 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Traffic Speed Dynamics from Visualizations
May 04, 2021
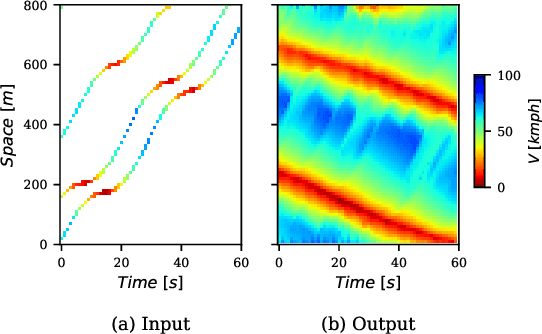
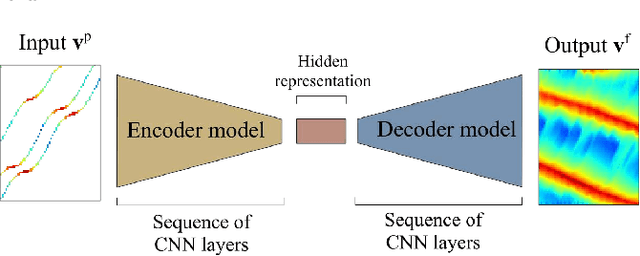
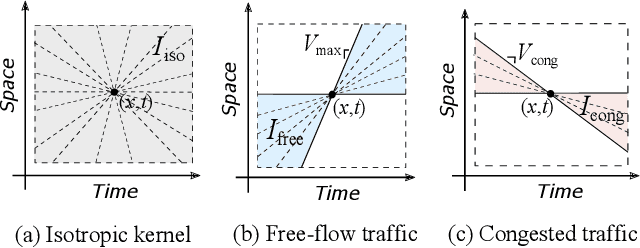
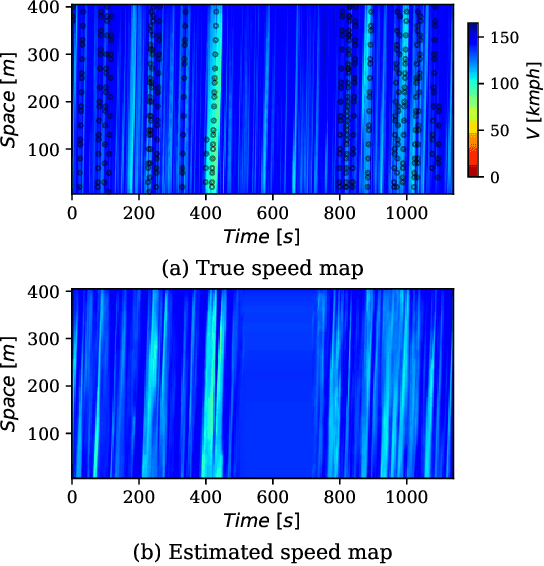
Space-time visualizations of macroscopic or microscopic traffic variables is a qualitative tool used by traffic engineers to understand and analyze different aspects of road traffic dynamics. We present a deep learning method to learn the macroscopic traffic speed dynamics from these space-time visualizations, and demonstrate its application in the framework of traffic state estimation. Compared to existing estimation approaches, our approach allows a finer estimation resolution, eliminates the dependence on the initial conditions, and is agnostic to external factors such as traffic demand, road inhomogeneities and driving behaviors. Our model respects causality in traffic dynamics, which improves the robustness of estimation. We present the high-resolution traffic speed fields estimated for several freeway sections using the data obtained from the Next Generation Simulation Program (NGSIM) and German Highway (HighD) datasets. We further demonstrate the quality and utility of the estimation by inferring vehicle trajectories from the estimated speed fields, and discuss the benefits of deep neural network models in approximating the traffic dynamics.
Time to Die: Death Prediction in Dota 2 using Deep Learning
May 21, 2019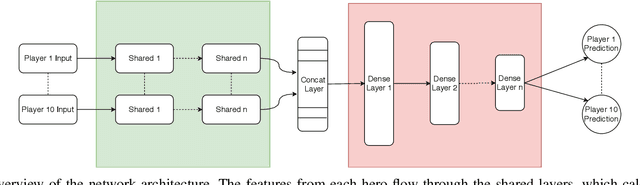
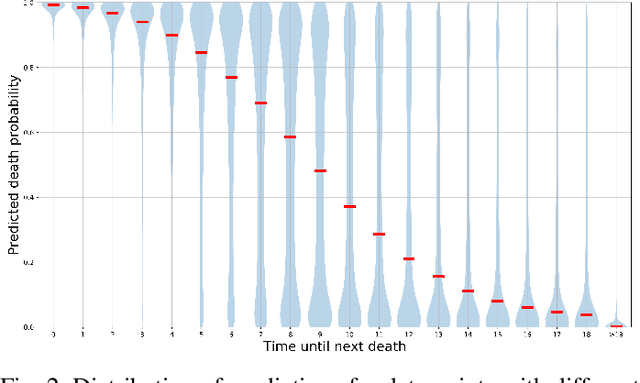
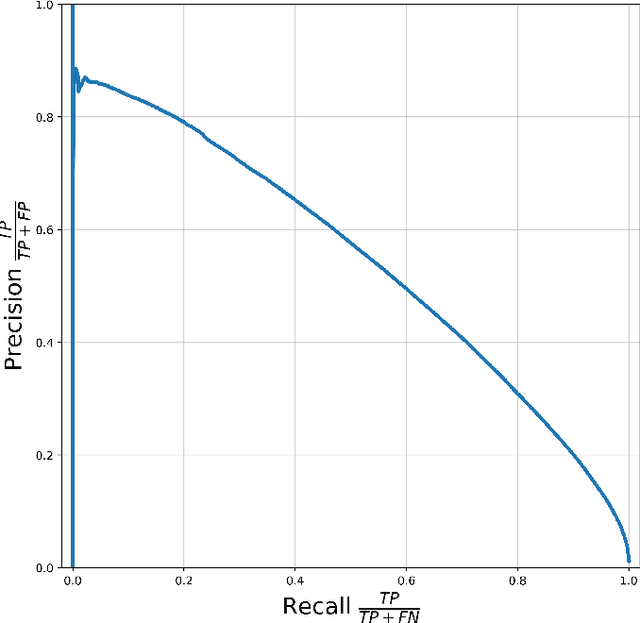
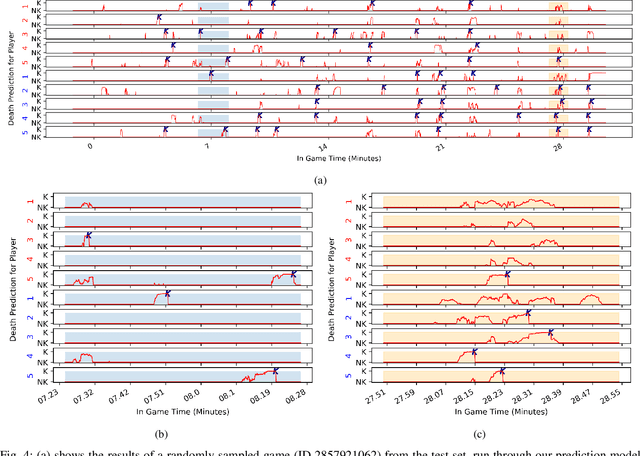
Esports have become major international sports with hundreds of millions of spectators. Esports games generate massive amounts of telemetry data. Using these to predict the outcome of esports matches has received considerable attention, but micro-predictions, which seek to predict events inside a match, is as yet unknown territory. Micro-predictions are however of perennial interest across esports commentators and audience, because they provide the ability to observe events that might otherwise be missed: esports games are highly complex with fast-moving action where the balance of a game can change in the span of seconds, and where events can happen in multiple areas of the playing field at the same time. Such events can happen rapidly, and it is easy for commentators and viewers alike to miss an event and only observe the following impact of events. In Dota 2, a player hero being killed by the opposing team is a key event of interest to commentators and audience. We present a deep learning network with shared weights which provides accurate death predictions within a five-second window. The network is trained on a vast selection of Dota 2 gameplay features and professional/semi-professional level match dataset. Even though death events are rare within a game (1\% of the data), the model achieves 0.377 precision with 0.725 recall on test data when prompted to predict which of any of the 10 players of either team will die within 5 seconds. An example of the system applied to a Dota 2 match is presented. This model enables real-time micro-predictions of kills in Dota 2, one of the most played esports titles in the world, giving commentators and viewers time to move their attention to these key events.
Using Query Expansion in Manifold Ranking for Query-Oriented Multi-Document Summarization
Jul 31, 2021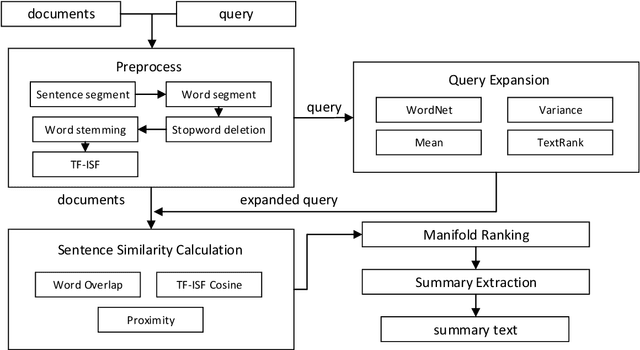
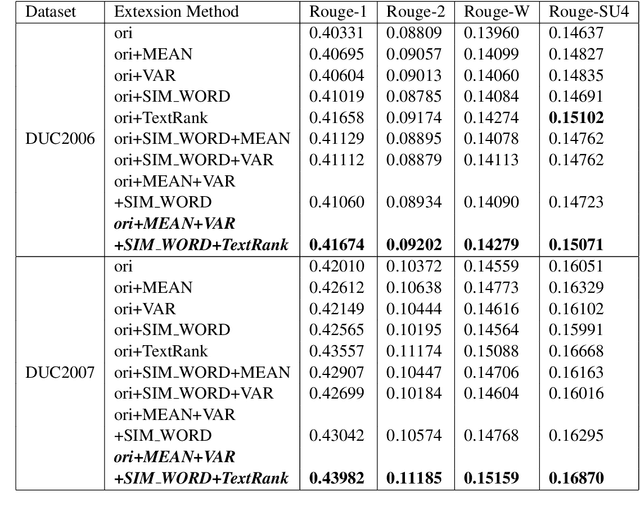
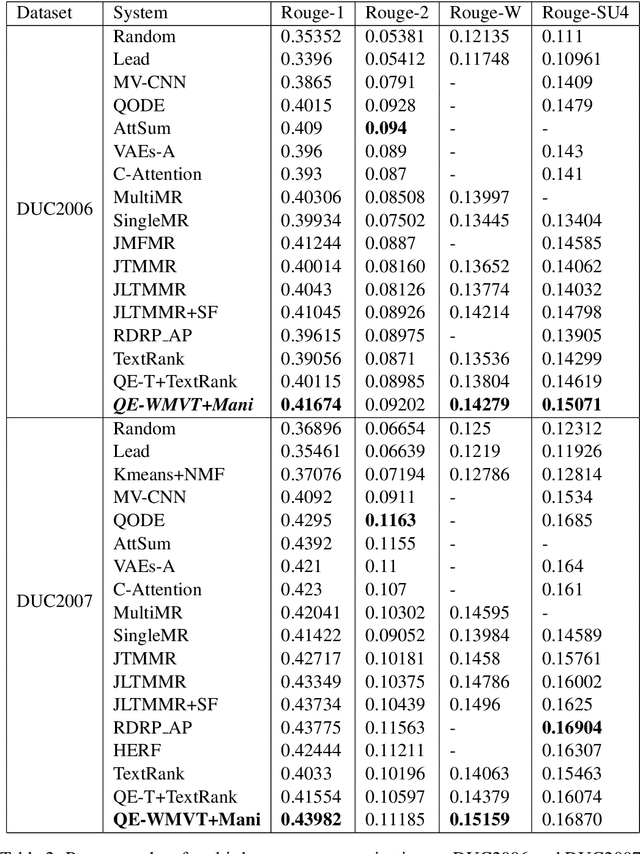
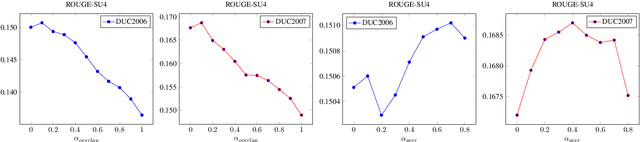
Manifold ranking has been successfully applied in query-oriented multi-document summarization. It not only makes use of the relationships among the sentences, but also the relationships between the given query and the sentences. However, the information of original query is often insufficient. So we present a query expansion method, which is combined in the manifold ranking to resolve this problem. Our method not only utilizes the information of the query term itself and the knowledge base WordNet to expand it by synonyms, but also uses the information of the document set itself to expand the query in various ways (mean expansion, variance expansion and TextRank expansion). Compared with the previous query expansion methods, our method combines multiple query expansion methods to better represent query information, and at the same time, it makes a useful attempt on manifold ranking. In addition, we use the degree of word overlap and the proximity between words to calculate the similarity between sentences. We performed experiments on the datasets of DUC 2006 and DUC2007, and the evaluation results show that the proposed query expansion method can significantly improve the system performance and make our system comparable to the state-of-the-art systems.
Dynamic Computational Time for Visual Attention
Sep 07, 2017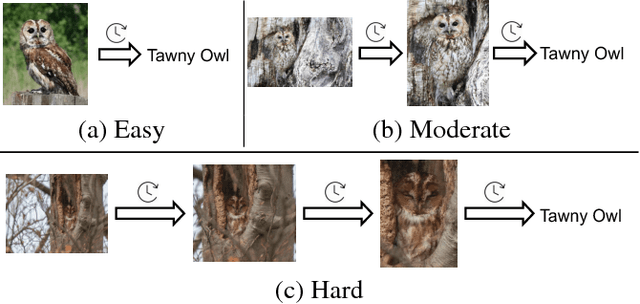
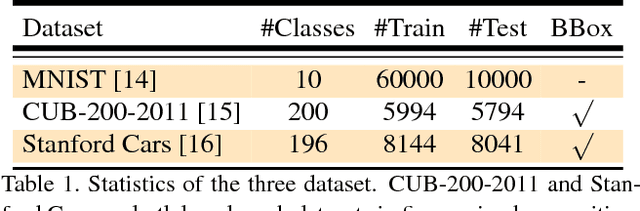
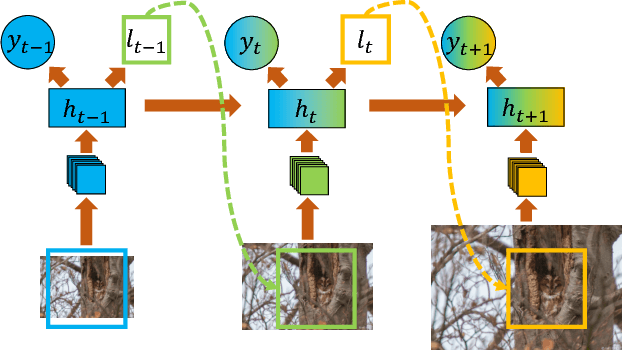

We propose a dynamic computational time model to accelerate the average processing time for recurrent visual attention (RAM). Rather than attention with a fixed number of steps for each input image, the model learns to decide when to stop on the fly. To achieve this, we add an additional continue/stop action per time step to RAM and use reinforcement learning to learn both the optimal attention policy and stopping policy. The modification is simple but could dramatically save the average computational time while keeping the same recognition performance as RAM. Experimental results on CUB-200-2011 and Stanford Cars dataset demonstrate the dynamic computational model can work effectively for fine-grained image recognition.The source code of this paper can be obtained from https://github.com/baidu-research/DT-RAM
OpTorch: Optimized deep learning architectures for resource limited environments
May 04, 2021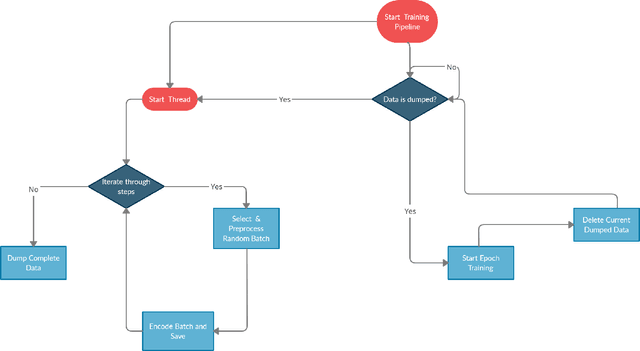
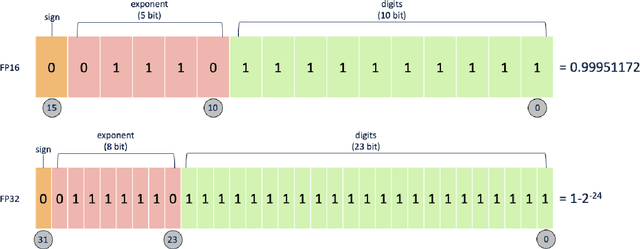
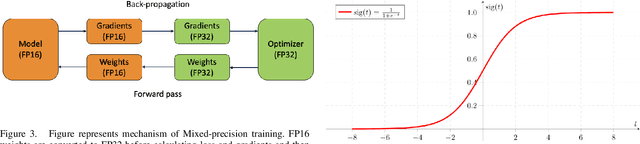
Deep learning algorithms have made many breakthroughs and have various applications in real life. Computational resources become a bottleneck as the data and complexity of the deep learning pipeline increases. In this paper, we propose optimized deep learning pipelines in multiple aspects of training including time and memory. OpTorch is a machine learning library designed to overcome weaknesses in existing implementations of neural network training. OpTorch provides features to train complex neural networks with limited computational resources. OpTorch achieved the same accuracy as existing libraries on Cifar-10 and Cifar-100 datasets while reducing memory usage to approximately 50%. We also explore the effect of weights on total memory usage in deep learning pipelines. In our experiments, parallel encoding-decoding along with sequential checkpoints results in much improved memory and time usage while keeping the accuracy similar to existing pipelines. OpTorch python package is available at available at https://github.com/cbrl-nuces/optorch
O-HAS: Optical Hardware Accelerator Search for Boosting Both Acceleration Performance and Development Speed
Aug 17, 2021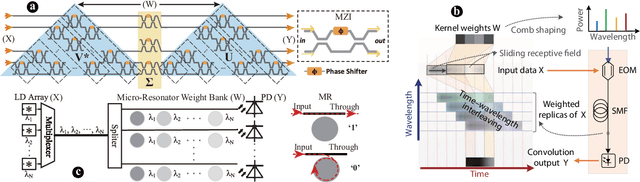
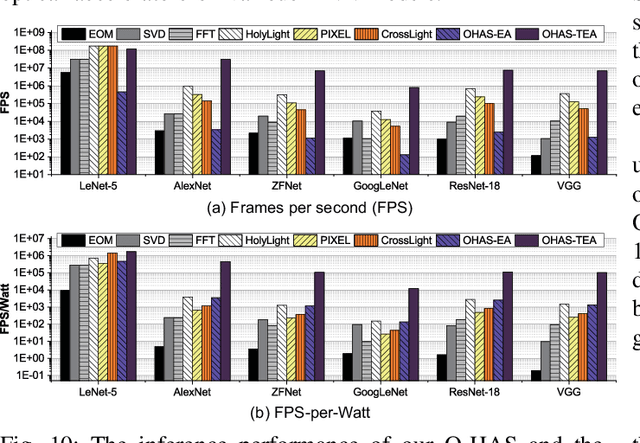
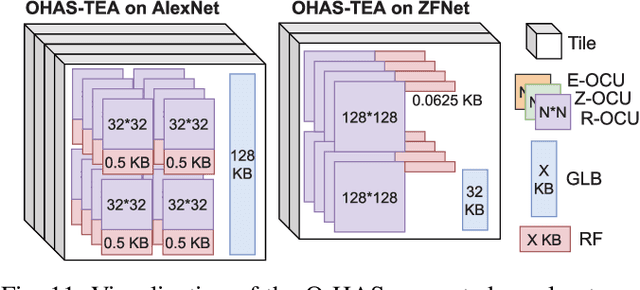
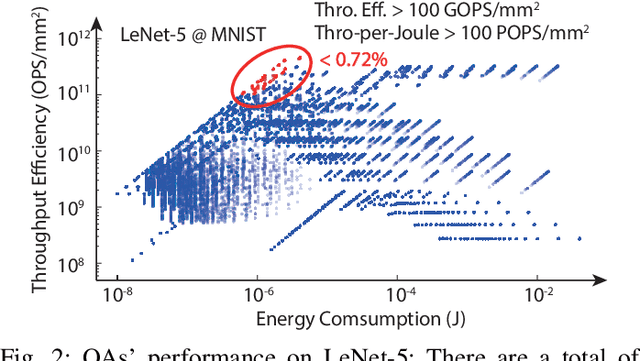
The recent breakthroughs and prohibitive complexities of Deep Neural Networks (DNNs) have excited extensive interest in domain-specific DNN accelerators, among which optical DNN accelerators are particularly promising thanks to their unprecedented potential of achieving superior performance-per-watt. However, the development of optical DNN accelerators is much slower than that of electrical DNN accelerators. One key challenge is that while many techniques have been developed to facilitate the development of electrical DNN accelerators, techniques that support or expedite optical DNN accelerator design remain much less explored, limiting both the achievable performance and the innovation development of optical DNN accelerators. To this end, we develop the first-of-its-kind framework dubbed O-HAS, which for the first time demonstrates automated Optical Hardware Accelerator Search for boosting both the acceleration efficiency and development speed of optical DNN accelerators. Specifically, our O-HAS consists of two integrated enablers: (1) an O-Cost Predictor, which can accurately yet efficiently predict an optical accelerator's energy and latency based on the DNN model parameters and the optical accelerator design; and (2) an O-Search Engine, which can automatically explore the large design space of optical DNN accelerators and identify the optimal accelerators (i.e., the micro-architectures and algorithm-to-accelerator mapping methods) in order to maximize the target acceleration efficiency. Extensive experiments and ablation studies consistently validate the effectiveness of both our O-Cost Predictor and O-Search Engine as well as the excellent efficiency of O-HAS generated optical accelerators.
Linear Contact-Implicit Model-Predictive Control
Jul 12, 2021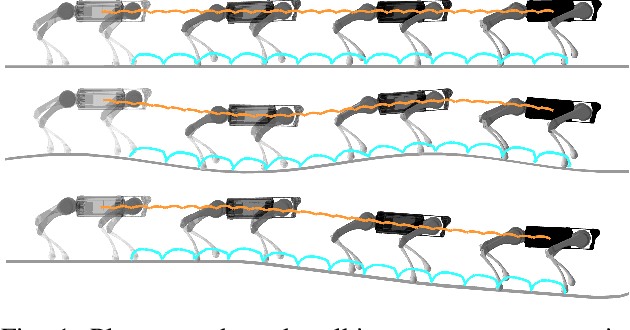
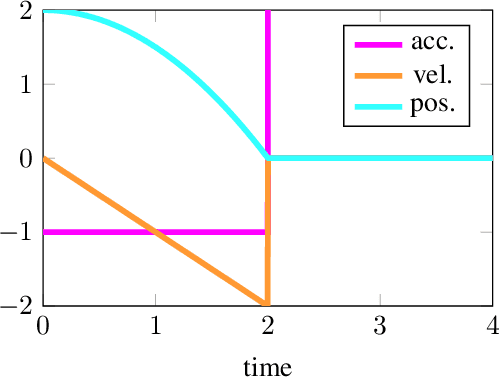

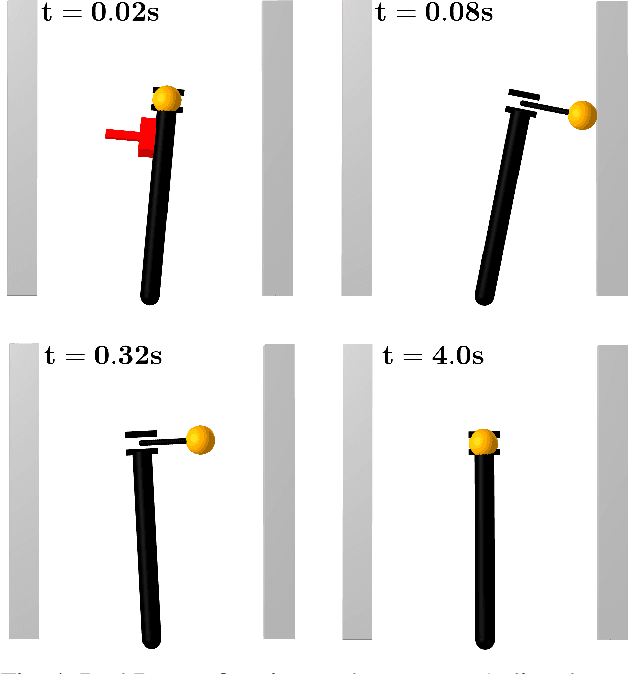
We present a general approach for controlling robotic systems that make and break contact with their environments: linear contact-implicit model-predictive control (LCI-MPC). Our use of differentiable contact dynamics provides a natural extension of linear model-predictive control to contact-rich settings. The policy leverages precomputed linearizations about a reference state or trajectory while contact modes, encoded via complementarity constraints, are explicitly retained, resulting in policies that can be efficiently evaluated while maintaining robustness to changes in contact timings. In many cases, the algorithm is even capable of generating entirely new contact sequences. To enable real-time performance, we devise a custom structure-exploiting linear solver for the contact dynamics. We demonstrate that the policy can respond to disturbances by discovering and exploiting new contact modes and is robust to model mismatch and unmodeled environments for a collection of simulated robotic systems, including: pushbot, hopper, quadruped, and biped.
Deep Learning-based Biological Anatomical Landmark Detection in Colonoscopy Videos
Aug 06, 2021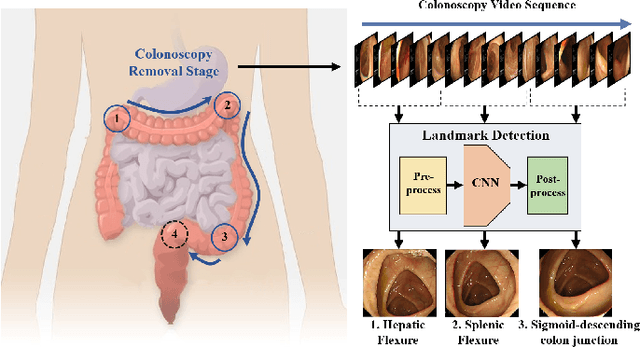
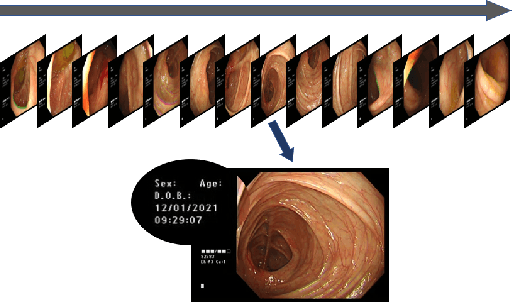
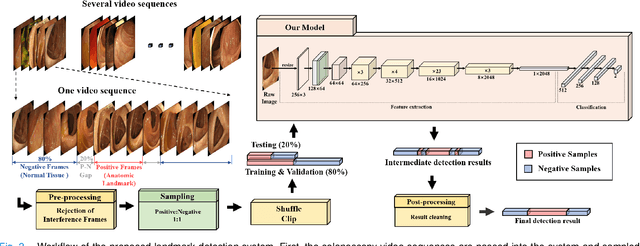
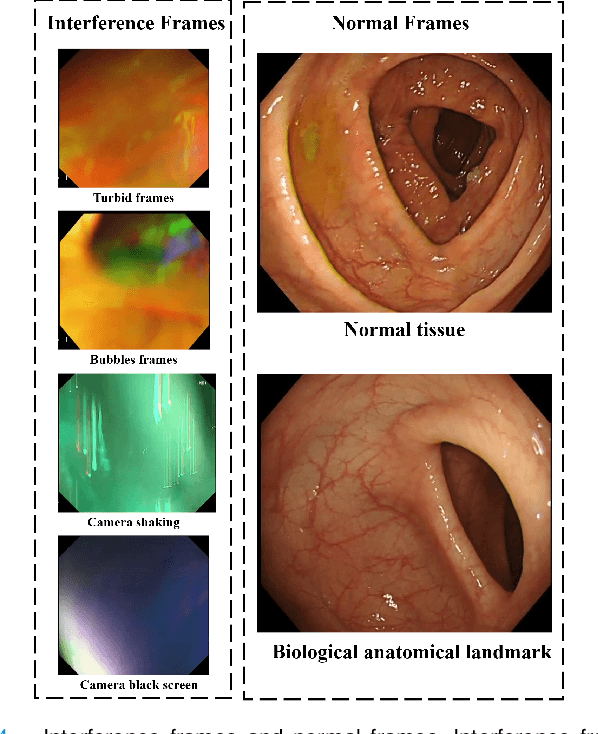
Colonoscopy is a standard imaging tool for visualizing the entire gastrointestinal (GI) tract of patients to capture lesion areas. However, it takes the clinicians excessive time to review a large number of images extracted from colonoscopy videos. Thus, automatic detection of biological anatomical landmarks within the colon is highly demanded, which can help reduce the burden of clinicians by providing guidance information for the locations of lesion areas. In this article, we propose a novel deep learning-based approach to detect biological anatomical landmarks in colonoscopy videos. First, raw colonoscopy video sequences are pre-processed to reject interference frames. Second, a ResNet-101 based network is used to detect three biological anatomical landmarks separately to obtain the intermediate detection results. Third, to achieve more reliable localization of the landmark periods within the whole video period, we propose to post-process the intermediate detection results by identifying the incorrectly predicted frames based on their temporal distribution and reassigning them back to the correct class. Finally, the average detection accuracy reaches 99.75\%. Meanwhile, the average IoU of 0.91 shows a high degree of similarity between our predicted landmark periods and ground truth. The experimental results demonstrate that our proposed model is capable of accurately detecting and localizing biological anatomical landmarks from colonoscopy videos.
A Modest Pareto Optimisation Analysis of Dependency Parsers in 2021
Jun 08, 2021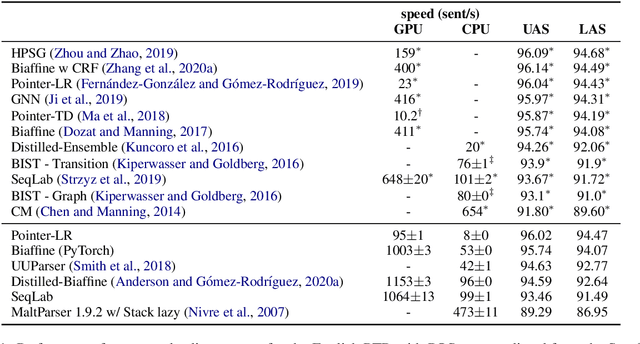
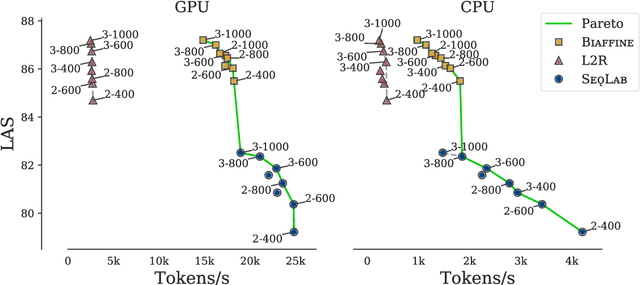
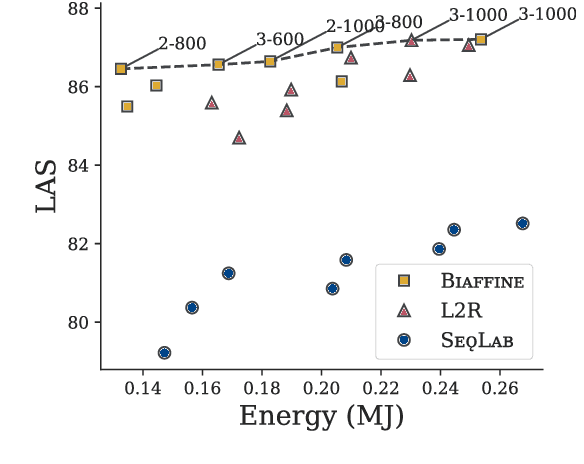

We evaluate three leading dependency parser systems from different paradigms on a small yet diverse subset of languages in terms of their accuracy-efficiency Pareto front. As we are interested in efficiency, we evaluate core parsers without pretrained language models (as these are typically huge networks and would constitute most of the compute time) or other augmentations that can be transversally applied to any of them. Biaffine parsing emerges as a well-balanced default choice, with sequence-labelling parsing being preferable if inference speed (but not training energy cost) is the priority.
Time-Guided High-Order Attention Model of Longitudinal Heterogeneous Healthcare Data
Nov 28, 2019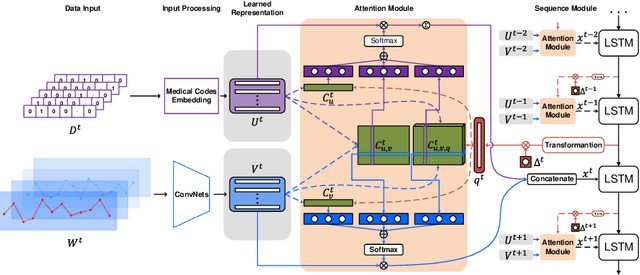
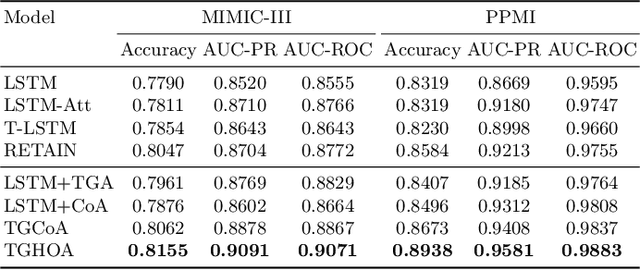
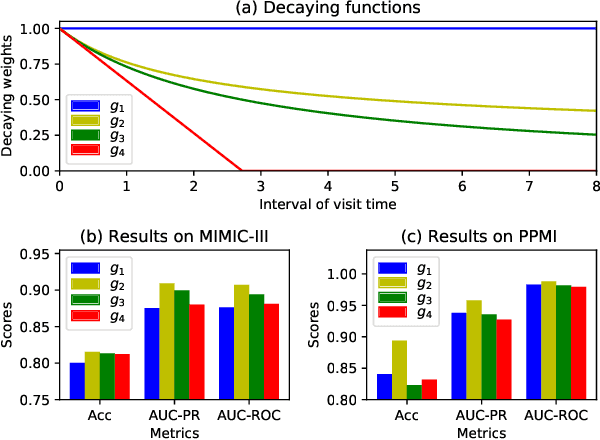

Due to potential applications in chronic disease management and personalized healthcare, the EHRs data analysis has attracted much attention of both researchers and practitioners. There are three main challenges in modeling longitudinal and heterogeneous EHRs data: heterogeneity, irregular temporality and interpretability. A series of deep learning methods have made remarkable progress in resolving these challenges. Nevertheless, most of existing attention models rely on capturing the 1-order temporal dependencies or 2-order multimodal relationships among feature elements. In this paper, we propose a time-guided high-order attention (TGHOA) model. The proposed method has three major advantages. (1) It can model longitudinal heterogeneous EHRs data via capturing the 3-order correlations of different modalities and the irregular temporal impact of historical events. (2) It can be used to identify the potential concerns of medical features to explain the reasoning process of the healthcare model. (3) It can be easily expanded into cases with more modalities and flexibly applied in different prediction tasks. We evaluate the proposed method in two tasks of mortality prediction and disease ranking on two real world EHRs datasets. Extensive experimental results show the effectiveness of the proposed model.