 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Segmentation of Shoulder Muscle MRI Using a New Region and Edge based Deep Auto-Encoder
Aug 26, 2021
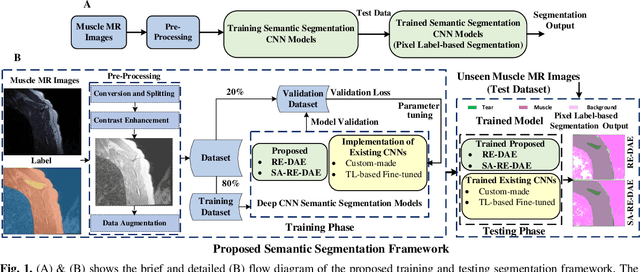
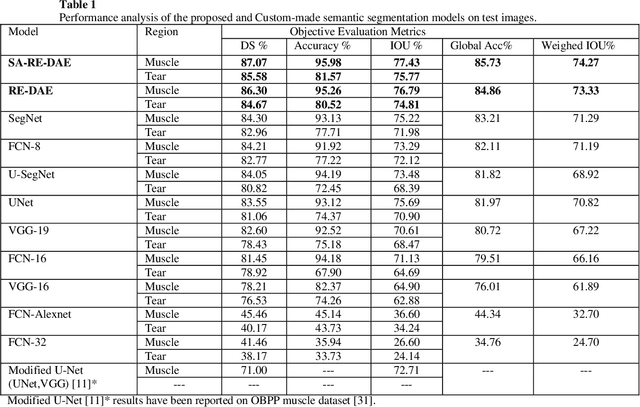
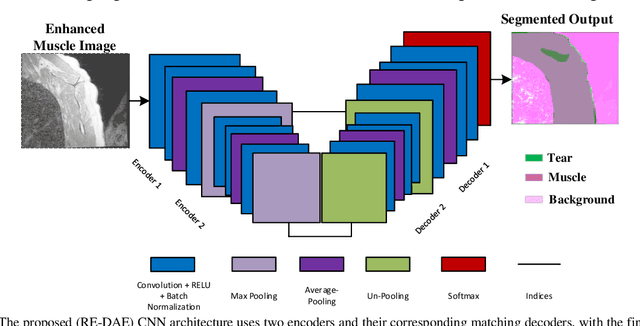
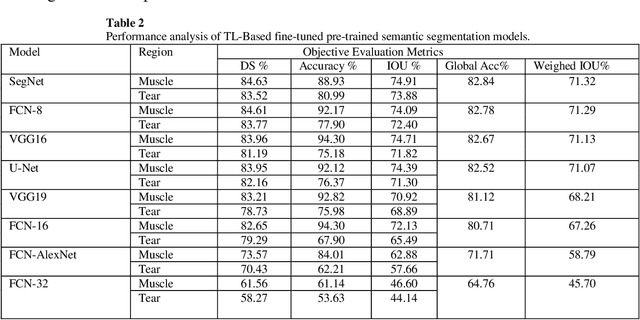
Automatic segmentation of shoulder muscle MRI is challenging due to the high variation in muscle size, shape, texture, and spatial position of tears. Manual segmentation of tear and muscle portion is hard, time-consuming, and subjective to pathological expertise. This work proposes a new Region and Edge-based Deep Auto-Encoder (RE-DAE) for shoulder muscle MRI segmentation. The proposed RE-DAE harmoniously employs average and max-pooling operation in the encoder and decoder blocks of the Convolutional Neural Network (CNN). Region-based segmentation incorporated in the Deep Auto-Encoder (DAE) encourages the network to extract smooth and homogenous regions. In contrast, edge-based segmentation tries to learn the boundary and anatomical information. These two concepts, systematically combined in a DAE, generate a discriminative and sparse hybrid feature space (exploiting both region homogeneity and boundaries). Moreover, the concept of static attention is exploited in the proposed RE-DAE that helps in effectively learning the tear region. The performances of the proposed MRI segmentation based DAE architectures have been tested using a 3D MRI shoulder muscle dataset using the hold-out cross-validation technique. The MRI data has been collected from the Korea University Anam Hospital, Seoul, South Korea. Experimental comparisons have been conducted by employing innovative custom-made and existing pre-trained CNN architectures both using transfer learning and fine-tuning. Objective evaluation on the muscle datasets using the proposed SA-RE-DAE showed a dice similarity of 85.58% and 87.07%, an accuracy of 81.57% and 95.58% for tear and muscle regions, respectively. The high visual quality and the objective result suggest that the proposed SA-RE-DAE is able to correctly segment tear and muscle regions in shoulder muscle MRI for better clinical decisions.
Improving Accuracy of Permutation DAG Search using Best Order Score Search
Aug 17, 2021The Sparsest Permutation (SP) algorithm is accurate but limited to about 9 variables in practice; the Greedy Sparest Permutation (GSP) algorithm is faster but less weak theoretically. A compromise can be given, the Best Order Score Search, which gives results as accurate as SP but for much larger and denser graphs. BOSS (Best Order Score Search) is more accurate for two reason: (a) It assumes the "brute faithfuness" assumption, which is weaker than faithfulness, and (b) it uses a different traversal of permutations than the depth first traversal used by GSP, obtained by taking each variable in turn and moving it to the position in the permutation that optimizes the model score. Results are given comparing BOSS to several related papers in the literature in terms of performance, for linear, Gaussian data. In all cases, with the proper parameter settings, accuracy of BOSS is lifted considerably with respect to competing approaches. In configurations tested, models with 60 variables are feasible with large samples out to about an average degree of 12 in reasonable time, with near-perfect accuracy, and sparse models with an average degree of 4 are feasible out to about 300 variables on a laptop, again with near-perfect accuracy. Mixed continuous discrete and all-discrete datasets were also tested. The mixed data analysis showed advantage for BOSS over GES more apparent at higher depths with the same score; the discrete data analysis showed a very small advantage for BOSS over GES with the same score, perhaps not enough to prefer it.
Species Distribution Modeling for Machine Learning Practitioners: A Review
Jul 03, 2021
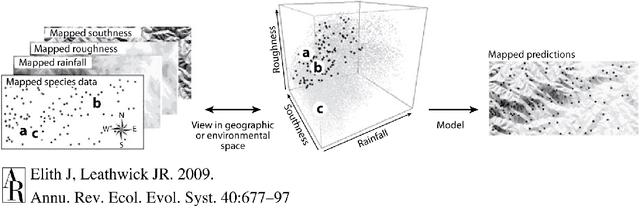

Conservation science depends on an accurate understanding of what's happening in a given ecosystem. How many species live there? What is the makeup of the population? How is that changing over time? Species Distribution Modeling (SDM) seeks to predict the spatial (and sometimes temporal) patterns of species occurrence, i.e. where a species is likely to be found. The last few years have seen a surge of interest in applying powerful machine learning tools to challenging problems in ecology. Despite its considerable importance, SDM has received relatively little attention from the computer science community. Our goal in this work is to provide computer scientists with the necessary background to read the SDM literature and develop ecologically useful ML-based SDM algorithms. In particular, we introduce key SDM concepts and terminology, review standard models, discuss data availability, and highlight technical challenges and pitfalls.
Convolutional Neural Network(CNN/ConvNet) in Stock Price Movement Prediction
Jun 03, 2021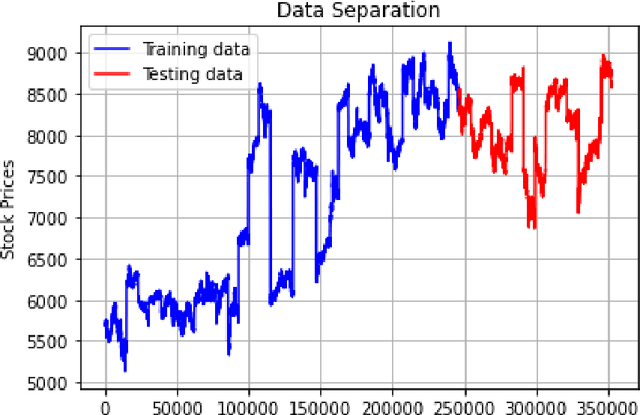
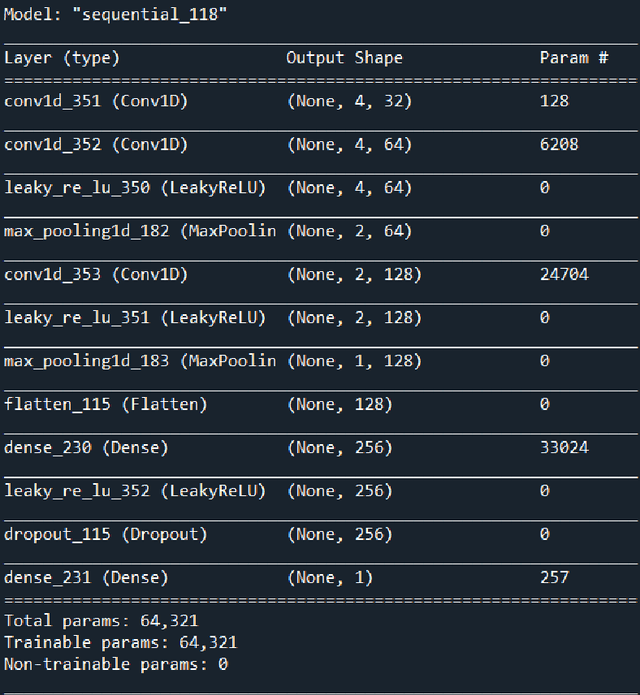
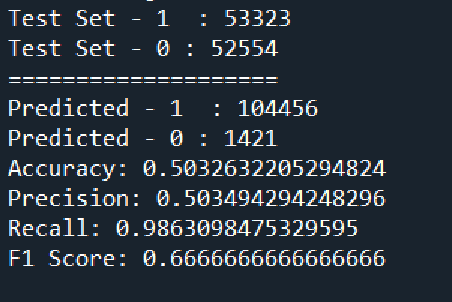
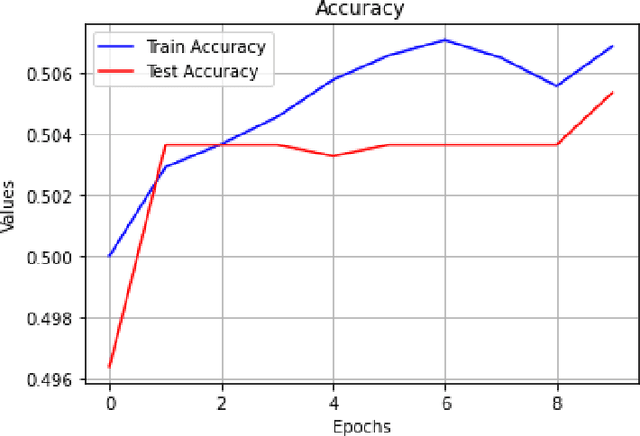
With technological advancements and the exponential growth of data, we have been unfolding different capabilities of neural networks in different sectors. In this paper, I have tried to use a specific type of Neural Network known as Convolutional Neural Network(CNN/ConvNet) in the stock market. In other words, I have tried to construct and train a convolutional neural network on past stock prices data and then tried to predict the movement of stock price i.e. whether the stock price would rise or fall, in the coming time.
LookUP: Vision-Only Real-Time Precise Underground Localisation for Autonomous Mining Vehicles
Mar 20, 2019

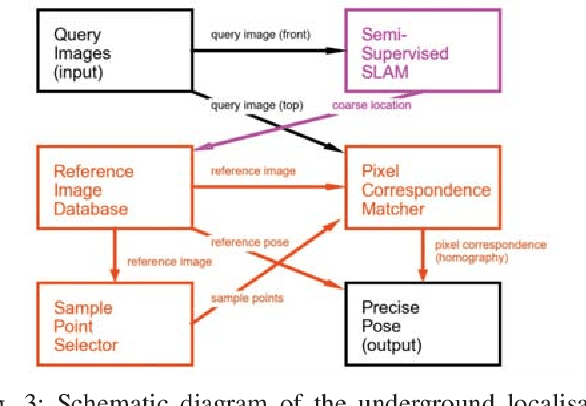

A key capability for autonomous underground mining vehicles is real-time accurate localisation. While significant progress has been made, currently deployed systems have several limitations ranging from dependence on costly additional infrastructure to failure of both visual and range sensor-based techniques in highly aliased or visually challenging environments. In our previous work, we presented a lightweight coarse vision-based localisation system that could map and then localise to within a few metres in an underground mining environment. However, this level of precision is insufficient for providing a cheaper, more reliable vision-based automation alternative to current range sensor-based systems. Here we present a new precision localisation system dubbed "LookUP", which learns a neural-network-based pixel sampling strategy for estimating homographies based on ceiling-facing cameras without requiring any manual labelling. This new system runs in real time on limited computation resource and is demonstrated on two different underground mine sites, achieving real time performance at ~5 frames per second and a much improved average localisation error of ~1.2 metre.
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018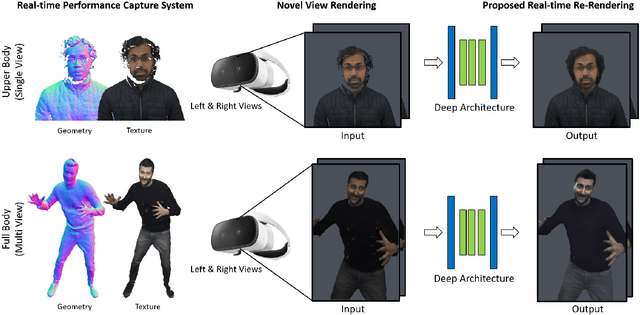



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
System identification using Bayesian neural networks with nonparametric noise models
Apr 25, 2021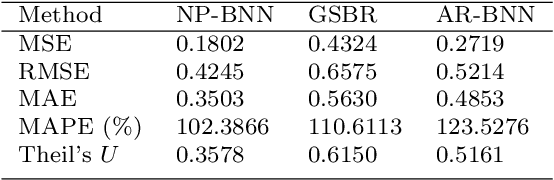
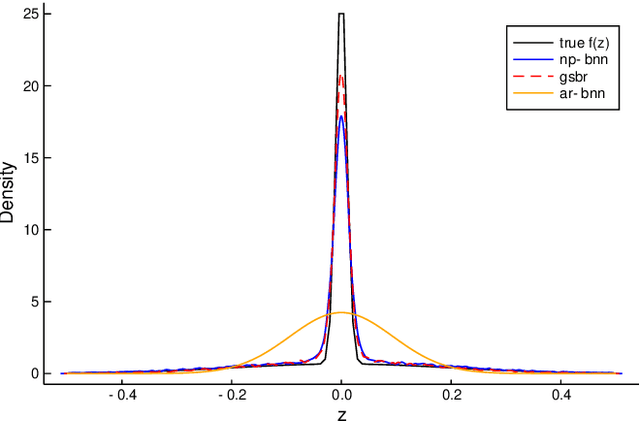
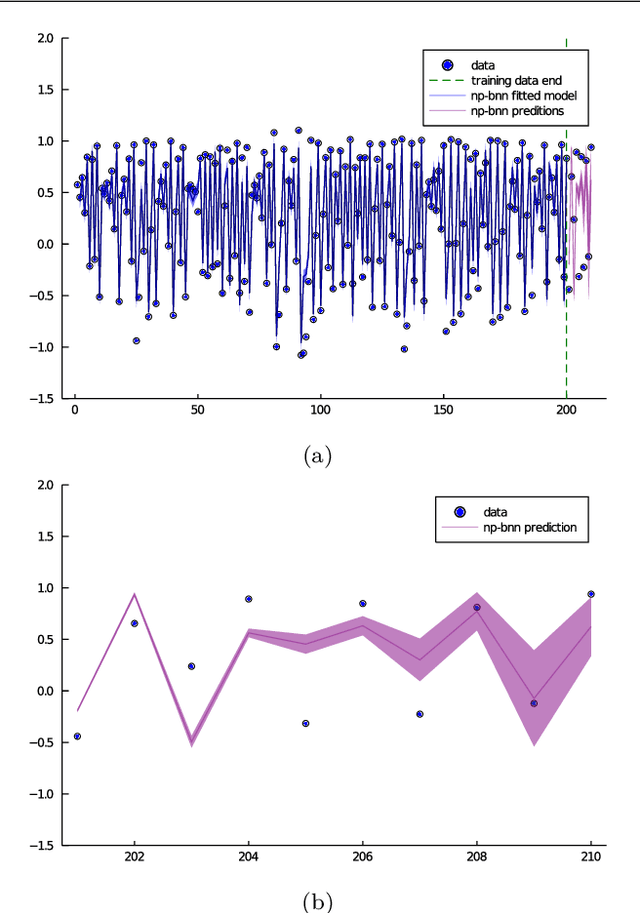
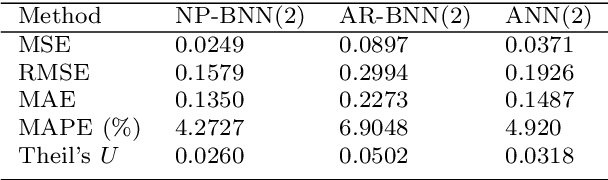
System identification is of special interest in science and engineering. This article is concerned with a system identification problem arising in stochastic dynamic systems, where the aim is to estimating the parameters of a system along with its unknown noise processes. In particular, we propose a Bayesian nonparametric approach for system identification in discrete time nonlinear random dynamical systems assuming only the order of the Markov process is known. The proposed method replaces the assumption of Gaussian distributed error components with a highly flexible family of probability density functions based on Bayesian nonparametric priors. Additionally, the functional form of the system is estimated by leveraging Bayesian neural networks which also leads to flexible uncertainty quantification. Asymptotically on the number of hidden neurons, the proposed model converges to full nonparametric Bayesian regression model. A Gibbs sampler for posterior inference is proposed and its effectiveness is illustrated in simulated and real time series.
Hitting Time of Stochastic Gradient Langevin Dynamics to Stationary Points: A Direct Analysis
Apr 30, 2019Stochastic gradient Langevin dynamics (SGLD) is a fundamental algorithm in stochastic optimization. Recent work by Zhang et al. [2017] presents an analysis for the hitting time of SGLD for the first and second order stationary points. The proof in Zhang et al. [2017] is a two-stage procedure through bounding the Cheeger's constant, which is rather complicated and leads to loose bounds. In this paper, using intuitions from stochastic differential equations, we provide a direct analysis for the hitting times of SGLD to the first and second order stationary points. Our analysis is straightforward. It only relies on basic linear algebra and probability theory tools. Our direct analysis also leads to tighter bounds comparing to Zhang et al. [2017] and shows the explicit dependence of the hitting time on different factors, including dimensionality, smoothness, noise strength, and step size effects. Under suitable conditions, we show that the hitting time of SGLD to first-order stationary points can be dimension-independent. Moreover, we apply our analysis to study several important online estimation problems in machine learning, including linear regression, matrix factorization, and online PCA.
Efficient Temporal Piecewise-Linear Numeric Planning with Lazy Consistency Checking
May 21, 2021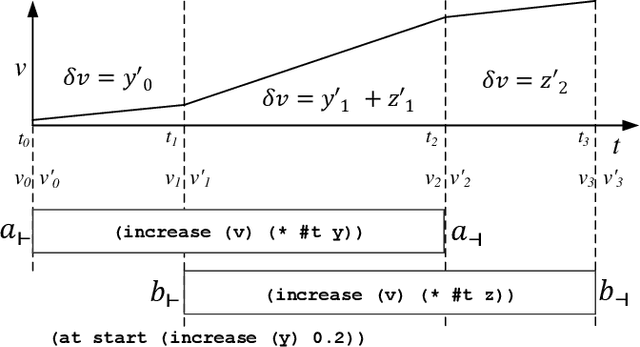

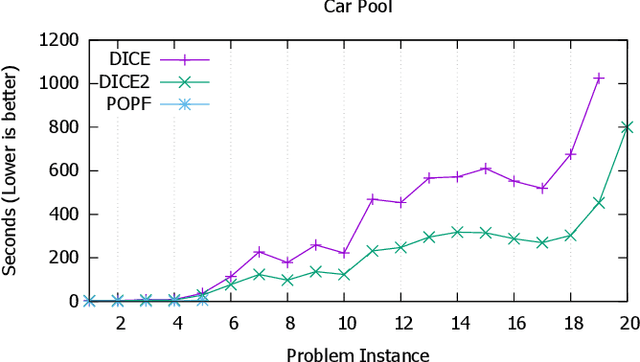
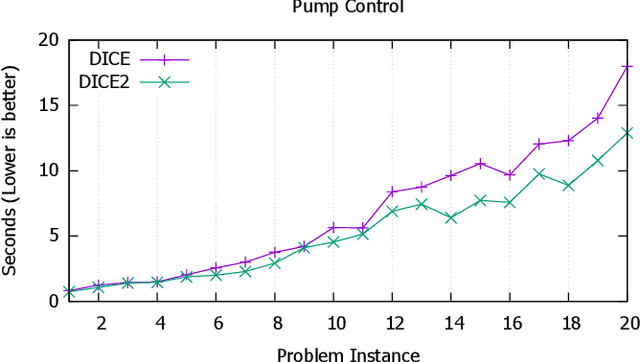
State-of-the-art temporal planners that support continuous numeric effects typically interweave search with scheduling to ensure temporal consistency. If such effects are linear, this process often makes use of Linear Programming (LP) to model the relationship between temporal constraints and conditions on numeric fluents that are subject to duration-dependent effects. While very effective on benchmark domains, this approach does not scale well when solving real-world problems that require long plans. We propose a set of techniques that allow the planner to compute LP consistency checks lazily where possible, significantly reducing the computation time required, thus allowing the planner to solve larger problem instances within an acceptable time-frame. We also propose an algorithm to perform duration-dependent goal checking more selectively. Furthermore, we propose an LP formulation with a smaller footprint that removes linearity restrictions on discrete effects applied within segments of the plan where a numeric fluent is not duration dependent. The effectiveness of these techniques is demonstrated on domains that use a mix of discrete and continuous effects, which is typical of real-world planning problems. The resultant planner is not only more efficient, but outperforms most state-of-the-art temporal-numeric and hybrid planners, in terms of both coverage and scalability.
DIODE: Dilatable Incremental Object Detection
Aug 12, 2021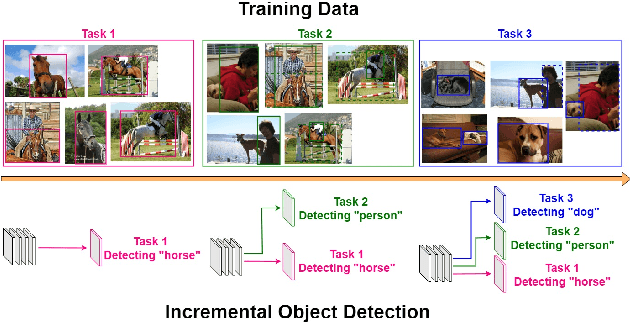



To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.