 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RIS-assisted UAV Communications for IoT with Wireless Power Transfer Using Deep Reinforcement Learning
Aug 05, 2021
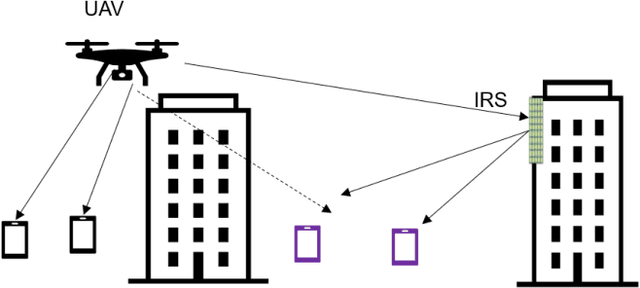
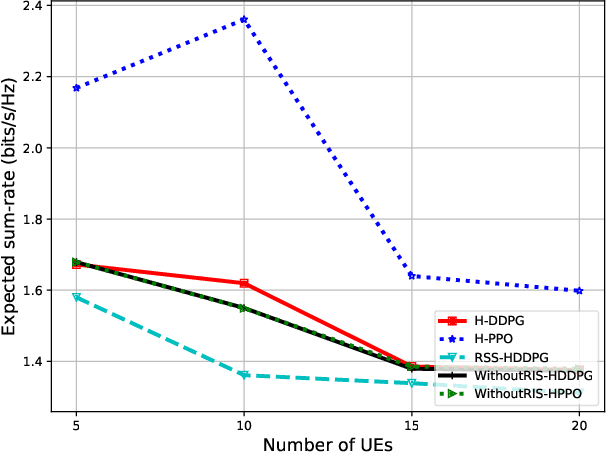
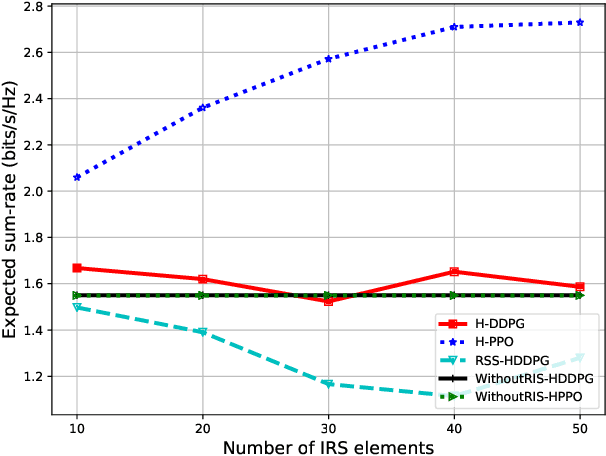
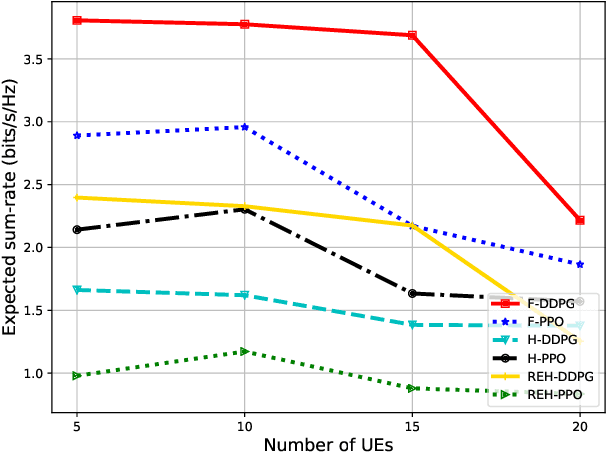
Many of the devices used in Internet-of-Things (IoT) applications are energy-limited, and thus supplying energy while maintaining seamless connectivity for IoT devices is of considerable importance. In this context, we propose a simultaneous wireless power transfer and information transmission scheme for IoT devices with support from reconfigurable intelligent surface (RIS)-aided unmanned aerial vehicle (UAV) communications. In particular, in a first phase, IoT devices harvest energy from the UAV through wireless power transfer; and then in a second phase, the UAV collects data from the IoT devices through information transmission. To characterise the agility of the UAV, we consider two scenarios: a hovering UAV and a mobile UAV. Aiming at maximizing the total network sum-rate, we jointly optimize the trajectory of the UAV, the energy harvesting scheduling of IoT devices, and the phaseshift matrix of the RIS. We formulate a Markov decision process and propose two deep reinforcement learning algorithms to solve the optimization problem of maximizing the total network sum-rate. Numerical results illustrate the effectiveness of the UAV's flying path optimization and the network's throughput of our proposed techniques compared with other benchmark schemes. Given the strict requirements of the RIS and UAV, the significant improvement in processing time and throughput performance demonstrates that our proposed scheme is well applicable for practical IoT applications.
Transfer learning for time series classification
Nov 05, 2018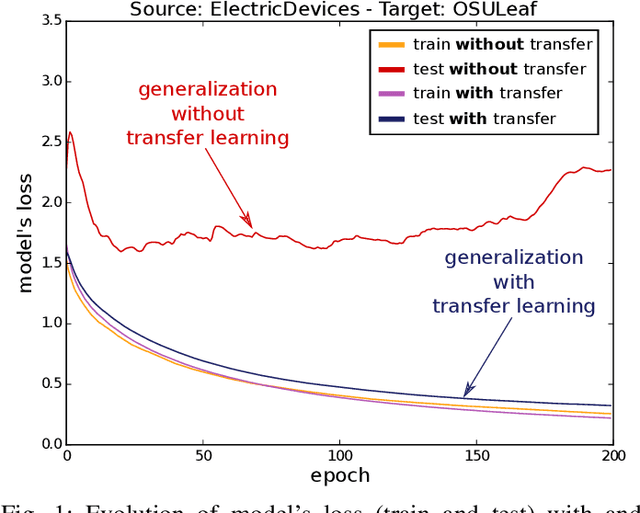
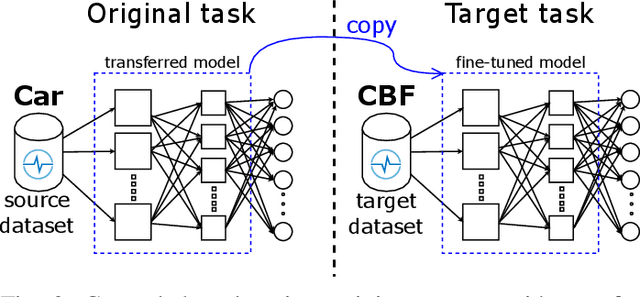
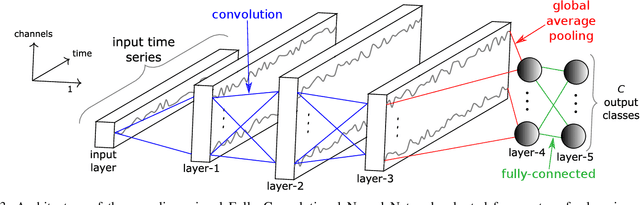
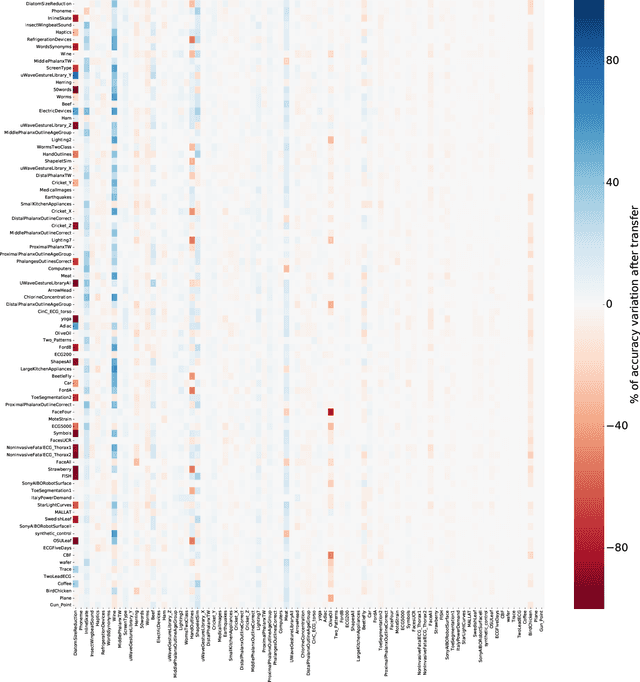
Transfer learning for deep neural networks is the process of first training a base network on a source dataset, and then transferring the learned features (the network's weights) to a second network to be trained on a target dataset. This idea has been shown to improve deep neural network's generalization capabilities in many computer vision tasks such as image recognition and object localization. Apart from these applications, deep Convolutional Neural Networks (CNNs) have also recently gained popularity in the Time Series Classification (TSC) community. However, unlike for image recognition problems, transfer learning techniques have not yet been investigated thoroughly for the TSC task. This is surprising as the accuracy of deep learning models for TSC could potentially be improved if the model is fine-tuned from a pre-trained neural network instead of training it from scratch. In this paper, we fill this gap by investigating how to transfer deep CNNs for the TSC task. To evaluate the potential of transfer learning, we performed extensive experiments using the UCR archive which is the largest publicly available TSC benchmark containing 85 datasets. For each dataset in the archive, we pre-trained a model and then fine-tuned it on the other datasets resulting in 7140 different deep neural networks. These experiments revealed that transfer learning can improve or degrade the model's predictions depending on the dataset used for transfer. Therefore, in an effort to predict the best source dataset for a given target dataset, we propose a new method relying on Dynamic Time Warping to measure inter-datasets similarities. We describe how our method can guide the transfer to choose the best source dataset leading to an improvement in accuracy on 71 out of 85 datasets.
REaL: Real-time Face Detection and Recognition Using Euclidean Space and Likelihood Estimation
Nov 30, 2020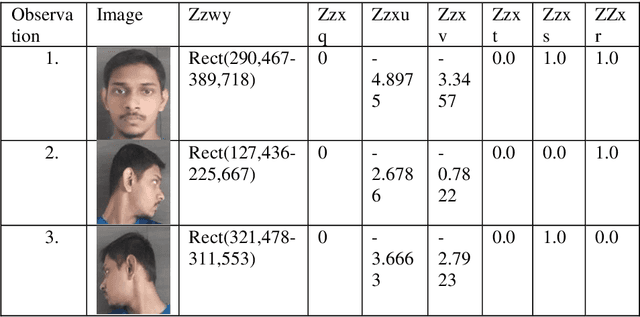
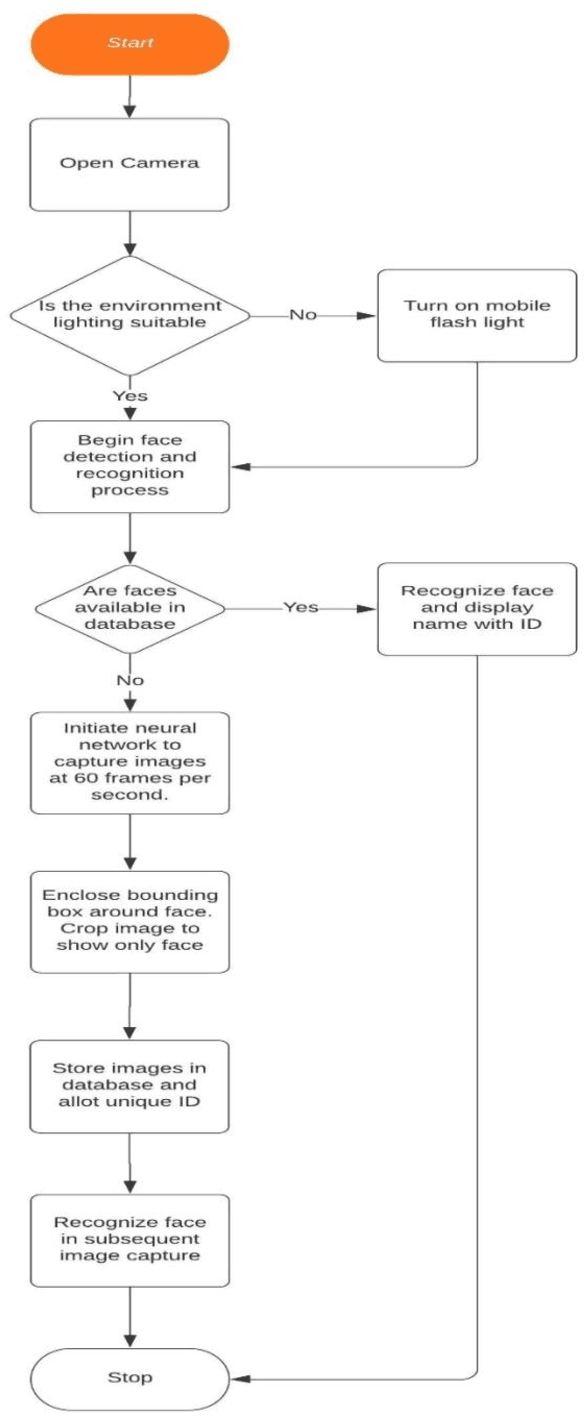
Detecting and recognizing faces accurately has always been a challenge. Differentiating facial features, training images, and producing quick results require a lot of computation. The REaL system we have proposed in this paper discusses its functioning and ways in which computations can be carried out in a short period. REaL experiments are carried out on live images and the recognition rates are promising. The system is also successful in removing non-human objects from its calculations. The system uses a local database to store captured images and feeds the neural network frequently. The captured images are cropped automatically to remove unwanted noise. The system calculates the Euler angles and the probability of whether the face is smiling, has its left eye, and right eyes open or not.
Learning in Modal Space: Solving Time-Dependent Stochastic PDEs Using Physics-Informed Neural Networks
May 03, 2019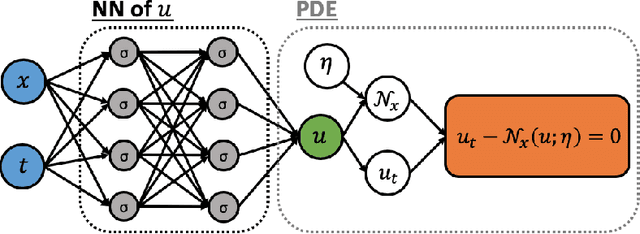
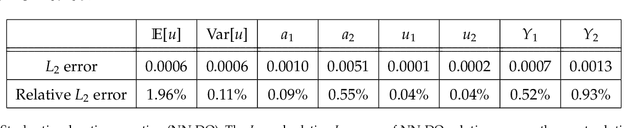
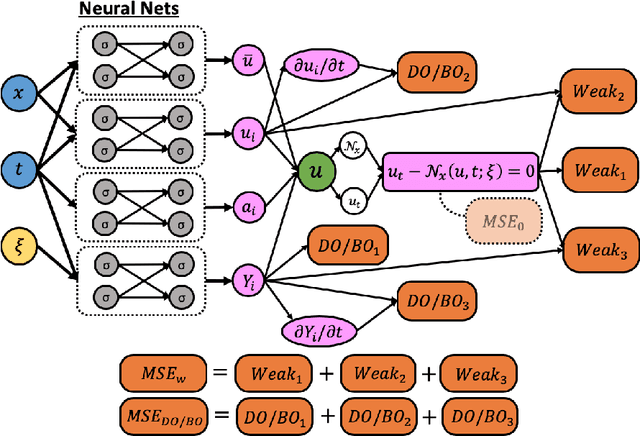

One of the open problems in scientific computing is the long-time integration of nonlinear stochastic partial differential equations (SPDEs). We address this problem by taking advantage of recent advances in scientific machine learning and the dynamically orthogonal (DO) and bi-orthogonal (BO) methods for representing stochastic processes. Specifically, we propose two new Physics-Informed Neural Networks (PINNs) for solving time-dependent SPDEs, namely the NN-DO/BO methods, which incorporate the DO/BO constraints into the loss function with an implicit form instead of generating explicit expressions for the temporal derivatives of the DO/BO modes. Hence, the proposed methods overcome some of the drawbacks of the original DO/BO methods: we do not need the assumption that the covariance matrix of the random coefficients is invertible as in the original DO method, and we can remove the assumption of no eigenvalue crossing as in the original BO method. Moreover, the NN-DO/BO methods can be used to solve time-dependent stochastic inverse problems with the same formulation and computational complexity as for forward problems. We demonstrate the capability of the proposed methods via several numerical examples: (1) A linear stochastic advection equation with deterministic initial condition where the original DO/BO method would fail; (2) Long-time integration of the stochastic Burgers' equation with many eigenvalue crossings during the whole time evolution where the original BO method fails. (3) Nonlinear reaction diffusion equation: we consider both the forward and the inverse problem, including noisy initial data, to investigate the flexibility of the NN-DO/BO methods in handling inverse and mixed type problems. Taken together, these simulation results demonstrate that the NN-DO/BO methods can be employed to effectively quantify uncertainty propagation in a wide range of physical problems.
Language-Independent Approach for Automatic Computation of Vowel Articulation Features in Dysarthric Speech Assessment
Aug 16, 2021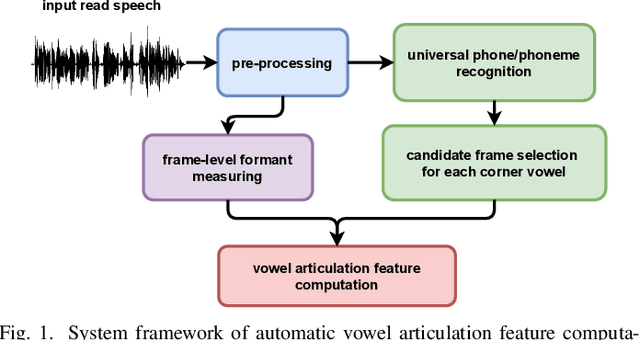
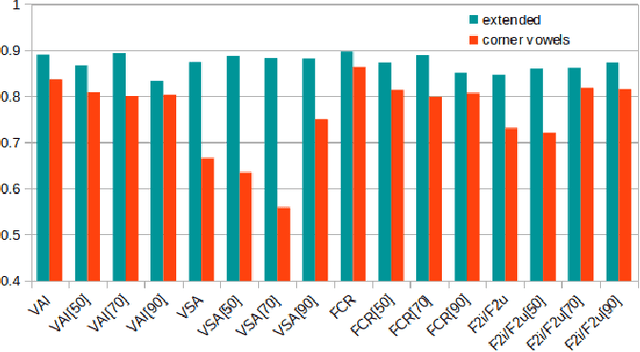
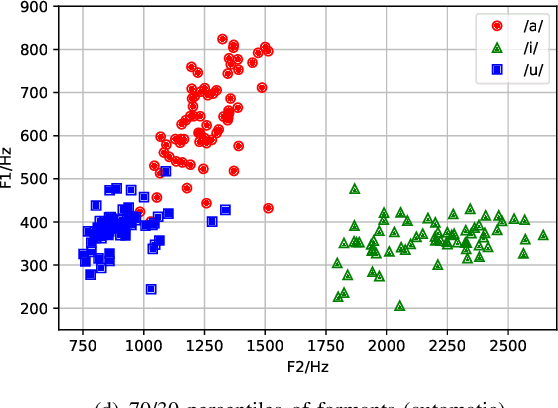
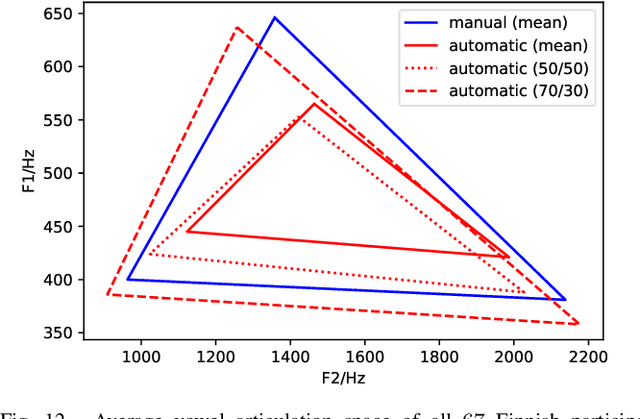
Imprecise vowel articulation can be observed in people with Parkinson's disease (PD). Acoustic features measuring vowel articulation have been demonstrated to be effective indicators of PD in its assessment. Standard clinical vowel articulation features of vowel working space area (VSA), vowel articulation index (VAI) and formants centralization ratio (FCR), are derived the first two formants of the three corner vowels /a/, /i/ and /u/. Conventionally, manual annotation of the corner vowels from speech data is required before measuring vowel articulation. This process is time-consuming. The present work aims to reduce human effort in clinical analysis of PD speech by proposing an automatic pipeline for vowel articulation assessment. The method is based on automatic corner vowel detection using a language universal phoneme recognizer, followed by statistical analysis of the formant data. The approach removes the restrictions of prior knowledge of speaking content and the language in question. Experimental results on a Finnish PD speech corpus demonstrate the efficacy and reliability of the proposed automatic method in deriving VAI, VSA, FCR and F2i/F2u (the second formant ratio for vowels /i/ and /u/). The automatically computed parameters are shown to be highly correlated with features computed with manual annotations of corner vowels. In addition, automatically and manually computed vowel articulation features have comparable correlations with experts' ratings on speech intelligibility, voice impairment and overall severity of communication disorder. Language-independence of the proposed approach is further validated on a Spanish PD database, PC-GITA, as well as on TORGO corpus of English dysarthric speech.
* 16 pages
Decentralized Dictionary Learning Over Time-Varying Digraphs
Aug 17, 2018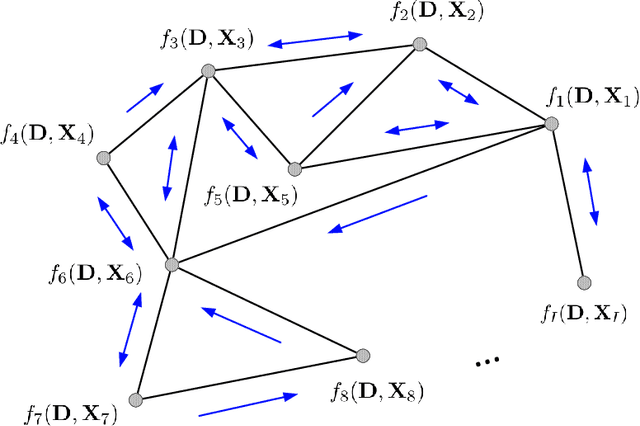
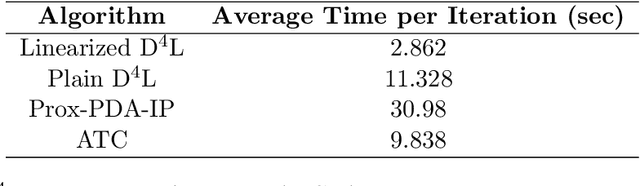
This paper studies Dictionary Learning problems wherein the learning task is distributed over a multi-agent network, modeled as a time-varying directed graph. This formulation is relevant, for instance, in Big Data scenarios where massive amounts of data are collected/stored in different locations (e.g., sensors, clouds) and aggregating and/or processing all data in a fusion center might be inefficient or unfeasible, due to resource limitations, communication overheads or privacy issues. We develop a unified decentralized algorithmic framework for this class of nonconvex problems, and we establish its asymptotic convergence to stationary solutions. The new method hinges on Successive Convex Approximation techniques, coupled with a decentralized tracking mechanism aiming at locally estimating the gradient of the smooth part of the sum-utility. To the best of our knowledge, this is the first provably convergent decentralized algorithm for Dictionary Learning and, more generally, bi-convex problems over (time-varying) (di)graphs.
DQ-GAT: Towards Safe and Efficient Autonomous Driving with Deep Q-Learning and Graph Attention Networks
Aug 11, 2021
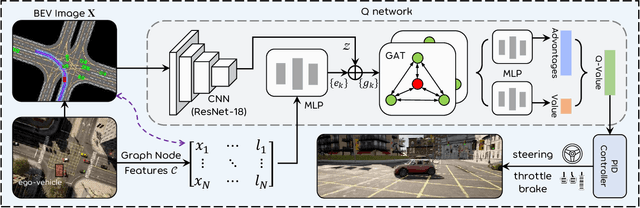
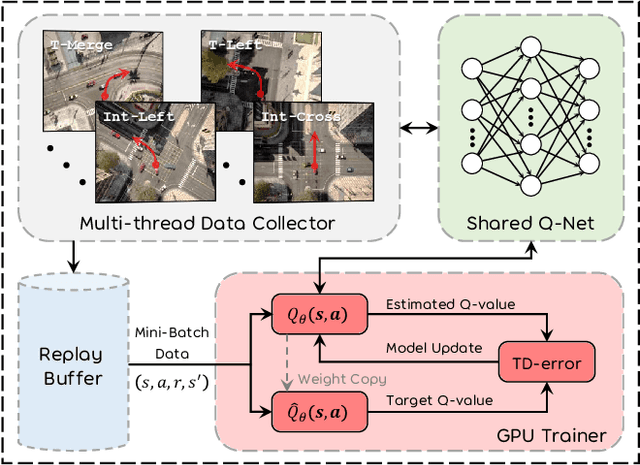
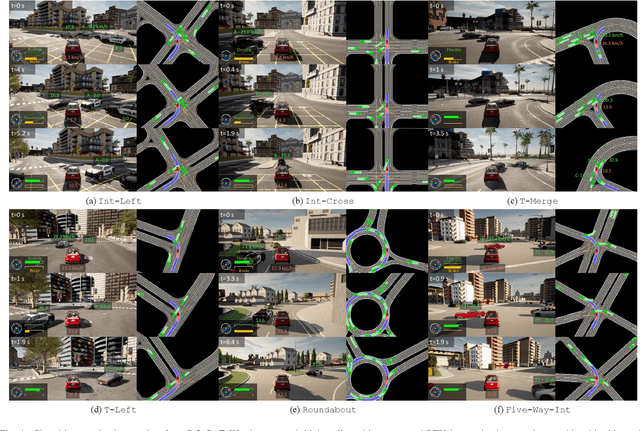
Autonomous driving in multi-agent and dynamic traffic scenarios is challenging, where the behaviors of other road agents are uncertain and hard to model explicitly, and the ego-vehicle should apply complicated negotiation skills with them to achieve both safe and efficient driving in various settings, such as giving way, merging and taking turns. Traditional planning methods are largely rule-based and scale poorly in these complex dynamic scenarios, often leading to reactive or even overly conservative behaviors. Therefore, they require tedious human efforts to maintain workability. Recently, deep learning-based methods have shown promising results with better generalization capability but less hand engineering effort. However, they are either implemented with supervised imitation learning (IL) that suffers from the dataset bias and distribution mismatch problems, or trained with deep reinforcement learning (DRL) but focus on one specific traffic scenario. In this work, we propose DQ-GAT to achieve scalable and proactive autonomous driving, where graph attention-based networks are used to implicitly model interactions, and asynchronous deep Q-learning is employed to train the network end-to-end in an unsupervised manner. Extensive experiments through a high-fidelity driving simulation show that our method can better trade-off safety and efficiency in both seen and unseen scenarios, achieving higher goal success rates than the baselines (at most 4.7$\times$) with comparable task completion time. Demonstration videos are available at https://caipeide.github.io/dq-gat/.
FEBR: Expert-Based Recommendation Framework for beneficial and personalized content
Jul 17, 2021
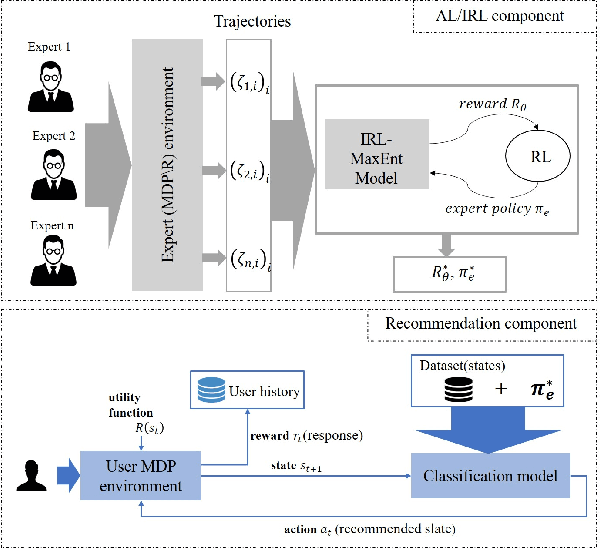
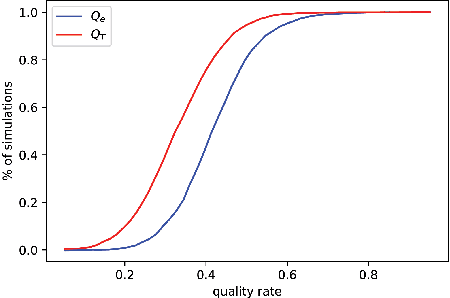
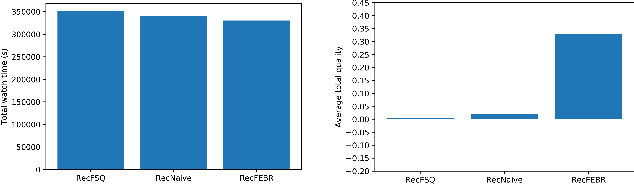
So far, most research on recommender systems focused on maintaining long-term user engagement and satisfaction, by promoting relevant and personalized content. However, it is still very challenging to evaluate the quality and the reliability of this content. In this paper, we propose FEBR (Expert-Based Recommendation Framework), an apprenticeship learning framework to assess the quality of the recommended content on online platforms. The framework exploits the demonstrated trajectories of an expert (assumed to be reliable) in a recommendation evaluation environment, to recover an unknown utility function. This function is used to learn an optimal policy describing the expert's behavior, which is then used in the framework to provide high-quality and personalized recommendations. We evaluate the performance of our solution through a user interest simulation environment (using RecSim). We simulate interactions under the aforementioned expert policy for videos recommendation, and compare its efficiency with standard recommendation methods. The results show that our approach provides a significant gain in terms of content quality, evaluated by experts and watched by users, while maintaining almost the same watch time as the baseline approaches.
Self-Supervised Learning from Unlabeled Fundus Photographs Improves Segmentation of the Retina
Aug 05, 2021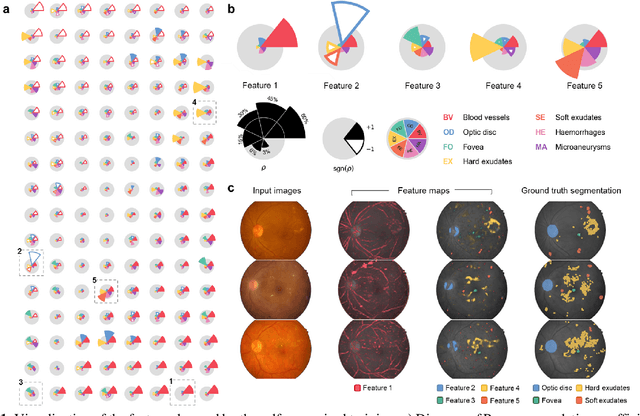
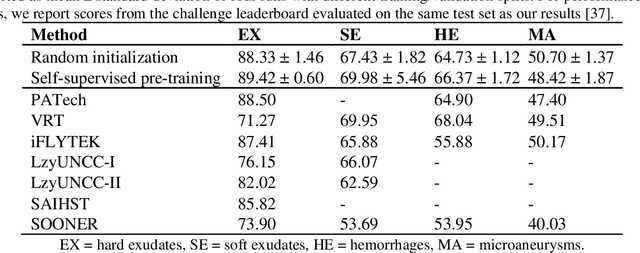
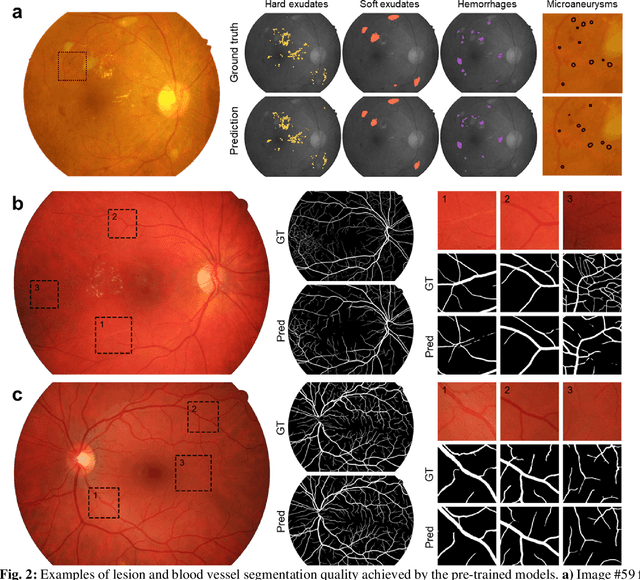
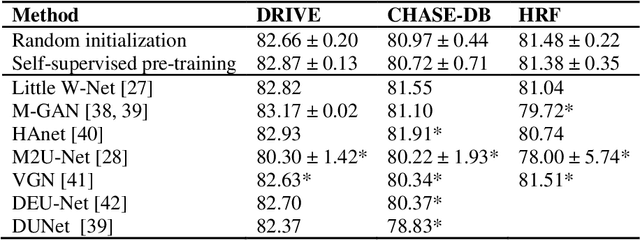
Fundus photography is the primary method for retinal imaging and essential for diabetic retinopathy prevention. Automated segmentation of fundus photographs would improve the quality, capacity, and cost-effectiveness of eye care screening programs. However, current segmentation methods are not robust towards the diversity in imaging conditions and pathologies typical for real-world clinical applications. To overcome these limitations, we utilized contrastive self-supervised learning to exploit the large variety of unlabeled fundus images in the publicly available EyePACS dataset. We pre-trained an encoder of a U-Net, which we later fine-tuned on several retinal vessel and lesion segmentation datasets. We demonstrate for the first time that by using contrastive self-supervised learning, the pre-trained network can recognize blood vessels, optic disc, fovea, and various lesions without being provided any labels. Furthermore, when fine-tuned on a downstream blood vessel segmentation task, such pre-trained networks achieve state-of-the-art performance on images from different datasets. Additionally, the pre-training also leads to shorter training times and an improved few-shot performance on both blood vessel and lesion segmentation tasks. Altogether, our results showcase the benefits of contrastive self-supervised pre-training which can play a crucial role in real-world clinical applications requiring robust models able to adapt to new devices with only a few annotated samples.
Sinsy: A Deep Neural Network-Based Singing Voice Synthesis System
Aug 05, 2021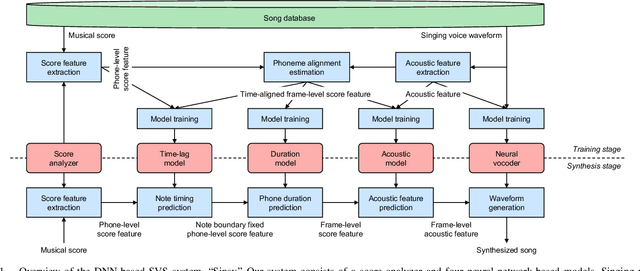
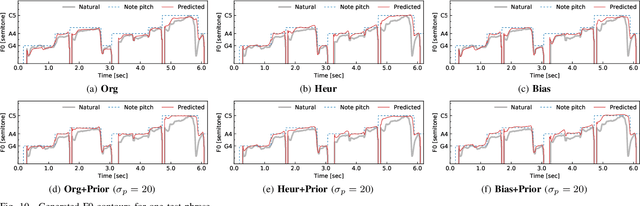
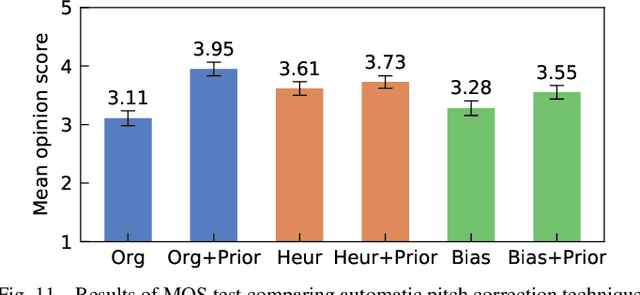
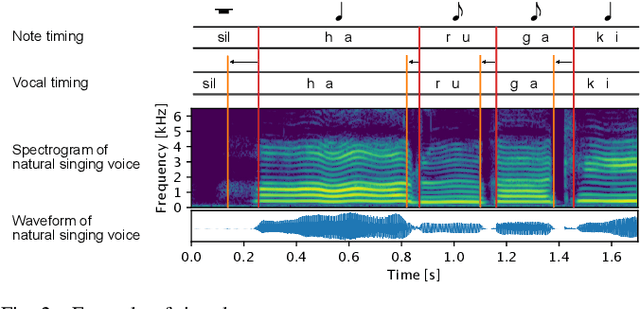
This paper presents Sinsy, a deep neural network (DNN)-based singing voice synthesis (SVS) system. In recent years, DNNs have been utilized in statistical parametric SVS systems, and DNN-based SVS systems have demonstrated better performance than conventional hidden Markov model-based ones. SVS systems are required to synthesize a singing voice with pitch and timing that strictly follow a given musical score. Additionally, singing expressions that are not described on the musical score, such as vibrato and timing fluctuations, should be reproduced. The proposed system is composed of four modules: a time-lag model, a duration model, an acoustic model, and a vocoder, and singing voices can be synthesized taking these characteristics of singing voices into account. To better model a singing voice, the proposed system incorporates improved approaches to modeling pitch and vibrato and better training criteria into the acoustic model. In addition, we incorporated PeriodNet, a non-autoregressive neural vocoder with robustness for the pitch, into our systems to generate a high-fidelity singing voice waveform. Moreover, we propose automatic pitch correction techniques for DNN-based SVS to synthesize singing voices with correct pitch even if the training data has out-of-tune phrases. Experimental results show our system can synthesize a singing voice with better timing, more natural vibrato, and correct pitch, and it can achieve better mean opinion scores in subjective evaluation tests.