 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Quasi-concave set optimization: A new frontier that scales without needing submodularity
Aug 19, 2021

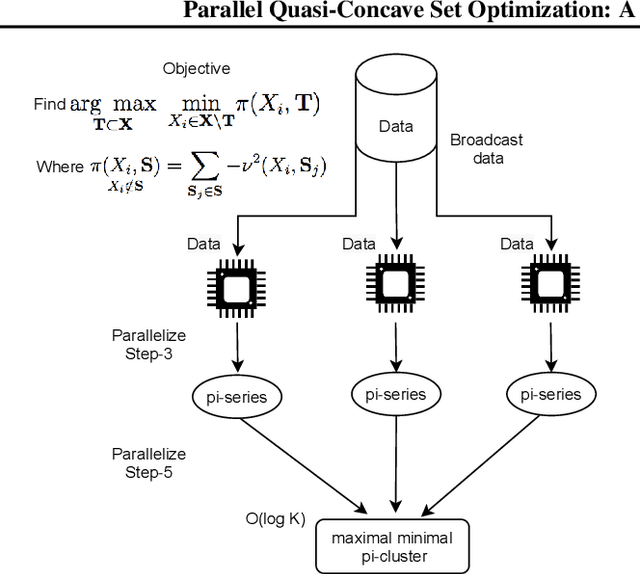
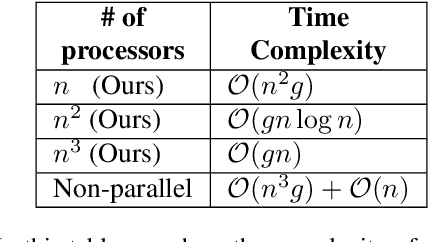
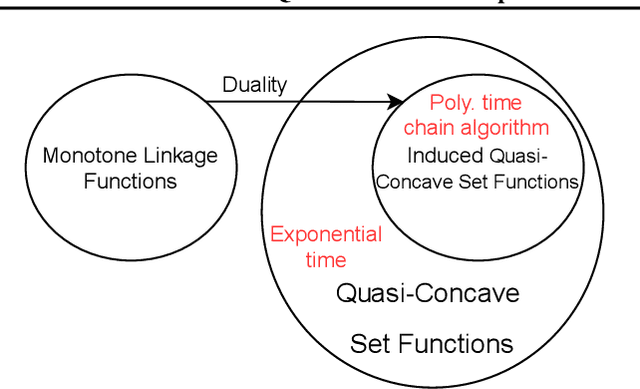
Classes of set functions along with a choice of ground set are a bedrock to determine and develop corresponding variants of greedy algorithms to obtain efficient solutions for combinatorial optimization problems. The class of approximate constrained submodular optimization has seen huge advances at the intersection of good computational efficiency, versatility and approximation guarantees while exact solutions for unconstrained submodular optimization are NP-hard. What is an alternative to situations when submodularity does not hold? Can efficient and globally exact solutions be obtained? We introduce one such new frontier: The class of quasi-concave set functions induced as a dual class to monotone linkage functions. We provide a parallel algorithm with a time complexity over $n$ processors of $\mathcal{O}(n^2g) +\mathcal{O}(\log{\log{n}})$ where $n$ is the cardinality of the ground set and $g$ is the complexity to compute the monotone linkage function that induces a corresponding quasi-concave set function via a duality. The complexity reduces to $\mathcal{O}(gn\log(n))$ on $n^2$ processors and to $\mathcal{O}(gn)$ on $n^3$ processors. Our algorithm provides a globally optimal solution to a maxi-min problem as opposed to submodular optimization which is approximate. We show a potential for widespread applications via an example of diverse feature subset selection with exact global maxi-min guarantees upon showing that a statistical dependency measure called distance correlation can be used to induce a quasi-concave set function.
Vision-Based Target Localization for a Flapping-Wing Aerial Vehicle
Jul 15, 2021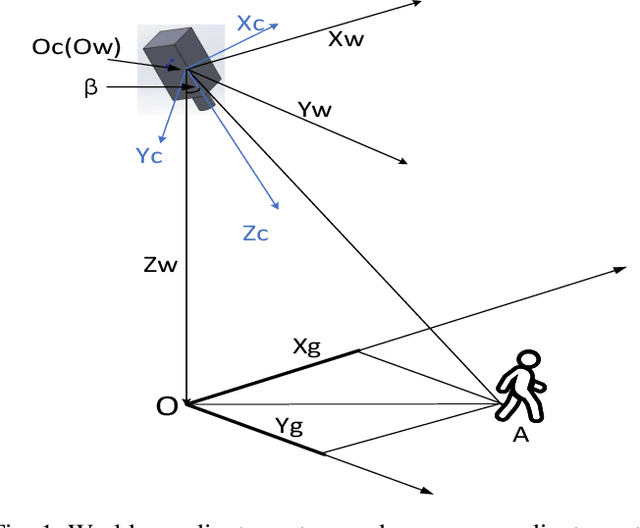
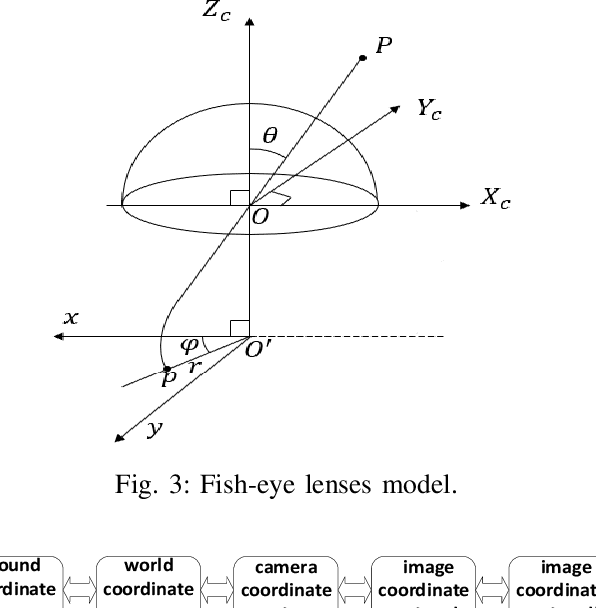

The flapping-wing aerial vehicle (FWAV) is a new type of flying robot that mimics the flight mode of birds and insects. However, FWAVs have their special characteristics of less load capacity and short endurance time, so that most existing systems of ground target localization are not suitable for them. In this paper, a vision-based target localization algorithm is proposed for FWAVs based on a generic camera model. Since sensors exist measurement error and the camera exists jitter and motion blur during flight, Gaussian noises are introduced in the simulation experiment, and then a first-order low-pass filter is used to stabilize the localization values. Moreover, in order to verify the feasibility and accuracy of the target localization algorithm, we design a set of simulation experiments where various noises are added. From the simulation results, it is found that the target localization algorithm has a good performance.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021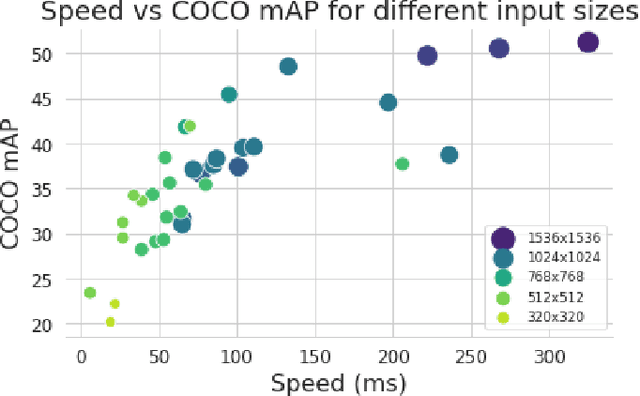
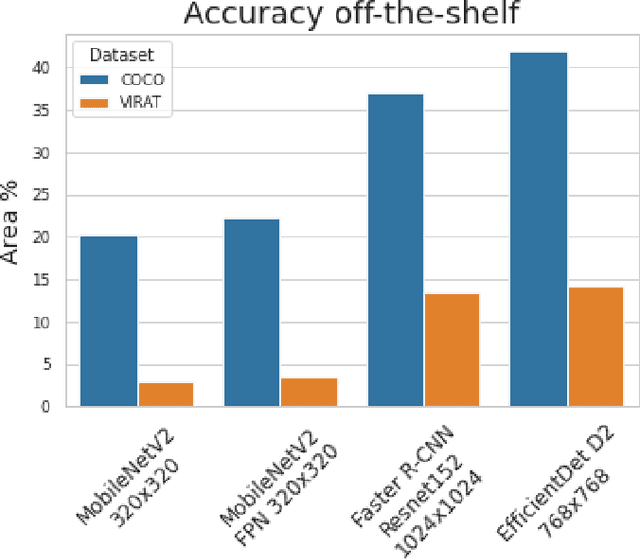
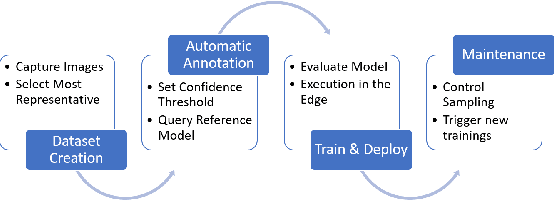
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.
Exact Acceleration of K-Means++ and K-Means$\|$
May 06, 2021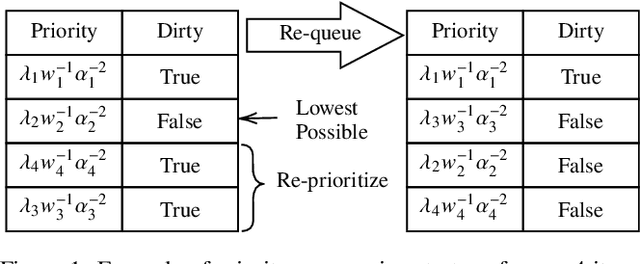
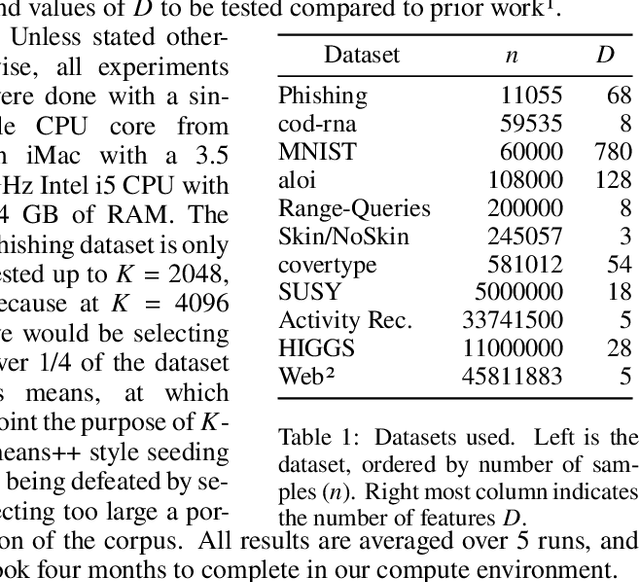
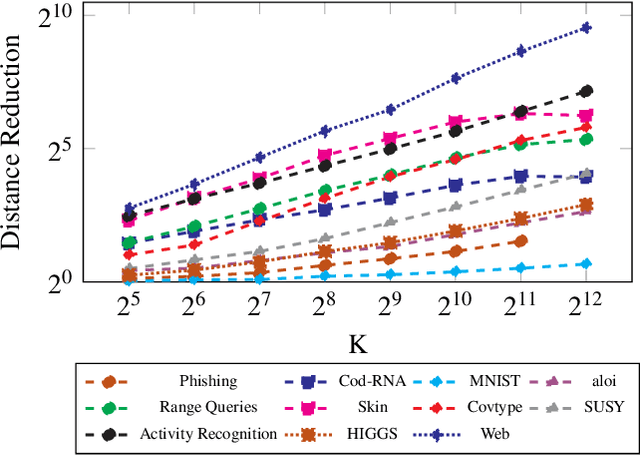
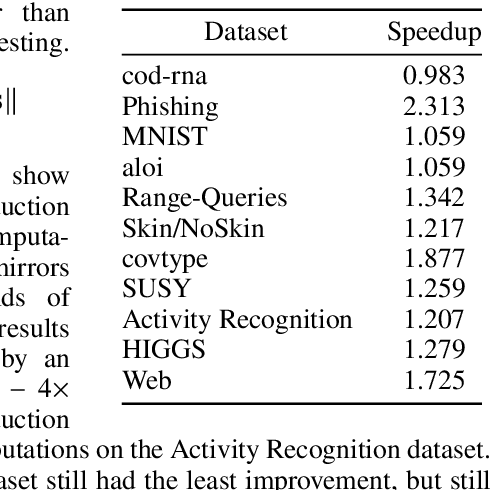
K-Means++ and its distributed variant K-Means$\|$ have become de facto tools for selecting the initial seeds of K-means. While alternatives have been developed, the effectiveness, ease of implementation, and theoretical grounding of the K-means++ and $\|$ methods have made them difficult to "best" from a holistic perspective. By considering the limited opportunities within seed selection to perform pruning, we develop specialized triangle inequality pruning strategies and a dynamic priority queue to show the first acceleration of K-Means++ and K-Means$\|$ that is faster in run-time while being algorithmicly equivalent. For both algorithms we are able to reduce distance computations by over $500\times$. For K-means++ this results in up to a 17$\times$ speedup in run-time and a $551\times$ speedup for K-means$\|$. We achieve this with simple, but carefully chosen, modifications to known techniques which makes it easy to integrate our approach into existing implementations of these algorithms.
Fuzzy Clustering with Similarity Queries
Jun 04, 2021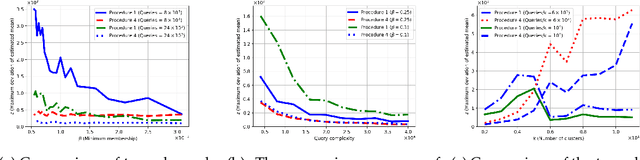
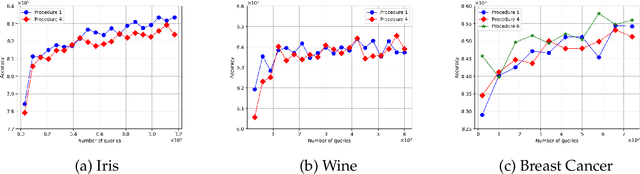
The fuzzy or soft $k$-means objective is a popular generalization of the well-known $k$-means problem, extending the clustering capability of the $k$-means to datasets that are uncertain, vague, and otherwise hard to cluster. In this paper, we propose a semi-supervised active clustering framework, where the learner is allowed to interact with an oracle (domain expert), asking for the similarity between a certain set of chosen items. We study the query and computational complexities of clustering in this framework. We prove that having a few of such similarity queries enables one to get a polynomial-time approximation algorithm to an otherwise conjecturally NP-hard problem. In particular, we provide probabilistic algorithms for fuzzy clustering in this setting that asks $O(\mathsf{poly}(k)\log n)$ similarity queries and run with polynomial-time-complexity, where $n$ is the number of items. The fuzzy $k$-means objective is nonconvex, with $k$-means as a special case, and is equivalent to some other generic nonconvex problem such as non-negative matrix factorization. The ubiquitous Lloyd-type algorithms (or, expectation-maximization algorithm) can get stuck at a local minima. Our results show that by making few similarity queries, the problem becomes easier to solve. Finally, we test our algorithms over real-world datasets, showing their effectiveness in real-world applications.
Dynamic Multi-scale Convolution for Dialect Identification
Aug 02, 2021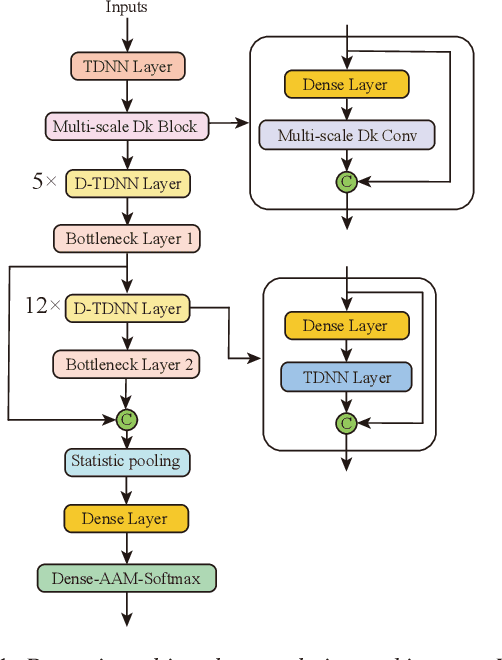

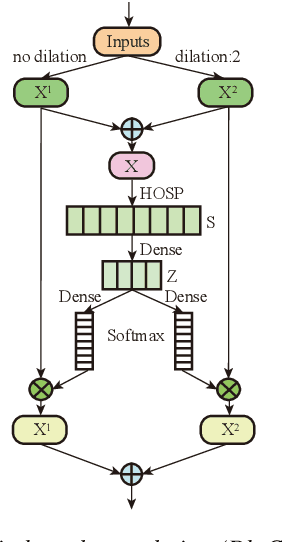

Time Delay Neural Networks (TDNN)-based methods are widely used in dialect identification. However, in previous work with TDNN application, subtle variant is being neglected in different feature scales. To address this issue, we propose a new architecture, named dynamic multi-scale convolution, which consists of dynamic kernel convolution, local multi-scale learning, and global multi-scale pooling. Dynamic kernel convolution captures features between short-term and long-term context adaptively. Local multi-scale learning, which represents multi-scale features at a granular level, is able to increase the range of receptive fields for convolution operation. Besides, global multi-scale pooling is applied to aggregate features from different bottleneck layers in order to collect information from multiple aspects. The proposed architecture significantly outperforms state-of-the-art system on the AP20-OLR-dialect-task of oriental language recognition (OLR) challenge 2020, with the best average cost performance (Cavg) of 0.067 and the best equal error rate (EER) of 6.52%. Compared with the known best results, our method achieves 9% of Cavg and 45% of EER relative improvement, respectively. Furthermore, the parameters of proposed model are 91% fewer than the best known model.
Distributed TD(0) with Almost No Communication
Apr 16, 2021
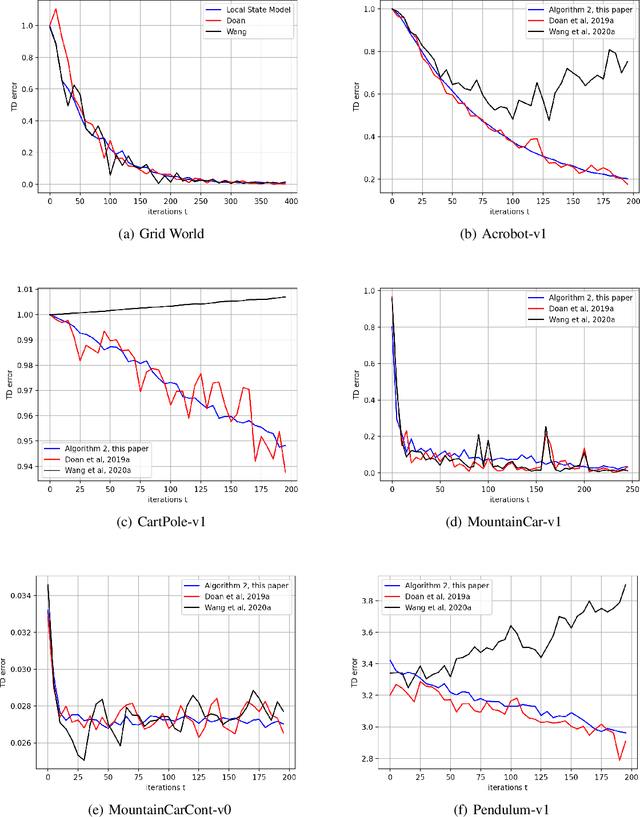
We provide a new non-asymptotic analysis of distributed TD(0) with linear function approximation. Our approach relies on "one-shot averaging," where $N$ agents run local copies of TD(0) and average the outcomes only once at the very end. We consider two models: one in which the agents interact with an environment they can observe and whose transitions depends on all of their actions (which we call the global state model), and one in which each agent can run a local copy of an identical Markov Decision Process, which we call the local state model. In the global state model, we show that the convergence rate of our distributed one-shot averaging method matches the known convergence rate of TD(0). By contrast, the best convergence rate in the previous literature showed a rate which, in the worst case, underperformed the non-distributed version by $O(N^3)$ in terms of the number of agents $N$. In the local state model, we demonstrate a version of the linear time speedup phenomenon, where the convergence time of the distributed process is a factor of $N$ faster than the convergence time of TD(0). As far as we are aware, this is the first result rigorously showing benefits from parallelism for temporal difference methods.
Efficient Federated Meta-Learning over Multi-Access Wireless Networks
Aug 14, 2021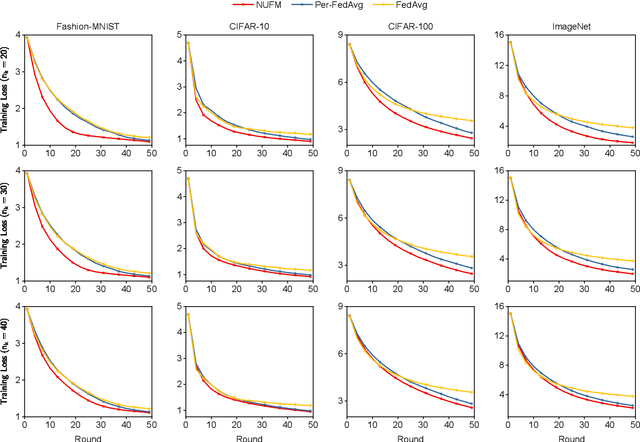
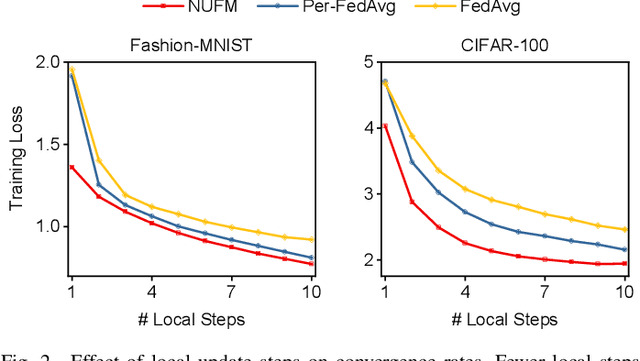
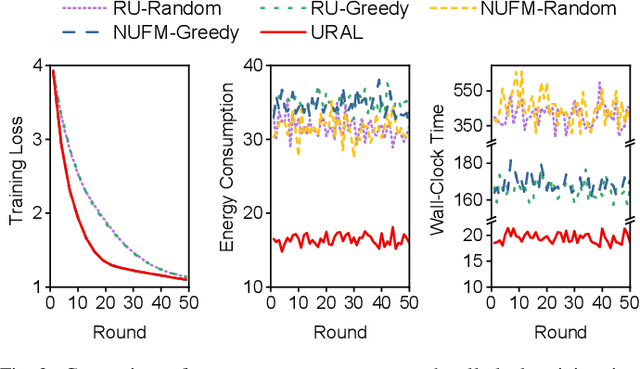
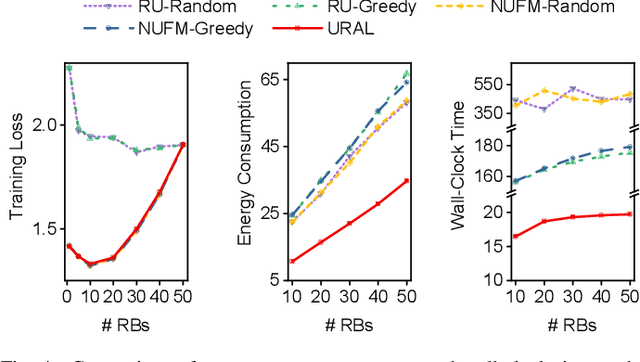
Federated meta-learning (FML) has emerged as a promising paradigm to cope with the data limitation and heterogeneity challenges in today's edge learning arena. However, its performance is often limited by slow convergence and corresponding low communication efficiency. Besides, since the wireless bandwidth and IoT devices' energy capacity are usually insufficient, it is crucial to control the resource allocation and energy consumption when deploying FML in realistic wireless networks. To overcome these challenges, in this paper, we first rigorously analyze each device's contribution to the global loss reduction in each round and develop an FML algorithm (called NUFM) with a non-uniform device selection scheme to accelerate the convergence. After that, we formulate a resource allocation problem integrating NUFM in multi-access wireless systems to jointly improve the convergence rate and minimize the wall-clock time along with energy cost. By deconstructing the original problem step by step, we devise a joint device selection and resource allocation strategy (called URAL) to solve the problem and provide theoretical guarantees. Further, we show that the computational complexity of NUFM can be reduced from $O(d^2)$ to $O(d)$ (with $d$ being the model dimension) via combining two first-order approximation techniques. Extensive simulation results demonstrate the effectiveness and superiority of the proposed methods by comparing with the existing baselines.
Waveform Design and Performance Analysis for Full-Duplex Integrated Sensing and Communication
Aug 14, 2021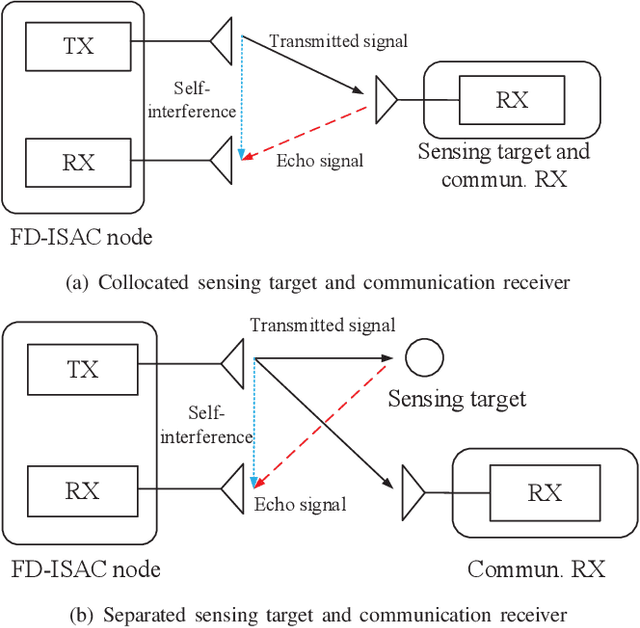
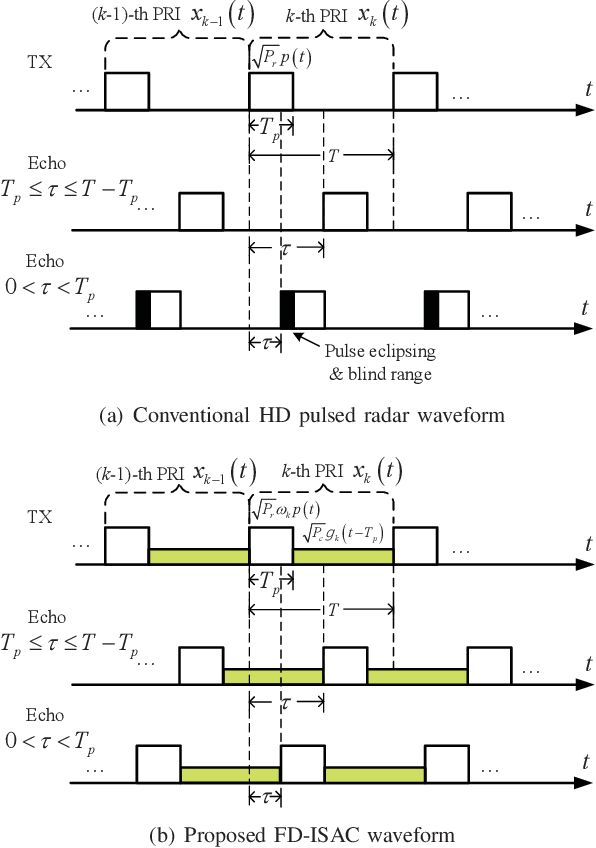
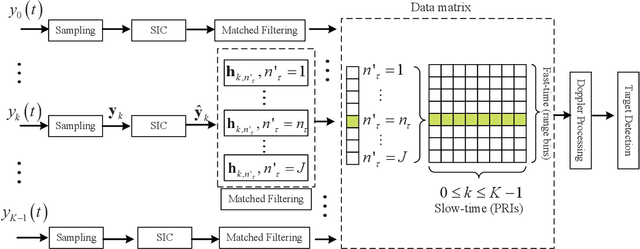
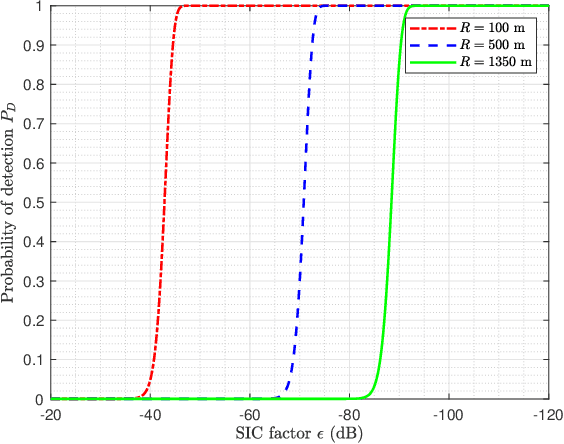
Integrated sensing and communication (ISAC) is a promising technology to fully utilize the precious spectrum and hardware in wireless systems, which has attracted significant attentions recently. This paper studies ISAC for the important and challenging monostatic setup, where one single ISAC node wishes to simultaneously sense a radar target while communicating with a communication receiver. Different from most existing schemes that rely on either radar-centric half-duplex (HD) pulsed transmission with information embedding that suffers from extremely low communication rate, or communication-centric waveform that suffers from degraded sensing performance, we propose a novel full-duplex (FD) ISAC scheme that utilizes the waiting time of conventional pulsed radars to transmit dedicated communication signals. Compared to radar-centric pulsed waveform with information embedding, the proposed design can drastically increase the communication rate, and also mitigate the sensing eclipsing and near-target blind range issues, as long as the self-interference (SI) is effectively suppressed. On the other hand, compared to communication-centric ISAC waveform, the proposed design has better auto-correlation property as it preserves the classic radar waveform for sensing. Performance analysis is developed by taking into account the residual SI, in terms of the probability of detection and ambiguity function for sensing, as well as the spectrum efficiency for communication. Numerical results are provided to show the significant performance gain of our proposed design over benchmark schemes.
Synthetic Active Distribution System Generation via Unbalanced Graph Generative Adversarial Network
Aug 02, 2021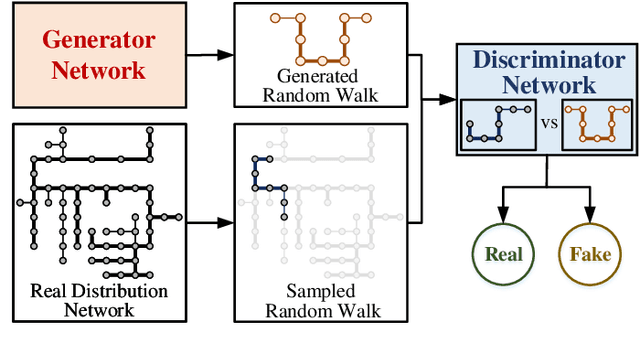
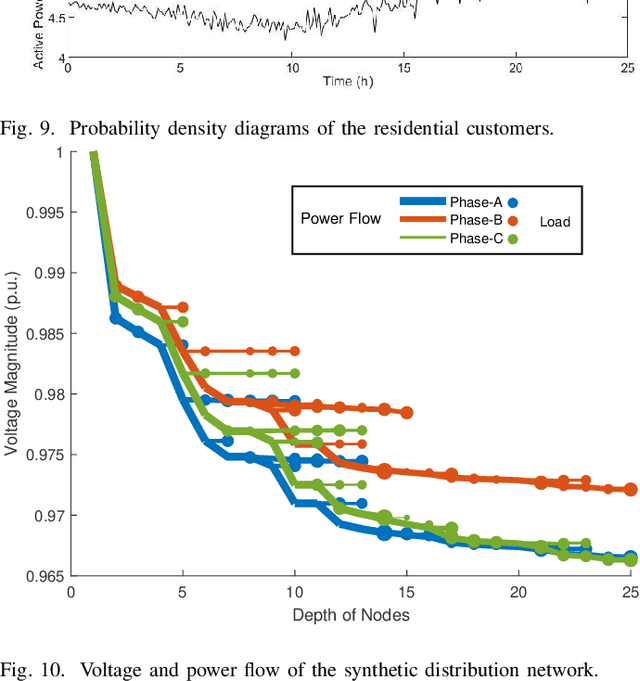
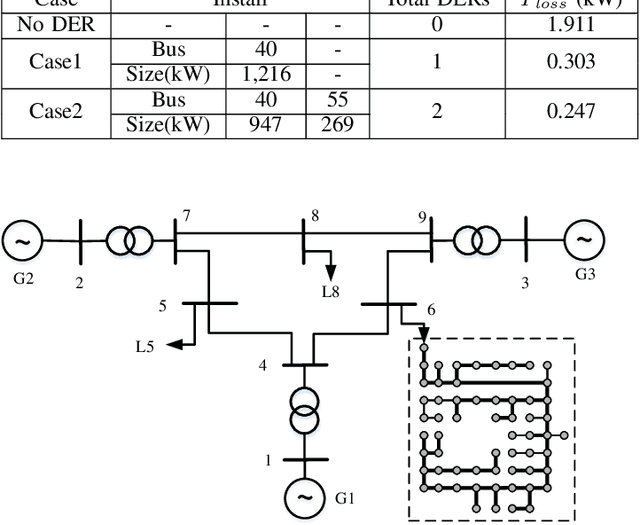
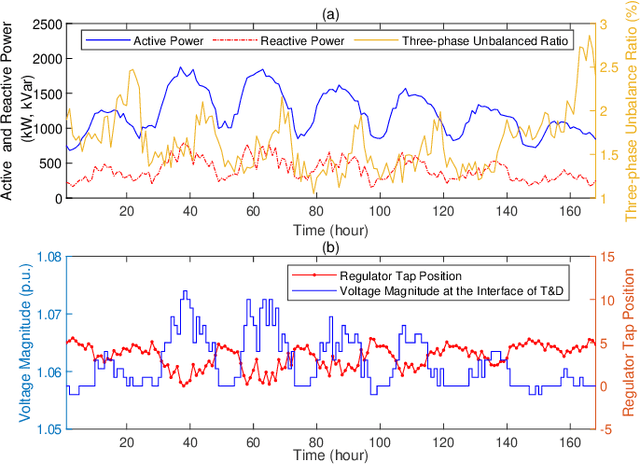
Real active distribution networks with associated smart meter (SM) data are critical for power researchers. However, it is practically difficult for researchers to obtain such comprehensive datasets from utilities due to privacy concerns. To bridge this gap, an implicit generative model with Wasserstein GAN objectives, namely unbalanced graph generative adversarial network (UG-GAN), is designed to generate synthetic three-phase unbalanced active distribution system connectivity. The basic idea is to learn the distribution of random walks both over a real-world system and across each phase of line segments, capturing the underlying local properties of an individual real-world distribution network and generating specific synthetic networks accordingly. Then, to create a comprehensive synthetic test case, a network correction and extension process is proposed to obtain time-series nodal demands and standard distribution grid components with realistic parameters, including distributed energy resources (DERs) and capacity banks. A Midwest distribution system with 1-year SM data has been utilized to validate the performance of our method. Case studies with several power applications demonstrate that synthetic active networks generated by the proposed framework can mimic almost all features of real-world networks while avoiding the disclosure of confidential information.