 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GNN4IP: Graph Neural Network for Hardware Intellectual Property Piracy Detection
Jul 19, 2021
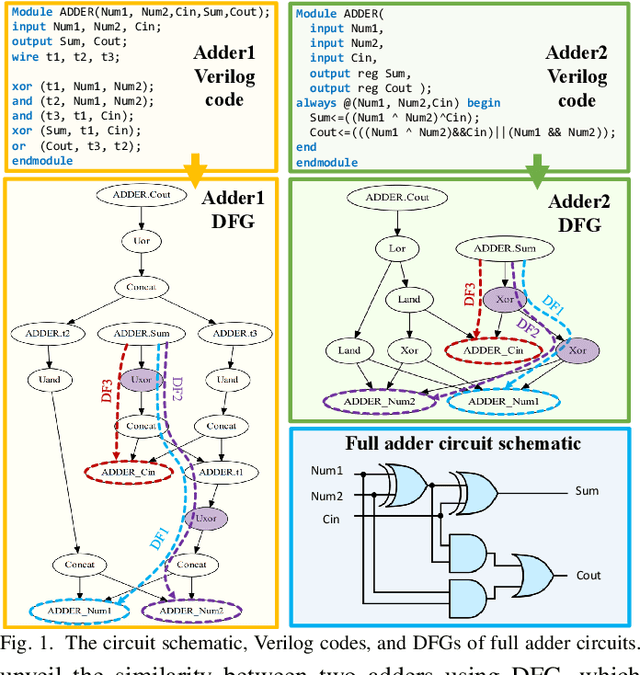
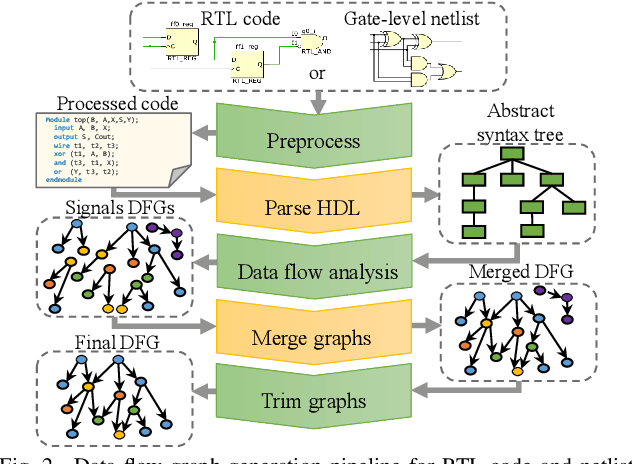
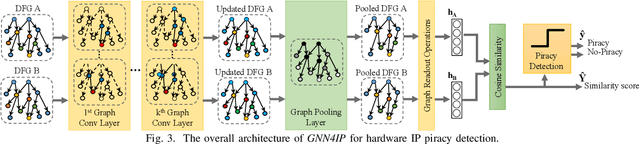
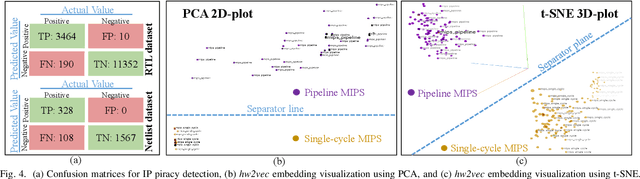
Aggressive time-to-market constraints and enormous hardware design and fabrication costs have pushed the semiconductor industry toward hardware Intellectual Properties (IP) core design. However, the globalization of the integrated circuits (IC) supply chain exposes IP providers to theft and illegal redistribution of IPs. Watermarking and fingerprinting are proposed to detect IP piracy. Nevertheless, they come with additional hardware overhead and cannot guarantee IP security as advanced attacks are reported to remove the watermark, forge, or bypass it. In this work, we propose a novel methodology, GNN4IP, to assess similarities between circuits and detect IP piracy. We model the hardware design as a graph and construct a graph neural network model to learn its behavior using the comprehensive dataset of register transfer level codes and gate-level netlists that we have gathered. GNN4IP detects IP piracy with 96% accuracy in our dataset and recognizes the original IP in its obfuscated version with 100% accuracy.
Aligning Across Large Gaps in Time
Mar 22, 2018



We present a method of temporally-invariant image registration for outdoor scenes, with invariance across time of day, across seasonal variations, and across decade-long periods, for low- and high-texture scenes. Our method can be useful for applications in remote sensing, GPS-denied UAV localization, 3D reconstruction, and many others. Our method leverages a recently proposed approach to image registration, where fully-convolutional neural networks are used to create feature maps which can be registered using the Inverse-Composition Lucas-Kanade algorithm (ICLK). We show that invariance that is learned from satellite imagery can be transferable to time-lapse data captured by webcams mounted on buildings near ground-level.
Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls
Aug 25, 2021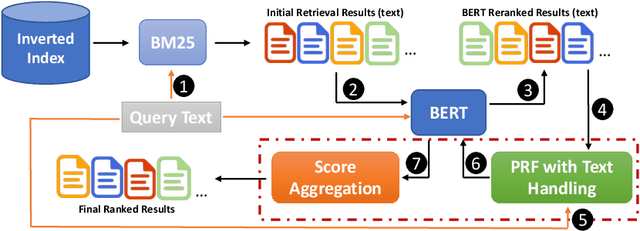
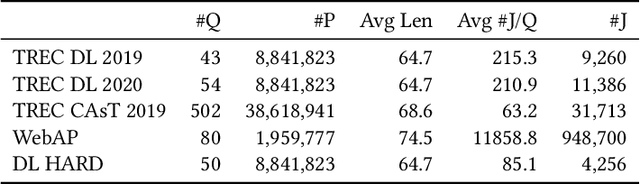
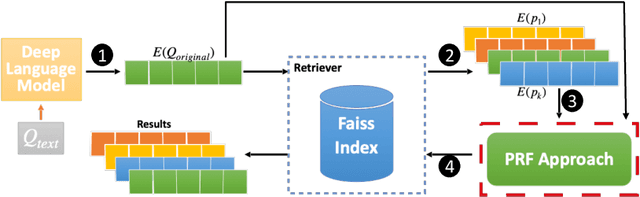
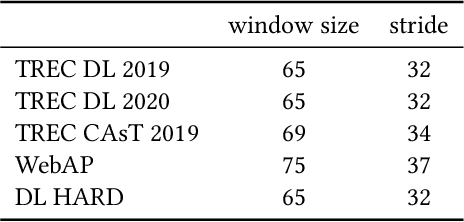
Pseudo Relevance Feedback (PRF) is known to improve the effectiveness of bag-of-words retrievers. At the same time, deep language models have been shown to outperform traditional bag-of-words rerankers. However, it is unclear how to integrate PRF directly with emergent deep language models. In this article, we address this gap by investigating methods for integrating PRF signals into rerankers and dense retrievers based on deep language models. We consider text-based and vector-based PRF approaches, and investigate different ways of combining and scoring relevance signals. An extensive empirical evaluation was conducted across four different datasets and two task settings (retrieval and ranking). Text-based PRF results show that the use of PRF had a mixed effect on deep rerankers across different datasets. We found that the best effectiveness was achieved when (i) directly concatenating each PRF passage with the query, searching with the new set of queries, and then aggregating the scores; (ii) using Borda to aggregate scores from PRF runs. Vector-based PRF results show that the use of PRF enhanced the effectiveness of deep rerankers and dense retrievers over several evaluation metrics. We found that higher effectiveness was achieved when (i) the query retains either the majority or the same weight within the PRF mechanism, and (ii) a shallower PRF signal (i.e., a smaller number of top-ranked passages) was employed, rather than a deeper signal. Our vector-based PRF method is computationally efficient; thus this represents a general PRF method others can use with deep rerankers and dense retrievers.
Latency-Constrained Highly-Reliable mmWave Communication via Multi-point Connectivity
Aug 20, 2021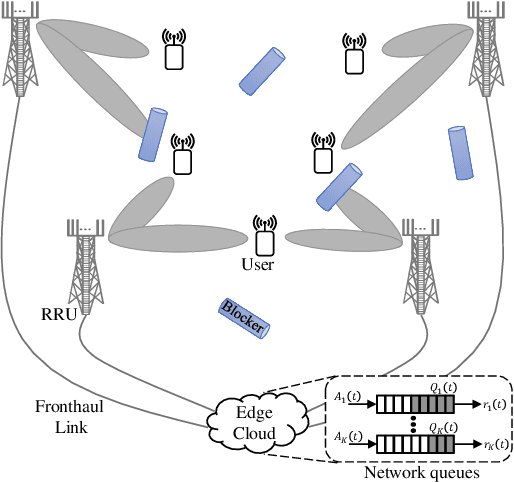
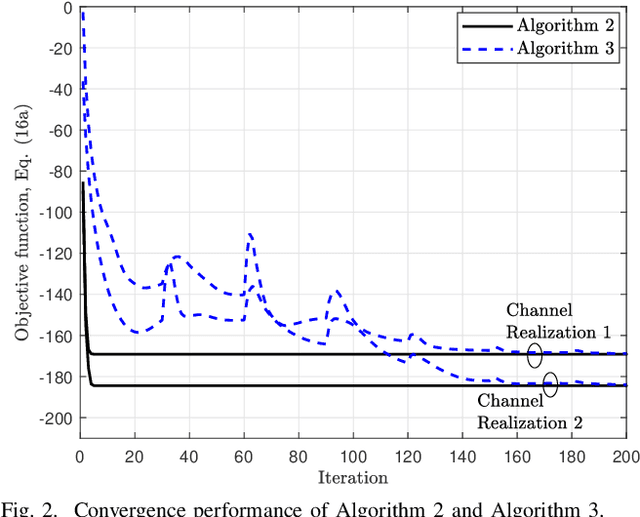
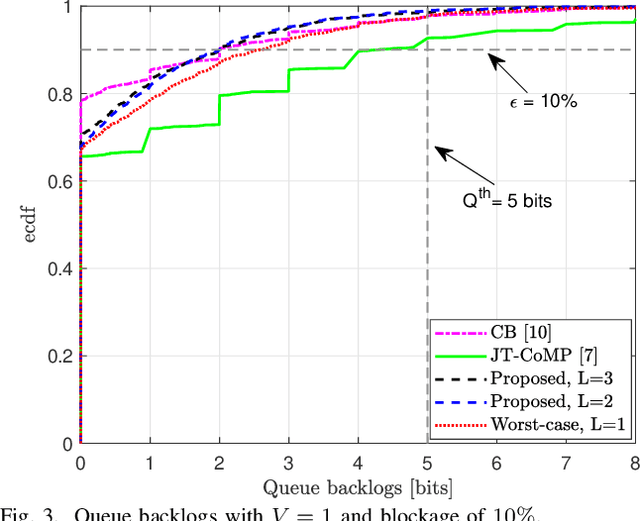
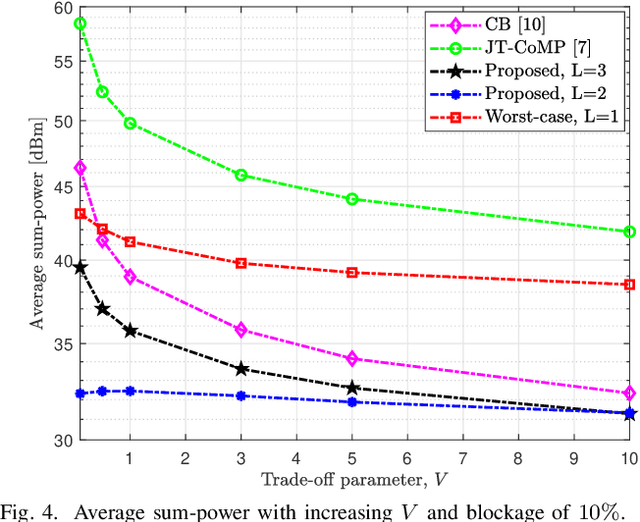
The sensitivity of millimeter-wave (mmWave) radio channel to blockage is a fundamental challenge in achieving low-latency and ultra-reliable connectivity. In this paper, we explore the viability of using coordinated multi-point (CoMP) transmission for a delay bounded and reliable mmWave communication. We propose a novel blockage-aware algorithm for the sum-power minimization problem under the user-specific latency requirements in a dynamic mobile access network. We use the Lyapunov optimization framework, and provide a dynamic control algorithm, which efficiently transforms a time-average stochastic problem into a sequence of deterministic subproblems. A robust beamformer design is then proposed by exploiting the queue backlogs and channel information, that efficiently allocates the required radio and cooperation resources, and proactively leverages the multi-antenna spatial diversity according to the instantaneous needs of the users. Further, to adapt to the uncertainties of the mmWave channel, we consider a pessimistic estimate of the rates over link blockage combinations and an adaptive selection of the CoMP serving set from the available remote radio units (RRUs). Moreover, after the relaxation of coupled and non-convex constraints via the Fractional Program (FP) techniques, a low-complexity closed-form iterative algorithm is provided by solving a system of Karush-Kuhn-Tucker (KKT) optimality conditions. The simulation results manifest that, in the presence of random blockages, the proposed methods outperform the baseline scenarios and provide power-efficient, high-reliable, and low-latency mmWave communication.
Forecaster: A Graph Transformer for Forecasting Spatial and Time-Dependent Data
Sep 12, 2019
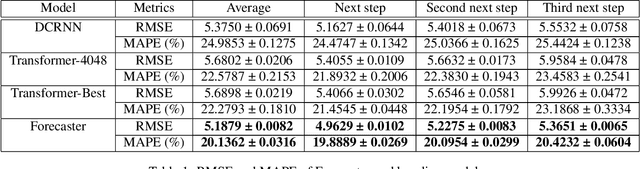
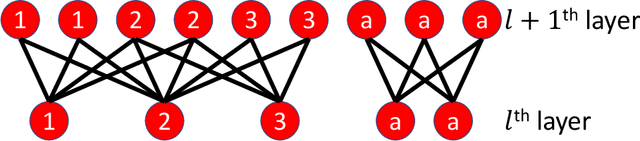
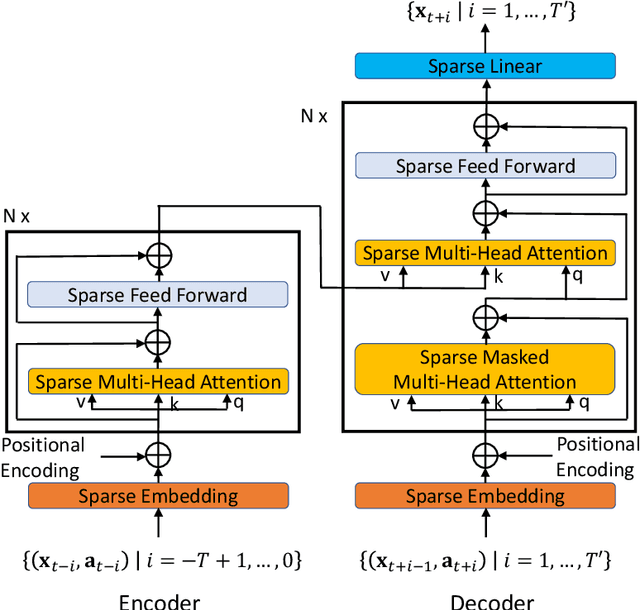
Spatial and time-dependent data is of interest in many applications. This task is difficult due to its complex spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. To address these challenges, we propose Forecaster, a graph Transformer architecture. Specifically, we start by learning the structure of the graph that parsimoniously represents the spatial dependency between the data at different locations. Based on the topology of the graph, we sparsify the Transformer to account for the strength of spatial dependency, long-range temporal dependency, data non-stationarity, and data heterogeneity. We evaluate Forecaster in the problem of forecasting taxi ride-hailing demand and show that our proposed architecture significantly outperforms the state-of-the-art baselines.
Virtual Reality based Digital Twin System for remote laboratories and online practical learning
Jun 17, 2021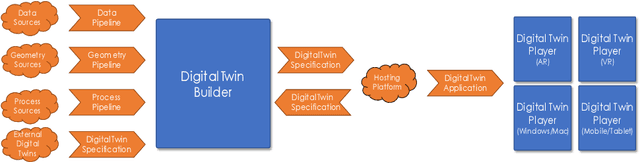

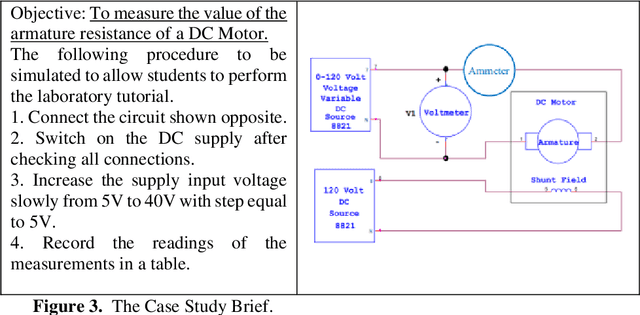
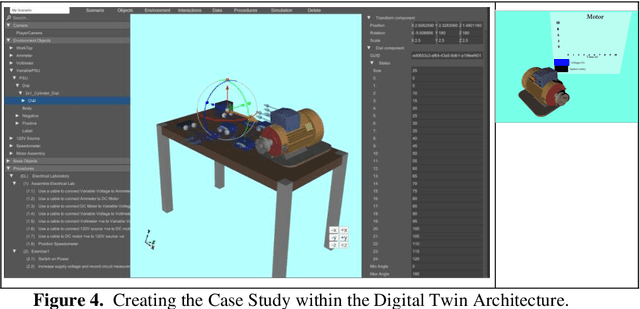
There is a need for remote learning and virtual learning applications such as virtual reality (VR) and tablet-based solutions which the current pandemic has demonstrated. Creating complex learning scenarios by developers is highly time-consuming and can take over a year. There is a need to provide a simple method to enable lecturers to create their own content for their laboratory tutorials. Research is currently being undertaken into developing generic models to enable the semi-automatic creation of a virtual learning application. A case study describing the creation of a virtual learning application for an electrical laboratory tutorial is presented.
OUTCOMES: Rapid Under-sampling Optimization achieves up to 50% improvements in reconstruction accuracy for multi-contrast MRI sequences
Mar 08, 2021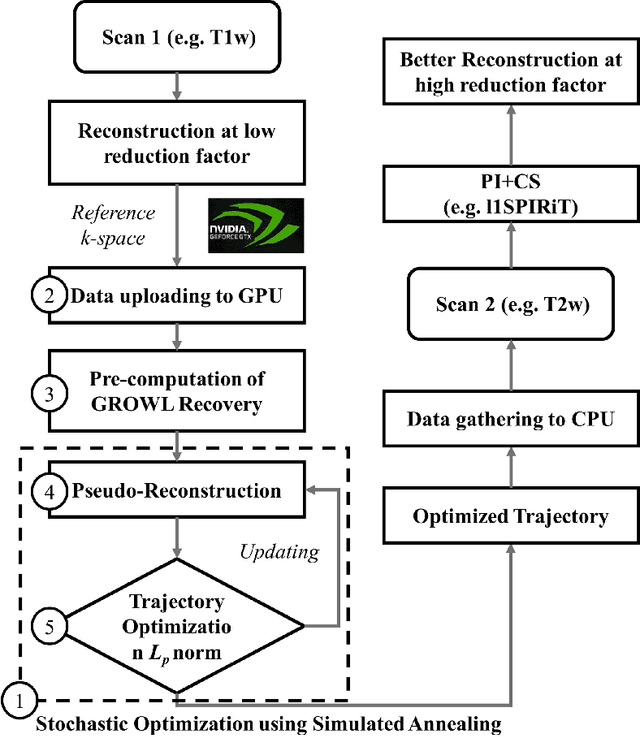

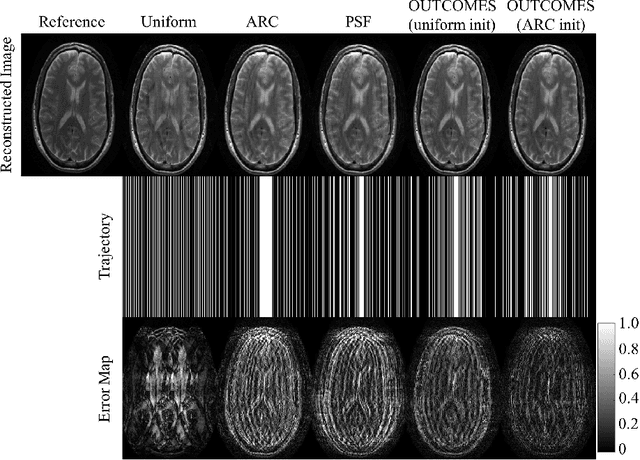
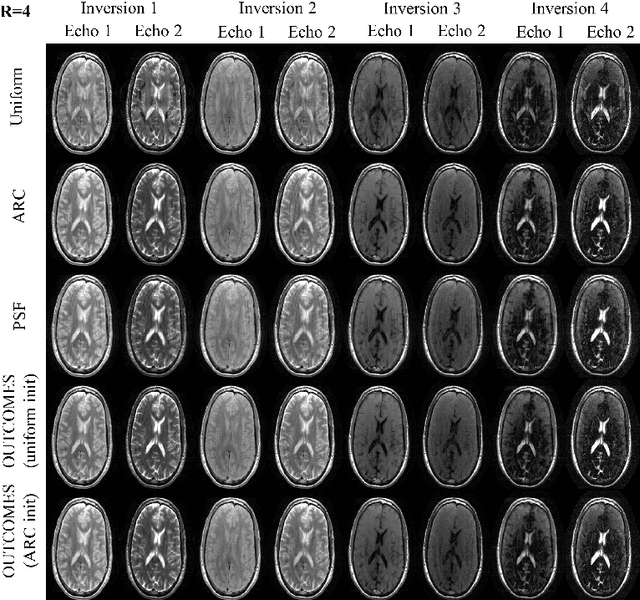
Multi-contrast Magnetic Resonance Imaging (MRI) acquisitions from a single scan have tremendous potential to streamline exams and reduce imaging time. However, maintaining clinically feasible scan time necessitates significant undersampling, pushing the limits on compressed sensing and other low-dimensional techniques. During MRI scanning, one of the possible solutions is by using undersampling designs which can effectively improve the acquisition and achieve higher reconstruction accuracy. However, existing undersampling optimization methods are time-consuming and the limited performance prevents their clinical applications. In this paper, we proposed an improved undersampling trajectory optimization scheme to generate an optimized trajectory within seconds and apply it to subsequent multi-contrast MRI datasets on a per-subject basis, where we named it OUTCOMES. By using a data-driven method combined with improved algorithm design, GPU acceleration, and more efficient computation, the proposed method can optimize a trajectory within 5-10 seconds and achieve 30%-50% reconstruction improvement with the same acquisition cost, which makes real-time under-sampling optimization possible for clinical applications.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 09, 2021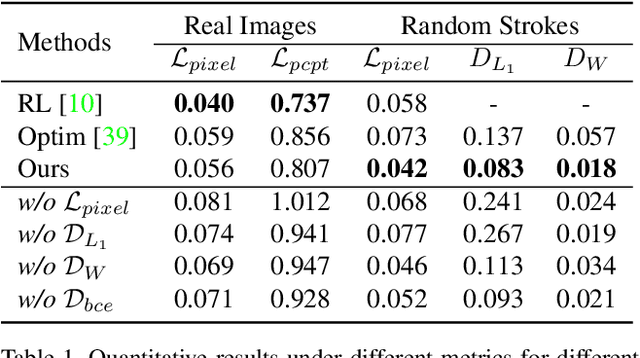
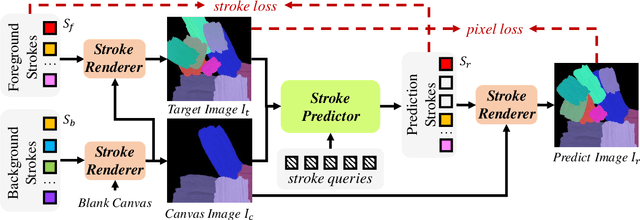
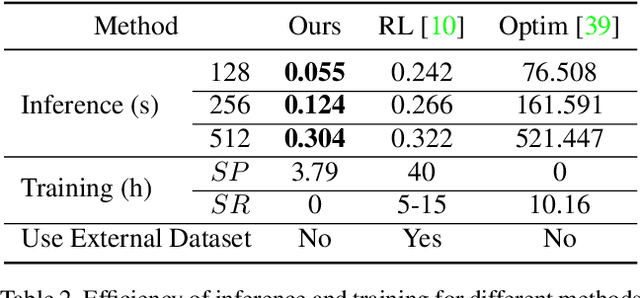
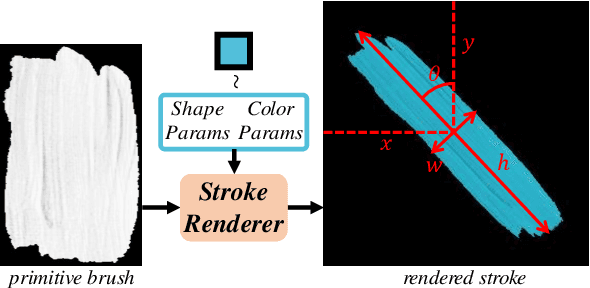
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
Aerial-PASS: Panoramic Annular Scene Segmentation in Drone Videos
May 15, 2021
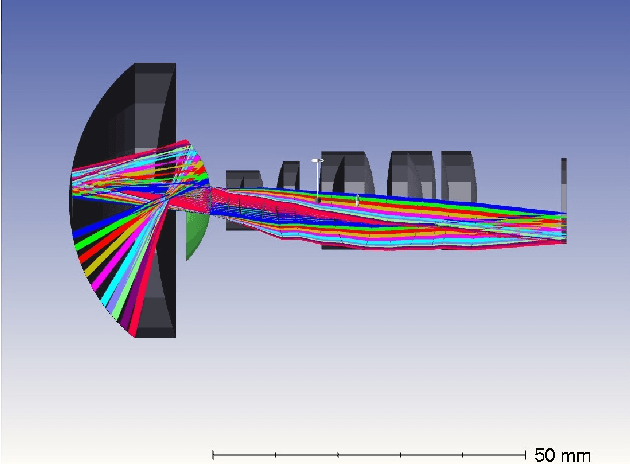
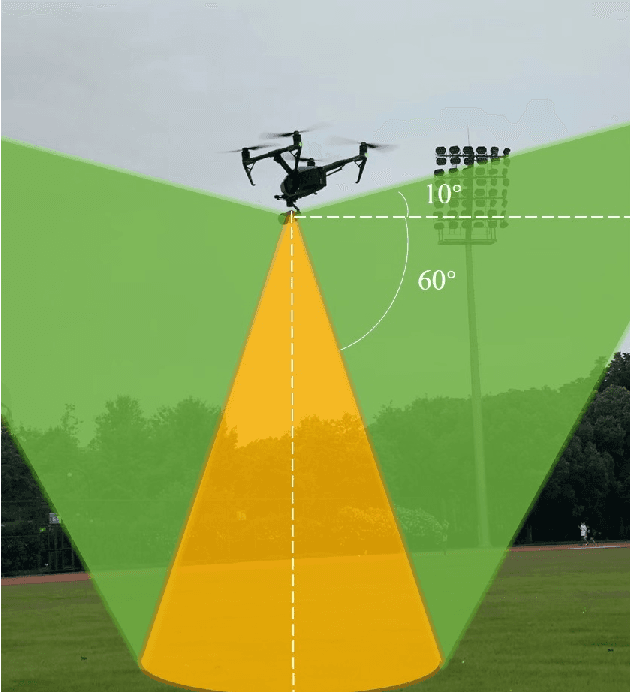
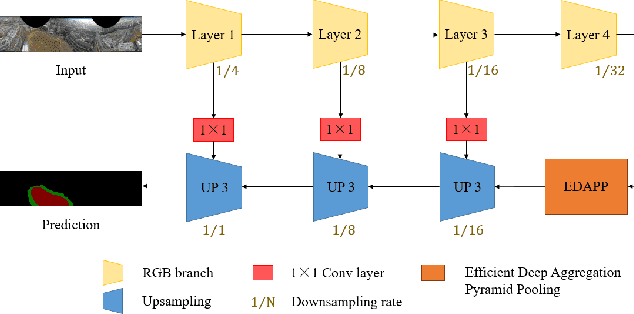
Aerial pixel-wise scene perception of the surrounding environment is an important task for UAVs (Unmanned Aerial Vehicles). Previous research works mainly adopt conventional pinhole cameras or fisheye cameras as the imaging device. However, these imaging systems cannot achieve large Field of View (FoV), small size, and lightweight at the same time. To this end, we design a UAV system with a Panoramic Annular Lens (PAL), which has the characteristics of small size, low weight, and a 360-degree annular FoV. A lightweight panoramic annular semantic segmentation neural network model is designed to achieve high-accuracy and real-time scene parsing. In addition, we present the first drone-perspective panoramic scene segmentation dataset Aerial-PASS, with annotated labels of track, field, and others. A comprehensive variety of experiments shows that the designed system performs satisfactorily in aerial panoramic scene parsing. In particular, our proposed model strikes an excellent trade-off between segmentation performance and inference speed suitable, validated on both public street-scene and our established aerial-scene datasets.
Context-Conditional Adaptation for Recognizing Unseen Classes in Unseen Domains
Jul 15, 2021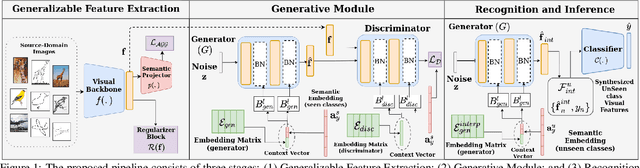
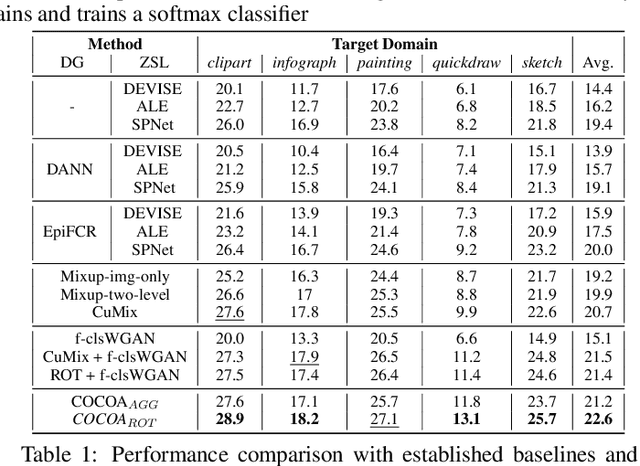
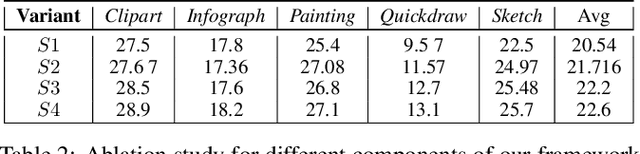
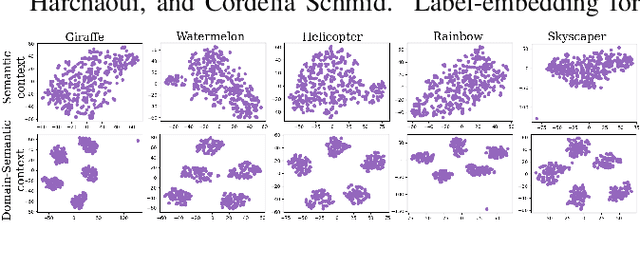
Recent progress towards designing models that can generalize to unseen domains (i.e domain generalization) or unseen classes (i.e zero-shot learning) has embarked interest towards building models that can tackle both domain-shift and semantic shift simultaneously (i.e zero-shot domain generalization). For models to generalize to unseen classes in unseen domains, it is crucial to learn feature representation that preserves class-level (domain-invariant) as well as domain-specific information. Motivated from the success of generative zero-shot approaches, we propose a feature generative framework integrated with a COntext COnditional Adaptive (COCOA) Batch-Normalization to seamlessly integrate class-level semantic and domain-specific information. The generated visual features better capture the underlying data distribution enabling us to generalize to unseen classes and domains at test-time. We thoroughly evaluate and analyse our approach on established large-scale benchmark - DomainNet and demonstrate promising performance over baselines and state-of-art methods.