 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Score-Based Point Cloud Denoising
Jul 23, 2021
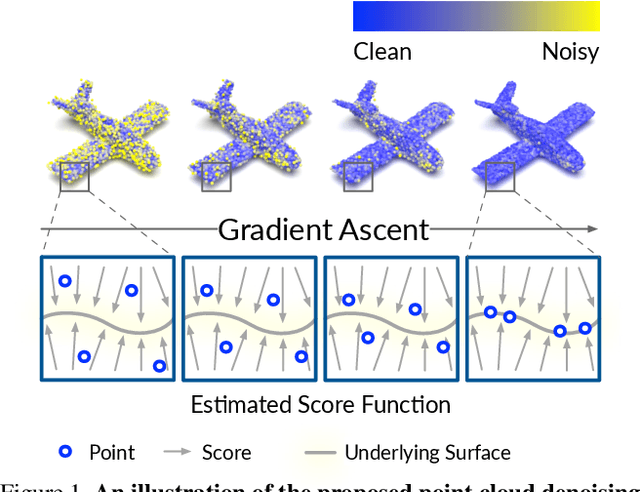
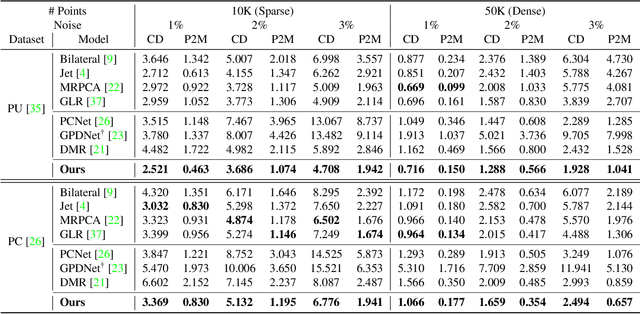
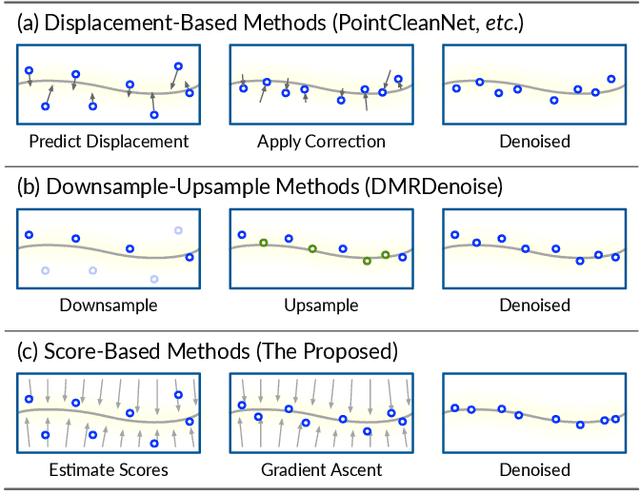
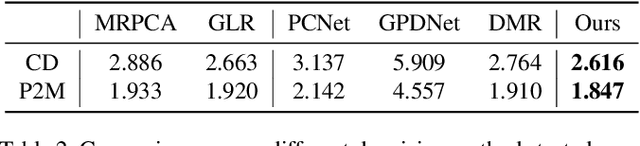
Point clouds acquired from scanning devices are often perturbed by noise, which affects downstream tasks such as surface reconstruction and analysis. The distribution of a noisy point cloud can be viewed as the distribution of a set of noise-free samples $p(x)$ convolved with some noise model $n$, leading to $(p * n)(x)$ whose mode is the underlying clean surface. To denoise a noisy point cloud, we propose to increase the log-likelihood of each point from $p * n$ via gradient ascent -- iteratively updating each point's position. Since $p * n$ is unknown at test-time, and we only need the score (i.e., the gradient of the log-probability function) to perform gradient ascent, we propose a neural network architecture to estimate the score of $p * n$ given only noisy point clouds as input. We derive objective functions for training the network and develop a denoising algorithm leveraging on the estimated scores. Experiments demonstrate that the proposed model outperforms state-of-the-art methods under a variety of noise models, and shows the potential to be applied in other tasks such as point cloud upsampling.
A Database for Research on Detection and Enhancement of Speech Transmitted over HF links
Jun 16, 2021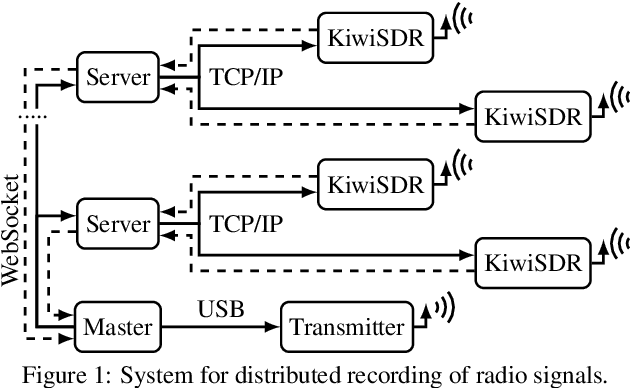
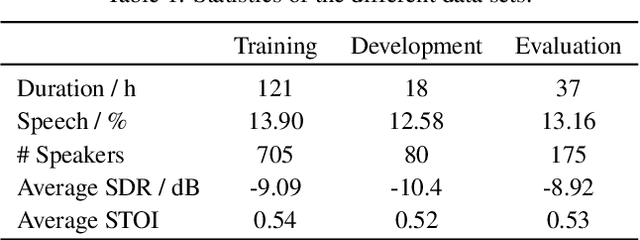

In this paper we present an open database for the development of detection and enhancement algorithms of speech transmitted over HF radio channels. It consists of audio samples recorded by various receivers at different locations across Europe, all monitoring the same single-sideband modulated transmission from a base station in Paderborn, Germany. Transmitted and received speech signals are precisely time aligned to offer parallel data for supervised training of deep learning based detection and enhancement algorithms. For the task of speech activity detection two exemplary baseline systems are presented, one based on statistical methods employing a multi-stage Wiener filter with minimum statistics noise floor estimation, and the other relying on a deep learning approach.
Lorenz System State Stability Identification using Neural Networks
Jun 16, 2021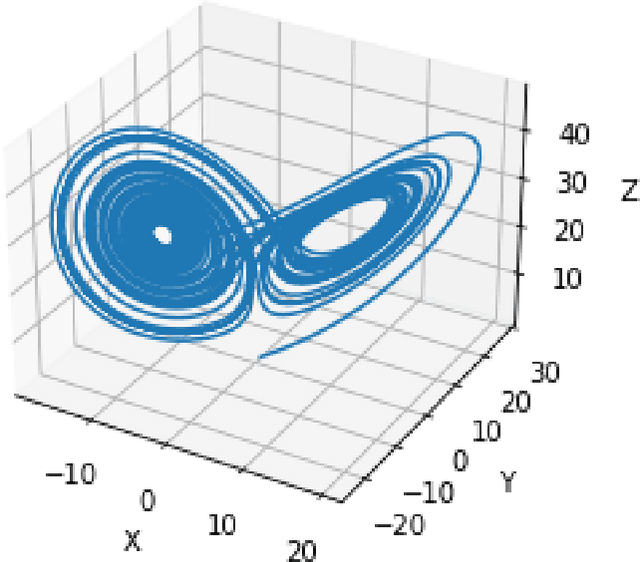
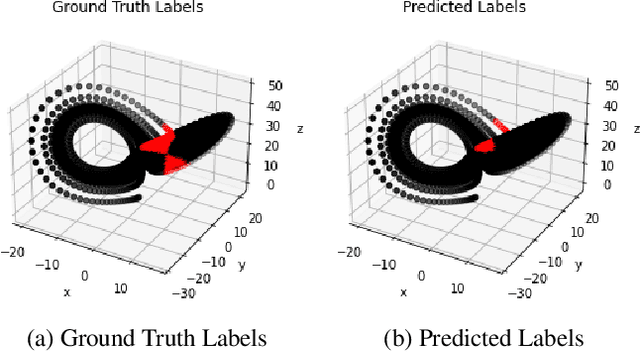
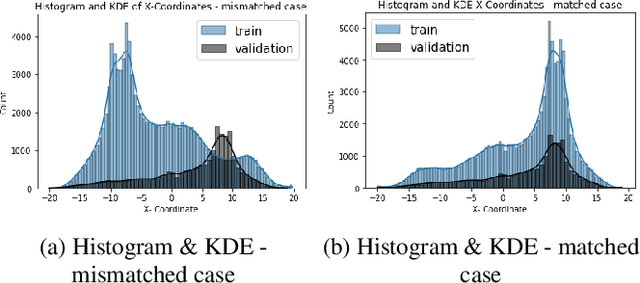
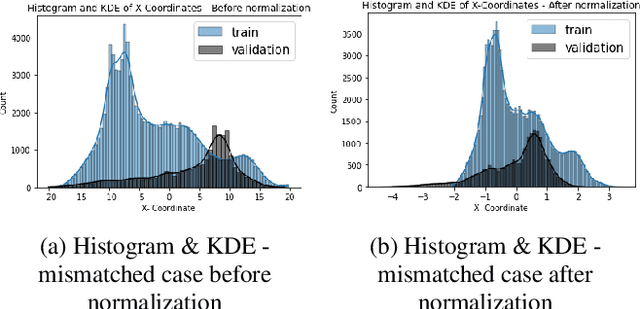
Nonlinear dynamical systems such as Lorenz63 equations are known to be chaotic in nature and sensitive to initial conditions. As a result, a small perturbation in the initial conditions results in deviation in state trajectory after a few time steps. The algorithms and computational resources needed to accurately identify the system states vary depending on whether the solution is in transition region or not. We refer to the transition and non-transition regions as unstable and stable regions respectively. We label a system state to be stable if it's immediate past and future states reside in the same regime. However, at a given time step we don't have the prior knowledge about whether system is in stable or unstable region. In this paper, we develop and train a feed forward (multi-layer perceptron) Neural Network to classify the system states of a Lorenz system as stable and unstable. We pose this task as a supervised learning problem where we train the neural network on Lorenz system which have states labeled as stable or unstable. We then test the ability of the neural network models to identify the stable and unstable states on a different Lorenz system that is generated using different initial conditions. We also evaluate the classification performance in the mismatched case i.e., when the initial conditions for training and validation data are sampled from different intervals. We show that certain normalization schemes can greatly improve the performance of neural networks in especially these mismatched scenarios. The classification framework developed in the paper can be a preprocessor for a larger context of sequential decision making framework where the decision making is performed based on observed stable or unstable states.
Reciprocal Multi-Robot Collision Avoidance with Asymmetric State Uncertainty
Jul 22, 2021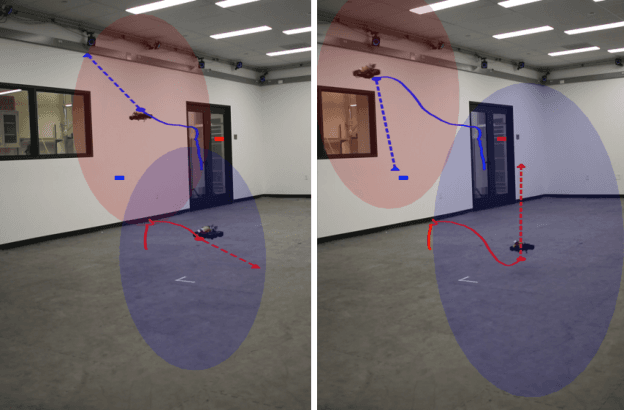
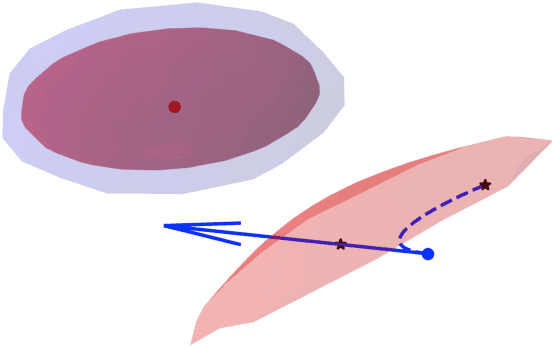
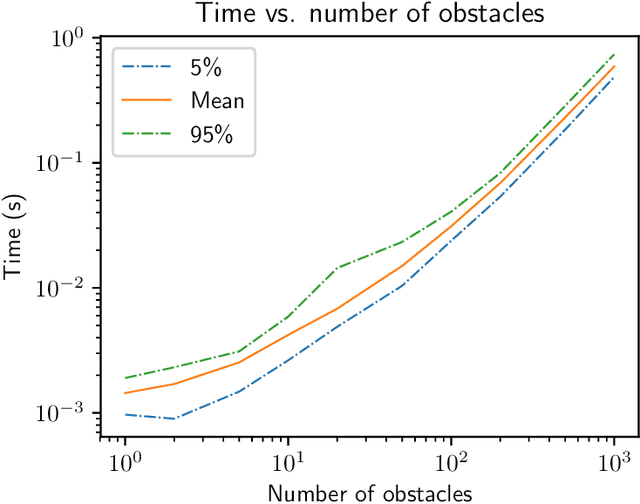
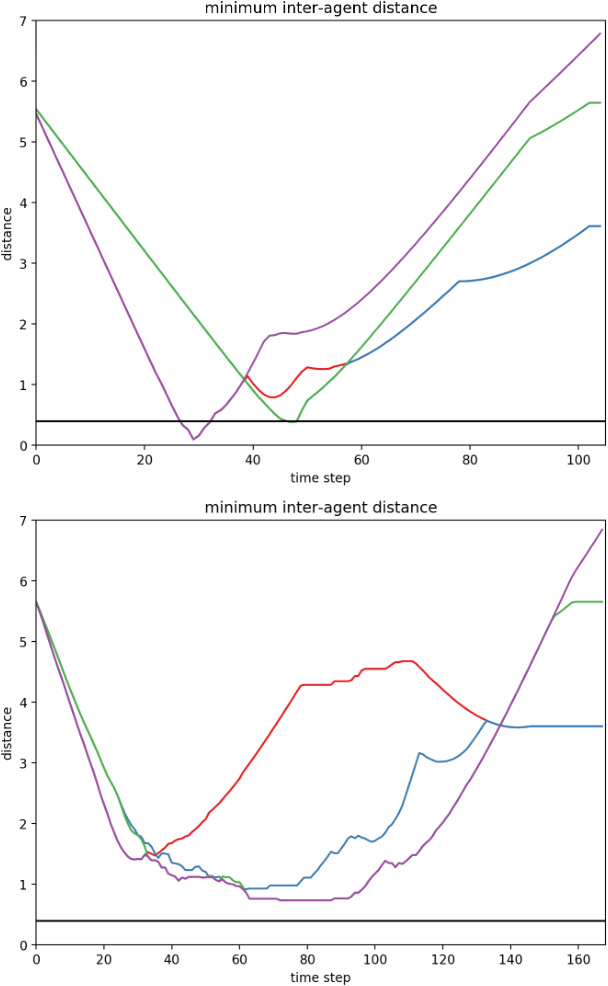
We present a general decentralized formulation for a large class of collision avoidance methods and show that all collision avoidance methods of this form are guaranteed to be collision free. This class includes several existing algorithms in the literature as special cases. We then present a particular instance of this collision avoidance method, CARP (Collision Avoidance by Reciprocal Projections), that is effective even when the estimates of other agents' positions and velocities are noisy. The method's main computational step involves the solution of a small convex optimization problem, which can be quickly solved in practice, even on embedded platforms, making it practical to use on computationally-constrained robots such as quadrotors. This method can be extended to find smooth polynomial trajectories for higher dynamic systems such at quadrotors. We demonstrate this algorithm's performance in simulations and on a team of physical quadrotors. Our method finds optimal projections in a median time of 17.12ms for 285 instances of 100 randomly generated obstacles, and produces safe polynomial trajectories at over 60hz on-board quadrotors. Our paper is accompanied by an open source Julia implementation and ROS package.
Scalable Quasi-Bayesian Inference for Instrumental Variable Regression
Jun 16, 2021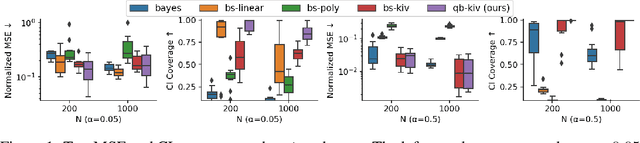

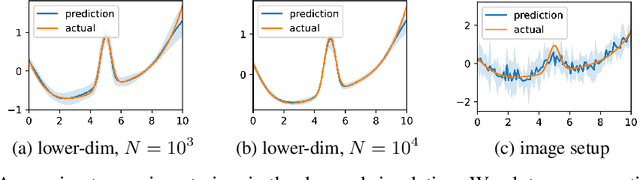

Recent years have witnessed an upsurge of interest in employing flexible machine learning models for instrumental variable (IV) regression, but the development of uncertainty quantification methodology is still lacking. In this work we present a scalable quasi-Bayesian procedure for IV regression, building upon the recently developed kernelized IV models. Contrary to Bayesian modeling for IV, our approach does not require additional assumptions on the data generating process, and leads to a scalable approximate inference algorithm with time cost comparable to the corresponding point estimation methods. Our algorithm can be further extended to work with neural network models. We analyze the theoretical properties of the proposed quasi-posterior, and demonstrate through empirical evaluation the competitive performance of our method.
Autonomous Drone Racing with Deep Reinforcement Learning
Mar 15, 2021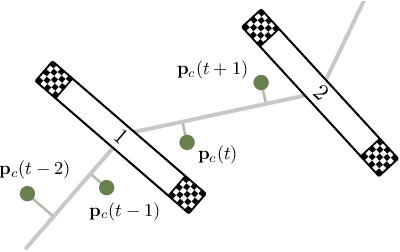
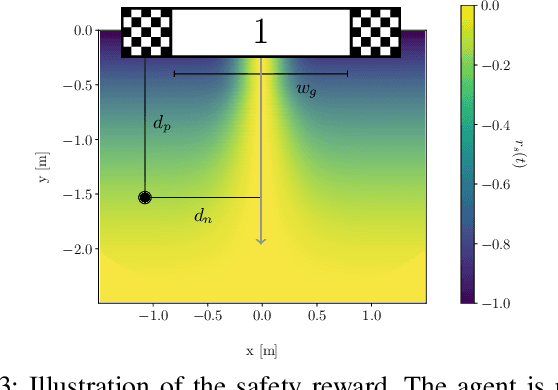
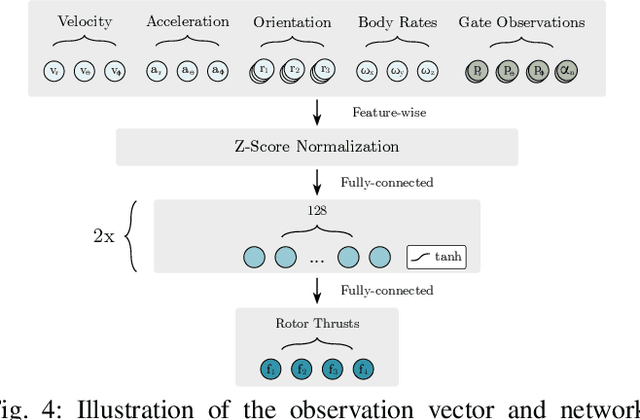
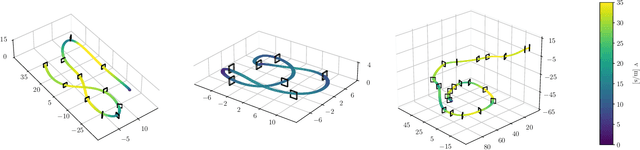
In many robotic tasks, such as drone racing, the goal is to travel through a set of waypoints as fast as possible. A key challenge for this task is planning the minimum-time trajectory, which is typically solved by assuming perfect knowledge of the waypoints to pass in advance. The resulting solutions are either highly specialized for a single-track layout, or suboptimal due to simplifying assumptions about the platform dynamics. In this work, a new approach to minimum-time trajectory generation for quadrotors is presented. Leveraging deep reinforcement learning and relative gate observations, this approach can adaptively compute near-time-optimal trajectories for random track layouts. Our method exhibits a significant computational advantage over approaches based on trajectory optimization for non-trivial track configurations. The proposed approach is evaluated on a set of race tracks in simulation and the real world, achieving speeds of up to 17 m/s with a physical quadrotor.
Deep convolutional neural networks for multi-scale time-series classification and application to disruption prediction in fusion devices
Nov 21, 2019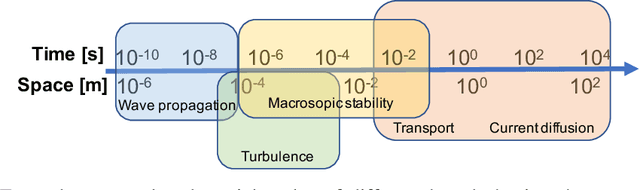
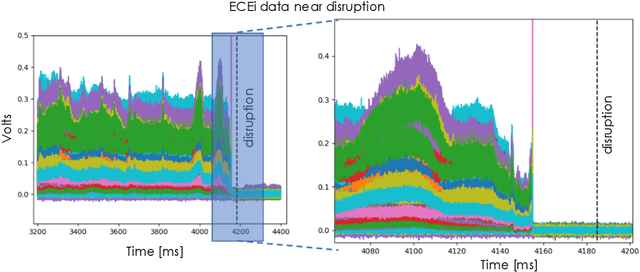
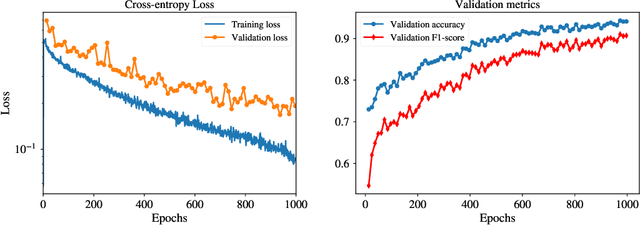
The multi-scale, mutli-physics nature of fusion plasmas makes predicting plasma events challenging. Recent advances in deep convolutional neural network architectures (CNN) utilizing dilated convolutions enable accurate predictions on sequences which have long-range, multi-scale characteristics, such as the time-series generated by diagnostic instruments observing fusion plasmas. Here we apply this neural network architecture to the popular problem of disruption prediction in fusion tokamaks, utilizing raw data from a single diagnostic, the Electron Cyclotron Emission imaging (ECEi) diagnostic from the DIII-D tokamak. ECEi measures a fundamental plasma quantity (electron temperature) with high temporal resolution over the entire plasma discharge, making it sensitive to a number of potential pre-disruptions markers with different temporal and spatial scales. Promising, initial disruption prediction results are obtained training a deep CNN with large receptive field (~30k), achieving an $F_1$-score of ~91% on individual time-slices using only the ECEi data.
A 51.3 TOPS/W, 134.4 GOPS In-memory Binary Image Filtering in 65nm CMOS
Jul 29, 2021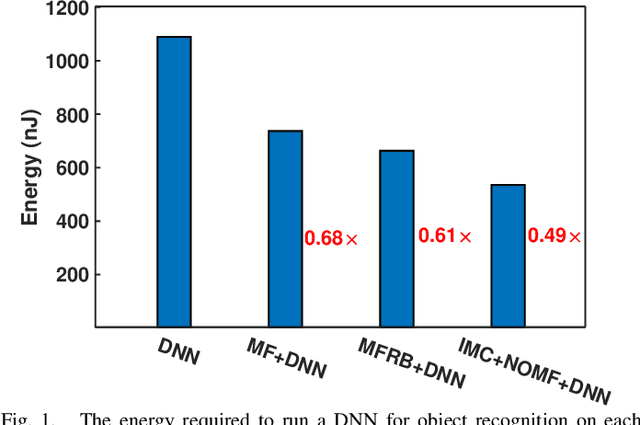
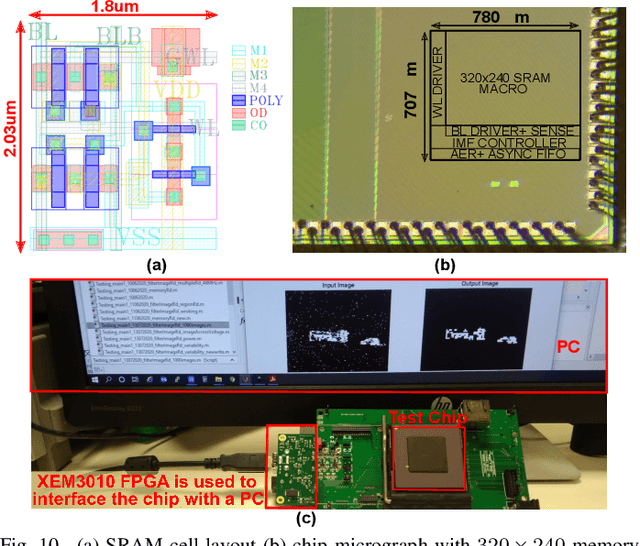
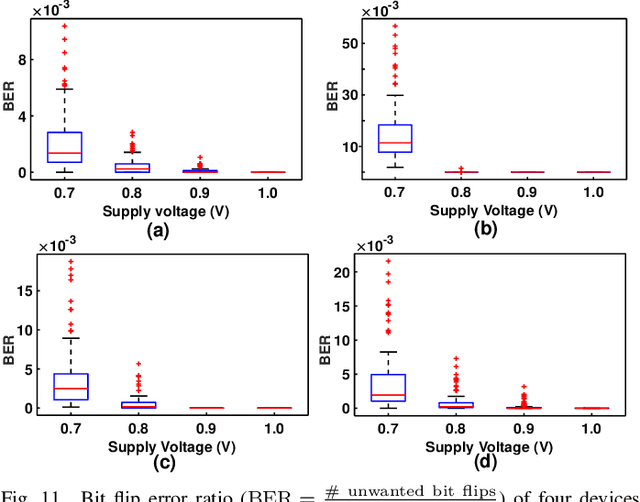
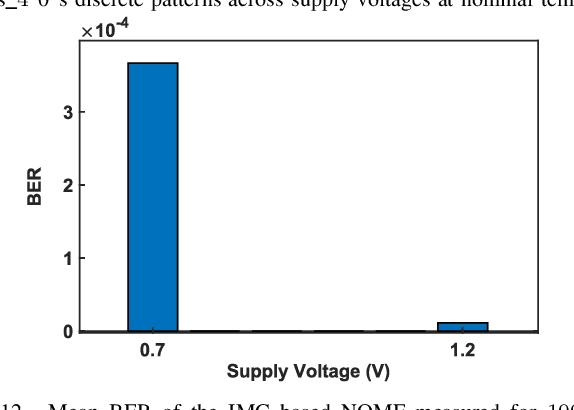
Neuromorphic vision sensors (NVS) can enable energy savings due to their event-driven that exploits the temporal redundancy in video streams from a stationary camera. However, noise-driven events lead to the false triggering of the object recognition processor. Image denoise operations require memoryintensive processing leading to a bottleneck in energy and latency. In this paper, we present in-memory filtering (IMF), a 6TSRAM in-memory computing based image denoising for eventbased binary image (EBBI) frame from an NVS. We propose a non-overlap median filter (NOMF) for image denoising. An inmemory computing framework enables hardware implementation of NOMF leveraging the inherent read disturb phenomenon of 6T-SRAM. To demonstrate the energy-saving and effectiveness of the algorithm, we fabricated the proposed architecture in a 65nm CMOS process. As compared to fully digital implementation, IMF enables > 70x energy savings and a > 3x improvement of processing time when tested with the video recordings from a DAVIS sensor and achieves a peak throughput of 134.4 GOPS. Furthermore, the peak energy efficiencies of the NOMF is 51.3 TOPS/W, comparable with state of the art inmemory processors. We also show that the accuracy of the images obtained by NOMF provide comparable accuracy in tracking and classification applications when compared with images obtained by conventional median filtering.
Human Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause
May 30, 2021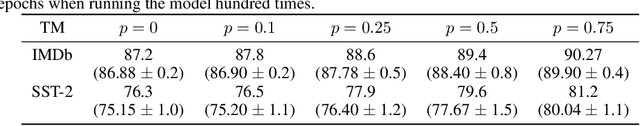


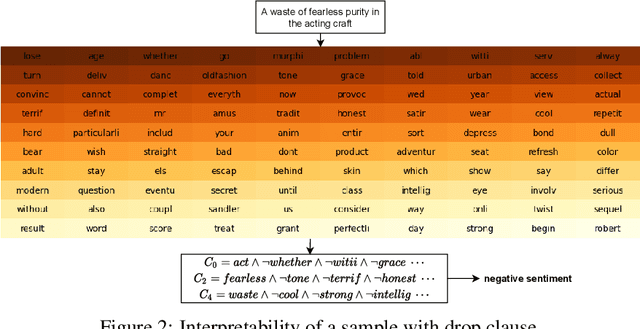
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. Along with producing more distinct and well-structured patterns that improve the performance, we also show that dropping clauses increases learning robustness. To explore the effects clause dropping has on accuracy, training time, and interpretability, we conduct extensive experiments on various benchmark datasets in natural language processing (NLP) (IMDb and SST2) as well as computer vision (MNIST and CIFAR10). In brief, we observe from +2% to +4% increase in accuracy and 2x to 4x faster learning. We further employ the Convolutional TM to document interpretable results on the CIFAR10 dataset. To the best of our knowledge, this is the first time an interpretable machine learning algorithm has been used to produce pixel-level human-interpretable results on CIFAR10. Also, unlike previous interpretable methods that focus on attention visualisation or gradient interpretability, we show that the TM is a more general interpretable method. That is, by producing rule-based propositional logic expressions that are \emph{human}-interpretable, the TM can explain how it classifies a particular instance at the pixel level for computer vision and at the word level for NLP.
Set-Valued Rigid Body Dynamics for Simultaneous Frictional Impact
Mar 29, 2021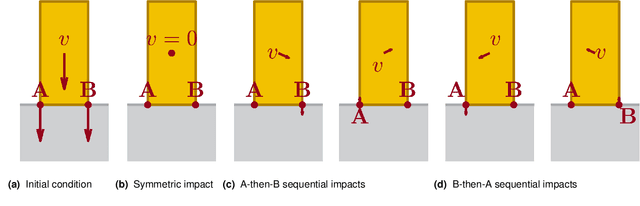

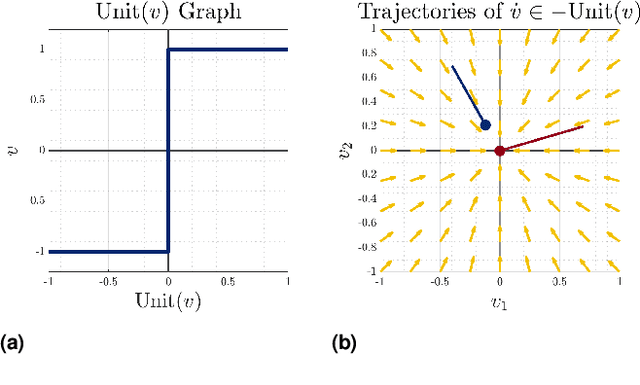

Robotic manipulation and locomotion often entail nearly-simultaneous collisions -- such as heel and toe strikes during a foot step -- with outcomes that are extremely sensitive to the order in which impacts occur. Robotic simulators commonly lack the accuracy to predict this ordering, and instead pick one with a heuristic. This discrepancy degrades performance when model-based controllers and policies learned in simulation are placed on a real robot. We reconcile this issue with a set-valued rigid-body model which generates a broad set of physically reasonable outcomes of simultaneous frictional impacts. We first extend Routh's impact model to multiple impacts by reformulating it as a differential inclusion (DI), and show that any solution will resolve all impacts in finite time. By considering time as a state, we embed this model into another DI which captures the continuous-time evolution of rigid body dynamics, and guarantee existence of solutions. We finally cast simulation of simultaneous impacts as a linear complementarity problem (LCP), and develop a probabilistically-complete algorithm for approximating the post-impact velocity set. We demonstrate our approach on several examples drawn from manipulation and legged locomotion.