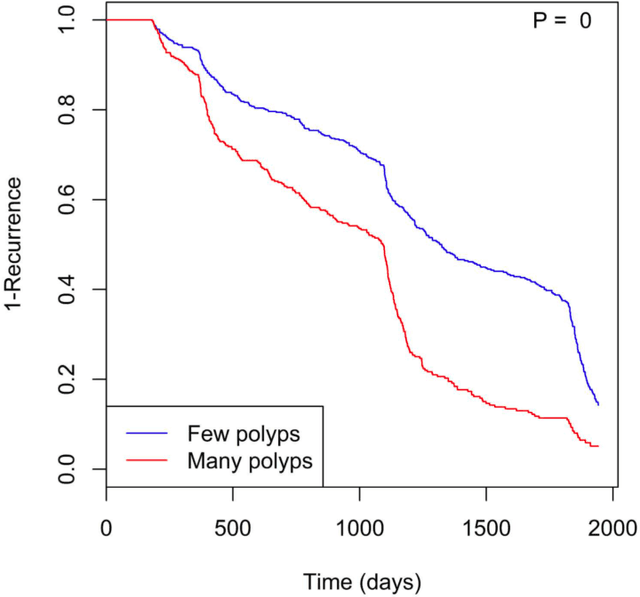
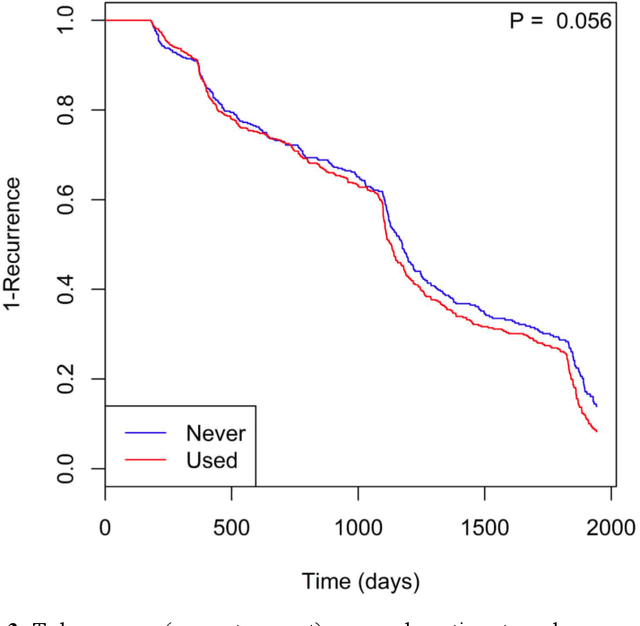
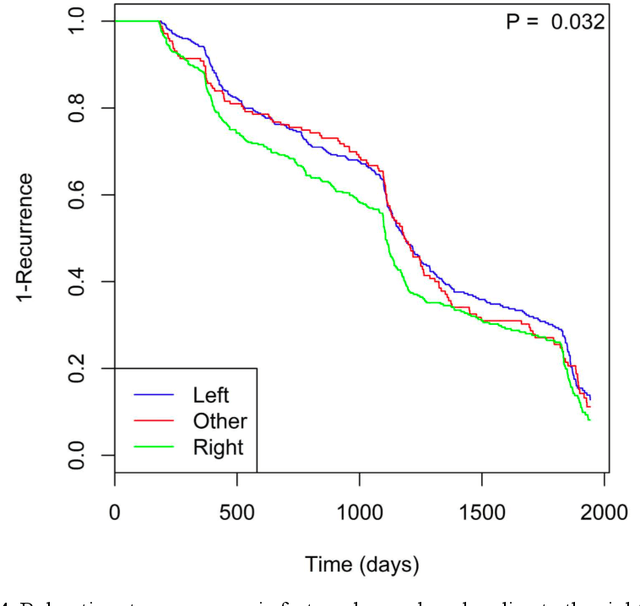
Identifying patient characteristics that influence the rate of colorectal polyp recurrence can provide important insights into which patients are at higher risk for recurrence. We used natural language processing to extract polyp morphological characteristics from 953 polyp-presenting patients' electronic medical records. We used subsequent colonoscopy reports to examine how the time to polyp recurrence (731 patients experienced recurrence) is influenced by these characteristics as well as anthropometric features using Kaplan-Meier curves, Cox proportional hazards modeling, and random survival forest models. We found that the rate of recurrence differed significantly by polyp size, number, and location and patient smoking status. Additionally, right-sided colon polyps increased recurrence risk by 30% compared to left-sided polyps. History of tobacco use increased polyp recurrence risk by 20% compared to never-users. A random survival forest model showed an AUC of 0.65 and identified several other predictive variables, which can inform development of personalized polyp surveillance plans.
Subgraph Federated Learning with Missing Neighbor Generation
Jul 22, 2021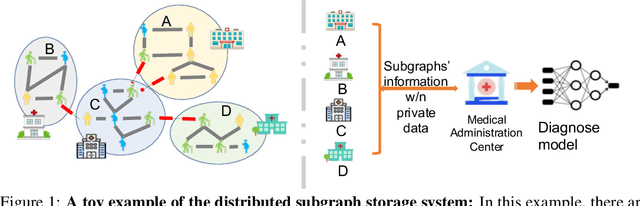
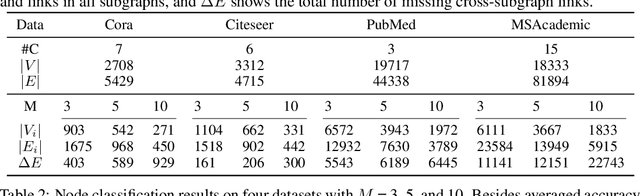
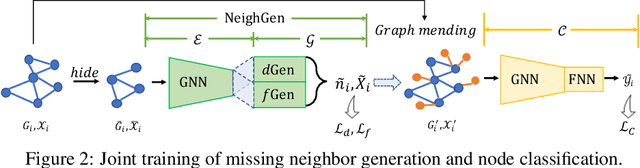
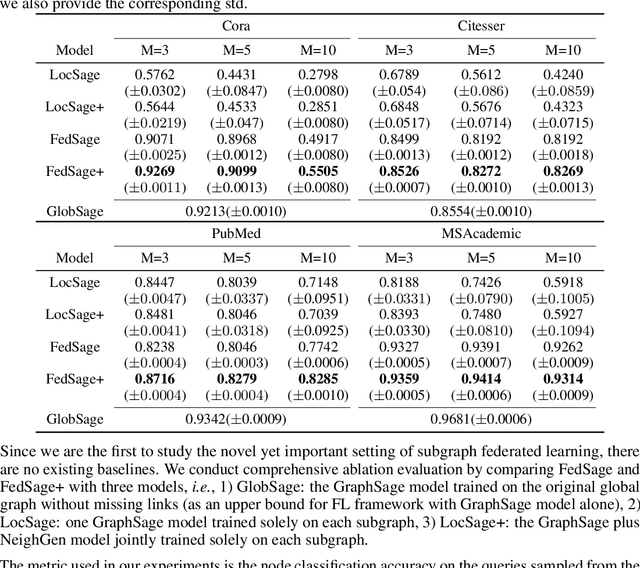
Graphs have been widely used in data mining and machine learning due to their unique representation of real-world objects and their interactions. As graphs are getting bigger and bigger nowadays, it is common to see their subgraphs separately collected and stored in multiple local systems. Therefore, it is natural to consider the subgraph federated learning setting, where each local system holding a small subgraph that may be biased from the distribution of the whole graph. Hence, the subgraph federated learning aims to collaboratively train a powerful and generalizable graph mining model without directly sharing their graph data. In this work, towards the novel yet realistic setting of subgraph federated learning, we propose two major techniques: (1) FedSage, which trains a GraphSage model based on FedAvg to integrate node features, link structures, and task labels on multiple local subgraphs; (2) FedSage+, which trains a missing neighbor generator along FedSage to deal with missing links across local subgraphs. Empirical results on four real-world graph datasets with synthesized subgraph federated learning settings demonstrate the effectiveness and efficiency of our proposed techniques. At the same time, consistent theoretical implications are made towards their generalization ability on the global graphs.
STRIDE : Scene Text Recognition In-Device
May 17, 2021
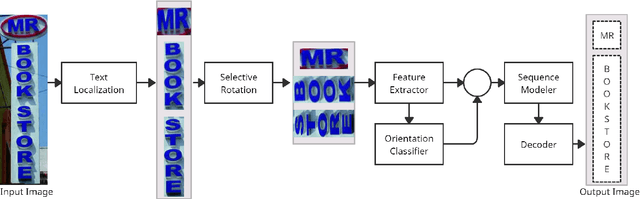
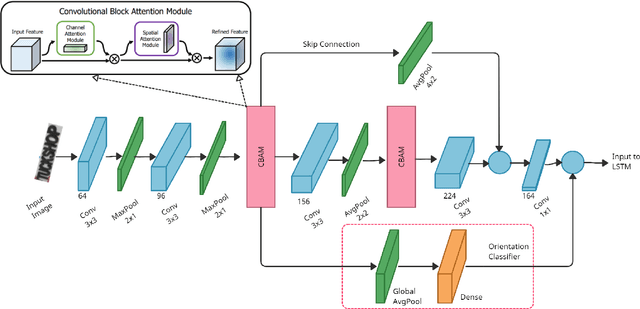

Optical Character Recognition (OCR) systems have been widely used in various applications for extracting semantic information from images. To give the user more control over their privacy, an on-device solution is needed. The current state-of-the-art models are too heavy and complex to be deployed on-device. We develop an efficient lightweight scene text recognition (STR) system, which has only 0.88M parameters and performs real-time text recognition. Attention modules tend to boost the accuracy of STR networks but are generally slow and not optimized for device inference. So, we propose the use of convolution attention modules to the text recognition networks, which aims to provide channel and spatial attention information to the LSTM module by adding very minimal computational cost. It boosts our word accuracy on ICDAR 13 dataset by almost 2\%. We also introduce a novel orientation classifier module, to support the simultaneous recognition of both horizontal and vertical text. The proposed model surpasses on-device metrics of inference time and memory footprint and achieves comparable accuracy when compared to the leading commercial and other open-source OCR engines. We deploy the system on-device with an inference speed of 2.44 ms per word on the Exynos 990 chipset device and achieve an accuracy of 88.4\% on ICDAR-13 dataset.
Sequoia: A Software Framework to Unify Continual Learning Research
Aug 03, 2021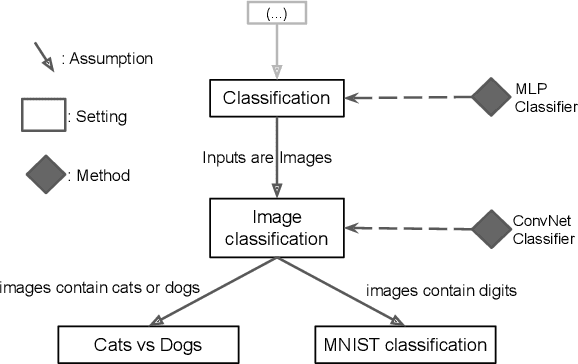
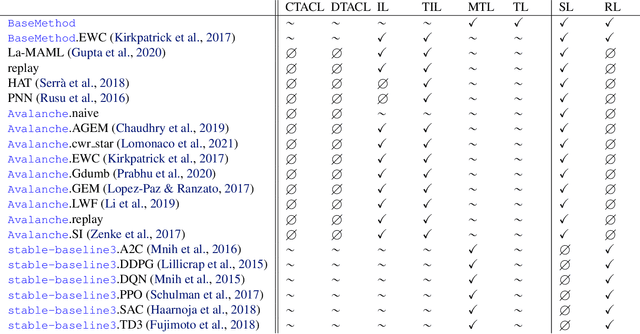
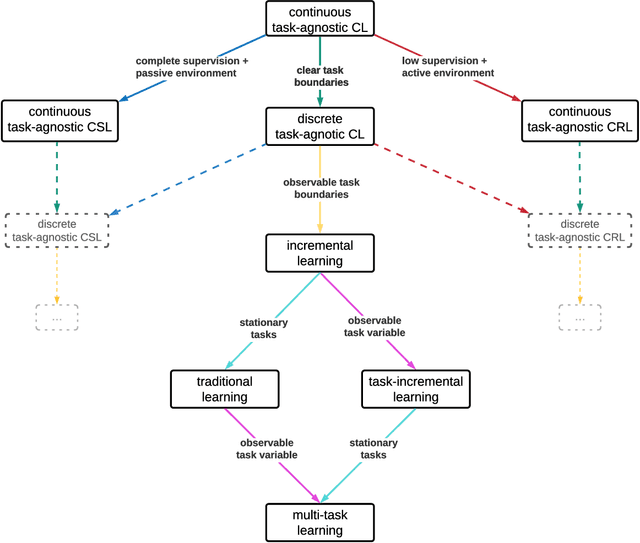
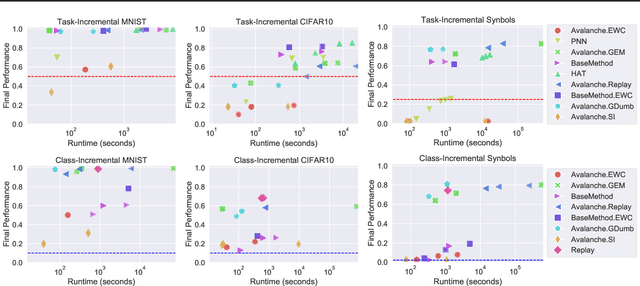
The field of Continual Learning (CL) seeks to develop algorithms that accumulate knowledge and skills over time through interaction with non-stationary environments and data distributions. Measuring progress in CL can be difficult because a plethora of evaluation procedures (ettings) and algorithmic solutions (methods) have emerged, each with their own potentially disjoint set of assumptions about the CL problem. In this work, we view each setting as a set of assumptions. We then create a tree-shaped hierarchy of the research settings in CL, in which more general settings become the parents of those with more restrictive assumptions. This makes it possible to use inheritance to share and reuse research, as developing a method for a given setting also makes it directly applicable onto any of its children. We instantiate this idea as a publicly available software framework called Sequoia, which features a variety of settings from both the Continual Supervised Learning (CSL) and Continual Reinforcement Learning (CRL) domains. Sequoia also includes a growing suite of methods which are easy to extend and customize, in addition to more specialized methods from third-party libraries. We hope that this new paradigm and its first implementation can serve as a foundation for the unification and acceleration of research in CL. You can help us grow the tree by visiting www.github.com/lebrice/Sequoia.