 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018
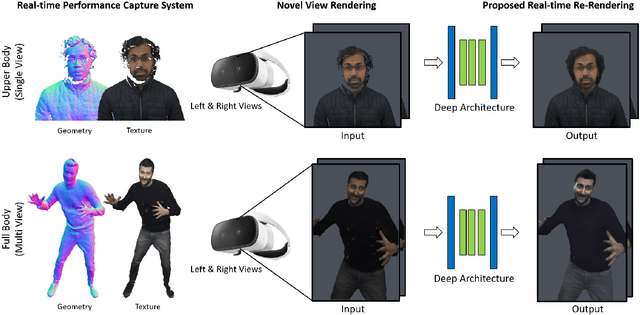



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
Sleep syndromes onset detection based on automatic sleep staging algorithm
Jul 07, 2021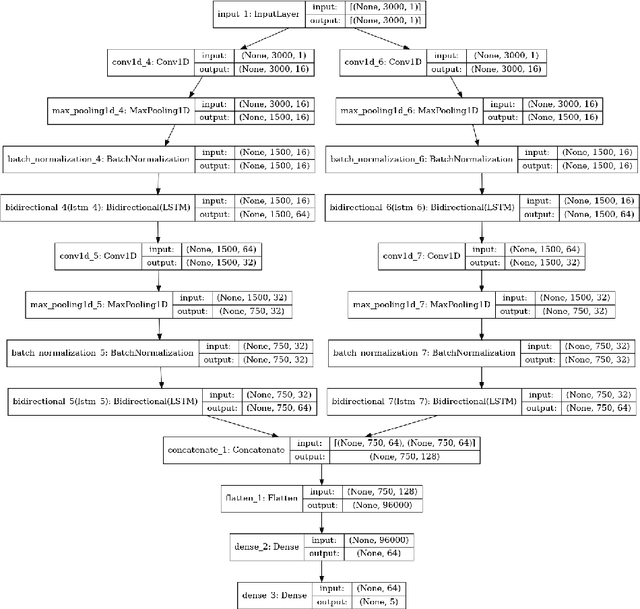
In this paper, we propose a novel method and a practical approach to predicting early onsets of sleep syndromes, including restless leg syndrome, insomnia, based on an algorithm that is comprised of two modules. A Fast Fourier Transform is applied to 30 seconds long epochs of EEG recordings to provide localized time-frequency information, and a deep convolutional LSTM neural network is trained for sleep stage classification. Automating sleep stages detection from EEG data offers great potential to tackling sleep irregularities on a daily basis. Thereby, a novel approach for sleep stage classification is proposed which combines the best of signal processing and statistics. In this study, we used the PhysioNet Sleep European Data Format (EDF) Database. The code evaluation showed impressive results, reaching an accuracy of 86.43, precision of 77.76, recall of 93,32, F1-score of 89.12 with the final mean false error loss of 0.09.
A generalized forecasting solution to enable future insights of COVID-19 at sub-national level resolutions
Aug 21, 2021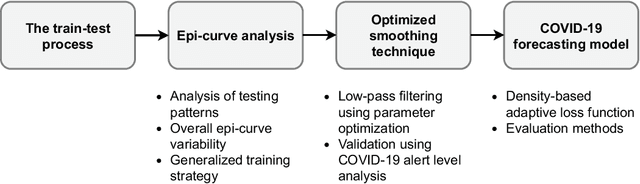
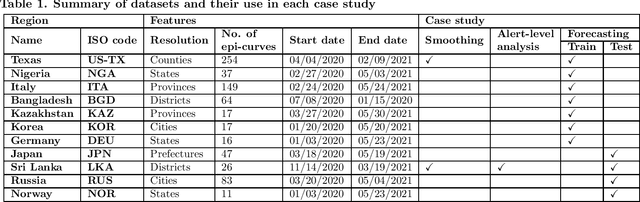
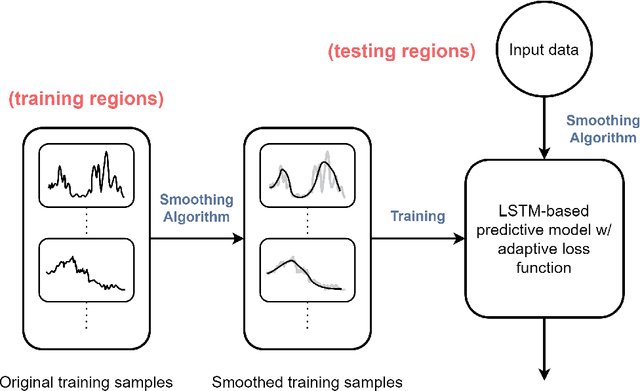
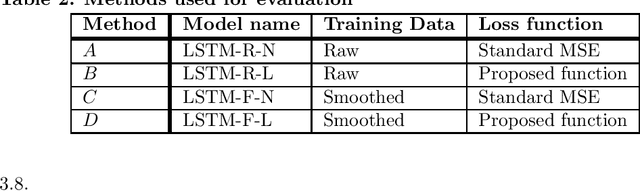
COVID-19 continues to cause a significant impact on public health. To minimize this impact, policy makers undertake containment measures that however, when carried out disproportionately to the actual threat, as a result if errorneous threat assessment, cause undesirable long-term socio-economic complications. In addition, macro-level or national level decision making fails to consider the localized sensitivities in small regions. Hence, the need arises for region-wise threat assessments that provide insights on the behaviour of COVID-19 through time, enabled through accurate forecasts. In this study, a forecasting solution is proposed, to predict daily new cases of COVID-19 in regions small enough where containment measures could be locally implemented, by targeting three main shortcomings that exist in literature; the unreliability of existing data caused by inconsistent testing patterns in smaller regions, weak deploy-ability of forecasting models towards predicting cases in previously unseen regions, and model training biases caused by the imbalanced nature of data in COVID-19 epi-curves. Hence, the contributions of this study are three-fold; an optimized smoothing technique to smoothen less deterministic epi-curves based on epidemiological dynamics of that region, a Long-Short-Term-Memory (LSTM) based forecasting model trained using data from select regions to create a representative and diverse training set that maximizes deploy-ability in regions with lack of historical data, and an adaptive loss function whilst training to mitigate the data imbalances seen in epi-curves. The proposed smoothing technique, the generalized training strategy and the adaptive loss function largely increased the overall accuracy of the forecast, which enables efficient containment measures at a more localized micro-level.
Hybrid Autoregressive Solver for Scalable Abductive Natural Language Inference
Jul 25, 2021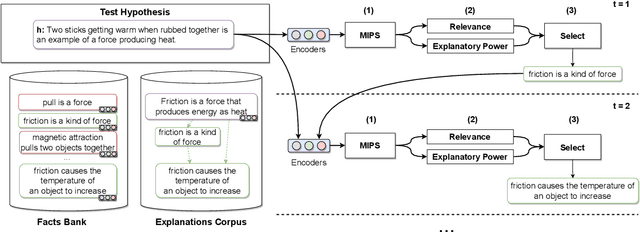

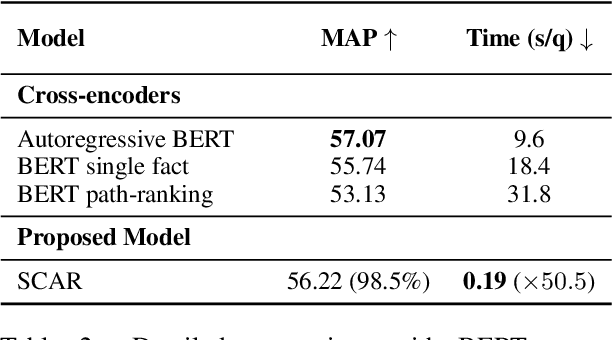
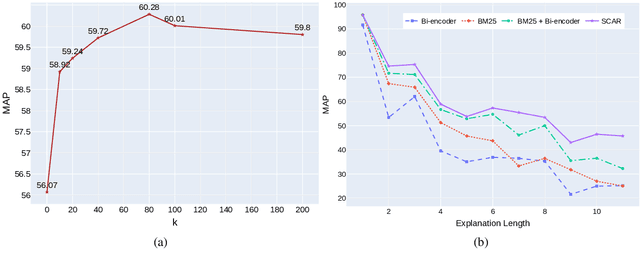
Regenerating natural language explanations for science questions is a challenging task for evaluating complex multi-hop and abductive inference capabilities. In this setting, Transformers trained on human-annotated explanations achieve state-of-the-art performance when adopted as cross-encoder architectures. However, while much attention has been devoted to the quality of the constructed explanations, the problem of performing abductive inference at scale is still under-studied. As intrinsically not scalable, the cross-encoder architectural paradigm is not suitable for efficient multi-hop inference on massive facts banks. To maximise both accuracy and inference time, we propose a hybrid abductive solver that autoregressively combines a dense bi-encoder with a sparse model of explanatory power, computed leveraging explicit patterns in the explanations. Our experiments demonstrate that the proposed framework can achieve performance comparable with the state-of-the-art cross-encoder while being $\approx 50$ times faster and scalable to corpora of millions of facts. Moreover, we study the impact of the hybridisation on semantic drift and science question answering without additional training, showing that it boosts the quality of the explanations and contributes to improved downstream inference performance.
A Study on Speech Enhancement Based on Diffusion Probabilistic Model
Jul 25, 2021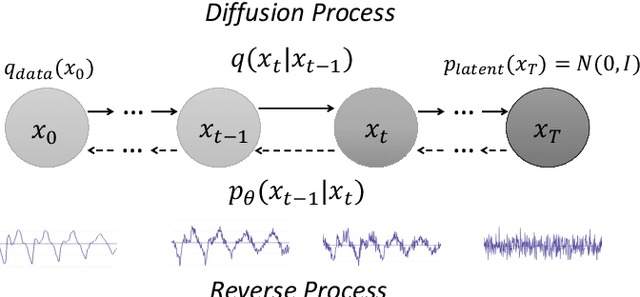
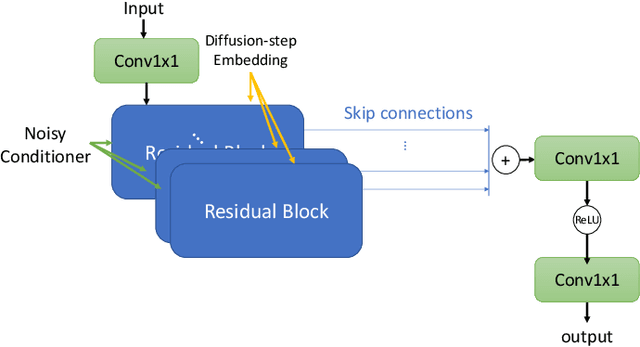
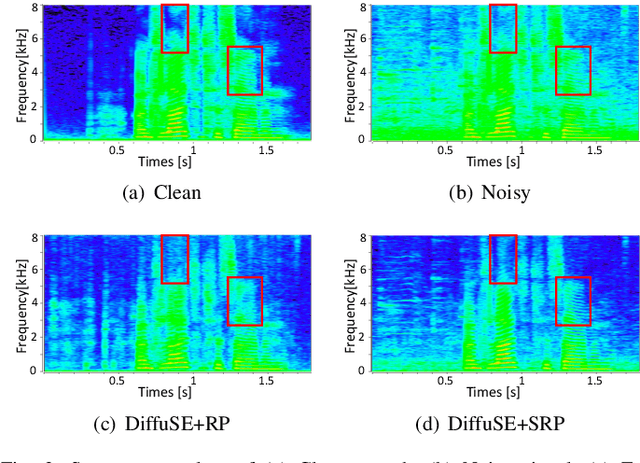
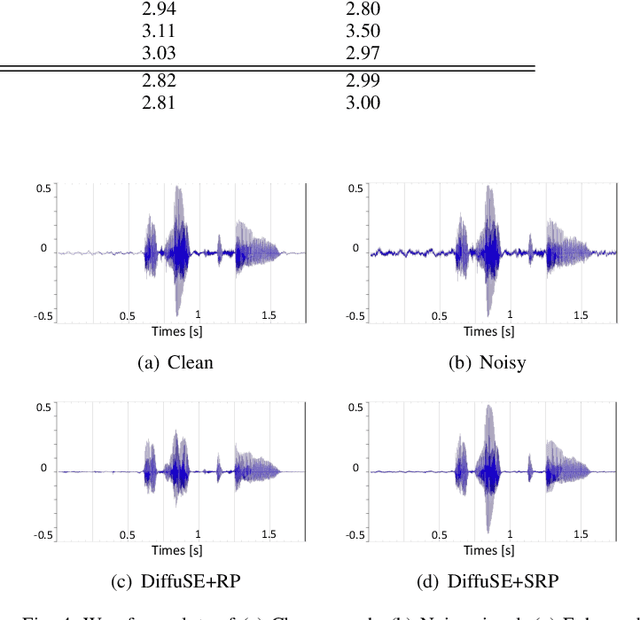
Diffusion probabilistic models have demonstrated an outstanding capability to model natural images and raw audio waveforms through a paired diffusion and reverse processes. The unique property of the reverse process (namely, eliminating non-target signals from the Gaussian noise and noisy signals) could be utilized to restore clean signals. Based on this property, we propose a diffusion probabilistic model-based speech enhancement (DiffuSE) model that aims to recover clean speech signals from noisy signals. The fundamental architecture of the proposed DiffuSE model is similar to that of DiffWave--a high-quality audio waveform generation model that has a relatively low computational cost and footprint. To attain better enhancement performance, we designed an advanced reverse process, termed the supportive reverse process, which adds noisy speech in each time-step to the predicted speech. The experimental results show that DiffuSE yields performance that is comparable to related audio generative models on the standardized Voice Bank corpus SE task. Moreover, relative to the generally suggested full sampling schedule, the proposed supportive reverse process especially improved the fast sampling, taking few steps to yield better enhancement results over the conventional full step inference process.
Joint Characterization of Spatiotemporal Data Manifolds
Aug 21, 2021Spatiotemporal (ST) image data are increasingly common and often high-dimensional (high-D). Modeling ST data can be a challenge due to the plethora of independent and interacting processes which may or may not contribute to the measurements. Characterization can be considered the complement to modeling by helping guide assumptions about generative processes and their representation in the data. Dimensionality reduction (DR) is a frequently implemented type of characterization designed to mitigate the "curse of dimensionality" on high-D signals. For decades, Principal Component (PC) and Empirical Orthogonal Function (EOF) analysis has been used as a linear, invertible approach to DR and ST analysis. Recent years have seen the additional development of a suite of nonlinear DR algorithms, frequently categorized as "manifold learning". Here, we explore the idea of joint characterization of ST data manifolds using PCs/EOFs alongside two nonlinear DR approaches: Laplacian Eigenmaps (LE) and t-distributed stochastic neighbor embedding (t-SNE). Starting with a synthetic example and progressing to global, regional, and field scale ST datasets spanning roughly 5 orders of magnitude in space and 2 in time, we show these three DR approaches can yield complementary information about ST manifold topology. Compared to the relatively diffuse TFS produced by PCs/EOFs, the nonlinear approaches yield more compact manifolds with decreased ambiguity in temporal endmembers (LE) and/or in spatiotemporal clustering (t-SNE). These properties are compensated by the greater interpretability, significantly lower computational demand and diminished sensitivity to spatial aliasing for PCs/EOFs than LE or t-SNE. Taken together, we find joint characterization using the three complementary DR approaches capable of greater insight into generative ST processes than possible using any single approach alone.
Circuit design and integration feasibility of a high-resolution broadband on-chip spectral monitor
Aug 12, 2021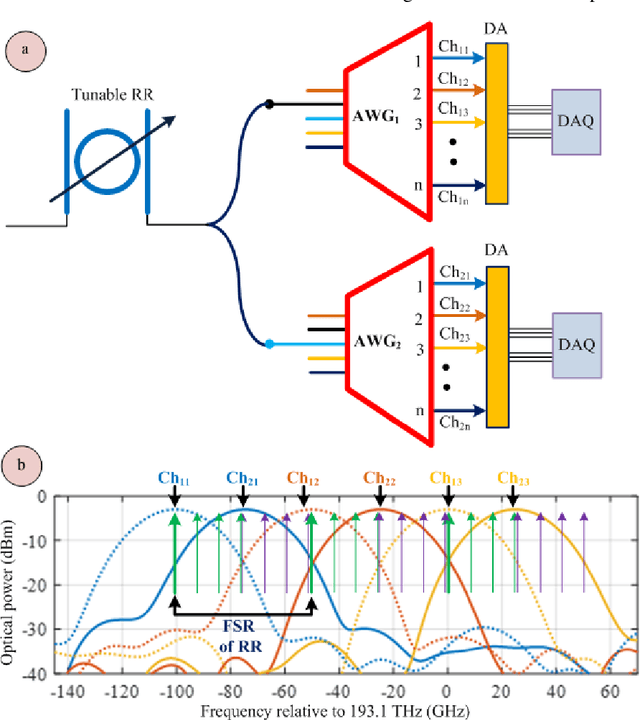

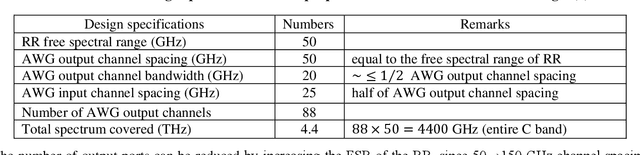
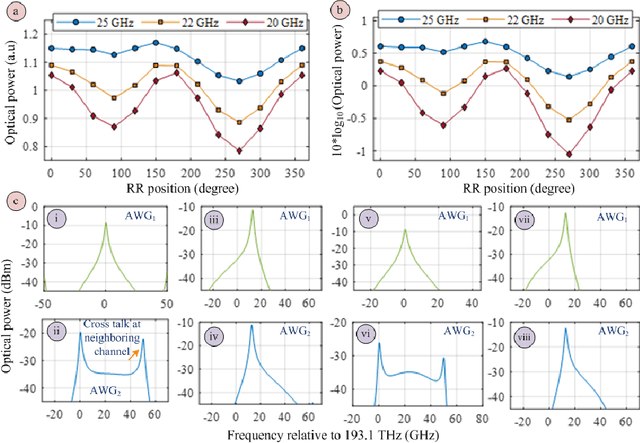
Up-to-date network telemetry is the key enabler for resource optimization by a variety of means including capacity scaling, fault recovery, network reconfiguration. Reliable optical performance monitoring in general and specifically the monitoring of the spectral profile of WDM signals in fixed- and flex-grid architecture across the entire C-band remains challenging. This article describes a spectrometer circuit architecture along with an original data processing algorithm that combined can measure the spectrum quantitatively across the entire C-band aiming at 1 GHz resolution bandwidth. The circuit is composed of a scanning ring resonator followed by a parallel arrangement of AWGs with interlaced channel spectra. The comb of ring resonances provides the high resolution and the algorithm creates a virtual tuneable AWG that isolates individual resonances of the comb within the flat pass-band of its synthesized channels. The parallel arrangement of AWGs may be replaced by a time multiplexed multi-input port AWG. The feasibility of a ring resonator functioning over whole C-band is experimentally validated. Full tuning of the comb of resonances over a free spectral range is achieved with a high-resolution bandwidth of 1.30 GHz. Due to its maturity and low loss, CMOS compatible silicon nitride is chosen for integration. Additionally, the whole system demonstration is presented using industry standard simulation tool. The architecture is robust to fabrication process variations owing to its data processing approach.
When Liebig's Barrel Meets Facial Landmark Detection: A Practical Model
May 27, 2021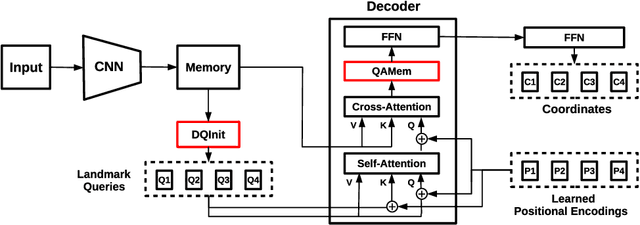
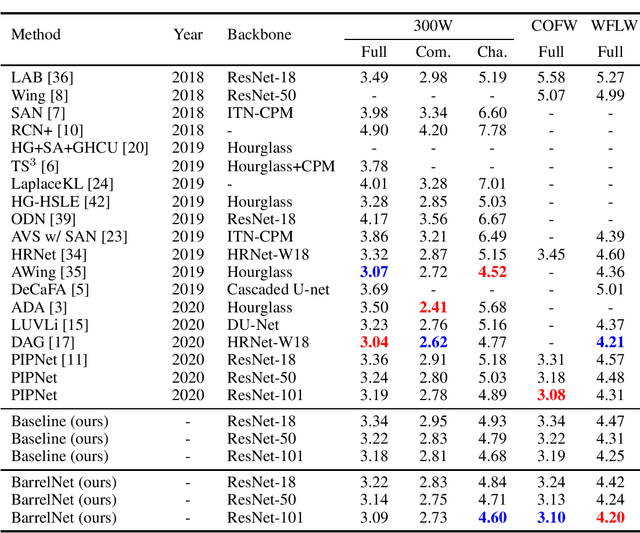
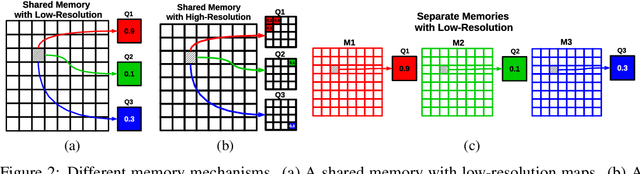
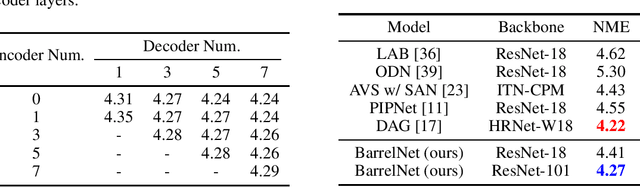
In recent years, significant progress has been made in the research of facial landmark detection. However, few prior works have thoroughly discussed about models for practical applications. Instead, they often focus on improving a couple of issues at a time while ignoring the others. To bridge this gap, we aim to explore a practical model that is accurate, robust, efficient, generalizable, and end-to-end trainable at the same time. To this end, we first propose a baseline model equipped with one transformer decoder as detection head. In order to achieve a better accuracy, we further propose two lightweight modules, namely dynamic query initialization (DQInit) and query-aware memory (QAMem). Specifically, DQInit dynamically initializes the queries of decoder from the inputs, enabling the model to achieve as good accuracy as the ones with multiple decoder layers. QAMem is designed to enhance the discriminative ability of queries on low-resolution feature maps by assigning separate memory values to each query rather than a shared one. With the help of QAMem, our model removes the dependence on high-resolution feature maps and is still able to obtain superior accuracy. Extensive experiments and analysis on three popular benchmarks show the effectiveness and practical advantages of the proposed model. Notably, our model achieves new state of the art on WFLW as well as competitive results on 300W and COFW, while still running at 50+ FPS.
Few-Shot Action Localization without Knowing Boundaries
Jun 08, 2021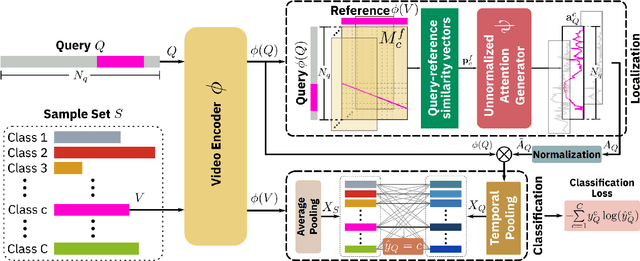

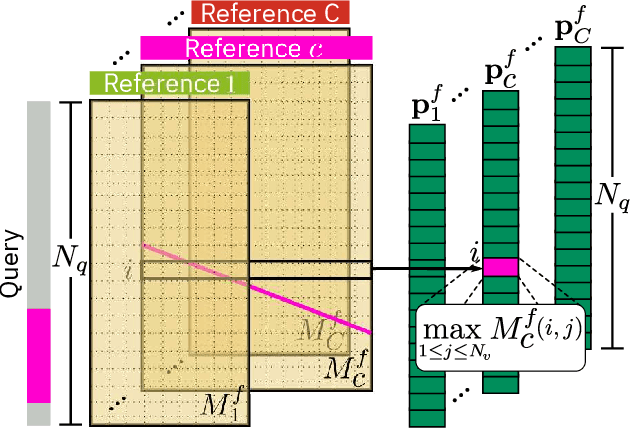
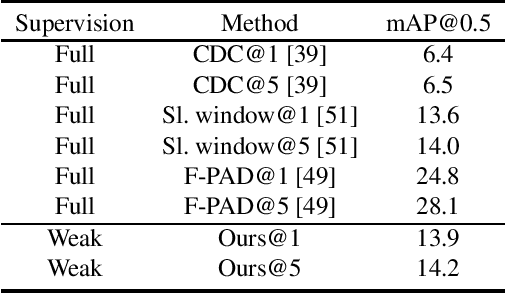
Learning to localize actions in long, cluttered, and untrimmed videos is a hard task, that in the literature has typically been addressed assuming the availability of large amounts of annotated training samples for each class -- either in a fully-supervised setting, where action boundaries are known, or in a weakly-supervised setting, where only class labels are known for each video. In this paper, we go a step further and show that it is possible to learn to localize actions in untrimmed videos when a) only one/few trimmed examples of the target action are available at test time, and b) when a large collection of videos with only class label annotation (some trimmed and some weakly annotated untrimmed ones) are available for training; with no overlap between the classes used during training and testing. To do so, we propose a network that learns to estimate Temporal Similarity Matrices (TSMs) that model a fine-grained similarity pattern between pairs of videos (trimmed or untrimmed), and uses them to generate Temporal Class Activation Maps (TCAMs) for seen or unseen classes. The TCAMs serve as temporal attention mechanisms to extract video-level representations of untrimmed videos, and to temporally localize actions at test time. To the best of our knowledge, we are the first to propose a weakly-supervised, one/few-shot action localization network that can be trained in an end-to-end fashion. Experimental results on THUMOS14 and ActivityNet1.2 datasets, show that our method achieves performance comparable or better to state-of-the-art fully-supervised, few-shot learning methods.
RRULES: An improvement of the RULES rule-based classifier
Jun 14, 2021
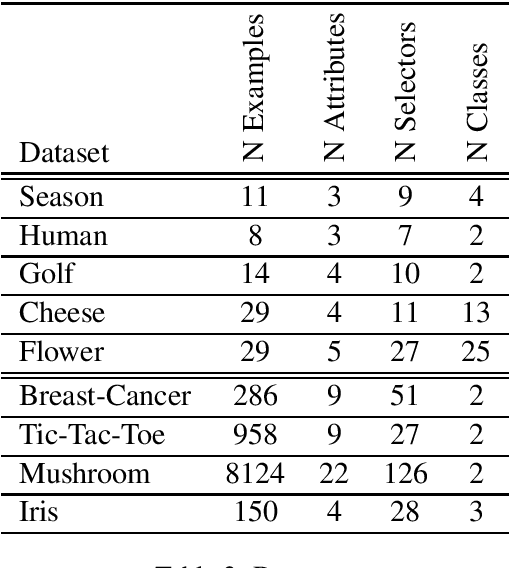
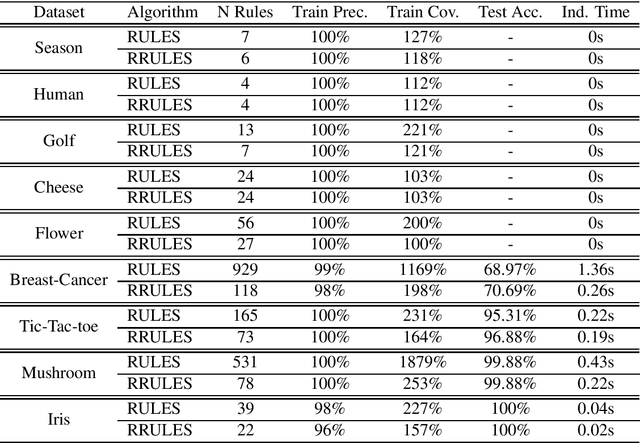
RRULES is presented as an improvement and optimization over RULES, a simple inductive learning algorithm for extracting IF-THEN rules from a set of training examples. RRULES optimizes the algorithm by implementing a more effective mechanism to detect irrelevant rules, at the same time that checks the stopping conditions more often. This results in a more compact rule set containing more general rules which prevent overfitting the training set and obtain a higher test accuracy. Moreover, the results show that RRULES outperforms the original algorithm by reducing the coverage rate up to a factor of 7 while running twice or three times faster consistently over several datasets.