 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Angle Based Feature Learning in GNN for 3D Object Detection using Point Cloud
Aug 02, 2021
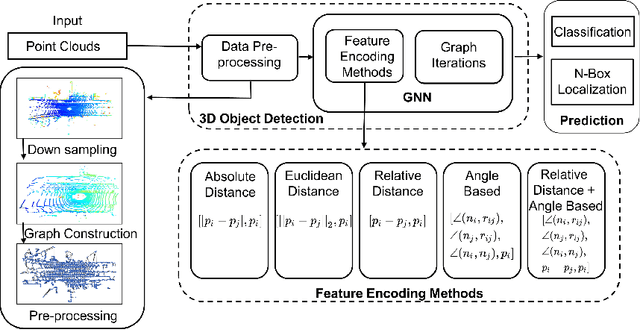
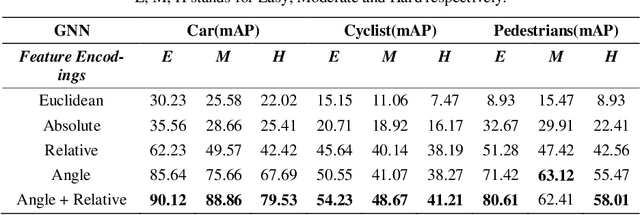
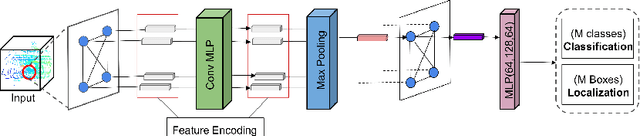
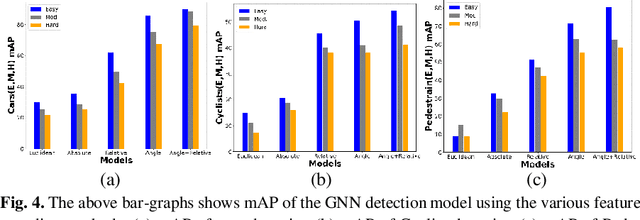
In this paper, we present new feature encoding methods for Detection of 3D objects in point clouds. We used a graph neural network (GNN) for Detection of 3D objects namely cars, pedestrians, and cyclists. Feature encoding is one of the important steps in Detection of 3D objects. The dataset used is point cloud data which is irregular and unstructured and it needs to be encoded in such a way that ensures better feature encapsulation. Earlier works have used relative distance as one of the methods to encode the features. These methods are not resistant to rotation variance problems in Graph Neural Networks. We have included angular-based measures while performing feature encoding in graph neural networks. Along with that, we have performed a comparison between other methods like Absolute, Relative, Euclidean distances, and a combination of the Angle and Relative methods. The model is trained and evaluated on the subset of the KITTI object detection benchmark dataset under resource constraints. Our results demonstrate that a combination of angle measures and relative distance has performed better than other methods. In comparison to the baseline method(relative), it achieved better performance. We also performed time analysis of various feature encoding methods.
ReCoNet: Real-time Coherent Video Style Transfer Network
Nov 01, 2018
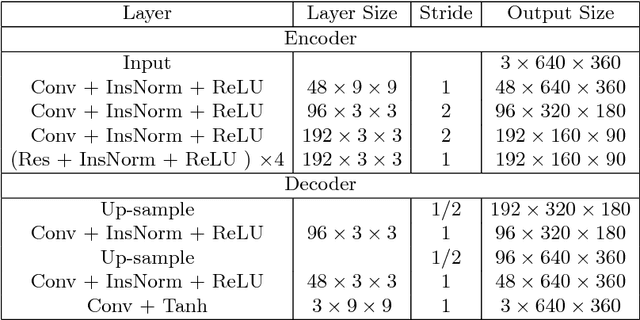
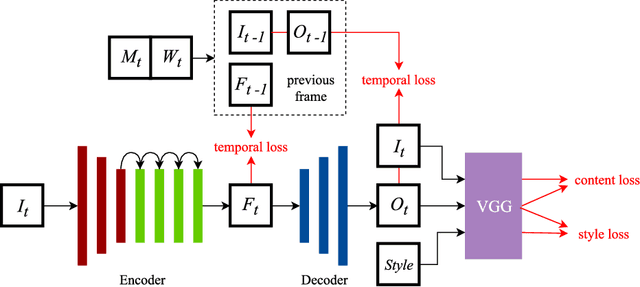

Image style transfer models based on convolutional neural networks usually suffer from high temporal inconsistency when applied to videos. Some video style transfer models have been proposed to improve temporal consistency, yet they fail to guarantee fast processing speed, nice perceptual style quality and high temporal consistency at the same time. In this paper, we propose a novel real-time video style transfer model, ReCoNet, which can generate temporally coherent style transfer videos while maintaining favorable perceptual styles. A novel luminance warping constraint is added to the temporal loss at the output level to capture luminance changes between consecutive frames and increase stylization stability under illumination effects. We also propose a novel feature-map-level temporal loss to further enhance temporal consistency on traceable objects. Experimental results indicate that our model exhibits outstanding performance both qualitatively and quantitatively.
Continuous-variable neural-network quantum states and the quantum rotor model
Jul 15, 2021
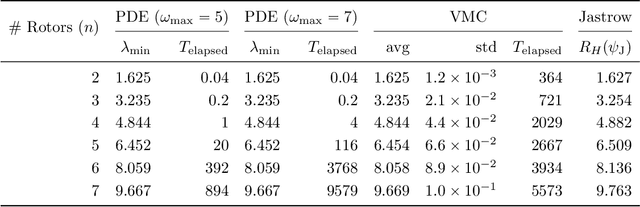
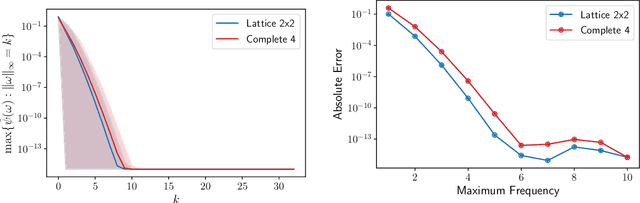
We initiate the study of neural-network quantum state algorithms for analyzing continuous-variable lattice quantum systems in first quantization. A simple family of continuous-variable trial wavefunctons is introduced which naturally generalizes the restricted Boltzmann machine (RBM) wavefunction introduced for analyzing quantum spin systems. By virtue of its simplicity, the same variational Monte Carlo training algorithms that have been developed for ground state determination and time evolution of spin systems have natural analogues in the continuum. We offer a proof of principle demonstration in the context of ground state determination of a stoquastic quantum rotor Hamiltonian. Results are compared against those obtained from partial differential equation (PDE) based scalable eigensolvers. This study serves as a benchmark against which future investigation of continuous-variable neural quantum states can be compared, and points to the need to consider deep network architectures and more sophisticated training algorithms.
Parallel Quasi-concave set optimization: A new frontier that scales without needing submodularity
Aug 19, 2021
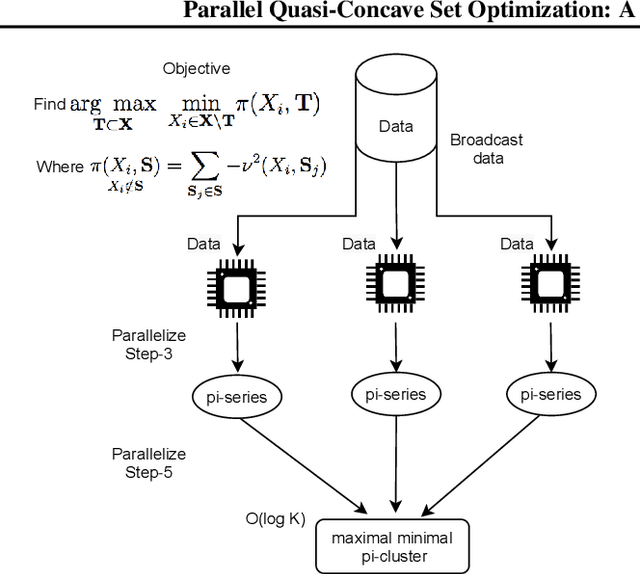
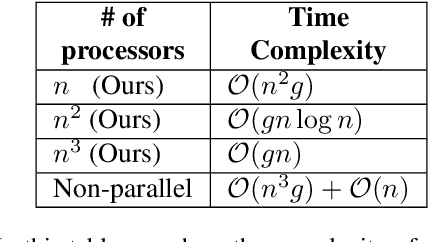
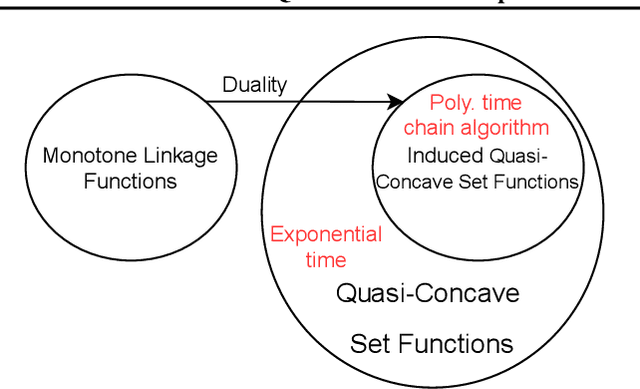
Classes of set functions along with a choice of ground set are a bedrock to determine and develop corresponding variants of greedy algorithms to obtain efficient solutions for combinatorial optimization problems. The class of approximate constrained submodular optimization has seen huge advances at the intersection of good computational efficiency, versatility and approximation guarantees while exact solutions for unconstrained submodular optimization are NP-hard. What is an alternative to situations when submodularity does not hold? Can efficient and globally exact solutions be obtained? We introduce one such new frontier: The class of quasi-concave set functions induced as a dual class to monotone linkage functions. We provide a parallel algorithm with a time complexity over $n$ processors of $\mathcal{O}(n^2g) +\mathcal{O}(\log{\log{n}})$ where $n$ is the cardinality of the ground set and $g$ is the complexity to compute the monotone linkage function that induces a corresponding quasi-concave set function via a duality. The complexity reduces to $\mathcal{O}(gn\log(n))$ on $n^2$ processors and to $\mathcal{O}(gn)$ on $n^3$ processors. Our algorithm provides a globally optimal solution to a maxi-min problem as opposed to submodular optimization which is approximate. We show a potential for widespread applications via an example of diverse feature subset selection with exact global maxi-min guarantees upon showing that a statistical dependency measure called distance correlation can be used to induce a quasi-concave set function.
Learning Sparse Interaction Graphs of Partially Observed Pedestrians for Trajectory Prediction
Jul 19, 2021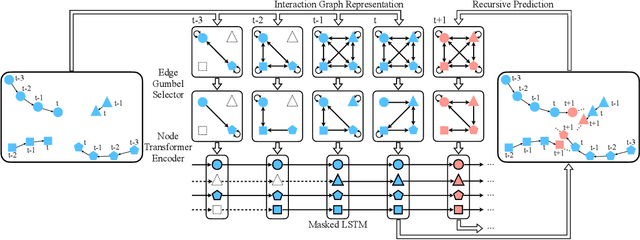
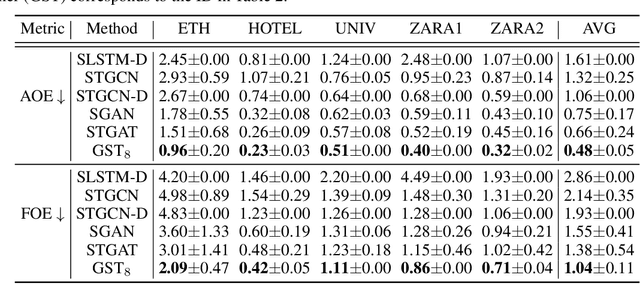
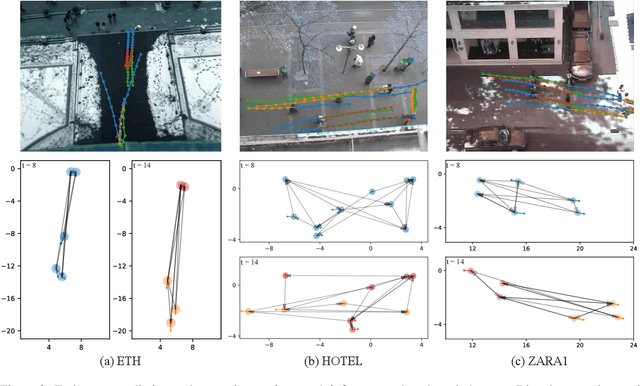
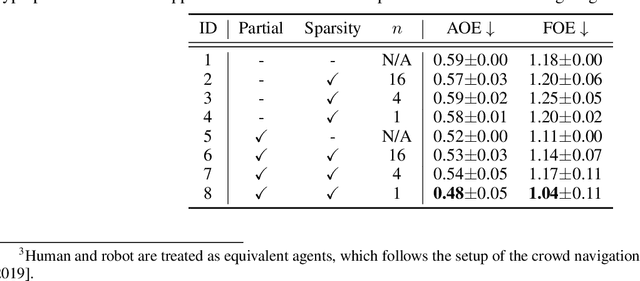
Multi-pedestrian trajectory prediction is an indispensable safety element of autonomous systems that interact with crowds in unstructured environments. Many recent efforts have developed trajectory prediction algorithms with focus on understanding social norms behind pedestrian motions. Yet we observe these works usually hold two assumptions that prevent them from being smoothly applied to robot applications: positions of all pedestrians are consistently tracked; the target agent pays attention to all pedestrians in the scene. The first assumption leads to biased interaction modeling with incomplete pedestrian data, and the second assumption introduces unnecessary disturbances and leads to the freezing robot problem. Thus, we propose Gumbel Social Transformer, in which an Edge Gumbel Selector samples a sparse interaction graph of partially observed pedestrians at each time step. A Node Transformer Encoder and a Masked LSTM encode the pedestrian features with the sampled sparse graphs to predict trajectories. We demonstrate that our model overcomes the potential problems caused by the assumptions, and our approach outperforms the related works in benchmark evaluation.
SymbolicGPT: A Generative Transformer Model for Symbolic Regression
Jun 27, 2021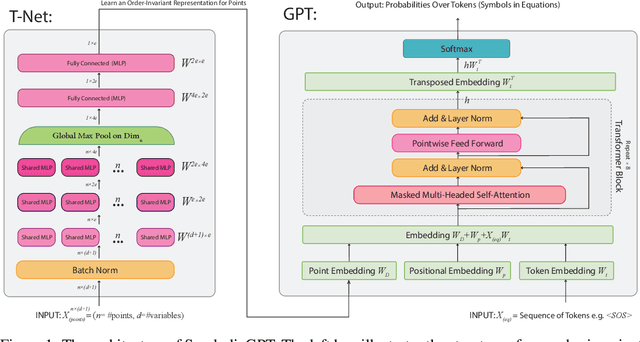



Symbolic regression is the task of identifying a mathematical expression that best fits a provided dataset of input and output values. Due to the richness of the space of mathematical expressions, symbolic regression is generally a challenging problem. While conventional approaches based on genetic evolution algorithms have been used for decades, deep learning-based methods are relatively new and an active research area. In this work, we present SymbolicGPT, a novel transformer-based language model for symbolic regression. This model exploits the advantages of probabilistic language models like GPT, including strength in performance and flexibility. Through comprehensive experiments, we show that our model performs strongly compared to competing models with respect to the accuracy, running time, and data efficiency.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021
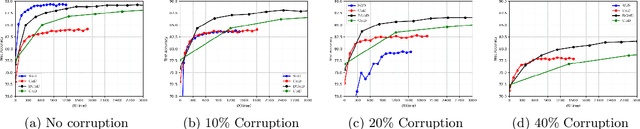
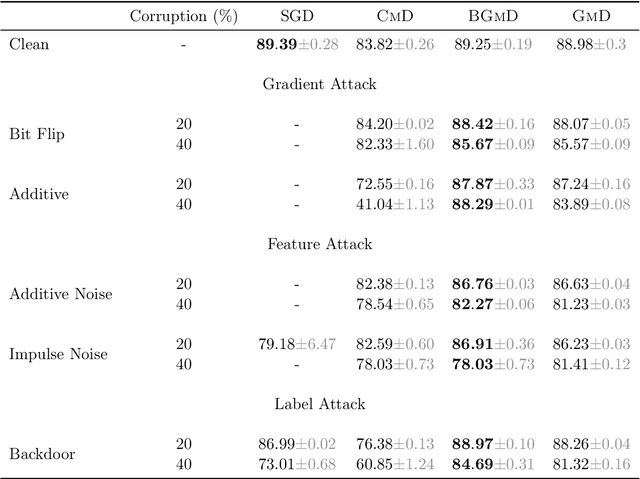
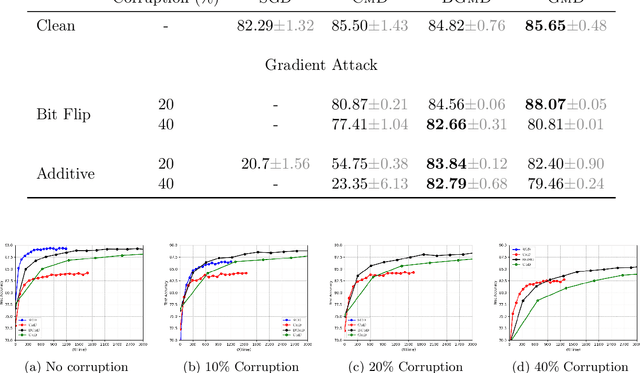
Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.
Vision-Based Target Localization for a Flapping-Wing Aerial Vehicle
Jul 15, 2021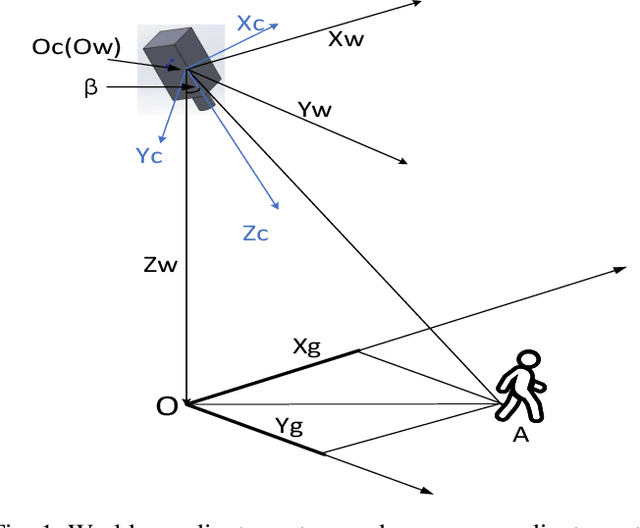
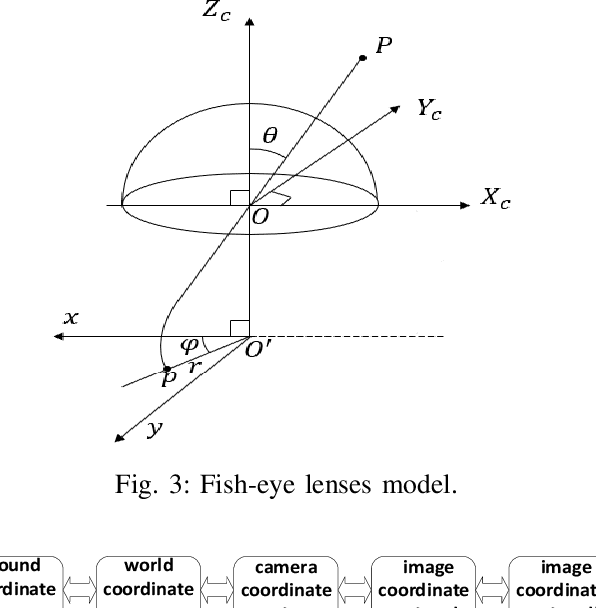

The flapping-wing aerial vehicle (FWAV) is a new type of flying robot that mimics the flight mode of birds and insects. However, FWAVs have their special characteristics of less load capacity and short endurance time, so that most existing systems of ground target localization are not suitable for them. In this paper, a vision-based target localization algorithm is proposed for FWAVs based on a generic camera model. Since sensors exist measurement error and the camera exists jitter and motion blur during flight, Gaussian noises are introduced in the simulation experiment, and then a first-order low-pass filter is used to stabilize the localization values. Moreover, in order to verify the feasibility and accuracy of the target localization algorithm, we design a set of simulation experiments where various noises are added. From the simulation results, it is found that the target localization algorithm has a good performance.
FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion
Apr 14, 2021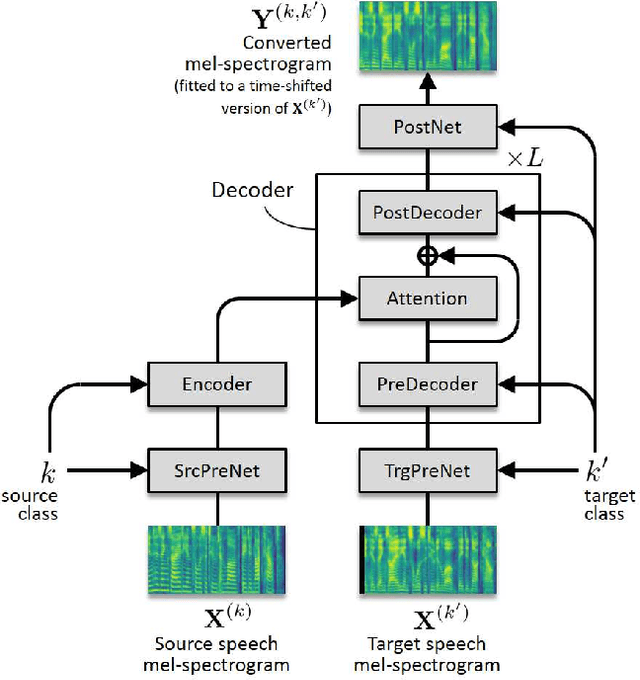
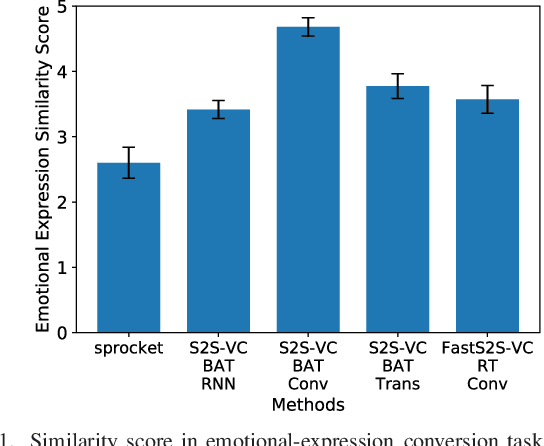
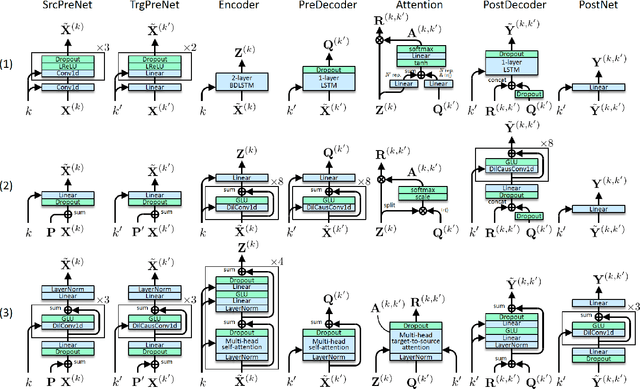
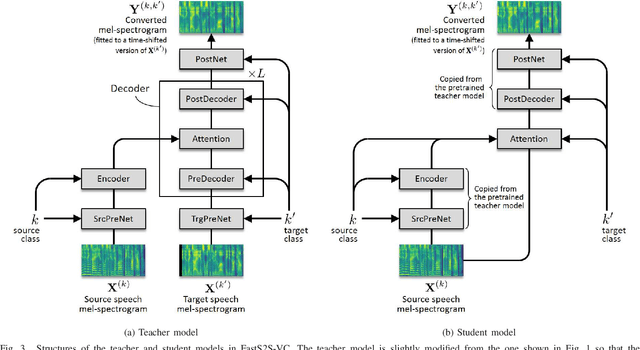
This paper proposes a non-autoregressive extension of our previously proposed sequence-to-sequence (S2S) model-based voice conversion (VC) methods. S2S model-based VC methods have attracted particular attention in recent years for their flexibility in converting not only the voice identity but also the pitch contour and local duration of input speech, thanks to the ability of the encoder-decoder architecture with the attention mechanism. However, one of the obstacles to making these methods work in real-time is the autoregressive (AR) structure. To overcome this obstacle, we develop a method to obtain a model that is free from an AR structure and behaves similarly to the original S2S models, based on a teacher-student learning framework. In our method, called "FastS2S-VC", the student model consists of encoder, decoder, and attention predictor. The attention predictor learns to predict attention distributions solely from source speech along with a target class index with the guidance of those predicted by the teacher model from both source and target speech. Thanks to this structure, the model is freed from an AR structure and allows for parallelization. Furthermore, we show that FastS2S-VC is suitable for real-time implementation based on a sliding-window approach, and describe how to make it run in real-time. Through speaker-identity and emotional-expression conversion experiments, we confirmed that FastS2S-VC was able to speed up the conversion process by 70 to 100 times compared to the original AR-type S2S-VC methods, without significantly degrading the audio quality and similarity to target speech. We also confirmed that the real-time version of FastS2S-VC can be run with a latency of 32 ms when run on a GPU.
Towards Unsupervised Fine-Tuning for Edge Video Analytics
Apr 14, 2021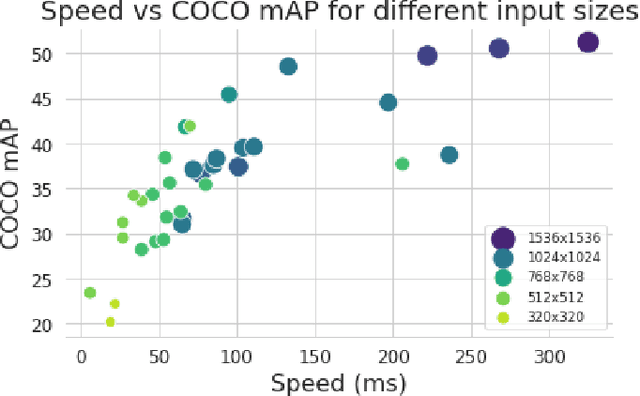
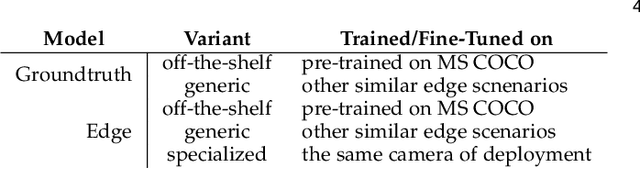
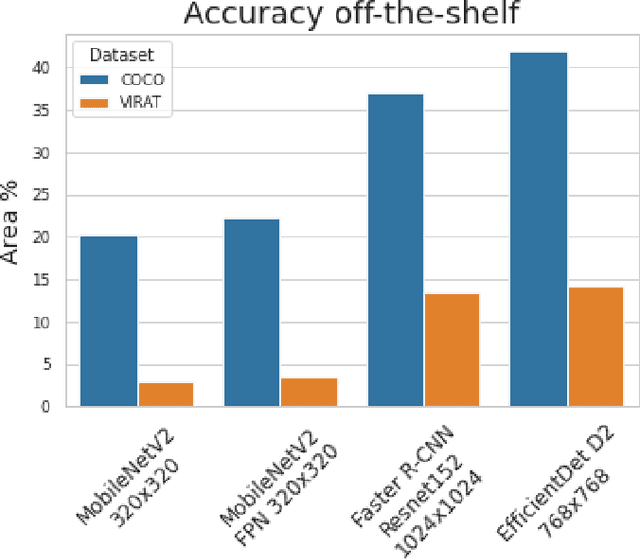
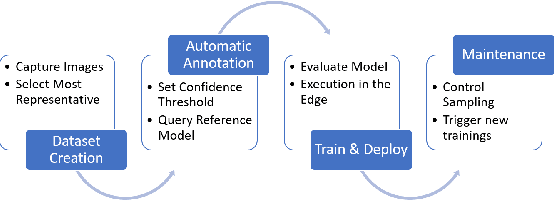
Judging by popular and generic computer vision challenges, such as the ImageNet or PASCAL VOC, neural networks have proven to be exceptionally accurate in recognition tasks. However, state-of-the-art accuracy often comes at a high computational price, requiring equally state-of-the-art and high-end hardware acceleration to achieve anything near real-time performance. At the same time, use cases such as smart cities or autonomous vehicles require an automated analysis of images from fixed cameras in real-time. Due to the huge and constant amount of network bandwidth these streams would generate, we cannot rely on offloading compute to the omnipresent and omnipotent cloud. Therefore, a distributed Edge Cloud must be in charge to process images locally. However, the Edge Cloud is, by nature, resource-constrained, which puts a limit on the computational complexity of the models executed in the edge. Nonetheless, there is a need for a meeting point between the Edge Cloud and accurate real-time video analytics. In this paper, we propose a method for improving accuracy of edge models without any extra compute cost by means of automatic model specialization. First, we show how the sole assumption of static cameras allows us to make a series of considerations that greatly simplify the scope of the problem. Then, we present Edge AutoTuner, a framework that implements and brings these considerations together to automate the end-to-end fine-tuning of models. Finally, we show that complex neural networks - able to generalize better - can be effectively used as teachers to annotate datasets for the fine-tuning of lightweight neural networks and tailor them to the specific edge context, which boosts accuracy at constant computational cost, and do so without any human interaction. Results show that our method can automatically improve accuracy of pre-trained models by an average of 21%.