 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Optimal Stopping with Application in Financial Engineering
May 19, 2021
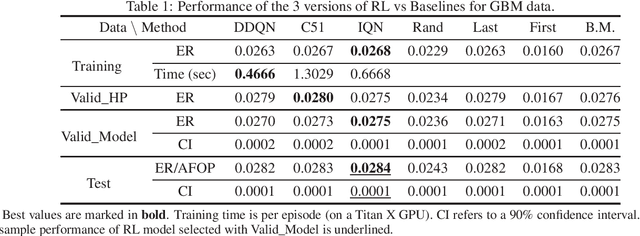
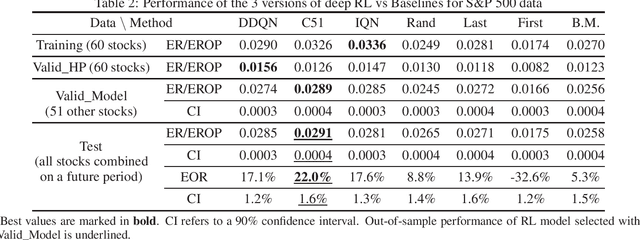

Optimal stopping is the problem of deciding the right time at which to take a particular action in a stochastic system, in order to maximize an expected reward. It has many applications in areas such as finance, healthcare, and statistics. In this paper, we employ deep Reinforcement Learning (RL) to learn optimal stopping policies in two financial engineering applications: namely option pricing, and optimal option exercise. We present for the first time a comprehensive empirical evaluation of the quality of optimal stopping policies identified by three state of the art deep RL algorithms: double deep Q-learning (DDQN), categorical distributional RL (C51), and Implicit Quantile Networks (IQN). In the case of option pricing, our findings indicate that in a theoretical Black-Schole environment, IQN successfully identifies nearly optimal prices. On the other hand, it is slightly outperformed by C51 when confronted to real stock data movements in a put option exercise problem that involves assets from the S&P500 index. More importantly, the C51 algorithm is able to identify an optimal stopping policy that achieves 8% more out-of-sample returns than the best of four natural benchmark policies. We conclude with a discussion of our findings which should pave the way for relevant future research.
Automatic Detection of COVID-19 Vaccine Misinformation with Graph Link Prediction
Aug 04, 2021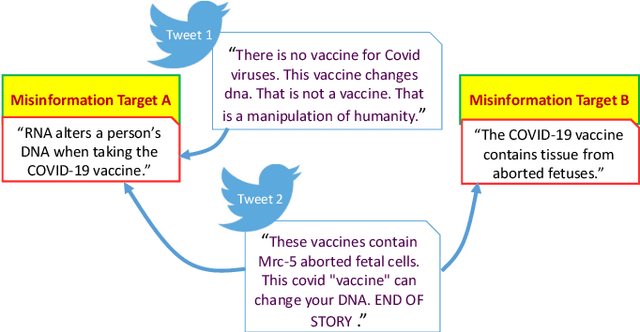
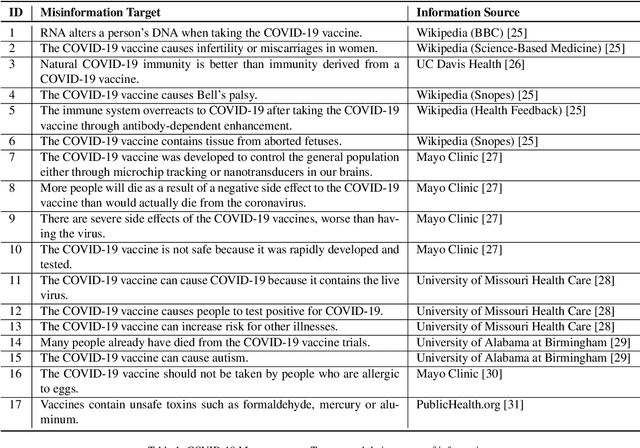
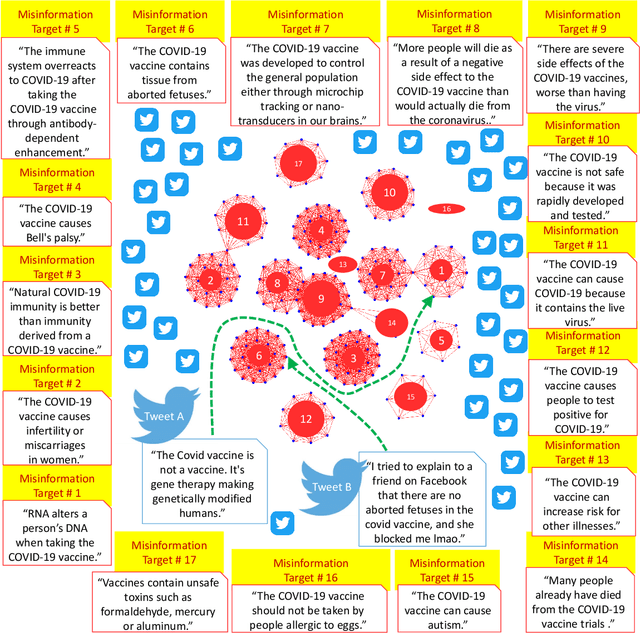
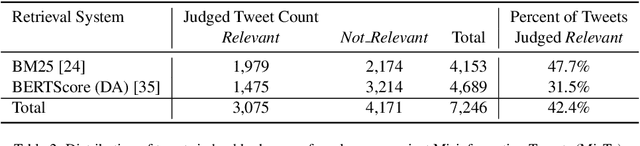
Enormous hope in the efficacy of vaccines became recently a successful reality in the fight against the COVID-19 pandemic. However, vaccine hesitancy, fueled by exposure to social media misinformation about COVID-19 vaccines became a major hurdle. Therefore, it is essential to automatically detect where misinformation about COVID-19 vaccines on social media is spread and what kind of misinformation is discussed, such that inoculation interventions can be delivered at the right time and in the right place, in addition to interventions designed to address vaccine hesitancy. This paper is addressing the first step in tackling hesitancy against COVID-19 vaccines, namely the automatic detection of misinformation about the vaccines on Twitter, the social media platform that has the highest volume of conversations about COVID-19 and its vaccines. We present CoVaxLies, a new dataset of tweets judged relevant to several misinformation targets about COVID-19 vaccines on which a novel method of detecting misinformation was developed. Our method organizes CoVaxLies in a Misinformation Knowledge Graph as it casts misinformation detection as a graph link prediction problem. The misinformation detection method detailed in this paper takes advantage of the link scoring functions provided by several knowledge embedding methods. The experimental results demonstrate the superiority of this method when compared with classification-based methods, widely used currently.
Score-Based Change Detection for Gradient-Based Learning Machines
Jun 27, 2021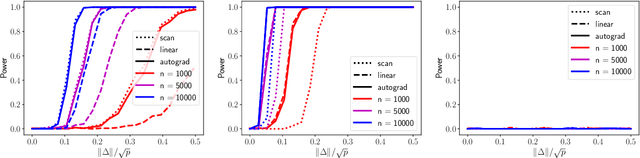

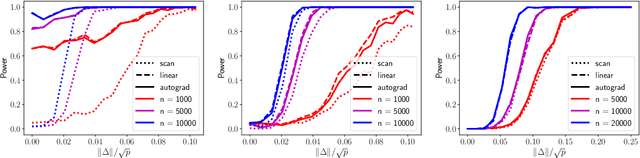

The widespread use of machine learning algorithms calls for automatic change detection algorithms to monitor their behavior over time. As a machine learning algorithm learns from a continuous, possibly evolving, stream of data, it is desirable and often critical to supplement it with a companion change detection algorithm to facilitate its monitoring and control. We present a generic score-based change detection method that can detect a change in any number of components of a machine learning model trained via empirical risk minimization. This proposed statistical hypothesis test can be readily implemented for such models designed within a differentiable programming framework. We establish the consistency of the hypothesis test and show how to calibrate it to achieve a prescribed false alarm rate. We illustrate the versatility of the approach on synthetic and real data.
Anomaly Detection and Automated Labeling for Voter Registration File Changes
Jun 16, 2021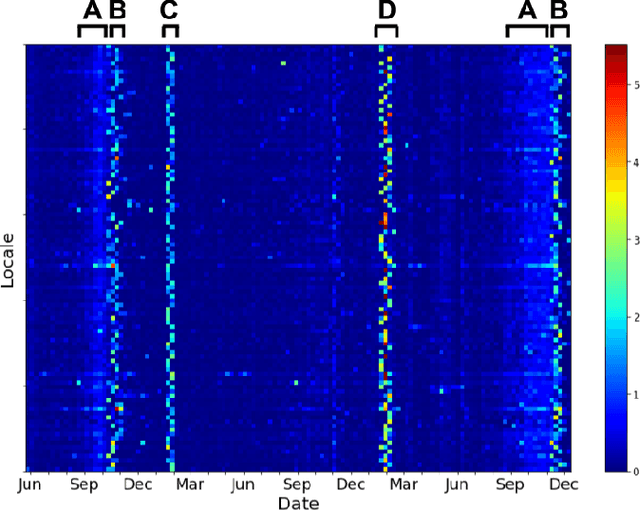
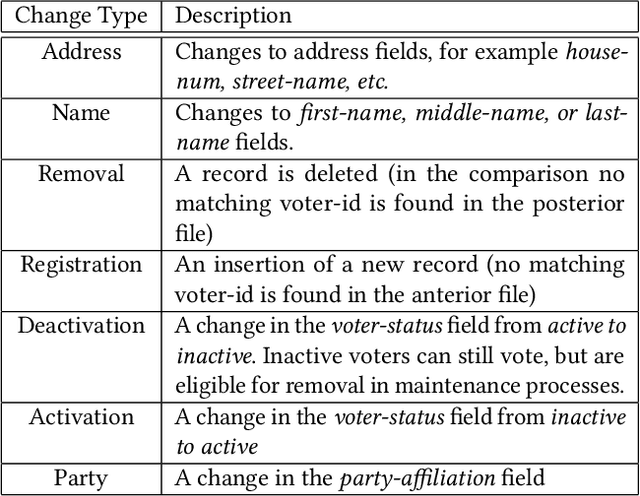
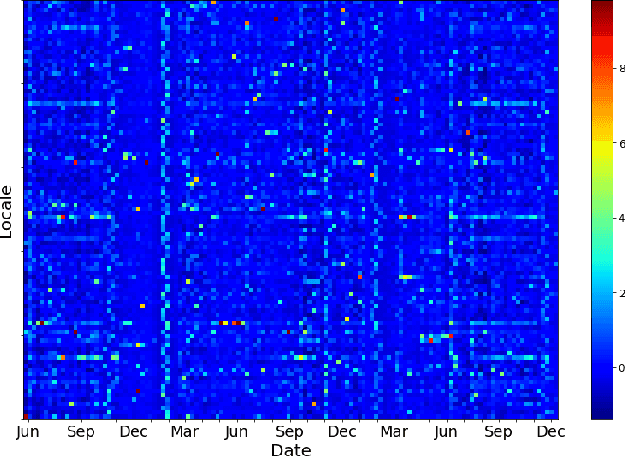
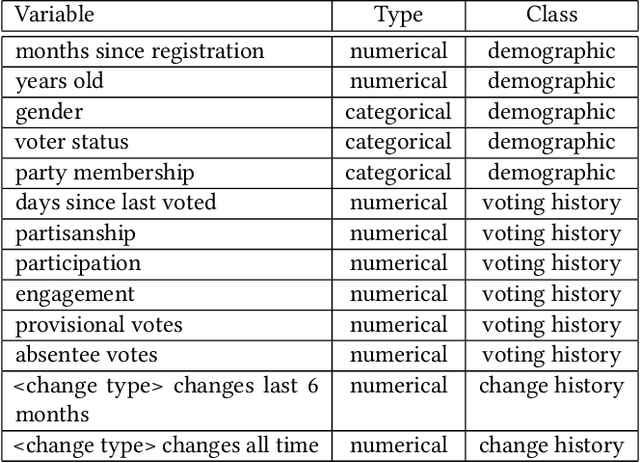
Voter eligibility in United States elections is determined by a patchwork of state databases containing information about which citizens are eligible to vote. Administrators at the state and local level are faced with the exceedingly difficult task of ensuring that each of their jurisdictions is properly managed, while also monitoring for improper modifications to the database. Monitoring changes to Voter Registration Files (VRFs) is crucial, given that a malicious actor wishing to disrupt the democratic process in the US would be well-advised to manipulate the contents of these files in order to achieve their goals. In 2020, we saw election officials perform admirably when faced with administering one of the most contentious elections in US history, but much work remains to secure and monitor the election systems Americans rely on. Using data created by comparing snapshots taken of VRFs over time, we present a set of methods that make use of machine learning to ease the burden on analysts and administrators in protecting voter rolls. We first evaluate the effectiveness of multiple unsupervised anomaly detection methods in detecting VRF modifications by modeling anomalous changes as sparse additive noise. In this setting we determine that statistical models comparing administrative districts within a short time span and non-negative matrix factorization are most effective for surfacing anomalous events for review. These methods were deployed during 2019-2020 in our organization's monitoring system and were used in collaboration with the office of the Iowa Secretary of State. Additionally, we propose a newly deployed model which uses historical and demographic metadata to label the likely root cause of database modifications. We hope to use this model to predict which modifications have known causes and therefore better identify potentially anomalous modifications.
Life is Random, Time is Not: Markov Decision Processes with Window Objectives
Jan 11, 2019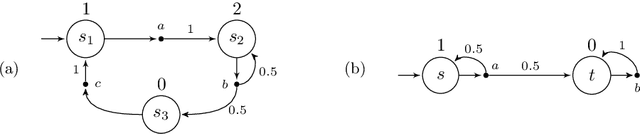

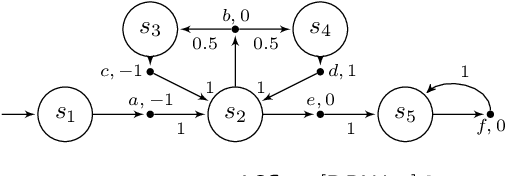
The window mechanism was introduced by Chatterjee et al. [1] to strengthen classical game objectives with time bounds. It permits to synthesize system controllers that exhibit acceptable behaviors within a configurable time frame, all along their infinite execution, in contrast to the traditional objectives that only require correctness of behaviors in the limit. The window concept has proved its interest in a variety of two-player zero-sum games, thanks to the ability to reason about such time bounds in system specifications, but also the increased tractability that it usually yields. In this work, we extend the window framework to stochastic environments by considering the fundamental threshold probability problem in Markov decision processes for window objectives. That is, given such an objective, we want to synthesize strategies that guarantee satisfying runs with a given probability. We solve this problem for the usual variants of window objectives, where either the time frame is set as a parameter, or we ask if such a time frame exists. We develop a generic approach for window-based objectives and instantiate it for the classical mean-payoff and parity objectives, already considered in games. Our work paves the way to a wide use of the window mechanism in stochastic models. [1] Krishnendu Chatterjee, Laurent Doyen, Mickael Randour, and Jean-Fran\c{c}ois Raskin. Looking at mean-payoff and total-payoff through windows. Inf. Comput., 242:25-52, 2015.
Multi-Start n-Dimensional Lattice Planning with Optimal Motion Primitives
Jul 23, 2021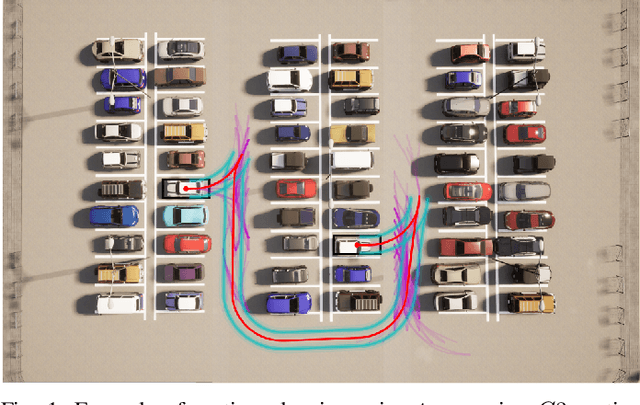
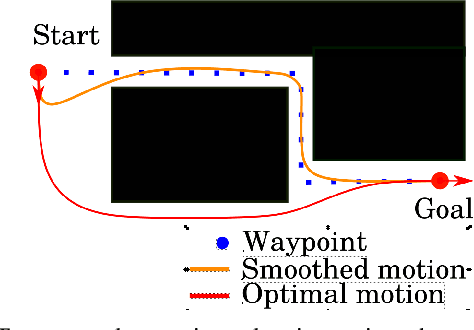
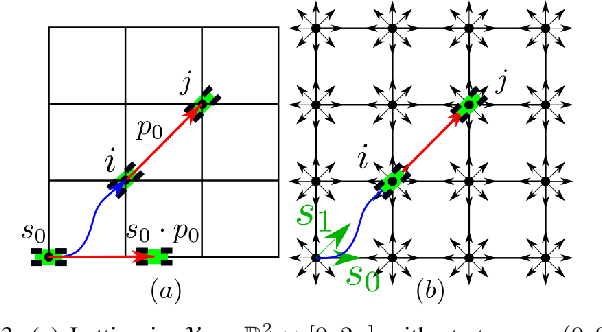
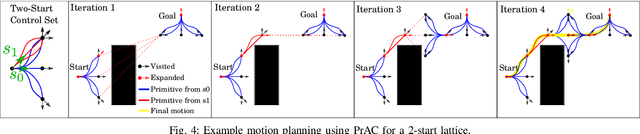
In the field of motion planning the use of pre-computed, feasible, locally optimal motions called motion primitives can not only increase the quality of motions, but decrease the computation time required to develop these motions. In this work we extend the results of our earlier work by developing a technique for computing primitives for a lattice that admits higher-order states like curvature, velocity, and acceleration. The technique involves computing a minimal set of motion primitives that $t$-span a configuration space lattice. A set of motion primitives $t$-span a lattice if, given a real number $t$ greater or equal to one, any configuration in the lattice can be reached via a sequence of motion primitives whose cost is no more than $t$ times the cost of the optimal path to that configuration. While motion primitives computed in this way could be used with any graph search algorithm to develop a motion, this paper also proposes one such algorithm which works well in practice in both short complex maneuvers and longer maneuvers. Finally, this paper proposes a shortcut-based smoothing algorithm based on shortest path planning in directed acyclic graphs.
Spartus: A 9.4 TOp/s FPGA-based LSTM Accelerator Exploiting Spatio-temporal Sparsity
Aug 04, 2021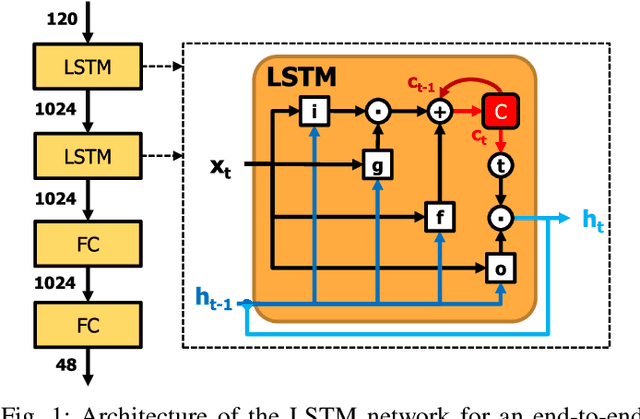
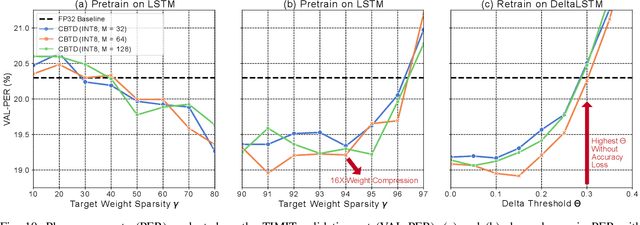
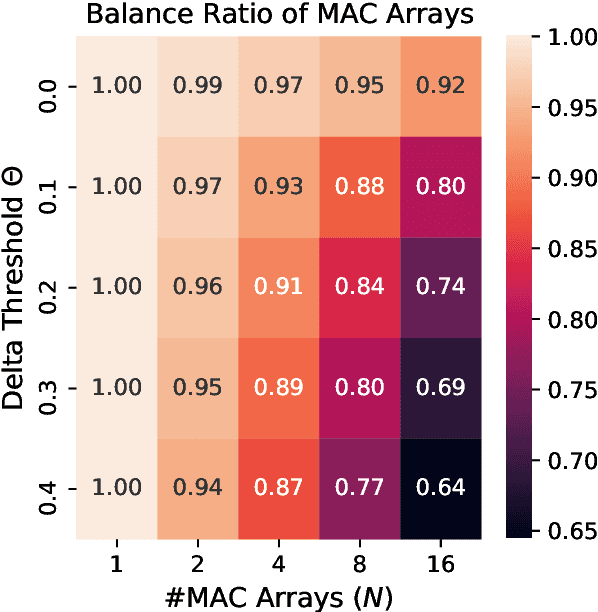
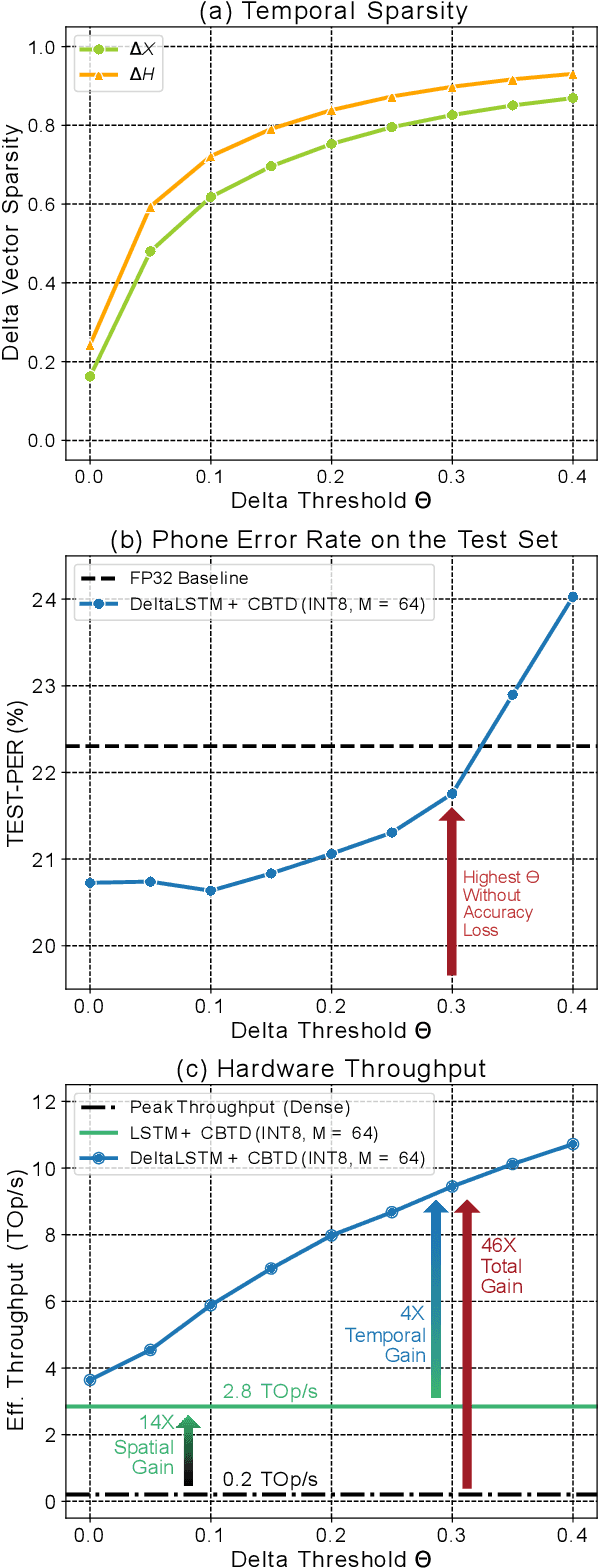
Long Short-Term Memory (LSTM) recurrent networks are frequently used for tasks involving time sequential data such as speech recognition. However, it is difficult to deploy these networks on hardware to achieve high throughput and low latency because the fully-connected structure makes LSTM networks a memory-bounded algorithm. Previous work in LSTM accelerators either exploited weight spatial sparsity or temporal sparsity. In this paper, we present a new accelerator called "Spartus" that exploits spatio-temporal sparsity to achieve ultra-low latency inference. The spatial sparsity was induced using our proposed pruning method called Column-Balanced Targeted Dropout (CBTD) that leads to structured sparse weight matrices benefiting workload balance. It achieved up to 96% weight sparsity with negligible accuracy difference for an LSTM network trained on a TIMIT phone recognition task. To induce temporal sparsity in LSTM, we create the DeltaLSTM by extending the previous DeltaGRU method to the LSTM network. This combined sparsity saves on weight memory access and associated arithmetic operations simultaneously. Spartus was implemented on a Xilinx Zynq-7100 FPGA. The per-sample latency for a single DeltaLSTM layer of 1024 neurons running on Spartus is 1 us. Spartus achieved 9.4 TOp/s effective batch-1 throughput and 1.1 TOp/J energy efficiency, which are respectively 4X and 7X higher than the previous state-of-the-art.
VolMap: A Real-time Model for Semantic Segmentation of a LiDAR surrounding view
Jun 12, 2019



This paper introduces VolMap, a real-time approach for the semantic segmentation of a 3D LiDAR surrounding view system in autonomous vehicles. We designed an optimized deep convolution neural network that can accurately segment the point cloud produced by a 360\degree{} LiDAR setup, where the input consists of a volumetric bird-eye view with LiDAR height layers used as input channels. We further investigated the usage of multi-LiDAR setup and its effect on the performance of the semantic segmentation task. Our evaluations are carried out on a large scale 3D object detection benchmark containing a LiDAR cocoon setup, along with KITTI dataset, where the per-point segmentation labels are derived from 3D bounding boxes. We show that VolMap achieved an excellent balance between high accuracy and real-time running on CPU.
BiX-NAS: Searching Efficient Bi-directional Architecture for Medical Image Segmentation
Jul 01, 2021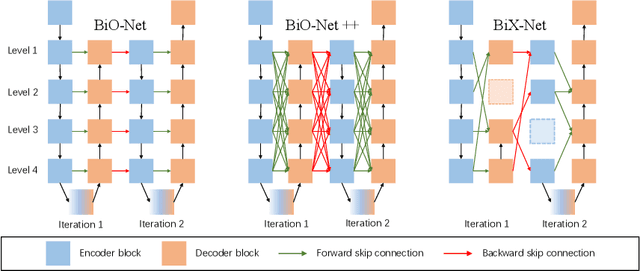
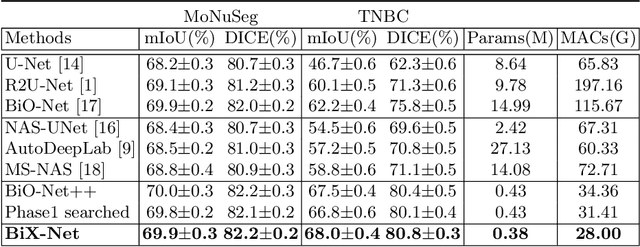
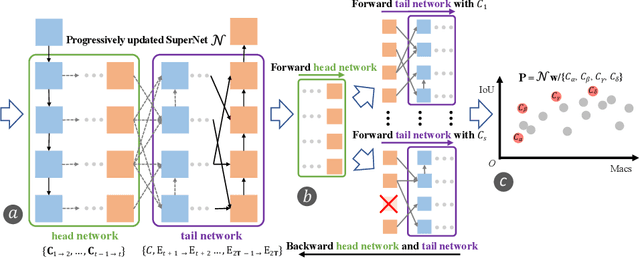
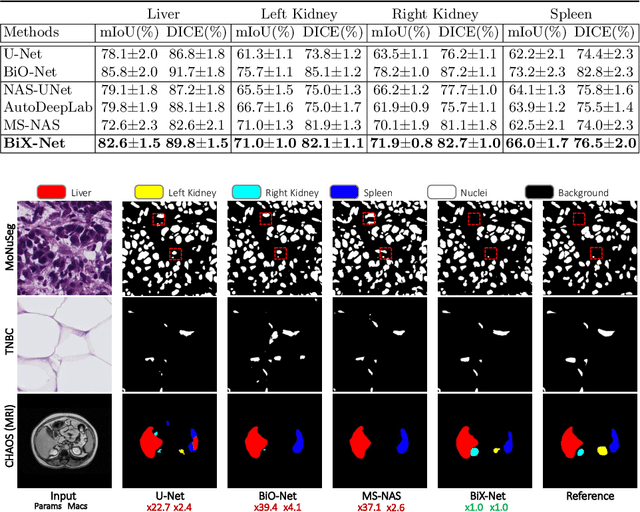
The recurrent mechanism has recently been introduced into U-Net in various medical image segmentation tasks. Existing studies have focused on promoting network recursion via reusing building blocks. Although network parameters could be greatly saved, computational costs still increase inevitably in accordance with the pre-set iteration time. In this work, we study a multi-scale upgrade of a bi-directional skip connected network and then automatically discover an efficient architecture by a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS. Our proposed method reduces the network computational cost by sifting out ineffective multi-scale features at different levels and iterations. We evaluate BiX-NAS on two segmentation tasks using three different medical image datasets, and the experimental results show that our BiX-NAS searched architecture achieves the state-of-the-art performance with significantly lower computational cost.
A general sample complexity analysis of vanilla policy gradient
Jul 23, 2021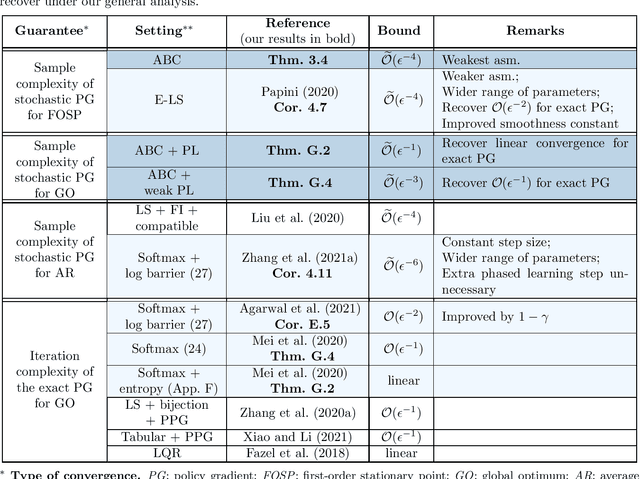
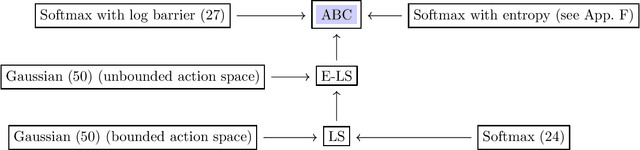

The policy gradient (PG) is one of the most popular methods for solving reinforcement learning (RL) problems. However, a solid theoretical understanding of even the "vanilla" PG has remained elusive for long time. In this paper, we apply recent tools developed for the analysis of SGD in non-convex optimization to obtain convergence guarantees for both REINFORCE and GPOMDP under smoothness assumption on the objective function and weak conditions on the second moment of the norm of the estimated gradient. When instantiated under common assumptions on the policy space, our general result immediately recovers existing $\widetilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity guarantees, but for wider ranges of parameters (e.g., step size and batch size $m$) with respect to previous literature. Notably, our result includes the single trajectory case (i.e., $m=1$) and it provides a more accurate analysis of the dependency on problem-specific parameters by fixing previous results available in the literature. We believe that the integration of state-of-the-art tools from non-convex optimization may lead to identify a much broader range of problems where PG methods enjoy strong theoretical guarantees.