 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Generic Multimodal Architecture for Batch and Streaming Big Data Integration
Aug 09, 2021
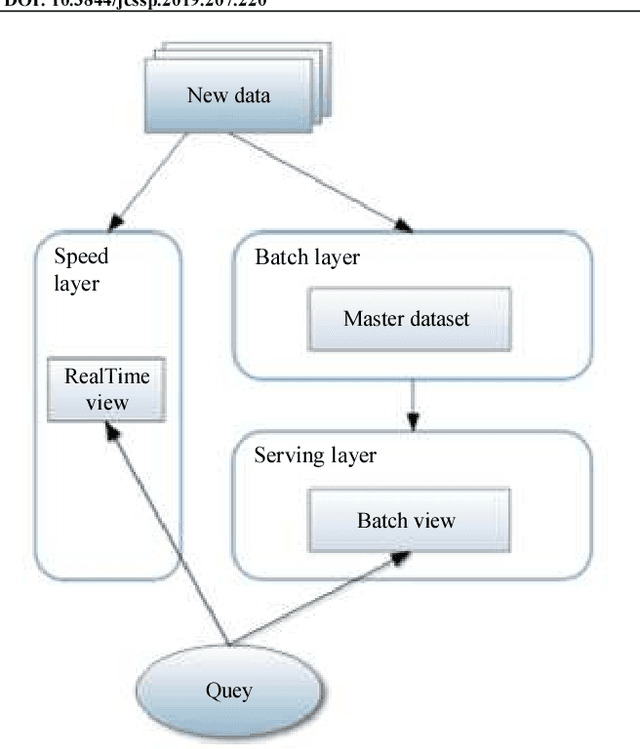
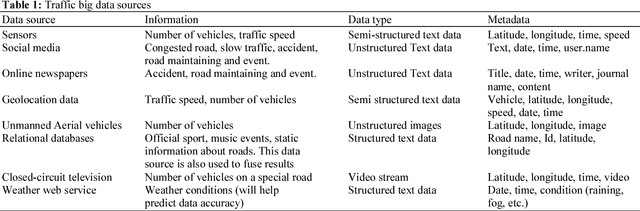
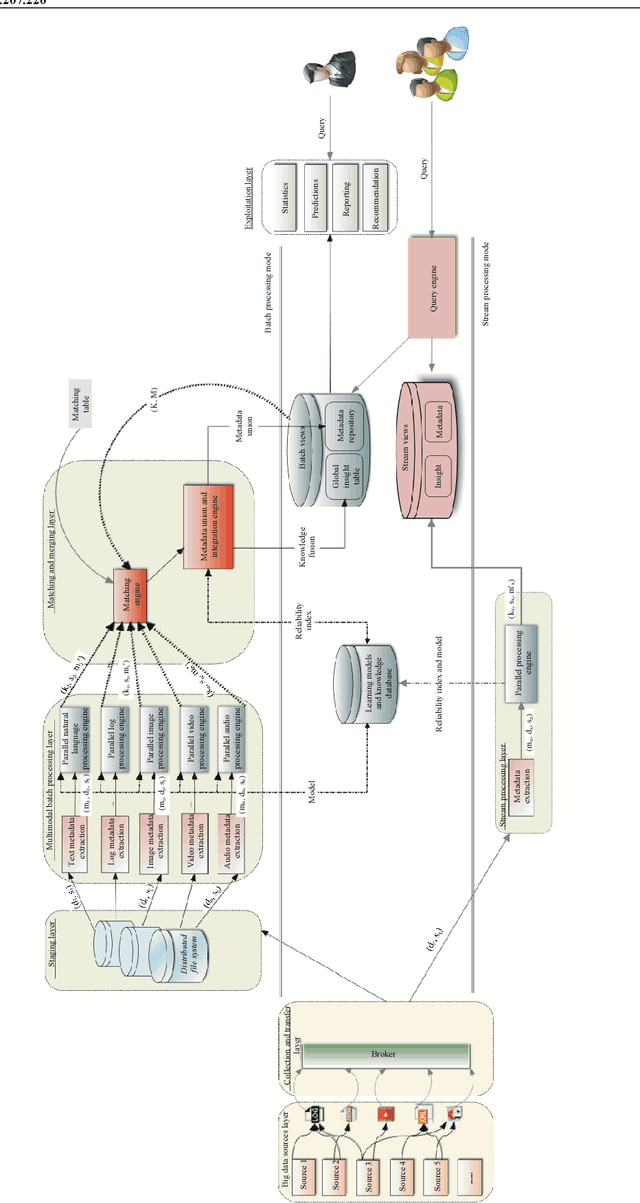
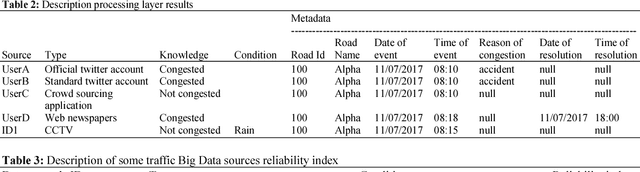
Big Data are rapidly produced from various heterogeneous data sources. They are of different types (text, image, video or audio) and have different levels of reliability and completeness. One of the most interesting architectures that deal with the large amount of emerging data at high velocity is called the lambda architecture. In fact, it combines two different processing layers namely batch and speed layers, each providing specific views of data while ensuring robustness, fast and scalable data processing. However, most papers dealing with the lambda architecture are focusing one single type of data generally produced by a single data source. Besides, the layers of the architecture are implemented independently, or, at best, are combined to perform basic processing without assessing either the data reliability or completeness. Therefore, inspired by the lambda architecture, we propose in this paper a generic multimodal architecture that combines both batch and streaming processing in order to build a complete, global and accurate insight in near-real-time based on the knowledge extracted from multiple heterogeneous Big Data sources. Our architecture uses batch processing to analyze the data structures and contents, build the learning models and calculate the reliability index of the involved sources, while the streaming processing uses the built-in models of the batch layer to immediately process incoming data and rapidly provide results. We validate our architecture in the context of urban traffic management systems in order to detect congestions.
COVID-19 Vaccine and Social Media: Exploring Emotions and Discussions on Twitter
Jul 29, 2021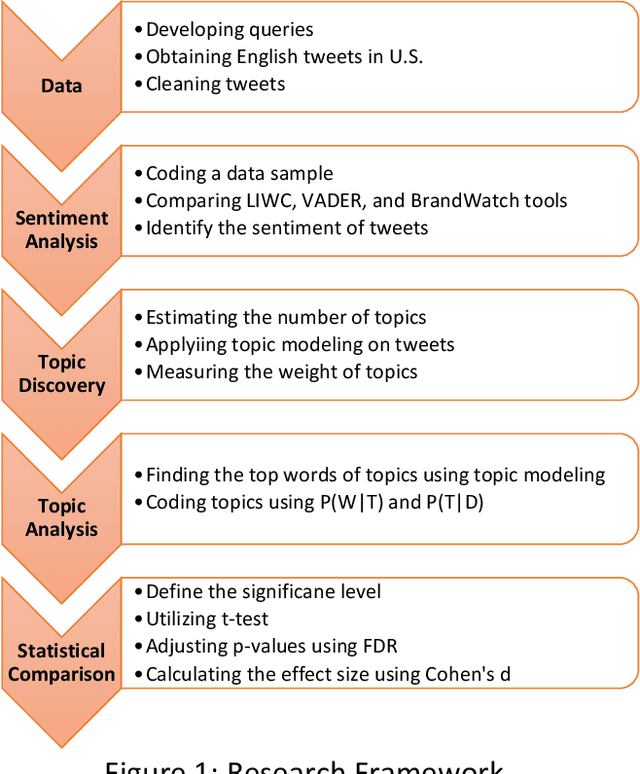
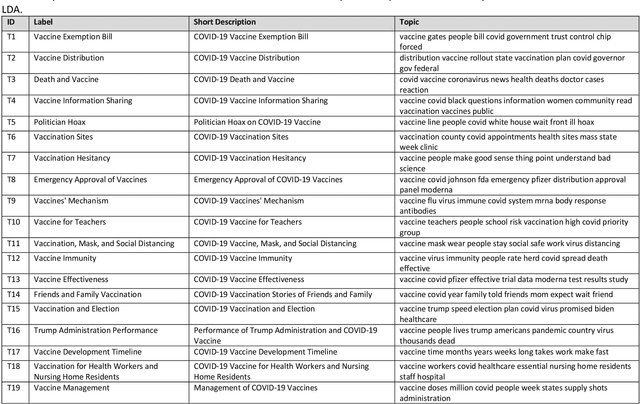
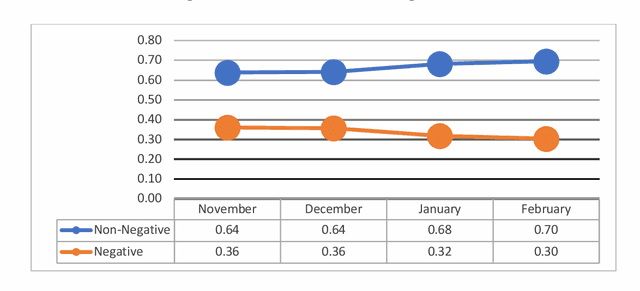
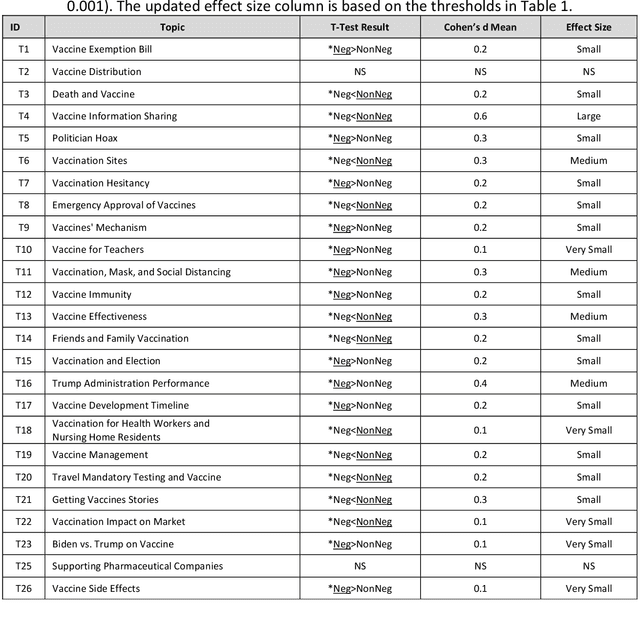
Public response to COVID-19 vaccines is the key success factor to control the COVID-19 pandemic. To understand the public response, there is a need to explore public opinion. Traditional surveys are expensive and time-consuming, address limited health topics, and obtain small-scale data. Twitter can provide a great opportunity to understand public opinion regarding COVID-19 vaccines. The current study proposes an approach using computational and human coding methods to collect and analyze a large number of tweets to provide a wider perspective on the COVID-19 vaccine. This study identifies the sentiment of tweets and their temporal trend, discovers major topics, compares topics of negative and non-negative tweets, and discloses top topics of negative and non-negative tweets. Our findings show that the negative sentiment regarding the COVID-19 vaccine had a decreasing trend between November 2020 and February 2021. We found Twitter users have discussed a wide range of topics from vaccination sites to the 2020 U.S. election between November 2020 and February 2021. The findings show that there was a significant difference between negative and non-negative tweets regarding the weight of most topics. Our results also indicate that the negative and non-negative tweets had different topic priorities and focuses.
Shape Analysis of Functional Data with Elastic Partial Matching
May 18, 2021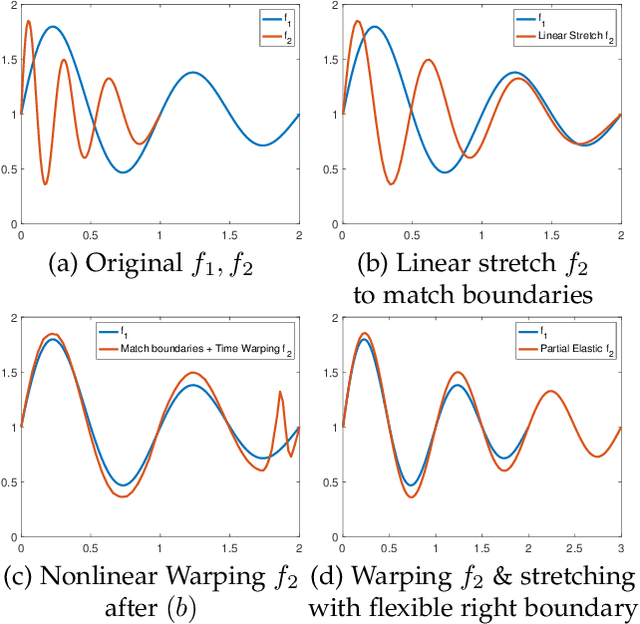
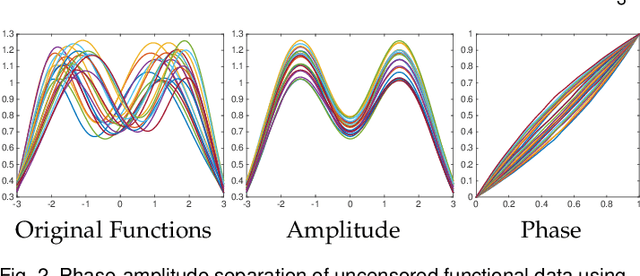
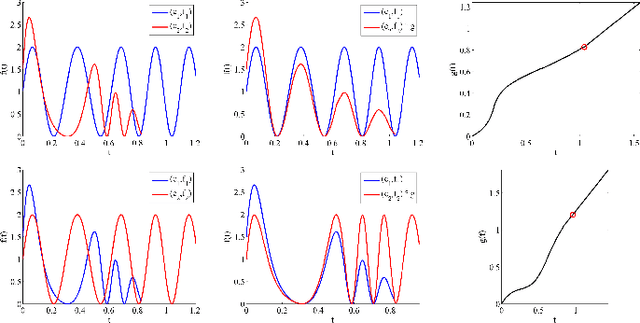
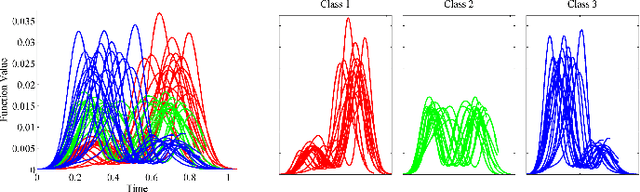
Elastic Riemannian metrics have been used successfully in the past for statistical treatments of functional and curve shape data. However, this usage has suffered from an important restriction: the function boundaries are assumed fixed and matched. Functional data exhibiting unmatched boundaries typically arise from dynamical systems with variable evolution rates such as COVID-19 infection rate curves associated with different geographical regions. In this case, it is more natural to model such data with sliding boundaries and use partial matching, i.e., only a part of a function is matched to another function. Here, we develop a comprehensive Riemannian framework that allows for partial matching, comparing, and clustering of functions under both phase variability and uncertain boundaries. We extend past work by: (1) Forming a joint action of the time-warping and time-scaling groups; (2) Introducing a metric that is invariant to this joint action, allowing for a gradient-based approach to elastic partial matching; and (3) Presenting a modification that, while losing the metric property, allows one to control relative influence of the two groups. This framework is illustrated for registering and clustering shapes of COVID-19 rate curves, identifying essential patterns, minimizing mismatch errors, and reducing variability within clusters compared to previous methods.
A Gaussian Process Model of Cross-Category Dynamics in Brand Choice
Apr 23, 2021Understanding individual customers' sensitivities to prices, promotions, brand, and other aspects of the marketing mix is fundamental to a wide swath of marketing problems, including targeting and pricing. Companies that operate across many product categories have a unique opportunity, insofar as they can use purchasing data from one category to augment their insights in another. Such cross-category insights are especially crucial in situations where purchasing data may be rich in one category, and scarce in another. An important aspect of how consumers behave across categories is dynamics: preferences are not stable over time, and changes in individual-level preference parameters in one category may be indicative of changes in other categories, especially if those changes are driven by external factors. Yet, despite the rich history of modeling cross-category preferences, the marketing literature lacks a framework that flexibly accounts for \textit{correlated dynamics}, or the cross-category interlinkages of individual-level sensitivity dynamics. In this work, we propose such a framework, leveraging individual-level, latent, multi-output Gaussian processes to build a nonparametric Bayesian choice model that allows information sharing of preference parameters across customers, time, and categories. We apply our model to grocery purchase data, and show that our model detects interesting dynamics of customers' price sensitivities across multiple categories. Managerially, we show that capturing correlated dynamics yields substantial predictive gains, relative to benchmarks. Moreover, we find that capturing correlated dynamics can have implications for understanding changes in consumers preferences over time, and developing targeted marketing strategies based on those dynamics.
DABT: A Dependency-aware Bug Triaging Method
Apr 26, 2021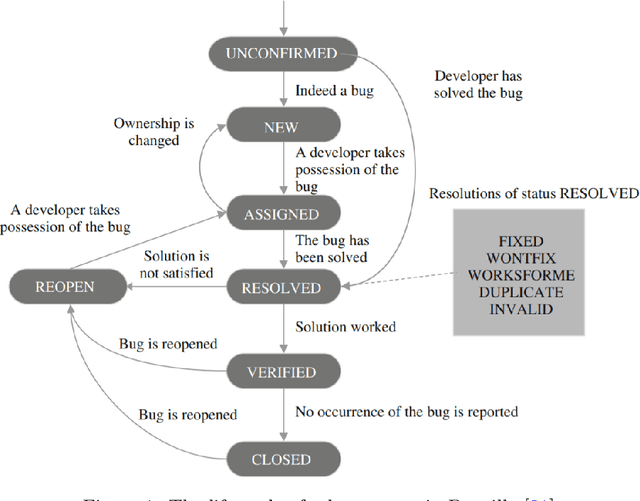
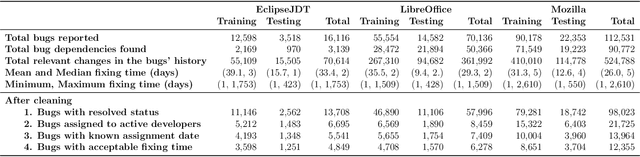
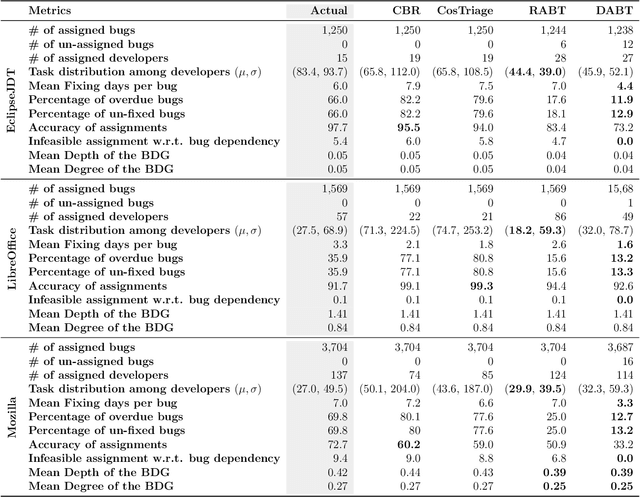
In software engineering practice, fixing a bug promptly reduces the associated costs. On the other hand, the manual bug fixing process can be time-consuming, cumbersome, and error-prone. In this work, we introduce a bug triaging method, called Dependency-aware Bug Triaging (DABT), which leverages natural language processing and integer programming to assign bugs to appropriate developers. Unlike previous works that mainly focus on one aspect of the bug reports, DABT considers the textual information, cost associated with each bug, and dependency among them. Therefore, this comprehensive formulation covers the most important aspect of the previous works while considering the blocking effect of the bugs. We report the performance of the algorithm on three open-source software systems, i.e., EclipseJDT, LibreOffice, and Mozilla. Our result shows that DABT is able to reduce the number of overdue bugs up to 12\%. It also decreases the average fixing time of the bugs by half. Moreover, it reduces the complexity of the bug dependency graph by prioritizing blocking bugs.
ConvDySAT: Deep Neural Representation Learning on Dynamic Graphs via Self-Attention and Convolutional Neural Networks
Jun 21, 2021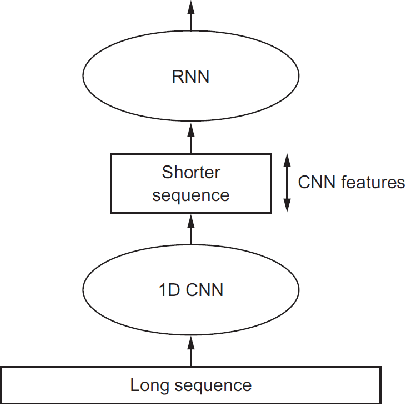
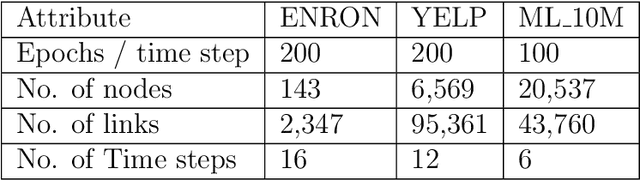
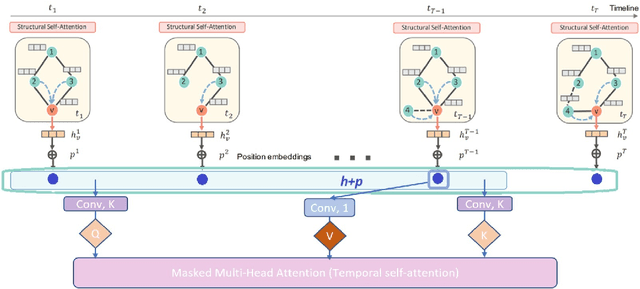
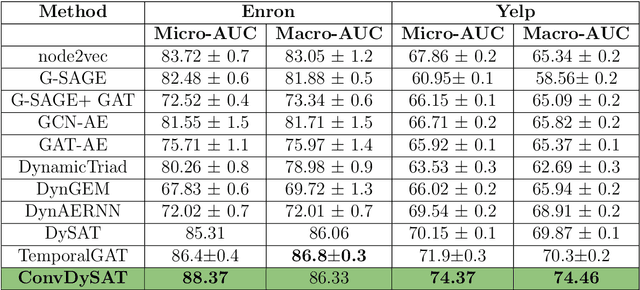
Learning node representations on temporal graphs is a fundamental step to learn real-word dynamic graphs efficiently. Real-world graphs have the nature of continuously evolving over time, such as changing edges weights, removing and adding nodes and appearing and disappearing of edges, while previous graph representation learning methods focused generally on static graphs. We present ConvDySAT as an enhancement of DySAT, one of the state-of-the-art dynamic methods, by augmenting convolution neural networks with the self-attention mechanism, the employed method in DySAT to express the structural and temporal evolution. We conducted single-step link prediction on a communication network and rating network, Experimental results show significant performance gains for ConvDySAT over various state-of-the-art methods.
HURRA! Human readable router anomaly detection
Jul 23, 2021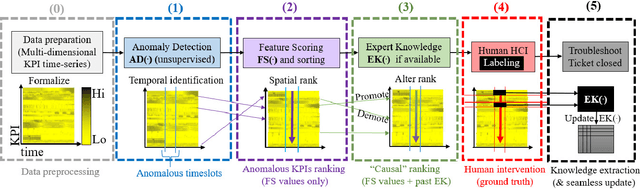
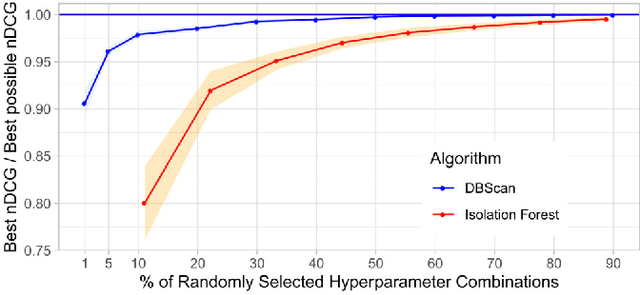
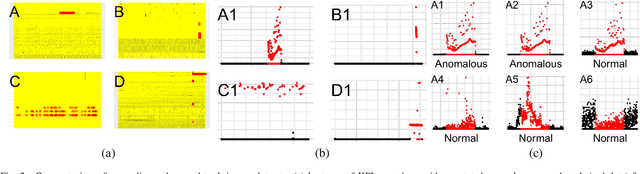
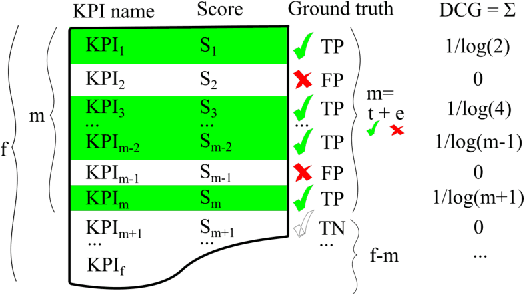
This paper presents HURRA, a system that aims to reduce the time spent by human operators in the process of network troubleshooting. To do so, it comprises two modules that are plugged after any anomaly detection algorithm: (i) a first attention mechanism, that ranks the present features in terms of their relation with the anomaly and (ii) a second module able to incorporates previous expert knowledge seamlessly, without any need of human interaction nor decisions. We show the efficacy of these simple processes on a collection of real router datasets obtained from tens of ISPs which exhibit a rich variety of anomalies and very heterogeneous set of KPIs, on which we gather manually annotated ground truth by the operator solving the troubleshooting ticket. Our experimental evaluation shows that (i) the proposed system is effective in achieving high levels of agreement with the expert, that (ii) even a simple statistical approach is able to extracting useful information from expert knowledge gained in past cases to further improve performance and finally that (iii) the main difficulty in live deployment concerns the automated selection of the anomaly detection algorithm and the tuning of its hyper-parameters.
Lexical Semantic Change Discovery
Jun 06, 2021
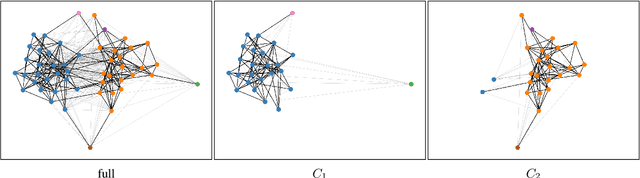

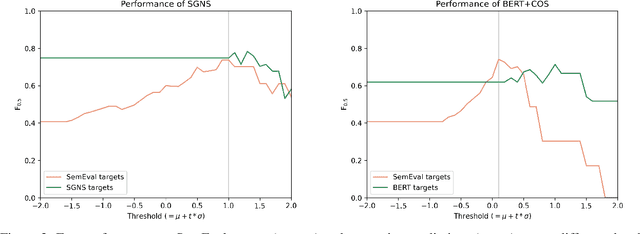
While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
Probabilistic Collision Constraint for Motion Planning in Dynamic Environments
Apr 04, 2021
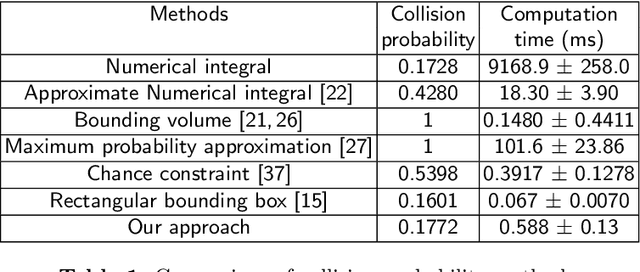
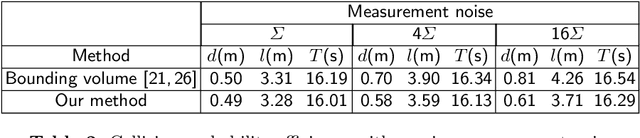
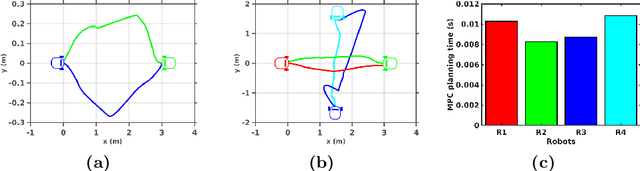
Online generation of collision free trajectories is of prime importance for autonomous navigation. Dynamic environments, robot motion and sensing uncertainties adds further challenges to collision avoidance systems. This paper presents an approach for collision avoidance in dynamic environments, incorporating robot and obstacle state uncertainties. We derive a tight upper bound for collision probability between robot and obstacle and formulate it as a motion planning constraint which is solvable in real time. The proposed approach is tested in simulation considering mobile robots as well as quadrotors to demonstrate that successful collision avoidance is achieved in real time application. We also provide a comparison of our approach with several state-of-the-art methods.
Developing a Deep Neural Network to Denoise Time-Resolved In Situ ETEM Movies of Catalyst Nanoparticles
Jan 19, 2021
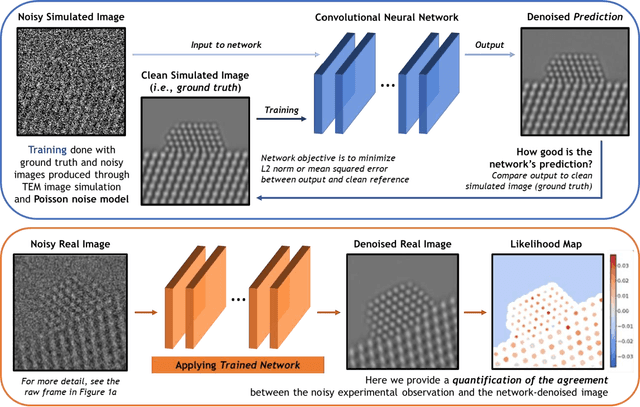
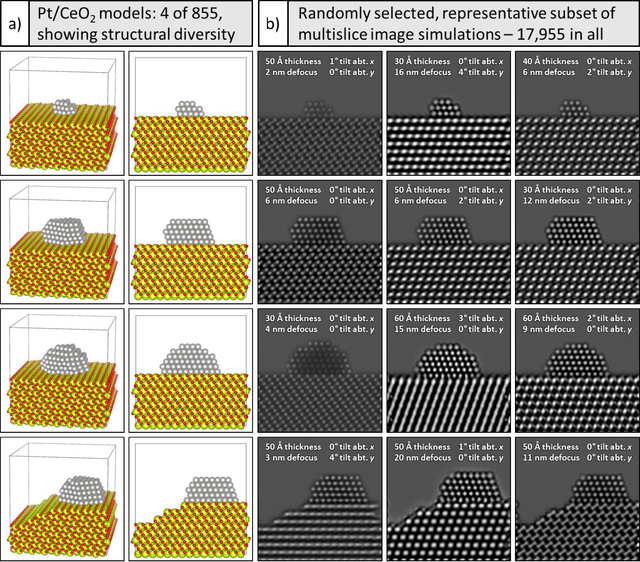

A deep learning-based convolutional neural network has been developed to denoise atomic-resolution in situ TEM image datasets of catalyst nanoparticles acquired on high speed, direct electron counting detectors, where the signal is severely limited by shot noise. The network was applied to a model catalyst of CeO2-supported Pt nanoparticles. We leverage multislice simulation to generate a large and flexible dataset for training and testing the network. The proposed network outperforms state-of-the-art denoising methods by a significant margin both on simulated and experimental test data. Factors contributing to the performance are identified, including most importantly (a) the geometry of the images used during training and (b) the size of the network's receptive field. Through a gradient-based analysis, we investigate the mechanisms used by the network to denoise experimental images. This shows the network exploits information on the surrounding structure and that it adapts its filtering approach when it encounters atomic-level defects at the catalyst surface. Extensive analysis has been done to characterize the network's ability to correctly predict the exact atomic structure at the catalyst surface. Finally, we develop an approach based on the log-likelihood ratio test that provides an quantitative measure of uncertainty regarding the atomic-level structure in the network-denoised image.